




# What's Ktorm?
Ktormは純粋なJDBCをベースにしたKotlin用の軽量で効率的なORMフレームワークです。強力に型付けされた柔軟性の高い SQL DSL と便利なシーケンス API を提供し、データベース操作の重複作業を軽減してくれます。もちろん、すべてのSQL文は自動的に生成されます。Ktormはオープンソースで、Apache 2.0ライセンスで提供されています。このライブラリが役に立ったならば、Starをつけてください!
詳細なドキュメントについては、私たちのサイトを参照してください。: [https://www.ktorm.org](https://www.ktorm.org).
:us: [English](README.md) | :cn: [简体中文](README_cn.md) | :jp: 日本語
# 特徴
- 設定ファイル、XML、アノテーション、サードパーティの依存関係もなく、軽量で使いやすい。
- 強力に型付けされた SQL DSL、コンパイル時に低レベルのバグを暴き出す。
- 柔軟なクエリ、生成されたSQLを思いのままに細かく制御。
- エンティティシーケンスAPI、`filter`, `map`, `sortedBy` などのシーケンス関数を使って、Kotlin のネイティブなコレクションやシーケンスを使うのと同じようにクエリを書くことができます。
- 拡張性のある設計。独自の拡張機能を書いて、より多くの演算子、データ型、SQL関数、データベースの方言などをサポートすることができます。
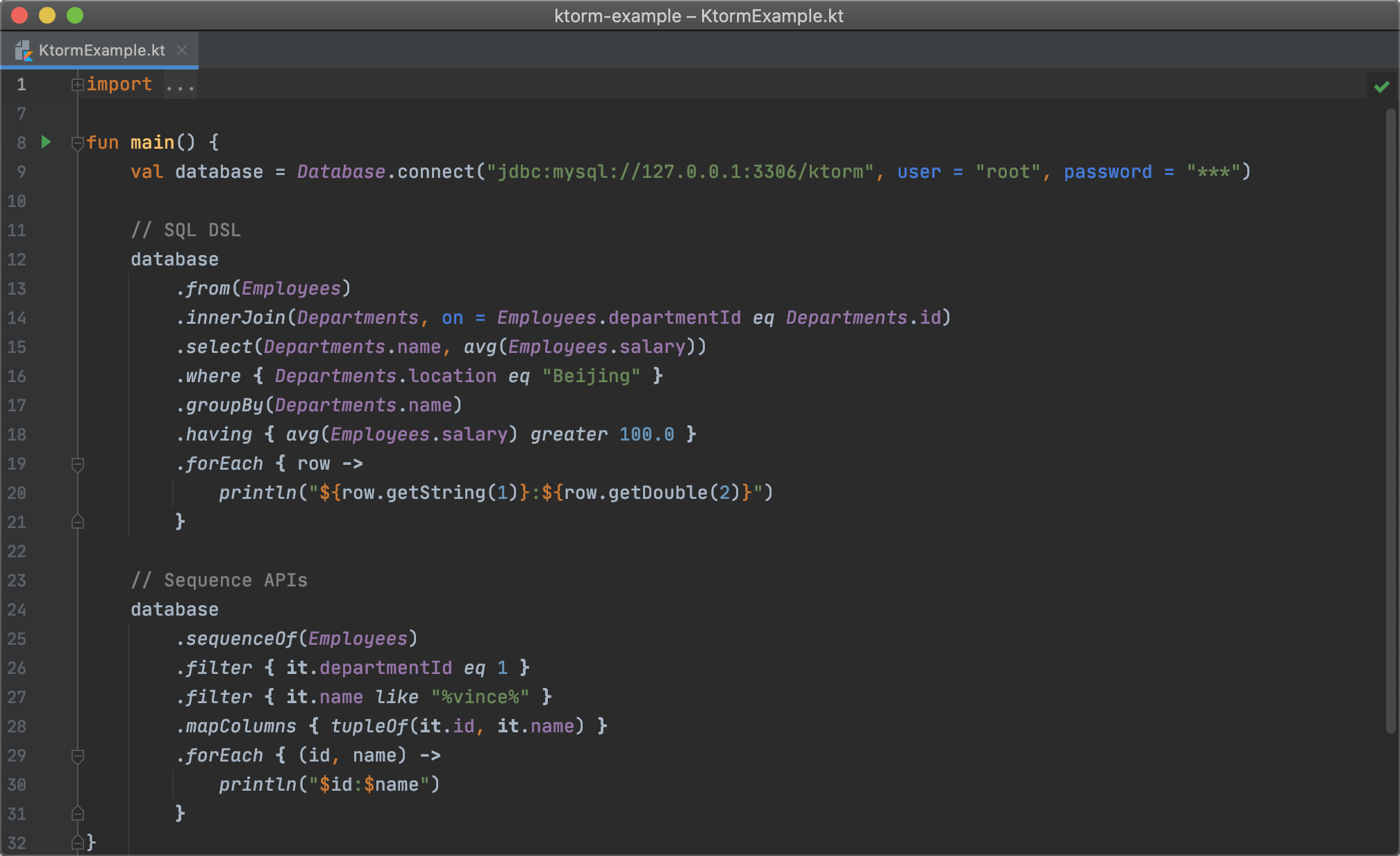
# クイックスタート
Ktormはmaven centralにデプロイされているので、mavenを使っている場合は `pom.xml` ファイルに依存関係を追加するだけです。
```xml
org.ktorm
ktorm-core
${ktorm.version}
```
Gradleの場合:
```groovy
compile "org.ktorm:ktorm-core:${ktorm.version}"
```
第一に、[テーブルスキーマを記述する](https://www.ktorm.org/en/schema-definition.html)ためのKotlinオブジェクトを作成します。
```kotlin
object Departments : Table("t_department") {
val id = int("id").primaryKey()
val name = varchar("name")
val location = varchar("location")
}
object Employees : Table("t_employee") {
val id = int("id").primaryKey()
val name = varchar("name")
val job = varchar("job")
val managerId = int("manager_id")
val hireDate = date("hire_date")
val salary = long("salary")
val departmentId = int("department_id")
}
```
そして、データベースに接続して、簡単なクエリを書きます。
```kotlin
fun main() {
val database = Database.connect("jdbc:mysql://localhost:3306/ktorm", user = "root", password = "***")
