# Auto-claude-code-research-in-sleep (ARIS ⚔️🌙)


[English](README.md) | 中文版
> 🌙 **让 Claude Code 在你睡觉时做科研。** 醒来发现论文已被打分、弱点已被定位、实验已跑完、叙事已重写——全自动。
>
> 🪶 **极致轻量——零依赖,零锁定。** 整个系统就是纯 Markdown 文件。没有框架要学、没有数据库要维护、没有 Docker 要配、没有守护进程要看管。每个 skill 就是一个 `SKILL.md`,任何 LLM 都能读懂——换成 [Codex CLI](skills/skills-codex/)、[OpenClaw](docs/OPENCLAW_ADAPTATION.md)、[Cursor](docs/CURSOR_ADAPTATION.md)、[Trae](docs/TRAE_ARIS_RUNBOOK_CN.md)、[Antigravity](docs/ANTIGRAVITY_ADAPTATION_CN.md)、Windsurf 或者你自己的 agent,工作流照样跑。Fork 它、改写它、适配到你的技术栈。
>
> *💡 ARIS 是方法论,不是平台。重要的是科研工作流——带着它去任何地方。🌱*
[](https://mp.weixin.qq.com/s/tDniVryVGjDkkkWl-5sTkQ) · [](https://mp.weixin.qq.com/s/KLFU74lAL2FAIc9K6i1Kqg) · [](https://github.com/VoltAgent/awesome-agent-skills) · [-orange?style=flat)](https://aidigitalcrew.com) · [💬 加入交流群](#-交流群) · [](#-引用)
基于 [Claude Code](https://docs.anthropic.com/en/docs/claude-code) 的自定义 Skills,用于自主 ML 科研工作流。核心机制是**跨模型协作**——Claude Code 负责执行(读文件、写代码、跑实验、收结果),外部 LLM(通过 [Codex MCP](https://github.com/openai/codex))负责评审(打分、找弱点、建议修复)。两个模型互不评自己的作业,形成真正的反馈循环。🔀 **也支持[替代模型组合](#-替代模型组合)(Kimi、LongCat、DeepSeek 等)——无需 Claude 或 OpenAI API。** 例如 [MiniMax-M2.7 + GLM-5 或 GLM-5 + MiniMax-M2.7](docs/MiniMax-GLM-Configuration.md)。 🤖 **[Codex CLI 原生版](skills/skills-codex/)** — 完整 skill 集合也支持 OpenAI Codex。🖱️ **[Cursor](docs/CURSOR_ADAPTATION.md)** — Cursor 也能用。🖥️ **[Trae](docs/TRAE_ARIS_RUNBOOK_CN.md)** — 字节跳动 AI IDE。🚀 **[Antigravity](docs/ANTIGRAVITY_ADAPTATION_CN.md)** — Google Agent-First IDE。🆓 **[ModelScope 免费接入](docs/MODELSCOPE_GUIDE.md)——零成本,零锁定。**
> 💭 **为什么不用单模型自我博弈?** 用 Claude Code 的 subagent 或 agent team 同时做执行和审稿在技术上可行,但容易陷入**局部最优**——同一个模型审自己的输出会产生盲区。
>
> *类比 bandit 问题:单模型自审是 stochastic bandit(噪声可预测),跨模型审稿则是 adversarial bandit(审稿者会主动探测执行者未预料的弱点)——而 adversarial bandit 天然更难被 game。*
>
> 💭 **为什么是两个模型而不是更多?** 两个是打破自我博弈盲区的最小配置,且双人博弈收敛到 Nash 均衡的效率远高于多人博弈。增加更多审稿者只会增加 API 开销和协调成本,边际收益递减——最大的提升来自 1→2,而非 2→4。
>
> Claude Code 的优势是快速丝滑的执行,Codex(GPT-5.4 xhigh)虽然慢但审稿更严谨深入。两者**速度 × 严谨**的互补特性,比单模型自我对话效果更好。
## 🎯 不止一句 Prompt
**基础模式** — 给 ARIS 一个研究方向,全自动:
```
/research-pipeline "离散扩散语言模型的 factorized gap"
```
**🔥 精准模式** — 有篇论文想改进?把论文 + 代码给 ARIS:
```
/research-pipeline "改进方法 X" — ref paper: https://arxiv.org/abs/2406.04329, base repo: https://github.com/org/project
```
ARIS 读论文 → 找弱点 → 克隆代码 → 针对*那些*弱点用*那套*代码生成改进方案 → 跑实验 → 写论文。就像跟研究助手说:*"读这篇论文,用这个 repo,找出哪里不行,然后修好它。"*
> 自由组合:`ref paper` 单独 = "这篇论文哪里能改进?",`base repo` 单独 = "这个代码能做什么?",两个都给 = "用*这个*代码改进*这篇*论文。"
**🔥 Rebuttal 模式** — 审稿意见来了?别慌。ARIS 读每条意见、制定策略、起草安全的 rebuttal:
```
/rebuttal "paper/ + reviews" — venue: ICML, character limit: 5000
```
| 参数 | 默认值 | 作用 |
|------|--------|------|
| `venue` | `ICML` | 目标会议 |
| `character limit` | — | **必填。** 字符限制 |
| `quick mode` | `false` | 仅解析 + 策略(Phase 0-3),先看审稿人要什么 |
| `auto experiment` | `false` | 自动跑补充实验(`/experiment-bridge`) |
| `max stress test rounds` | `1` | GPT-5.4 压力测试轮数 |
| `max followup rounds` | `3` | 每个 reviewer follow-up 上限 |
三道安全门:
- 🔒 **不编造** — 每句话有出处
- 🔒 **不过度承诺** — 没批准的不承诺
- 🔒 **全覆盖** — 每个审稿意见都追踪
两版输出:`PASTE_READY.txt`(精确字数,直接粘贴)+ `REBUTTAL_DRAFT_rich.md`(详细版,自己改)
**中稿之后** — 论文录了,准备展示:
```
/paper-slides "paper/" # → Beamer PDF + PPTX + 演讲稿 + Q&A 预案
/paper-poster "paper/" # → A0/A1 海报 PDF + 可编辑 PPTX + SVG
```
> *💡 从 idea 到论文到讲台到 rebuttal——一条工具链。🌱*
> 以上是全流程——你也可以单独用任何一个工作流。已有 idea?直接进工作流 1.5。有结果了?跳到工作流 3。见[快速开始](#-快速开始)查看所有命令,[工作流](#-工作流)了解完整流程。
## 🏆 ARIS 中稿论文
| 论文 | 评分 | 会议 | 作者 | 技术栈 |
|------|:---:|------|------|--------|
| CS 论文 | **8/10** "clear accept" | CS 会议 | [@DefanXue](https://github.com/DefanXue) & [@Monglitay](https://github.com/Monglitay) | Claude Code + GPT-5.4 |
| AAAI 论文 | **7/10** "good paper, accept" | AAAI 2026 Main Technical | [@xinbo820-web](https://github.com/xinbo820-web) | 纯 Codex CLI |
> 🎉 全程 ARIS 完成——从 idea 到接收。[详情 + 审稿截图 →](#-社区实操--用-aris-完成的论文)
## 📢 最近更新
- **2026-03-27** —  📄 **IEEE 模板** — `IEEE_JOURNAL`(TPAMI/TIP/TNNLS)+ `IEEE_CONF`(ICC/GLOBECOM/INFOCOM/ICASSP)。**9 个 venue 族。** 🔎 **[Semantic Scholar](skills/semantic-scholar/SKILL.md)** — 搜索 arXiv 之外的正式发表论文(`— sources: semantic-scholar`)。社区贡献 by [@ypd666](https://github.com/ypd666)
- **2026-03-26** —  📄 **文档输入** — 放一个 `RESEARCH_BRIEF.md` 到项目根目录,`/idea-discovery` 和 `/research-pipeline` 自动检测。复杂研究方向不用挤在一句话里。[模板](templates/RESEARCH_BRIEF_TEMPLATE.md)
- **2026-03-24** —  📝 **[工作流 4:`/rebuttal`](skills/rebuttal/SKILL.md)** — 投稿后 rebuttal 流水线。解析 review → 原子化 → 策略 → 起草 → 安全检查 → GPT-5.4 压力测试 → 定稿(精确版 + 详细版)→ follow-up。3 道安全门。`quick mode` 仅分析。`auto experiment` 补实验。基于 5 篇成功 rebuttal 案例 + 3 轮 GPT-5.4 设计评审
- **2026-03-23** —  🔧 **3 个 skill 集成到核心工作流**:`/training-check`、`/result-to-claim`、`/ablation-planner`。📦 **`compact` 模式**。🔄 **断点续跑**。社区贡献 by [@JingxuanKang](https://github.com/JingxuanKang) & [@couragec](https://github.com/couragec)
- **2026-03-22** —  📋 **[模板](templates/)** + 📄 **7 个会议模板** + 🛡️ **反幻觉修复** + 🔗 **`base repo`**
- **2026-03-22** —  🔍 **[Codex + Gemini 审稿](docs/CODEX_GEMINI_REVIEW_GUIDE_CN.md)** — Codex 执行,Gemini 审稿
- **2026-03-20** —  🚀 **[Antigravity 适配指南](docs/ANTIGRAVITY_ADAPTATION_CN.md)** — 在 [Google Antigravity](https://antigravity.google/)(Agent-First IDE)中使用 ARIS skills。原生 `SKILL.md` 支持,双模型(Claude Opus 4.6 Thinking / Gemini 3.1 Pro),MCP 配置,[英文](docs/ANTIGRAVITY_ADAPTATION.md) + 中文指南
- **2026-03-20** —  🖥️ **[Trae 适配指南](docs/TRAE_ARIS_RUNBOOK_CN.md)** — 在 [Trae](https://www.trae.ai/)(字节跳动 AI IDE)中使用 ARIS skills,中英文指南。社区贡献 by [@Prometheus-cotigo](https://github.com/Prometheus-cotigo)。🔢 **[`formula-derivation`](skills/formula-derivation/SKILL.md)** — 公式推导与验证。社区贡献 by [@Falling-Flower](https://github.com/Falling-Flower)
- **2026-03-19** —  🖼️ **[`paper-poster`](skills/paper-poster/SKILL.md)** — 会议海报(tcbposter → A0/A1 PDF + PPTX + SVG),会议配色、视觉审查、Codex 评审。社区贡献 by [@dengzhe-hou](https://github.com/dengzhe-hou)
- **2026-03-19** —  🔗 **工作流 1.5 升级** — `/experiment-bridge` 新增 **GPT-5.4 跨模型代码审查**(`code review: true` 默认开启)。📊 **W&B 修正** — 真实 `wandb.Api()` 调用
