{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Pipeline Parallelism\n",
"이번 세션에서는 파이프라인 병렬화에 대해 알아보겠습니다.\n",
"\n",
"## 1. Inter-layer model parallelism\n",
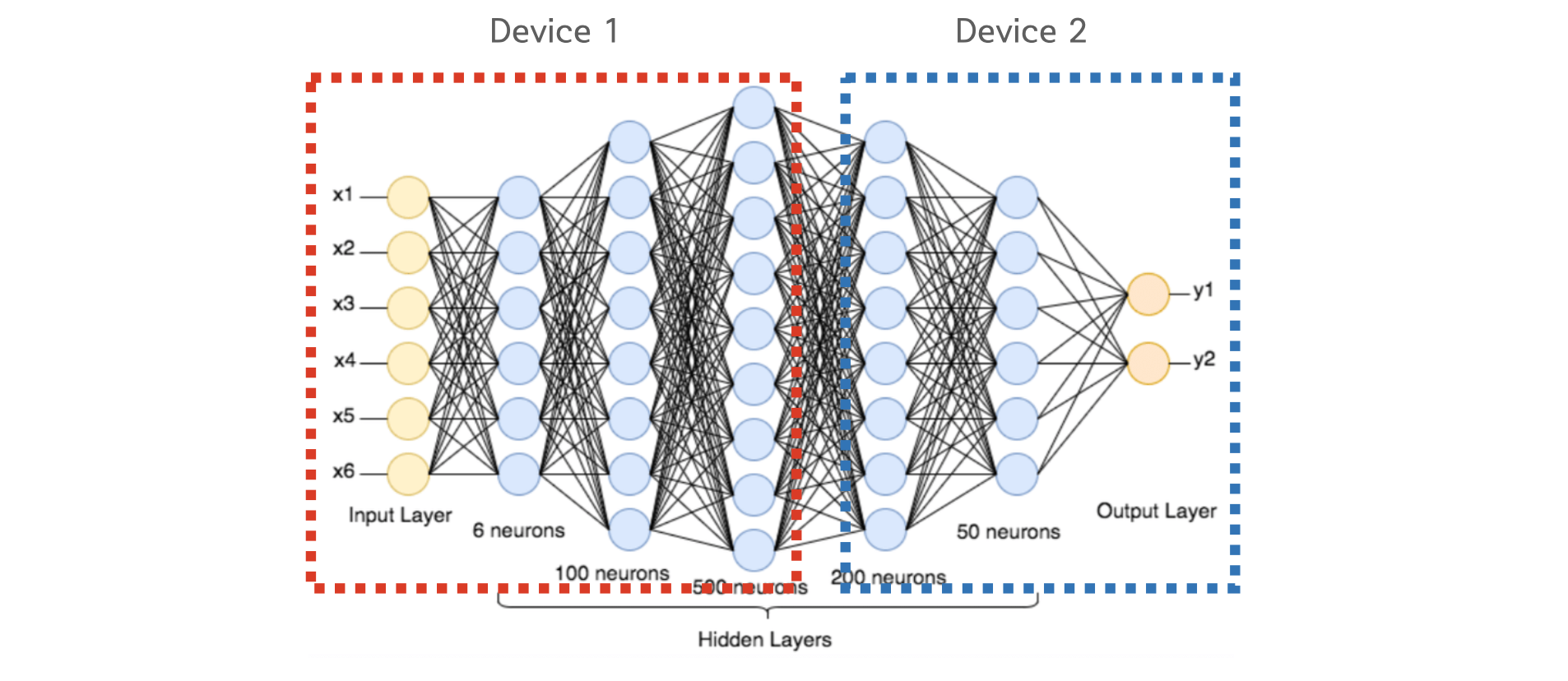
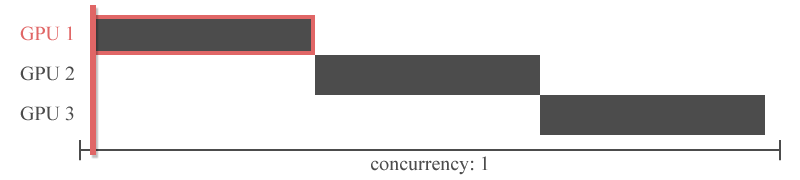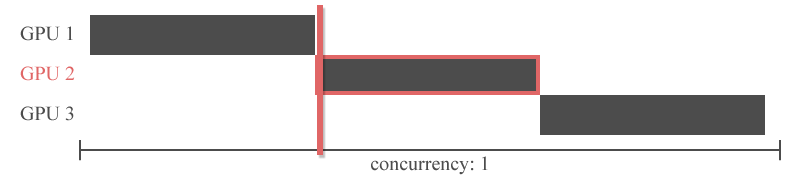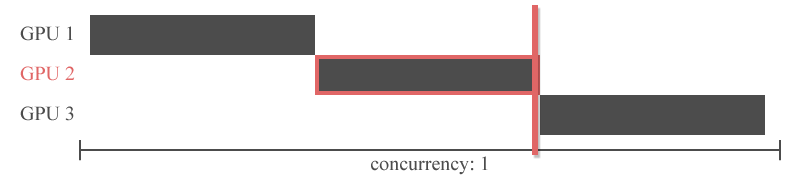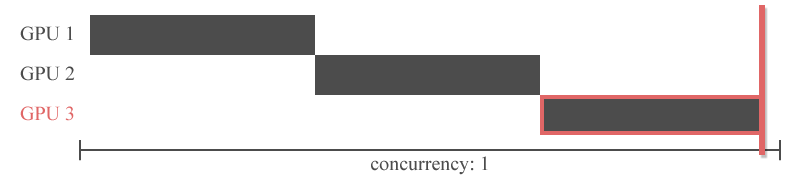
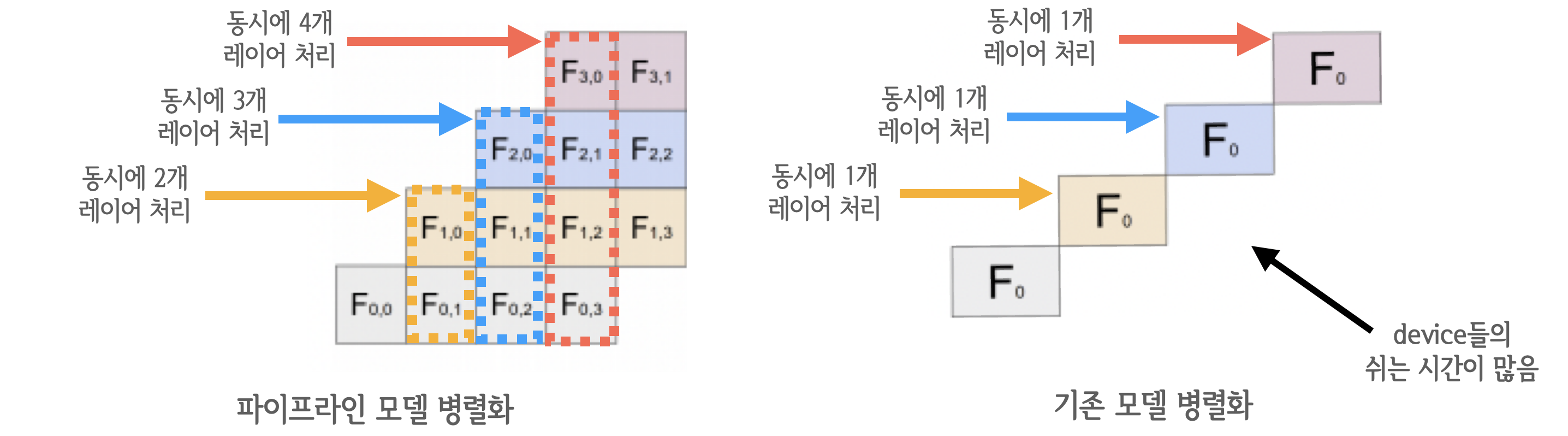
"파이프라인 병렬화는 Inter-layer 모델 병렬화를 개선한 것입니다. Inter-layer 모델 병렬화는 아래와 같이 특정 GPU에 특정 레이어들을 할당하는 모델 병렬화 방법이였죠. 아래 그림에서는 GPU1번에 1,2,3번 레이어가 할당되었고, GPU2번에 4,5번 레이어가 할당 되었는데, 이 때 쪼개진 하나의 조각을 `stage(스테이지)`라고 합니다. 아래 예시의 경우 2개의 스테이지로 분할되었습니다.\n",
"\n",
"\n",
"\n",
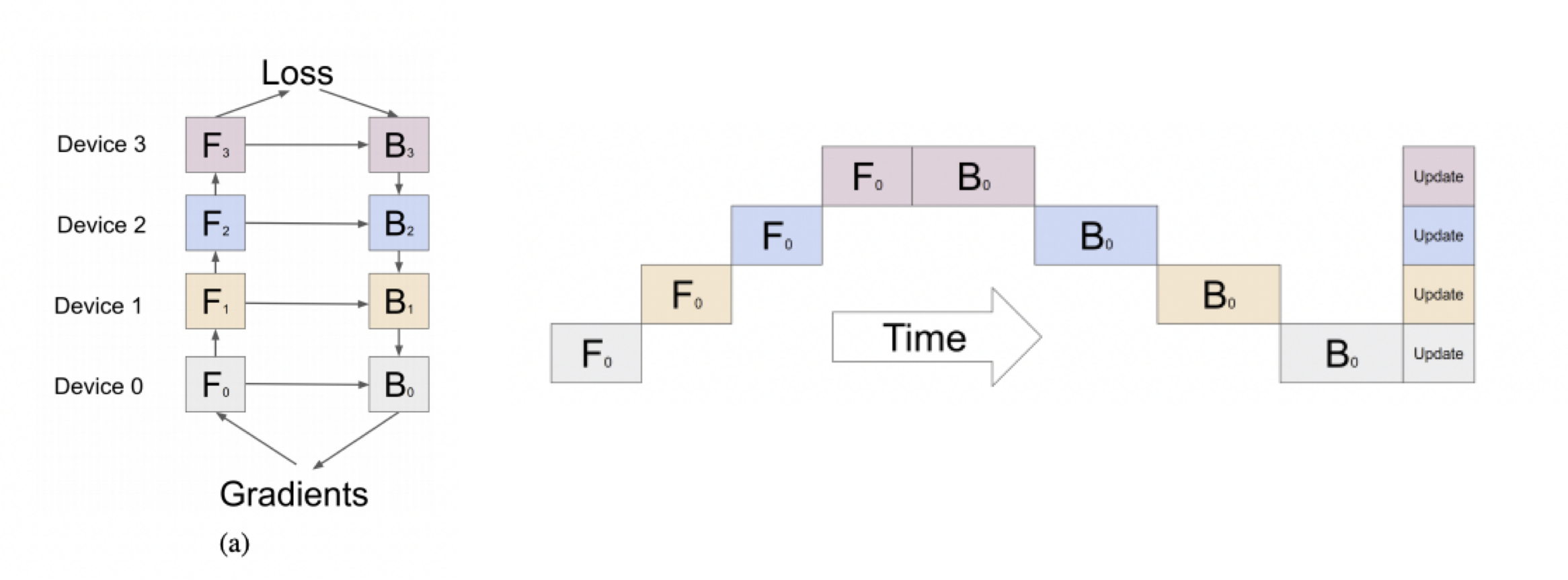
"그러나 이전 레이어의 출력을 다음 레이어의 입력으로 하는 신경망의 특성상 특정 GPU의 연산이 끝나야 다른 GPU가 연산을 시작할 수 있습니다. 즉, 아래의 그림처럼 Inter-layer 모델 병렬화는 동시에 하나의 GPU만 사용할 수 있다는 치명적인 한계를 가지고 있습니다.\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. GPipe\n",
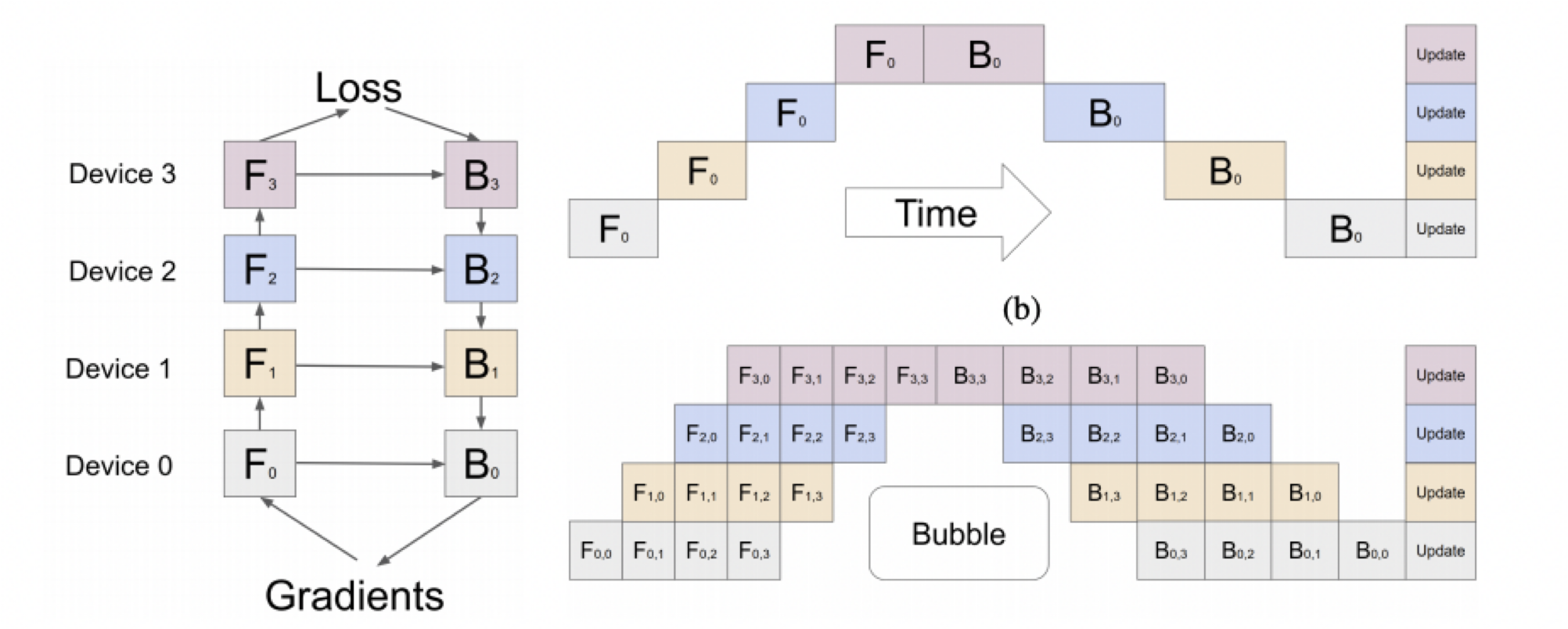
"GPipe는 Google에서 개발된 파이프라인 병렬화 기법으로 Inter Layer 모델 병렬화 시 GPU가 쉬는 시간 (idle time)을 줄이기 위해 등장했으며, mini-batch를 micro-batch로 한번 더 쪼개서 학습 과정을 파이프라이닝 하는 방식으로 동작합니다.\n",
"\n",
"\n",
"\n",
"
\n",
"
\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"### Micro-batch\n",
"- Mini-batch는 전체 데이터셋을 n개로 분할한 서브샘플 집합입니다.\n",
"- Micro-batch는 Mini-batch를 m개로 한번 더 분할한 서브샘플 집합입니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"### Pipelining\n",
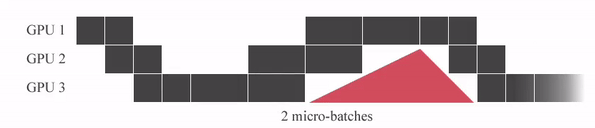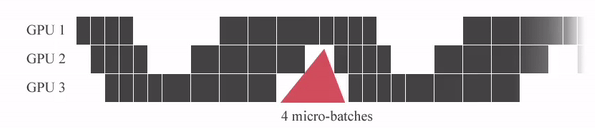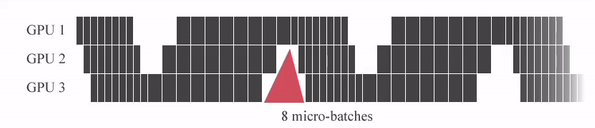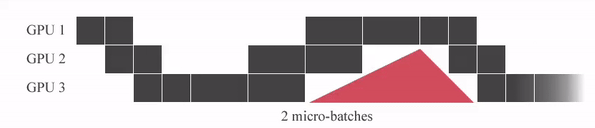
"GPipe는 미니배치를 마이크로 배치로 쪼개고 연산을 파이프라이닝 합니다. 붉은색 (GPU가 쉬는 부분)을 Bubble time이라고 하는데, Micro batch 사이즈가 커질 수록 Bubble time이 줄어드는 것을 알 수 있습니다.\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### GPipe with PyTorch\n",
"kakaobrain에서 공개한 `torchgpipe`를 사용하면 손쉽게 GPipe를 사용할 수 있습니다. 단, `nn.Sequential`로 래핑된 모델만 사용 가능하며 모든 모듈의 입력과 출력 타입은 `torch.Tensor` 혹은 `Tuple[torch.Tensor]`로 제한됩니다. 따라서 코딩하기가 상당히 까다롭습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/gpipe.py\n",
"\"\"\"\n",
"\n",
"import torch\n",
"import torch.nn as nn\n",
"from datasets import load_dataset\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader\n",
"from torchgpipe import GPipe\n",
"from transformers import GPT2Tokenizer, GPT2LMHeadModel\n",
"from transformers.models.gpt2.modeling_gpt2 import GPT2Block as GPT2BlockBase\n",
"\n",
"\n",
"class GPT2Preprocessing(nn.Module):\n",
" def __init__(self, config):\n",
" super().__init__()\n",
" self.embed_dim = config.hidden_size\n",
" self.wte = nn.Embedding(config.vocab_size, self.embed_dim)\n",
" self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)\n",
" self.drop = nn.Dropout(config.embd_pdrop)\n",
"\n",
" def forward(self, input_ids):\n",
" input_shape = input_ids.size()\n",
" input_ids = input_ids.view(-1, input_shape[-1])\n",
" position_ids = torch.arange(\n",
" 0, input_shape[-1], dtype=torch.long, device=input_ids.device\n",
" )\n",
" position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])\n",
" inputs_embeds = self.wte(input_ids)\n",
" position_embeds = self.wpe(position_ids)\n",
" hidden_states = inputs_embeds + position_embeds\n",
" hidden_states = self.drop(hidden_states)\n",
" return hidden_states\n",
"\n",
"\n",
"class GPT2Block(GPT2BlockBase):\n",
" def forward(self, hidden_states):\n",
" hidden_states = super(GPT2Block, self).forward(\n",
" hidden_states=hidden_states,\n",
" )\n",
