# EduBench: A Comprehensive Benchmark Dataset for Evaluating Large Language Models in Diverse Educational Scenarios
📄 Paper |
🤗 Model |
🎰 Datasets |
⚖️ MIT License
# Table of Contents
- [Overview](#overview)
- [Framework](#framework)
- [Dataset Construction](#dataset-construction)
- [Evaluation Metrics Design](#evaluation-metrics-design)
- [Dataset Generation](#Dataset-Generation)
- [Dataset Evaluation](#Dataset-Evaluation)
- [Experiments and Analysis](#experiments-and-analysis)
- [Evaluation Results](#evaluation-results)
- [Model-Human Evaluation Consistency Analysis](#model-human-evaluation-consistency-analysis)
- [Model Distillation](#model-distillation)
# Overview
 The left section displays our 9 educational scenarios, showing their multidimensional educational contexts and corresponding metrics along the vertical axis. The right section presents human evaluation results on EduBench.
The left section displays our 9 educational scenarios, showing their multidimensional educational contexts and corresponding metrics along the vertical axis. The right section presents human evaluation results on EduBench.
Introducing EduBench 📚, a diversified benchmark dataset 🌟 specifically tailored for educational scenarios, covering 9 major educational contexts 🏫 and over 4,000 different educational situations 🔍, providing a fresh perspective for model evaluation in the education domain.
We designed multidimensional evaluation metrics 🛠️, comprehensively covering 12 key dimensions 🧠 from both teacher and student perspectives, ensuring in-depth assessment of scenario adaptability, factual and reasoning accuracy, and more.
Moreover, through knowledge distillation technology 🔬, we enabled smaller models like Qwen2.5-7B-Instruct to achieve performance comparable to state-of-the-art large models such as DeepSeek V3 and Qwen Max with only minimal data. EduBench is not just a benchmark—it's a game changer 🚀 for educational model development!
---
# Framework
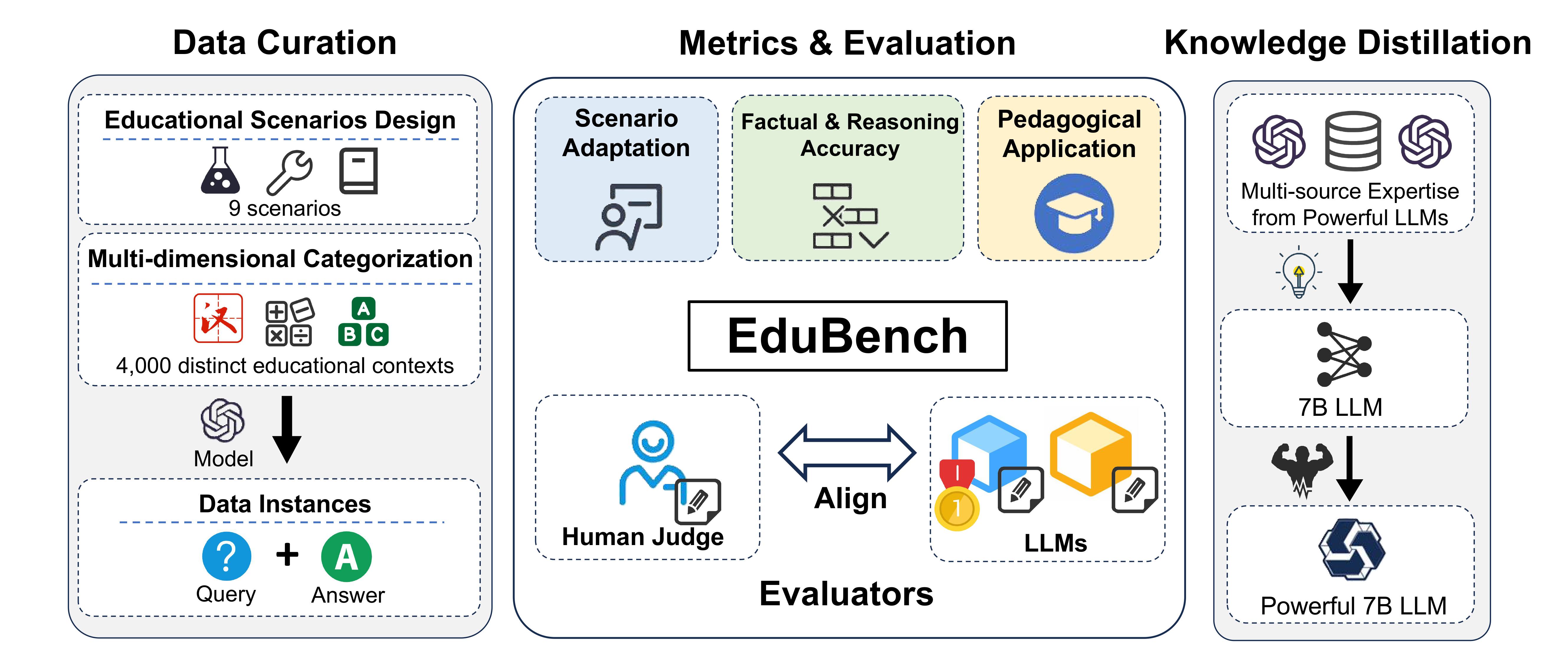 The left part illustrates our data curation process; the middle part presents our three main evaluation principles and our exploration of the consistency between large language models and human judgments; the right part demonstrates how our data enhances the performance of small models.
