---
title: Iterative Methods for Solving Linear Equations
subtitle: Biostat/Biomath M257
author: Dr. Hua Zhou @ UCLA
date: today
format:
html:
theme: cosmo
embed-resources: true
number-sections: true
toc: true
toc-depth: 4
toc-location: left
code-fold: false
jupyter:
jupytext:
formats: 'ipynb,qmd'
text_representation:
extension: .qmd
format_name: quarto
format_version: '1.0'
jupytext_version: 1.14.5
kernelspec:
display_name: Julia 1.8.5
language: julia
name: julia-1.8
---
System information (for reproducibility):
```{julia}
versioninfo()
```
Load packages:
```{julia}
using Pkg
Pkg.activate(pwd())
Pkg.instantiate()
Pkg.status()
```
## Introduction
So far we have considered direct methods for solving linear equations.
* **Direct methods** (flops fixed _a priori_) vs **iterative methods**:
- Direct method (GE/LU, Cholesky, QR, SVD): good for dense, small to moderate sized $\mathbf{A}$
- Iterative methods (Jacobi, Gauss-Seidal, SOR, conjugate-gradient, GMRES): good for large, sparse, structured linear system, parallel computing, warm start
## PageRank problem
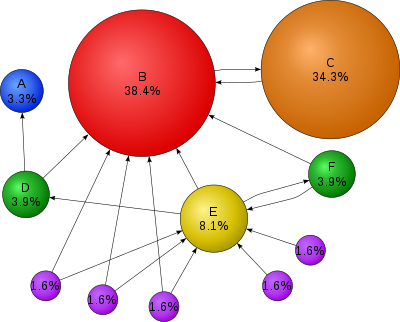 * $\mathbf{A} \in \{0,1\}^{n \times n}$ the connectivity matrix of webpages with entries
$$
a_{ij} = \begin{cases}
1 & \text{if page $i$ links to page $j$} \\
0 & \text{otherwise}
\end{cases}.
$$
$n \approx 10^9$ in May 2017.
* $r_i = \sum_j a_{ij}$ is the *out-degree* of page $i$.
* [Larry Page](https://en.wikipedia.org/wiki/PageRank) imagines a random surfer wandering on internet according to following rules:
- From a page $i$ with $r_i>0$
* with probability $p$, (s)he randomly chooses a link on page $i$ (uniformly) and follows that link to the next page
* with probability $1-p$, (s)he randomly chooses one page from the set of all $n$ pages (uniformly) and proceeds to that page
- From a page $i$ with $r_i=0$ (a dangling page), (s)he randomly chooses one page from the set of all $n$ pages (uniformly) and proceeds to that page
The process defines a Markov chain on the space of $n$ pages. Stationary distribution of this Markov chain gives the ranks (probabilities) of each page.
* Stationary distribution is the top left eigenvector of the transition matrix $\mathbf{P}$ corresponding to eigenvalue 1. Equivalently it can be cast as a linear equation
$$
(\mathbf{I} - \mathbf{P}^T) \mathbf{x} = \mathbf{0}.
$$
* Gene Golub: Largest matrix computation in world.
* GE/LU will take $2 \times (10^9)^3/3/10^{12} \approx 6.66 \times 10^{14}$ seconds $\approx 20$ million years on a tera-flop supercomputer!
* Iterative methods come to the rescue.
## Jacobi method
* $\mathbf{A} \in \{0,1\}^{n \times n}$ the connectivity matrix of webpages with entries
$$
a_{ij} = \begin{cases}
1 & \text{if page $i$ links to page $j$} \\
0 & \text{otherwise}
\end{cases}.
$$
$n \approx 10^9$ in May 2017.
* $r_i = \sum_j a_{ij}$ is the *out-degree* of page $i$.