" return hidden_states[0]\n",
"\n",
"\n",
"class GPT2Postprocessing(nn.Module):\n",
" def __init__(self, config):\n",
" super().__init__()\n",
" self.ln_f = nn.LayerNorm(\n",
" config.hidden_size,\n",
" eps=config.layer_norm_epsilon,\n",
" )\n",
" self.lm_head = nn.Linear(\n",
" config.hidden_size,\n",
" config.vocab_size,\n",
" bias=False,\n",
" )\n",
"\n",
" def forward(self, hidden_states):\n",
" hidden_states = self.ln_f(hidden_states)\n",
" lm_logits = self.lm_head(hidden_states)\n",
" return lm_logits\n",
"\n",
"\n",
"def create_model_from_pretrained(model_name):\n",
" pretrained = GPT2LMHeadModel.from_pretrained(model_name)\n",
" preprocess = GPT2Preprocessing(pretrained.config)\n",
" preprocess.wte.weight = pretrained.transformer.wte.weight\n",
" preprocess.wpe.weight = pretrained.transformer.wpe.weight\n",
"\n",
" blocks = pretrained.transformer.h\n",
" for i, block in enumerate(blocks):\n",
" block.__class__ = GPT2Block\n",
"\n",
" postprocess = GPT2Postprocessing(pretrained.config)\n",
" postprocess.ln_f.weight = pretrained.transformer.ln_f.weight\n",
" postprocess.ln_f.bias = pretrained.transformer.ln_f.bias\n",
" postprocess.lm_head.weight.data = pretrained.lm_head.weight.data.clone()\n",
"\n",
" return nn.Sequential(preprocess, *blocks, postprocess)\n",
"\n",
"\n",
"if __name__ == \"__main__\":\n",
" world_size = 4\n",
"\n",
" tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\n",
" tokenizer.pad_token = tokenizer.eos_token\n",
"\n",
" model = create_model_from_pretrained(model_name=\"gpt2\")\n",
" model = GPipe(\n",
" model,\n",
" balance=[4, 3, 3, 4],\n",
" devices=[0, 1, 2, 3],\n",
" chunks=world_size,\n",
" )\n",
"\n",
" datasets = load_dataset(\"squad\").data[\"train\"][\"context\"]\n",
" datasets = [str(sample) for sample in datasets]\n",
" data_loader = DataLoader(datasets, batch_size=8, num_workers=8)\n",
"\n",
" optimizer = Adam(model.parameters(), lr=3e-5)\n",
" loss_fn = nn.CrossEntropyLoss()\n",
"\n",
" for i, data in enumerate(data_loader):\n",
" optimizer.zero_grad()\n",
" tokens = tokenizer(data, return_tensors=\"pt\", truncation=True, padding=True)\n",
" input_ids = tokens.input_ids.to(0)\n",
" labels = tokens.input_ids.to(world_size - 1)\n",
"\n",
" lm_logits = model(input_ids)\n",
" shift_logits = lm_logits[..., :-1, :].contiguous()\n",
" shift_labels = labels[..., 1:].contiguous()\n",
" loss = nn.CrossEntropyLoss()(\n",
" shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)\n",
" )\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" if i % 10 == 0:\n",
" print(f\"step: {i}, loss: {loss}\")\n",
" if i == 300:\n",
" break\n"
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|█████████████████████████████████████████████| 2/2 [00:00<00:00, 55.94it/s]\n",
"step: 0, loss: 6.084661483764648\n",
"step: 10, loss: 3.2574026584625244\n",
"step: 20, loss: 2.796205759048462\n",
"step: 30, loss: 2.5538008213043213\n",
"step: 40, loss: 2.8463237285614014\n",
"step: 50, loss: 2.3466761112213135\n",
"step: 60, loss: 2.5407633781433105\n",
"step: 70, loss: 2.2434418201446533\n",
"step: 80, loss: 2.4792842864990234\n",
"step: 90, loss: 2.9400510787963867\n",
"step: 100, loss: 2.8163280487060547\n",
"step: 110, loss: 2.4787795543670654\n",
"step: 120, loss: 2.9588236808776855\n",
"step: 130, loss: 2.3893203735351562\n",
"step: 140, loss: 2.9571073055267334\n",
"step: 150, loss: 3.9219329357147217\n",
"step: 160, loss: 3.023880958557129\n",
