{
"cells": [
{
"cell_type": "markdown",
"id": "b22066fd",
"metadata": {},
"source": [
"# Zero Redundancy Optimization (ZeRO)\n",
"\n",
"이번 세션에는 Microsoft의 뉴럴넷 학습 최적화 솔루션인 ZeRO에 대해서 알아보도록 하겠습니다."
]
},
{
"cell_type": "markdown",
"id": "7bea8763",
"metadata": {},
"source": [
"## 1. Mixed Precision\n",
"\n",
"최신 GPU들이 Lower precision에 대한 계산을 지원하면서 현대의 뉴럴넷 학습은 대부분 FP16(half)과 FP32(single)을 함께 사용하는 Mixed precision 방식을 사용합니다. V100 기준으로 FP32에서 속도가 14TFLOPS 정도라면, FP16에서는 100TFLOPS의 속도로 모델을 학습할 수 있습니다. 또한 FP16을 사용하면 모델의 사이즈가 줄기 때문에 학습 뿐만 아니라 배포시에도 장점이 있죠.\n",
"\n",
""
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"fp16_model = Net().half().to(\"cuda\")\n",
"fp16_model.load_state_dict(fp32_model.state_dict())"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "b9da7079",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'GPU = 1.5029296875 GiB'"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"f\"GPU = {torch.cuda.memory_allocated(0) / (1024 ** 2)} GiB\""
]
},
{
"cell_type": "markdown",
"id": "310dbf91",
"metadata": {},
"source": [
"\n",
"\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from IPython.display import HTML\n",
"\n",
"HTML(\"\"\"\n",
"\n",
"\n",
" \n",
"
\"\"\")\n"
]
},
{
"cell_type": "markdown",
"id": "2021a227",
"metadata": {},
"source": [
"\n",
"\n",
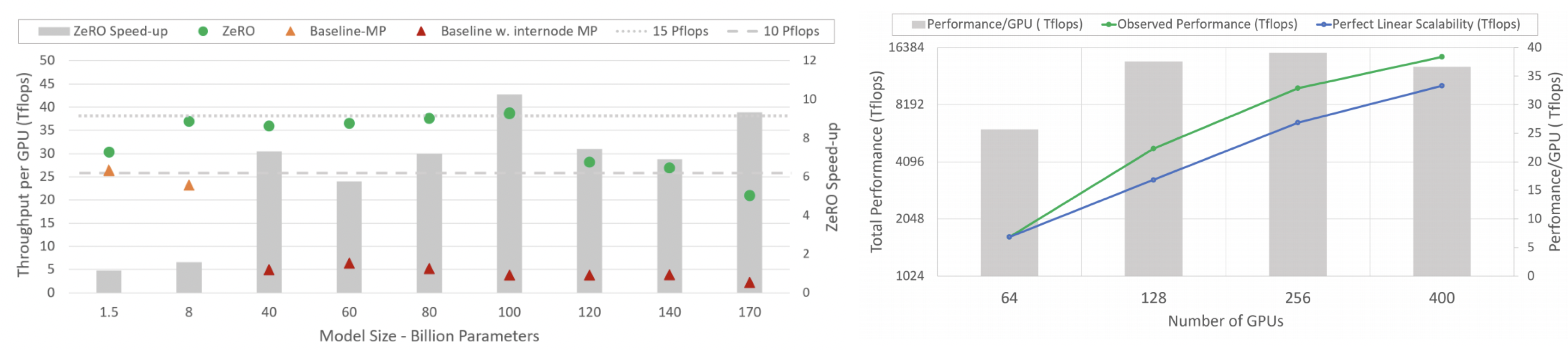
"결론적으로 ZeRO-DP를 적용하면 기존보다 훨씬 큰 모델을 작은 GPU에서 학습시킬 수 있습니다. 바로 실습해봅시다. 먼저 configuration 파일을 만듭니다. 저는 learning rate scheduler, fp16, zero optimization (stage 1) 등을 활성화 시켰습니다. 이외에도 deepspeed configuration에는 매우 다양한 옵션들이 있습니다. 더 많은 옵션들은 https://www.deepspeed.ai/docs/config-json 여기에서 확인하세요."
]
},
{
"cell_type": "markdown",
"id": "df7a1054",
"metadata": {},
"source": [
"```\n",
"{\n",
" \"train_batch_size\": 16,\n",
" \"gradient_accumulation_steps\": 1,\n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\",\n",
" \"params\": {\n",
" \"total_num_steps\": 300,\n",
" \"warmup_min_lr\": 0,\n",
" \"warmup_max_lr\": 3e-5,\n",
" \"warmup_num_steps\": 30\n",
" }\n",
" },\n",
" \"fp16\": {\n",
" \"enabled\": true,\n",
" \"initial_scale_power\": 32,\n",
" \"loss_scale_window\": 1000,\n",
" \"hysteresis\": 2,\n",
" \"min_loss_scale\": 1\n",
" },\n",
" \"zero_optimization\": {\n",
" \"stage\": 1\n",
" },\n",
" \"zero_allow_untested_optimizer\": true,\n",
" \"wall_clock_breakdown\": false,\n",
" \"steps_per_print\": 9999999999\n",
"}\n",
"\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "dc7c1512",
"metadata": {},
"source": [
"그리고 다음과 같은 코드를 작성합니다. argument parser의 옵션으로 `--local_rank`와 `--deepspeed_config`가 반드시 필요하며, 이 중 `--local_rank`는 스크립트 실행시에 자동으로 입력됩니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "fc6b403a",
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/zero_dp_args.py\n",
"\"\"\"\n",
"from argparse import ArgumentParser\n",
"from datasets import load_dataset\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader\n",
"from transformers import GPT2LMHeadModel, GPT2Tokenizer\n",
"import deepspeed\n",
"import torch.distributed as dist\n",
"\n",
"model = GPT2LMHeadModel.from_pretrained(\"gpt2\")\n",
"tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\n",
"tokenizer.pad_token = tokenizer.eos_token\n",
"\n",
"parser = ArgumentParser()\n",
"parser.add_argument(\n",
" \"--deepspeed_config\", default=\"../src/zero_dp_config.json\", type=str\n",
")\n",
"parser.add_argument(\"--local_rank\", default=0, type=int)\n",
"args = parser.parse_args()\n",
"\n",
"optimizer = Adam(model.parameters(), lr=3e-5, weight_decay=3e-7)\n",
"\n",
"engine, optimizer, _, scheduler = deepspeed.initialize(\n",
" args=args,\n",
" model=model,\n",
" optimizer=optimizer,\n",
")\n",
"\n",
"datasets = load_dataset(\"squad\").data[\"train\"][\"context\"]\n",
"datasets = [str(sample) for sample in datasets]\n",
"data_loader = DataLoader(datasets, batch_size=8, num_workers=8)\n",
"\n",
"for i, data in enumerate(data_loader):\n",
" tokens = tokenizer(\n",
" data,\n",
" return_tensors=\"pt\",\n",
" truncation=True,\n",
" padding=True,\n",
" max_length=1024,\n",
" )\n",
"\n",
" loss = engine(\n",
" input_ids=tokens.input_ids.cuda(),\n",
" attention_mask=tokens.attention_mask.cuda(),\n",
" labels=tokens.input_ids.cuda(),\n",
" ).loss\n",
"\n",
" engine.backward(loss)\n",
" engine.step()\n",
"\n",
" if i % 10 == 0 and dist.get_rank() == 0:\n",
" print(f\"step:{i}, loss:{loss}\")\n",
"\n",
" if i >= 300:\n",
" break\n"
]
},
{
"cell_type": "code",
"execution_count": 24,
"id": "9761d852",
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2021-10-27 22:23:20,777] [WARNING] [runner.py:122:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.\n",
"[2021-10-27 22:23:20,955] [INFO] [runner.py:360:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ../src/zero_args.py --deepspeed_config=../src/zero_dp_config.json\n",
"[2021-10-27 22:23:22,061] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}\n",
"[2021-10-27 22:23:22,061] [INFO] [launch.py:89:main] nnodes=1, num_local_procs=4, node_rank=0\n",
"[2021-10-27 22:23:22,062] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(, {'localhost': [0, 1, 2, 3]})\n",
"[2021-10-27 22:23:22,062] [INFO] [launch.py:102:main] dist_world_size=4\n",
"[2021-10-27 22:23:22,062] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\n",
"[2021-10-27 22:23:27,188] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:23:27,191] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:23:27,255] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:23:27,259] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:23:27,266] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:23:27,270] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:23:27,273] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:23:27,276] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:23:32,824] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed groups\n",
"[2021-10-27 22:23:32,824] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed model parallel group with size 1\n",
"[2021-10-27 22:23:32,903] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed expert parallel group with size 1\n",
"[2021-10-27 22:23:32,903] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert data parallel process group with ranks: [0, 1, 2, 3]\n",
"[2021-10-27 22:23:32,903] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [0]\n",
"[2021-10-27 22:23:32,903] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [1]\n",
"[2021-10-27 22:23:32,904] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [2]\n",
"[2021-10-27 22:23:32,904] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [3]\n",
"[2021-10-27 22:23:33,170] [INFO] [engine.py:205:__init__] DeepSpeed Flops Profiler Enabled: False\n",
"[2021-10-27 22:23:33,170] [INFO] [engine.py:849:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer\n",
"[2021-10-27 22:23:33,171] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer\n",
"[2021-10-27 22:23:33,175] [INFO] [engine.py:871:_configure_optimizer] DeepSpeed Basic Optimizer = Adam\n",
