---
title: "Course Introduction"
subtitle: "Biostat 203B"
author: "Dr. Hua Zhou @ UCLA"
date: "`r format(Sys.time(), '%d %B, %Y')`"
format:
html:
theme: cosmo
number-sections: true
toc: true
toc-depth: 4
toc-location: left
code-fold: false
bibliography: "../bib-HZ.bib"
csl: "../apa.csl"
---
## Statistics and data science
- Statistics, the science of *data analysis*, is the applied mathematics in the 21st century.
- Data is increasing in [volume, velocity, and variety](http://www.forbes.com/sites/oreillymedia/2012/01/19/volume-velocity-variety-what-you-need-to-know-about-big-data/).
- My favorite definition of a *data scientist*:
> A data scientist is someone who is better at statistics than any software engineer and better at software engineering than any statistician.
``` {shortcodes=false}
{{< tweet user="josh_wills" id="198093512149958656" >}}
```
## Big data in 1990s
@Huber94HugeData; @Huber96MassiveData
| Data Size | Bytes | Storage Mode |
|-----------|----------------|----------------------------|
| tiny | $10^2$ | piece of paper |
| small | $10^4$ | a few pieces of paper |
| medium | $10^6$ (MB) | a floppy disk |
| large | $10^8$ | hard disk |
| huge | $10^9$ (GB) | hard disk(s) |
| massive | $10^{12}$ (TB) | hard disk(s); RAID storage |
## Big data in 21st centry
4V's of big data:
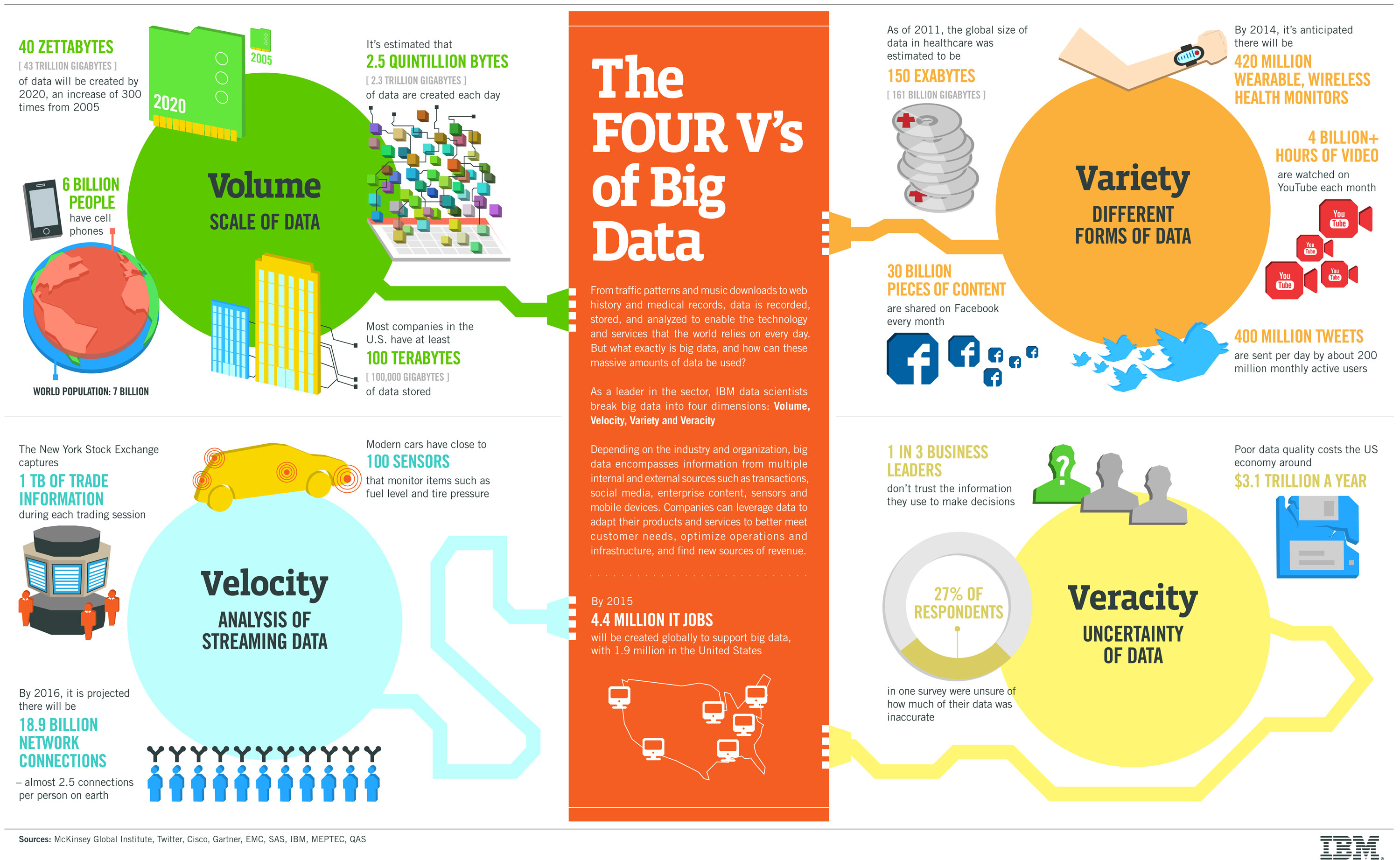
Source: [IBM](http://www.ibmbigdatahub.com/infographic/four-vs-big-data).
