✨X2SAM✨
Any Segmentation in Images and Videos
[Hao Wang](https://wanghao9610.github.io)1,2, [Limeng Qiao](https://scholar.google.com/citations?user=3PFZAg0AAAAJ&hl)3, [Chi Zhang](https://scholar.google.com/citations?user=I0aKo_4AAAAJ&hl)3, [Guanglu Wan](https://scholar.google.com/citations?user=NRG_hpYAAAAJ&hl)3, [Lin Ma](https://forestlinma.com/)3, [Xiangyuan Lan](https://scholar.google.com/citations?user=c3iwWRcAAAAJ&hl)2:email:, [Xiaodan Liang](https://scholar.google.com/citations?user=voxznZAAAAAJ&hl)1:email:
1 Sun Yat-sen University, 2 Peng Cheng Laboratory, 3 Meituan Inc.
:email: Corresponding author
## :eyes: Notice
> **Note:** X2SAM is under active development, and we will continue to update the code and documentation. Please check [TODO](#white_check_mark-todo) to get our development schedule.
We strongly recommend that everyone uses **English** to communicate in issues. This helps developers from around the world discuss, share experiences, and answer questions together.
*If you have any questions, please feel free to open an issue or reach out to me at `wanghao9610@gmail.com`.*
## :boom: Updates
- **`2026-04-28`**: ✨ X2SAM is now fully open-sourced! All training, evaluation, visualization, and demo code has been released. Head over to the [**Quickstart**](#checkered_flag-quickstart) section to get started.
- **`2026-04-27`**: 👏 The X2SAM technical report is now available! Check it out [**Here**](https://huggingface.co/hao9610/X2SAM/blob/main/X2SAM.pdf) for comprehensive technical details.
- **`2026-03-20`**: 🫣 The X2SAM repository is now live. Paper and code updates are on the way, stay tuned!
## :rocket: Highlights
This repository provides the official PyTorch implementation, pre-trained models, training, evaluation, visualization, and demo code of X2SAM:
* X2SAM introduces a unified segmentation MLLM framework that extends any-segmentation capabilities from images to videos, supporting generic, open-vocabulary, referring, reasoning, grounded conversation generation, interactive, and visual grounded segmentation in one model.
* X2SAM supports both conversational instructions and visual prompts through a unified interface, and couples an LLM with a Mask Memory module to store guided vision features for temporally consistent video mask generation.
* X2SAM proposes the Video Visual Grounded (V-VGD) segmentation benchmark and adopts a unified joint training strategy over heterogeneous image and video datasets, achieving strong video segmentation performance while remaining competitive on image segmentation and preserving general image/video chat ability.
✨ X2SAM offers a powerful and comprehensive solution for any segmentation task across both images and videos, featuring a unified pipeline for training and evaluation on all supported benchmarks. Whether you're new to segmentation MLLMs or looking to advance your research, X2SAM is an excellent starting point. We hope you enjoy exploring and using X2SAM!
## :book: Table of Contents
- [Abstract](#bookmark-abstract)
- [Overview](#mag-overview)
- [Benchmarks](#bar_chart-benchmarks)
- [Quickstart](#checkered_flag-quickstart)
- [Demo](#computer-demo)
- [TODO](#white_check_mark-todo)
- [Acknowledge](#blush-acknowledge)
- [Citation](#pushpin-citation)
## :bookmark: Abstract
Multimodal Large Language Models (MLLMs) have demonstrated strong image-level visual understanding and reasoning, yet their pixel-level perception across both images and videos remains limited. Foundation segmentation models such as the SAM series produce high-quality masks, but they rely on low-level visual prompts and cannot natively interpret complex conversational instructions. Existing segmentation MLLMs narrow this gap, but are usually specialized for either images or videos and rarely support both textual and visual prompts in one interface. We introduce X2SAM, a unified segmentation MLLM that extends any-segmentation capabilities from images to videos. Given conversational instructions and visual prompts, X2SAM couples an LLM with a Mask Memory module that stores guided vision features for temporally consistent video mask generation. The same formulation supports generic, open-vocabulary, referring, reasoning, grounded conversation generation, interactive, and visual grounded segmentation across image and video inputs. We further introduce the Video Visual Grounded (V-VGD) segmentation benchmark, which evaluates whether a model can segment object tracks in videos from interactive visual prompts. With a unified joint training strategy over heterogeneous image and video datasets, X2SAM delivers strong video segmentation performance, remains competitive on image segmentation benchmarks, and preserves general image and video chat ability.