- **2026-03-18** —  🎤 **[`paper-slides`](skills/paper-slides/SKILL.md)** — 会议演讲幻灯片(beamer → PDF + PPTX),含演讲稿、speaker notes、Q&A 预案。4 种类型(oral/spotlight/poster/invited)。社区贡献 by [@dengzhe-hou](https://github.com/dengzhe-hou)
- **2026-03-18** —  🔁 **[Codex + Claude 审稿 bridge](docs/CODEX_CLAUDE_REVIEW_GUIDE_CN.md)** — Codex 执行、Claude 审稿,通过本地 `claude-review` MCP bridge。社区贡献 by [@loujc](https://github.com/loujc)
- **2026-03-18** —  🖱️ **[Cursor 适配指南](docs/CURSOR_ADAPTATION.md)** — 在 [Cursor](https://www.cursor.com/) 中使用 ARIS skills,`@` 引用、MCP 配置、状态文件恢复。社区贡献 by [@YecanLee](https://github.com/YecanLee)
- **2026-03-18** —  🤖 **[Codex CLI 原生 skills](skills/skills-codex/)** — 完整 31 个 ARIS skill 的 Codex CLI 版本,用 `spawn_agent`。社区贡献 by [@Falling-Flower](https://github.com/Falling-Flower) & [@No-518](https://github.com/No-518)
- **2026-03-18** —  📝 **[`grant-proposal`](skills/grant-proposal/SKILL.md)** — 从研究 idea 自动生成结构化基金申请书。支持 9 个资助机构。社区贡献 by [@dengzhe-hou](https://github.com/dengzhe-hou)
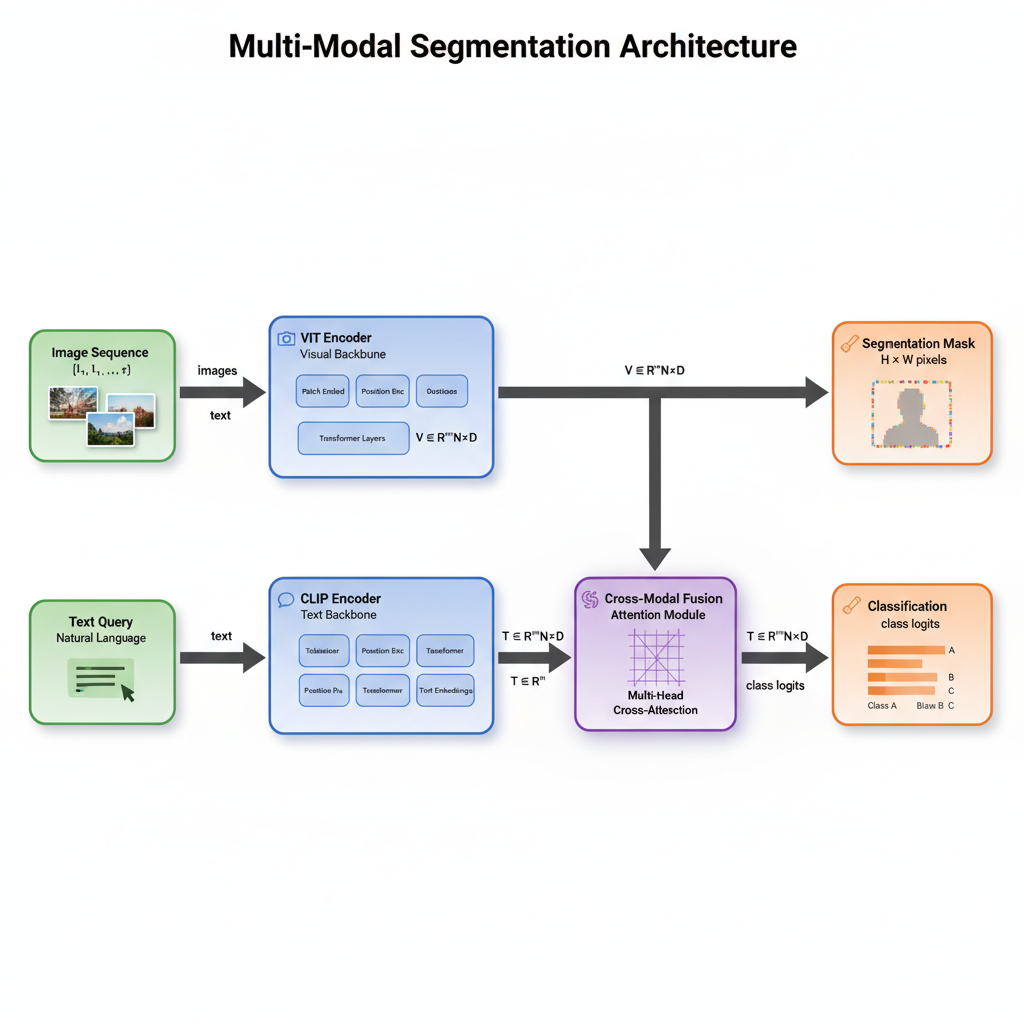
- **2026-03-18** —  🎨 **[`paper-illustration`](skills/paper-illustration/SKILL.md)** — AI 生成架构图(Gemini),集成到工作流 3。基于 [PaperBanana](https://github.com/dwzhu-pku/PaperBanana)。社区贡献 by [@Joseph-li343](https://github.com/Joseph-li343)
预览 demo
更早的更新(2026-03-12 — 2026-03-16)
- **2026-03-16** — 🔬 **[`research-refine`](skills/research-refine/SKILL.md)** + [`experiment-plan`](skills/experiment-plan/SKILL.md) — 模糊 idea → 问题锚点明确的方案 + claim-driven 实验路线图。社区贡献 by [@zjYao36](https://github.com/zjYao36)
- **2026-03-16** — 🇨🇳 **[阿里百炼 Coding Plan 接入指南](docs/ALI_CODING_PLAN_GUIDE.md)** — 一个 API Key、4 款模型。社区贡献 by [@tianhao909](https://github.com/tianhao909)
- **2026-03-15** — 🔀 **自带模型!** [任意 OpenAI 兼容 API](#-替代模型组合) 均可作为审查器
- **2026-03-15** — 🐾 **[OpenClaw 适配指南](docs/OPENCLAW_ADAPTATION.md)** — 在 OpenClaw 中使用 ARIS 工作流
- **2026-03-15** — 📐 **[`proof-writer`](skills/proof-writer/SKILL.md)** + 📚 **反幻觉引用**(DBLP/CrossRef)
- **2026-03-14** — 📱 [飞书集成](#-飞书lark-集成可选):三种模式(关闭/推送/交互)
- **2026-03-13** — 🛑 Human-in-the-loop:`AUTO_PROCEED` 检查点
- **2026-03-12** — 🔗 Zotero + Obsidian + arXiv/Scholar 多源文献检索
- **2026-03-12** — 🚀 三大工作流端到端贯通 + 📝 论文写作流水线(4/10 → 8.5/10)
## 🚀 快速开始
```bash
# 1. 安装 skills
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cp -r Auto-claude-code-research-in-sleep/skills/* ~/.claude/skills/
# 2. 配置 Codex MCP(review 类 skill 需要)
npm install -g @openai/codex
codex setup # 提示选模型时选 gpt-5.4
claude mcp add codex -s user -- codex mcp-server
# 3. 在 Claude Code 中使用
claude
> /idea-discovery "你的研究方向" # 工作流 1 — 方向要具体!不要 "NLP",要 "离散扩散语言模型的 factorized gap"
> /experiment-bridge # 工作流 1.5 — 有计划了?实现 + 部署 + 收结果
> /auto-review-loop "你的论文主题或范围" # 工作流 2:审稿 → 修复 → 再审,一夜完成
> /paper-writing "NARRATIVE_REPORT.md" # 工作流 3:研究叙事 → 精修 PDF
> /rebuttal "paper/ + reviews" — venue: ICML # 工作流 4:解析 review → 起草 rebuttal → follow-up
> /research-pipeline "你的研究方向" # 全流程:工作流 1 → 1.5 → 2 → 3 端到端
```
> 📝 **模板可用!** 见 [`templates/`](templates/) 目录——每个工作流都有现成输入模板:[研究简报](templates/RESEARCH_BRIEF_TEMPLATE.md)(工作流 1)、[实验计划](templates/EXPERIMENT_PLAN_TEMPLATE.md)(工作流 1.5)、[研究叙事](templates/NARRATIVE_REPORT_TEMPLATE.md)(工作流 3)、[论文大纲](templates/PAPER_PLAN_TEMPLATE.md)(工作流 3)。
> **提示:** 所有流水线行为均可通过内联参数配置——在命令后追加 `— key: value`:
>
> | 参数 | 默认 | 说明 |
> |------|------|------|
> | `AUTO_PROCEED` | `true` | 在 idea 选择关卡自动继续。设为 `false` 可在花 GPU 前手动挑选 idea |
> | `human checkpoint` | `false` | 每轮 review 后暂停,让你查看分数、给出修改意见、跳过特定修复或提前终止 |
> | `sources` | `all` | 搜索哪些文献源:`zotero`、`obsidian`、`local`、`web`、`semantic-scholar`、`all`。`semantic-scholar` 需显式指定 |
> | `arxiv download` | `false` | 文献调研时下载最相关的 arXiv PDF。为 `false` 时仅获取元数据(标题、摘要、作者) |
> | `DBLP_BIBTEX` | `true` | 从 [DBLP](https://dblp.org)/[CrossRef](https://www.crossref.org) 获取真实 BibTeX,替代 LLM 生成。杜绝幻觉引用。零安装 |
> | `code review` | `true` | GPT-5.4 xhigh 部署前审查实验代码。设 `false` 跳过 |
> | `wandb` | `false` | 自动给实验脚本加 W&B 日志。设 `true` + 在 CLAUDE.md 配 `wandb_project`。`/monitor-experiment` 从 W&B 拉训练曲线 |
> | `illustration` | `gemini` | 工作流 3 AI 作图:`gemini`(默认,需 `GEMINI_API_KEY`,[获取](https://aistudio.google.com/apikey))、`mermaid`(免费)、`false`(跳过) |
> | `venue` | `ICLR` | 目标会议:`ICLR`、`NeurIPS`、`ICML`、`CVPR`、`ACL`、`AAAI`、`ACM`、`IEEE_JOURNAL`、`IEEE_CONF`。决定 LaTeX 样式和页数限制 |
> | `base repo` | `false` | GitHub 仓库 URL,克隆作为实验基础代码(如 `— base repo: https://github.com/org/project`)。没有代码?基于开源项目开发 |
> | `compact` | `false` | 生成精简摘要文件(`IDEA_CANDIDATES.md`、`findings.md`、`EXPERIMENT_LOG.md`),适合短 context 模型和 session 恢复 |
> | `ref paper` | `false` | 参考论文(PDF 路径或 arXiv URL)。先总结论文,再基于它找 idea。配合 `base repo` 实现"论文+代码"工作流 |
>
> ```
> /research-pipeline "你的课题" — AUTO_PROCEED: false # 在 idea 选择关卡暂停
> /research-pipeline "你的课题" — human checkpoint: true # 每轮 review 后暂停,可给修改意见
> /research-pipeline "你的课题" — sources: zotero, web # 只搜 Zotero + 网络(跳过本地 PDF)
> /research-pipeline "你的课题" — arxiv download: true # 文献调研时下载最相关的 arXiv PDF
> /research-pipeline "你的课题" — AUTO_PROCEED: false, human checkpoint: true # 组合使用
> ```
> **重要:** Codex MCP 使用的模型取决于 `~/.codex/config.toml`,而非 skill 文件中的设置。请确认其中写的是 `model = "gpt-5.4"`(推荐)。其他可用模型:`gpt-5.3-codex`、`gpt-5.2-codex`、`o3`。运行 `codex setup` 或直接编辑该文件。
> **想让 Codex 执行、Claude Code 审稿?** 见 [`docs/CODEX_CLAUDE_REVIEW_GUIDE_CN.md`](docs/CODEX_CLAUDE_REVIEW_GUIDE_CN.md)。这条路径会先安装基础 `skills/skills-codex/*`,再叠加 `skills/skills-codex-claude-review/*`,并通过本地 `claude-review` MCP bridge 转发 review-heavy skill 的审稿请求。
> **想让 Codex 执行、Gemini 在本地做审稿?** 见 [`docs/CODEX_GEMINI_REVIEW_GUIDE_CN.md`](docs/CODEX_GEMINI_REVIEW_GUIDE_CN.md) 和[英文版](docs/CODEX_GEMINI_REVIEW_GUIDE.md)。这条路径会先安装基础 `skills/skills-codex/*`,再叠加 `skills/skills-codex-gemini-review/*`,并通过本地 `gemini-review` MCP bridge 转发 reviewer-aware 预定义 skills 的审稿请求,默认 direct Gemini API。
详见[完整安装指南](#%EF%B8%8F-安装)和[替代模型组合](#-替代模型组合)(无需 Claude/OpenAI API)。
## ✨ 功能亮点
- 📊 **31 个可组合 skill** — 自由混搭,或串联为完整流水线(`/idea-discovery`、`/auto-review-loop`、`/paper-writing`、`/research-pipeline`)
- 🔍 **文献 & 查新** — 多源论文搜索(**[Zotero](#-zotero-集成可选)** + **[Obsidian](#-obsidian-集成可选)** + **本地 PDF** + arXiv/Scholar)+ 跨模型查新验证