* [Larry Page](https://en.wikipedia.org/wiki/PageRank) imagines a random surfer wandering on internet according to following rules:
- From a page $i$ with $r_i>0$
* with probability $p$, (s)he randomly chooses a link on page $i$ (uniformly) and follows that link to the next page
* with probability $1-p$, (s)he randomly chooses one page from the set of all $n$ pages (uniformly) and proceeds to that page
- From a page $i$ with $r_i=0$ (a dangling page), (s)he randomly chooses one page from the set of all $n$ pages (uniformly) and proceeds to that page
The process defines a Markov chain on the space of $n$ pages. Stationary distribution of this Markov chain gives the ranks (probabilities) of each page.
* Stationary distribution is the top left eigenvector of the transition matrix $\mathbf{P}$ corresponding to eigenvalue 1. Equivalently it can be cast as a linear equation
$$
(\mathbf{I} - \mathbf{P}^T) \mathbf{x} = \mathbf{0}.
$$
* Gene Golub: Largest matrix computation in world.
* GE/LU will take $2 \times (10^9)^3/3/10^{12} \approx 6.66 \times 10^{14}$ seconds $\approx 20$ million years on a tera-flop supercomputer!
* Iterative methods come to the rescue.
## Jacobi method
 Solve $\mathbf{A} \mathbf{x} = \mathbf{b}$.
* Jacobi iteration:
$$
x_i^{(t+1)} = \frac{b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)}}{a_{ii}}.
$$
* With splitting: $\mathbf{A} = \mathbf{L} + \mathbf{D} + \mathbf{U}$, Jacobi iteration can be written as
$$
\mathbf{D} \mathbf{x}^{(t+1)} = - (\mathbf{L} + \mathbf{U}) \mathbf{x}^{(t)} + \mathbf{b},
$$
i.e.,
$$
\mathbf{x}^{(t+1)} = - \mathbf{D}^{-1} (\mathbf{L} + \mathbf{U}) \mathbf{x}^{(t)} + \mathbf{D}^{-1} \mathbf{b} = - \mathbf{D}^{-1} \mathbf{A} \mathbf{x}^{(t)} + \mathbf{x}^{(t)} + \mathbf{D}^{-1} \mathbf{b}.
$$
* One round costs $2n^2$ flops with an **unstructured** $\mathbf{A}$. Gain over GE/LU if converges in $o(n)$ iterations. Saving is huge for **sparse** or **structured** $\mathbf{A}$. By structured, we mean the matrix-vector multiplication $\mathbf{A} \mathbf{v}$ is fast ($O(n)$ or $O(n \log n)$).
## Gauss-Seidel method
Solve $\mathbf{A} \mathbf{x} = \mathbf{b}$.
* Jacobi iteration:
$$
x_i^{(t+1)} = \frac{b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)}}{a_{ii}}.
$$
* With splitting: $\mathbf{A} = \mathbf{L} + \mathbf{D} + \mathbf{U}$, Jacobi iteration can be written as
$$
\mathbf{D} \mathbf{x}^{(t+1)} = - (\mathbf{L} + \mathbf{U}) \mathbf{x}^{(t)} + \mathbf{b},
$$
i.e.,
$$
\mathbf{x}^{(t+1)} = - \mathbf{D}^{-1} (\mathbf{L} + \mathbf{U}) \mathbf{x}^{(t)} + \mathbf{D}^{-1} \mathbf{b} = - \mathbf{D}^{-1} \mathbf{A} \mathbf{x}^{(t)} + \mathbf{x}^{(t)} + \mathbf{D}^{-1} \mathbf{b}.
$$
* One round costs $2n^2$ flops with an **unstructured** $\mathbf{A}$. Gain over GE/LU if converges in $o(n)$ iterations. Saving is huge for **sparse** or **structured** $\mathbf{A}$. By structured, we mean the matrix-vector multiplication $\mathbf{A} \mathbf{v}$ is fast ($O(n)$ or $O(n \log n)$).
