{
"metadata": {
"name": "",
"signature": "sha256:8a53cdb3b92307574945fc2293ec7b02b495e5af3c9ddd1970e26332af25f1b3"
},
"nbformat": 3,
"nbformat_minor": 0,
"worksheets": [
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[](http://cse.illinois.edu/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# C & Fortran Interfacing with Python\n",
"\n",
"## Contents\n",
"- [Python as Duct Tape](#motivation)\n",
"- [Fortran](#fortran)\n",
" - [A Brief Introduction](#intro-f)\n",
" - [F2Py](#f2py)\n",
"- [C](#c)\n",
" - [A Brief Introduction](#intro-c)\n",
" - [Using C with Python](#using-c)\n",
" - [Weave](#weave)\n",
" - [Cython](#cython)\n",
"- [References](#refs)\n",
"- [Credits](#credits)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"\n",
"## Python as Duct Tape\n",
"\n",
"Python is considered to behave as an excellent adhesive between different programming languages. Most of what we have seen along those lines thus far involves invoking shell programs indirectly, perhaps via IPython's `!` notation or by using `sys` or `os.popen`. However, many performance-critical modules in Python, such as NumPy, have substantial components written in C or other high-performance languages. We'll examine several ways to interface or incorporate other languages\u2014particularly C and Fortran\u2014into your Python program in this lesson."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from __future__ import division\n",
"\n",
"import numpy as np\n",
"import scipy as sp\n",
"import matplotlib as mpl\n",
"import matplotlib.pyplot as plt"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import sys\n",
"print(sys.prefix)\n",
"\n",
"!echo $PYTHONPATH"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Motivation**\n",
"\n",
"As is probably now clear to you, Python is a flexible and easy-to-use language. The programmer time required to program a new model or calculation is typically quite short.\n",
"\n",
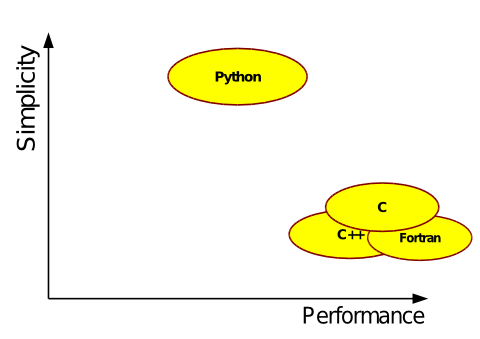
"However, this reduction in human time, comes at the expense of increasing computation time, especially when we are talking about calculations which involve iterating over large arrays. Interpreted languages (MATLAB, Python, Perl, Ruby, etc.) are thus categorically slower than low-level compiled languages (C, C++, Fortran, etc.). On the other hand, writing lengthy programs in C and FORTRAN is a cumbersome task. This tradeoff is one motivation to code the expensive chunks in C or FORTRAN and glue the bigger picture with Python.\n",
"\n",
"\n",
"\n",
"In real terms, the range in relative performance on a set of standard benchmarks can be quantified thus (where 1.0 is the performance of C):\n",
"\n",
"[](http://julialang.org/benchmarks/)\n",
"\n",
"Python doesn't comport itself poorly among these peers, but it's still not in the same performance league as the heavy hitters.\n",
"\n",
"Another major reason you may need to use Fortran or C with Python is access to legacy code: code that is already performing to specifications that would be too expensive, difficult, or loss-incurring to port to Python."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Fortran"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### A Brief Introduction to Fortran\n",
"\n",
"[Fortran](https://en.wikipedia.org/wiki/Fortran) (**For**mula **Tran**slation) was introduced in 1954 for numeric and scientific computing. Fortran is compiled to machine code for the purpose of speed, and it serves as the benchmark for high-performance computing even today. Despite ongoing criticisms, it has managed to survive and adapt for nearly sixty years. Fortran still exists and dominates HPC due to both its computational performance and *software inertia*\u2014the enormously large body of legacy code written in Fortran.\n",
"\n",
"Let's look at an example FORTRAN function to get a better understanding of how it works!\n",
"\n",
"_Note: This lesson's aim is not to verse you well in Fortran, so we'll neglect nitty-gritty details. We will introduce just enough to address common needs and demonstrates interfacing with Python._"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file circle.f\n",
"PROGRAM CIRCLE\n",
"REAL R, AREA\n",
"! This program reads a real number r and prints\n",
"! the area of a circle with radius r.\n",
"WRITE (*,*) 'Enter radius, r = '\n",
"READ (*,*) R\n",
"AREA = 3.14159*R*R\n",
"WRITE (*,*) 'Area, A = ', AREA\n",
"STOP\n",
"END"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The resulting compilation and execution:\n",
"\n",
" $ gfortran -ffree-form -o circle circle.f\n",
" $ ./circle\n",