## Who are hiring data scientists?
Following tables are based on a survey of 403 students who earned a master's degree in statistics, biostatistics, or a related field (actuarial science, data science, informatics, math with stats focus) during the 2019--2020 academic year.
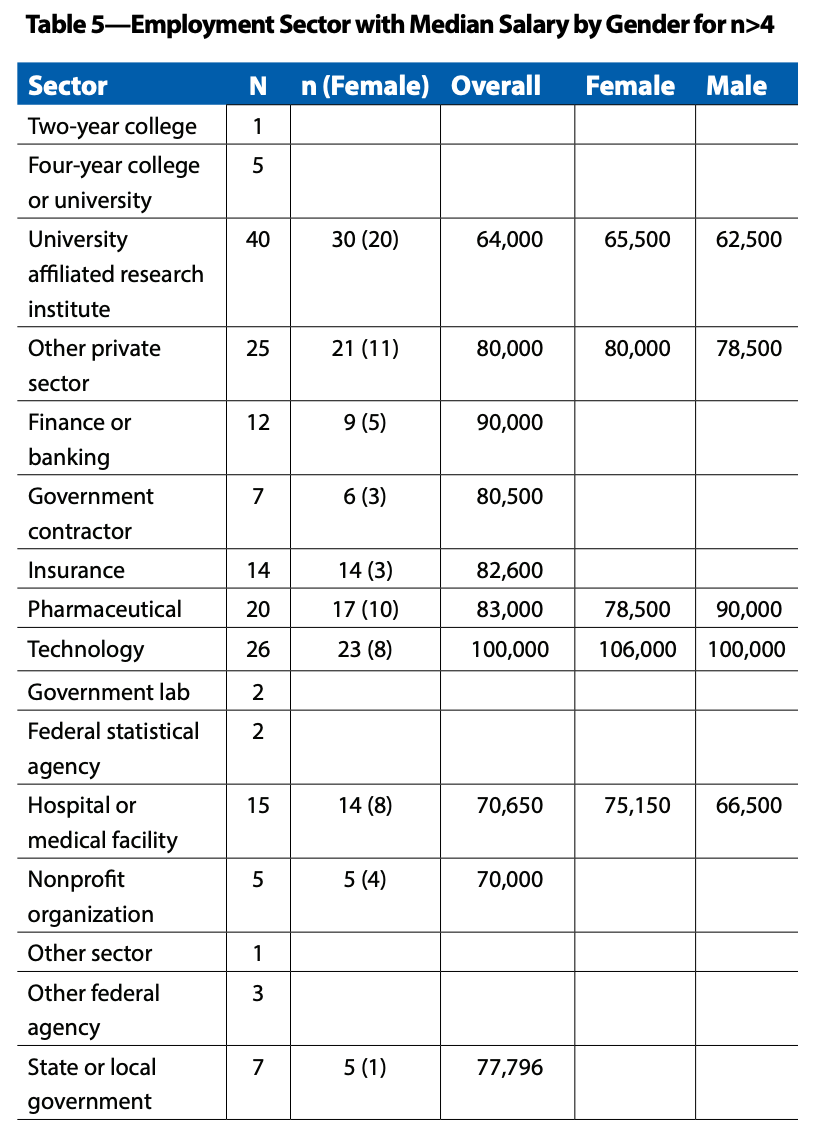
Source: [AmStat News (2021 Nov)](https://magazine.amstat.org/wp-content/uploads/2021/11/AmstatNewsNov2021-updated.pdf).