"step: 170, loss: 3.018484592437744\n",
"step: 180, loss: 1.6825034618377686\n",
"step: 190, loss: 3.5461761951446533\n",
"step: 200, loss: 3.6606838703155518\n",
"step: 210, loss: 3.527740001678467\n",
"step: 220, loss: 2.988645315170288\n",
"step: 230, loss: 3.1758480072021484\n",
"step: 240, loss: 2.5451812744140625\n",
"step: 250, loss: 3.1476473808288574\n",
"step: 260, loss: 3.4633867740631104\n",
"step: 270, loss: 3.199225902557373\n",
"step: 280, loss: 2.612720489501953\n",
"step: 290, loss: 2.139256238937378\n",
"step: 300, loss: 3.437178373336792\n"
]
}
],
"source": [
"# !python -m torch.distributed.launch --nproc_per_node=4 ../src/gpipe.py\n",
"!python ../src/gpipe.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## 3. 1F1B Pipelining (PipeDream)\n",
"\n",
"Microsoft에서 공개한 `PipeDream`은 `GPipe`와는 약간 다른 방식의 파이프라이닝을 수행합니다. 흔히 이 방법을 1F1B라고 부르는데, 모든 Forward가 끝나고 나서 Backward를 수행하는 GPipe와 달리 `PipeDream`은 Forward와 Backward를 번갈아가면서 수행합니다.\n",
"\n",
" \n",
"\n",
"1F1B Pipelining에는 다음과 같은 두가지 챌린지가 존재합니다.\n",
"1. Weight version managing\n",
"2. Work partitioning\n",
"\n",
"
\n",
"\n",
"1F1B Pipelining에는 다음과 같은 두가지 챌린지가 존재합니다.\n",
"1. Weight version managing\n",
"2. Work partitioning\n",
"\n",
"
\n",
"\n",
"### 1) Weight version managinig\n",
"GPipe의 경우 하나의 weight 버전만 운용하지만 주기적으로 Pipeline flush가 일어납니다. Pipeline flush란 계산된 Gradient를 통해 파라미터를 업데이트 하는 과정입니다. 이러한 flush 과정 중에는 어떠한 forward, backward 연산도 하지 않기 때문에 처리 효율이 떨어집니다.\n",
"\n",
" \n",
"\n",
"PipeDream은 이러한 flush 없이 계속해서 파라미터를 업데이트 해나갑니다. 따라서 forward와 backward가 모두 쉬는 시간이 사라집니다. 그러나 이를 위해서는 여러 버전의 파라미터 상태를 지속적으로 관리해야 합니다. 만약 최신버전의 파라미터만 저장하고 있으면 이전 layer의 출력이 다음 layer로 전송될 때, 다음 layer 부분이 업데이트 될 수도 있기 때문이죠.\n",
"\n",
"
\n",
"\n",
"PipeDream은 이러한 flush 없이 계속해서 파라미터를 업데이트 해나갑니다. 따라서 forward와 backward가 모두 쉬는 시간이 사라집니다. 그러나 이를 위해서는 여러 버전의 파라미터 상태를 지속적으로 관리해야 합니다. 만약 최신버전의 파라미터만 저장하고 있으면 이전 layer의 출력이 다음 layer로 전송될 때, 다음 layer 부분이 업데이트 될 수도 있기 때문이죠.\n",
"\n",
" \n",
"\n",
"이러한 문제를 막기 위해 여러 버전의 weight를 저장하여 관리하는데 그러면 weight를 저장하면 메모리 공간을 많이 차지하게 됩니다. 따라서 이 부분에서 트레이드 오프가 발생합니다.\n",
"- GPipe: 메모리 효율적, 프로세싱 비효율적\n",
"- PipeDream: 메모리 비효율적, 프로세싱 효율적\n",
" \n",
"
\n",
"\n",
"이러한 문제를 막기 위해 여러 버전의 weight를 저장하여 관리하는데 그러면 weight를 저장하면 메모리 공간을 많이 차지하게 됩니다. 따라서 이 부분에서 트레이드 오프가 발생합니다.\n",
"- GPipe: 메모리 효율적, 프로세싱 비효율적\n",
"- PipeDream: 메모리 비효율적, 프로세싱 효율적\n",
" \n",
"
\n",
"\n",
"### 2) Work Partitioning\n",
"두번쨰 문제는 뉴럴넷을 어떻게 쪼갤건지에 대한 문제입니다. 단순히 Layer별로 동일한 수의 레이어를 갖게끔 하는 것이 항상 최고의 솔루션이라고 할 수는 없겠죠. 우리에게 가장 중요한 것은 idle time을 최소화을 최소화 하는 것입니다. 그러기 위해서는 각 파티션의 running time이 비슷해야겠죠. 그 이외에도 추가로 parameter size, activation memory 등을 고려해야 합니다.\n",
"\n",
" \n",
"\n",
"PipeDream은 Profiling과 Optimizing을 통해 최적의 Partioning 전략을 찾아냅니다.\n",
"\n",
"
\n",
"\n",
"PipeDream은 Profiling과 Optimizing을 통해 최적의 Partioning 전략을 찾아냅니다.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4. Variations of 1F1B Pipelining\n",
"\n",
"PipeDream의 1F1B 파이프라이닝을 개선한 두가지 버전의 파이프라인 전략을 소개합니다.\n",
"\n",
"
\n",
"\n",
"### 1) PipeDream 2BW (2-buffered weight update)\n",
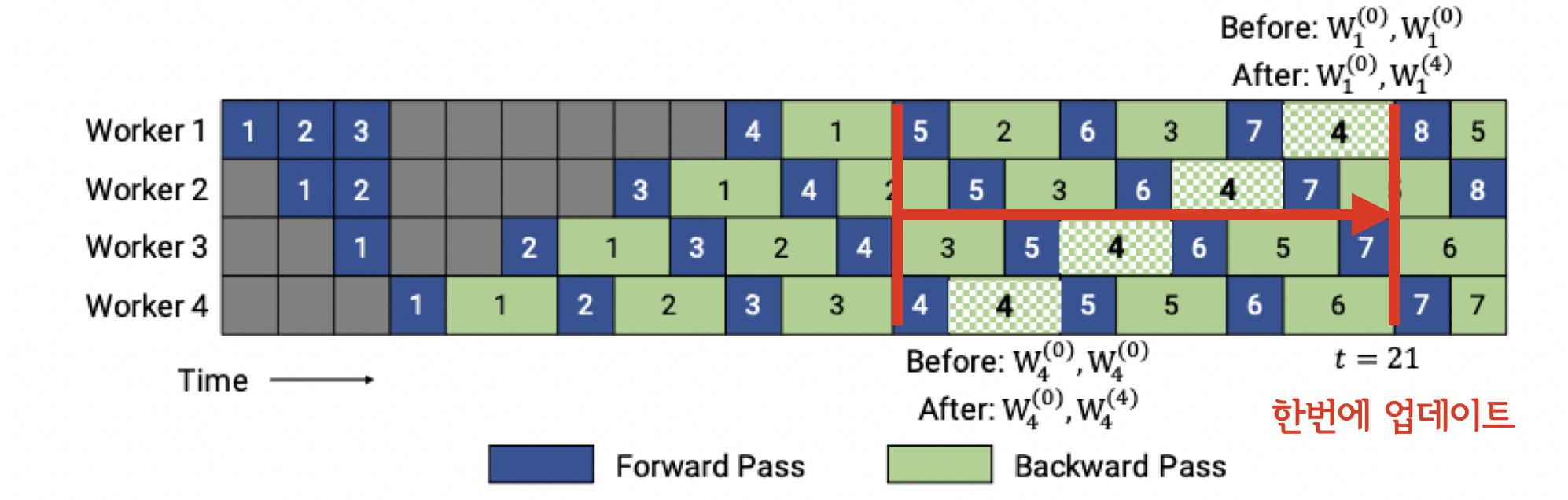
"PipeDream 2BW는 PipeDream의 메모리 비효율성을 개선하기 위해 등장했습니다. 핵심 아이디어는 파이프라이닝 중에 Gradient Accumulation을 수행하는 것입니다. 여러개의 Gradient들을 모아두다가 한번에 업데이트를 수행하는 방식으로 메모리 비효율성 문제를 해결했죠. 2BW는 이전과 달리 단 두개의 weight version만 유지하면 됩니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"### 2) PipeDream Flush\n",