" Enter radius, r = \n",
" 1\n",
" Area, A = 3.14159012 \n",
"\n",
"Anyway, that's a little ugly, isn't it? Originally, all Fortran programs had to be written in upper-case letters. Most people now write lower-case. You are free to mix letter case, but note that Fortran is not case-sensitive: `X` and `x` are the same variable.\n",
"\n",
"If you wish to use $\\pi$ as a constant, you can do it using the `parameter` statement:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file circle.f\n",
"program circle\n",
"real r, area, pi\n",
"parameter (pi = 3.14159)\n",
"! This program reads a real number r and prints\n",
"! the area of a circle with radius r.\n",
"write (*,*) 'Enter radius, r = '\n",
"read (*,*) R\n",
"area = 3.14159*r*r\n",
"write (*,*) 'Area, A = ', area\n",
"stop\n",
"end"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Data Types\n",
"\n",
"Every variable _should_ be defined in a declaration. This establishes the type of the variable. The most common declarations are:\n",
"\n",
" integer list of variables\n",
" real list of variables\n",
" double precision list of variables\n",
" complex list of variables\n",
" logical list of variables\n",
" character list of variables\n",
"\n",
"Implicit typing can be turned on or off using `implicit [real]` or `implicit none`, and the latter in particular is often seen in the wild.\n",
"\n",
"- [FORTRAN77 Tutorial](http://web.stanford.edu/class/me200c/tutorial_77/10_arrays.html)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Arrays\n",
"\n",
"FORTRAN uses one dimensional arrays to correspond to vectors and 2D arrays to represent matrices."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 1D Arrays\n",
"\n",
" real a(20)\n",
"\n",
"declares an array of size 20. By convention, Fortran arrays are indexed from 1 (MATLAB follows this convention as well). Thus the first number in the array is denoted by a(1) and the last by a(20).\n",
"\n",
" integer i(10)\n",
" logical aa(0:1)\n",
" double precision x(100)\n",
"\n",
"This code segment stores the 10 first square numbers in the array sq:\n",
"\n",
" integer i, sq(10)\n",
" do 100 i = 1, 10\n",
" sq(i) = i**2\n",
" 100 continue\n",
" \n",
"A common bug in Fortran is that the program tries to access array elements that are out of bounds or undefined. This is the responsibility of the programmer, and the Fortran compiler will not detect any such bugs!\n",
"\n",
"_Note_: One tricky thing about reading Fortran code is that constructs may not mean what you think. For instance:\n",
"- `real*8 a` does not mean a vector `a` with eight components, but an eight-byte (C `double`) floating-point number `a`.\n",
"- `.le.` and other operators of this type mean less than or equal to, `<=`, etc."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### 2D Arrays\n",
"\n",
" real A(3,5)\n",
"\n",
"declares a 2D array of size 3x5. It is common to declare arrays of a larger size than what we use because in FORTRAN we cannot dynamically change the size of an array. In other words, arrays are *static*.\n",
"\n",
" real A(3,5)\n",
" integer i,j\n",
" ! We will only use the upper 3 by 3 part of this array.\n",
" do 20 j = 1, 3\n",
" do 10 i = 1, 3\n",
" a(i,j) = real(i)/real(j)\n",
" 10 continue\n",
" 20 continue\n",
"\n",
"Note also that, contrary to C and Python, Fortran arrays are _column-major_. The first index refers to the _row_, as is conventional in linear algebraic notation, but loops would need to be reversed relative to C (thus loop over rows before columns in Fortran for efficiency ([src](http://jblevins.org/log/efficient-code))). This becomes critical when passing data to and from Fortran."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"#### F2PY\n",
"\n",
"The [F2PY](http://docs.scipy.org/doc/numpy-dev/f2py/) program (now part of NumPy) offers the best of both worlds: it wraps existing Fortran code for use in Python, including providing reasonable documentation automatically. With F2PY, we can compile modules from Fortran code which can then be imported into Python directly.\n",
"\n",
"\n",
"\n",
"- [F2PY References](http://www.f2py.com/home/references)"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file hellofortran.f\n",
"! File hellofortran.f\n",
" subroutine hellofortran (n)\n",
" integer n\n",
" \n",
" do 100 i=0, n\n",
" print *, \"Fortran says hello\"\n",
"100 continue\n",
" end"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!f2py -c -m hellofortran hellofortran.f"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we write a Python script which uses the module"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file hello.py\n",