- 💡 **Idea 发现** — 文献调研 → 头脑风暴 8-12 个 idea → 查新 → GPU pilot 实验 → 排名报告
- 🔄 **自动 review 循环** — 4 轮自主审稿,一夜从 5/10 提升到 7.5/10,自动跑 20+ 组 GPU 实验
- 📝 **论文写作** — 研究叙事 → 大纲 → 图表 → LaTeX → PDF → 自动审稿(4/10 → 8.5/10),一条命令。通过 [DBLP](https://dblp.org)/[CrossRef](https://www.crossref.org) 反幻觉引用
- 🤖 **跨模型协作** — Claude Code 执行,GPT-5.4 xhigh 审稿。对抗式而非自我博弈
- 📝 **Peer Review** — 以审稿人视角审阅他人论文,结构化打分 + meta-review
- 🖥️ **审稿驱动实验** — GPT-5.4 说"跑个消融实验",Claude Code 自动写脚本、rsync 到服务器、screen 启动、收结果、写回论文。只需在 `CLAUDE.md` 里配好服务器信息([配置指南](#%EF%B8%8F-gpu-服务器配置自动实验用))
- 🔀 **灵活模型** — 默认 Claude × GPT-5.4,也支持 [GLM、MiniMax、Kimi、LongCat、DeepSeek 等](#-替代模型组合)——无需 Claude 或 OpenAI API
- 🛑 **Human-in-the-loop** — 关键决策点可配置检查点。`AUTO_PROCEED=true` 全自动,`false` 逐步审批
- 📱 **[飞书通知](#-飞书lark-集成可选)** — 三种模式:**关闭(默认,强烈建议大多数用户保持关闭)**、仅推送(webhook,手机收通知)、双向交互(在飞书里审批/回复)。未配置时零影响
预览:推送卡片(群聊)& 交互对话(私聊)
**仅推送** — 群聊彩色卡片(实验完成、checkpoint、报错、流水线结束):
 **双向交互** — 与 Claude Code 私聊(审批/拒绝、自定义指令):
**双向交互** — 与 Claude Code 私聊(审批/拒绝、自定义指令):
- 🧩 **可扩展** — 欢迎贡献领域专用 skill!添加一个 `SKILL.md` 即可提 PR。参见[社区 skills](#-全部-skills),如 [`dse-loop`](skills/dse-loop/SKILL.md)(体系结构/EDA)
---
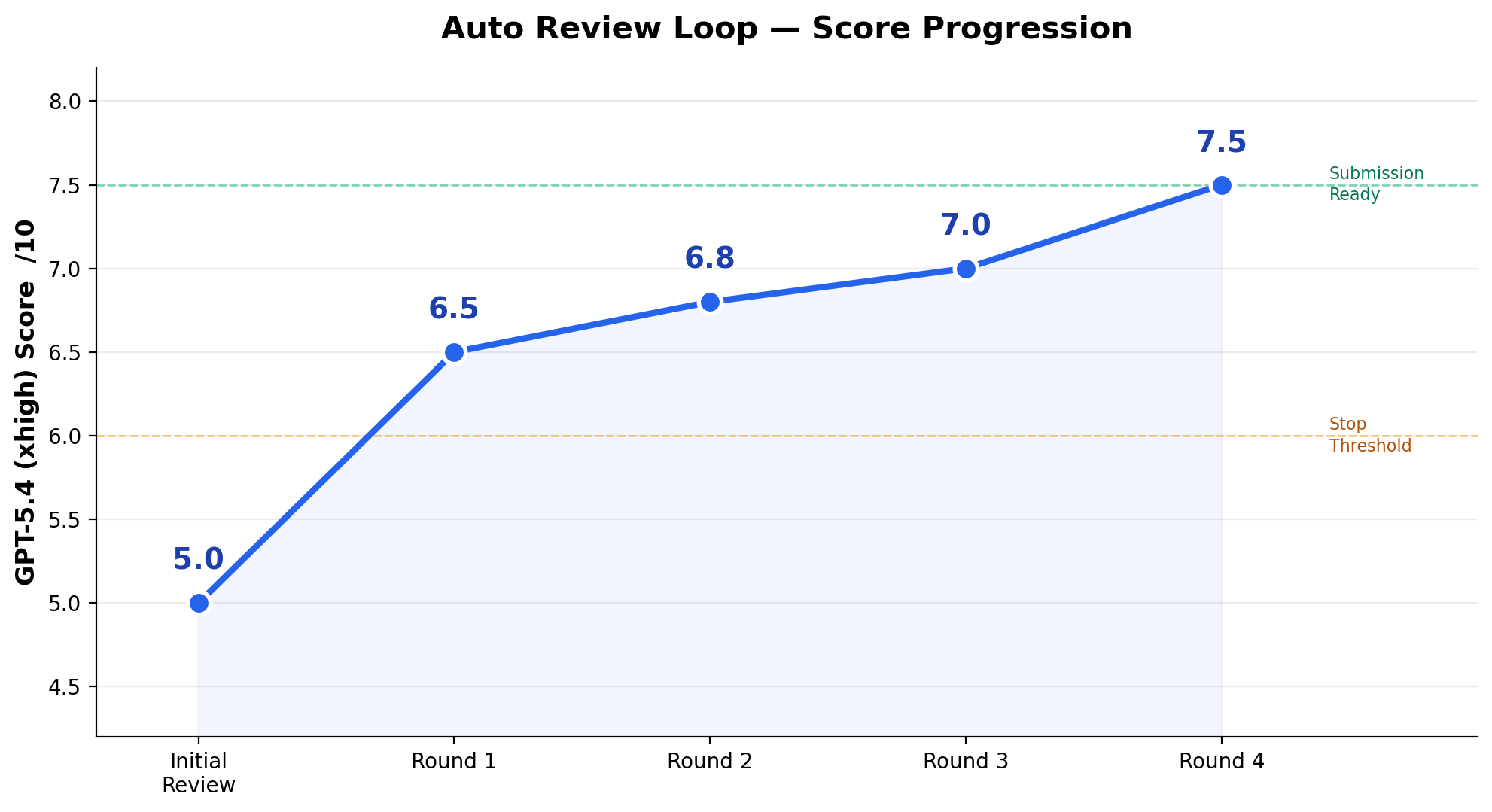
## 📈 真实运行效果
某 ML 研究项目上的 4 轮自动循环,从 borderline reject 到可投稿:
| 轮次 | 分数 | 发生了什么 |
|------|------|-----------|
| 初始 | 5.0/10 | Borderline reject |
| 第 1 轮 | 6.5/10 | 补了标准指标,发现指标脱钩 |
| 第 2 轮 | 6.8/10 | 核心声明不可复现,转换叙事 |
| 第 3 轮 | 7.0/10 | 大规模 seed 研究推翻了主要改善声明 |
| 第 4 轮 | **7.5/10** ✅ | 诊断证据确立,**可以投稿** |
循环自主跑了 **20+ 个 GPU 实验**,重写了论文叙事框架,杀掉了经不住检验的声明——全程无人干预。
## 🏆 社区实操 — 用 ARIS 完成的论文
ARIS 全流程完成的真实项目。**如果你也用 ARIS 完成了论文,欢迎提 Issue 或 PR 告诉我们!**
| 论文 | 评分 | 会议 | 作者 | 备注 |
|------|:---:|------|------|------|
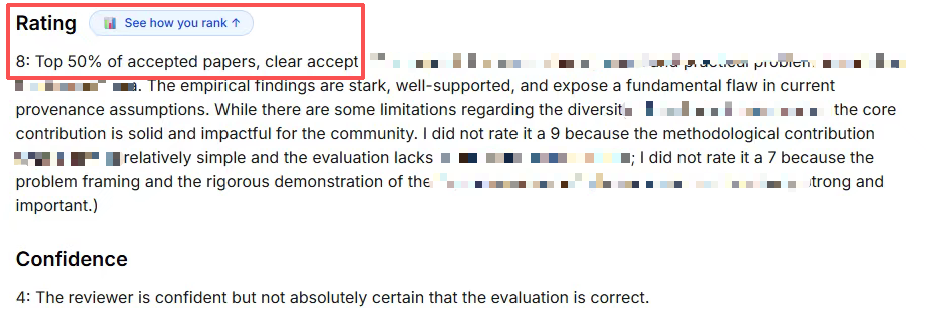
| CS 论文 | **8/10** — "Top 50% of accepted papers, clear accept" | CS 会议 | [@DefanXue](https://github.com/DefanXue) & [@Monglitay](https://github.com/Monglitay) | ARIS 全流程:idea → 实验 → auto-review → 论文写作。审稿人:"empirical findings are stark, well-supported" |
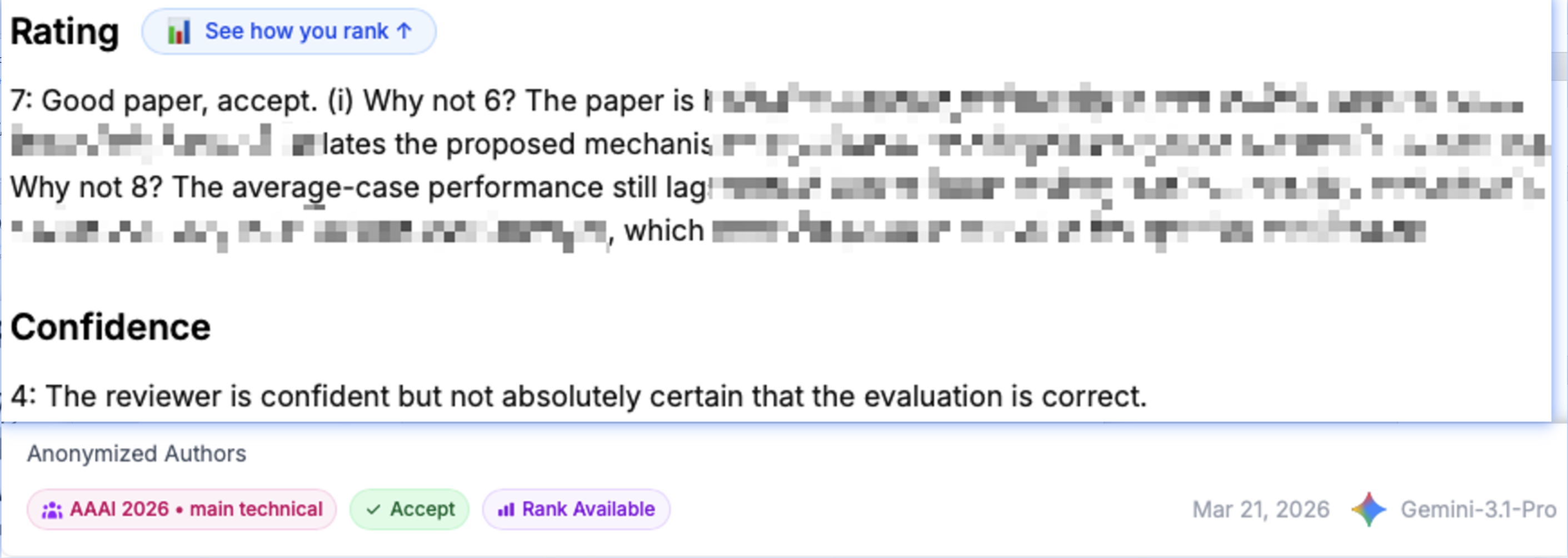
| AAAI 2026 论文 | **7/10** — "Good paper, accept" | AAAI 2026 Main Technical | [@xinbo820-web](https://github.com/xinbo820-web) | 纯 **Codex CLI**(ARIS-Codex skills)。已被 AAAI 2026 接收 |
审稿截图
🎉 社区 Skills(11 个) — 点击展开
| 名称 | 领域 | 描述 | Codex MCP? |
|------|------|------|-----------|
| 🔬 [`research-refine`](skills/research-refine/SKILL.md) | 通用 | 把模糊 idea 精炼成问题锚点明确、可实现的方法方案 | 是 |
| 🧪 [`experiment-plan`](skills/experiment-plan/SKILL.md) | 通用 | claim-driven 实验路线图,含 ablation、预算和执行顺序 | 否 |
| 🧭 [`research-refine-pipeline`](skills/research-refine-pipeline/SKILL.md) | 通用 | 一条龙:`/research-refine` → `/experiment-plan` | 是 |
| 📝 [`grant-proposal`](skills/grant-proposal/SKILL.md) | 通用 | 基金申请书(科研費/NSF/国自然/ERC/DFG/SNSF/ARC/NWO) | 是 |
| 🎤 [`paper-slides`](skills/paper-slides/SKILL.md) | 通用 | 会议演讲幻灯片(beamer → PDF + PPTX),含完整演讲稿、speaker notes、Q&A 预案 | 是 |
| 📐 [`proof-writer`](skills/proof-writer/SKILL.md) | ML 理论 | 严格定理/引理证明撰写——可行性分类、依赖图谱 | 否 |
| 📡 [`comm-lit-review`](skills/comm-lit-review/SKILL.md) | 通信 / 无线 | 通信领域文献检索——IEEE/ACM 优先、venue 分层、PHY/MAC/NTN 分类 | 否 |
| 🏗️ [`dse-loop`](skills/dse-loop/SKILL.md) | 体系结构 / EDA | 自动设计空间探索——迭代调参(gem5、Yosys 等) | 否 |
| 🤖 [`idea-discovery-robot`](skills/idea-discovery-robot/SKILL.md) | 机器人 / 具身智能 | 工作流 1 适配版——按 embodiment、sim2real、安全约束筛选 idea | 是 |
| 🖼️ [`paper-poster`](skills/paper-poster/SKILL.md) | 通用 | 会议海报(article + tcbposter → A0/A1 PDF + 组件化 PPTX + SVG),会议配色、视觉审稿循环、Codex MCP 评审 | 是 |
| 📐 [`mermaid-diagram`](skills/mermaid-diagram/SKILL.md) | 通用 | Mermaid 图表(20+ 种类型)——`paper-illustration` 的免费替代,无需 API key | 否 |
🌐 外部项目 & 文档(7 个) — 点击展开
| 名称 | 领域 | 描述 |
|------|------|------|
| 🛡️ [open-source-hardening-skills](https://github.com/zeyuzhangzyz/open-source-hardening-skills) | DevOps / 开源 | 10 个 skill 流水线,将研究代码加固为生产级开源项目 |
| 📊 [CitationClaw](https://github.com/VisionXLab/CitationClaw) | 通用 | 引用影响力分析——论文标题 → 引用爬取、学者识别、HTML 报告 |
| 🚀 [Antigravity 适配指南](docs/ANTIGRAVITY_ADAPTATION_CN.md) | 通用 | 在 [Google Antigravity](https://antigravity.google/) 中使用 ARIS skills——原生 SKILL.md 支持,双模型(Claude Opus 4.6 / Gemini 3.1 Pro),MCP 配置,中[英](docs/ANTIGRAVITY_ADAPTATION.md)文指南 |
| 🐾 [OpenClaw 适配指南](docs/OPENCLAW_ADAPTATION.md) | 通用 | 在 [OpenClaw](https://github.com/All-Hands-AI/OpenHands) 中使用 ARIS 工作流 |
| 🖱️ [Cursor 适配指南](docs/CURSOR_ADAPTATION.md) | 通用 | 在 [Cursor](https://www.cursor.com/) 中使用 ARIS skills |
| 🖥️ [Trae 适配指南](docs/TRAE_ARIS_RUNBOOK_CN.md) | 通用 | 在 [Trae](https://www.trae.ai/)(字节跳动 AI IDE)中使用 ARIS skills |
| 🎨 [`paper-illustration`](skills/paper-illustration/SKILL.md) | 通用 | AI 生成架构图(Gemini)。基于 [PaperBanana](https://github.com/dwzhu-pku/PaperBanana),集成到工作流 3 |
| 🤖 [`skills-codex`](skills/skills-codex/) | 通用 | 主线科研技能的 Codex CLI 同步包,已补入 `training-check`、`result-to-claim`、`ablation-planner`、`rebuttal`,并附带 `shared-references/` 支持目录 |
| 🎛️ [auto-hparam-tuning](https://github.com/zxh0916/auto-hparam-tuning) | 通用 | 自动超参调优——AI agent 读项目、规划策略、跑实验、分析 TensorBoard、从结果中学习。基于 Hydra |
## 🔄 工作流
所有 Skills 组成完整科研流水线。四个工作流可以单独使用,也可以串联:
- **探索新方向(比如写 survey)?** 从工作流 1 开始 → `/idea-discovery`
- **有计划了,需要实现和跑实验?** 工作流 1.5 → `/experiment-bridge`
- **已有结果,需要迭代改进?** 工作流 2 → `/auto-review-loop`
- **准备写论文了?** 工作流 3 → `/paper-writing`(或分步:`/paper-plan` → `/paper-figure` → `/paper-write` → `/paper-compile` → `/auto-paper-improvement-loop`)
- **全流程?** 工作流 1 → 1.5 → 2 → 3 → `/research-pipeline`,从文献调研一路到投稿
> ⚠️ **重要提醒:** 这些工具加速科研,但不能替代你自己的思考。生成的 idea 一定要用你的领域知识审视,质疑其假设,最终决策权在你手上。最好的研究 = 人的洞察 + AI 的执行力,而不是全自动流水线。
### 完整流程 🚀
```
/research-lit → /idea-creator → /novelty-check → /research-refine → /experiment-bridge → /auto-review-loop → /paper-plan → /paper-figure → /paper-write → /auto-paper-improvement-loop → 投稿
(调研文献) (找idea) (查新验证) (打磨方案) (实现+部署) (自动改到能投) (大纲) (作图) (LaTeX+PDF) (审稿×2 + 格式检查) (搞定!)
├────────────── 工作流 1:找 Idea + 方案精炼 ──────────────┤ ├─ 工作流 1.5 ─┤ ├── 工作流 2 ──┤ ├───────────────── 工作流 3:论文写作 ─────────────────────┤
```
📝 **博客:** [梦中科研全流程开源](http://xhslink.com/o/2iV33fYoc7Q)
### 工作流 1:Idea 发现与方案精炼 🔍
> "这个领域最新进展是什么?哪里有 gap?怎么解决?"