The left part illustrates our data curation process; the middle part presents our three main evaluation principles and our exploration of the consistency between large language models and human judgments; the right part demonstrates how our data enhances the performance of small models.
# Dataset Construction
We first classify educational scenarios into the following two categories based on their target users:
**I. Student-Oriented Scenarios**
- Question Answering (Q&A)
- Error Correction (EC)
- Idea Provision (IP)
- Personalized Learning Support (PLS)
- Emotional Support (ES)
**II. Teacher-Oriented Scenarios**
- Question Generation (QG)
- Automatic Grading (AG)
- Teaching Material Generation (TMG)
- Personalized Content Creation (PCC)
---
## Evaluation Metrics Design
Based on the defined educational scenarios, we have designed a comprehensive evaluation metric system. Each scenario includes 4 sub-indicators, resulting in a total of 12 core evaluation indicators.
### 1. Scenario Adaptability
Measures whether the model's response is contextually appropriate and meets the expectations of the educational scenario.
- **Instruction Following & Task Completion**
- **Role & Tone Consistency**
- **Content Relevance & Scope Control**
- **Scenario Element Integration**
### 2. Factual & Reasoning Accuracy
Evaluates the accuracy of factual information and the rigor of reasoning processes within the model’s responses.
- **Basic Factual Accuracy**
- **Domain Knowledge Accuracy**
- **Reasoning Process Rigor**
- **Error Identification & Correction Precision**
### 3. Pedagogical Application
Assesses whether the model's responses reflect effective teaching principles and support student learning.
- **Clarity, Simplicity & Inspiration**
- **Motivation, Guidance & Positive Feedback**
- **Personalization, Adaptation & Learning Support**
- **Higher-Order Thinking & Skill Development**
## Dataset Generation
As an example, we use the **Error Correction (EC)** scenario to generate data by running the following code:
```bash
python ./code/generation/EC.py
```
## Dataset Evaluation
To evaluate the dataset, simply run the following code (make sure to adjust the API configuration as needed):
```bash
python ./code/evaluation/evaluation.py
```
# Experiments and Analysis
## Evaluation Results
| Evaluator | Model | Q&A | PLS | EC | IP | AG | TMG | ES | QG | PCC | Average |
|-----------------|------------------------|------|------|------|------|------|------|------|------|------|---------|
| **DeepSeek R1** | DeepSeek R1 | **9.81** | **9.83** | **9.05** | **9.11** | 7.74 | **9.46** | **9.71** | **9.22** | **9.73** | **9.29** |
| | DeepSeek V3 | 9.67 | 9.12 | 8.97 | 8.82 | **8.32** | 9.31 | 9.34 | 8.65 | 9.23 | 9.05 |
| | Qwen Max | 9.07 | 9.11 | 8.86 | 8.84 | 7.99 | 9.15 | 9.40 | 8.89 | 9.29 | 8.96 |