> there were more than 109 unique---although similar---job titles. The most common were data scientist (20), biostatistician (18), data analyst (9), biostatistician I (7), and statistician (5).
## A typical data scientist on [LinkedIn](http://linkedin.com)
A position posted by Genetech.
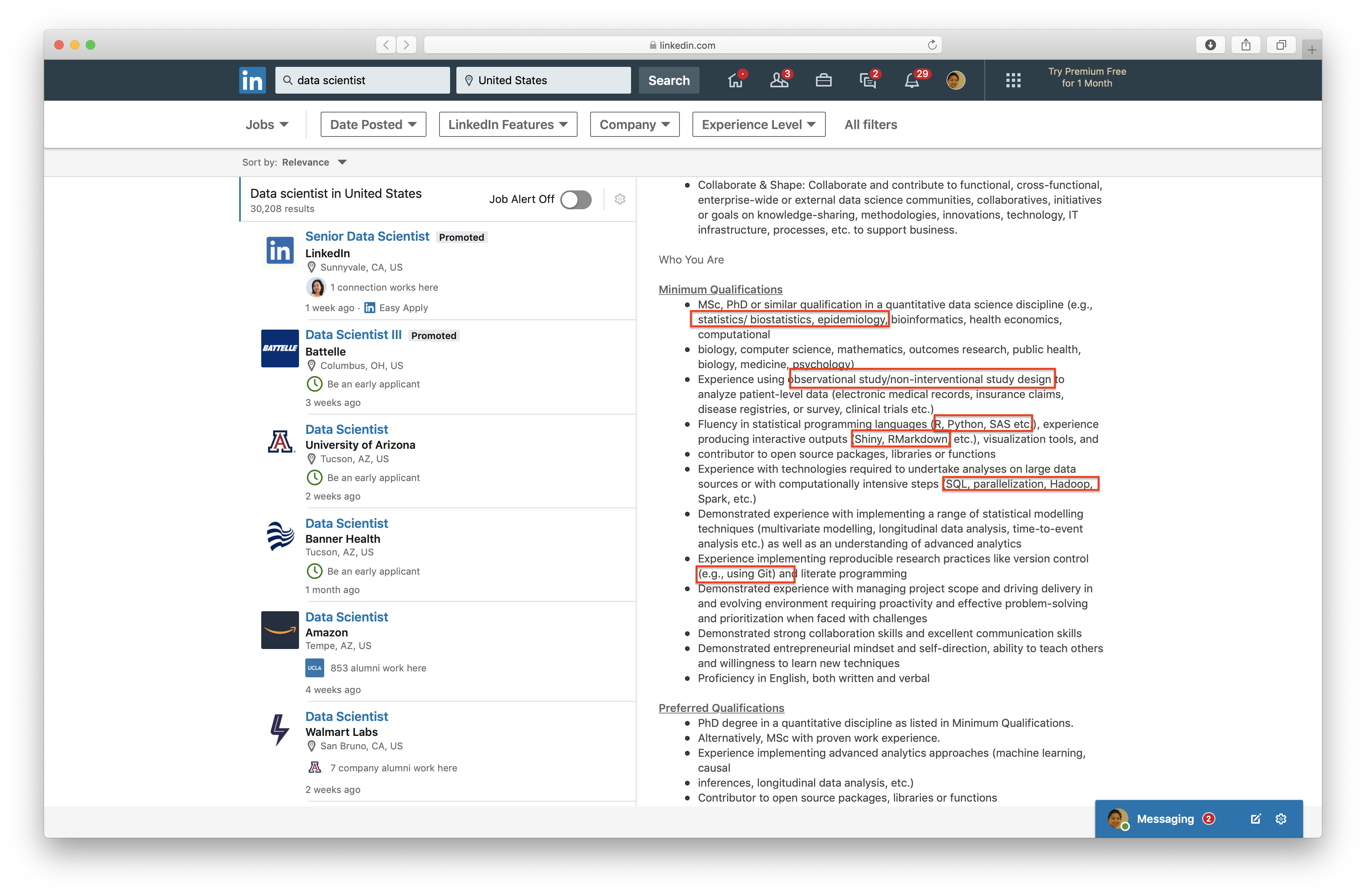
## Course description
- This course introduces some computing skills and software tools for handling potentially big public health data in a reproducible way.
