{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Homework: going neural (6 pts)\n",
"\n",
"We've checked out statistical approaches to language models in the last notebook. Now let's go find out what deep learning has to offer.\n",
"\n",
" \n",
"\n",
"We're gonna use the same dataset as before, except this time we build a language model that's character-level, not word level."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import pandas as pd\n",
"import matplotlib.pyplot as plt\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Working on character level means that we don't need to deal with large vocabulary or missing words. Heck, we can even keep uppercase words in text! The downside, however, is that all our sequences just got a lot longer.\n",
"\n",
"However, we still need special tokens:\n",
"* Begin Of Sequence (__BOS__) - this token is at the start of each sequence. We use it so that we always have non-empty input to our neural network. $P(x_t) = P(x_1 | BOS)$\n",
"* End Of Sequence (__EOS__) - you guess it... this token is at the end of each sequence. The catch is that it should __not__ occur anywhere else except at the very end. If our model produces this token, the sequence is over.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"BOS, EOS = ' ', '\\n'\n",
"\n",
"data = pd.read_json(\"./arxivData.json\")\n",
"lines = data.apply(lambda row: (row['title'] + ' ; ' + row['summary'])[:512], axis=1) \\\n",
" .apply(lambda line: BOS + line.replace(EOS, ' ') + EOS) \\\n",
" .tolist()\n",
"\n",
"# if you missed the seminar, download data here - https://yadi.sk/d/_nGyU2IajjR9-w"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our next step is __building char-level vocabulary__. Put simply, you need to assemble a list of all unique tokens in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get all unique characters from lines (including capital letters and symbols)\n",
"tokens = \n",
"\n",
"tokens = sorted(tokens)\n",
"n_tokens = len(tokens)\n",
"print ('n_tokens = ',n_tokens)\n",
"assert 100 < n_tokens < 150\n",
"assert BOS in tokens, EOS in tokens"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now assign each character with it's index in tokens list. This way we can encode a string into a TF-friendly integer vector."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# dictionary of character -> its identifier (index in tokens list)\n",
"token_to_id = "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert len(tokens) == len(token_to_id), \"dictionaries must have same size\"\n",
"for i in range(n_tokens):\n",
" assert token_to_id[tokens[i]] == i, \"token identifier must be it's position in tokens list\"\n",
"\n",
"print(\"Seems alright!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our final step is to assemble several strings in a integet matrix `[batch_size, text_length]`. \n",
"\n",
"The only problem is that each sequence has a different length. We can work around that by padding short sequences with extra _EOS_ or cropping long sequences. Here's how it works:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def to_matrix(lines, max_len=None, pad=token_to_id[EOS], dtype='int32'):\n",
" \"\"\"Casts a list of lines into tf-digestable matrix\"\"\"\n",
" max_len = max_len or max(map(len, lines))\n",
" lines_ix = np.zeros([len(lines), max_len], dtype) + pad\n",
" for i in range(len(lines)):\n",
" line_ix = list(map(token_to_id.get, lines[i][:max_len]))\n",
" lines_ix[i, :len(line_ix)] = line_ix\n",
" return lines_ix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#Example: cast 4 random names to matrices, pad with zeros\n",
"dummy_lines = [\n",
" ' abc\\n',\n",
" ' abacaba\\n',\n",
" ' abc1234567890\\n',\n",
"]\n",
"print(to_matrix(dummy_lines))\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
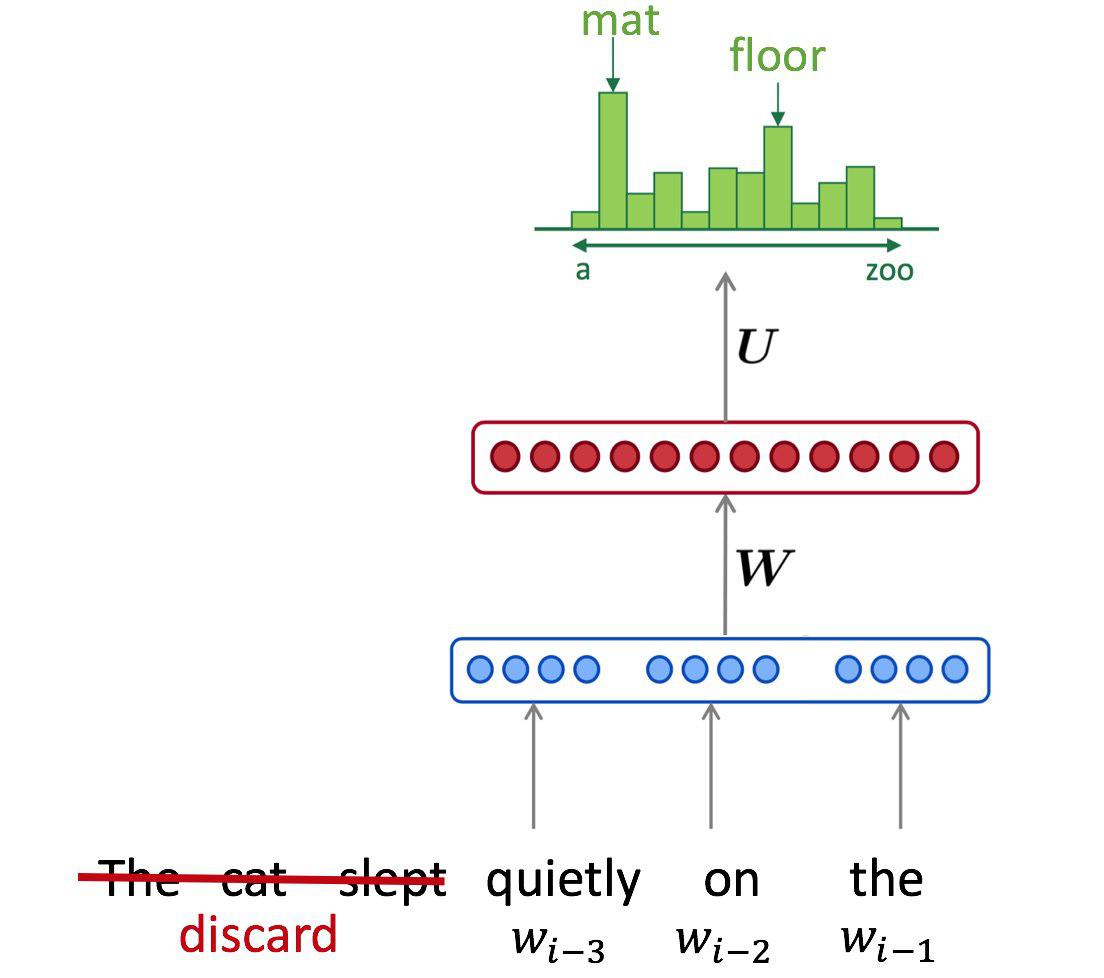
"### Neural Language Model\n",
"\n",
"Just like for N-gram LMs, we want to estimate probability of text as a joint probability of tokens (symbols this time).\n",
"\n",
"$$P(X) = \\prod_t P(x_t \\mid x_0, \\dots, x_{t-1}).$$ \n",
"\n",
"Instead of counting all possible statistics, we want to train a neural network with parameters $\\theta$ that estimates the conditional probabilities:\n",
"\n",
"$$ P(x_t \\mid x_0, \\dots, x_{t-1}) \\approx p(x_t \\mid x_0, \\dots, x_{t-1}, \\theta) $$\n",
"\n",
"\n",
"But before we optimize, we need to define our neural network. Let's start with a fixed-window (aka convolutional) architecture:\n",
"\n",
"
\n",
"\n",
"We're gonna use the same dataset as before, except this time we build a language model that's character-level, not word level."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import pandas as pd\n",
"import matplotlib.pyplot as plt\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Working on character level means that we don't need to deal with large vocabulary or missing words. Heck, we can even keep uppercase words in text! The downside, however, is that all our sequences just got a lot longer.\n",
"\n",
"However, we still need special tokens:\n",