"[2021-10-27 22:23:33,175] [INFO] [utils.py:44:is_zero_supported_optimizer] Checking ZeRO support for optimizer=Adam type=\n",
"[2021-10-27 22:23:33,176] [INFO] [logging.py:68:log_dist] [Rank 0] Creating fp16 ZeRO stage 1 optimizer\n",
"[2021-10-27 22:23:33,176] [INFO] [stage2.py:111:__init__] Reduce bucket size 500000000\n",
"[2021-10-27 22:23:33,176] [INFO] [stage2.py:112:__init__] Allgather bucket size 500000000\n",
"[2021-10-27 22:23:33,176] [INFO] [stage2.py:113:__init__] CPU Offload: False\n",
"[2021-10-27 22:23:33,176] [INFO] [stage2.py:114:__init__] Round robin gradient partitioning: False\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...\n",
"Building extension module utils...\n",
"Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\n",
"ninja: no work to do.\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.3419780731201172 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.402141809463501 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021260738372803 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021601676940918 seconds\n",
"Rank: 0 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 2 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 3 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 1 partition count [4] and sizes[(31109952, False)] \n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.000469207763671875 seconds\n",
"Time to load utils op: 0.0004677772521972656 seconds\n",
"Time to load utils op: 0.0004513263702392578 seconds\n",
"[2021-10-27 22:23:34,521] [INFO] [utils.py:806:see_memory_usage] Before initializing optimizer states\n",
"[2021-10-27 22:23:34,522] [INFO] [utils.py:811:see_memory_usage] MA 0.36 GB Max_MA 0.42 GB CA 0.61 GB Max_CA 1 GB \n",
"[2021-10-27 22:23:34,522] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:23:34,563] [INFO] [utils.py:806:see_memory_usage] After initializing optimizer states\n",
"[2021-10-27 22:23:34,564] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 1.06 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:23:34,564] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:23:34,565] [INFO] [stage2.py:474:__init__] optimizer state initialized\n",
"[2021-10-27 22:23:34,601] [INFO] [utils.py:806:see_memory_usage] After initializing ZeRO optimizer\n",
"[2021-10-27 22:23:34,602] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 0.59 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:23:34,602] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:23:34,602] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam\n",
"[2021-10-27 22:23:34,602] [INFO] [engine.py:587:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupDecayLR\n",
"[2021-10-27 22:23:34,602] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = \n",
"[2021-10-27 22:23:34,602] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]\n",
"[2021-10-27 22:23:34,602] [INFO] [config.py:940:print] DeepSpeedEngine configuration:\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] activation_checkpointing_config {\n",
" \"partition_activations\": false, \n",
" \"contiguous_memory_optimization\": false, \n",
" \"cpu_checkpointing\": false, \n",
" \"number_checkpoints\": null, \n",
" \"synchronize_checkpoint_boundary\": false, \n",
" \"profile\": false\n",
"}\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] amp_enabled .................. False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] amp_params ................... False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] curriculum_enabled ........... False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] curriculum_params ............ False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] dataloader_drop_last ......... False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] disable_allgather ............ False\n",
"[2021-10-27 22:23:34,604] [INFO] [config.py:944:print] dump_state ................... False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_enabled ........... False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] eigenvalue_verbose ........... False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] elasticity_enabled ........... False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] flops_profiler_config ........ {\n",
" \"enabled\": false, \n",
" \"profile_step\": 1, \n",
" \"module_depth\": -1, \n",
" \"top_modules\": 1, \n",
" \"detailed\": true, \n",
" \"output_file\": null\n",
"}\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] fp16_enabled ................. True\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] global_rank .................. 0\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1\n",
"[2021-10-27 22:23:34,605] [INFO] [config.py:944:print] gradient_clipping ............ 0.0\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] loss_scale ................... 0\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] memory_breakdown ............. False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] optimizer_name ............... None\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] optimizer_params ............. None\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] pld_enabled .................. False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] pld_params ................... False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] prescale_gradients ........... False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_groups .............. 1\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_offset .............. 1000\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_period .............. 1000\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_rounding ............ 0\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_start_bits .......... 16\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_target_bits ......... 8\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_training_enabled .... False\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_type ................ 0\n",
"[2021-10-27 22:23:34,606] [INFO] [config.py:944:print] quantize_verbose ............. False\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] scheduler_name ............... WarmupDecayLR\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] scheduler_params ............. {'total_num_steps': 300, 'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 30}\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] sparse_attention ............. None\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] steps_per_print .............. 9999999999\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] tensorboard_enabled .......... False\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] tensorboard_output_path ...... \n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] train_batch_size ............. 16\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 4\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] use_quantizer_kernel ......... False\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] wall_clock_breakdown ......... False\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] world_size ................... 4\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] zero_allow_untested_optimizer True\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] zero_config .................. {\n",
