{
"cells": [
{
"cell_type": "markdown",
"id": "e5908c0e",
"metadata": {},
"source": [
"# Additional Techniques\n",
"\n",
"지금까지는 거의 대부분 병렬화 및 메모리에 관련된 영역을 다루었습니다. 그러나 병렬화 말고도 large-scale 모델링에 유용한 테크닉들이 많이 있습니다. 이번 세션에서는 그러한 몇몇 테크닉을 간단하게 소개드리도록 하겠습니다."
]
},
{
"cell_type": "markdown",
"id": "673638b6",
"metadata": {},
"source": [
"## 1. Kernel Fusion\n",
"\n",
"커널퓨전은 CUDA로 구현된 커스텀 코드를 이용하여 연산속도를 개선하는 방법입니다.\n",
"\n",
"### Kernel은 무엇일까?\n",
"\n",
"커널은 GPU 디바이스에서 직접 돌아가는 코드라고 생각하시면 됩니다. CUDA에는 다음과 같은 문법이 존재합니다.\n",
"\n",
"
\n",
"\n",
"```cpp\n",
"__device__ void func(){...}\n",
"\n",
"__global__ void func(){...}\n",
"\n",
"__host__ void func(){...}\n",
"```\n",
"\n",
"
\n",
"\n",
"이 때, `__global__`이나 `__device__`와 같은 prefix가 붙어있는 함수는 GPU에서 작동하고, `__host__`가 붙어있거나 혹은 아무것도 붙어있지 않는 함수는 CPU에서 작동합니다. 보통 `__global__`이나 `__device__`와 같은 prefix가 포함되어 있고 GPU에서 작동하는 코드를 우리는 \"커널\"이라고 부릅니다. \n",
"\n",
"\n",
"### Fusion은 무엇일까?\n",
"\n",
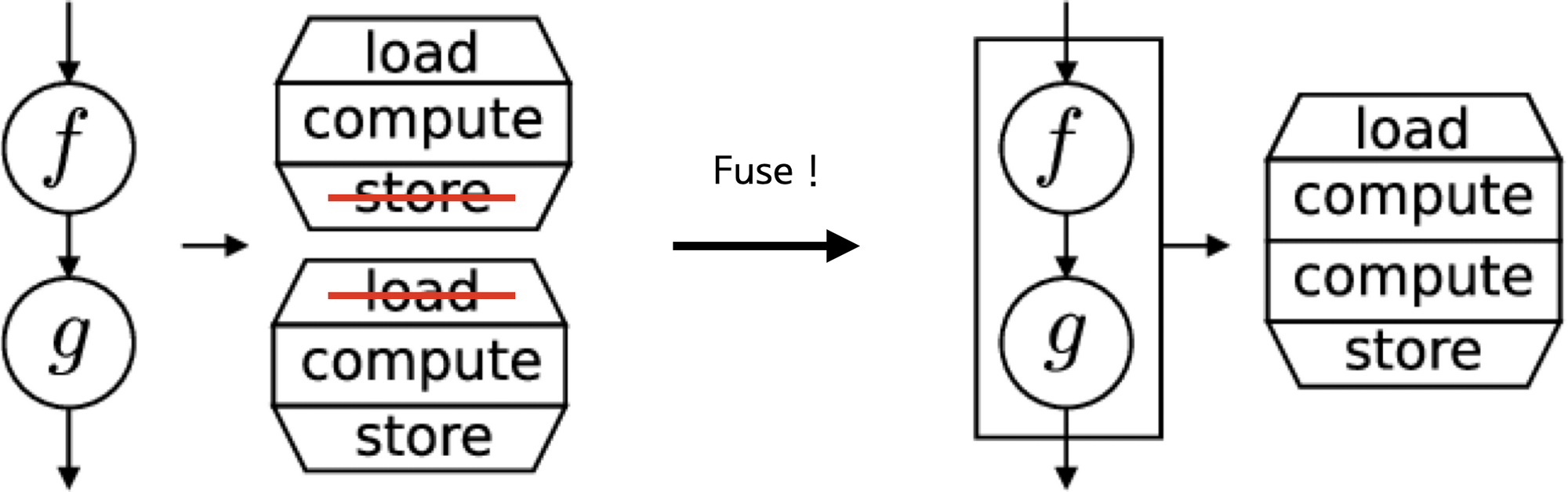
"일반적으로 우리는 PyTorch에서 제공해주는 작은 연산들을 결합해서 모델을 만듭니다. 예를 들어 `torch.matmul`과 `torch.add`를 결합하여 `y = torch.matmul(x, w) + b`와 같은 연산을 만들어냅니다. 마찬가지로 `torch.split`과 `torch.permute` 등의 연산을 결합하여 Transformer Head Split & Merge 등을 구현하기도 합니다. 이러한 방식은 구현하기 쉽고 깔끔하지만 내부적으로 분석해보면 상당히 비효율적입니다.\n",
"\n",
"
\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"우리가 `torch.matmul(x, w) * b`와 같은 연산을 실행했다고 가정해봅시다. 그러면 가장 먼저 torch의 호스트 코드는 `torch.matmul`에 해당하는 커널(cuBLAS)을 실행하기 위해 텐서 x와 w를 load합니다. 그리고 연산된 결과를 store합니다. 두번째로 `* b`를 연산하기 위해 방금 store 되었던 `matmul(x, w)`의 결과와 `b`를 load해서 연산하고 그 결과를 다시 store 합니다. \n",