"* Begin Of Sequence (__BOS__) - this token is at the start of each sequence. We use it so that we always have non-empty input to our neural network. $P(x_t) = P(x_1 | BOS)$\n",
"* End Of Sequence (__EOS__) - you guess it... this token is at the end of each sequence. The catch is that it should __not__ occur anywhere else except at the very end. If our model produces this token, the sequence is over.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"BOS, EOS = ' ', '\\n'\n",
"\n",
"data = pd.read_json(\"./arxivData.json\")\n",
"lines = data.apply(lambda row: (row['title'] + ' ; ' + row['summary'])[:512], axis=1) \\\n",
" .apply(lambda line: BOS + line.replace(EOS, ' ') + EOS) \\\n",
" .tolist()\n",
"\n",
"# if you missed the seminar, download data here - https://yadi.sk/d/_nGyU2IajjR9-w"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our next step is __building char-level vocabulary__. Put simply, you need to assemble a list of all unique tokens in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get all unique characters from lines (including capital letters and symbols)\n",
"tokens = \n",
"\n",
"tokens = sorted(tokens)\n",
"n_tokens = len(tokens)\n",
"print ('n_tokens = ',n_tokens)\n",
"assert 100 < n_tokens < 150\n",
"assert BOS in tokens, EOS in tokens"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now assign each character with it's index in tokens list. This way we can encode a string into a TF-friendly integer vector."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# dictionary of character -> its identifier (index in tokens list)\n",
"token_to_id = "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert len(tokens) == len(token_to_id), \"dictionaries must have same size\"\n",
"for i in range(n_tokens):\n",
" assert token_to_id[tokens[i]] == i, \"token identifier must be it's position in tokens list\"\n",
"\n",
"print(\"Seems alright!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our final step is to assemble several strings in a integet matrix `[batch_size, text_length]`. \n",
"\n",
"The only problem is that each sequence has a different length. We can work around that by padding short sequences with extra _EOS_ or cropping long sequences. Here's how it works:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def to_matrix(lines, max_len=None, pad=token_to_id[EOS], dtype='int32'):\n",
" \"\"\"Casts a list of lines into tf-digestable matrix\"\"\"\n",
" max_len = max_len or max(map(len, lines))\n",
" lines_ix = np.zeros([len(lines), max_len], dtype) + pad\n",
" for i in range(len(lines)):\n",
" line_ix = list(map(token_to_id.get, lines[i][:max_len]))\n",
" lines_ix[i, :len(line_ix)] = line_ix\n",
" return lines_ix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#Example: cast 4 random names to matrices, pad with zeros\n",
"dummy_lines = [\n",
" ' abc\\n',\n",
" ' abacaba\\n',\n",
" ' abc1234567890\\n',\n",
"]\n",
"print(to_matrix(dummy_lines))\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Neural Language Model\n",
"\n",
"Just like for N-gram LMs, we want to estimate probability of text as a joint probability of tokens (symbols this time).\n",
"\n",
"$$P(X) = \\prod_t P(x_t \\mid x_0, \\dots, x_{t-1}).$$ \n",
"\n",
"Instead of counting all possible statistics, we want to train a neural network with parameters $\\theta$ that estimates the conditional probabilities:\n",
"\n",
"$$ P(x_t \\mid x_0, \\dots, x_{t-1}) \\approx p(x_t \\mid x_0, \\dots, x_{t-1}, \\theta) $$\n",
"\n",
"\n",
"But before we optimize, we need to define our neural network. Let's start with a fixed-window (aka convolutional) architecture:\n",
"\n",
" \n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"import keras, keras.layers as L\n",
"sess = tf.InteractiveSession()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class FixedWindowLanguageModel:\n",
" def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=64):\n",
" \"\"\" \n",
" A fixed window model that looks on at least 5 previous symbols.\n",
" \n",
" Note: fixed window LM is effectively performing a convolution over a sequence of words.\n",
" This convolution only looks on current and previous words.\n",
" Such convolution can be represented as a sequence of 2 operations:\n",
" - pad input vectors by {strides * (filter_size - 1)} zero vectors on the \"left\", do not pad right\n",
" - perform regular convolution with {filter_size} and {strides}\n",
" \n",
" You can stack several convolutions at once\n",
" \"\"\"\n",
" \n",
" #YOUR CODE - create layers/variables and any metadata you want, e.g. self.emb = L.Embedding(...)\n",
" \n",
" <...>\n",
" \n",
" #END OF YOUR CODE\n",
" \n",
" self.prefix_ix = tf.placeholder('int32', [None, None])\n",
" self.next_token_probs = tf.nn.softmax(self(self.prefix_ix)[:, -1])\n",
" \n",
" def __call__(self, input_ix):\n",
" \"\"\"\n",
" compute language model logits given input tokens\n",
" :param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]\n",
" :returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]\n",
" these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})\n",
" \"\"\"\n",