" \"stage\": 1, \n",
" \"contiguous_gradients\": true, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": false, \n",
" \"load_from_fp32_weights\": true, \n",
" \"elastic_checkpoint\": true, \n",
" \"offload_param\": null, \n",
" \"offload_optimizer\": null, \n",
" \"sub_group_size\": 1.000000e+09, \n",
" \"prefetch_bucket_size\": 5.000000e+07, \n",
" \"param_persistence_threshold\": 1.000000e+05, \n",
" \"max_live_parameters\": 1.000000e+09, \n",
" \"max_reuse_distance\": 1.000000e+09, \n",
" \"gather_fp16_weights_on_model_save\": false, \n",
" \"ignore_unused_parameters\": true, \n",
" \"round_robin_gradients\": false, \n",
" \"legacy_stage1\": false\n",
"}\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] zero_enabled ................. True\n",
"[2021-10-27 22:23:34,607] [INFO] [config.py:944:print] zero_optimization_stage ...... 1\n",
"[2021-10-27 22:23:34,608] [INFO] [config.py:952:print] json = {\n",
" \"train_batch_size\": 16, \n",
" \"gradient_accumulation_steps\": 1, \n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\", \n",
" \"params\": {\n",
" \"total_num_steps\": 300, \n",
" \"warmup_min_lr\": 0, \n",
" \"warmup_max_lr\": 3e-05, \n",
" \"warmup_num_steps\": 30\n",
" }\n",
" }, \n",
" \"fp16\": {\n",
" \"enabled\": true, \n",
" \"initial_scale_power\": 32, \n",
" \"loss_scale_window\": 1000, \n",
" \"hysteresis\": 2, \n",
" \"min_loss_scale\": 1\n",
" }, \n",
" \"zero_optimization\": {\n",
" \"stage\": 1, \n",
" \"allgather_partitions\": true, \n",
" \"overlap_comm\": false, \n",
" \"reduce_scatter\": true\n",
" }, \n",
" \"zero_allow_untested_optimizer\": true, \n",
" \"wall_clock_breakdown\": false, \n",
" \"steps_per_print\": 1.000000e+10\n",
"}\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.000453948974609375 seconds\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 545.35it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 618.17it/s]\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 576.02it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 578.09it/s]\n",
"step:0, loss:5.453125\n",
"step:10, loss:3.6484375\n",
"step:20, loss:3.546875\n",
"step:30, loss:3.76953125\n",
"step:40, loss:2.880859375\n",
"step:50, loss:2.408203125\n",
"step:60, loss:2.5234375\n",
"step:70, loss:2.265625\n",
"step:80, loss:2.505859375\n",
"step:90, loss:2.939453125\n",
"step:100, loss:2.791015625\n",
"step:110, loss:2.48828125\n",
"step:120, loss:2.95703125\n",
"step:130, loss:2.361328125\n",
"step:140, loss:2.92578125\n",
"step:150, loss:3.8515625\n",
"step:160, loss:3.044921875\n",
"step:170, loss:3.052734375\n",
"step:180, loss:1.65625\n",
"step:190, loss:3.509765625\n",
"step:200, loss:3.716796875\n",
"step:210, loss:3.560546875\n",
"step:220, loss:2.98046875\n",
"step:230, loss:3.251953125\n",
"step:240, loss:2.564453125\n",
"step:250, loss:3.19921875\n",
"step:260, loss:3.564453125\n",
"step:270, loss:3.23828125\n",
"step:280, loss:2.615234375\n",
"step:290, loss:2.23046875\n",
"step:300, loss:3.48828125\n"
]
}
],
"source": [
"!deepspeed --num_gpus=4 ../src/zero_args.py --deepspeed_config=../src/zero_dp_config.json"
]
},
{
"cell_type": "markdown",
"id": "6dd4b739",
"metadata": {},
"source": [
"혹은 configuration을 `deepspeed.initialize()`에 직접 넣을 수도 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7fb4f4e5",
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/zero_dp_args.py\n",
"\"\"\"\n",
"from datasets import load_dataset\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader\n",
"from transformers import GPT2LMHeadModel, GPT2Tokenizer\n",
"import deepspeed\n",
"import torch.distributed as dist\n",
"\n",
"model = GPT2LMHeadModel.from_pretrained(\"gpt2\")\n",
"tokenizer = GPT2Tokenizer.from_pretrained(\"gpt2\")\n",
"tokenizer.pad_token = tokenizer.eos_token\n",
"optimizer = Adam(model.parameters(), lr=3e-5, weight_decay=3e-7)\n",
"\n",
"engine, optimizer, _, scheduler = deepspeed.initialize(\n",
" optimizer=optimizer,\n",
" model=model,\n",
" config={\n",
" \"train_batch_size\": 16,\n",
" \"gradient_accumulation_steps\": 1,\n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\",\n",
" \"params\": {\n",
" \"total_num_steps\": 300,\n",
" \"warmup_min_lr\": 0,\n",
" \"warmup_max_lr\": 3e-5,\n",
" \"warmup_num_steps\": 30,\n",
" },\n",
" },\n",
" \"fp16\": {\n",
" \"enabled\": True,\n",
" \"initial_scale_power\": 32,\n",
" \"loss_scale_window\": 1000,\n",
" \"hysteresis\": 2,\n",
" \"min_loss_scale\": 1,\n",
" },\n",
" \"zero_optimization\": {\n",
" \"stage\": 1,\n",
" \"allgather_partitions\": True,\n",
" \"allgather_bucket_size\": 5e8,\n",
" \"overlap_comm\": False,\n",
" \"reduce_scatter\": True,\n",
" \"reduce_bucket_size\": 5e8,\n",
" \"contiguous_gradients\": True,\n",
" },\n",
" \"zero_allow_untested_optimizer\": True,\n",
" \"wall_clock_breakdown\": False,\n",
" \"steps_per_print\": 9999999999,\n",
" },\n",
")\n",
"\n",
"datasets = load_dataset(\"squad\").data[\"train\"][\"context\"]\n",
"datasets = [str(sample) for sample in datasets]\n",
"data_loader = DataLoader(datasets, batch_size=8, num_workers=8)\n",
"\n",
"for i, data in enumerate(data_loader):\n",
" tokens = tokenizer(\n",
" data,\n",
" return_tensors=\"pt\",\n",
" truncation=True,\n",
" padding=True,\n",
" max_length=1024,\n",
" )\n",
"\n",
" loss = engine(\n",
" input_ids=tokens.input_ids.cuda(),\n",
" attention_mask=tokens.attention_mask.cuda(),\n",
" labels=tokens.input_ids.cuda(),\n",
" ).loss\n",
"\n",
" engine.backward(loss)\n",
" engine.step()\n",
"\n",
" if i % 10 == 0 and dist.get_rank() == 0:\n",
" print(f\"step:{i}, loss:{loss}\")\n",
"\n",
" if i >= 300:\n",
" break\n"
]
},
{
"cell_type": "code",
"execution_count": 20,
"id": "fc75c22f",
"metadata": {
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2021-10-27 22:17:23,924] [WARNING] [runner.py:122:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.\n",
"[2021-10-27 22:17:24,099] [INFO] [runner.py:360:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ../src/zero_dp_config.py\n",
"[2021-10-27 22:17:25,207] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}\n",
"[2021-10-27 22:17:25,208] [INFO] [launch.py:89:main] nnodes=1, num_local_procs=4, node_rank=0\n",
"[2021-10-27 22:17:25,208] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(, {'localhost': [0, 1, 2, 3]})\n",
"[2021-10-27 22:17:25,208] [INFO] [launch.py:102:main] dist_world_size=4\n",
"[2021-10-27 22:17:25,208] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\n",