- This is _not_ a machine learning course.
- Read [syllabus](https://ucla-biostat-203b.github.io/2023winter/syllabus/syllabus.html) and [schedule](https://ucla-biostat-203b.github.io/2023winter/schedule/schedule.html) for a tentative list of topics and course logistics.
## Why R?
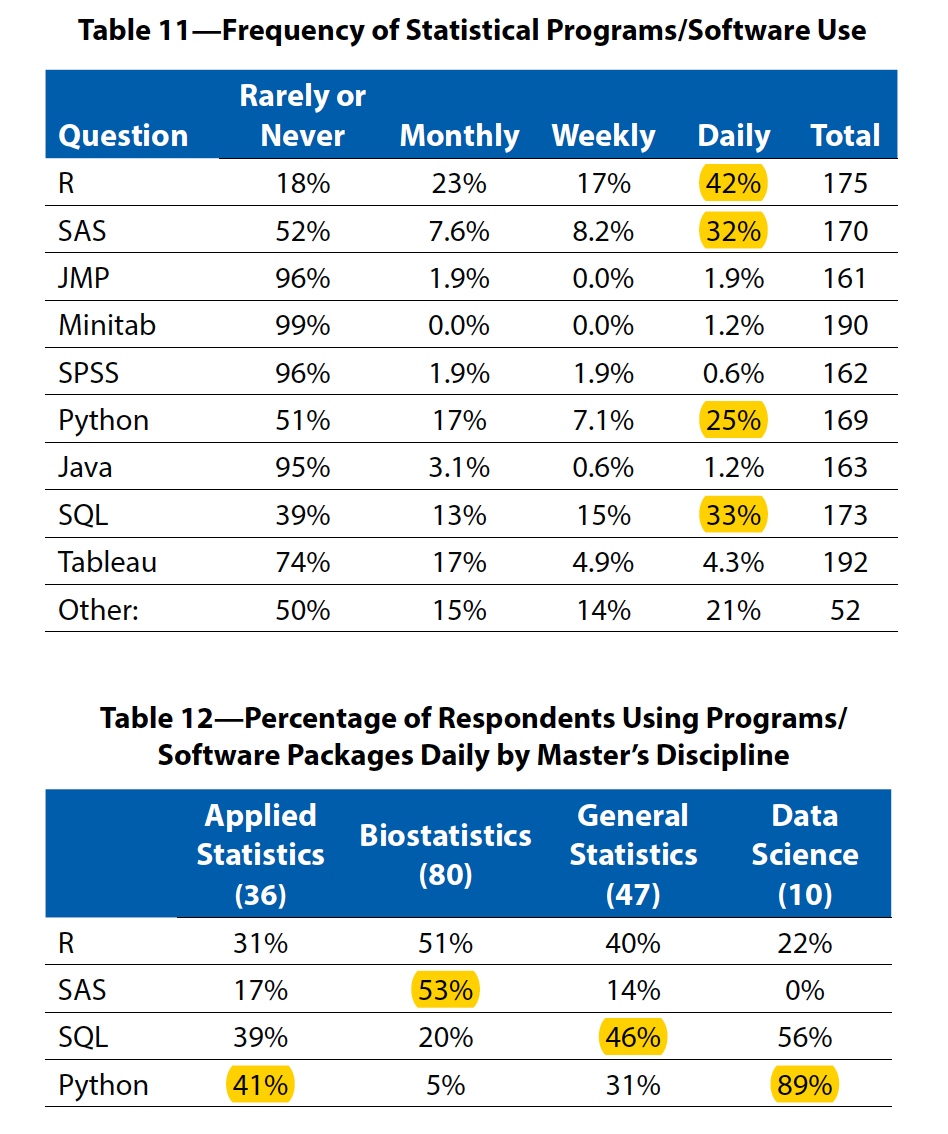
If time permits, I'll add some Python code in the lectures.
## What I expect from you
- You are curious and are excited about "figuring stuff out".
- You are proficient in coding and debugging (or are ready to work to get there).
- You are willing to ask questions.
## What you can expect from me
- I value your learning experience and process.
- I'm flexible with respect to the topics we cover.
- I'm happy to share my professional connections.
- I'll try my best to be responsive in class, in office hours, and on Slack.
## More (free) UCLA resources for learning data science
- IDRE workshops:
- QCBio workshops:
## References