




# Ktorm 是什么?
Ktorm 是直接基于纯 JDBC 编写的高效简洁的轻量级 Kotlin ORM 框架,它提供了强类型而且灵活的 SQL DSL 和方便的序列 API,以减少我们操作数据库的重复劳动。当然,所有的 SQL 都是自动生成的。Ktorm 基于 Apache 2.0 协议开放源代码,如果对你有帮助的话,请留下你的 star。
查看更多详细文档,请前往官网:[https://www.ktorm.org](https://www.ktorm.org/zh-cn)。
:us: [English](README.md) | :cn: 简体中文 | :jp: [日本語](README_jp.md)
# 特性
- 没有配置文件、没有 xml、没有注解、甚至没有任何第三方依赖、轻量级、简洁易用
- 强类型 SQL DSL,将低级 bug 暴露在编译期
- 灵活的查询,随心所欲地精确控制所生成的 SQL
- 实体序列 API,使用 `filter`、`map`、`sortedBy` 等序列函数进行查询,就像使用 Kotlin 中的原生集合一样方便
- 易扩展的设计,可以灵活编写扩展,支持更多运算符、数据类型、 SQL 函数、数据库方言等
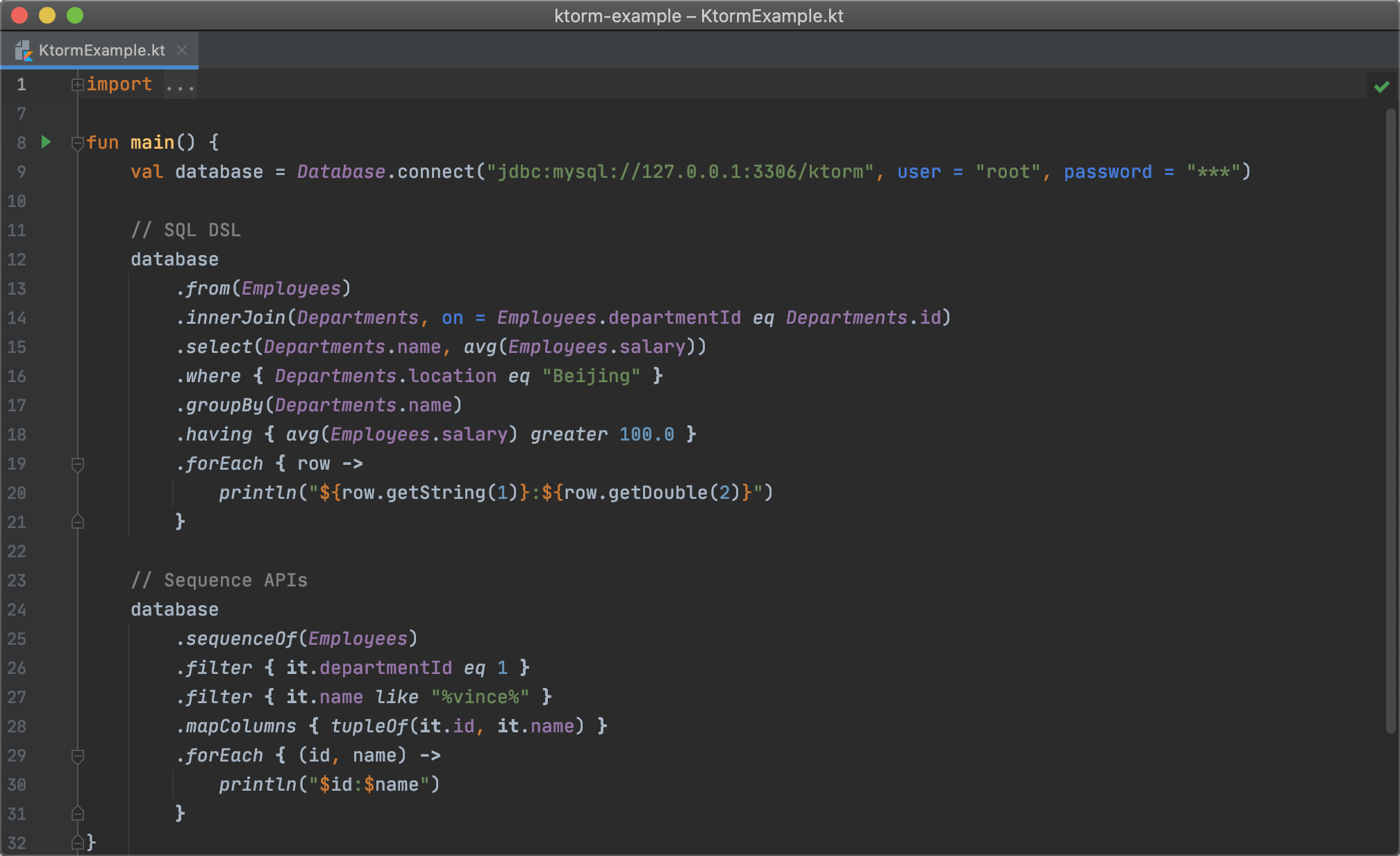
# 快速开始
Ktorm 已经发布到 maven 中央仓库,因此,如果你使用 maven 的话,只需要在 `pom.xml` 文件里面添加一个依赖:
```xml
org.ktorm
ktorm-core
${ktorm.version}
```
或者 gradle:
```groovy
compile "org.ktorm:ktorm-core:${ktorm.version}"
```
首先,创建 Kotlin object,[描述你的表结构](https://www.ktorm.org/zh-cn/schema-definition.html):
```kotlin
object Departments : Table("t_department") {
val id = int("id").primaryKey()
val name = varchar("name")
val location = varchar("location")
}
object Employees : Table("t_employee") {
val id = int("id").primaryKey()
val name = varchar("name")
val job = varchar("job")
val managerId = int("manager_id")
val hireDate = date("hire_date")
val salary = long("salary")
val departmentId = int("department_id")
}
```
然后,连接到数据库,执行一个简单的查询:
```kotlin
fun main() {
val database = Database.connect("jdbc:mysql://localhost:3306/ktorm", user = "root", password = "***")
for (row in database.from(Employees).select()) {
println(row[Employees.name])
}
}
```
现在,你可以执行这个程序了,Ktorm 会生成一条 SQL `select * from t_employee`,查询表中所有的员工记录,然后打印出他们的名字。 因为 `select` 函数返回的查询对象重载了迭代器运算符,所以你可以在这里使用 for-each 循环的语法。
## SQL DSL
让我们在上面的查询里再增加一点筛选条件:
```kotlin
database
.from(Employees)
.select(Employees.name)
.where { (Employees.departmentId eq 1) and (Employees.name like "%vince%") }
.forEach { row ->
println(row[Employees.name])
}
```
生成的 SQL 如下:
```sql
select t_employee.name as t_employee_name
from t_employee
where (t_employee.department_id = ?) and (t_employee.name like ?)
```
这就是 Kotlin 的魔法,使用 Ktorm 写查询十分地简单和自然,所生成的 SQL 几乎和 Kotlin 代码一一对应。并且,Ktorm 是强类型的,编译器会在你的代码运行之前对它进行检查,IDE 也能对你的代码进行智能提示和自动补全。