还没有具体 idea?给一个研究方向就行——`/idea-discovery` 搞定剩下的:
1. 📚 **调研**全景(最新论文、开放问题、反复出现的局限性)
2. 🧠 **头脑风暴** 8-12 个具体 idea(GPT-5.4 xhigh)
3. 🔍 **初筛**可行性、算力成本、快速查新
4. 🛡️ **深度验证** top idea(完整查新 + devil's advocate review)
5. 🧪 **并行 pilot 实验**(top 2-3 个 idea 分别上不同 GPU,30 分钟 - 2 小时)
6. 🏆 **按实验信号排序**——有正信号的 idea 排前面
7. 🔬 **精炼方案**——冻结问题锚点,通过 GPT-5.4 迭代 review 打磨方法
8. 🧪 **规划实验**——claim-driven 实验路线图,含 ablation、预算和执行顺序
输出 `IDEA_REPORT.md`(排名后的 idea)+ `refine-logs/FINAL_PROPOSAL.md`(精炼后的方案)+ `refine-logs/EXPERIMENT_PLAN.md`(实验路线图)。失败的 idea 也记录在案,避免重复踩坑。
**涉及 Skills:** `research-lit` + `idea-creator` + `novelty-check` + `research-review` + `research-refine-pipeline`
> 💡 **一键调用:** `/idea-discovery "你的研究方向"` 自动跑完整个工作流 1。
> 🔄 **人在回路中:** 每个阶段都会展示结果等你反馈。不满意?告诉它哪里不对——调整 prompt 重新生成。信任默认选择?它会自动带着最优方案继续。你决定参与多深。
> ⚙️ Pilot 实验预算(最大时长、超时、GPU 总预算)均可配置——见[自定义](#%EF%B8%8F-自定义)。
```
1. /research-lit "discrete diffusion models" ← Zotero→Obsidian→本地→网络,整理全景
/research-lit "topic" — sources: zotero, web ← 或指定只搜部分源
/research-lit "topic" — arxiv download: true ← 同时下载最相关的 arXiv PDF
2. /idea-creator "DLLMs post training" ← 自动生成 8-12 个 idea,筛选排序
3. 选 top 2-3 个 idea
4. /novelty-check "top idea" ← 查新:有没有人做过?
5. /research-review "top idea" ← 让外部 LLM 批判你的想法
6. /research-refine "top idea" ← 冻结问题锚点 + 精炼方法
7. /experiment-plan ← claim-driven 实验路线图
8. /run-experiment → /auto-review-loop ← 闭环!
```
📝 **博客:** [Claude Code 两月 NeurIPS 指北](http://xhslink.com/o/7IvAJQ41IBA)
### 工作流 1.5:实验桥接 🔗
> "我有计划了,帮我实现代码、部署实验、拿到初始结果。"
已有实验计划(来自工作流 1 或自己写的)?`/experiment-bridge` 一键搞定:
1. 📋 **解析**实验计划(`refine-logs/EXPERIMENT_PLAN.md`)
2. 💻 **实现**实验脚本(复用已有代码,加 argparse/logging/seed)
3. 🔍 **GPT-5.4 代码审查** — 跨模型 review 在浪费 GPU 前抓逻辑 bug(`code review: true` 默认开启)
4. ✅ **Sanity check** — 先跑最小实验,发现运行时 bug
5. 🚀 **部署**完整实验到 GPU(`/run-experiment`)
6. 📊 **收集**初始结果,更新实验 tracker
```
┌─────────────────────────────────────────────────────────────────┐
│ 工作流 1.5:实验桥接 │
│ │
│ EXPERIMENT_PLAN.md │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Claude │────▶│ GPT-5.4 │────▶│ Sanity │ │
│ │ Code │ │ xhigh │ │ Check │ │
│ │ 写代码 │ │ 审查代码 │ │ (1 GPU) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 收集 │◀────│ 监控进度 │◀────│ 部署到 │ │
│ │ 结果 │ │ (+ W&B) │ │ GPU │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ 准备好进入 /auto-review-loop │
└─────────────────────────────────────────────────────────────────┘
```
**涉及 Skills:** `experiment-bridge` + `run-experiment` + `monitor-experiment`
> 💡 **一键调用:** `/experiment-bridge` 自动读取 `refine-logs/EXPERIMENT_PLAN.md`。也可指定:`/experiment-bridge "my_plan.md"`。
> ⚙️ `CODE_REVIEW`、`AUTO_DEPLOY`、`SANITY_FIRST`、`MAX_PARALLEL_RUNS` 均可配置——见[自定义](#%EF%B8%8F-自定义)。
### 工作流 2:自动科研循环 🔁(睡一觉醒来看结果)
> "帮我 review 论文,修复问题,循环到通过为止。"
>
> GPT-5.4 审稿 → 定位弱点 → 建议实验 → Claude Code 自动写脚本、部署到 GPU、监控结果、改写论文——你睡觉就行。只需在 `CLAUDE.md` 里配好[GPU 服务器信息](#%EF%B8%8F-gpu-服务器配置自动实验用)。
**涉及 Skills:** `auto-review-loop` + `research-review` + `novelty-check` + `run-experiment` + `analyze-results` + `monitor-experiment`
> 💡 **一键调用:** `/auto-review-loop "你的论文主题"` 自动跑完整个工作流 2。
>
> **传什么参数?** 简短的主题或范围就够——skill 会自动读取项目中的叙事文档(`NARRATIVE_REPORT.md`)、memory 文件、实验结果和历史 review,为 GPT-5.4 组装完整上下文。示例:
> - `/auto-review-loop "离散扩散语言模型的 factorized gap"` — 宽泛主题,skill 自动搜集
> - `/auto-review-loop "重点看第 3-5 节,CRF 结果偏弱"` — 指定范围 + 提示
> - `/auto-review-loop` — 也行:skill 读项目文件自动推断主题
```
外部 LLM 评审 → Claude Code 实现修复 → /run-experiment 部署 → 收结果 → 再评审 → 循环
↑ 需要新方向时自动 /novelty-check 查新
```
用法:
```
> /auto-review-loop 我的 diffusion model 论文
```
**🛡️ 关键安全机制:**
- 🔒 **MAX_ROUNDS = 4** — 防止无限循环;达到分数阈值时提前停止
- ⏱️ **> 4 GPU-hour 的实验自动跳过** — 不会启动超大实验,标记为"需人工跟进"
- 🧠 **优先改叙事而非跑新实验** — 同样能解决问题时,选择成本更低的路径
- 🪞 **不隐藏弱点** — 明确规则:"不要隐藏弱点来骗高分"
- 🔧 **先修后审** — 必须实现修复后再重新 review,不能只承诺修
- 💾 **上下文压缩恢复** — 每轮结束后持久化状态到 `REVIEW_STATE.json`。如果上下文窗口满了触发自动 compact,工作流会从状态文件恢复断点继续——无需人工干预
> ⚙️ MAX_ROUNDS、分数阈值、GPU 限制均可配置——见[自定义](#%EF%B8%8F-自定义)。
📝 **博客:** [开源 | 睡觉 Claude 自动跑实验改文](http://xhslink.com/o/5cBMTDigNXz)
### 工作流 3:论文写作流水线 📝
> "把我的研究报告变成可投稿的 PDF。" 需要本地 LaTeX 环境——见[前置条件](#前置条件)。
**涉及 Skills:** `paper-plan` + `paper-figure` + `paper-write` + `paper-compile` + `auto-paper-improvement-loop` +(投稿后)`paper-poster` + `paper-slides`
> **一键调用:** `/paper-writing "NARRATIVE_REPORT.md"` 自动跑完整个工作流 3。
**输入:** 一份 `NARRATIVE_REPORT.md`,描述研究内容:声明、实验、结果、图表。叙事越详细(尤其是图表描述和定量结果),输出越好。完整示例见 [`templates/NARRATIVE_REPORT_TEMPLATE.md`](templates/NARRATIVE_REPORT_TEMPLATE.md)。
**输出:** 一个可投稿的 `paper/` 目录,含 LaTeX 源码、干净的 `.bib`(仅含实际引用)、编译好的 PDF。
```
NARRATIVE_REPORT.md ──► /paper-plan ──► /paper-figure ──► /paper-write ──► /paper-compile
(研究叙事) (大纲+矩阵) (图表+LaTeX) (逐节LaTeX) (编译PDF)
```
```
典型流程:
1. 写 NARRATIVE_REPORT.md(来自工作流 2 的结果)
2. /paper-plan — 生成 claims-evidence 矩阵 + 分节计划
3. /paper-figure — 生成对比表、训练曲线等图表
4. /paper-write — 逐 section 生成 LaTeX(含 bib 清理、de-AI 打磨)
5. /paper-compile — 编译 PDF、修复错误、页数验证
6. /auto-paper-improvement-loop — 内容审稿 ×2 + 格式合规检查
```
**核心特性:**
- 📐 **Claims-Evidence 矩阵** — 每个声明映射到证据,每个实验支撑一个声明
- 📊 **自动图表生成** — 从 JSON 数据生成折线图、柱状图、对比表
- 🧹 **Bib 自动清理** — 过滤未引用条目(实测 948→215 行)。通过 [DBLP](https://dblp.org)/[CrossRef](https://www.crossref.org) 获取真实 BibTeX,替代 LLM 生成
- 📄 **灵活节数** — 5-8 节按论文类型选择(理论论文常需 7 节)
- 🔍 **GPT-5.4 审稿** — 每步可选外部 LLM 审查
- ✂️ **De-AI 打磨** — 去除 AI 写作痕迹(delve、pivotal、landscape…)
- 🎯 **精确页数验证** — 基于 `pdftotext` 定位 Conclusion 结束位置
> ⚠️ **`/paper-figure` 能做什么、不能做什么:** 能自动生成**数据驱动的图表**(训练曲线、柱状图、热力图)和 **LaTeX 对比表**(从 JSON/CSV 数据)。**不能**生成架构图、流程图、模型示意图、生成样本网格——这些需要手动创建(draw.io、Figma、TikZ 等),放到 `figures/` 目录后再跑 `/paper-write`。一篇典型 ML 论文中,约 60% 的图表可自动生成,约 40% 需手动制作。
**端到端实测:** 从一份 NARRATIVE_REPORT.md 生成了一篇 9 页 ICLR 2026 理论论文(7 节、29 条引用、4 张图、2 个对比表)——零编译错误、零 undefined reference。
#### 论文自动润色循环 ✨
工作流 3 生成论文后,`/auto-paper-improvement-loop` 自动跑 2 轮 GPT-5.4 xhigh 内容审稿 → 修复 → 重编译,外加一轮格式合规检查,将粗稿自动提升到可投稿质量。
**分数变化(实测 — ICLR 2026 理论论文):**
| 轮次 | 分数 | 关键改动 |
|------|------|---------|
| Round 0 | 4/10(内容) | 基线生成论文 |
| Round 1 | 6/10(内容) | 修复假设、软化声明、重命名符号 |
| Round 2 | 7/10(内容) | 添加合成验证、强化局限性 |
| Round 3 | 5→8.5/10(格式) | 移除多余图、拆附录、压缩结论、修 overfull hbox |
**最终:正文 8 页(ICLR 限 9 页),0 个 overfull hbox,格式合规。** 3 轮共涨 4.5 分。
Round 1 修复细节(6 项)
1. **CRITICAL — 假设与模型矛盾**:有界性假设与模型的分布族不一致。改为与尾部兼容的假设,并添加正式截断桥接。
2. **CRITICAL — 理论-实验 gap**:理论假设理想化编码器,实验用学习的非线性编码器。软化 "validate" → "demonstrate practical relevance",添加明确声明。
3. **MAJOR — 缺定量指标**:添加参数量对比表(latent vs total),诚实计入系统总开销。