"[2021-10-27 22:17:30,319] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:17:30,322] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:17:30,413] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:17:30,416] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:17:30,439] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:17:30,442] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:17:30,454] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:17:30,457] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:17:36,269] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed groups\n",
"[2021-10-27 22:17:36,270] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed model parallel group with size 1\n",
"[2021-10-27 22:17:36,294] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed expert parallel group with size 1\n",
"[2021-10-27 22:17:36,295] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert data parallel process group with ranks: [0, 1, 2, 3]\n",
"[2021-10-27 22:17:36,295] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [0]\n",
"[2021-10-27 22:17:36,295] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [1]\n",
"[2021-10-27 22:17:36,296] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [2]\n",
"[2021-10-27 22:17:36,296] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [3]\n",
"[2021-10-27 22:17:36,559] [INFO] [engine.py:205:__init__] DeepSpeed Flops Profiler Enabled: False\n",
"[2021-10-27 22:17:36,560] [INFO] [engine.py:849:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer\n",
"[2021-10-27 22:17:36,560] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer\n",
"[2021-10-27 22:17:36,564] [INFO] [engine.py:871:_configure_optimizer] DeepSpeed Basic Optimizer = Adam\n",
"[2021-10-27 22:17:36,565] [INFO] [utils.py:44:is_zero_supported_optimizer] Checking ZeRO support for optimizer=Adam type=\n",
"[2021-10-27 22:17:36,565] [INFO] [logging.py:68:log_dist] [Rank 0] Creating fp16 ZeRO stage 1 optimizer\n",
"[2021-10-27 22:17:36,565] [INFO] [stage2.py:111:__init__] Reduce bucket size 500000000.0\n",
"[2021-10-27 22:17:36,565] [INFO] [stage2.py:112:__init__] Allgather bucket size 500000000.0\n",
"[2021-10-27 22:17:36,565] [INFO] [stage2.py:113:__init__] CPU Offload: False\n",
"[2021-10-27 22:17:36,565] [INFO] [stage2.py:114:__init__] Round robin gradient partitioning: False\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...\n",
"Building extension module utils...\n",
"Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\n",
"ninja: no work to do.\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.3468191623687744 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.40213942527770996 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.40210413932800293 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021165370941162 seconds\n",
"Rank: 0 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 2 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 3 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 1 partition count [4] and sizes[(31109952, False)] \n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.00046753883361816406 seconds\n",
"Time to load utils op: 0.0004527568817138672 seconds\n",
"Time to load utils op: 0.00045871734619140625 seconds\n",
"[2021-10-27 22:17:37,930] [INFO] [utils.py:806:see_memory_usage] Before initializing optimizer states\n",
"[2021-10-27 22:17:37,931] [INFO] [utils.py:811:see_memory_usage] MA 0.36 GB Max_MA 0.42 GB CA 0.61 GB Max_CA 1 GB \n",
"[2021-10-27 22:17:37,931] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 15.74 GB, percent = 6.6%\n",
"[2021-10-27 22:17:37,971] [INFO] [utils.py:806:see_memory_usage] After initializing optimizer states\n",
"[2021-10-27 22:17:37,971] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 1.06 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:17:37,972] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 15.74 GB, percent = 6.6%\n",
"[2021-10-27 22:17:37,972] [INFO] [stage2.py:474:__init__] optimizer state initialized\n",
"[2021-10-27 22:17:38,009] [INFO] [utils.py:806:see_memory_usage] After initializing ZeRO optimizer\n",
"[2021-10-27 22:17:38,010] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 0.59 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:17:38,010] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 15.74 GB, percent = 6.6%\n",
"[2021-10-27 22:17:38,010] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam\n",
"[2021-10-27 22:17:38,010] [INFO] [engine.py:587:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupDecayLR\n",
"[2021-10-27 22:17:38,010] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = \n",
"[2021-10-27 22:17:38,010] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]\n",
"[2021-10-27 22:17:38,011] [INFO] [config.py:940:print] DeepSpeedEngine configuration:\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] activation_checkpointing_config {\n",
" \"partition_activations\": false, \n",
" \"contiguous_memory_optimization\": false, \n",
" \"cpu_checkpointing\": false, \n",
" \"number_checkpoints\": null, \n",
" \"synchronize_checkpoint_boundary\": false, \n",
" \"profile\": false\n",
"}\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] amp_enabled .................. False\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] amp_params ................... False\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False\n",
"[2021-10-27 22:17:38,012] [INFO] [config.py:944:print] curriculum_enabled ........... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] curriculum_params ............ False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] dataloader_drop_last ......... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] disable_allgather ............ False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] dump_state ................... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_enabled ........... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] eigenvalue_verbose ........... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] elasticity_enabled ........... False\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] flops_profiler_config ........ {\n",
" \"enabled\": false, \n",
" \"profile_step\": 1, \n",
" \"module_depth\": -1, \n",
" \"top_modules\": 1, \n",
" \"detailed\": true, \n",
" \"output_file\": null\n",
"}\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] fp16_enabled ................. True\n",