动态查询,根据不同的情况在 where 子句中增加不同的筛选条件:
```kotlin
val query = database
.from(Employees)
.select(Employees.name)
.whereWithConditions {
if (someCondition) {
it += Employees.managerId.isNull()
}
if (otherCondition) {
it += Employees.departmentId eq 1
}
}
```
聚合查询:
```kotlin
val t = Employees.aliased("t")
database
.from(t)
.select(t.departmentId, avg(t.salary))
.groupBy(t.departmentId)
.having { avg(t.salary) gt 100.0 }
.forEach { row ->
println("${row.getInt(1)}:${row.getDouble(2)}")
}
```
Union:
```kotlin
val query = database
.from(Employees)
.select(Employees.id)
.unionAll(
database.from(Departments).select(Departments.id)
)
.unionAll(
database.from(Departments).select(Departments.id)
)
.orderBy(Employees.id.desc())
```
多表连接查询:
```kotlin
data class Names(val name: String?, val managerName: String?, val departmentName: String?)
val emp = Employees.aliased("emp")
val mgr = Employees.aliased("mgr")
val dept = Departments.aliased("dept")
val results = database
.from(emp)
.leftJoin(dept, on = emp.departmentId eq dept.id)
.leftJoin(mgr, on = emp.managerId eq mgr.id)
.select(emp.name, mgr.name, dept.name)
.orderBy(emp.id.asc())
.map { row ->
Names(
name = row[emp.name],
managerName = row[mgr.name],
departmentName = row[dept.name]
)
}
```
插入:
```kotlin
database.insert(Employees) {
set(it.name, "jerry")
set(it.job, "trainee")
set(it.managerId, 1)
set(it.hireDate, LocalDate.now())
set(it.salary, 50)
set(it.departmentId, 1)
}
```
更新:
```kotlin
database.update(Employees) {
set(it.job, "engineer")
set(it.managerId, null)
set(it.salary, 100)
where {
it.id eq 2
}
}
```
删除:
```kotlin
database.delete(Employees) { it.id eq 4 }
```
更多 SQL DSL 的用法,请参考[具体文档](https://www.ktorm.org/zh-cn/query.html)。
## 实体类与列绑定
除了 SQL DSL 以外,Ktorm 也支持实体对象。首先,我们需要定义实体类,然后在表对象中使用 `bindTo` 函数将表与实体类进行绑定。在 Ktorm 里面,我们使用接口定义实体类,继承 `Entity` 即可:
```kotlin
interface Department : Entity {
companion object : Entity.Factory()
val id: Int
var name: String
var location: String
}
interface Employee : Entity {
companion object : Entity.Factory()
val id: Int
var name: String
var job: String
var manager: Employee?