4. **MAJOR — 定理不自包含**:添加 "Interpretation" 段落,显式列出所有依赖。
5. **MAJOR — 新颖性声明过宽**:将宽泛的 "首个收敛保证" 精确限定到具体成立条件。
6. **MAJOR — 符号冲突**:重命名一个与另一关键变量冲突的符号。添加 Notation 段。
Round 2 修复细节(4 项)
1. **MAJOR — 缺理论验证实验**:添加合成验证子节,在受控条件下直接测试两个核心理论预测。
2. **MAJOR — 声明仍然过强**:将强等价声明替换为适当的 hedge 语言,全文统一。
3. **MAJOR — 非正式理论论证**:将非正式论证正式化为一个命题,给出显式误差界。
4. **MINOR — 局限性不足**:扩展为显式列出所有假设,承认缺少标准评估指标。
Round 3 格式修复(8 项)
1. 移除多余的 hero figure(省 ~0.7 页)
2. 压缩结论 15→9 行
3. 合成验证移至附录 A
4. 对比表格移至附录 B
5. 修复 overfull hbox (85pt),用 `\resizebox`
6. 添加紧凑 float spacing(`\captionsetup`、`\textfloatsep`)
7. Introduction 中行内化居中问题块
8. 收紧 `itemize` 环境间距
---
## 🧰 全部 Skills
### 🚀 全流程
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 🏗️ [`research-pipeline`](skills/research-pipeline/SKILL.md) | **端到端**:工作流 1 → 1.5 → 2 → 3,从研究方向到投稿 | 是 |
### 🔍 工作流 1:Idea 发现与方案精炼
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 🔭 **[`idea-discovery`](skills/idea-discovery/SKILL.md)** | **流水线编排** — 按顺序调用以下全部 skill | 是 |
| ├ 📚 [`research-lit`](skills/research-lit/SKILL.md) | 多源文献搜索([Zotero](#-zotero-集成可选) + [Obsidian](#-obsidian-集成可选) + 本地 PDF + [arXiv API](#arxiv-集成) + 网络) | 否 |
| ├ 💡 [`idea-creator`](skills/idea-creator/SKILL.md) | 头脑风暴 8-12 个 idea,按可行性筛选,GPU pilot,按信号排序 | 是 |
| ├ 🔍 [`novelty-check`](skills/novelty-check/SKILL.md) | 多源查新 + GPT-5.4 交叉验证 | 是 |
| ├ 🔬 [`research-review`](skills/research-review/SKILL.md) | 单轮深度评审(外部 LLM,xhigh 推理) | 是 |
| └ 🧭 **[`research-refine-pipeline`](skills/research-refine-pipeline/SKILL.md)** | 方法精炼 + 实验规划一条龙 | 是 |
| ├ 🔬 [`research-refine`](skills/research-refine/SKILL.md) | 冻结问题锚点 → 迭代精炼方法(最多 5 轮,≥9 分停) | 是 |
| └ 🧪 [`experiment-plan`](skills/experiment-plan/SKILL.md) | Claim-driven 实验路线图,含 ablation、预算和执行顺序 | 否 |
### 🔗 工作流 1.5:实验桥接
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 🔗 **[`experiment-bridge`](skills/experiment-bridge/SKILL.md)** | 读取实验计划 → 实现代码 → sanity check → 部署到 GPU → 收集初始结果 | 否 |
| ├ 🚀 [`run-experiment`](skills/run-experiment/SKILL.md) | 部署实验到本地(MPS/CUDA)或远程 GPU 服务器 | 否 |
| └ 👀 [`monitor-experiment`](skills/monitor-experiment/SKILL.md) | 监控实验进度、收集结果 | 否 |
### 🔁 工作流 2:自动科研循环
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 🔁 **[`auto-review-loop`](skills/auto-review-loop/SKILL.md)** | **流水线编排** — 自动 review→修复→再 review(最多 4 轮) | 是 |
| ├ 🔬 [`research-review`](skills/research-review/SKILL.md) | 深度评审(与工作流 1 共用) | 是 |
| ├ 🔍 [`novelty-check`](skills/novelty-check/SKILL.md) | 审稿人建议新方向时验证新颖性 | 是 |
| ├ 🚀 [`run-experiment`](skills/run-experiment/SKILL.md) | 部署实验到本地(MPS/CUDA)或远程 GPU 服务器 | 否 |
| ├ 📊 [`analyze-results`](skills/analyze-results/SKILL.md) | 分析实验结果、统计、生成对比表 | 否 |
| └ 👀 [`monitor-experiment`](skills/monitor-experiment/SKILL.md) | 监控实验进度、收集结果 | 否 |
| 🔁 [`auto-review-loop-llm`](skills/auto-review-loop-llm/SKILL.md) | 同上,但使用任意 OpenAI 兼容 API,通过 [`llm-chat`](mcp-servers/llm-chat/) MCP 服务器 | 否 |
### 📝 工作流 3:论文写作
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 📝 **[`paper-writing`](skills/paper-writing/SKILL.md)** | **流水线编排** — 按顺序调用以下全部 skill | 是 |
| ├ 📐 [`paper-plan`](skills/paper-plan/SKILL.md) | Claims-evidence 矩阵、章节结构、图表计划、引用规划 | 是 |
| ├ 📊 [`paper-figure`](skills/paper-figure/SKILL.md) | 出版级 matplotlib/seaborn 图表 + LaTeX 对比表 | 可选 |
| ├ 🎨 [`paper-illustration`](skills/paper-illustration/SKILL.md) | AI 生成架构图/方法示意图(Gemini),`illustration: true` 时启用 | 否(需 Gemini API) |
| ├ ✍️ [`paper-write`](skills/paper-write/SKILL.md) | 逐 section LaTeX 生成(ICLR/NeurIPS/ICML)。通过 DBLP/CrossRef 反幻觉 BibTeX | 是 |
| ├ 🔨 [`paper-compile`](skills/paper-compile/SKILL.md) | 编译 LaTeX 为 PDF,自动修复错误,投稿就绪检查 | 否 |
| └ 🔄 [`auto-paper-improvement-loop`](skills/auto-paper-improvement-loop/SKILL.md) | 2 轮内容审稿 + 格式检查(4/10 → 8.5/10) | 是 |
### 🛠️ 独立 / 工具类
| Skill | 功能 | Codex MCP? |
|-------|------|:---:|
| 📄 [`arxiv`](skills/arxiv/SKILL.md) | 搜索、下载、摘要 arXiv 论文。可独立使用或作为 `/research-lit` 补充 | 否 |
| 🎨 [`pixel-art`](skills/pixel-art/SKILL.md) | 生成像素风 SVG 插图,用于 README、文档或幻灯片 | 否 |
| 📱 [`feishu-notify`](skills/feishu-notify/SKILL.md) | [飞书](#-飞书lark-集成可选)推送(webhook)或双向交互。默认关闭 | 否 |
---
## ⚙️ 安装
### 前置条件
1. 安装 [Claude Code](https://docs.anthropic.com/en/docs/claude-code)
2. (仅 review 类 skill 需要)安装 [Codex CLI](https://github.com/openai/codex) 并配置为 MCP server:
```bash
npm install -g @openai/codex
claude mcp add codex -s user -- codex mcp-server
```
3. (仅工作流 3:论文写作需要)**LaTeX** 环境,含 `latexmk` 和 `pdfinfo`:
```bash
# macOS
brew install --cask mactex # 或: brew install basictex
brew install poppler # 提供 pdfinfo
# Ubuntu/Debian
sudo apt install texlive-full latexmk poppler-utils
# 验证
latexmk --version && pdfinfo -v
```
> 如果只用工作流 1 和 2(找 idea + 自动 review),不需要安装 LaTeX。
### 安装 Skills
```bash
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
# 安装全部 skills(全局可用)
cp -r skills/* ~/.claude/skills/
# 或者只安装特定 skill
cp -r skills/auto-review-loop ~/.claude/skills/
cp -r skills/research-lit ~/.claude/skills/
```
### 更新 Skills
```bash
cd Auto-claude-code-research-in-sleep
git pull
# 方案 A:全量更新(用最新版覆盖所有 skill)
cp -r skills/* ~/.claude/skills/
# 方案 B:安全更新(只加新 skill,保留你的定制)
cp -rn skills/* ~/.claude/skills/
# 方案 C:只更新指定 skill
cp -r skills/experiment-bridge ~/.claude/skills/
```
> 💡 **选哪个?** 没改过 skill 用 **A**。改过用 **B**(新 skill 会加进来,你的改动保留——但改过的文件不会收到上游 bug fix)。**C** 精确更新。
### 🌙 过夜自动运行的免确认配置(可选)
在 `.claude/settings.local.json` 中添加:
```json
{
"permissions": {
"allow": [
"mcp__codex__codex",
"mcp__codex__codex-reply",
"Write",
"Edit",
"Skill(auto-review-loop)"
]
}
}
```
🖥️ GPU 服务器配置(自动跑实验用)
当 GPT-5.4 审稿说"需要补一个消融实验"或"加一个 baseline 对比"时,Claude Code 会自动写实验脚本并部署到你的 GPU 服务器。为此,Claude Code 需要知道你的服务器环境。
在项目的 `CLAUDE.md` 中添加服务器信息:
```markdown
## 远程服务器
- SSH:`ssh my-gpu-server`(密钥免密登录)
- GPU:4x A100
- Conda 环境:`research`(Python 3.10 + PyTorch)
- 激活:`eval "$(/opt/conda/bin/conda shell.bash hook)" && conda activate research`
- 代码目录:`/home/user/experiments/`
- 后台运行用 `screen`:`screen -dmS exp0 bash -c '...'`
```
Claude Code 读到这些就知道怎么 SSH、激活环境、启动实验。GPT-5.4(审稿人)只决定**做什么实验**——Claude Code 根据你的 `CLAUDE.md` 搞定**怎么跑**。
如果你已经在 GPU 服务器上,可以添加以下到你的 `CLAUDE.md`:
```markdown
## GPU 环境
- 这台机器有直接 GPU 访问(不需要 SSH)
- GPU:4x A100 80GB
- 实验环境:`YOUR_CONDA_ENV`(Python 3.x + PyTorch)
- 激活前任何 Python 命令:`激活实验环境的命令`(uv, conda 等)
- 代码目录:`/home/YOUR_USERNAME/YOUR_CODE_DIRECTORY/`
```
**没有 GPU 服务器?** Review 和改写功能不受影响,只有需要跑实验的修复会被跳过(标记为"需人工跟进")。
📚 Zotero 集成(可选)