"import hellofortran\n",
"\n",
"hellofortran.hellofortran(5)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# run the script\n",
"!python hello.py"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*Vector input , scalar output *"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file dprod.f\n",
"\n",
" subroutine dprod(x, y, n)\n",
" \n",
" double precision x(n), y\n",
" y = 1.0\n",
" \n",
" do 100 i=1, n\n",
" y = y * x(i)\n",
"100 continue\n",
" end\n"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!rm -f dprod.pyf\n",
"!f2py -m dprod -h dprod.pyf dprod.f"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The f2py program generates a declaration file `dprod.pyf`"
]
},
{
"cell_type": "code",
"collapsed": true,
"input": [
"!cat dprod.pyf"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The module does not know what Fortran subroutine arguments is input and output, so we need to manually edit the module declaration files and mark output variables with intent(out) and input variable with intent(in):"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file dprod.pyf\n",
"python module dprod ! in \n",
" interface ! in :dprod\n",
" subroutine dprod(x,y,n) ! in :dprod:dprod.f\n",
" double precision dimension(n), intent(in) :: x\n",
" double precision, intent(out) :: y\n",
" integer, optional,check(len(x)>=n),depend(x),intent(in) :: n=len(x)\n",
" end subroutine dprod\n",
" end interface \n",
"end python module dprod"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!f2py -c dprod.pyf dprod.f #Compile the code which can be included in Python"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import dprod #Using the module in Python"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"help (dprod)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"dprod.dprod(np.arange(1,50))"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"np.prod(np.arange(1.0,50.0))"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Comparing the performance"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"xvec = np.random.rand(1000)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit dprod.dprod(xvec)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit xvec.prod()"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Example: Cumulative sum of an array\n",
"\n",
"The cumulative sum over data in an array is a loop-intensive algorithm and hence a good example to exploit the performance advantage in Fortran."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# pure Python \n",
"def py_dcumsum(a):\n",
" b = np.empty_like(a)\n",
" b[0] = a[0]\n",
" for n in range(1,len(a)):\n",
" b[n] = b[n-1]+a[n]\n",
" return b"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file dcumsum.f\n",
"c File dcumsum.f\n",
" subroutine dcumsum(a, b, n)\n",
" double precision a(n)\n",
" double precision b(n)\n",
" integer n\n",
"cf2py intent(in) :: a\n",
"cf2py intent(out) :: b\n",
"cf2py intent(hide) :: n\n",
"\n",
" b(1) = a(1)\n",
" do 100 i=2, n\n",
" b(i) = b(i-1) + a(i)\n",
"100 continue\n",
" end"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!f2py -c dcumsum.f -m dcumsum"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import dcumsum\n",
"\n",
"a = np.array([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0])"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"py_dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"dcumsum.dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"a = np.random.rand(10000)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit py_dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit dcumsum.dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## C\n",
"\n",
"Now we move on to a more intuitive\u2014or at least familiar\u2014language C. C is often called a _mid-level_ or _systems_ programming language. This is not a reflection on its lack of programming power but more a reflection on its capability to access the system's low level functions. It wins on the performance aspect and also on the not-as-ludicrously-obscure-as-Fortran aspect.\n",
"\n",
"Despite its increased ease of use as opposed to FORTRAN, it still requires quite a bit of detail with respect to data types, functions, data structures etc. Python still involves less human time than C does. So, we benefit from gluing C and Python together."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"#### A Brief Introduction to C\n",
"\n",
"##### Data Types\n",
"\n",
"- `int`\u2014integer.\n",
"- `float`\u2014floating point value: _i.e._, a number with a fractional part.\n",