"\n",
"뭔가 비효율적입니다. 만약 한번에 `x`, `w`, `b`를 load 한 뒤에 모든연산을 끝내고 한번에 store 할 수는 없을까요? 불행히도 torch는 유저의 자유도를 위해 최대한 연산을 작은 단위로 제공해야 할 필요가 있습니다. 따라서 몇몇 연산을 제외하고는 이런 방식으로 load, store 과정이 불필요하게 반복되죠. 하지만 우리가 CUDA 코드를 작성할 줄 안다면 굳이 torch의 커널을 쓸 필요가 없습니다. 우리가 직접 `x`, `w`, `b`를 한번에 로드해서 연산하고 저장하는 커널을 구현해서 사용하면 그만이니까요. 따라서 많은 CUDA 프로그래머들이 불필요한 load, store 과정과 함수호출 오버헤드를 줄이기 위해 필요한 모든 파라미터를 불러와서 연산한 뒤 한번에 store하는 방식으로 구현하곤합니다.\n",
"\n",
"\n",
"
\n",
"\n",
"### 그러나 ...\n",
"그러나 본 발표에 CUDA 프로그래밍에 대한 내용을 처음부터 넣으려면 분량이 심하게 오버되기 때문에 CUDA 프로그래밍에 관련된 내용은 생략하도록 하겠습니다. 대신 지금까지 출시되었던 효과적인 Transformer 커널들을 추천해드리도록 하겠습니다. 도큐먼트 등에 사용법이 잘 나와있으니 이들을 참고하여 연산 성능을 개선해보시길 권해드립니다. (추후에 여유가 되면 CUDA 관련 노트북도 만들 수 있으면 좋겠네요)\n",
"\n",
"
\n",
"\n",
"#### Training Kernel\n",
"- [Apex Fused Kernel](https://github.com/NVIDIA/apex/tree/master/csrc): \n",