"PipeDream Flush는 1F1B와 Pipeline Flush를 결합한 파이프라이닝 방법입니다. 이 파이프라이닝 방법은 Flush가 일어나기 때문에 GPIpe와 비교하여 idle time은 비슷하나, forward-backward 과정에서 유지해야 하는 **activation memory가 줄어듭니다.** PipeDream Flush는 Flush가 일어나기 때문에 여러버전의 파라미터를 관리할 필요가 없습니다. 따라서 단일 가중치만 유지하면 되기 때문에 PipeDream 2BW보다도 더 메모리 효율적입니다. (지금까지 소개드린 기법들 중 가장 메모리 효율적입니다.)\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### 잠깐... 근데 Activation Memory가 뭐야?\n",
"대부분의 Layer들은 Backward를 호출하기 전에 Forward에서 나온 출력값들을 저장하고 있습니다. 이는 `torch.autograd.Function`을 사용해보신 분들은 잘 아실텐데요. `ctx`변수에 forward 레이어의 출력값들을 저장해둡니다.\n"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"참고: https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html\n",
"\"\"\"\n",
"\n",
"import torch\n",
"\n",
"\n",
"class ReLU(torch.autograd.Function):\n",
"\n",
" @staticmethod\n",
" def forward(ctx, input):\n",
" ctx.save_for_backward(input)\n",
" # input 값을 저장하고 있음.\n",
" \n",
" return input.clamp(min=0)\n",
"\n",
" @staticmethod\n",
" def backward(ctx, grad_output):\n",
" input, = ctx.saved_tensors\n",
" grad_input = grad_output.clone()\n",
" grad_input[input < 0] = 0\n",
" return grad_input"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
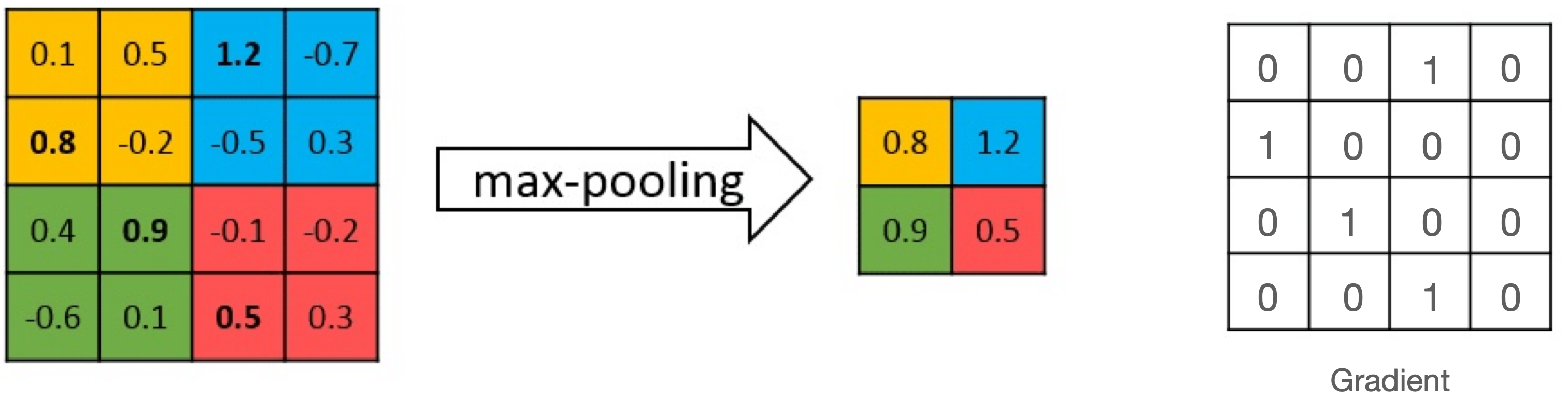
"이는 미분값(Gradient)을 계산할때 Forward 과정에서 사용했던 값들이 필요하기 때문입니다. 다음 예시를 봅시다.\n",
"\n",
"\n",
"\n",
"위는 Max Pooling 연산과 그에 대한 Gradient를 계산한 것입니다. Backward를 수행할때는 [[0.8, 1.2], [0.9, 0.5]]와 같은 (2, 2) 텐서가 입력으로 들어옵니다. 이 값을 가지고 오른쪽의 Gradient Matrix를 찾아내야 하는데 반드시 Forward에서 받았던 (4, 4)의 텐서가 필요합니다. 따라서 이 텐서를 메모리에 저장하고 있는 것이죠. 이렇게 Backward를 수행하기 위해 Forward 당시에 쓰였던 텐서들을 저장해두기 위해 필요한 메모리를 Activation Memory라고 합니다."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"이제 Activation Memory가 뭔지 알았으니, PipeDream을 실습해볼까요? **PipeDream Flush는 MS의 분산처리 라이브러리 DeepSpeed에 구현되어 있습니다.** (참고: https://github.com/microsoft/DeepSpeed/issues/1110) 따라서 DeepSpeed를 사용해봅시다.\n",
"\n",
"### DeepSpeed 명령어 사용법\n",
"아 참, 그 전에 `deepspeed`가 제공하는 매우 편리한 기능을 먼저 알아보고 가겠습니다. 기존에는 분산처리를 위해 `python -m torch.distributed.launch --nproc_per_node=n OOO.py`를 사용했으나 너무 길어서 불편했죠. DeepSpeed는 `deepspeed` 혹은 `ds`와 같은 명령어를 제공하고 있습니다. \n",
"\n",
"- `ds --num_gpus=n OOO.py`\n",
"- `deepspeed --num_gpus=n OOO.py`\n",
"\n",
"위와 같은 명령어를 입력하면 `torch.distributed.launch`와 동일하게 작동합니다. 이제부터는 모든 분산처리 프로그램에 `deepspeed`의 명령어를 사용하도록 하겠습니다. (솔직히 `torch.distributed.launch`는 너무 길어요 😭)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/pipe_dream.py\n",
"\"\"\"\n",
"import deepspeed\n",
"import torch\n",
"import torch.nn as nn\n",
"from datasets import load_dataset\n",
"from deepspeed import PipelineModule\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader\n",
"from tqdm import tqdm\n",
"from transformers import GPT2Tokenizer, GPT2LMHeadModel\n",
"from transformers.models.gpt2.modeling_gpt2 import GPT2Block as GPT2BlockBase\n",
"import torch.distributed as dist\n",
"\n",
"\n",
"class GPT2Preprocessing(nn.Module):\n",
" def __init__(self, config):\n",
" super().__init__()\n",
" self.embed_dim = config.hidden_size\n",
" self.wte = nn.Embedding(config.vocab_size, self.embed_dim)\n",
" self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)\n",
" self.drop = nn.Dropout(config.embd_pdrop)\n",
"\n",
" def forward(self, input_ids):\n",
" input_shape = input_ids.size()\n",
" input_ids = input_ids.view(-1, input_shape[-1])\n",
" position_ids = torch.arange(\n",
" 0, input_shape[-1], dtype=torch.long, device=input_ids.device\n",
" )\n",
" position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])\n",