## :mag: Overview
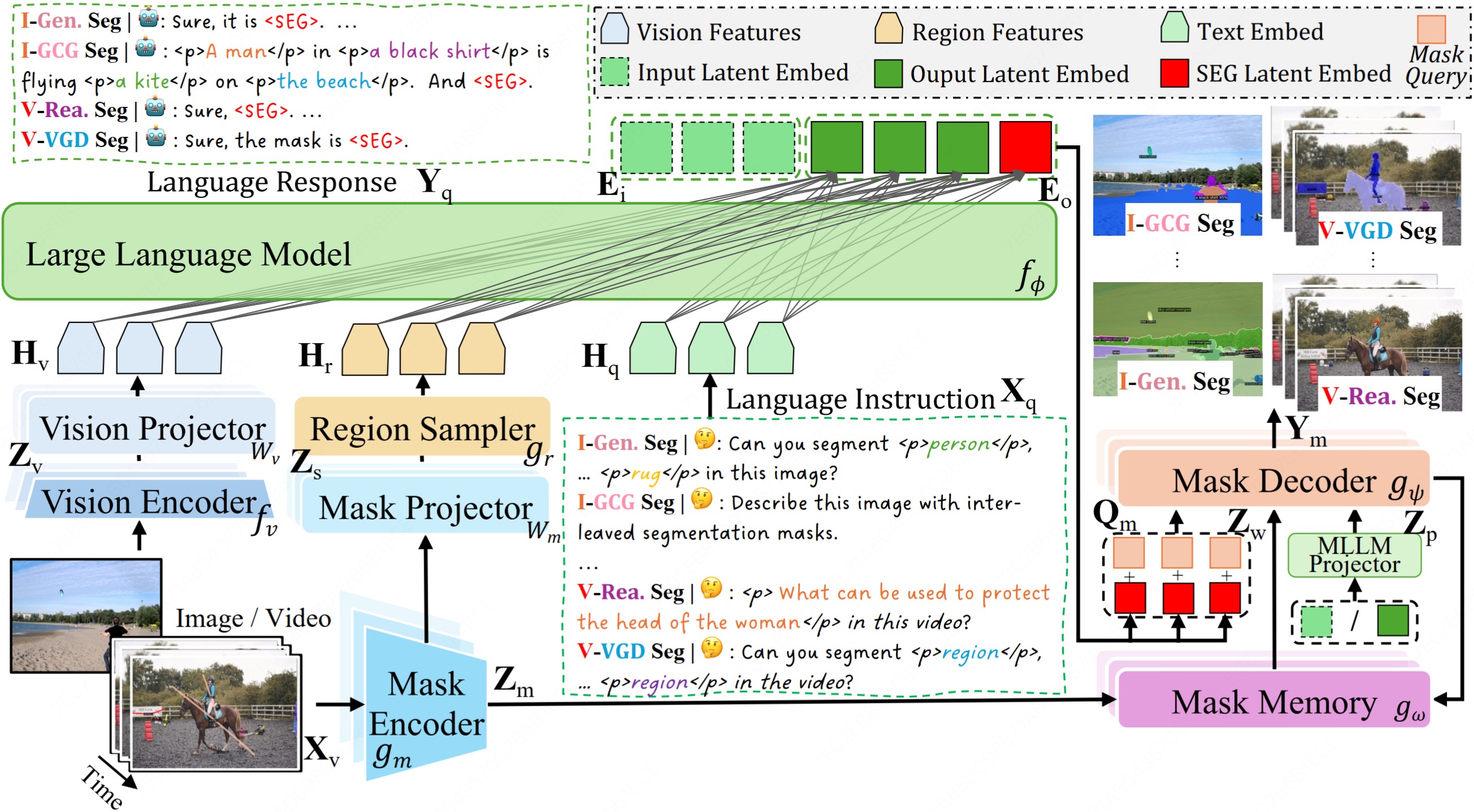
Figure 1: Overview of X2SAM. The Vision Encoder extracts global visual representations, while the Mask Encoder captures fine-grained visual features. The Large Language Model generates the language response and produces the latent condition embedding, which guides the Mask Decoder in generating the segmentation mask. The Mask Memory module stores guided vision features for each video frame, and the Region Sampler extracts region-of-interest embeddings from both images and videos.