var hireDate: LocalDate
var salary: Long
var department: Department
}
```
修改前面的表对象,把数据库中的列绑定到实体类的属性上:
```kotlin
object Departments : Table("t_department") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val location = varchar("location").bindTo { it.location }
}
object Employees : Table("t_employee") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val job = varchar("job").bindTo { it.job }
val managerId = int("manager_id").bindTo { it.manager.id }
val hireDate = date("hire_date").bindTo { it.hireDate }
val salary = long("salary").bindTo { it.salary }
val departmentId = int("department_id").references(Departments) { it.department }
}
```
> 命名规约:强烈建议使用单数名词命名实体类,使用名词的复数形式命名表对象,如:Employee/Employees、Department/Departments。
完成列绑定后,我们就可以使用[序列 API](#实体序列-API) 对实体进行各种灵活的操作。我们先给 `Database` 定义两个扩展属性,它们使用 `sequenceOf` 函数创建序列对象并返回。这两个属性可以帮助我们提高代码的可读性:
```kotlin
val Database.departments get() = this.sequenceOf(Departments)
val Database.employees get() = this.sequenceOf(Employees)
```
下面的代码使用 `find` 函数从序列中根据名字获取一个 Employee 对象:
```kotlin
val employee = database.employees.find { it.name eq "vince" }
```
我们还能使用 `filter` 函数对序列进行筛选,比如获取所有名字为 vince 的员工:
```kotlin
val employees = database.employees.filter { it.name eq "vince" }.toList()
```
`find` 和 `filter` 函数都接受一个 lambda 表达式作为参数,使用该 lambda 的返回值作为条件,生成一条查询 SQL。可以看到,生成的 SQL 自动 left join 了关联表 `t_department`:
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where t_employee.name = ?
```
将实体对象保存到数据库:
```kotlin
val employee = Employee {
name = "jerry"
job = "trainee"
hireDate = LocalDate.now()
salary = 50
department = database.departments.find { it.name eq "tech" }
}
database.employees.add(employee)
```
将内存中实体对象的变化更新到数据库:
```kotlin
val employee = database.employees.find { it.id eq 2 } ?: return
employee.job = "engineer"
employee.salary = 100
employee.flushChanges()
```
从数据库中删除实体对象:
```kotlin
val employee = database.employees.find { it.id eq 2 } ?: return
employee.delete()
```
更多实体 API 的用法,可参考[列绑定](https://www.ktorm.org/zh-cn/entities-and-column-binding.html)和[实体查询](https://www.ktorm.org/zh-cn/entity-finding.html)相关的文档。
## 实体序列 API
Ktorm 提供了一套名为”实体序列”的 API,用来从数据库中获取实体对象。正如其名字所示,它的风格和使用方式与 Kotlin 标准库中的序列 API 极其类似,它提供了许多同名的扩展函数,比如 `filter`、`map`、`reduce` 等。
Ktorm 的实体序列 API,大部分都是以扩展函数的方式提供的,这些扩展函数大致可以分为两类,它们分别是中间操作和终止操作。
### 中间操作
这类操作并不会执行序列中的查询,而是修改并创建一个新的序列对象,比如 `filter` 函数会使用指定的筛选条件创建一个新的序列对象。下面使用 `filter` 获取部门 1 中的所有员工:
```kotlin
val employees = database.employees.filter { it.departmentId eq 1 }.toList()
```
可以看到,用法几乎与 `kotlin.sequences` 完全一样,不同的仅仅是在 lambda 表达式中的等号 `==` 被这里的 `eq` 函数代替了而已。`filter` 函数还可以连续使用,此时所有的筛选条件将使用 `and` 运算符进行连接,比如:
```kotlin
val employees = database.employees
.filter { it.departmentId eq 1 }
.filter { it.managerId.isNotNull() }
.toList()
```
生成 SQL:
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where (t_employee.department_id = ?) and (t_employee.manager_id is not null)
```
使用 `sortedBy` 或 `sortedByDescending` 对序列中的元素进行排序:
```kotlin
val employees = database.employees.sortedBy { it.salary }.toList()