"- [LightSeq Training Kernel](https://github.com/bytedance/lightseq/tree/master/lightseq/training)\n",
"- [DeepSpeed Training Kernel](https://www.deepspeed.ai/tutorials/inference-tutorial/)\n",
"\n",
"#### Inference Kernel\n",
"- [LightSeq Inference Kernel](https://github.com/bytedance/lightseq/tree/master/lightseq/inference)\n",
"- [FastSeq NGram repeat blocking Kernel](https://github.com/microsoft/fastseq/tree/main/fastseq/clib/cuda)\n",
"- [Faster Transformer Kernel](https://github.com/NVIDIA/FasterTransformer)\n",
"- [DeepSpeed Inference Kernel](https://www.deepspeed.ai/tutorials/transformer_kernel/)\n",
"- [Turbo Transformer Kernel](https://github.com/Tencent/TurboTransformers)\n",
"- [Effective Transformer Kernel](https://github.com/bytedance/effective_transformer)"
]
},
{
"cell_type": "markdown",
"id": "3d69d5c1",
"metadata": {},
"source": [
"## 2. Progressive Layer Dropping (PLD)\n",
"\n",
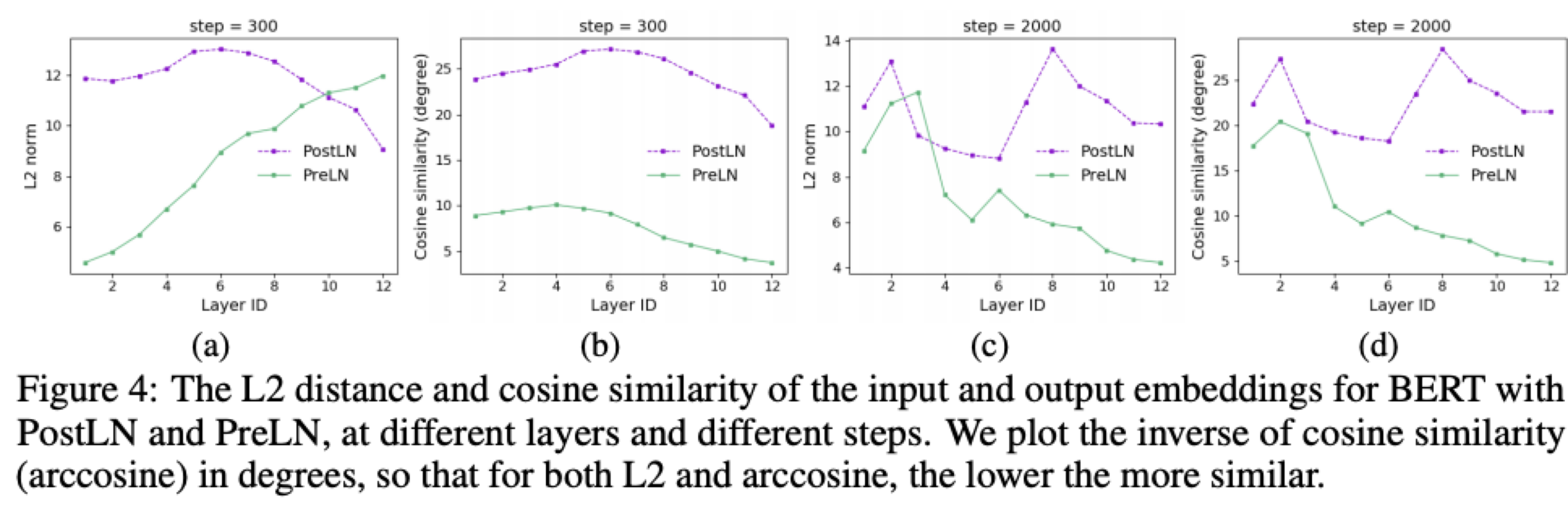
"Progressive Layer Dropping은 랜덤하게 Layer를 Skip해서 학습 속도와 성능을 개선하는 방법입니다. 논문의 저자들은 BERT의 학습과정을 아래와 같은 두가지의 인사이트를 얻을 수 있었다고 합니다.\n",
"\n",
"
\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"- **학습 초반**에는 Layer에 따른 Input과 Output의 L2-Norm과 Cos similiarity **차이가** 크지만 **후반으로 갈 수록 작아진다.**\n",
" - 즉, 학습 초반에는 많은 것들을 새로 배우고 변하게 되지만 학습 후반에는 거의 미세한 교정만 하는 것으로 보인다.\n",
"\n",
"
\n",
"\n",
"- Pre-LN 모델의 경우 **앞쪽 레이어**는 Input과 Output의 차이가 꽤 있지만, **뒤쪽은 레이어는 거의 비슷한 출력**을 내놓는다.\n",
" - 뒤쪽 Layer로 갈수록 기존 결과를 크게 바꾸지 않고 아주 미세한 교정만 하는 것으로 보인다.\n",
" \n",
"
\n",
"\n",
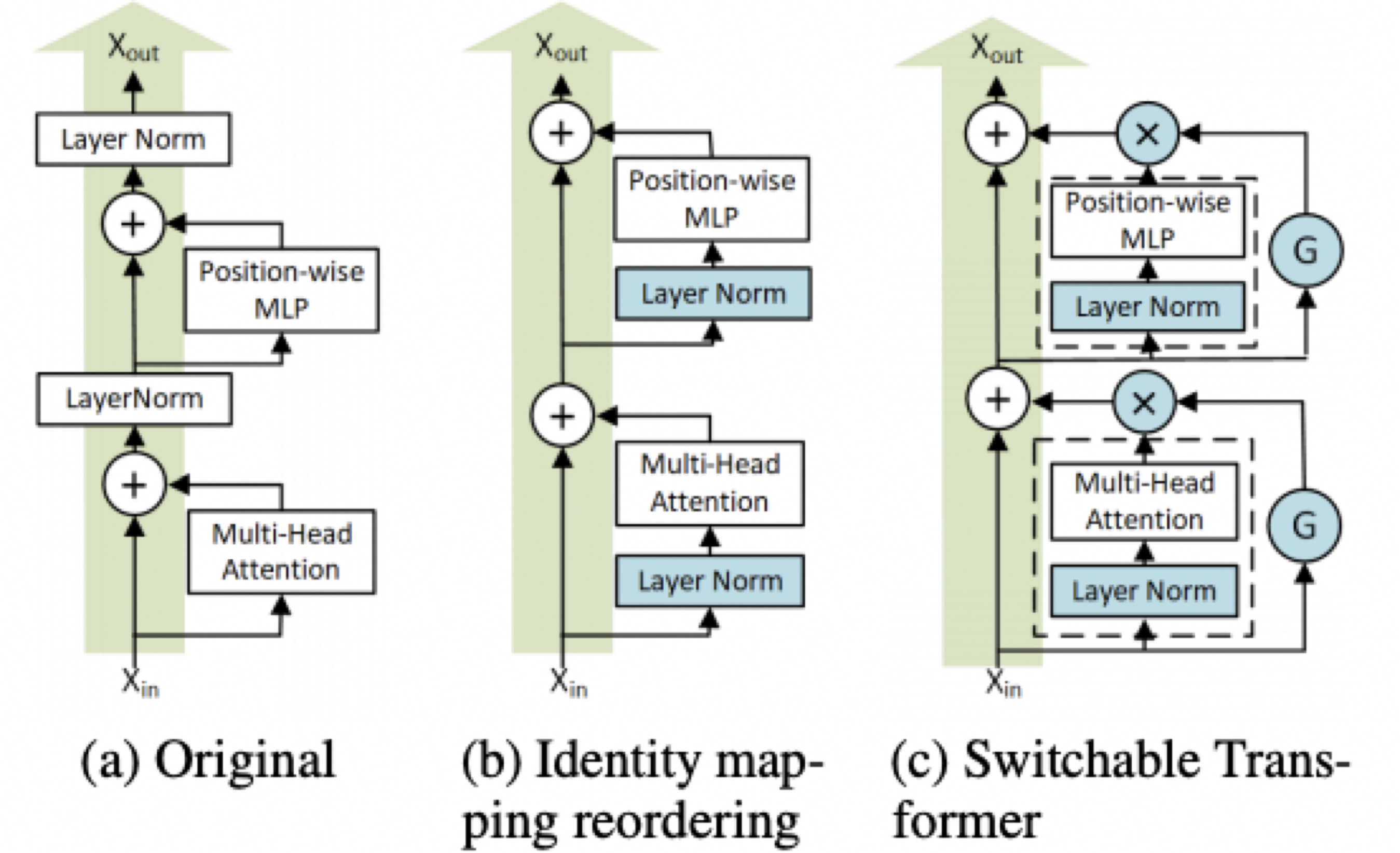