for (row in database.from(Employees).select()) {
println(row[Employees.name])
}
}
```
このプログラムを実行すると、Ktormは `select * from t_employee` というSQL文を生成し、テーブル内のすべての従業員を選択して名前を表示します。`select` 関数が返すクエリオブジェクトは反復演算子をオーバーロードしているので、for-eachループを使うことができます。
## SQL DSL
クエリにいくつかフィルタ条件を追加してみましょう。
```kotlin
database
.from(Employees)
.select(Employees.name)
.where { (Employees.departmentId eq 1) and (Employees.name like "%vince%") }
.forEach { row ->
println(row[Employees.name])
}
```
生成される SQL文:
```sql
select t_employee.name as t_employee_name
from t_employee
where (t_employee.department_id = ?) and (t_employee.name like ?)
```
Ktormを使ってクエリを書くのは簡単で自然です。生成されたSQLは元のKotlinのコードに正確に対応しています。さらに、強力な型付けがされており、実行前にコンパイラがあなたのコードをチェックし、IDEのintelligent senseとコード補完の恩恵を受けることができます。
状況に応じて異なるフィルタ条件を適用する動的クエリ:
```kotlin
val query = database
.from(Employees)
.select(Employees.name)
.whereWithConditions {
if (someCondition) {
it += Employees.managerId.isNull()
}
if (otherCondition) {
it += Employees.departmentId eq 1
}
}
```
集計:
```kotlin
val t = Employees.aliased("t")
database
.from(t)
.select(t.departmentId, avg(t.salary))
.groupBy(t.departmentId)
.having { avg(t.salary) gt 100.0 }
.forEach { row ->
println("${row.getInt(1)}:${row.getDouble(2)}")
}
```
Union:
```kotlin
val query = database
.from(Employees)
.select(Employees.id)
.unionAll(
database.from(Departments).select(Departments.id)
)
.unionAll(
database.from(Departments).select(Departments.id)
)
.orderBy(Employees.id.desc())
```
多数のテーブルを結合する:
```kotlin
data class Names(val name: String?, val managerName: String?, val departmentName: String?)