" # YOUR CODE - apply layers\n",
" return <...>\n",
" \n",
" def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100, sess=sess):\n",
" \"\"\" :returns: probabilities of next token, dict {token : prob} for all tokens \"\"\"\n",
" probs = sess.run(self.next_token_probs, {self.prefix_ix: to_matrix([prefix])})[0]\n",
" return dict(zip(tokens, probs))\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"window_lm = FixedWindowLanguageModel()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dummy_input_ix = tf.constant(to_matrix(dummy_lines))\n",
"dummy_lm_out = window_lm(dummy_input_ix)\n",
"# note: tensorflow and keras layers only create variables after they're first applied (called)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"dummy_logits = sess.run(dummy_lm_out)\n",
"\n",
"assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), \"please check output shape\"\n",
"assert np.all(np.isfinite(dummy_logits)), \"inf/nan encountered\"\n",
"assert not np.allclose(dummy_logits.sum(-1), 1), \"please predict linear outputs, don't use softmax (maybe you've just got unlucky)\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# test for lookahead\n",
"dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))\n",
"dummy_lm_out_2 = window_lm(dummy_input_ix_2)\n",
"dummy_logits_2 = sess.run(dummy_lm_out_2)\n",
"assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), \"your model's predictions depend on FUTURE tokens. \" \\\n",
" \" Make sure you don't allow any layers to look ahead of current token.\" \\\n",
" \" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test.\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now tune our network's parameters to minimize categorical crossentropy over training dataset $D$:\n",
"\n",
"$$ L = {\\frac1{|D|}} \\sum_{X \\in D} \\sum_{x_i \\in X} - \\log p(x_t \\mid x_1, \\dots, x_{t-1}, \\theta) $$\n",
"\n",
"As usual with with neural nets, this optimization is performed via stochastic gradient descent with backprop. One can also note that minimizing crossentropy is equivalent to minimizing model __perplexity__, KL-divergence or maximizng log-likelihood."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def compute_lengths(input_ix, eos_ix=token_to_id[EOS]):\n",
" \"\"\" compute length of each line in input ix (incl. first EOS), int32 vector of shape [batch_size] \"\"\"\n",
" count_eos = tf.cumsum(tf.to_int32(tf.equal(input_ix, eos_ix)), axis=1, exclusive=True)\n",
" lengths = tf.reduce_sum(tf.to_int32(tf.equal(count_eos, 0)), axis=1)\n",
" return lengths\n",
"\n",
"print('matrix:\\n', dummy_input_ix.eval())\n",
"print('lengths:', compute_lengths(dummy_input_ix).eval())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_ix = tf.placeholder('int32', [None, None])\n",
"\n",
"logits = window_lm(input_ix[:, :-1])\n",
"reference_answers = input_ix[:, 1:]\n",
"\n",
"# Your task: implement loss function as per formula above\n",
"# your loss should only be computed on actual tokens, excluding padding\n",
"# predicting actual tokens and first EOS do count. Subsequent EOS-es don't\n",
"# you will likely need to use compute_lengths and/or tf.sequence_mask to get it right.\n",
"\n",
"\n",
"\n",
"loss = <...>\n",
"\n",
"# operation to update network weights\n",
"train_step = <...>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"loss_1 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=50)})\n",
"loss_2 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=100)})\n",
"assert (np.ndim(loss_1) == 0) and (0 < loss_1 < 100), \"loss must be a positive scalar\"\n",
"assert np.allclose(loss_1, loss_2), 'do not include AFTER first EOS into loss. '\\\n",
" 'Hint: use tf.sequence_mask. Beware +/-1 errors. And be careful when averaging!'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Training loop\n",
"\n",
"Now let's train our model on minibatches of data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.model_selection import train_test_split\n",
"train_lines, dev_lines = train_test_split(lines, test_size=0.25, random_state=42)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"batch_size = 256\n",
"score_dev_every = 250\n",
"train_history, dev_history = [], []"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def score_lines(dev_lines, batch_size):\n",
" \"\"\" computes average loss over the entire dataset \"\"\"\n",
" dev_loss_num, dev_loss_len = 0., 0.\n",
" for i in range(0, len(dev_lines), batch_size):\n",
" batch_ix = to_matrix(dev_lines[i: i + batch_size])\n",
" dev_loss_num += sess.run(loss, {input_ix: batch_ix}) * len(batch_ix)\n",
" dev_loss_len += len(batch_ix)\n",
" return dev_loss_num / dev_loss_len\n",
"\n",
"def generate(lm, prefix=BOS, temperature=1.0, max_len=100):\n",
" \"\"\"\n",
" Samples output sequence from probability distribution obtained by lm\n",
" :param temperature: samples proportionally to lm probabilities ^ temperature\n",
" if temperature == 0, always takes most likely token. Break ties arbitrarily.\n",
" \"\"\"\n",
" while True:\n",
" token_probs = lm.get_possible_next_tokens(prefix)\n",
" tokens, probs = zip(*token_probs.items())\n",