## Gauss-Seidel method

 * Gauss-Seidel (GS) iteration:
$$
x_i^{(t+1)} = \frac{b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t+1)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)}}{a_{ii}}.
$$
* With splitting, $(\mathbf{D} + \mathbf{L}) \mathbf{x}^{(t+1)} = - \mathbf{U} \mathbf{x}^{(t)} + \mathbf{b}$, i.e.,
$$
\mathbf{x}^{(t+1)} = - (\mathbf{D} + \mathbf{L})^{-1} \mathbf{U} \mathbf{x}^{(t)} + (\mathbf{D} + \mathbf{L})^{-1} \mathbf{b}.
$$
* GS converges for any $\mathbf{x}^{(0)}$ for symmetric and pd $\mathbf{A}$.
* Convergence rate of Gauss-Seidel is the spectral radius of the $(\mathbf{D} + \mathbf{L})^{-1} \mathbf{U}$.
## Successive over-relaxation (SOR)
* SOR:
$$
x_i^{(t+1)} = \omega \left( b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t+1)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)} \right) / a_{ii} + (1-\omega) x_i^{(t)},
$$
i.e.,
$$
\mathbf{x}^{(t+1)} = (\mathbf{D} + \omega \mathbf{L})^{-1} [(1-\omega) \mathbf{D} - \omega \mathbf{U}] \mathbf{x}^{(t)} + (\mathbf{D} + \omega \mathbf{L})^{-1} (\mathbf{D} + \mathbf{L})^{-1} \omega \mathbf{b}.
$$
* Need to pick $\omega \in [0,1]$ beforehand, with the goal of improving convergence rate.
## Conjugate gradient method
* **Conjugate gradient and its variants are the top-notch iterative methods for solving huge, structured linear systems.**
* A UCLA invention! Hestenes and Stiefel in 60s.
* Solving $\mathbf{A} \mathbf{x} = \mathbf{b}$ is equivalent to minimizing the quadratic function $\frac{1}{2} \mathbf{x}^T \mathbf{A} \mathbf{x} - \mathbf{b}^T \mathbf{x}$.
[Kershaw's results](http://www.sciencedirect.com/science/article/pii/0021999178900980?via%3Dihub) for a fusion problem.
| Method | Number of Iterations |
|----------------------------------------|----------------------|
| Gauss Seidel | 208,000 |
| Block SOR methods | 765 |
| Incomplete Cholesky conjugate gradient | 25 |
## MatrixDepot.jl
MatrixDepot.jl is an extensive collection of test matrices in Julia. After installation, we can check available test matrices by
```{julia}
using MatrixDepot
mdinfo()
```
```{julia}
# List matrices that are positive definite and sparse:
mdlist(:symmetric & :posdef & :sparse)
```
```{julia}
# Get help on Poisson matrix
mdinfo("poisson")
```
```{julia}
# Generate a Poisson matrix of dimension n=10
A = matrixdepot("poisson", 10)
```
```{julia}
using UnicodePlots
spy(A)
```
```{julia}
# Get help on Wathen matrix
mdinfo("wathen")
```
```{julia}
# Generate a Wathen matrix of dimension n=5
A = matrixdepot("wathen", 5)
```
```{julia}
spy(A)
```
## Numerical examples
The [`IterativeSolvers.jl`](https://github.com/JuliaMath/IterativeSolvers.jl) package implements most commonly used iterative solvers.
### Generate test matrix
```{julia}
using BenchmarkTools, IterativeSolvers, LinearAlgebra, MatrixDepot, Random
Random.seed!(280)
n = 100
# Poisson matrix of dimension n^2=10000, pd and sparse
A = matrixdepot("poisson", n)
@show typeof(A)
# dense matrix representation of A
Afull = convert(Matrix, A)
@show typeof(Afull)
# sparsity level
count(!iszero, A) / length(A)
```
```{julia}
spy(A)
```
```{julia}
# storage difference
Base.summarysize(A), Base.summarysize(Afull)
```
### Matrix-vector muliplication
```{julia}
# randomly generated vector of length n^2
b = randn(n^2)
# dense matrix-vector multiplication
@benchmark $Afull * $b
```
```{julia}
# sparse matrix-vector multiplication
@benchmark $A * $b
```
### Dense solve via Cholesky
```{julia}
# record the Cholesky solution
xchol = cholesky(Afull) \ b;
```
```{julia}
# dense solve via Cholesky
@benchmark cholesky($Afull) \ $b
```
### Jacobi solver
It seems that Jacobi solver doesn't give the correct answer.