## :bar_chart: Benchmarks
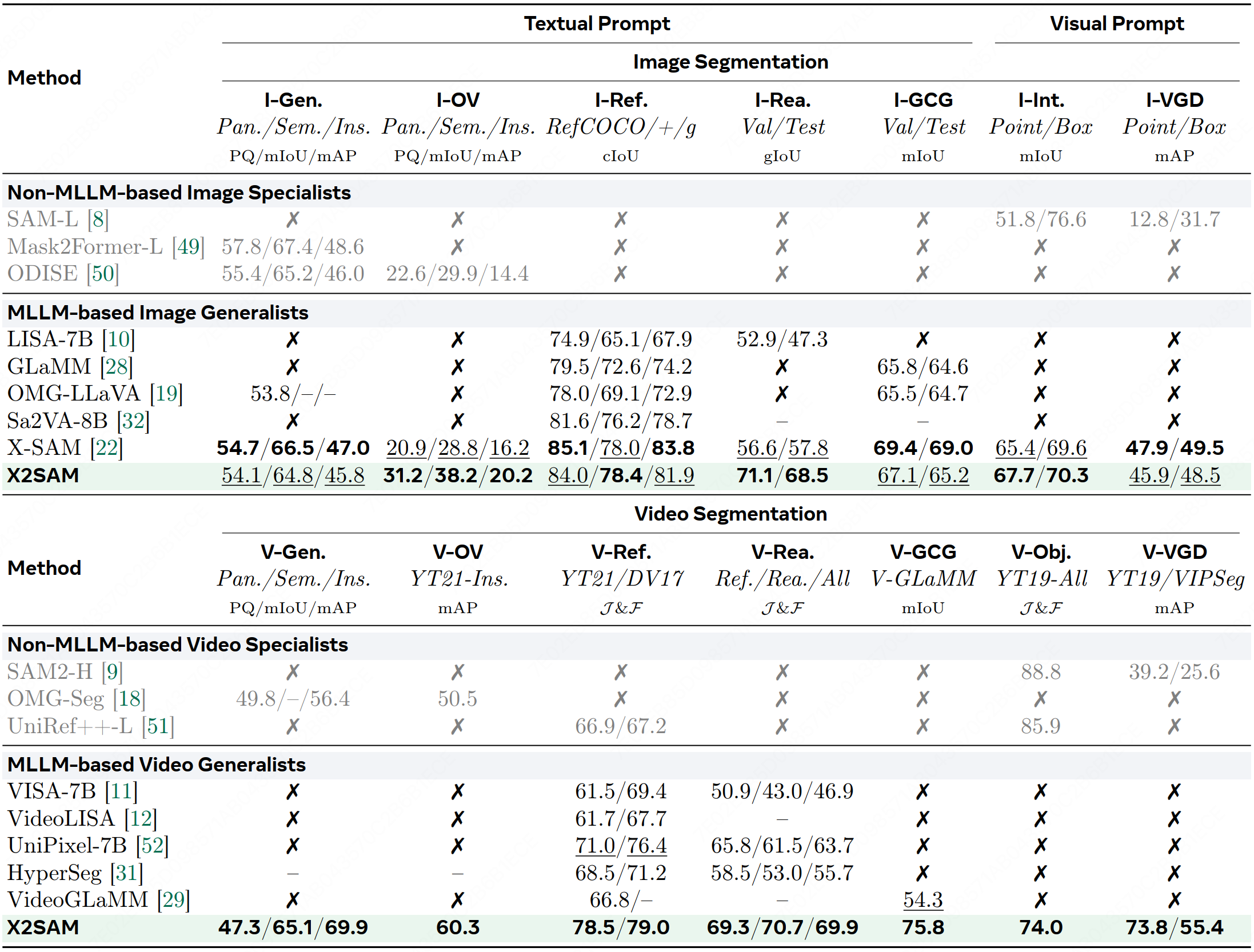
Table 1: Comparison of state-of-the-art segmentation methods across image and video segmentation benchmarks.