"[2021-10-27 22:17:38,013] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] global_rank .................. 0\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] gradient_clipping ............ 0.0\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] loss_scale ................... 0\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] memory_breakdown ............. False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] optimizer_name ............... None\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] optimizer_params ............. None\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] pld_enabled .................. False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] pld_params ................... False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] prescale_gradients ........... False\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] quantize_groups .............. 1\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] quantize_offset .............. 1000\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] quantize_period .............. 1000\n",
"[2021-10-27 22:17:38,014] [INFO] [config.py:944:print] quantize_rounding ............ 0\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] quantize_start_bits .......... 16\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] quantize_target_bits ......... 8\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] quantize_training_enabled .... False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] quantize_type ................ 0\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] quantize_verbose ............. False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] scheduler_name ............... WarmupDecayLR\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] scheduler_params ............. {'total_num_steps': 300, 'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 30}\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] sparse_attention ............. None\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] steps_per_print .............. 9999999999\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] tensorboard_enabled .......... False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] tensorboard_output_path ...... \n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] train_batch_size ............. 16\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 4\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] use_quantizer_kernel ......... False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] wall_clock_breakdown ......... False\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] world_size ................... 4\n",
"[2021-10-27 22:17:38,015] [INFO] [config.py:944:print] zero_allow_untested_optimizer True\n",
"[2021-10-27 22:17:38,016] [INFO] [config.py:944:print] zero_config .................. {\n",
" \"stage\": 1, \n",
" \"contiguous_gradients\": true, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": false, \n",
" \"load_from_fp32_weights\": true, \n",
" \"elastic_checkpoint\": true, \n",
" \"offload_param\": null, \n",
" \"offload_optimizer\": null, \n",
" \"sub_group_size\": 1.000000e+09, \n",
" \"prefetch_bucket_size\": 5.000000e+07, \n",
" \"param_persistence_threshold\": 1.000000e+05, \n",
" \"max_live_parameters\": 1.000000e+09, \n",
" \"max_reuse_distance\": 1.000000e+09, \n",
" \"gather_fp16_weights_on_model_save\": false, \n",
" \"ignore_unused_parameters\": true, \n",
" \"round_robin_gradients\": false, \n",
" \"legacy_stage1\": false\n",
"}\n",
"[2021-10-27 22:17:38,016] [INFO] [config.py:944:print] zero_enabled ................. True\n",
"[2021-10-27 22:17:38,016] [INFO] [config.py:944:print] zero_optimization_stage ...... 1\n",
"[2021-10-27 22:17:38,016] [INFO] [config.py:952:print] json = {\n",
" \"train_batch_size\": 16, \n",
" \"gradient_accumulation_steps\": 1, \n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\", \n",
" \"params\": {\n",
" \"total_num_steps\": 300, \n",
" \"warmup_min_lr\": 0, \n",
" \"warmup_max_lr\": 3e-05, \n",
" \"warmup_num_steps\": 30\n",
" }\n",
" }, \n",
" \"fp16\": {\n",
" \"enabled\": true, \n",
" \"initial_scale_power\": 32, \n",
" \"loss_scale_window\": 1000, \n",
" \"hysteresis\": 2, \n",
" \"min_loss_scale\": 1\n",
" }, \n",
" \"zero_optimization\": {\n",
" \"stage\": 1, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": false, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"contiguous_gradients\": true\n",
" }, \n",
" \"zero_allow_untested_optimizer\": true, \n",
" \"wall_clock_breakdown\": false, \n",
" \"steps_per_print\": 1.000000e+10\n",
"}\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.0004813671112060547 seconds\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 533.39it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 534.03it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 625.36it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 500.99it/s]\n",
"step:0, loss:5.453125\n",
"step:10, loss:3.6484375\n",
"step:20, loss:3.546875\n",
"step:30, loss:3.76953125\n",
"step:40, loss:2.880859375\n",
"step:50, loss:2.408203125\n",
"step:60, loss:2.5234375\n",
"step:70, loss:2.265625\n",
"step:80, loss:2.505859375\n",
"step:90, loss:2.939453125\n",
"step:100, loss:2.791015625\n",
"step:110, loss:2.48828125\n",
"step:120, loss:2.95703125\n",
"step:130, loss:2.361328125\n",
"step:140, loss:2.92578125\n",
"step:150, loss:3.8515625\n",
"step:160, loss:3.044921875\n",
"step:170, loss:3.052734375\n",
"step:180, loss:1.65625\n",
"step:190, loss:3.509765625\n",
"step:200, loss:3.716796875\n",
"step:210, loss:3.560546875\n",
"step:220, loss:2.98046875\n",
"step:230, loss:3.251953125\n",
"step:240, loss:2.564453125\n",
"step:250, loss:3.19921875\n",
"step:260, loss:3.564453125\n",
"step:270, loss:3.23828125\n",
"step:280, loss:2.615234375\n",
"step:290, loss:2.23046875\n",
"step:300, loss:3.48828125\n"
]
}
],
"source": [
"!deepspeed --num_gpus=4 ../src/zero_config.py"
]
},
{
"cell_type": "markdown",
"id": "5cd8505c",
"metadata": {},
"source": [
")\n"
]
}
],
"source": [
"\"\"\"\n",
"src/checkpointing.py\n",
"\"\"\"\n",
"from torch import nn\n",
"from torch.utils.checkpoint import checkpoint\n",
"from transformers import BertTokenizer, BertLayer, BertConfig\n",
"\n",
"config = BertConfig.from_pretrained(\"bert-base-cased\")\n",
"tokenizer = BertTokenizer.from_pretrained(\"bert-base-cased\")\n",
"tokens = tokenizer(\"Hello I am Kevin\", return_tensors=\"pt\")\n",
"\n",
"embedding = nn.Embedding(tokenizer.vocab_size, config.hidden_size)\n",
"layers = nn.ModuleList([BertLayer(config) for _ in range(6)])\n",
"\n",
"hidden_states = embedding(tokens.input_ids)\n",
"attention_mask = tokens.attention_mask\n",
"\n",
"for i, layer_module in enumerate(layers):\n",
" layer_outputs = checkpoint(\n",
" layer_module,\n",
" hidden_states,\n",
" attention_mask,\n",
" )\n",
"\n",
" hidden_states = layer_outputs[0]\n",
"\n",
"print(f\"output: {hidden_states}\")"
]
},
{
"cell_type": "markdown",
"id": "0fd693ff",
"metadata": {},
"source": [
"사용법은 위 예제처럼 기존에 **`module(a, b, c)`와 같이 사용하던 것을 `checkpoint(module, a, b, c)`와 같이 변경**하기만 하면 끝입니다. \n",
"\n",
"또한 우리가 자주 사용하는 Hugging Face `transformers`에도 거의 대부분 모델에 이러한 Activation Checkpointing 기능이 탑재되어 있습니다. **단순히 `model.gradient_checkpointing_enable()`와 `model.gradient_checkpointing_disable()`으로 켜고 끌 수 있습니다.** 정말 쉽죠?"