```{julia}
xjacobi = jacobi(A, b)
@show norm(xjacobi - xchol)
```
Reading [documentation](https://juliamath.github.io/IterativeSolvers.jl/dev/linear_systems/stationary/#Jacobi-1) we found that the default value of `maxiter` is 10. A couple trial runs shows that 30000 Jacobi iterations are enough to get an accurate solution.
```{julia}
xjacobi = jacobi(A, b, maxiter = 30000)
@show norm(xjacobi - xchol)
```
```{julia}
@benchmark jacobi($A, $b, maxiter = 30000)
```
### Gauss-Seidal
```{julia}
# Gauss-Seidel solution is fairly close to Cholesky solution after 15000 iters
xgs = gauss_seidel(A, b, maxiter = 15000)
@show norm(xgs - xchol)
```
```{julia}
@benchmark gauss_seidel($A, $b, maxiter = 15000)
```
### SOR
```{julia}
# symmetric SOR with ω=0.75
xsor = ssor(A, b, 0.75, maxiter = 10000)
@show norm(xsor - xchol)
```
```{julia}
@benchmark sor($A, $b, 0.75, maxiter = 10000)
```
### Conjugate Gradient (preview of next lecture)
```{julia}
# conjugate gradient
xcg = cg(A, b)
@show norm(xcg - xchol)
```
```{julia}
@benchmark cg($A, $b)
```
* Gauss-Seidel (GS) iteration:
$$
x_i^{(t+1)} = \frac{b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t+1)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)}}{a_{ii}}.
$$
* With splitting, $(\mathbf{D} + \mathbf{L}) \mathbf{x}^{(t+1)} = - \mathbf{U} \mathbf{x}^{(t)} + \mathbf{b}$, i.e.,
$$
\mathbf{x}^{(t+1)} = - (\mathbf{D} + \mathbf{L})^{-1} \mathbf{U} \mathbf{x}^{(t)} + (\mathbf{D} + \mathbf{L})^{-1} \mathbf{b}.
$$
* GS converges for any $\mathbf{x}^{(0)}$ for symmetric and pd $\mathbf{A}$.
* Convergence rate of Gauss-Seidel is the spectral radius of the $(\mathbf{D} + \mathbf{L})^{-1} \mathbf{U}$.
## Successive over-relaxation (SOR)
* SOR:
$$
x_i^{(t+1)} = \omega \left( b_i - \sum_{j=1}^{i-1} a_{ij} x_j^{(t+1)} - \sum_{j=i+1}^n a_{ij} x_j^{(t)} \right) / a_{ii} + (1-\omega) x_i^{(t)},
$$
i.e.,
$$
\mathbf{x}^{(t+1)} = (\mathbf{D} + \omega \mathbf{L})^{-1} [(1-\omega) \mathbf{D} - \omega \mathbf{U}] \mathbf{x}^{(t)} + (\mathbf{D} + \omega \mathbf{L})^{-1} (\mathbf{D} + \mathbf{L})^{-1} \omega \mathbf{b}.
$$
* Need to pick $\omega \in [0,1]$ beforehand, with the goal of improving convergence rate.
## Conjugate gradient method
* **Conjugate gradient and its variants are the top-notch iterative methods for solving huge, structured linear systems.**
* A UCLA invention! Hestenes and Stiefel in 60s.
* Solving $\mathbf{A} \mathbf{x} = \mathbf{b}$ is equivalent to minimizing the quadratic function $\frac{1}{2} \mathbf{x}^T \mathbf{A} \mathbf{x} - \mathbf{b}^T \mathbf{x}$.