"이를 기반으로 학습중에 일부 레이어를 dropping 하도록 구현해서 학습 속도와 성능을 개선합니다. 실험에서 얻은 인사이트를 바탕으로 학습에 중요하다고 여겨지는 학습초반 / 앞쪽 레이어는 비교적 덜 dropping 하고 학습에 덜 중요하다고 여겨지는 학습 후반 / 뒤쪽 레이어는 자주 dropping시켜서 좋은 성능을 얻었다고 합니다.\n",
"\n",
"\n",
"\n",
"Dropping은 Gate Function: G = {0, 1}를 두어 Layer를 Dropping 할지 말지 결정합니다.\n",
"\n",
"Gate Function이 0을 가리키게 되면, 단순히 Identity Mapping만 다음 레이어로 넘어가도록 구현되었습니다.\n",
"\n",
"\n",
"\n",
"현재 DeepSpeed에 탑재되어있는 기능인데, ZeRO 등과 아직 호환이 되지 않아서 실제로 large-scale 모델 개발할 때 사용하는건 어려울 것 같습니다. PLD도 DeepSpeed 내의 다른 기능들과 하루 빨리 결합되었으면 좋겠네요 :) 더 자세한 내용은 논문 https://arxiv.org/abs/2010.13369 을 참고하세요."
]
},
{
"cell_type": "markdown",
"id": "26d101cf",
"metadata": {},
"source": [
"## 3. 1Bit Compressive Optimizers\n",
"\n",
"- 1bit Adam\n",
"- 1bit Ladam\n",
"\n",
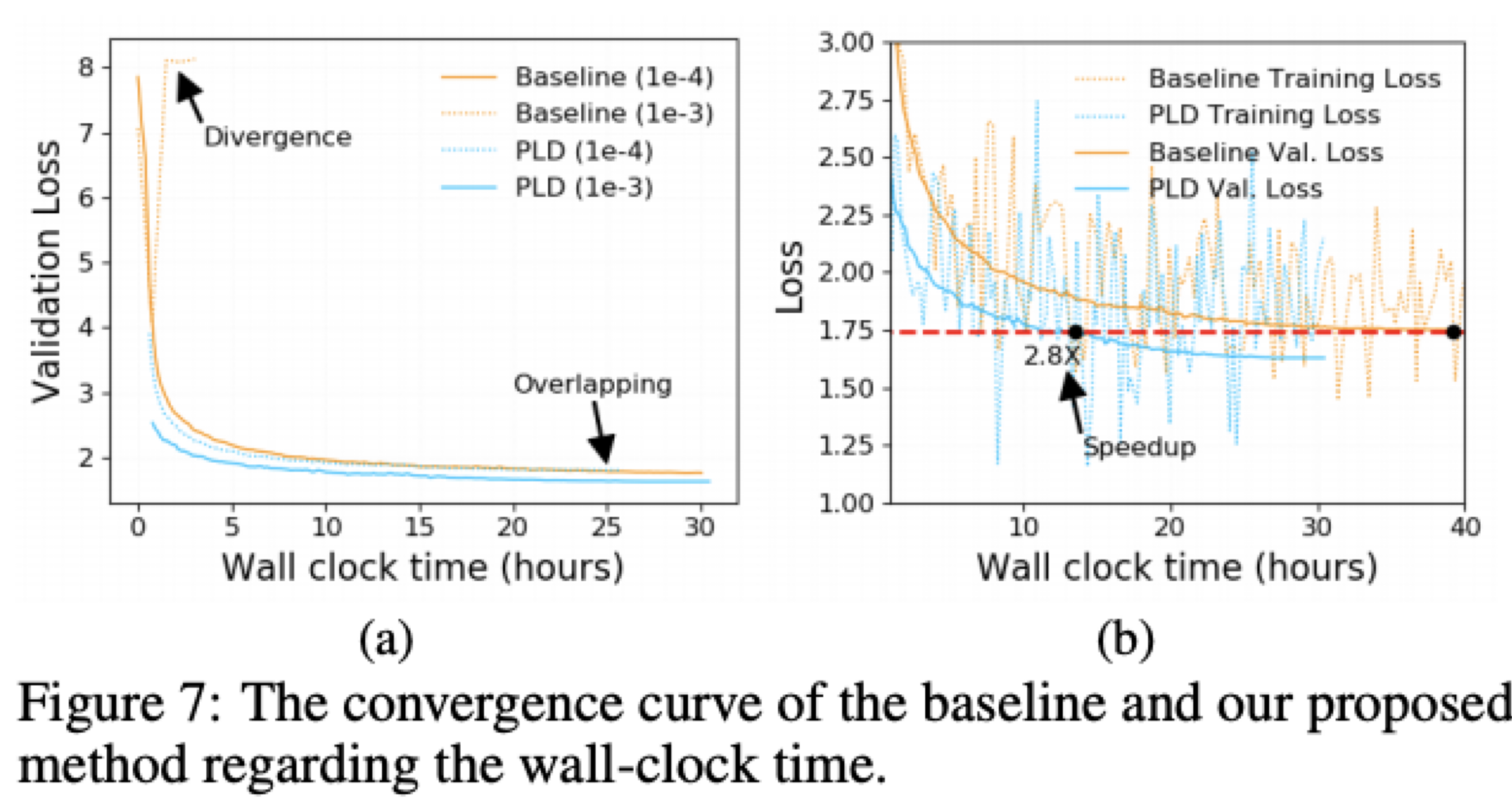