]
},
{
"cell_type": "markdown",
"id": "16c467f1",
"metadata": {},
"source": [
", {'localhost': [0, 1, 2, 3]})\n",
"[2021-10-27 22:30:26,909] [INFO] [launch.py:102:main] dist_world_size=4\n",
"[2021-10-27 22:30:26,910] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\n",
"[2021-10-27 22:30:32,066] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:30:32,069] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:30:32,126] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:30:32,129] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:30:32,144] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:30:32,148] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:30:32,153] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 22:30:32,156] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 22:30:37,512] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed groups\n",
"[2021-10-27 22:30:37,512] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed model parallel group with size 1\n",
"[2021-10-27 22:30:37,517] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed expert parallel group with size 1\n",
"[2021-10-27 22:30:37,517] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert data parallel process group with ranks: [0, 1, 2, 3]\n",
"[2021-10-27 22:30:37,517] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [0]\n",
"[2021-10-27 22:30:37,518] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [1]\n",
"[2021-10-27 22:30:37,518] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [2]\n",
"[2021-10-27 22:30:37,518] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [3]\n",
"[2021-10-27 22:30:37,781] [INFO] [engine.py:205:__init__] DeepSpeed Flops Profiler Enabled: False\n",
"[2021-10-27 22:30:37,781] [INFO] [engine.py:849:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer\n",
"[2021-10-27 22:30:37,781] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer\n",
"[2021-10-27 22:30:37,786] [INFO] [engine.py:871:_configure_optimizer] DeepSpeed Basic Optimizer = Adam\n",
"[2021-10-27 22:30:37,786] [INFO] [utils.py:44:is_zero_supported_optimizer] Checking ZeRO support for optimizer=Adam type=\n",
"[2021-10-27 22:30:37,786] [INFO] [logging.py:68:log_dist] [Rank 0] Creating fp16 ZeRO stage 1 optimizer\n",
"[2021-10-27 22:30:37,786] [INFO] [stage2.py:111:__init__] Reduce bucket size 500000000.0\n",
"[2021-10-27 22:30:37,786] [INFO] [stage2.py:112:__init__] Allgather bucket size 500000000.0\n",
"[2021-10-27 22:30:37,786] [INFO] [stage2.py:113:__init__] CPU Offload: False\n",
"[2021-10-27 22:30:37,786] [INFO] [stage2.py:114:__init__] Round robin gradient partitioning: False\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...\n",
"Building extension module utils...\n",
"Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\n",
"ninja: no work to do.\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.34302282333374023 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.40213775634765625 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021179676055908 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021291732788086 seconds\n",
"Rank: 0 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 3 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 1 partition count [4] and sizes[(31109952, False)] \n",
"Rank: 2 partition count [4] and sizes[(31109952, False)] \n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Loading extension module utils...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.00044083595275878906 seconds\n",
"Time to load utils op: 0.0004825592041015625 seconds\n",
"Time to load utils op: 0.00045371055603027344 seconds\n",
"[2021-10-27 22:30:39,142] [INFO] [utils.py:806:see_memory_usage] Before initializing optimizer states\n",
"[2021-10-27 22:30:39,142] [INFO] [utils.py:811:see_memory_usage] MA 0.36 GB Max_MA 0.42 GB CA 0.61 GB Max_CA 1 GB \n",
"[2021-10-27 22:30:39,143] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:30:39,182] [INFO] [utils.py:806:see_memory_usage] After initializing optimizer states\n",
"[2021-10-27 22:30:39,183] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 1.06 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:30:39,183] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:30:39,183] [INFO] [stage2.py:474:__init__] optimizer state initialized\n",
"[2021-10-27 22:30:39,219] [INFO] [utils.py:806:see_memory_usage] After initializing ZeRO optimizer\n",
"[2021-10-27 22:30:39,220] [INFO] [utils.py:811:see_memory_usage] MA 0.59 GB Max_MA 0.59 GB CA 1.31 GB Max_CA 1 GB \n",
"[2021-10-27 22:30:39,220] [INFO] [utils.py:816:see_memory_usage] CPU Virtual Memory: used = 16.61 GB, percent = 6.9%\n",
"[2021-10-27 22:30:39,221] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam\n",
"[2021-10-27 22:30:39,221] [INFO] [engine.py:587:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupDecayLR\n",
"[2021-10-27 22:30:39,221] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = \n",
"[2021-10-27 22:30:39,221] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:940:print] DeepSpeedEngine configuration:\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] activation_checkpointing_config {\n",
" \"partition_activations\": true, \n",
" \"contiguous_memory_optimization\": true, \n",
" \"cpu_checkpointing\": true, \n",
" \"number_checkpoints\": 4, \n",
" \"synchronize_checkpoint_boundary\": false, \n",
" \"profile\": false\n",
"}\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] amp_enabled .................. False\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] amp_params ................... False\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True\n",
"[2021-10-27 22:30:39,221] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] curriculum_enabled ........... False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] curriculum_params ............ False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] dataloader_drop_last ......... False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] disable_allgather ............ False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] dump_state ................... False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_enabled ........... False\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] eigenvalue_verbose ........... False\n",
"[2021-10-27 22:30:39,222] [INFO] [config.py:944:print] elasticity_enabled ........... False\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] flops_profiler_config ........ {\n",
" \"enabled\": false, \n",
" \"profile_step\": 1, \n",
" \"module_depth\": -1, \n",
" \"top_modules\": 1, \n",
" \"detailed\": true, \n",
" \"output_file\": null\n",
"}\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] fp16_enabled ................. True\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] global_rank .................. 0\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] gradient_clipping ............ 0.0\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] loss_scale ................... 0\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] memory_breakdown ............. False\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] optimizer_name ............... None\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] optimizer_params ............. None\n",
"[2021-10-27 22:30:39,224] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] pld_enabled .................. False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] pld_params ................... False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] prescale_gradients ........... False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_groups .............. 1\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_offset .............. 1000\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_period .............. 1000\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_rounding ............ 0\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_start_bits .......... 16\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_target_bits ......... 8\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_training_enabled .... False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_type ................ 0\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] quantize_verbose ............. False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] scheduler_name ............... WarmupDecayLR\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] scheduler_params ............. {'total_num_steps': 300, 'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 30}\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] sparse_attention ............. None\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] steps_per_print .............. 9999999999\n",