" if temperature == 0:\n",
" next_token = tokens[np.argmax(probs)]\n",
" else:\n",
" probs = np.array([p ** (1. / temperature) for p in probs])\n",
" probs /= sum(probs)\n",
" next_token = np.random.choice(tokens, p=probs)\n",
" \n",
" prefix += next_token\n",
" if next_token == EOS or len(prefix) > max_len: break\n",
" return prefix\n",
"\n",
"if len(dev_history) == 0:\n",
" dev_history.append((0, score_lines(dev_lines, batch_size)))\n",
" print(\"Before training:\", generate(window_lm, 'Bridging'))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.display import clear_output\n",
"from random import sample\n",
"from tqdm import trange\n",
"\n",
"for i in trange(len(train_history), 5000):\n",
" batch = to_matrix(sample(train_lines, batch_size))\n",
" loss_i, _ = sess.run([loss, train_step], {input_ix: batch})\n",
" train_history.append((i, loss_i))\n",
" \n",
" if (i + 1) % 50 == 0:\n",
" clear_output(True)\n",
" plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')\n",
" if len(dev_history):\n",
" plt.plot(*zip(*dev_history), color='red', label='dev_loss')\n",
" plt.legend(); plt.grid(); plt.show()\n",
" print(\"Generated examples (tau=0.5):\")\n",
" for j in range(3):\n",
" print(generate(window_lm, temperature=0.5))\n",
" \n",
" if (i + 1) % score_dev_every == 0:\n",
" print(\"Scoring dev...\")\n",
" dev_history.append((i, score_lines(dev_lines, batch_size)))\n",
" print('#%i Dev loss: %.3f' % dev_history[-1])\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], \"The model didn't converge.\"\n",
"print(\"Final dev loss:\", dev_history[-1][-1])\n",
"\n",
"for i in range(10):\n",
" print(generate(window_lm, temperature=0.5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
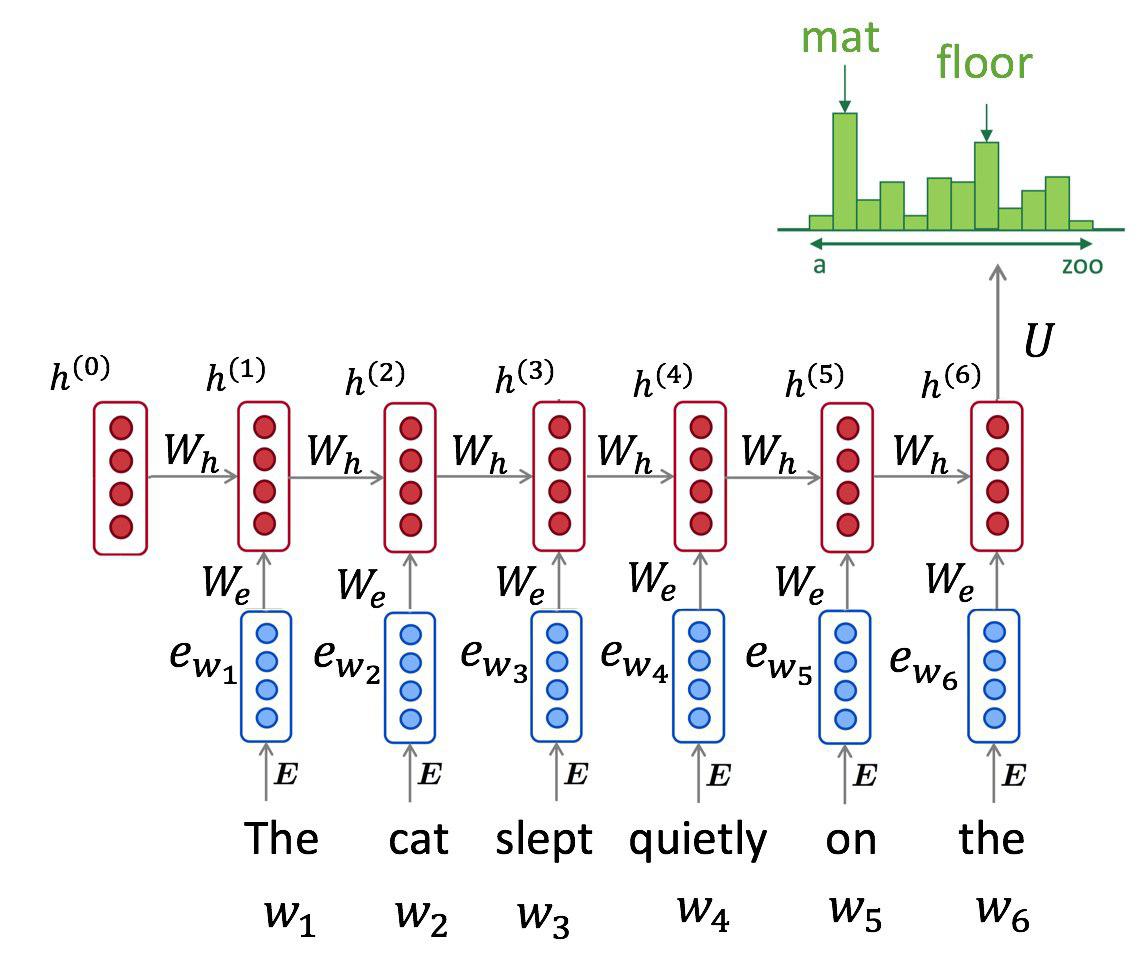
"### RNN Language Models\n",
"\n",
"Fixed-size architectures are reasonably good when capturing short-term dependencies, but their design prevents them from capturing any signal outside their window. We can mitigate this problem by using a __recurrent neural network__:\n",
"\n",
"$$ h_0 = \\vec 0 ; \\quad h_{t+1} = RNN(x_t, h_t) $$\n",
"\n",
"$$ p(x_t \\mid x_0, \\dots, x_{t-1}, \\theta) = dense_{softmax}(h_{t-1}) $$\n",
"\n",
"Such model processes one token at a time, left to right, and maintains a hidden state vector between them. Theoretically, it can learn arbitrarily long temporal dependencies given large enough hidden size.\n",
"\n",
"
\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"import keras, keras.layers as L\n",
"sess = tf.InteractiveSession()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class FixedWindowLanguageModel:\n",
" def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=64):\n",
" \"\"\" \n",
" A fixed window model that looks on at least 5 previous symbols.\n",
" \n",
" Note: fixed window LM is effectively performing a convolution over a sequence of words.\n",
" This convolution only looks on current and previous words.\n",
" Such convolution can be represented as a sequence of 2 operations:\n",
" - pad input vectors by {strides * (filter_size - 1)} zero vectors on the \"left\", do not pad right\n",
" - perform regular convolution with {filter_size} and {strides}\n",
" \n",
" You can stack several convolutions at once\n",
" \"\"\"\n",
" \n",
" #YOUR CODE - create layers/variables and any metadata you want, e.g. self.emb = L.Embedding(...)\n",
" \n",
" <...>\n",
" \n",
" #END OF YOUR CODE\n",
" \n",
" self.prefix_ix = tf.placeholder('int32', [None, None])\n",
" self.next_token_probs = tf.nn.softmax(self(self.prefix_ix)[:, -1])\n",
" \n",
" def __call__(self, input_ix):\n",
" \"\"\"\n",
" compute language model logits given input tokens\n",
" :param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]\n",
" :returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]\n",
" these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})\n",
" \"\"\"\n",
" # YOUR CODE - apply layers\n",
" return <...>\n",
" \n",
" def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100, sess=sess):\n",
" \"\"\" :returns: probabilities of next token, dict {token : prob} for all tokens \"\"\"\n",
" probs = sess.run(self.next_token_probs, {self.prefix_ix: to_matrix([prefix])})[0]\n",
" return dict(zip(tokens, probs))\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"window_lm = FixedWindowLanguageModel()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dummy_input_ix = tf.constant(to_matrix(dummy_lines))\n",
"dummy_lm_out = window_lm(dummy_input_ix)\n",
"# note: tensorflow and keras layers only create variables after they're first applied (called)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"dummy_logits = sess.run(dummy_lm_out)\n",
"\n",
"assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), \"please check output shape\"\n",
"assert np.all(np.isfinite(dummy_logits)), \"inf/nan encountered\"\n",
"assert not np.allclose(dummy_logits.sum(-1), 1), \"please predict linear outputs, don't use softmax (maybe you've just got unlucky)\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# test for lookahead\n",
"dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))\n",
"dummy_lm_out_2 = window_lm(dummy_input_ix_2)\n",
"dummy_logits_2 = sess.run(dummy_lm_out_2)\n",
"assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), \"your model's predictions depend on FUTURE tokens. \" \\\n",
" \" Make sure you don't allow any layers to look ahead of current token.\" \\\n",
" \" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test.\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now tune our network's parameters to minimize categorical crossentropy over training dataset $D$:\n",
"\n",
"$$ L = {\\frac1{|D|}} \\sum_{X \\in D} \\sum_{x_i \\in X} - \\log p(x_t \\mid x_1, \\dots, x_{t-1}, \\theta) $$\n",
"\n",
"As usual with with neural nets, this optimization is performed via stochastic gradient descent with backprop. One can also note that minimizing crossentropy is equivalent to minimizing model __perplexity__, KL-divergence or maximizng log-likelihood."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def compute_lengths(input_ix, eos_ix=token_to_id[EOS]):\n",
" \"\"\" compute length of each line in input ix (incl. first EOS), int32 vector of shape [batch_size] \"\"\"\n",
" count_eos = tf.cumsum(tf.to_int32(tf.equal(input_ix, eos_ix)), axis=1, exclusive=True)\n",
" lengths = tf.reduce_sum(tf.to_int32(tf.equal(count_eos, 0)), axis=1)\n",
" return lengths\n",
"\n",
"print('matrix:\\n', dummy_input_ix.eval())\n",
"print('lengths:', compute_lengths(dummy_input_ix).eval())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_ix = tf.placeholder('int32', [None, None])\n",
"\n",
"logits = window_lm(input_ix[:, :-1])\n",
"reference_answers = input_ix[:, 1:]\n",
"\n",
"# Your task: implement loss function as per formula above\n",
"# your loss should only be computed on actual tokens, excluding padding\n",
"# predicting actual tokens and first EOS do count. Subsequent EOS-es don't\n",
"# you will likely need to use compute_lengths and/or tf.sequence_mask to get it right.\n",
"\n",
"\n",
"\n",
"loss = <...>\n",
"\n",
"# operation to update network weights\n",
"train_step = <...>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"loss_1 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=50)})\n",
"loss_2 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=100)})\n",
"assert (np.ndim(loss_1) == 0) and (0 < loss_1 < 100), \"loss must be a positive scalar\"\n",
"assert np.allclose(loss_1, loss_2), 'do not include AFTER first EOS into loss. '\\\n",
" 'Hint: use tf.sequence_mask. Beware +/-1 errors. And be careful when averaging!'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Training loop\n",
"\n",
"Now let's train our model on minibatches of data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.model_selection import train_test_split\n",
"train_lines, dev_lines = train_test_split(lines, test_size=0.25, random_state=42)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"batch_size = 256\n",
"score_dev_every = 250\n",
"train_history, dev_history = [], []"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def score_lines(dev_lines, batch_size):\n",
" \"\"\" computes average loss over the entire dataset \"\"\"\n",
" dev_loss_num, dev_loss_len = 0., 0.\n",
" for i in range(0, len(dev_lines), batch_size):\n",
" batch_ix = to_matrix(dev_lines[i: i + batch_size])\n",
" dev_loss_num += sess.run(loss, {input_ix: batch_ix}) * len(batch_ix)\n",
" dev_loss_len += len(batch_ix)\n",
" return dev_loss_num / dev_loss_len\n",
"\n",
"def generate(lm, prefix=BOS, temperature=1.0, max_len=100):\n",
" \"\"\"\n",
" Samples output sequence from probability distribution obtained by lm\n",
" :param temperature: samples proportionally to lm probabilities ^ temperature\n",
" if temperature == 0, always takes most likely token. Break ties arbitrarily.\n",
" \"\"\"\n",
" while True:\n",
" token_probs = lm.get_possible_next_tokens(prefix)\n",
" tokens, probs = zip(*token_probs.items())\n",
" if temperature == 0:\n",
" next_token = tokens[np.argmax(probs)]\n",
" else:\n",
" probs = np.array([p ** (1. / temperature) for p in probs])\n",
" probs /= sum(probs)\n",
" next_token = np.random.choice(tokens, p=probs)\n",
" \n",
" prefix += next_token\n",
" if next_token == EOS or len(prefix) > max_len: break\n",
" return prefix\n",
"\n",
"if len(dev_history) == 0:\n",
" dev_history.append((0, score_lines(dev_lines, batch_size)))\n",
" print(\"Before training:\", generate(window_lm, 'Bridging'))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.display import clear_output\n",
"from random import sample\n",
"from tqdm import trange\n",
"\n",
"for i in trange(len(train_history), 5000):\n",
" batch = to_matrix(sample(train_lines, batch_size))\n",
" loss_i, _ = sess.run([loss, train_step], {input_ix: batch})\n",
" train_history.append((i, loss_i))\n",
" \n",
" if (i + 1) % 50 == 0:\n",
" clear_output(True)\n",
" plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')\n",
" if len(dev_history):\n",
" plt.plot(*zip(*dev_history), color='red', label='dev_loss')\n",
" plt.legend(); plt.grid(); plt.show()\n",
" print(\"Generated examples (tau=0.5):\")\n",