" inputs_embeds = self.wte(input_ids)\n",
" position_embeds = self.wpe(position_ids)\n",
" hidden_states = inputs_embeds + position_embeds\n",
" hidden_states = self.drop(hidden_states)\n",
" return hidden_states\n",
"\n",
"\n",
"class GPT2Block(GPT2BlockBase):\n",
" def forward(self, hidden_states):\n",
" hidden_states = super(GPT2Block, self).forward(\n",
" hidden_states=hidden_states,\n",
" )\n",
" return hidden_states[0]\n",
"\n",
"\n",
"class GPT2Postprocessing(nn.Module):\n",
" def __init__(self, config):\n",
" super().__init__()\n",
" self.ln_f = nn.LayerNorm(\n",
" config.hidden_size,\n",
" eps=config.layer_norm_epsilon,\n",
" )\n",
" self.lm_head = nn.Linear(\n",
" config.hidden_size,\n",
" config.vocab_size,\n",
" bias=False,\n",
" )\n",
"\n",
" def forward(self, hidden_states):\n",
" hidden_states = self.ln_f(hidden_states)\n",
" lm_logits = self.lm_head(hidden_states)\n",
" return lm_logits\n",
"\n",
"\n",
"def create_model_from_pretrained(model_name):\n",
" pretrained = GPT2LMHeadModel.from_pretrained(model_name)\n",
" preprocess = GPT2Preprocessing(pretrained.config)\n",
" preprocess.wte.weight = pretrained.transformer.wte.weight\n",
" preprocess.wpe.weight = pretrained.transformer.wpe.weight\n",
"\n",
" blocks = pretrained.transformer.h\n",
" for i, block in enumerate(blocks):\n",
" block.__class__ = GPT2Block\n",
"\n",
" postprocess = GPT2Postprocessing(pretrained.config)\n",
" postprocess.ln_f.weight = pretrained.transformer.ln_f.weight\n",
" postprocess.ln_f.bias = pretrained.transformer.ln_f.bias\n",
" postprocess.lm_head.weight.data = pretrained.lm_head.weight.data.clone()\n",
"\n",
" return nn.Sequential(preprocess, *blocks, postprocess)\n",
"\n",
"\n",
"def collate_fn(batch):\n",
" batch_encoding = tokenizer.pad(\n",
" {\"input_ids\": batch}, padding=\"max_length\", max_length=1024\n",
" )\n",
" return batch_encoding.input_ids\n",
"\n",
"\n",
"def batch_fn(data):\n",
" input_ids = data\n",
" labels = data\n",
" return input_ids, labels\n",
"\n",
"\n",
"def loss_fn(logits, labels):\n",
" logits = logits[..., :-1, :].contiguous()\n",
" labels = labels[..., 1:].contiguous()\n",
"\n",
" return nn.CrossEntropyLoss()(\n",
" logits.view(-1, logits.size(-1)),\n",
" labels.view(-1),\n",
" )\n",
"\n",
"\n",
"if __name__ == \"__main__\":\n",
" dist.init_process_group(\"nccl\")\n",
" world_size, rank = dist.get_world_size(), dist.get_rank()\n",
" batch_size, train_steps = 16, 300\n",
" train_samples = batch_size * train_steps\n",
"\n",
" tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\n",
" tokenizer.pad_token = tokenizer.eos_token\n",
"\n",
" model = PipelineModule(\n",
" create_model_from_pretrained(model_name=\"gpt2\"),\n",
" loss_fn=loss_fn,\n",
" num_stages=world_size,\n",
" partition_method=\"type:GPT2Block\"\n",
" # partition_method를 통해 병렬화 하고 싶은 레이어를 고를 수 있습니다.\n",
" )\n",
" engine, optimizer, _, _ = deepspeed.initialize(\n",
" model=model,\n",
" optimizer=Adam(model.parameters(), lr=3e-5),\n",
" config={\n",
" \"train_batch_size\": batch_size,\n",
" \"steps_per_print\": 9999999,\n",
" # turn off: https://github.com/microsoft/DeepSpeed/issues/1119\n",
" },\n",
" )\n",
" engine.set_batch_fn(batch_fn)\n",
"\n",
" datasets = load_dataset(\"squad\").data[\"train\"][\"context\"]\n",
" datasets = [str(sample) for i, sample in enumerate(datasets) if i < train_samples]\n",
" datasets = [\n",
" tokenizer(data, return_tensors=\"pt\", max_length=1024).input_ids[0]\n",