"[2021-10-27 22:30:39,225] [INFO] [config.py:944:print] tensorboard_enabled .......... False\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] tensorboard_output_path ...... \n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] train_batch_size ............. 16\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 4\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] use_quantizer_kernel ......... False\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] wall_clock_breakdown ......... False\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] world_size ................... 4\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] zero_allow_untested_optimizer True\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] zero_config .................. {\n",
" \"stage\": 1, \n",
" \"contiguous_gradients\": true, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": false, \n",
" \"load_from_fp32_weights\": true, \n",
" \"elastic_checkpoint\": true, \n",
" \"offload_param\": null, \n",
" \"offload_optimizer\": null, \n",
" \"sub_group_size\": 1.000000e+09, \n",
" \"prefetch_bucket_size\": 5.000000e+07, \n",
" \"param_persistence_threshold\": 1.000000e+05, \n",
" \"max_live_parameters\": 1.000000e+09, \n",
" \"max_reuse_distance\": 1.000000e+09, \n",
" \"gather_fp16_weights_on_model_save\": false, \n",
" \"ignore_unused_parameters\": true, \n",
" \"round_robin_gradients\": false, \n",
" \"legacy_stage1\": false\n",
"}\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] zero_enabled ................. True\n",
"[2021-10-27 22:30:39,226] [INFO] [config.py:944:print] zero_optimization_stage ...... 1\n",
"[2021-10-27 22:30:39,227] [INFO] [config.py:952:print] json = {\n",
" \"train_batch_size\": 16, \n",
" \"gradient_accumulation_steps\": 1, \n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\", \n",
" \"params\": {\n",
" \"total_num_steps\": 300, \n",
" \"warmup_min_lr\": 0, \n",
" \"warmup_max_lr\": 3e-05, \n",
" \"warmup_num_steps\": 30\n",
" }\n",
" }, \n",
" \"fp16\": {\n",
" \"enabled\": true, \n",
" \"initial_scale_power\": 32, \n",
" \"loss_scale_window\": 1000, \n",
" \"hysteresis\": 2, \n",
" \"min_loss_scale\": 1\n",
" }, \n",
" \"zero_optimization\": {\n",
" \"stage\": 1, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"reduce_bucket_size\": 5.000000e+08\n",
" }, \n",
" \"activation_checkpointing\": {\n",
" \"partition_activations\": true, \n",
" \"cpu_checkpointing\": true, \n",
" \"contiguous_memory_optimization\": true, \n",
" \"number_checkpoints\": 4\n",
" }, \n",
" \"zero_allow_untested_optimizer\": true, \n",
" \"wall_clock_breakdown\": false, \n",
" \"steps_per_print\": 1.000000e+10\n",
"}\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.0004620552062988281 seconds\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 565.38it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 609.24it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 550.14it/s]\n",
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
"100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 549.78it/s]\n",
"step:0, loss:5.453125\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"step:10, loss:3.6484375\n",
"step:20, loss:3.546875\n",
"step:30, loss:3.76953125\n",
"step:40, loss:2.880859375\n",
"step:50, loss:2.408203125\n",
"step:60, loss:2.5234375\n",
"step:70, loss:2.265625\n",
"step:80, loss:2.505859375\n",
"step:90, loss:2.939453125\n",
"step:100, loss:2.791015625\n",
"step:110, loss:2.48828125\n",
"step:120, loss:2.95703125\n",
"step:130, loss:2.361328125\n",
"step:140, loss:2.92578125\n",
"step:150, loss:3.8515625\n",
"step:160, loss:3.044921875\n",
"step:170, loss:3.052734375\n",
"step:180, loss:1.65625\n",
"step:190, loss:3.509765625\n",
"step:200, loss:3.716796875\n",
"step:210, loss:3.560546875\n",
"step:220, loss:2.98046875\n",
"step:230, loss:3.251953125\n",
"step:240, loss:2.564453125\n",
"step:250, loss:3.19921875\n",
"step:260, loss:3.564453125\n",
"step:270, loss:3.23828125\n",
"step:280, loss:2.615234375\n",
"step:290, loss:2.23046875\n",
"step:300, loss:3.48828125\n"
]
}
],
"source": [
"!deepspeed --num_gpus=4 ../src/zero_args.py --deepspeed_config=../src/zero_r_config.json"
]
},
{
"cell_type": "markdown",
"id": "588bccfc",
"metadata": {},
"source": [
", {'localhost': [0, 1, 2, 3]})\n",
"[2021-10-27 23:25:26,109] [INFO] [launch.py:102:main] dist_world_size=4\n",
"[2021-10-27 23:25:26,109] [INFO] [launch.py:105:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3\n",
"[2021-10-27 23:25:31,292] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 23:25:31,295] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 23:25:31,337] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 23:25:31,340] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 23:25:31,355] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 23:25:31,358] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 23:25:31,366] [INFO] [logging.py:68:log_dist] [Rank -1] DeepSpeed info: version=0.5.4, git-hash=unknown, git-branch=unknown\n",
"[2021-10-27 23:25:31,369] [INFO] [distributed.py:47:init_distributed] Initializing torch distributed with backend: nccl\n",
"[2021-10-27 23:25:36,773] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed groups\n",
"[2021-10-27 23:25:36,774] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed model parallel group with size 1\n",
"[2021-10-27 23:25:36,779] [INFO] [logging.py:68:log_dist] [Rank 0] initializing deepspeed expert parallel group with size 1\n",
"[2021-10-27 23:25:36,780] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert data parallel process group with ranks: [0, 1, 2, 3]\n",
"[2021-10-27 23:25:36,780] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [0]\n",
"[2021-10-27 23:25:36,780] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [1]\n",
"[2021-10-27 23:25:36,780] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [2]\n",
"[2021-10-27 23:25:36,780] [INFO] [logging.py:68:log_dist] [Rank 0] creating expert parallel process group with ranks: [3]\n",
"[2021-10-27 23:25:37,092] [INFO] [engine.py:205:__init__] DeepSpeed Flops Profiler Enabled: False\n",
"[2021-10-27 23:25:37,092] [INFO] [engine.py:849:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer\n",
"[2021-10-27 23:25:37,092] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer\n",
"[2021-10-27 23:25:37,097] [INFO] [engine.py:871:_configure_optimizer] DeepSpeed Basic Optimizer = Adam\n",
"[2021-10-27 23:25:37,097] [INFO] [utils.py:44:is_zero_supported_optimizer] Checking ZeRO support for optimizer=Adam type=\n",
"[2021-10-27 23:25:37,097] [INFO] [logging.py:68:log_dist] [Rank 0] Creating fp16 ZeRO stage 3 optimizer\n",
"Initializing ZeRO Stage 3\n",
"[2021-10-27 23:25:37,101] [INFO] [stage3.py:638:__init__] Reduce bucket size 500000000.0\n",
"[2021-10-27 23:25:37,101] [INFO] [stage3.py:639:__init__] Allgather bucket size 50000000\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...\n",
"Building extension module utils...\n",
"Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)\n",
"ninja: no work to do.\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.3441762924194336 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.4021937847137451 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.40210652351379395 seconds\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.40212202072143555 seconds\n",
"[2021-10-27 23:25:38,717] [INFO] [stage3.py:831:__init__] optimizer state initialized\n",
"[2021-10-27 23:25:38,942] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam\n",
"[2021-10-27 23:25:38,942] [INFO] [engine.py:587:_configure_lr_scheduler] DeepSpeed using configured LR scheduler = WarmupDecayLR\n",
"[2021-10-27 23:25:38,942] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = \n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"[2021-10-27 23:25:38,943] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:940:print] DeepSpeedEngine configuration:\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.00048089027404785156 seconds\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] activation_checkpointing_config {\n",
" \"partition_activations\": true, \n",
" \"contiguous_memory_optimization\": true, \n",
" \"cpu_checkpointing\": true, \n",
" \"number_checkpoints\": 4, \n",
" \"synchronize_checkpoint_boundary\": false, \n",
" \"profile\": false\n",
"}\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}\n",
"Time to load utils op: 0.0004799365997314453 seconds\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] amp_enabled .................. False\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] amp_params ................... False\n",
