---
title: "String Manipulation With stringr"
author: "Dr. Hua Zhou @ UCLA"
date: "Feb 1, 2022"
subtitle: Biostat 203B
output:
# ioslides_presentation: default
html_document:
toc: true
toc_depth: 4
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(fig.width=5, fig.height=3.5, fig.align='center', cache=FALSE)
```
# String | r4ds chapter 14
We encounter text data often: sentiment analysis, electronic health records (doctor notes), twitter data, websites, ...
## stringr
- stringr package, by Hadley Wickham et al, provides utilities for handling strings.
- Included in tidyverse.
```{r}
library("tidyverse")
```
```{r}
# load htmlwidgets
library(htmlwidgets)
```
- Main functions:
- `str_detect(string, pattern)`: Detect the presence or absence of a pattern in a string.
- `str_locate(string, pattern)`: Locate the first position of a pattern and return a matrix with start and end.
- `str_extract(string, pattern)`: Extract text corresponding to the first match.
- `str_match(string, pattern)`: Extract matched groups from a string.
- `str_split(string, pattern)`: Split string into pieces and returns a list of character vectors.
- `str_replace(string, pattern, replacement)`: Replace the first matched pattern and returns a character vector.
- Variants with an `_all` suffix will match more than 1 occurrence of the pattern in a given string.
- Most functions are vectorized.
## Basics
- Strings are enclosed by double quotes or single quotes:
```{r}
string1 <- "This is a string"
string2 <- 'If I want to include a "quote" inside a string, I use single quotes'
```
- Literal single or double quote:
```{r}
double_quote <- "\"" # or '"'
single_quote <- '\'' # or "'"
```
----
- Printed representation:
```{r}
x <- c("\"", "\\")
x
```
vs `cat` (how R views your string after all special characters have been parsed):
```{r}
cat(x)
```
vs `writeLines()` (how R views your string after all special characters have been parsed):
```{r}
writeLines(x)
```
----
- Other special characters: `"\n"` (new line), `"\t"` (tab), ... Check
```{r, eval = FALSE}
?"'"
```
for a complete list.
```{r}
cat("a\"b")
cat("a\tb")
cat("a\nb")
```
- Unicode
```{r}
x <- "\u00b5"
x
```
- Character vector (vector of strings):
```{r}
c("one", "two", "three")
```
## String length
- Length of a single string:
```{r}
str_length("R for data science")
```
- Lengths of a character vector:
```{r}
str_length(c("a", "R for data science", NA))
```
## Combining strings
- Combine two or more strings
```{r}
str_c("x", "y")
str_c("x", "y", "z")
```
- Separator:
```{r}
str_c("x", "y", sep = ", ")
```
----
- `str_c()` is vectorised:
```{r}
str_c("prefix-", c("a", "b", "c"), "-suffix")
```
- Objects of length 0 are silently dropped:
```{r}
name <- "Hadley"
time_of_day <- "morning"
birthday <- FALSE
str_c(
"Good ",
time_of_day,
" ",
name,
if (birthday) " and HAPPY BIRTHDAY",
"."
)
```
----
- Combine a vector of strings:
```{r}
# this is not collapsing
str_c(c("x", "y", "z"))
# collapse
str_c(c("x", "y", "z"), collapse = ", ")
# equivalently
str_flatten(c("x", "y", "z"), collapse = ", ")
```
## Subsetting strings
- By position:
```{r}
str_sub("Apple", 1, 3)
# vectorized
x <- c("Apple", "Banana", "Pear")
str_sub(x, 1, 3)
```
- Negative numbers count backwards from end:
```{r}
str_sub(x, -3, -1)
```
----
- Out of range:
```{r}
str_sub("a", 1, 5)
str_sub("a", 2, 5)
```
- Assignment to a substring:
```{r}
str_sub(x, 1, 1) <- str_to_lower(str_sub(x, 1, 1))
x
```
## Matching patterns with regular expressions
- `str_view()` shows the first match;
`str_view_all()` shows all matches.
- Match exact strings:
```{r}
x <- c("apple", "banana", "pear")
str_view(x, "an")
str_view_all(x, "an")
```
----
- `.` matches any character apart from a newline:
```{r}
str_view(x, ".a.")
```
```{r}
str_view_all(x, ".a.")
```
- **Regex escapes live on top of regular string escapes, so there needs to be two levels of escapes.**
To match a literal `.`:
```{r, error=TRUE}
# doesn't work because "a\.c" is treated as a regular expression
str_view(c("abc", "a.c", "bef"), "a\.c")
```
```{r}
# regular expression needs double escape
str_view(c("abc", "a.c", "bef"), "a\\.c")
```
To match a literal `\`:
```{r}
str_view("a\\b", "\\\\")
```

## Anchors
- `^` matches the start of the string:
```{r}
x <- c("apple", "banana", "pear")
str_view(x, "^a")
```
- `$` matches the end of the string:
```{r}
str_view(x, "a$")
```
----
- To force a regular expression to only match a complete string:
```{r}
x <- c("apple pie", "apple", "apple cake")
str_view(x, "^apple$")
```
## Alternation
- `[abc]`: matches a, b, or c. Same as `(a|b|c)`.