如果你用 [Zotero](https://www.zotero.org/) 管理论文,`/research-lit` 可以搜索你的文献库、读取标注/高亮、导出 BibTeX——全在联网搜索之前完成。
**推荐:[zotero-mcp](https://github.com/54yyyu/zotero-mcp)**(1.8k⭐,语义搜索 + PDF 标注 + BibTeX 导出)
```bash
# 安装
uv tool install zotero-mcp-server # 或: pip install zotero-mcp-server
# 添加到 Claude Code(本地 API——需要 Zotero 桌面端运行)
claude mcp add zotero -s user -- zotero-mcp -e ZOTERO_LOCAL=true
# 或使用 Web API(不需要打开 Zotero)
claude mcp add zotero -s user -- zotero-mcp \
-e ZOTERO_API_KEY=your_key -e ZOTERO_USER_ID=your_id
```
> API Key 在 https://www.zotero.org/settings/keys 获取
**启用后 `/research-lit` 新增能力:**
- 🔍 按主题搜索 Zotero 库(含语义/向量搜索)
- 📂 浏览 Collections 和 Tags
- 📝 读取你的 PDF 标注和高亮(你个人认为重要的内容)
- 📄 导出 BibTeX 供论文写作直接使用
**不用 Zotero?** 没关系——`/research-lit` 自动跳过,用本地 PDF + 网络搜索。
📓 Obsidian 集成(可选)
如果你用 [Obsidian](https://obsidian.md/) 做研究笔记,`/research-lit` 可以搜索你的 vault 中的论文总结、带标签的引用和你自己的洞察。
**推荐:[mcpvault](https://github.com/bitbonsai/mcpvault)**(760⭐,不需要打开 Obsidian,14 个工具,BM25 搜索)
```bash
# 添加到 Claude Code(指向你的 vault 路径)
claude mcp add obsidian-vault -s user -- npx @bitbonsai/mcpvault@latest /path/to/your/vault
```
**可选补充:[obsidian-skills](https://github.com/kepano/obsidian-skills)**(13.6k⭐,Obsidian CEO 维护)——让 Claude 理解 Obsidian 特有的 Markdown 格式(wikilinks、callouts、properties):
```bash
git clone https://github.com/kepano/obsidian-skills.git
cp -r obsidian-skills/.claude /path/to/your/vault/
```
**启用后 `/research-lit` 新增能力:**
- 🔍 搜索 vault 中与研究主题相关的笔记
- 🏷️ 按标签查找笔记(如 `#paper-review`、`#diffusion-models`)
- 📝 读取你的加工后总结和洞察(比原始论文更有价值)
- 🔗 沿 wikilinks 发现相关笔记
**不用 Obsidian?** 没关系——`/research-lit` 自动跳过,照常工作。
> 💡 **Zotero + Obsidian 同时使用**:很多研究者用 Zotero 存论文、Obsidian 记笔记。两个集成可以同时工作——`/research-lit` 先查 Zotero(原始论文 + 标注),再查 Obsidian(加工后笔记),再查本地 PDF,最后搜网络。
#### arXiv 集成
`/research-lit` 自动通过 arXiv API 获取结构化元数据(标题、摘要、完整作者列表、分类),比网页搜索片段更丰富。无需额外配置。
默认只获取元数据(不下载文件)。如需同时下载最相关的 PDF:
```
/research-lit "topic" — arxiv download: true # 下载 top 5 篇 PDF
/research-lit "topic" — arxiv download: true, max download: 10 # 下载至多 10 篇
```
也可使用独立的 [`/arxiv`](skills/arxiv/SKILL.md) skill 直接搜索和下载:
```
/arxiv "attention mechanism" # 搜索
/arxiv "2301.07041" — download # 下载指定论文
```
📱 飞书/Lark 集成(可选)
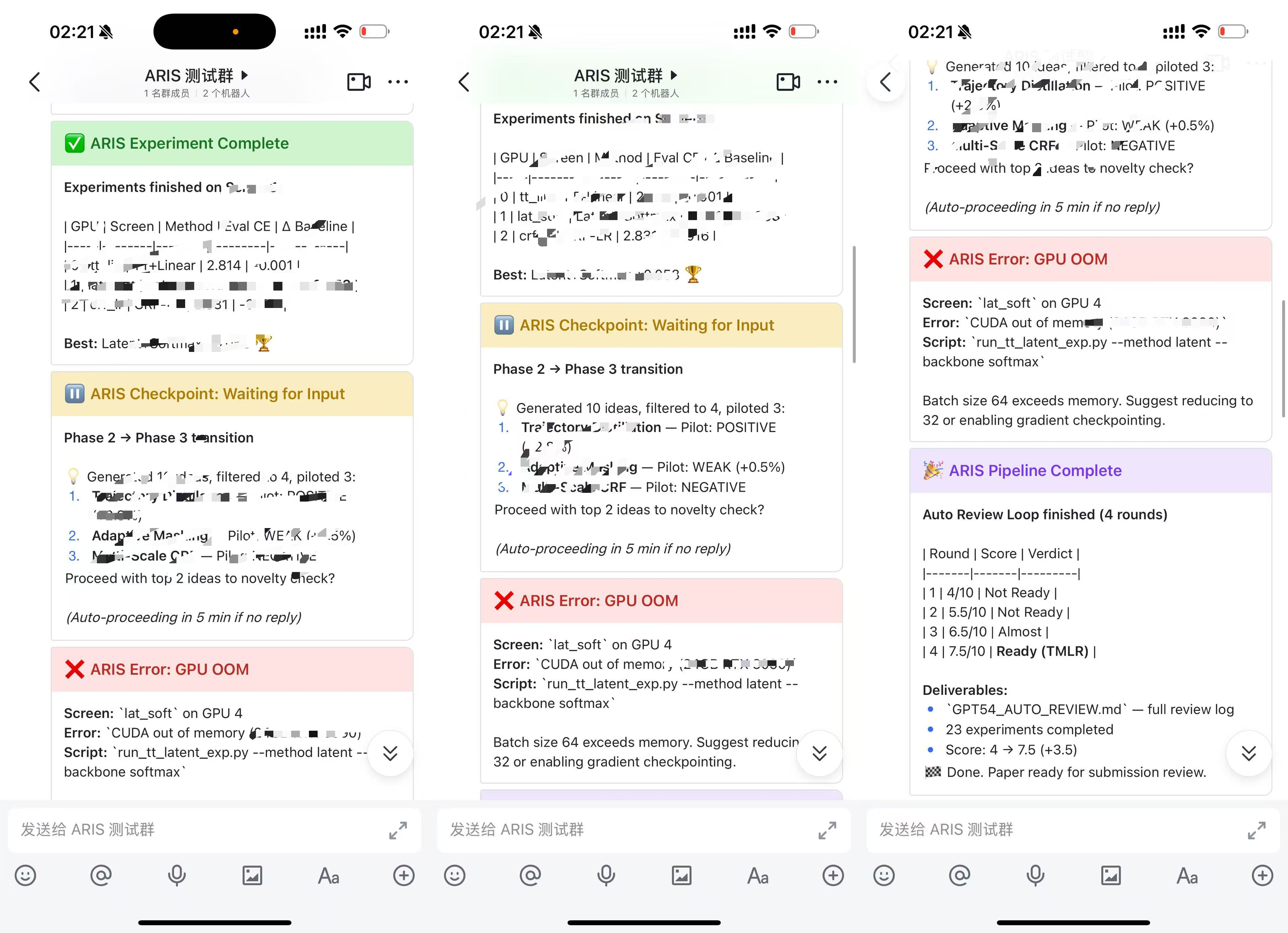
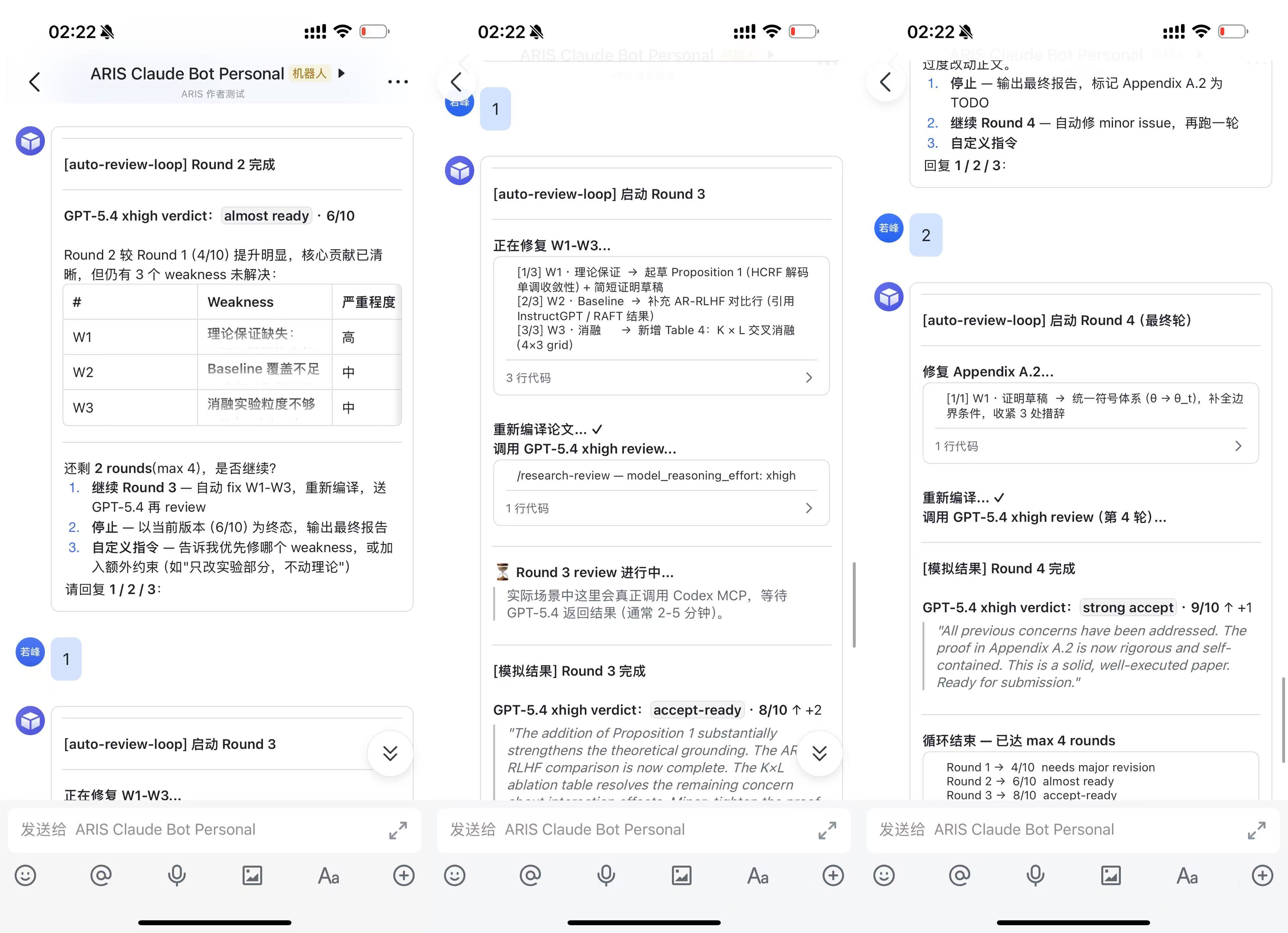
实验跑完、review 出分、checkpoint 等你审批——手机收飞书通知,不用守在终端前。
| 仅推送(群聊卡片) | 双向交互(私聊) |
|:-:|:-:|
| | |
**三种模式,按需选择:**
| 模式 | 效果 | 你需要 |
|------|------|--------|
| **关闭**(默认) | 什么都不做,纯 CLI 不变 | 什么都不用 |
| **仅推送** | 关键事件发 webhook 通知,手机收推送,不能回复 | 飞书机器人 webhook URL |
| **双向交互** | 全双工:在飞书里审批/拒绝 idea、回复 checkpoint | [feishu-claude-code](https://github.com/joewongjc/feishu-claude-code) 运行中 |
仅推送模式(5 分钟配好)
群通知,彩色富文本卡片——实验跑完、review 出分、流水线结束,手机收推送就行,不需要回复。
**第 1 步:创建飞书群机器人**
1. 打开你的飞书群(或新建一个测试群)
2. 群设置 → 群机器人 → 添加机器人 → **自定义机器人**
3. 起个名字(如 `ARIS Notifications`),复制 **Webhook 地址**
4. 安全设置:添加自定义关键词 `ARIS`(所有通知都包含这个词),或不设限制
**第 2 步:创建配置文件**
```bash
cat > ~/.claude/feishu.json << 'EOF'
{
"mode": "push",
"webhook_url": "https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_ID"
}
EOF
```
**第 3 步:测试**
```bash
curl -s -X POST "YOUR_WEBHOOK_URL" \
-H "Content-Type: application/json" \
-d '{
"msg_type": "interactive",
"card": {
"header": {"title": {"tag": "plain_text", "content": "🧪 ARIS Test"}, "template": "blue"},
"elements": [{"tag": "markdown", "content": "Push mode working! 🎉"}]
}
}'
```
群里应该出现一张蓝色卡片。之后 skill 会在关键事件自动推送富文本卡片:
| 事件 | 卡片颜色 | 内容 |
|------|---------|------|
| Review 出分 ≥ 6 | 🟢 绿色 | 分数、结论、主要 weakness |
| Review 出分 < 6 | 🟠 橙色 | 分数、结论、待修复项 |
| 实验完成 | 🟢 绿色 | 结果对比表、delta vs baseline |
| Checkpoint 等待 | 🟡 黄色 | 问题、选项、上下文 |
| 出错 | 🔴 红色 | 错误信息、建议修复方案 |
| 流水线结束 | 🟣 紫色 | 分数进展表、最终交付物 |
双向交互模式(15 分钟)
推送模式的全部功能 **加上** 通过飞书私聊与 Claude Code 双向对话。审批/拒绝 idea、回复 checkpoint、给自定义指令——全在手机上完成。
**工作方式**:推送卡片发到**群里**(所有人看到状态),交互对话发到**私聊**(你回复,Claude Code 执行)。
**第 1 步:先完成上面的推送模式配置**(两种模式并存)
**第 2 步:在[飞书开放平台](https://open.feishu.cn/app)创建应用**
1. 点击 **创建企业自建应用** → 填名称(如 `ARIS Claude Bot`)→ 创建
2. 左侧菜单 → **添加应用能力** → 勾选 **机器人**
3. 左侧 → **权限管理** → 搜索并开通以下 5 个权限:
| 权限 | Scope | 作用 |
|------|-------|------|
| `im:message` | 获取与发送单聊、群组消息 | 核心消息能力 |
| `im:message:send_as_bot` | 以应用身份发消息 | 机器人回复 |
| `im:message.group_at_msg:readonly` | 接收群聊中@机器人消息 | 群消息 |
| `im:message.p2p_msg:readonly` | **读取用户发给机器人的单聊消息** | ⚠️ **极易遗漏!** 不开这个权限,机器人能连上但永远收不到你的私聊消息 |
| `im:resource` | 获取与上传图片或文件资源 | 图片/文件 |
4. 左侧 → **事件与回调** → 选择 **长连接** 模式 → 添加事件:`im.message.receive_v1` → 保存
> ⚠️ **注意**:长连接页面可能显示"未检测到应用连接信息"——这是正常的。需要先启动桥接服务(第 3 步),再回来保存。
5. 左侧 → **版本管理与发布** → **创建版本** → 填写描述 → **提交审核**
> 个人/测试企业通常秒过审核。
**第 3 步:部署桥接服务**
```bash
git clone https://github.com/joewongjc/feishu-claude-code.git
cd feishu-claude-code
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
# 配置
cp .env.example .env
```
编辑 `.env`:
```bash
FEISHU_APP_ID=cli_your_app_id # 凭证与基础信息页面获取
FEISHU_APP_SECRET=your_app_secret # 凭证与基础信息页面获取
DEFAULT_MODEL=claude-opus-4-6 # ⚠️ 默认是 sonnet——改成 opus 效果好很多
DEFAULT_CWD=/path/to/your/project # Claude Code 的工作目录
PERMISSION_MODE=bypassPermissions # 或 "default"(需手动确认敏感操作)
```
> ⚠️ **模型很重要**:默认的 `claude-sonnet-4-6` 能用但可能无法理解复杂项目上下文。实测 `claude-opus-4-6` 首次即正确识别了 18 个 ARIS skills,而 sonnet 反复失败。
启动桥接:
```bash
python main.py
# 预期输出:
# ✅ 连接飞书 WebSocket 长连接(自动重连)...
# [Lark] connected to wss://msg-frontier.feishu.cn/ws/v2?...
```
长期运行丢 screen 里:
```bash
screen -dmS feishu-bridge bash -c 'cd /path/to/feishu-claude-code && source .venv/bin/activate && python main.py'
```
**第 4 步:保存事件配置** — 回到飞书开放平台 → 事件与回调 → 长连接应该显示"已检测到连接"→ **保存**
> 如果在桥接启动前就发布了应用版本,可能需要再创建一个新版本(如 1.0.1)并重新发布。
**第 5 步:测试私聊**
1. 在飞书里搜索机器人名称,打开私聊
2. 发送:`你好`
3. 机器人应通过 Claude Code 回复
**如果机器人不回复**:发 `/new` 重置 session,再试一次。常见问题:
| 症状 | 原因 | 解决 |
|------|------|------|
| 机器人连上了但收不到消息 | 缺少 `im:message.p2p_msg:readonly` 权限 | 开通权限 → 创建新版本 → 发布 |
| 机器人回复但不认识你的项目 | `DEFAULT_CWD` 指向错误目录 | 修改 `.env` → 重启桥接 |
| 机器人回复但不够聪明 | 使用的是 `claude-sonnet-4-6` | 改为 `claude-opus-4-6` → 重启桥接 |
| 旧 session 上下文过时 | 修改配置前的 session 被缓存 | 在聊天中发 `/new` 开始新 session |
| 保存事件时"未检测到连接" | 桥接服务还没启动 | 先启动桥接,再保存事件配置 |
**第 6 步:更新 ARIS 配置**
```bash
cat > ~/.claude/feishu.json << 'EOF'
{
"mode": "interactive",
"webhook_url": "https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_ID",
"interactive": {
"bridge_url": "http://localhost:5000",
"timeout_seconds": 300
}
}
EOF
```
现在 skill 会:
- **推送**富文本卡片到群里(状态通知,所有人可见)
- **私聊**你做决策(checkpoint 审批、继续/停止、自定义指令)