" for data in tqdm(datasets)\n",
" ]\n",
" data_loader = iter(\n",
" DataLoader(\n",
" sorted(datasets, key=len, reverse=True),\n",
" # uniform length batching\n",
" # https://mccormickml.com/2020/07/29/smart-batching-tutorial/\n",
" batch_size=batch_size,\n",
" num_workers=8,\n",
" collate_fn=collate_fn,\n",
" shuffle=False,\n",
" )\n",
" )\n",
"\n",
" for i in range(train_steps):\n",
" loss = engine.train_batch(data_loader)\n",
"\n",
" if i % 10 == 0 and rank == 0:\n",
" print(f\"step: {i}, loss: {loss}\")\n"
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2021-10-21 23:11:01,063] [WARNING] [runner.py:122:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.\n",
"[2021-10-21 23:11:01,184] [INFO] [runner.py:360:main] cmd = /home/ubuntu/kevin/kevin_env/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ../src/pipe_dream.py\n",
"[2021-10-21 23:11:02,065] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}\n",
"[2021-10-21 23:11:02,065] [INFO] [launch.py:86:main] nnodes=1, num_local_procs=4, node_rank=0\n",
"[2021-10-21 23:11:02,065] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(, {'localhost': [0, 1, 2, 3]})\n",
"[2021-10-21 23:11:02,065] [INFO] [launch.py:102:main] dist_world_size=4\n",
"[2021-10-21 23:11:02,065] [INFO] [launch.py:104:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\n",
"SEED_LAYERS=False BASE_SEED=1234 SEED_FN=None\n",
"Using topology: {ProcessCoord(pipe=0, data=0): 0, ProcessCoord(pipe=1, data=0): 1, ProcessCoord(pipe=2, data=0): 2, ProcessCoord(pipe=3, data=0): 3}\n",
"[2021-10-21 23:11:24,460] [INFO] [module.py:365:_partition_layers] Partitioning pipeline stages with method type:GPT2Block\n",
"stage=0 layers=4\n",
" 0: GPT2Preprocessing\n",
" 1: GPT2Block\n",
" 2: GPT2Block\n",
" 3: GPT2Block\n",
"stage=1 layers=3\n",
" 4: GPT2Block\n",
" 5: GPT2Block\n",
" 6: GPT2Block\n",
"stage=2 layers=3\n",
" 7: GPT2Block\n",
" 8: GPT2Block\n",
" 9: GPT2Block\n",
"stage=3 layers=4\n",
" 10: GPT2Block\n",
" 11: GPT2Block\n",
" 12: GPT2Block\n",
" 13: GPT2Postprocessing\n",
" loss: loss_fn\n",
"[2021-10-21 23:14:05,483] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed info: version=0.5.4+c6d1418, git-hash=c6d1418, git-branch=master\n",
"[2021-10-21 23:14:05,869] [INFO] [engine.py:204:__init__] DeepSpeed Flops Profiler Enabled: False\n",
"[2021-10-21 23:14:05,869] [INFO] [engine.py:848:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer\n",
"[2021-10-21 23:14:05,869] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer\n",
"[2021-10-21 23:14:05,892] [INFO] [engine.py:870:_configure_optimizer] DeepSpeed Basic Optimizer = Adam\n",
"[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam\n",
"[2021-10-21 23:14:05,892] [INFO] [engine.py:596:_configure_lr_scheduler] DeepSpeed using client LR scheduler\n",
"[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = None\n",
"[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]\n",
"[2021-10-21 23:14:05,892] [INFO] [config.py:940:print] DeepSpeedEngine configuration:\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] activation_checkpointing_config {\n",
" \"partition_activations\": false, \n",
" \"contiguous_memory_optimization\": false, \n",
" \"cpu_checkpointing\": false, \n",
" \"number_checkpoints\": null, \n",
" \"synchronize_checkpoint_boundary\": false, \n",
" \"profile\": false\n",
