{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Normal Distribution and 3 Sigma Rule\n",
"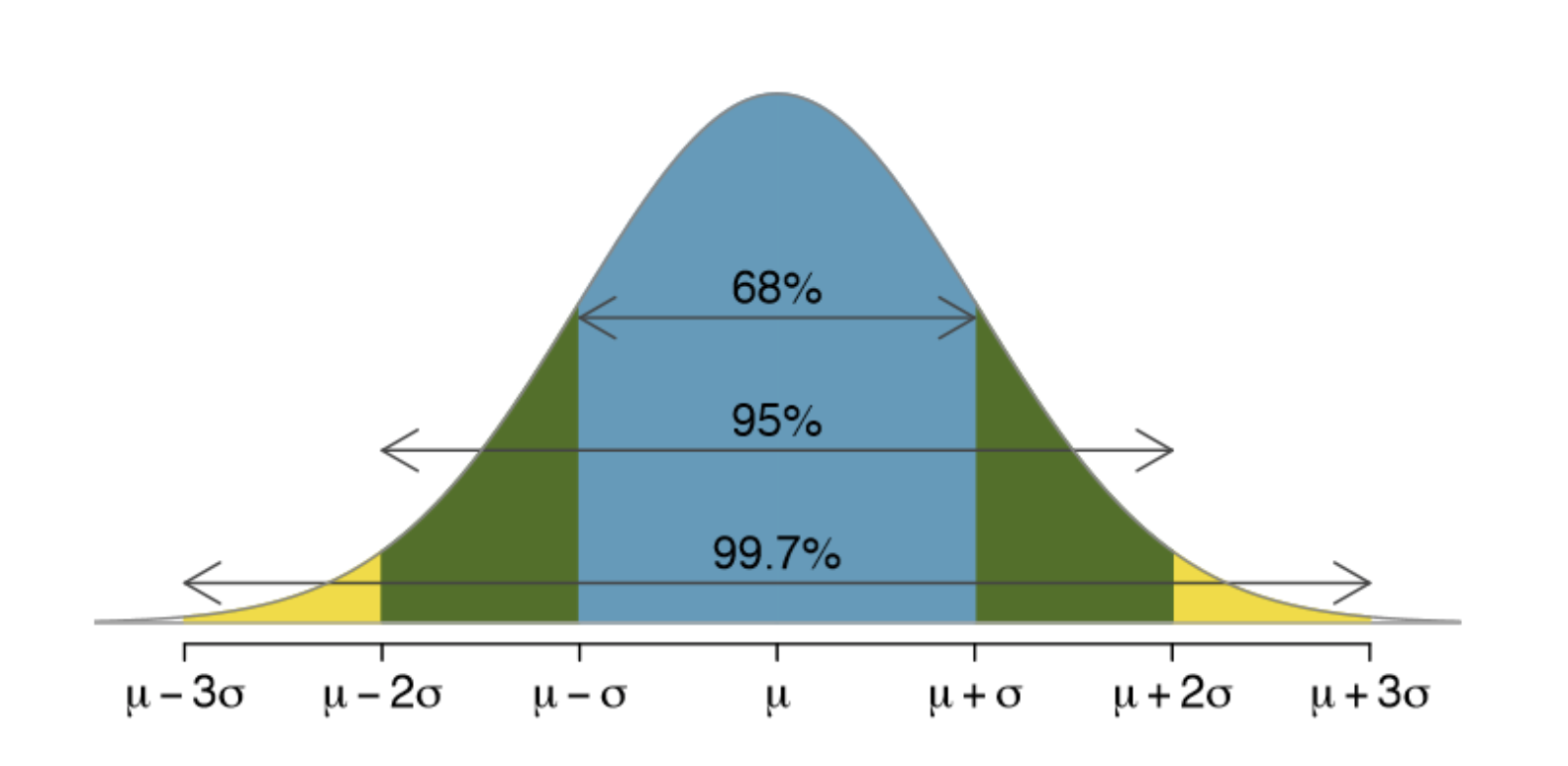\n",
"\n",
"\n",
"## Anomaly/Outlier\n",
"If a test_point is $3\\sigma$ away from the mean $\\mu$, it can be classified as an anomaly\n",
"\n",
"## Is there an anomaly?\n",
""
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"data = np.array([2, 3, 4,2,3,2,2,2,3,486])"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"(50.9, 145.03478893010464)"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"m , s = data.mean(), data.std()\n",
"m , s"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"def anomalyDetector(data, test_point):\n",
" m , s = data.mean(), data.std()\n",
" return np.abs(test_point - m) > 3 * s"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"anomalyDetector(data, test_point = 486)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"485.9"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"50.9 + 3 * 145"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## A better way of doing anomaly detection\n",
" - Remove the max %5 of data points\n",
" - Remove the min %5 of data points\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 2 | \n",
"
\n",
" \n",
" | 1 | \n",
" 3 | \n",
"
\n",
" \n",
" | 2 | \n",
" 4 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
"
\n",
" \n",
" | 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" 2 | \n",
"
\n",
" \n",
" | 6 | \n",
" 2 | \n",
"
\n",
" \n",
" | 7 | \n",
" 2 | \n",
"
\n",
" \n",
" | 8 | \n",
" 3 | \n",
"
\n",
" \n",
" | 9 | \n",
" 486 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
"
\n",
" \n",
" \n",
" \n",
" | count | \n",
" 10.000000 | \n",
"
\n",
" \n",
" | mean | \n",
" 50.900000 | \n",
"
\n",
" \n",
" | std | \n",
" 152.880091 | \n",
"
\n",
" \n",
" | min | \n",
" 2.000000 | \n",
"
\n",
" \n",
" | 25% | \n",
" 2.000000 | \n",
"
\n",
" \n",
" | 50% | \n",
" 2.500000 | \n",
"
\n",
" \n",
" | 75% | \n",
" 3.000000 | \n",
"
\n",
" \n",
" | max | \n",
" 486.000000 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 2 | \n",
"
\n",
" \n",
" | 1 | \n",
" 3 | \n",
"
\n",
" \n",
" | 2 | \n",
" 4 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
"
\n",
" \n",
" | 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" 2 | \n",
"
\n",
" \n",
" | 6 | \n",
" 2 | \n",
"
\n",
" \n",
" | 7 | \n",
" 2 | \n",
"
\n",
" \n",
" | 8 | \n",
" 3 | \n",
"
\n",
" \n",
" | 9 | \n",
" 486 | \n",
"
\n",
" \n",
"
\n",
"