" for j in range(3):\n",
" print(generate(window_lm, temperature=0.5))\n",
" \n",
" if (i + 1) % score_dev_every == 0:\n",
" print(\"Scoring dev...\")\n",
" dev_history.append((i, score_lines(dev_lines, batch_size)))\n",
" print('#%i Dev loss: %.3f' % dev_history[-1])\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], \"The model didn't converge.\"\n",
"print(\"Final dev loss:\", dev_history[-1][-1])\n",
"\n",
"for i in range(10):\n",
" print(generate(window_lm, temperature=0.5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### RNN Language Models\n",
"\n",
"Fixed-size architectures are reasonably good when capturing short-term dependencies, but their design prevents them from capturing any signal outside their window. We can mitigate this problem by using a __recurrent neural network__:\n",
"\n",
"$$ h_0 = \\vec 0 ; \\quad h_{t+1} = RNN(x_t, h_t) $$\n",
"\n",
"$$ p(x_t \\mid x_0, \\dots, x_{t-1}, \\theta) = dense_{softmax}(h_{t-1}) $$\n",
"\n",
"Such model processes one token at a time, left to right, and maintains a hidden state vector between them. Theoretically, it can learn arbitrarily long temporal dependencies given large enough hidden size.\n",
"\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class RNNLanguageModel:\n",
" def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=256):\n",
" \"\"\" \n",
" Build a recurrent language model.\n",
" You are free to choose anything you want, but the recommended architecture is\n",
" - token embeddings\n",
" - one or more LSTM/GRU layers with hid size\n",
" - linear layer to predict logits\n",
" \"\"\"\n",
" \n",
" # YOUR CODE - create layers/variables/etc\n",
" \n",
" <...>\n",
" \n",
" #END OF YOUR CODE\n",
" \n",
" \n",
" self.prefix_ix = tf.placeholder('int32', [None, None])\n",
" self.next_token_probs = tf.nn.softmax(self(self.prefix_ix)[:, -1])\n",
" \n",
" def __call__(self, input_ix):\n",
" \"\"\"\n",
" compute language model logits given input tokens\n",
" :param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]\n",
" :returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]\n",
" these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})\n",
" \"\"\"\n",
" #YOUR CODE\n",
" return <...>\n",
" \n",
" def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100, sess=sess):\n",
" \"\"\" :returns: probabilities of next token, dict {token : prob} for all tokens \"\"\"\n",
" probs = sess.run(self.next_token_probs, {self.prefix_ix: to_matrix([prefix])})[0]\n",
" return dict(zip(tokens, probs))\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rnn_lm = RNNLanguageModel()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dummy_input_ix = tf.constant(to_matrix(dummy_lines))\n",
"dummy_lm_out = rnn_lm(dummy_input_ix)\n",
"# note: tensorflow and keras layers only create variables after they're first applied (called)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"dummy_logits = sess.run(dummy_lm_out)\n",
"\n",
"assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), \"please check output shape\"\n",
"assert np.all(np.isfinite(dummy_logits)), \"inf/nan encountered\"\n",
"assert not np.allclose(dummy_logits.sum(-1), 1), \"please predict linear outputs, don't use softmax (maybe you've just got unlucky)\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# test for lookahead\n",
"dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))\n",
"dummy_lm_out_2 = rnn_lm(dummy_input_ix_2)\n",
"dummy_logits_2 = sess.run(dummy_lm_out_2)\n",
"assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), \"your model's predictions depend on FUTURE tokens. \" \\\n",
" \" Make sure you don't allow any layers to look ahead of current token.\" \\\n",
" \" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test.\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### RNN training\n",
"\n",
"Our RNN language model should optimize the same loss function as fixed-window model. But there's a catch. Since RNN recurrently multiplies gradients through many time-steps, gradient values may explode, [breaking](https://raw.githubusercontent.com/yandexdataschool/nlp_course/master/resources/nan.jpg) your model.\n",
"The common solution to that problem is to clip gradients either [individually](https://www.tensorflow.org/versions/r1.1/api_docs/python/tf/clip_by_value) or [globally](https://www.tensorflow.org/versions/r1.1/api_docs/python/tf/clip_by_global_norm).\n",
"\n",
"Your task here is to prepare tensorflow graph that would minimize the same loss function. If you encounter large loss fluctuations during training, please add gradient clipping using urls above.\n",
"\n",
"_Note: gradient clipping is not exclusive to RNNs. Convolutional networks with enough depth often suffer from the same issue._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_ix = tf.placeholder('int32', [None, None])\n",
"\n",
"logits = rnn_lm(input_ix[:, :-1])\n",
"reference_answers = input_ix[:, 1:]\n",
"\n",
"# Copy the loss function and train step from the fixed-window model training\n",
"loss = <...>\n",
"\n",
"# and the train step\n",