"}\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] amp_enabled .................. False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] amp_params ................... False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] curriculum_enabled ........... False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] curriculum_params ............ False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] dataloader_drop_last ......... False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] disable_allgather ............ False\n",
"[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] dump_state ................... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... None\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_enabled ........... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_verbose ........... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] elasticity_enabled ........... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] flops_profiler_config ........ {\n",
" \"enabled\": false, \n",
" \"profile_step\": 1, \n",
" \"module_depth\": -1, \n",
" \"top_modules\": 1, \n",
" \"detailed\": true, \n",
" \"output_file\": null\n",
"}\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_enabled ................. False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] global_rank .................. 0\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_clipping ............ 0.0\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] loss_scale ................... 0\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] memory_breakdown ............. False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_name ............... None\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_params ............. None\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pld_enabled .................. False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pld_params ................... False\n",
"[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] prescale_gradients ........... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_groups .............. 1\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_offset .............. 1000\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_period .............. 1000\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_rounding ............ 0\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_start_bits .......... 16\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_target_bits ......... 8\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_training_enabled .... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_type ................ 0\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_verbose ............. False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] scheduler_name ............... None\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] scheduler_params ............. None\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] sparse_attention ............. None\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] steps_per_print .............. 9999999\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_enabled .......... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_output_path ...... \n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] train_batch_size ............. 16\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 16\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] use_quantizer_kernel ......... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] wall_clock_breakdown ......... False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] world_size ................... 1\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_allow_untested_optimizer False\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_config .................. {\n",