👉 **More benchmark results can be found in [benchmarks.md](docs/mds/benchmarks.md).**
## :checkered_flag: Quickstart
### 1. Structure
We provide a detailed project structure for X2SAM. Please follow this structure to organize the project.
📁 Project
```bash
X2SAM
├── datas
│ ├── img_chat
│ ├── img_gcgseg
│ ├── img_genseg
│ ├── img_intseg
│ ├── img_ovseg
│ ├── img_reaseg
│ ├── img_refseg
│ ├── img_sam
│ ├── img_vgdseg
│ ├── vid_chat
│ ├── vid_gcgseg
│ ├── vid_objseg
│ ├── vid_ovseg
│ ├── vid_reaseg
│ ├── vid_refseg
│ └── vid_vgdseg
├── inits
│ ├── huggingface
│ ├── Qwen3-VL-4B-Instruct
│ ├── X2SAM
│ ├── mask2former-swin-large-coco-panoptic
│ └── sam2.1-hiera-large
├── x2sam
│ ├── requirements
│ ├── x2sam
│ │ ├── configs
│ │ ├── dataset
│ │ ├── demo
│ │ ├── engine
│ │ ├── evaluation
│ │ ├── model
│ │ ├── registry
│ │ ├── structures
│ │ ├── tools
│ │ └── utils
├── wkdrs
│ ├── s1_train
│ │ ├── ...
│ ├── s2_train
│ │ ├── ...
│ ├── s3_train
│ │ ├── ...
│ ├── ...
...
```
### 2. Enviroment
#### Basic setup
```bash
# 1) Clone X2SAM and enter project home directory
git clone https://github.com/wanghao9610/X2SAM.git
cd X2SAM
export PROJ_HOME="$(realpath ./)"
export PYTHONPATH="$PROJ_HOME/x2sam:$PYTHONPATH"
# 2) Create and activate conda environment
conda create -n x2sam python=3.10 -y
conda activate x2sam
# 3) Install X2SAM dependencies
cd "$PROJ_HOME/x2sam"
pip install -r requirements.txt
# 4) Compile Deformable-Attention
cd "$PROJ_HOME/x2sam/x2sam/model/ops"
bash make.sh
```
#### Optional: set CUDA_HOME
```bash
export CUDA_HOME="your_cuda12.4_path"
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="$CUDA_HOME/lib64:$LD_LIBRARY_PATH"
echo -e "CUDA version:\n$(nvcc -V)"
```
#### Optional: install VLMEvalKit
```bash
cd "$PROJ_HOME"
git clone -b v0.3rc1 https://github.com/open-compass/VLMEvalKit.git
cd VLMEvalKit
pip install -e .
```
### 3. Dataset
Please refer to [datasets.md](docs/mds/datasets.md) for detailed instructions on data preparation.
### 4. Model
Please refer to [models.md](docs/mds/models.md) for detailed instructions on model preparation.