[Kershaw's results](http://www.sciencedirect.com/science/article/pii/0021999178900980?via%3Dihub) for a fusion problem.
| Method | Number of Iterations |
|----------------------------------------|----------------------|
| Gauss Seidel | 208,000 |
| Block SOR methods | 765 |
| Incomplete Cholesky conjugate gradient | 25 |
## MatrixDepot.jl
MatrixDepot.jl is an extensive collection of test matrices in Julia. After installation, we can check available test matrices by
```{julia}
using MatrixDepot
mdinfo()
```
```{julia}
# List matrices that are positive definite and sparse:
mdlist(:symmetric & :posdef & :sparse)
```
```{julia}
# Get help on Poisson matrix
mdinfo("poisson")
```
```{julia}
# Generate a Poisson matrix of dimension n=10
A = matrixdepot("poisson", 10)
```
```{julia}
using UnicodePlots
spy(A)
```
```{julia}
# Get help on Wathen matrix
mdinfo("wathen")
```
```{julia}
# Generate a Wathen matrix of dimension n=5
A = matrixdepot("wathen", 5)
```
```{julia}
spy(A)
```
## Numerical examples
The [`IterativeSolvers.jl`](https://github.com/JuliaMath/IterativeSolvers.jl) package implements most commonly used iterative solvers.
### Generate test matrix
```{julia}
using BenchmarkTools, IterativeSolvers, LinearAlgebra, MatrixDepot, Random
Random.seed!(280)
n = 100
# Poisson matrix of dimension n^2=10000, pd and sparse
A = matrixdepot("poisson", n)
@show typeof(A)
# dense matrix representation of A
Afull = convert(Matrix, A)
@show typeof(Afull)
# sparsity level
count(!iszero, A) / length(A)
```
```{julia}
spy(A)
```
```{julia}
# storage difference
Base.summarysize(A), Base.summarysize(Afull)
```
### Matrix-vector muliplication
```{julia}
# randomly generated vector of length n^2
b = randn(n^2)
# dense matrix-vector multiplication
@benchmark $Afull * $b
```
```{julia}
# sparse matrix-vector multiplication
@benchmark $A * $b
```
### Dense solve via Cholesky
```{julia}
# record the Cholesky solution
xchol = cholesky(Afull) \ b;
```
```{julia}
# dense solve via Cholesky
@benchmark cholesky($Afull) \ $b
```
### Jacobi solver
It seems that Jacobi solver doesn't give the correct answer.
```{julia}
xjacobi = jacobi(A, b)
@show norm(xjacobi - xchol)
```
Reading [documentation](https://juliamath.github.io/IterativeSolvers.jl/dev/linear_systems/stationary/#Jacobi-1) we found that the default value of `maxiter` is 10. A couple trial runs shows that 30000 Jacobi iterations are enough to get an accurate solution.
```{julia}
xjacobi = jacobi(A, b, maxiter = 30000)
@show norm(xjacobi - xchol)
```
```{julia}
@benchmark jacobi($A, $b, maxiter = 30000)
```
### Gauss-Seidal
```{julia}
# Gauss-Seidel solution is fairly close to Cholesky solution after 15000 iters
xgs = gauss_seidel(A, b, maxiter = 15000)
@show norm(xgs - xchol)
```
```{julia}
@benchmark gauss_seidel($A, $b, maxiter = 15000)
```
### SOR
```{julia}
# symmetric SOR with ω=0.75
xsor = ssor(A, b, 0.75, maxiter = 10000)
@show norm(xsor - xchol)
```
```{julia}
@benchmark sor($A, $b, 0.75, maxiter = 10000)
```
### Conjugate Gradient (preview of next lecture)
```{julia}
# conjugate gradient
xcg = cg(A, b)
@show norm(xcg - xchol)
```
```{julia}
@benchmark cg($A, $b)
```