#### 哪些 skill 会发通知?
| Skill | 事件 | 推送模式 | 交互模式 |
|-------|------|----------|----------|
| `/auto-review-loop` | 每轮出分、循环结束 | 分数 + 结论 | + 等你决定继续/停止 |
| `/auto-paper-improvement-loop` | 每轮出分、全部完成 | 分数进展表 | 分数进展表 |
| `/run-experiment` | 实验已部署 | GPU 分配 + 预计时间 | GPU 分配 + 预计时间 |
| `/monitor-experiment` | 结果已收集 | 结果对比表 | 结果对比表 |
| `/idea-discovery` | 阶段切换、最终报告 | 各阶段摘要 | + 审批/拒绝 |
| `/research-pipeline` | 阶段切换、流水线结束 | 阶段摘要 | + 审批/拒绝 |
**不用飞书?** 没关系——没有 `~/.claude/feishu.json` 文件时,所有 skill 行为完全不变。零开销,零副作用。
> 💡 **其他 IM 平台**:推送模式的 webhook 模式适用于任何支持 incoming webhook 的服务(Slack、Discord、钉钉、企业微信)。只需改 `webhook_url` 和卡片格式。双向交互可参考 [cc-connect](https://github.com/chenhg5/cc-connect)(多平台桥接)或 [clawdbot-feishu](https://github.com/m1heng/clawdbot-feishu)。
## 🎛️ 自定义
Skills 就是普通的 Markdown 文件,fork 后随意改:
> 💡 **参数自动透传**:参数沿调用链自动向下传递。例如 `/research-pipeline "方向" — sources: zotero, arxiv download: true` 会将 `sources` 和 `arxiv download` 经 `idea-discovery` 一路传到 `research-lit`。你可以在任何层级设置下游参数——只需加 `— key: value`。
>
> ```
> research-pipeline ──→ idea-discovery ──→ research-lit
> ──→ experiment-bridge ──→ run-experiment
> ──→ auto-review-loop
> ──→ idea-creator
> ──→ novelty-check
> ──→ research-review
> ```
### 全流程(`research-pipeline`)
| 常量 | 默认值 | 说明 | 透传 |
|------|--------|------|:---:|
| `AUTO_PROCEED` | true | 用户不回复时自动带着最优方案继续 | → `idea-discovery` |
| `ARXIV_DOWNLOAD` | false | 搜索后自动下载最相关的 arXiv PDF | → `idea-discovery` → `research-lit` |
| `HUMAN_CHECKPOINT` | false | 设为 `true` 时每轮 review 后暂停等待确认 | → `auto-review-loop` |
| `WANDB` | false | 自动给实验脚本加 W&B 日志 | → `experiment-bridge` → `run-experiment` |
| `CODE_REVIEW` | true | GPT-5.4 部署前审查实验代码 | → `experiment-bridge` |
| `BASE_REPO` | false | GitHub 仓库 URL,克隆作为实验基础代码 | → `experiment-bridge` |
| `COMPACT` | false | 生成精简摘要文件,适合短 context 模型和 session 恢复 | → 所有工作流 |
| `REF_PAPER` | false | 参考论文(PDF 或 URL),先总结再基于它找 idea | → `idea-discovery` |
| `ILLUSTRATION` | `gemini` | AI 作图:`gemini`(默认,需 API key)、`mermaid`(免费)、`false`(跳过) | → `paper-writing` |
行内覆盖:`/research-pipeline "方向" — auto proceed: false, wandb: true, illustration: true`
### 自动 Review 循环(`auto-review-loop`)
| 常量 | 默认值 | 说明 |
|------|--------|------|
| `MAX_ROUNDS` | 4 | 最多 review→修复→再 review 轮数 |
| `POSITIVE_THRESHOLD` | 6/10 | 达到此分数自动停止(可投稿) |
| `> 4 GPU-hour 跳过` | 4h | 超过此时长的实验标记为"需人工跟进" |
### 找 Idea(`idea-discovery` / `idea-creator`)
| 常量 | 默认值 | 说明 | 透传 |
|------|--------|------|:---:|
| `PILOT_MAX_HOURS` | 2h | 单个 pilot 预估超时则跳过 | — |
| `PILOT_TIMEOUT_HOURS` | 3h | 硬超时——强制终止,收集部分结果 | — |
| `MAX_PILOT_IDEAS` | 3 | 最多并行 pilot 几个 idea | — |
| `MAX_TOTAL_GPU_HOURS` | 8h | 所有 pilot 的总 GPU 预算 | — |
| `AUTO_PROCEED` | true | 用户不回复时自动带着最优方案继续。设 `false` 则每步都等确认 | — |
| `ARXIV_DOWNLOAD` | false | 搜索后自动下载最相关的 arXiv PDF | → `research-lit` |
行内覆盖:`/idea-discovery "方向" — pilot budget: 4h per idea, sources: zotero, arxiv download: true`
### 实验桥接(`experiment-bridge`)
| 常量 | 默认值 | 说明 |
|------|--------|------|
| `CODE_REVIEW` | true | GPT-5.4 xhigh 部署前审查代码。在浪费 GPU 前抓逻辑 bug |
| `AUTO_DEPLOY` | true | 实现 + 审查后自动部署。设 `false` 可手动检查 |
| `BASE_REPO` | false | GitHub 仓库 URL,克隆作为实验基础代码 |
| `SANITY_FIRST` | true | 先跑最小实验,提前发现 bug |
| `MAX_PARALLEL_RUNS` | 4 | 最多并行部署几个实验(受可用 GPU 限制) |
| `WANDB` | false | 自动加 W&B 日志。需在 CLAUDE.md 配 `wandb_project` |
行内覆盖:`/experiment-bridge — code review: false, wandb: true`
### 文献搜索(`research-lit`)
| 常量 | 默认值 | 说明 |
|------|--------|------|
| `PAPER_LIBRARY` | `papers/`, `literature/` | 本地论文目录,搜外部之前先扫这里的 PDF |
| `MAX_LOCAL_PAPERS` | 20 | 最多扫描多少本地 PDF(每篇读前 3 页) |
| `SOURCES` | `all` | 搜索哪些源:`zotero`、`obsidian`、`local`、`web`、`all`(逗号分隔) |
| `ARXIV_DOWNLOAD` | false | 设为 `true` 时,搜索后自动下载最相关的 arXiv PDF 到 PAPER_LIBRARY |
| `ARXIV_MAX_DOWNLOAD` | 5 | `ARXIV_DOWNLOAD = true` 时最多下载的 PDF 数量 |
行内覆盖:`/research-lit "方向" — sources: zotero, web`、`/research-lit "方向" — arxiv download: true, max download: 10`
### 论文写作(`paper-write`)
| 常量 | 默认值 | 说明 |
|------|--------|------|
| `DBLP_BIBTEX` | true | 从 DBLP/CrossRef 拉取真实 BibTeX,替代 LLM 生成的条目 |
| `TARGET_VENUE` | `ICLR` | 目标会议/期刊格式:`ICLR`、`NeurIPS`、`ICML`、`CVPR`、`ACL`、`AAAI`、`ACM`、`IEEE_JOURNAL`、`IEEE_CONF` |
| `ANONYMOUS` | true | 匿名审稿模式。注意:大多数 IEEE 期刊/会议不匿名,IEEE 时设为 `false` |
| `MAX_PAGES` | 9 | 页数上限。ML 会议:正文不含参考文献。IEEE:总页数含参考文献 |
| `ILLUSTRATION` | `gemini` | AI 作图:`gemini`(默认,需 API key)、`mermaid`(免费)、`false`(跳过) |
行内覆盖:`/paper-write — target venue: NeurIPS, illustration: true`
### 通用(所有使用 Codex MCP 的 skill)
| 常量 | 默认值 | 说明 |
|------|--------|------|
| `REVIEWER_MODEL` | `gpt-5.4` | Codex MCP 调用的 OpenAI 模型。其他可选:`gpt-5.3-codex`、`gpt-5.2-codex`、`o3`。完整列表见 [supported models](https://developers.openai.com/codex/models/) |
- **Prompt 模板** — 定制评审人格和评估标准
- **`allowed-tools`** — 限制或扩展每个 skill 可用的工具
## 🔀 替代模型组合
没有 Claude / OpenAI API?可以换用其他模型——同样的跨模型架构,不同的提供商。
> ⭐ **强烈推荐使用 Claude + GPT-5.4(默认组合)。** 这是经过最充分测试、最稳定的组合。替代方案可用但可能需要调整 prompt。
| | 执行者 | 审稿人 | 需要 Claude API? | 需要 OpenAI API? | 配置指南 |
|---|--------|--------|:---:|:---:|---------|
| **默认** ⭐ | Claude Opus/Sonnet | GPT-5.4(Codex MCP) | 是 | 是 | [快速开始](#-快速开始) |
| **方案 A** | GLM-5(Z.ai) | GPT-5.4(Codex MCP) | 否 | 是 | [配置见下](#方案-a-glm--gpt) |
| **方案 B** | GLM-5(Z.ai) | MiniMax-M2.5 | 否 | 否 | [MINIMAX_MCP_GUIDE](docs/MINIMAX_MCP_GUIDE.md) |
| **方案 C** | 任意 CC 兼容 | 任意 OpenAI 兼容 | 否 | 否 | [LLM_API_MIX_MATCH_GUIDE](docs/LLM_API_MIX_MATCH_GUIDE.md) |
| **方案 D** | Kimi-K2.5 / Qwen3.5+ | GLM-5 / MiniMax-M2.5 | 否 | 否 | [ALI_CODING_PLAN_GUIDE](docs/ALI_CODING_PLAN_GUIDE.md) |
| **方案 E** 🆓 | DeepSeek-V3.1 / Qwen3-Coder | DeepSeek-R1 / Qwen3-235B | 否 | 否 | [MODELSCOPE_GUIDE](docs/MODELSCOPE_GUIDE.md) |
| **方案 F** | Codex CLI (GPT-5.4) | Codex `spawn_agent` (GPT-5.4) | 否 | 是 | [skills-codex/](skills/skills-codex/) |
| **方案 G** 🆕 | Codex CLI | Claude Code CLI(`claude-review` MCP) | 否* | 否* | [CODEX_CLAUDE_REVIEW_GUIDE_CN](docs/CODEX_CLAUDE_REVIEW_GUIDE_CN.md) |
| **方案 H** 🆕 | Antigravity(Claude Opus 4.6 / Gemini 3.1 Pro) | GPT-5.4(Codex MCP)或 llm-chat | 否 | 可选 | [ANTIGRAVITY_ADAPTATION_CN](docs/ANTIGRAVITY_ADAPTATION_CN.md) |
| **方案 I** 🆕 | Codex CLI | Gemini direct API(`gemini-review` MCP) | 否 | 否 | [CODEX_GEMINI_REVIEW_GUIDE_CN](docs/CODEX_GEMINI_REVIEW_GUIDE_CN.md) |
**方案 C** 已适配的提供商:GLM(Z.ai)、Kimi(Moonshot)、LongCat(美团)作为执行器;DeepSeek、MiniMax 作为审查器。任何 OpenAI 兼容 API 理论上均可通过通用 [`llm-chat`](mcp-servers/llm-chat/) MCP 服务器接入。**方案 D** 使用[阿里百炼 Coding Plan](https://bailian.console.aliyun.com/)——一个 API Key 包含 4 款模型(Kimi、Qwen、GLM、MiniMax),双端点配置。**方案 E** 使用 [ModelScope(魔搭社区)](https://www.modelscope.cn/)——**免费**(2000 次/天),一个 Key,无自动化限制。**方案 G** 保持 Codex 作为执行者,但把审稿人切换成通过本地 `claude-review` MCP bridge 暴露出来的 Claude Code CLI,并用异步轮询处理长论文 / 长 review prompt。**方案 H** 使用 [Google Antigravity](https://antigravity.google/) 作为执行器,原生支持 SKILL.md——可选 Claude Opus 4.6(Thinking)或 Gemini 3.1 Pro(high)作为执行模型。**方案 I** 保持 Codex 作为执行者,只增加一层很薄的 `skills-codex-gemini-review` overlay,并通过本地 `gemini-review` MCP bridge 把 reviewer-aware 预定义 skills 默认接到 direct Gemini API。这是与现有 Codex+Claude 审稿路径最接近的 Gemini 版本,同时 skill 改动最少,而且连 poster PNG 审查也复用了同一个 bridge。免费层可用性、限速和数据处理条款仍以 Google 当前政策为准。
\* 方案 G 通常依赖本地 Codex CLI 和 Claude Code CLI 的登录态;不强制要求 API key。
### 方案 A: GLM + GPT
只替换执行者(Claude → GLM),保留 GPT-5.4 通过 Codex MCP 审稿。
```bash
npm install -g @anthropic-ai/claude-code
npm install -g @openai/codex
codex setup # 提示选模型时选 gpt-5.4
```
配置 `~/.claude/settings.json`:
```json
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_zai_api_key",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5"
},
"mcpServers": {
"codex": {
"command": "/opt/homebrew/bin/codex",
"args": ["mcp-server"]
}
}
}
```
Codex CLI 使用你已有的 `OPENAI_API_KEY`(来自 `~/.codex/config.toml` 或环境变量)——审稿端不需要额外配置。
### 方案 B: GLM + MiniMax
无需 Claude 或 OpenAI API。使用自定义 MiniMax MCP 服务器替代 Codex(因为 MiniMax 不支持 OpenAI 的 Responses API)。完整指南:[`docs/MINIMAX_MCP_GUIDE.md`](docs/MINIMAX_MCP_GUIDE.md)。
### 方案 C: 任意执行者 + 任意审稿人
通过通用 `llm-chat` MCP 服务器自由混搭,支持任意 OpenAI 兼容 API 作为审稿人。完整指南:[`docs/LLM_API_MIX_MATCH_GUIDE.md`](docs/LLM_API_MIX_MATCH_GUIDE.md)。
示例组合:GLM + DeepSeek、Kimi + MiniMax、Claude + DeepSeek、LongCat + GLM 等。
### 配置完成后:安装 Skills 并验证
```bash
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
cd Auto-claude-code-research-in-sleep
cp -r skills/* ~/.claude/skills/
claude
```
> **⚠️ 非 Claude 执行者(GLM、Kimi 等):** 需要让模型先读一遍项目,确保 skill 能正确解析。尤其是当你已经[改写了 skill](#-替代模型组合) 以使用不同的审查器 MCP(如 `mcp__llm-chat__chat` 替代 `mcp__codex__codex`)时——新执行器需要理解变更后的工具调用方式:
>
> ```
> 读一下这个项目,验证所有 skills 是否正常:
> /idea-creator, /research-review, /auto-review-loop, /novelty-check,
> /idea-discovery, /research-pipeline, /research-lit, /run-experiment,
> /analyze-results, /monitor-experiment, /pixel-art
> ```
> ⚠️ **注意:** 替代模型的行为可能与 Claude 和 GPT-5.4 有所不同。你可能需要微调 prompt 模板以获得最佳效果。核心的跨模型架构不变。
## 📋 Roadmap
### 已完成
- [x] **Human-in-the-loop 检查点** — idea-discovery 和 research-pipeline 在关键决策点暂停等待用户审批。通过 `AUTO_PROCEED` 配置(默认自动继续,设 `false` 则每步等确认)