"1Bit Compressive Optimizers는 Adam Optimizer 등의 모멘텀을 1bit로 압축하는 기술입니다. Gradient와 Optimizer states는 분산 장치들이 자주 주고받는, 통신에 있어서 병목이 될 수 있는 데이터들입니다. 따라서 SGD의 경우 모멘텀 항을 1bit로 압축해서 통신한 뒤에 이후에 후처리로 오차를 보정하는 기술을 적용해서 통신 속도를 개선하곤 했습니다. Adam의 경우는 분산 항이 비선형성이 있어서 이러한 기술을 적용하기 어려웠지만 1bit Adam은 한가지 트릭으로 이 문제를 풀어냈고, 데이터를 압축해도 좋은 성능을 보였습니다.\n",
"\n",
"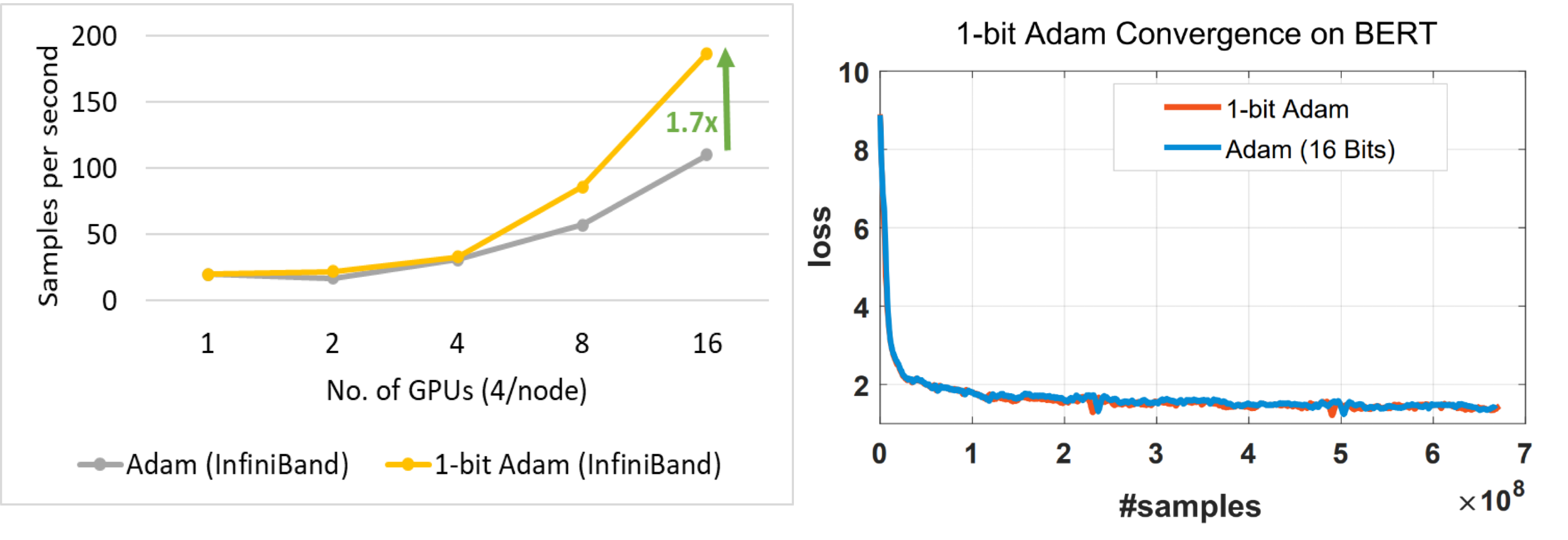\n",
"\n",
"그 방법은 처음 몇 번은 비 압축으로 진행하고 어느 단계에 다다르면 분산 항은 그냥 상수로 고정해서 전송하고, 모멘텀 항만 제대로 압축하여 SGD 처럼 전송하는 것이였습니다. 이 기술은 비 압축 Adam과 동일한 수렴률을 보여주며, 그 결과 통신량을 최대 5배 감소시킬 수 있다고 합니다. 더 자세한 내용은 논문 https://arxiv.org/abs/2102.02888을 참고하세요 :)\n"
]
},
{
"cell_type": "markdown",
"id": "bd5b1466",
"metadata": {},
"source": [
"## 4. Curriculum Learning\n",
"\n",