### 5. Training
We provide a comprehensive script that covers the entire pipeline, including training, evaluation, visualization, and dataset exploration. For detailed instructions, please refer to [gpu_run.sh](runs/gpu_run.sh).
```bash
cd "$PROJ_HOME"
# Distributed training of X2SAM across 4 nodes, 32 NVIDIA H800 (80GB) GPUs.
# Set NODE_RANK to specify the rank (ID) of each node in distributed training.
# MASTER_ADDR and MASTER_PORT should be set to the IP address and port of your master node.
# Execute the following commands on every machine, updating NODE_RANK for each node accordingly.
# 1) Agnostic Segmentor Training.
NUM_NODES=4 NODE_RANK=0 GPU_PER_NODE=1 MASTER_ADDR=YOUR_MASTER_ADDR MASTER_PORT=29510 GPU_PER_NODE=8 \
bash runs/gpu_run.sh \
x2sam/x2sam/configs/x2sam/s1_train/x2sam_sam2.1_hiera_large_m2f_e1_gpu32.py \
"train"
# 2) Unified Joint Training.
NUM_NODES=4 NODE_RANK=0 GPU_PER_NODE=1 MASTER_ADDR=YOUR_MASTER_ADDR MASTER_PORT=29510 GPU_PER_NODE=8 \
bash runs/gpu_run.sh \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
"train segeval vlmeval visualize"
```
### 6. Evaluation
#### Image and Video Segmentation Benchmarks
```bash
cd "$PROJ_HOME"
bash runs/gpu_run.sh \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
"segeval"
```
#### Image and Video Chat Benchmarks
```bash
cd "$PROJ_HOME"
bash runs/gpu_run.sh \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
"vlmeval"
```
### 7. Visualization
```bash
cd "$PROJ_HOME"
bash runs/gpu_run.sh \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
"visualize"
```
### 8. Tools
Dataset Exploration
We provide a tool for dataset exploration, you can use it to explore the dataset and get the visualizations of the dataset.
```bash
cd "$PROJ_HOME"
python x2sam/tools/explore.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--output-dir "wkdrs/dataset_exploration" \
--subset train \
--max-samples 100
```
Model Conversion
We provide a tool for model conversion, you can use it to convert the model to the Hugging Face checkpoint format.
```bash
cd "$PROJ_HOME"
python x2sam/tools/pth_to_hf.py \
--work-dir "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora" \
--tag-dir "last_checkpoint"
```
## :computer: Demo
### Local Demo
🏞️ / 🎥 Inference
```bash
cd "$PROJ_HOME"
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name TASK_NAME \
--image/--video INPUT_IMAGE/INPUT_VIDEO/INPUT_DIR \
--prompt INPUT_PROMPT \
--vprompt-masks INPUT_VPROMPT_MASKS \
```
🏞️ / 🎥 Examples
```bash
# Example: img_chat
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_chat \
--image x2sam/x2sam/demo/sample.jpg \
--prompt "What is unusal about this image?"
# Example: img_genseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_genseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
--prompt "ins: person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush;
sem: banner, blanket, bridge, cardboard, counter, curtain, door-stuff, floor-wood, flower, fruit, gravel, house, light, mirror-stuff, net, pillow, platform, playingfield, railroad, river, road, roof, sand, sea, shelf, snow, stairs, tent, towel, wall-brick, wall-stone, wall-tile, wall-wood, water-other, window-blind, window-other, tree-merged, fence-merged, ceiling-merged, sky-other-merged, cabinet-merged, table-merged, floor-other-merged, pavement-merged, mountain-merged, grass-merged, dirt-merged, paper-merged, food-other-merged, building-other-merged, rock-merged, wall-other-merged, rug-merged"
# Example: img_refseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_refseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
--prompt "the ironing man"
# Example: img_reaseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_reaseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
--prompt "What can be used to warm clothes?"