"Time to load utils op: 0.00047278404235839844 seconds\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False\n",
"[2021-10-27 23:25:38,943] [INFO] [config.py:944:print] curriculum_enabled ........... False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] curriculum_params ............ False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] dataloader_drop_last ......... False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] disable_allgather ............ False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] dump_state ................... False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... {'init_scale': 4294967296, 'scale_window': 1000, 'delayed_shift': 2, 'min_scale': 1}\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_enabled ........... False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] eigenvalue_verbose ........... False\n",
"[2021-10-27 23:25:38,944] [INFO] [config.py:944:print] elasticity_enabled ........... False\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] flops_profiler_config ........ {\n",
" \"enabled\": false, \n",
" \"profile_step\": 1, \n",
" \"module_depth\": -1, \n",
" \"top_modules\": 1, \n",
" \"detailed\": true, \n",
" \"output_file\": null\n",
"}\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] fp16_enabled ................. True\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] global_rank .................. 0\n",
"[2021-10-27 23:25:38,946] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] gradient_clipping ............ 0.0\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] loss_scale ................... 0\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] memory_breakdown ............. False\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] optimizer_name ............... None\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] optimizer_params ............. None\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] pld_enabled .................. False\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] pld_params ................... False\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] prescale_gradients ........... False\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] quantize_groups .............. 1\n",
"[2021-10-27 23:25:38,947] [INFO] [config.py:944:print] quantize_offset .............. 1000\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_period .............. 1000\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_rounding ............ 0\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_start_bits .......... 16\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_target_bits ......... 8\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_training_enabled .... False\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_type ................ 0\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] quantize_verbose ............. False\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] scheduler_name ............... WarmupDecayLR\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] scheduler_params ............. {'total_num_steps': 300, 'warmup_min_lr': 0, 'warmup_max_lr': 3e-05, 'warmup_num_steps': 30}\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] sparse_attention ............. None\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] steps_per_print .............. 9999999999\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] tensorboard_enabled .......... False\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName\n",
"[2021-10-27 23:25:38,948] [INFO] [config.py:944:print] tensorboard_output_path ...... \n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] train_batch_size ............. 16\n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 4\n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] use_quantizer_kernel ......... False\n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] wall_clock_breakdown ......... False\n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] world_size ................... 4\n",
"[2021-10-27 23:25:38,949] [INFO] [config.py:944:print] zero_allow_untested_optimizer True\n",
"[2021-10-27 23:25:38,950] [INFO] [config.py:944:print] zero_config .................. {\n",
" \"stage\": 3, \n",
" \"contiguous_gradients\": true, \n",
" \"reduce_scatter\": true, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"allgather_partitions\": true, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"overlap_comm\": true, \n",
" \"load_from_fp32_weights\": true, \n",
" \"elastic_checkpoint\": true, \n",
" \"offload_param\": {\n",
" \"device\": \"cpu\", \n",
" \"nvme_path\": null, \n",
" \"buffer_count\": 5, \n",
" \"buffer_size\": 1.000000e+08, \n",
" \"max_in_cpu\": 1.000000e+09, \n",
" \"pin_memory\": true\n",
" }, \n",
" \"offload_optimizer\": {\n",
" \"device\": \"cpu\", \n",
" \"nvme_path\": null, \n",
" \"buffer_count\": 4, \n",
" \"pin_memory\": true, \n",
" \"pipeline_read\": false, \n",
" \"pipeline_write\": false, \n",
" \"fast_init\": false, \n",
" \"pipeline\": false\n",
" }, \n",
" \"sub_group_size\": 1.000000e+09, \n",
" \"prefetch_bucket_size\": 5.000000e+07, \n",
" \"param_persistence_threshold\": 1.000000e+05, \n",
" \"max_live_parameters\": 1.000000e+09, \n",
" \"max_reuse_distance\": 1.000000e+09, \n",
" \"gather_fp16_weights_on_model_save\": false, \n",
" \"ignore_unused_parameters\": true, \n",
" \"round_robin_gradients\": false, \n",
" \"legacy_stage1\": false\n",
"}\n",
"[2021-10-27 23:25:38,950] [INFO] [config.py:944:print] zero_enabled ................. True\n",
"[2021-10-27 23:25:38,950] [INFO] [config.py:944:print] zero_optimization_stage ...... 3\n",
"[2021-10-27 23:25:38,950] [INFO] [config.py:952:print] json = {\n",
" \"train_batch_size\": 16, \n",
" \"gradient_accumulation_steps\": 1, \n",
" \"scheduler\": {\n",
" \"type\": \"WarmupDecayLR\", \n",
" \"params\": {\n",
" \"total_num_steps\": 300, \n",
" \"warmup_min_lr\": 0, \n",
" \"warmup_max_lr\": 3e-05, \n",
" \"warmup_num_steps\": 30\n",
" }\n",
" }, \n",
" \"fp16\": {\n",
" \"enabled\": true, \n",
" \"initial_scale_power\": 32, \n",
" \"loss_scale_window\": 1000, \n",
" \"hysteresis\": 2, \n",
" \"min_loss_scale\": 1\n",
" }, \n",
" \"zero_optimization\": {\n",
" \"stage\": 3, \n",
" \"allgather_bucket_size\": 5.000000e+08, \n",
" \"reduce_bucket_size\": 5.000000e+08, \n",
" \"offload_param\": {\n",
" \"device\": \"cpu\", \n",
" \"pin_memory\": true\n",
" }, \n",
" \"offload_optimizer\": {\n",
" \"device\": \"cpu\", \n",
" \"pin_memory\": true\n",
" }\n",
" }, \n",
" \"activation_checkpointing\": {\n",
" \"partition_activations\": true, \n",
" \"cpu_checkpointing\": true, \n",
" \"contiguous_memory_optimization\": true, \n",
" \"number_checkpoints\": 4\n",
" }, \n",
" \"zero_allow_untested_optimizer\": true, \n",
" \"wall_clock_breakdown\": false, \n",
" \"steps_per_print\": 1.000000e+10\n",
"}\n",
"Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...\n",
"No modifications detected for re-loaded extension module utils, skipping build step...\n",
"Loading extension module utils...\n",
"Time to load utils op: 0.0004980564117431641 seconds\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)\n",
" 0%| | 0/2 [00:00\n",
"\n",
"## 6. ZeRO Infinity\n",
"\n",
"ZeRO Infinity는 NVMe(SSD) 메모리에 파라미터를 저장하는 방식을 채택하였습니다. NVMe는 CPU 메모리보다도 훨씬 커다란 메모리 용량을 가지기 때문에 메모리의 한계를 한번 더 돌파 하였다고 평가됩니다. ZeRO Infinity 알고리즘 역시 매우 복잡하기 영샹으로 확인하겠습니다. https://www.microsoft.com/en-us/research/uploads/prod/2021/04/1400x788_deepspeed_nologo-1.mp4"
]
},
{
"cell_type": "code",
"execution_count": 34,
"id": "3ac31629",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"\n",
" \n",
"
"
],
"text/plain": [
""
]
},
"execution_count": 34,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from IPython.display import HTML\n",
"\n",
"HTML(\"\"\"\n",
"\n",
"\n",
" \n",
"
\"\"\")\n"
]
},
{
"cell_type": "markdown",
"id": "093cd70f",
"metadata": {},
"source": [
"### ZeRO Infinity의 핵심 아이디어\n",
"\n",
"ZeRO Infinity는 ZeRO Offload의 확장판입니다. 기존에 ZeRO Offload는 CPU RAM과 GPU VRAM를 다음과 같이 운용하였습니다.\n",
"\n",
"- **GPU**: FP16 parameter & gradient 상주, **Forward & Backward 수행**.\n",
"- **CPU**: FP32 parameter & gradient & optimizer 상주, **Weight Update 수행**.\n",
"\n",
"ZeRO Infinity는 NVMe가 추가되어 세개의 디바이스를 운용합니다. 활용법은 아래와 같습니다.\n",
"\n",
"- **NVMe**: 기본적으로 모든 파라미터는 사용되지 않을때 NVMe에 상주.\n",
"- **GPU**: FP16 parameter & gradient가 Forward & Backward를 수행해야 할 때 NVMe에서 필요한 부분만 GPU로 업로드.\n",
"- **CPU**: FP32 parameter & gradient, optimizer가 Weight Update를 수행해야 할 때 NVMe에서 필요한 부분만 CPU로 업로드.\n",
"\n",
"즉, 기본적으로 모든 텐서를 NVMe로 내리고 있다가, 그들이 필요할때만 CPU & GPU 등의 연산 장비로 올리는 방식을 사용합니다.\n",
"\n",
"