"커리큘럼 러닝은 학습 인간의 학습을 뉴럴넷 학습에 묘사한 것입니다. 인간의 경우 어릴때는 쉬운 것들을 먼저 배우다가 나중에 나이가 들면서 점점 어려운 것들을 배우게 됩니다. 그러나 현대의 뉴럴넷 학습은 이러한 경향이 없습니다. 따라서 뉴럴넷도 비슷하게 초반에는 쉬운 샘플을 보여주고 후반에는 어려운 샘플을 보여주는 방법으로 학습합니다. \n",
"\n",
"그렇다면 어려운 샘플과 쉬운 샘플은 어떻게 구별할까요? 논문 저자들은 GPT 모델 Pre-training에 이 방식을 적용했는데요. 단순히 길이가 긴 샘플은 어려운 샘플이고 길이가 짧은 샘플은 쉬운 샘플이라고 생각했습니다. Megatron-LM의 경우 모든 샘플이 붙어있는채로 학습되기 때문에 의도적으로 학습초반에는 입력 데이터를 chunking해서 자른다음 짧은 상태로 넣어주고, 학습이 진행되면서 점점 긴 샘플을 입력받게 했다고 합니다.\n",
"\n",
"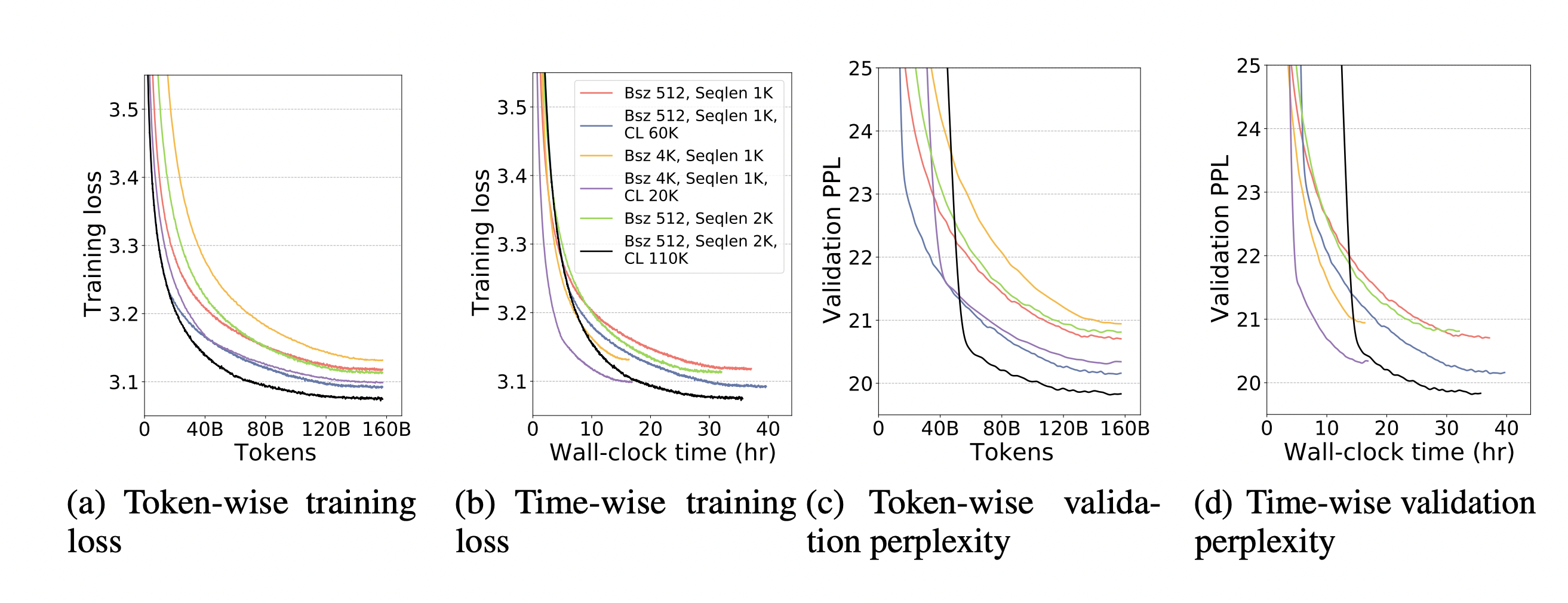\n",
"\n",
"매우 간단한 방법이지만 꽤 놀라운 성능을 보여줬습니다. 그래프를 보면 Curriculum learning을 적용한 경우가 Loss가 더 낮게 측정 된다는 것을 알 수 있죠. Curriculum Learning도 현재 DeepSpeed에 구현이 되어있는 상태입니다. 이러한 기능들도 잘 활용해보시길 추천드립니다. 자세한 내용은 https://arxiv.org/abs/2108.06084 논문을 참고하세요."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.9"
}
},
"nbformat": 4,
"nbformat_minor": 5
}