val emp = Employees.aliased("emp")
val mgr = Employees.aliased("mgr")
val dept = Departments.aliased("dept")
val results = database
.from(emp)
.leftJoin(dept, on = emp.departmentId eq dept.id)
.leftJoin(mgr, on = emp.managerId eq mgr.id)
.select(emp.name, mgr.name, dept.name)
.orderBy(emp.id.asc())
.map { row ->
Names(
name = row[emp.name],
managerName = row[mgr.name],
departmentName = row[dept.name]
)
}
```
挿入:
```kotlin
database.insert(Employees) {
set(it.name, "jerry")
set(it.job, "trainee")
set(it.managerId, 1)
set(it.hireDate, LocalDate.now())
set(it.salary, 50)
set(it.departmentId, 1)
}
```
更新:
```kotlin
database.update(Employees) {
set(it.job, "engineer")
set(it.managerId, null)
set(it.salary, 100)
where {
it.id eq 2
}
}
```
削除:
```kotlin
database.delete(Employees) { it.id eq 4 }
```
SQL DSLの詳しい使い方については、[詳細ドキュメント](https://www.ktorm.org/en/query.html)を参照してください。
## エンティティと列のバインド
SQL DSL に加えて、他の ORM フレームワークと同様にエンティティオブジェクトもサポートされています。まず、エンティティクラスを定義し、それにテーブルオブジェクトをバインドする必要があります。Ktormでは、エンティティクラスは `Entity` を拡張したインタフェースとして定義されています。
```kotlin
interface Department : Entity {
companion object : Entity.Factory()
val id: Int
var name: String
var location: String
}
interface Employee : Entity {
companion object : Entity.Factory()
val id: Int
var name: String
var job: String
var manager: Employee?
var hireDate: LocalDate
var salary: Long
var department: Department
}
```
上記のテーブルオブジェクトを変更し、データベースの列をエンティティのプロパティにバインドします。
```kotlin
object Departments : Table("t_department") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val location = varchar("location").bindTo { it.location }
}
object Employees : Table("t_employee") {
val id = int("id").primaryKey().bindTo { it.id }
val name = varchar("name").bindTo { it.name }
val job = varchar("job").bindTo { it.job }
val managerId = int("manager_id").bindTo { it.manager.id }
val hireDate = date("hire_date").bindTo { it.hireDate }
val salary = long("salary").bindTo { it.salary }
val departmentId = int("department_id").references(Departments) { it.department }
}
```
> 名前付けのコツ:エンティティクラスに単数名詞で名前を付け、テーブルオブジェクトに複数形で名前を付けることを強くお勧めします(例:Employee/Employees、Department/Departments)。
これで列バインディングが設定されたので、[エンティティシーケンス API](#エンティティシーケンス-API)を使ってエンティティに対して多くの操作を行うことができます。最初に、 `Database`の2つの拡張プロパティを定義します。これは、` sequenceOf`関数を使用してシーケンスオブジェクトを作成して返します。 これらの2つの属性は、コードを読みやすくするのに役立ちます。
```kotlin
val Database.departments get() = this.sequenceOf(Departments)
val Database.employees get() = this.sequenceOf(Employees)
```
次のコードは、 `find`関数を使用して、名前からシーケンスからEmployeeオブジェクトを取得します。
```kotlin
val employee = database.employees.find { it.name eq "vince" }
```
また、`filter`関数でシーケンスをフィルタリングすることもできます。たとえば、名前が`vince`であるすべての従業員を取得します。
```kotlin
val employees = database.employees.filter { it.name eq "vince" }.toList()
```
関数 `find` と `filter` はどちらもラムダ式を受け取り、ラムダによって返された条件を持つSELECT SQLを生成します。生成されたSQLは自動的に参照されたテーブル `t_department` に結合します。
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where t_employee.name = ?