# Example: img_gcgseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_gcgseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
# Example: img_intseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_intseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
--vprompt-masks "x2sam/x2sam/configs/x2sam/samples/vpmasks/img_vpmask0.png"
# Example: img_vgdseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name img_vgdseg \
--image x2sam/x2sam/demo/sample.jpg \
--output-dir "wkdrs/demo_outputs" \
--vprompt-masks "x2sam/x2sam/configs/x2sam/samples/vpmasks/img_vpmask0.png" "x2sam/x2sam/configs/x2sam/samples/vpmasks/img_vpmask1.png"
# Example: vid_chat
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_chat \
--video x2sam/x2sam/demo/sample.mp4 \
--prompt "Please describe this video in detail."
# Example: vid_genseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_genseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
--prompt "ins: person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush;
sem: banner, blanket, bridge, cardboard, counter, curtain, door-stuff, floor-wood, flower, fruit, gravel, house, light, mirror-stuff, net, pillow, platform, playingfield, railroad, river, road, roof, sand, sea, shelf, snow, stairs, tent, towel, wall-brick, wall-stone, wall-tile, wall-wood, water-other, window-blind, window-other, tree-merged, fence-merged, ceiling-merged, sky-other-merged, cabinet-merged, table-merged, floor-other-merged, pavement-merged, mountain-merged, grass-merged, dirt-merged, paper-merged, food-other-merged, building-other-merged, rock-merged, wall-other-merged, rug-merged"
# Example: vid_refseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_refseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
--prompt "the jumping boy on the bed"
# Example: vid_reaseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_reaseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
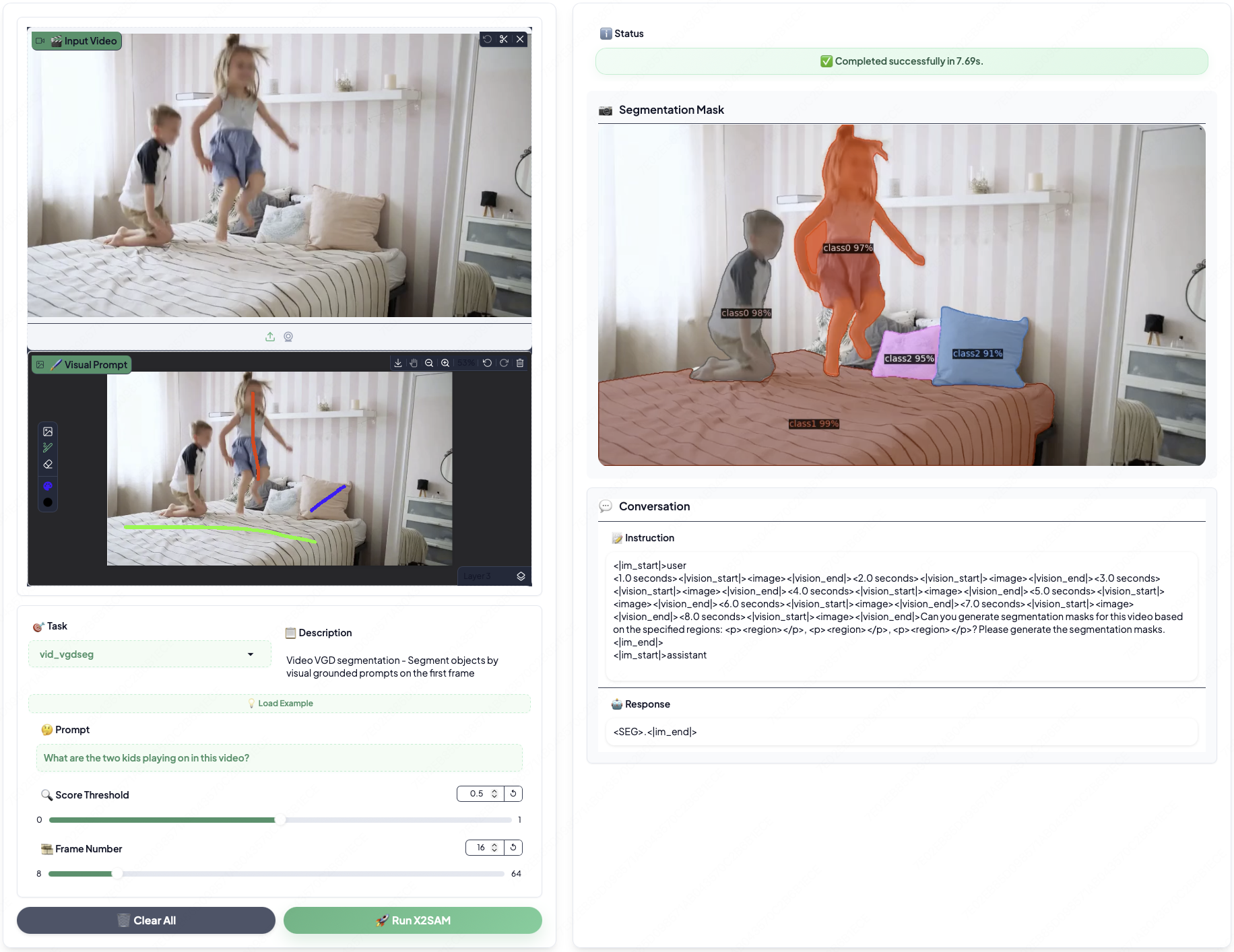
--prompt "What are the two kids playing on in this video?"
# Example: vid_gcgseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_gcgseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
# Example: vid_objseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_objseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
--vprompt-masks "x2sam/x2sam/configs/x2sam/samples/vpmasks/vid_vpmask0.png"