"train_step = <...>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"loss_1 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=50)})\n",
"loss_2 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=100)})\n",
"assert (np.ndim(loss_1) == 0) and (0 < loss_1 < 100), \"loss must be a positive scalar\"\n",
"assert np.allclose(loss_1, loss_2), 'do not include AFTER first EOS into loss. Hint: use tf.sequence_mask. Be careful when averaging!'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### RNN: Training loop"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sess.run(tf.global_variables_initializer())\n",
"batch_size = 128\n",
"score_dev_every = 250\n",
"train_history, dev_history = [], []\n",
"\n",
"dev_history.append((0, score_lines(dev_lines, batch_size)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for i in trange(len(train_history), 5000):\n",
" batch = to_matrix(sample(train_lines, batch_size))\n",
" loss_i, _ = sess.run([loss, train_step], {input_ix: batch})\n",
" train_history.append((i, loss_i))\n",
" \n",
" if (i + 1) % 50 == 0:\n",
" clear_output(True)\n",
" plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')\n",
" if len(dev_history):\n",
" plt.plot(*zip(*dev_history), color='red', label='dev_loss')\n",
" plt.legend(); plt.grid(); plt.show()\n",
" print(\"Generated examples (tau=0.5):\")\n",
" for j in range(3):\n",
" print(generate(rnn_lm, temperature=0.5))\n",
" \n",
" if (i + 1) % score_dev_every == 0:\n",
" print(\"Scoring dev...\")\n",
" dev_history.append((i, score_lines(dev_lines, batch_size)))\n",
" print('#%i Dev loss: %.3f' % dev_history[-1])\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], \"The model didn't converge.\"\n",
"print(\"Final dev loss:\", dev_history[-1][-1])\n",
"for i in range(10):\n",
" print(generate(rnn_lm, temperature=0.5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Bonus quest: Ultimate Language Model\n",
"\n",
"So you've learned the building blocks of neural language models, you can now build the ultimate monster: \n",
"* Make it char-level, word level or maybe use sub-word units like [bpe](https://github.com/rsennrich/subword-nmt);\n",
"* Combine convolutions, recurrent cells, pre-trained embeddings and all the black magic deep learning has to offer;\n",
" * Use strides to get larger window size quickly. Here's a [scheme](https://storage.googleapis.com/deepmind-live-cms/documents/BlogPost-Fig2-Anim-160908-r01.gif) from google wavenet.\n",
"* Train on large data. Like... really large. Try [1 Billion Words](http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz) benchmark;\n",
"* Use training schedules to speed up training. Start with small length and increase over time; Take a look at [one cycle](https://medium.com/@nachiket.tanksale/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6) for learning rate;\n",
"\n",
"_You are NOT required to submit this assignment. Please make sure you don't miss your deadline because of it :)_"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"class RNNLanguageModel:\n",
" def __init__(self, n_tokens=n_tokens, emb_size=16, hid_size=256):\n",
" \"\"\" \n",
" Build a recurrent language model.\n",
" You are free to choose anything you want, but the recommended architecture is\n",
" - token embeddings\n",
" - one or more LSTM/GRU layers with hid size\n",
" - linear layer to predict logits\n",
" \"\"\"\n",
" \n",
" # YOUR CODE - create layers/variables/etc\n",
" \n",
" <...>\n",
" \n",
" #END OF YOUR CODE\n",
" \n",
" \n",
" self.prefix_ix = tf.placeholder('int32', [None, None])\n",
" self.next_token_probs = tf.nn.softmax(self(self.prefix_ix)[:, -1])\n",
" \n",
" def __call__(self, input_ix):\n",
" \"\"\"\n",
" compute language model logits given input tokens\n",
" :param input_ix: batch of sequences with token indices, tf tensor: int32[batch_size, sequence_length]\n",
" :returns: pre-softmax linear outputs of language model [batch_size, sequence_length, n_tokens]\n",
" these outputs will be used as logits to compute P(x_t | x_0, ..., x_{t - 1})\n",
" \"\"\"\n",
" #YOUR CODE\n",
" return <...>\n",
" \n",
" def get_possible_next_tokens(self, prefix=BOS, temperature=1.0, max_len=100, sess=sess):\n",
" \"\"\" :returns: probabilities of next token, dict {token : prob} for all tokens \"\"\"\n",
" probs = sess.run(self.next_token_probs, {self.prefix_ix: to_matrix([prefix])})[0]\n",
" return dict(zip(tokens, probs))\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rnn_lm = RNNLanguageModel()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dummy_input_ix = tf.constant(to_matrix(dummy_lines))\n",
"dummy_lm_out = rnn_lm(dummy_input_ix)\n",
"# note: tensorflow and keras layers only create variables after they're first applied (called)\n",
"\n",
"sess.run(tf.global_variables_initializer())\n",
"dummy_logits = sess.run(dummy_lm_out)\n",
"\n",
"assert dummy_logits.shape == (len(dummy_lines), max(map(len, dummy_lines)), n_tokens), \"please check output shape\"\n",
"assert np.all(np.isfinite(dummy_logits)), \"inf/nan encountered\"\n",