- [x] **替代模型组合** — [GLM + GPT、GLM + MiniMax](#-替代模型组合) 完整文档及配置指南。无需 Claude 或 OpenAI API
- [x] **Workflow 3:论文写作流水线** — 完整链路:`/paper-plan` → `/paper-figure` → `/paper-write` → `/paper-compile`。支持 ICLR/NeurIPS/ICML 模板、claims-evidence 矩阵、出版级图表、latexmk 自动修复。参考 [claude-scholar](https://github.com/Galaxy-Dawn/claude-scholar)、[Research-Paper-Writing-Skills](https://github.com/Master-cai/Research-Paper-Writing-Skills)、[baoyu-skills](https://github.com/jimliu/baoyu-skills)
展开 6 项更早完成的功能
- [x] **可配置 REVIEWER_MODEL** — 所有依赖 Codex 的 skill 支持自定义审稿模型(默认 `gpt-5.4`,也支持 `gpt-5.3-codex`、`gpt-5.2-codex`、`o3` 等)
- [x] **本地论文库扫描** — `/research-lit` 在外部搜索前先扫描本地 `papers/` 和 `literature/` 目录,复用已读论文
- [x] **Idea Discovery 流水线** — `/idea-discovery` 一键编排 research-lit → idea-creator → novelty-check → research-review,含 GPU pilot 实验
- [x] **全流程研究管线** — `/research-pipeline` 串联 Workflow 1(idea discovery)→ 实现 → Workflow 2(auto-review-loop),端到端
- [x] **Peer Review skill** — `/peer-review` 以审稿人视角审阅他人论文,含 GPT-5.4 meta-review(规划中;目前可用 `/research-review` + 论文 PDF 实现)
- [x] **跨模型协作架构** — Claude Code(执行者)× Codex GPT-5.4 xhigh(审稿者),避免单模型自我博弈的局部最优
- [x] **飞书集成** — 三种模式(关闭/推送/交互),通过 `~/.claude/feishu.json` 配置。推送只需 webhook URL;交互用 [feishu-claude-code](https://github.com/joewongjc/feishu-claude-code)。默认关闭——对已有工作流零影响。见[设置指南](#-飞书lark-集成可选)
- [x] **Zotero MCP 集成** — `/research-lit` 搜索 Zotero 文献库、读取标注/高亮、导出 BibTeX。推荐:[zotero-mcp](https://github.com/54yyyu/zotero-mcp)(1.8k⭐)。见[设置指南](#-zotero-集成可选)
- [x] **Obsidian 集成** — `/research-lit` 搜索 Obsidian vault 中的研究笔记、标签引用、wikilinks。推荐:[mcpvault](https://github.com/bitbonsai/mcpvault)(760⭐)+ [obsidian-skills](https://github.com/kepano/obsidian-skills)(13.6k⭐)。见[设置指南](#-obsidian-集成可选)
- [x] **更多执行者 × 评审者组合** — 任意 OpenAI 兼容 API 均可通过 [`llm-chat`](mcp-servers/llm-chat/) MCP 服务器接入
- [x] **GitHub 代码同步** — `/run-experiment` 支持 `code_sync: git`(`git push` → `ssh "git pull"`)
- [x] **W&B 集成** — `wandb: true` 时自动加 `wandb.init()` + `wandb.log()`,`/monitor-experiment` 拉训练曲线
- [x] **ModelScope 集成** — [免费](docs/MODELSCOPE_GUIDE.md)(2000 次/天),一个 Key,双协议
### 计划中
- [ ] **常驻模式(Daemon mode)** — 通过 `launchd`/`systemd` 自动重启 Claude Code 会话,实现真正的无人值守运行([#11](https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep/issues/11))
- [ ] **参考风格图表生成** — 参考论文 PDF 图表 → 识别配色/布局 → 生成同风格数据图表。方法示意图 ✅ 已由 `paper-illustration` 解决
- [ ] **工作流执行报告** — 每个工作流完成后自动生成结构化总结:做了什么、关键决策、实验结果、评分和耗时。输出 `WORKFLOW_REPORT.md`,方便汇报
- [ ] **文档输入全流程** — 支持传入详细文档(如 `RESEARCH_BRIEF.md`)作为 `/research-pipeline` 或 `/idea-discovery` 的输入,替代一句话 prompt。很多研究方向需要详细的上下文(前期结果、约束条件、领域知识),一句话说不清楚。文档会被解析提取问题定义、约束、已有结果和具体需求
- [ ] **自动超参调优 skill** — 将 [auto-hparam-tuning](https://github.com/zxh0916/auto-hparam-tuning) 改写为 ARIS SKILL.md。5 步循环:理解项目 → 规划调优策略 → 跑实验 → 分析指标(TensorBoard/W&B)→ 学习迭代。接入工作流 1.5 或工作流 2
## 💬 交流群
**欢迎贡献领域专用 skill!** 核心 skills 覆盖通用科研工作流,但每个领域都有自己的工具和范式。欢迎提交 PR 为你的领域添加新 skill——EDA、生物信息学、机器人、HPC 等等。只需添加一个 `skills/your-skill/SKILL.md` 并开 PR 即可。参考 [`dse-loop`](skills/dse-loop/SKILL.md) 作为示例。
欢迎加入微信群,交流 Claude Code + AI 科研工作流:
 ## 📖 引用
如果 ARIS 对你的研究有帮助,请引用:
```bibtex
@misc{yang2026aris,
author = {Yang, Ruofeng and Li, Yongcan and Li, Shuai},
title = {ARIS: Fully Autonomous Research via Adversarial Multi-Agent Collaboration},
year = {2026},
organization = {GitHub},
url = {https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep},
}
```
## ⭐ Star History

[](https://star-history.com/#wanshuiyin/Auto-claude-code-research-in-sleep&Date)
## 🙏 致谢
ARIS 的灵感来自:
- 🧪 [AI Scientist](https://github.com/SakanaAI/AI-Scientist)(Sakana AI)— 自动化科研先驱
- 📖 [AutoResearch](https://github.com/karpathy/autoresearch)(Andrej Karpathy)— 端到端科研自动化
- 🔭 [FARS](https://analemma.ai/blog/introducing-fars/)(Analemma)— 全自动科研系统
- 🎨 [PaperBanana](https://github.com/dwzhu-pku/PaperBanana)(PKU)— 多 Agent 学术插图框架
本项目构建于并集成了许多优秀的开源项目:
**核心基础设施**
- [Claude Code](https://docs.anthropic.com/en/docs/claude-code) — Anthropic 的 Claude CLI,执行层骨干
- [Codex CLI](https://github.com/openai/codex) — OpenAI 的 CLI,作为 MCP server 实现跨模型审稿
**Zotero 集成**([安装指南](#-zotero-集成可选))
- [zotero-mcp](https://github.com/54yyyu/zotero-mcp) — Zotero MCP server,语义搜索 + PDF 标注
- [Zotero](https://www.zotero.org/) — 开源文献管理器
**Obsidian 集成**([安装指南](#-obsidian-集成可选))
- [mcpvault](https://github.com/bitbonsai/mcpvault) — Obsidian vault MCP server(不需要打开 Obsidian)
- [obsidian-skills](https://github.com/kepano/obsidian-skills) — Obsidian CEO Steph Ango 维护的 Claude Code skills
**论文写作灵感来源**
- [claude-scholar](https://github.com/Galaxy-Dawn/claude-scholar) — 用 Claude 写学术论文
- [Research-Paper-Writing-Skills](https://github.com/Master-cai/Research-Paper-Writing-Skills) — 论文写作 skill 模板
- [baoyu-skills](https://github.com/jimliu/baoyu-skills) — Claude Code skills 合集
**飞书集成**([安装指南](#-飞书lark-集成可选))
- [feishu-claude-code](https://github.com/joewongjc/feishu-claude-code) — 飞书 ↔ Claude Code 双向桥接
- [clawdbot-feishu](https://github.com/m1heng/clawdbot-feishu) — 飞书 Claude 机器人
- [cc-connect](https://github.com/chenhg5/cc-connect) — 多平台消息桥接
- [lark-openapi-mcp](https://github.com/larksuite/lark-openapi-mcp) — 飞书官方 MCP server
**社区**
- [awesome-agent-skills](https://github.com/VoltAgent/awesome-agent-skills) — Claude Code skills 精选列表(已收录)
**特别感谢 — 平台适配**
ARIS 能在这么多平台上运行,离不开这些贡献者:
- 🤖 [@Falling-Flower](https://github.com/Falling-Flower) — 将全部 ARIS skills 适配为 [Codex CLI](https://github.com/openai/codex) 版本(`spawn_agent`)
- 🔧 [@No-518](https://github.com/No-518) — 持续维护 Codex skill 集合,保持与最新更新同步
- 🖱️ [@YecanLee](https://github.com/YecanLee) — 编写 [Cursor 适配指南](docs/CURSOR_ADAPTATION.md)及本地 GPU 配置文档
- 🏆 [@DefanXue](https://github.com/DefanXue) & [@Monglitay](https://github.com/Monglitay) — 首个 ARIS 全流程完成的社区论文,CS 会议评分 8/10
**特别感谢 — 架构与愿景**
- 💡 [@JingxuanKang](https://github.com/JingxuanKang) — 不止于代码贡献(training-check、result-to-claim、ablation-planner、watchdog、模板、session 恢复),更深度参与了 ARIS 的架构讨论——compact 模式、工作流状态管理、自主科研工作流的愿景。今天很多核心功能——从结构化项目文件到 context-aware session 恢复——都源自这些对话。
## License
MIT
## 📖 引用
如果 ARIS 对你的研究有帮助,请引用:
```bibtex
@misc{yang2026aris,
author = {Yang, Ruofeng and Li, Yongcan and Li, Shuai},
title = {ARIS: Fully Autonomous Research via Adversarial Multi-Agent Collaboration},
year = {2026},
organization = {GitHub},
url = {https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep},
}
```
## ⭐ Star History

[](https://star-history.com/#wanshuiyin/Auto-claude-code-research-in-sleep&Date)
## 🙏 致谢
ARIS 的灵感来自:
- 🧪 [AI Scientist](https://github.com/SakanaAI/AI-Scientist)(Sakana AI)— 自动化科研先驱
- 📖 [AutoResearch](https://github.com/karpathy/autoresearch)(Andrej Karpathy)— 端到端科研自动化
- 🔭 [FARS](https://analemma.ai/blog/introducing-fars/)(Analemma)— 全自动科研系统
- 🎨 [PaperBanana](https://github.com/dwzhu-pku/PaperBanana)(PKU)— 多 Agent 学术插图框架
本项目构建于并集成了许多优秀的开源项目:
**核心基础设施**
- [Claude Code](https://docs.anthropic.com/en/docs/claude-code) — Anthropic 的 Claude CLI,执行层骨干
- [Codex CLI](https://github.com/openai/codex) — OpenAI 的 CLI,作为 MCP server 实现跨模型审稿
**Zotero 集成**([安装指南](#-zotero-集成可选))
- [zotero-mcp](https://github.com/54yyyu/zotero-mcp) — Zotero MCP server,语义搜索 + PDF 标注
- [Zotero](https://www.zotero.org/) — 开源文献管理器
**Obsidian 集成**([安装指南](#-obsidian-集成可选))
- [mcpvault](https://github.com/bitbonsai/mcpvault) — Obsidian vault MCP server(不需要打开 Obsidian)
- [obsidian-skills](https://github.com/kepano/obsidian-skills) — Obsidian CEO Steph Ango 维护的 Claude Code skills
**论文写作灵感来源**
- [claude-scholar](https://github.com/Galaxy-Dawn/claude-scholar) — 用 Claude 写学术论文
- [Research-Paper-Writing-Skills](https://github.com/Master-cai/Research-Paper-Writing-Skills) — 论文写作 skill 模板
- [baoyu-skills](https://github.com/jimliu/baoyu-skills) — Claude Code skills 合集
**飞书集成**([安装指南](#-飞书lark-集成可选))
- [feishu-claude-code](https://github.com/joewongjc/feishu-claude-code) — 飞书 ↔ Claude Code 双向桥接
- [clawdbot-feishu](https://github.com/m1heng/clawdbot-feishu) — 飞书 Claude 机器人
- [cc-connect](https://github.com/chenhg5/cc-connect) — 多平台消息桥接
- [lark-openapi-mcp](https://github.com/larksuite/lark-openapi-mcp) — 飞书官方 MCP server
**社区**
- [awesome-agent-skills](https://github.com/VoltAgent/awesome-agent-skills) — Claude Code skills 精选列表(已收录)
**特别感谢 — 平台适配**
ARIS 能在这么多平台上运行,离不开这些贡献者:
- 🤖 [@Falling-Flower](https://github.com/Falling-Flower) — 将全部 ARIS skills 适配为 [Codex CLI](https://github.com/openai/codex) 版本(`spawn_agent`)
- 🔧 [@No-518](https://github.com/No-518) — 持续维护 Codex skill 集合,保持与最新更新同步
- 🖱️ [@YecanLee](https://github.com/YecanLee) — 编写 [Cursor 适配指南](docs/CURSOR_ADAPTATION.md)及本地 GPU 配置文档
- 🏆 [@DefanXue](https://github.com/DefanXue) & [@Monglitay](https://github.com/Monglitay) — 首个 ARIS 全流程完成的社区论文,CS 会议评分 8/10
**特别感谢 — 架构与愿景**
- 💡 [@JingxuanKang](https://github.com/JingxuanKang) — 不止于代码贡献(training-check、result-to-claim、ablation-planner、watchdog、模板、session 恢复),更深度参与了 ARIS 的架构讨论——compact 模式、工作流状态管理、自主科研工作流的愿景。今天很多核心功能——从结构化项目文件到 context-aware session 恢复——都源自这些对话。
## License
MIT