" \"stage\": 0, \n",
" \"contiguous_gradients\": true, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": false, \n",
" \"load_from_fp32_weights\": true, \n",
" \"elastic_checkpoint\": true, \n",
" \"offload_param\": null, \n",
" \"offload_optimizer\": null, \n",
" \"sub_group_size\": 1.000000e+09, \n",
" \"prefetch_bucket_size\": 5.000000e+07, \n",
" \"param_persistence_threshold\": 1.000000e+05, \n",
" \"max_live_parameters\": 1.000000e+09, \n",
" \"max_reuse_distance\": 1.000000e+09, \n",
" \"gather_fp16_weights_on_model_save\": false, \n",
" \"ignore_unused_parameters\": true, \n",
" \"round_robin_gradients\": false, \n",
" \"legacy_stage1\": false\n",
"}\n",
"[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_enabled ................. False\n",
"[2021-10-21 23:14:05,896] [INFO] [config.py:944:print] zero_optimization_stage ...... 0\n",
"[2021-10-21 23:14:05,896] [INFO] [config.py:946:print] json = {\n",
" \"train_batch_size\": 16, \n",
" \"steps_per_print\": 9.999999e+06\n",
"}\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...\n",
"Building extension module utils...\n",
"Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"ninja: no work to do.\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.6987707614898682 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.30276012420654297 seconds\n",
"[2021-10-21 23:14:06,793] [INFO] [engine.py:77:__init__] CONFIG: micro_batches=1 micro_batch_size=16\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.3035085201263428 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.10213756561279297 seconds\n",
"[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=0 STAGE=0 LAYERS=4 [0, 4) STAGE_PARAMS=60647424 (60.647M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)\n",
"[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=1 STAGE=1 LAYERS=3 [4, 7) STAGE_PARAMS=21263616 (21.264M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)\n",
"[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=3 STAGE=3 LAYERS=4 [10, 14) STAGE_PARAMS=59862528 (59.863M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)\n",
"[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=2 STAGE=2 LAYERS=3 [7, 10) STAGE_PARAMS=21263616 (21.264M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)\n",
"WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 256.29it/s]\n",
"WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 472.65it/s]\n",
" 0%| | 0/4800 [00:00
\n",
"\n",
"## 5. Interleaved Scheduling\n",
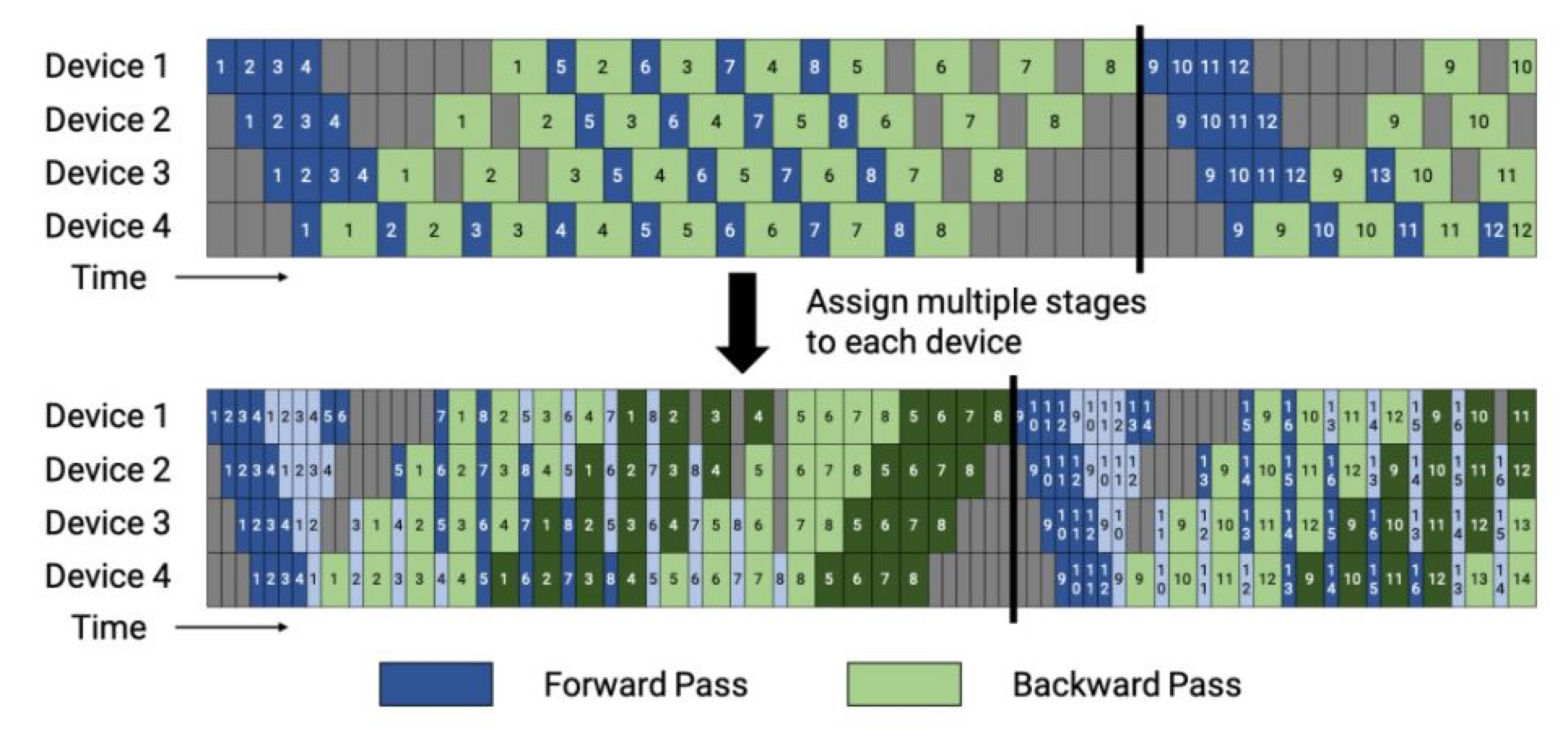
"이전에는 하나의 스테이지(연속된 레이어 집합)를 순차적으로 계산해서 결과 값을 출력했습니다. 예를 들면 8개의 레이어가 있고 2개의 디바이스가 주어졌다고 가정한다면, 일반적으로 1번 device에 1-4번 레이어, 2번 device에 5-8번 레이어에 할당되겠죠. 그러면 1번 device는 1~4번 레이어를 순차적으로 진행하여 출력했습니다. (GPipe, 1F1B 모두 이렇게 동작함)\n",
" \n",
"\n",
"\n",
"그러나 **Interleaved Scheduling은 Bubble time을 극도로 줄이기 위해 하나의 스테이지를 중첩해서 진행**합니다. 예를 들면 1번 device가 1-4번 레이어에 할당 되었다면, 1-2번 레이어의 동시에 3-4번 레이어를 동시에 수행합니다. 이렇게 되면 Bubble time은 줄어들지만 통신비용이 커지기 때문에 잘 조절할 필요가 있습니다. (트레이드 오프 존재)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 4
}