"- `double`\u2014a double-precision floating point value.\n",
"- `char`\u2014a single character.\n",
"- `void`\u2014a valueless special-purpose type.\n",
"\n",
"##### Input/Output Functions\n",
"\n",
"- [`printf`](http://www.cplusplus.com/reference/cstdio/printf/)\u2014Output formatted string.\n",
"- [`scanf`](http://www.cplusplus.com/reference/cstdio/scanf/)\u2014Input stream (until Return pressed).\n",
"- [`getchar`](http://www.cplusplus.com/reference/cstdio/getchar/)\u2014Input single character.\n",
"\n",
"##### A Simple Program in C\n",
"(This program should be run at the command line; `getchar`-based input is not currently supported in the IPython notebook interface.)\n",
"\n",
"Salient features of this program include the `#include` statement, the `int` return type of the `main` function, and the use of `{` and `}` to delimit a block of code."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file test.c\n",
"#include \n",
"int main() {\n",
" printf( \"Happy Halloween! \\n\" );\n",
" getchar();\n",
" return 0;\n",
"}"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!gcc -o test test.c"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!./test"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Arrays\n",
" int some_array[5];\n",
"declares an array of five elements."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"###### Example: Array Summation\n",
"\n",
" int sum_values_of_array(int all_nums[]) {\n",
" int i, sum=0;\n",
" for(i = 0; i<5; i++)\n",
" sum = sum + all_nums[i];\n",
" return sum;\n",
" }"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"#### `ctypes`\n",
"\n",
"[`ctypes`](https://docs.python.org/3/library/ctypes.html) is a Python library for calling out to C libraries. It is not as automatic as F2PY, and we manually need to load the library and set properties such as the function argument and return types. On the other hand, we do not need to touch the C code at all."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import ctypes\n",
"ctypes.cdll.LoadLibrary(\"libc.so.6\")\n",
"libc = ctypes.CDLL(\"libc.so.6\")\n",
"libc.printf"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"print(libc.time(None)) "
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file functions.c\n",
"\n",
"#include \n",
"\n",
"void hello(int n);\n",
"\n",
"double dprod(double *x, int n);\n",
"\n",
"void dcumsum(double *a, double *b, int n);\n",
"\n",
"void\n",
"hello(int n)\n",
"{\n",
" int i;\n",
" \n",
" for (i = 0; i < n; i++)\n",
" {\n",
" printf(\"C says hello\\n\");\n",
" }\n",
"}\n",
"\n",
"\n",
"double \n",
"dprod(double *x, int n)\n",
"{\n",
" int i;\n",
" double y = 1.0;\n",
" \n",
" for (i = 0; i < n; i++)\n",
" {\n",
" y *= x[i];\n",
" }\n",
"\n",
" return y;\n",
"}\n",
"\n",
"void\n",
"dcumsum(double *a, double *b, int n)\n",
"{\n",
" int i;\n",
" \n",
" b[0] = a[0];\n",
" for (i = 1; i < n; i++)\n",
" {\n",
" b[i] = a[i] + b[i-1];\n",
" }\n",
"}"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Compiling the C code"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!gcc -c -Wall -O2 -Wall -ansi -pedantic -fPIC -o functions.o functions.c\n",
"!gcc -o libfunctions.so -shared functions.o"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!file libfunctions.so"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we need to write wrapper functions to access the C library: To load the library we use the ctypes package, which included in the Python standard library (with extensions from numpy for passing arrays to C). Then we manually set the types of the argument and return values (no automatic code inspection here!). "
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file functions.py\n",
"\n",
"import numpy\n",
"import ctypes\n",
"\n",
"_libfunctions = numpy.ctypeslib.load_library('libfunctions', '.')\n",
"\n",
"_libfunctions.hello.argtypes = [ctypes.c_int]\n",
"_libfunctions.hello.restype = ctypes.c_void_p\n",
"\n",
"_libfunctions.dprod.argtypes = [numpy.ctypeslib.ndpointer(dtype=numpy.float), ctypes.c_int]\n",
"_libfunctions.dprod.restype = ctypes.c_double\n",
"\n",
"_libfunctions.dcumsum.argtypes = [numpy.ctypeslib.ndpointer(dtype=numpy.float), numpy.ctypeslib.ndpointer(dtype=numpy.float), ctypes.c_int]\n",
"_libfunctions.dcumsum.restype = ctypes.c_void_p\n",
"\n",
"def hello(n):\n",
" return _libfunctions.hello(int(n))\n",
"\n",
"def dprod(x, n=None):\n",
" if n is None:\n",
" n = len(x)\n",
" x = numpy.asarray(x, dtype=numpy.float)\n",
" return _libfunctions.dprod(x, int(n))\n",
"\n",
"def dcumsum(a, n):\n",
" a = numpy.asarray(a, dtype=numpy.float)\n",