- `[^abc]`: matches anything except a, b, or c.
```{r}
str_view(c("grey", "gray"), "gr(e|a)y")
```
```{r}
str_view(c("grey", "gray"), "gr[ea]y")
```
## Repetition
-
`?`: 0 or 1
`+`: 1 or more
`*`: 0 or more
-
```{r}
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
# match either C or CC, being greedy here
str_view(x, "CC?")
# show all matches
str_view_all(x, "CC?")
# greedy matches
str_view(x, "CC+")
# greedy matches
str_view(x, 'C[LX]+')
```
----
- Specify number of matches:
`{n}`: exactly n
`{n,}`: n or more
`{,m}`: at most m
`{n,m}`: between n and m
-
```{r}
str_view(x, "C{2}")
# greedy matches
str_view(x, "C{2,}")
# greedy matches
str_view(x, "C{2,3}")
```
----
- Greedy (default) vs lazy (put `?` after repetition):
```{r}
# lazy matches
str_view(x, 'C{2,3}?')
# lazy matches
str_view(x, 'C[LX]+?')
```
- What went wrong here?
```{r}
text = ""
str_extract(text, ".*
")
```
If we add ? after a quantifier, the matching will be lazy (find the shortest possible match, not the longest).
```{r}
str_extract(text, ".*?
")
```
## Grouping and backreference
- `fruit` is a character vector pre-defined in `stringr` package:
```{r}
fruit
```
- Parentheses define groups, which can be back-referenced as `\1`, `\2`, ...
```{r}
# with match = TRUE, only show matched strings
str_view(fruit, "(..)\\1", match = TRUE)
```
## Detect matches
-
```{r}
x <- c("apple", "banana", "pear")
str_detect(x, "e")
```
- Vector `words` contains 980 commonly used words:
```{r}
length(words)
head(words)
```
----
-
```{r}
# How many common words start with t?
sum(str_detect(words, "^t"))
# What proportion of common words end with a vowel?
mean(str_detect(words, "[aeiou]$"))
```
----
- Find words that end with `x`:
```{r}
words[str_detect(words, "x$")]
```
same as
```{r}
str_subset(words, "x$")
```
----
- Filter a data frame:
```{r}
df <- tibble(
word = words,
i = seq_along(word)
)
df %>%
filter(str_detect(word, "x$"))
```
----
- `str_count()` tells how many matches are found:
```{r}
x <- c("apple", "banana", "pear")
str_count(x, "a")
```
```{r}
# On average, how many vowels per word?
mean(str_count(words, "[aeiou]"))
```
- Matches never overlap:
```{r}
str_count("abababa", "aba")
str_view_all("abababa", "aba")
```
----
- Mutate a data frame:
```{r}
df %>%
mutate(
vowels = str_count(word, "[aeiou]"),
consonants = str_count(word, "[^aeiou]")
)
```
## Extract matches
- `sentences` is a collection of 720 phrases:
```{r}
length(sentences)
head(sentences)
```
- Suppose we want to find all sentences that contain a colour.
----
- Create a collection of colours:
```{r}
(colours <- c("red", "orange", "yellow", "green", "blue", "purple"))
```
```{r}
(colour_match <- str_c(colours, collapse = "|"))
```
- Select the sentences that contain a colour, and then extract the colour to figure out which one it is:
```{r}
(has_colour <- str_subset(sentences, colour_match))
```
```{r}
(matches <- str_extract(has_colour, colour_match))
```
----
- `str_extract()` only extracts the first match.
-
```{r}
more <- sentences[str_count(sentences, colour_match) > 1]
str_view_all(more, colour_match)
```
- `str_extract_all()` extracts all matches:
```{r}
str_extract_all(more, colour_match)
```
----
- Setting `simplify = TRUE` in `str_extract_all()` will return a matrix with short matches expanded to the same length as the longest:
```{r}
str_extract_all(more, colour_match, simplify = TRUE)
```
```{r}
x <- c("a", "a b", "a b c")
str_extract_all(x, "[a-z]", simplify = TRUE)
```
## Grouped matches
- `str_extract()` gives us the complete match:
```{r}
# why "([^ ]+)" match a word?
noun <- "(a|the) ([^ ]+)"
has_noun <- sentences %>%
str_subset(noun) %>%
head(10)
has_noun %>%
str_extract(noun)
```
----
- `str_match()` gives each individual component:
```{r}
has_noun %>%
str_match(noun)
```
----
- `tidyr::extract()` works with tibble:
```{r}
tibble(sentence = sentences) %>%
tidyr::extract(
sentence, c("article", "noun"), "(a|the) ([^ ]+)",
remove = FALSE
)
```
## Replacing matches
- Replace the first match:
```{r}
x <- c("apple", "pear", "banana")
str_replace(x, "[aeiou]", "-")
```
- Replace all matches:
```{r}
str_replace_all(x, "[aeiou]", "-")
```
- Multiple replacement:
```{r}
x <- c("1 house", "2 cars", "3 people")
str_replace_all(x, c("1" = "one", "2" = "two", "3" = "three"))
```
----
- Back-reference:
```{r}
# flip the order of the second and third words
sentences %>%
str_replace("([^ ]+) ([^ ]+) ([^ ]+)", "\\1 \\3 \\2") %>%
head(5)
```
## Splitting
- Split a string up into pieces:
```{r}
sentences %>%
head(5) %>%
str_split(" ")
```
----
- Use `simplify = TRUE` to return a matrix:
```{r}
sentences %>%
head(5) %>%
str_split(" ", simplify = TRUE)
```
# More regular expressions
## Character classes
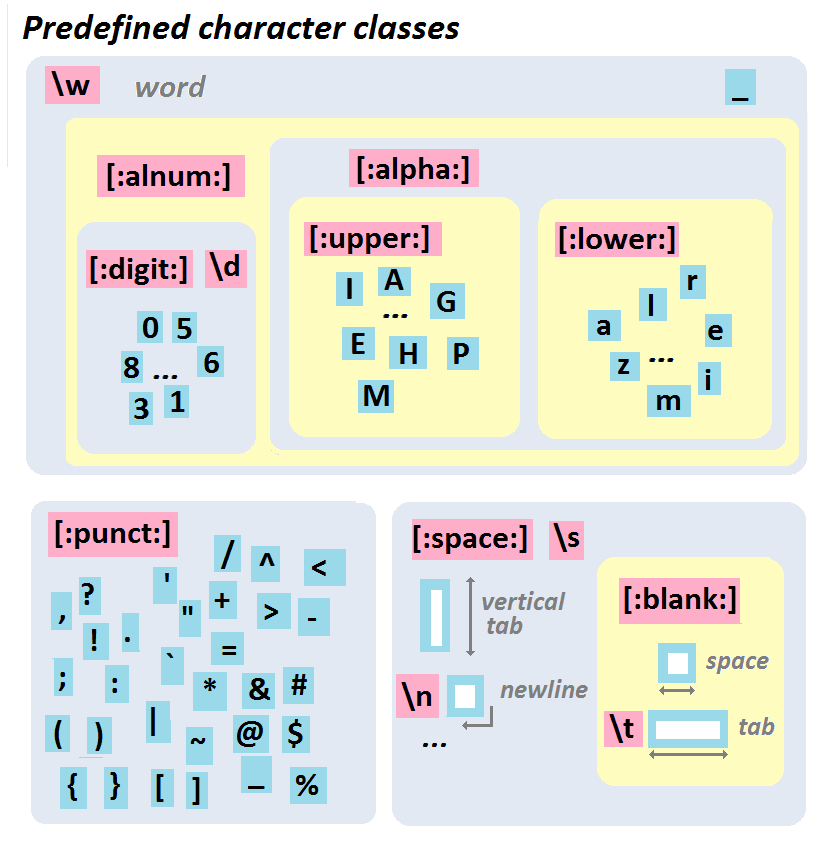
- A number of built-in convenience classes of characters:
- `.`: Any character except new line `\n`.
- `\s`: White space.
- `\S`: Not white space.
- `\d`: Digit (0-9).
- `\D`: Not digit.
- `\w`: Word (A-Z, a-z, 0-9, or _).
- `\W`: Not word.
- Example: How to match a telephone number with the form (###) ###-####?
```{r, error=TRUE}
# This produces error. Why?
text = c("apple", "(219) 733-8965", "(329) 293-8753")
str_detect(text, "(\d\d\d) \d\d\d-\d\d\d\d")
```
```{r}
# This doesn't give the answer we want. Why?
text = c("apple", "(219) 733-8965", "(329) 293-8753")
str_detect(text, "(\\d\\d\\d) \\d\\d\\d-\\d\\d\\d\\d")
# This should yield the desired answer
str_detect(text, "\\(\\d\\d\\d\\) \\d\\d\\d-\\d\\d\\d\\d")
```
## Lists and ranges
- Lists and ranges:
- `[abc]`: List (a or b or c)
- `[^abc]`: Excluded list (not a or b or c)
- `[a-q]`: Range lower case letter from a to q
- `[A-Q]`: Range upper case letter from A to Q
- `[0-7]`: Digit from 0 to 7
```{r}
text = c("apple", "(219) 733-8965", "(329) 293-8753")
str_replace_all(text, "[aeiou]", "") # strip all vowels
str_replace_all(text, "[13579]", "*")
str_replace_all(text, "[1-5a-ep]", "*")
```
# Teaser: how to validate email address using RegEx
# Cheat sheet
[RStudio cheat sheet](https://raw.githubusercontent.com/rstudio/cheatsheets/main/strings.pdf) is extremely helpful.