```
エンティティをデータベースに保存します。:
```kotlin
val employee = Employee {
name = "jerry"
job = "trainee"
hireDate = LocalDate.now()
salary = 50
department = database.departments.find { it.name eq "tech" }
}
database.employees.add(employee)
```
メモリ内のプロパティの変更をデータベースにフラッシュする
```kotlin
val employee = database.employees.find { it.id eq 2 } ?: return
employee.job = "engineer"
employee.salary = 100
employee.flushChanges()
```
データベースからエンティティを削除する:
```kotlin
val employee = database.employees.find { it.id eq 2 } ?: return
employee.delete()
```
エンティティAPIの詳しい使い方は、[column binding](https://www.ktorm.org/en/entities-and-column-binding.html)と[entity query](https://www.ktorm.org/en/entity-finding.html)のドキュメントに記載されています。
## エンティティシーケンス API
Ktormは*Entity Sequence*という名前のAPIセットを提供しており、これを使ってデータベースからエンティティオブジェクトを取得することができます。その名が示すように、そのスタイルや利用パターンはKotlin標準ライブラリのシーケンスAPIと非常によく似ており、`filter`, `map`, `reduce`などの同じ名前の拡張関数が多数提供されています。
エンティティシーケンスAPIのほとんどは拡張関数として提供されており、それらは`中間処理`と`末端処理`の2つのグループに分けることができます。
### 中間処理
これらの関数は,内部クエリを実行するのではなく,いくつかの変更を加えて新たに作成されたシーケンスオブジェクトを返します。たとえば、`filter`関数はパラメータで与えられたフィルタ条件を持つ新しいシーケンスオブジェクトを生成します。以下のコードは、`filter`を用いて部門IDが1である全従業員を取得します。
```kotlin
val employees = database.employees.filter { it.departmentId eq 1 }.toList()
```
使い方は `kotlin.sequences` とほぼ同じですが、唯一の違いはラムダの `==` が `eq` 関数に置き換えられていることです。フィルタ条件はすべて `and` 演算子と結合されるので、`filter` 関数は連続して呼び出すこともできます。
```kotlin
val employees = database.employees
.filter { it.departmentId eq 1 }
.filter { it.managerId.isNotNull() }
.toList()
```
生成される SQL文:
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
where (t_employee.department_id = ?) and (t_employee.manager_id is not null)
```
エンティティを順番に並べ替えるには、`sortedBy` や `soretdByDescending` を使います。:
```kotlin
val employees = database.employees.sortedBy { it.salary }.toList()
```
ページネーションには `drop` と `take` を使います。:
```kotlin
val employees = database.employees.drop(1).take(1).toList()
```
### 末端処理
エンティティシーケンスの端末操作は、今すぐにクエリを実行し、クエリの結果を取得し、それに対していくつかの計算を行います。for-eachループは典型的な端末操作であり、次のコードはこれを使用して、シーケンス内のすべての従業員を出力します。:
```kotlin
for (employee in database.employees) {
println(employee)
}
```
生成される SQL文:
```sql
select *
from t_employee
left join t_department _ref0 on t_employee.department_id = _ref0.id
```
`toCollection` のような関数群( `toList`, `toSet` などを含む) は、すべての要素を指定したコレクションに集めるために用いられます。:
```kotlin
val employees = database.employees.toCollection(ArrayList())
```
カラムの結果を得るには、`mapColumns`関数を用います。:
```kotlin
val names = database.employees.mapColumns { it.name }
```
さらに、2つ以上の列を選択する場合は、選択した列をクロージャの `tupleOf` でラップするだけでよく、関数の戻り値の型は `List>` になります:
```kotlin
database.employees
.filter { it.departmentId eq 1 }
.mapColumns { tupleOf(it.id, it.name) }
.forEach { (id, name) ->
println("$id:$name")
}
```
生成される SQL文:
```sql
select t_employee.id, t_employee.name
from t_employee
where t_employee.department_id = ?