" b = numpy.empty(len(a), dtype=numpy.float)\n",
" _libfunctions.dcumsum(a, b, int(n))\n",
" return b"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file run_hello_c.py\n",
"\n",
"import functions\n",
"\n",
"functions.hello(3)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!python run_hello_c.py"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import functions"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"functions.dprod([1,2,3,4,5]) #product"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"a = np.random.rand(100000)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"res_c = functions.dcumsum(a, len(a)) "
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"res_fortran = dcumsum.dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"res_c - res_fortran"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"###### Timing"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit functions.dcumsum(a, len(a))"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit dcumsum.dcumsum(a)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"timeit a.cumsum()"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"#### Weave\n",
"\n",
"[Weave](http://docs.scipy.org/doc/scipy-0.14.0/reference/tutorial/weave.html) essentially does for C/C++ what F2PY does for Fortran: we can use data stored in NumPy `ndarray`s with C/C++ code for mission-critical performance. (For instance, C can unroll loops or recurse faster than Python.)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Example: Laplace Equation\n",
"\n",
"Consider solving the Laplace equation $\\nabla^2 u = 0$ over a square grid ([source](http://technicaldiscovery.blogspot.com/2011/06/speeding-up-python-numpy-cython-and.html)). The pure Python version follows:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from numpy import zeros\n",
"from scipy import weave\n",
"\n",
"dx = 0.1\n",
"dy = 0.1\n",
"dx2 = dx*dx\n",
"dy2 = dy*dy\n",
"\n",
"def py_update(u):\n",
" nx, ny = u.shape\n",
" for i in xrange(1,nx-1):\n",
" for j in xrange(1, ny-1):\n",
" u[i,j] = ((u[i+1, j] + u[i-1, j]) * dy2 +\n",
" (u[i, j+1] + u[i, j-1]) * dx2) / (2*(dx2+dy2))\n",
"\n",
"def calc(N, Niter=100, func=py_update, args=()):\n",
" u = zeros([N, N])\n",
" u[0] = 1\n",
" for i in range(Niter):\n",
" func(u,*args)\n",
" return u"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%timeit calc(100, 200, func=py_update)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Using `numpy`"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def num_update(u):\n",
" u[1:-1,1:-1] = ((u[2:,1:-1]+u[:-2,1:-1])*dy2 + \n",
" (u[1:-1,2:] + u[1:-1,:-2])*dx2) / (2*(dx2+dy2))"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%timeit calc(100, 200, func=num_update)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Using the `weave` module to implement C."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def weave_update(u):\n",
" code = \"\"\"\n",
" int i, j;\n",
" for (i=1; i\n",
"#### Cython\n",
"\n",
"\n",
"\n",
"[Cython](http://cython.org/) serves as another interface between Python and C. Strictly speaking, Cython is a static compiler for a superset of the Python language. From the [documentation](http://docs.cython.org/): \"The Cython language is a superset of the Python language that additionally supports calling C functions and declaring C types on variables and class attributes. This allows the compiler to generate very efficient C code from Cython code.\"\n",
"\n",
"Basically any Python code is valid Cython code, but Cython additionally imposes C data types (and manages them intelligently behind the scenes), as well as provides a basic superset of the language to manage this extensions (such as the keywords `cdef` and `cimport`). So you lose the flexibility of a dynamic interpreted language, but gain some performance and interoperability.\n",
"\n",
"- [Cython language reference](http://docs.cython.org/src/userguide/language_basics.html#language-basics)\n",
"\n",
"##### Using Cython\n",
"\n",
"Using Cython consists of the following steps:\n",
"\n",
"1. Composing a `.pyx` source file.\n",
"1. Running the Cython compiler to generate a C file.\n",
"1. Running a C compiler to generate a compiled library.\n",
"1. Running the Python interpreter and `import`ing the module."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%file factorial.pyx\n",
"def factorial(n):\n",
" return 1 if (n < 1) else n * factorial(n-1)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Hop over to a shell and take a look at the generated code in `factorial.c`. I dare you to untangle it.\n",
"\n",