# Example: vid_vgdseg
python x2sam/x2sam/demo/demo.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--task-name vid_vgdseg \
--video x2sam/x2sam/demo/sample.mp4 \
--output-dir "wkdrs/demo_outputs" \
--vprompt-masks "x2sam/x2sam/configs/x2sam/samples/vpmasks/vid_vpmask0.png" "x2sam/x2sam/configs/x2sam/samples/vpmasks/vid_vpmask1.png"
```
### Web Demo
🛠️ Deployment
```bash
cd "$PROJ_HOME"
python x2sam/x2sam/demo/app.py \
x2sam/x2sam/configs/x2sam/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora.py \
--pth_model "wkdrs/s3_train/x2sam_qwen3_vl_4b_sam2.1_hiera_large_m2f_e1_gpu32_lora/pytorch_model.bin" \
--log-dir "wkdrs/app_logs" \
--seed 0 \
--port 7860
```
Then, you can access the demo website at `http://localhost:7860`.
## :white_check_mark: TODO
- [x] Release the technical report.
- [x] Release the pre-trained models.
- [x] Release the demo website.
- [x] Release the demo instructions.
- [x] Release the evaluation code.
- [x] Release the training code.
## :pray: Acknowledge
This project has referenced some excellent open-sourced repos ([xtuner](https://github.com/InternLM/xtuner), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), [X-SAM](https://github.com/wanghao9610/X-SAM)). Thanks for their wonderful works and contributions to the community!
## :pushpin: Citation
If you find X2SAM and X-SAM are helpful for your research or applications, please consider giving us a star 🌟 and citing the following papers by the following BibTex entry.
```bibtex
@article{wang2026x2sam,
title={X2SAM: Any Segmentation in Images and Videos},
author={Wang, Hao and Qiao, Limeng and Zhang, Chi and Wan, Guanglu and Ma, Lin and Lan, Xiangyuan and Liang, Xiaodan},
journal={arXiv preprint arXiv:2605.00891},
year={2026}
}
@inproceedings{wang2026xsam,
title={X-SAM: From segment anything to any segmentation},
author={Wang, Hao and Qiao, Limeng and Jie, Zequn and Huang, Zhijian and Feng, Chengjian and Zheng, Qingfang and Ma, Lin and Lan, Xiangyuan and Liang, Xiaodan},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={40},
number={31},
pages={26187--26196},
year={2026}
}
```