```
使用 `drop` 和 `take` 函数进行分页:
```kotlin
val employees = database.employees.drop(1).take(1).toList()
```
### 终止操作
实体序列的终止操作会马上执行一个查询,获取查询的执行结果,然后执行一定的计算。for-each 循环就是一个典型的终止操作,下面我们使用 for-each 循环打印出序列中所有的员工:
```kotlin
for (employee in database.employees) {
println(employee)
}
```
生成的 SQL 如下:
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
```
`toCollection`、`toList` 等方法用于将序列中的元素保存为一个集合:
```kotlin
val employees = database.employees.toCollection(ArrayList())
```
`mapColumns` 函数用于获取指定列的结果:
```kotlin
val names = database.employees.mapColumns { it.name }
```
除此之外,`mapColumns` 还可以同时获取多个列的结果,这时我们只需要在闭包中使用 `tupleOf` 包装我们的这些字段,函数的返回值也相应变成了 `List>`:
```kotlin
database.employees
.filter { it.departmentId eq 1 }
.mapColumns { tupleOf(it.id, it.name) }
.forEach { (id, name) ->
println("$id:$name")
}
```
生成 SQL:
```sql
select t_employee.id, t_employee.name
from t_employee
where t_employee.department_id = ?
```
其他我们熟悉的序列函数也都支持,比如 `fold`、`reduce`、`forEach` 等,下面使用 `fold` 计算所有员工的工资总和:
```kotlin
val totalSalary = database.employees.fold(0L) { acc, employee -> acc + employee.salary }
```
### 序列聚合
实体序列 API 不仅可以让我们使用类似 `kotlin.sequences` 的方式获取数据库中的实体对象,它还支持丰富的聚合功能,让我们可以方便地对指定字段进行计数、求和、求平均值等操作。
下面使用 `aggregateColumns` 函数获取部门 1 中工资的最大值:
```kotlin
val max = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { max(it.salary) }
```
如果你希望同时获取多个聚合结果,只需要在闭包中使用 `tupleOf` 包装我们的这些聚合表达式即可,此时函数的返回值就相应变成了 `TupleN`。下面的例子获取部门 1 中工资的平均值和极差:
```kotlin
val (avg, diff) = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { tupleOf(avg(it.salary), max(it.salary) - min(it.salary)) }
```
生成 SQL:
```sql
select avg(t_employee.salary), max(t_employee.salary) - min(t_employee.salary)
from t_employee
where t_employee.department_id = ?
```
除了直接使用 `aggregateColumns` 函数以外,Ktorm 还为序列提供了许多方便的辅助函数,他们都是基于 `aggregateColumns` 函数实现的,分别是 `count`、`any`、`none`、`all`、`sumBy`、`maxBy`、`minBy`、`averageBy`。
下面改用 `maxBy` 函数获取部门 1 中工资的最大值:
```kotlin
val max = database.employees
.filter { it.departmentId eq 1 }
.maxBy { it.salary }
```
除此之外,Ktorm 还支持分组聚合,只需要先调用 `groupingBy`,再调用 `aggregateColumns`。下面的代码可以获取所有部门的平均工资,它的返回值类型是 `Map`,其中键为部门 ID,值是各个部门工资的平均值:
```kotlin
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.aggregateColumns { avg(it.salary) }
```
生成 SQL:
```sql
select t_employee.department_id, avg(t_employee.salary)
from t_employee
group by t_employee.department_id
```
在分组聚合时,Ktorm 也提供了许多方便的辅助函数,它们是 `eachCount(To)`、`eachSumBy(To)`、`eachMaxBy(To)`、`eachMinBy(To)`、`eachAverageBy(To)`。有了这些辅助函数,上面获取所有部门平均工资的代码就可以改写成:
```kotlin
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.eachAverageBy { it.salary }
```
除此之外,Ktorm 还提供了 `aggregate`、`fold`、`reduce` 等函数,它们与 `kotlin.collections.Grouping` 的相应函数同名,功能也完全一样。下面的代码使用 `fold` 函数计算每个部门工资的总和:
```kotlin
val totalSalaries = database.employees
.groupingBy { it.departmentId }
.fold(0L) { acc, employee ->
acc + employee.salary
}
```
更多实体序列 API 的用法,可参考[实体序列](https://www.ktorm.org/zh-cn/entity-sequence.html)和[序列聚合](https://www.ktorm.org/zh-cn/sequence-aggregation.html)相关的文档。