"Given a `pyx` file, there are a few ways we can convert this to a C module using Cython. The first is to carry out the basic steps manually."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!cython factorial.pyx"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"#!gcc -shared -fPIC -o factorial.so factorial.c\n",
"!gcc -I /software/canopy-1.4.1/installer/appdata/canopy-1.4.1.1975.rh5-x86_64/include/python2.7/ -shared -fPIC -o factorial.so factorial.c"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import factorial\n",
"print(factorial.factorial(6))"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Another path to Cython is to use the built-in `cythonize` function. (This is preferred for large codes.) I had trouble getting this to work on the EWS installation of Python, however."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from distutils.core import setup\n",
"from Cython.Build import cythonize\n",
"\n",
"setup(\n",
" ext_modules=cythonize(\"factorial.pyx\"),\n",
")\n",
"# problem is clang \u00f1 gcc here (-fopenmp)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%tb"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"!python setup.py build_ext --inplace"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"When working with the IPython notebook environment, there is a convenient way of compiling and loading Cython code. Using the `%%cython` IPython magic, we can simply type the Cython code in a code cell and let IPython take care of the conversion to C code, compilation and loading of the function. To be able to use the `%%cython` magic in IPython, we first need to load the extension `cythonmagic`:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%load_ext cythonmagic"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"%%cython\n",
"cimport numpy\n",
"\n",
"def cy_dcumsum2(numpy.ndarray[numpy.float64_t, ndim=1] a, numpy.ndarray[numpy.float64_t, ndim=1] b):\n",
" cdef int i, n = len(a)\n",
" b[0] = a[0]\n",
" for i from 1 <= i < n:\n",
" b[i] = b[i-1] + a[i]\n",
" return b"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import numpy as np\n",
"\n",
"x = np.ones((32))\n",
"y = np.zeros(x.shape)\n",
"\n",
"cy_dcumsum2(x,y)\n",
"\n",
"print(y)"
],
"language": "python",
"metadata": {},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Okay, so as a refresher, Cython usage [boils down to](http://docs.cython.org/src/userguide/numpy_tutorial.html#your-cython-environment):\n",
"\n",
" $ cython mymodule.pyx\n",
" $ gcc mymodule.c -o mymodule.so\n",
" $ python\n",
" >>> import mymodule"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## `MPI4Py` and MPI in C/Fortran\n",
"\n",
"In response to last week's question about combining C/Fortran MPI programs with `MPI4Py`, I didn't find any examples of that being done. Which doesn't mean it's impossible, but means it's likely that no one has a use case sufficiently compelling to make it work yet."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## References\n",
"\n",
"- [On using Arrays in FORTRAN](http://web.stanford.edu/class/me200c/tutorial_77/10_arrays.html)\n",
"- [Gently introducing C](http://www.ntu.edu.sg/home/ehchua/programming/cpp/c0_Introduction.html)\n",
"- [On ctypes](https://docs.python.org/2/library/ctypes.html)\n",
"- [On exploiting Python for performance](http://wiki.scipy.org/PerformancePython)\n",
"- [A look at combining Python with FORTRAN, C and C++](http://www.sam.math.ethz.ch/~raoulb/teaching/PythonTutorial/combining.html)\n",
"\n",
"- J. R. Johansson's [Scientific Python Lectures](https://github.com/jrjohansson/scientific-python-lectures)\u2014[Lesson 6A](http://nbviewer.ipython.org/urls/raw.github.com/jrjohansson/scientific-python-lectures/master/Lecture-6A-Fortran-and-C.ipynb)\n",
"\n",
"- [Stack Overflow: Wrapping a C library in Python: C, Cython or ctypes?](https://stackoverflow.com/questions/1942298/wrapping-a-c-library-in-python-c-cython-or-ctypes)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"## Credits\n",
"\n",
"Lakshmi Rao and Neal Davis developed these materials for [Computational Science and Engineering](http://cse.illinois.edu/) at the University of Illinois at Urbana\u2013Champaign.\n",
"\n",
" \n",
"This content is available under a [Creative Commons Attribution 3.0 Unported License](https://creativecommons.org/licenses/by/3.0/).\n",
"\n",
"[](http://cse.illinois.edu/)"
]
}
],
"metadata": {}
}
]
}
\n",
"This content is available under a [Creative Commons Attribution 3.0 Unported License](https://creativecommons.org/licenses/by/3.0/).\n",
"\n",
"[](http://cse.illinois.edu/)"
]
}
],
"metadata": {}
}
]
}