"assert not np.allclose(dummy_logits.sum(-1), 1), \"please predict linear outputs, don't use softmax (maybe you've just got unlucky)\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# test for lookahead\n",
"dummy_input_ix_2 = tf.constant(to_matrix([line[:3] + 'e' * (len(line) - 3) for line in dummy_lines]))\n",
"dummy_lm_out_2 = rnn_lm(dummy_input_ix_2)\n",
"dummy_logits_2 = sess.run(dummy_lm_out_2)\n",
"assert np.allclose(dummy_logits[:, :3] - dummy_logits_2[:, :3], 0), \"your model's predictions depend on FUTURE tokens. \" \\\n",
" \" Make sure you don't allow any layers to look ahead of current token.\" \\\n",
" \" You can also get this error if your model is not deterministic (e.g. dropout). Disable it for this test.\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### RNN training\n",
"\n",
"Our RNN language model should optimize the same loss function as fixed-window model. But there's a catch. Since RNN recurrently multiplies gradients through many time-steps, gradient values may explode, [breaking](https://raw.githubusercontent.com/yandexdataschool/nlp_course/master/resources/nan.jpg) your model.\n",
"The common solution to that problem is to clip gradients either [individually](https://www.tensorflow.org/versions/r1.1/api_docs/python/tf/clip_by_value) or [globally](https://www.tensorflow.org/versions/r1.1/api_docs/python/tf/clip_by_global_norm).\n",
"\n",
"Your task here is to prepare tensorflow graph that would minimize the same loss function. If you encounter large loss fluctuations during training, please add gradient clipping using urls above.\n",
"\n",
"_Note: gradient clipping is not exclusive to RNNs. Convolutional networks with enough depth often suffer from the same issue._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_ix = tf.placeholder('int32', [None, None])\n",
"\n",
"logits = rnn_lm(input_ix[:, :-1])\n",
"reference_answers = input_ix[:, 1:]\n",
"\n",
"# Copy the loss function and train step from the fixed-window model training\n",
"loss = <...>\n",
"\n",
"# and the train step\n",
"train_step = <...>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"loss_1 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=50)})\n",
"loss_2 = sess.run(loss, {input_ix: to_matrix(dummy_lines, max_len=100)})\n",
"assert (np.ndim(loss_1) == 0) and (0 < loss_1 < 100), \"loss must be a positive scalar\"\n",
"assert np.allclose(loss_1, loss_2), 'do not include AFTER first EOS into loss. Hint: use tf.sequence_mask. Be careful when averaging!'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### RNN: Training loop"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sess.run(tf.global_variables_initializer())\n",
"batch_size = 128\n",
"score_dev_every = 250\n",
"train_history, dev_history = [], []\n",
"\n",
"dev_history.append((0, score_lines(dev_lines, batch_size)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for i in trange(len(train_history), 5000):\n",
" batch = to_matrix(sample(train_lines, batch_size))\n",
" loss_i, _ = sess.run([loss, train_step], {input_ix: batch})\n",
" train_history.append((i, loss_i))\n",
" \n",
" if (i + 1) % 50 == 0:\n",
" clear_output(True)\n",
" plt.scatter(*zip(*train_history), alpha=0.1, label='train_loss')\n",
" if len(dev_history):\n",
" plt.plot(*zip(*dev_history), color='red', label='dev_loss')\n",
" plt.legend(); plt.grid(); plt.show()\n",
" print(\"Generated examples (tau=0.5):\")\n",
" for j in range(3):\n",
" print(generate(rnn_lm, temperature=0.5))\n",
" \n",
" if (i + 1) % score_dev_every == 0:\n",
" print(\"Scoring dev...\")\n",
" dev_history.append((i, score_lines(dev_lines, batch_size)))\n",
" print('#%i Dev loss: %.3f' % dev_history[-1])\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"assert np.mean(train_history[:10], axis=0)[1] > np.mean(train_history[-10:], axis=0)[1], \"The model didn't converge.\"\n",
"print(\"Final dev loss:\", dev_history[-1][-1])\n",
"for i in range(10):\n",
" print(generate(rnn_lm, temperature=0.5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Bonus quest: Ultimate Language Model\n",
"\n",
"So you've learned the building blocks of neural language models, you can now build the ultimate monster: \n",
"* Make it char-level, word level or maybe use sub-word units like [bpe](https://github.com/rsennrich/subword-nmt);\n",
"* Combine convolutions, recurrent cells, pre-trained embeddings and all the black magic deep learning has to offer;\n",
" * Use strides to get larger window size quickly. Here's a [scheme](https://storage.googleapis.com/deepmind-live-cms/documents/BlogPost-Fig2-Anim-160908-r01.gif) from google wavenet.\n",
"* Train on large data. Like... really large. Try [1 Billion Words](http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz) benchmark;\n",
"* Use training schedules to speed up training. Start with small length and increase over time; Take a look at [one cycle](https://medium.com/@nachiket.tanksale/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6) for learning rate;\n",
"\n",
"_You are NOT required to submit this assignment. Please make sure you don't miss your deadline because of it :)_"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}