```
他にも、`fold`, `reduce`, `forEach` などのおなじみの関数もサポートされています。以下のコードは全従業員の給与総額を計算します。:
```kotlin
val totalSalary = database.employees.fold(0L) { acc, employee -> acc + employee.salary }
```
### シーケンスの集約
エンティティシーケンスAPIは、`kotlin.sequence`を使うのと同じようにデータベースからエンティティを取得できるだけでなく、集約関数のサポートも充実しているので、列の数を数えたり、合計したり、平均値を計算したりするのに便利です。
以下のコードは、第1部門の最大給与を取得します。:
```kotlin
val max = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { max(it.salary) }
```
また、2つ以上の列を集計する場合は、クロージャー内の `tupleOf` で集計式をラップするだけでよく、関数の戻り値の型は `TupleN` になります。 以下の例では、部門1の給与の平均と範囲を取得しています。
```kotlin
val (avg, diff) = database.employees
.filter { it.departmentId eq 1 }
.aggregateColumns { tupleOf(avg(it.salary), max(it.salary) - min(it.salary)) }
```
生成される SQL文:
```sql
select avg(t_employee.salary), max(t_employee.salary) - min(t_employee.salary)
from t_employee
where t_employee.department_id = ?
```
Ktormは、`aggregateColumns` に基づいて実装された多くの便利なヘルパー関数を提供しています。(`count`, `any`, `none`, `all`, `sumBy`, `maxBy`, `minBy`, `averageBy`)
以下のコードでは、第1部門の給与の最大値を `maxBy`関数を用いて取得しています。:
```kotlin
val max = database.employees
.filter { it.departmentId eq 1 }
.maxBy { it.salary }
```
さらに、グループ化された集約もサポートされているので、`aggregateColumns` を呼び出す前に `groupingBy` を呼び出すだけで良いのです。以下のコードは、各部門の平均給与を取得するものです。ここでは、結果の型は `Map` であり、キーは部門のID、値は部門の平均給与額です。:
```kotlin
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.aggregateColumns { avg(it.salary) }
```
生成される SQL文:
```sql
select t_employee.department_id, avg(t_employee.salary)
from t_employee
group by t_employee.department_id
```
Ktormはまた、集計をグループ化するための便利なヘルパー関数を多数提供しています(`eachCount(To)`, `eachSumBy(To)`, `eachMaxBy(To)`, `eachMinBy(To)`, `eachAverageBy(To)`)。これらの関数を使って、以下のコードを書けば、各部門の平均給与を求めることができます。:
```kotlin
val averageSalaries = database.employees
.groupingBy { it.departmentId }
.eachAverageBy { it.salary }
```
他にも `aggregate`, `fold`, `reduce` などのおなじみの関数がサポートされています。これらの関数は `kotlin.collections.Grouping` の拡張関数と同じ名前で、使い方も全く同じです。以下のコードは `fold` を用いて各部門の給与総額を計算しています。:
```kotlin
val totalSalaries = database.employees
.groupingBy { it.departmentId }
.fold(0L) { acc, employee ->
acc + employee.salary
}
```
エンティティシーケンスAPIの詳しい使い方は、[entity sequence](https://www.ktorm.org/en/entity-sequence.html)や[sequence aggregation](https://www.ktorm.org/en/sequence-aggregation.html)のドキュメントに記載されています。