| | Qwen2.5-14B-Instruct | 8.94 | 8.79 | 8.68 | 8.23 | 7.83 | 9.06 | 8.52 | 8.35 | 8.80 | 8.58 |
| | Qwen2.5-7B-Instruct | 8.34 | 9.01 | 8.64 | 8.16 | 6.64 | 9.33 | 8.75 | 8.23 | 9.06 | 8.46 |
| **DeepSeek V3** | DeepSeek R1 | 9.49 | **9.65** | **9.27** | **8.75** | **7.27** | **9.45** | **9.38** | **9.33** | **9.71** | **9.14** |
| | DeepSeek V3 | **9.68** | 9.04 | 9.14 | 8.53 | 7.05 | 9.34 | 9.00 | 9.06 | 8.92 | 8.86 |
| | Qwen Max | 9.18 | 8.88 | 9.06 | 8.52 | 7.23 | 9.24 | 9.04 | 9.05 | 9.29 | 8.83 |
| | Qwen2.5-14B-Instruct | 9.07 | 8.72 | 8.97 | 8.30 | 6.77 | 9.21 | 8.74 | 9.02 | 8.80 | 8.62 |
| | Qwen2.5-7B-Instruct | 9.15 | 9.07 | 9.01 | 8.47 | 6.44 | 9.21 | 8.85 | 8.69 | 9.00 | 8.65 |
| **GPT-4o** | DeepSeek R1 | 9.32 | **9.38** | 9.05 | 8.78 | 8.51 | **9.25** | **9.15** | 8.98 | **9.08** | **9.06** |
| | DeepSeek V3 | 9.22 | 9.15 | **9.14** | 8.77 | 8.54 | 9.12 | 9.05 | **9.00** | 8.95 | 8.99 |
| | Qwen Max | **9.50** | 9.17 | 9.01 | 8.69 | **8.70** | 8.99 | 8.96 | 8.92 | 9.05 | 8.99 |
| | Qwen2.5-14B-Instruct | 9.34 | 9.25 | 8.92 | 8.51 | 8.11 | 8.99 | 9.11 | 8.77 | 8.82 | 8.87 |
| | Qwen2.5-7B-Instruct | 9.22 | 9.17 | 8.92 | **8.84** | 8.04 | 9.05 | 9.00 | 8.62 | 8.94 | 8.87 |
| **QwQ-Plus** | DeepSeek R1 | **9.85** | **9.87** | **9.24** | **9.05** | **8.78** | **9.75** | **9.85** | **9.09** | **9.88** | **9.49** |
| | DeepSeek V3 | 9.59 | 9.43 | 9.06 | 8.66 | 8.18 | 9.29 | 9.66 | 8.47 | 9.24 | 9.06 |
| | Qwen Max | 9.90 | 9.25 | 9.03 | 8.78 | 8.11 | 9.54 | 9.56 | 8.79 | 9.70 | 9.18 |
| | Qwen2.5-14B-Instruct | 9.83 | 9.21 | 9.05 | 8.23 | 7.88 | 9.22 | 9.45 | 8.48 | 9.02 | 8.94 |
| | Qwen2.5-7B-Instruct | 9.02 | 9.28 | 8.79 | 8.82 | 7.16 | 9.33 | 9.31 | 8.69 | 9.35 | 8.78 |
| **Human** | DeepSeek R1 | 7.17 | **9.11** | **8.71** | **8.80** | **8.42** | **8.86** | **9.15** | **8.79** | **9.35** | **8.71** |
| | DeepSeek V3 | 7.45 | 8.12 | 8.16 | 8.17 | 7.84 | 7.56 | 8.08 | 8.01 | 7.03 | 7.82 |
| | Qwen Max | **7.72** | 7.94 | 8.21 | 8.15 | 7.89 | 7.99 | 7.85 | 8.39 | 8.42 | 8.06 |
| | Qwen2.5-14B-Instruct | 7.66 | 7.38 | 7.92 | 7.56 | 7.55 | 7.84 | 7.31 | 7.91 | 7.36 | 7.61 |
| | Qwen2.5-7B-Instruct | 6.78 | 7.63 | 7.93 | 7.74 | 6.79 | 7.86 | 7.79 | 7.55 | 7.42 | 7.50 |
Table 1: Scenario-level average scores evaluated by different evaluation models.
| Evaluator | Model | BFA | CSI | CRSC | DKA | EICP | HOTS | IFTC | MGP | PAS | RPR | RTC | SEI | Average |
|-----------------|------------------------|------|------|------|------|------|------|------|------|------|------|------|------|---------|
| **DeepSeek R1** | DeepSeek R1 | 9.55 | **8.67** | **9.64** | **9.53** | 8.66 | **8.39** | **9.61** | 7.30 | **9.80** | **9.17** | **9.64** | **9.45** | **9.12** |
| | DeepSeek V3 | **9.58** | 8.47 | 9.48 | 9.30 | **9.32** | 7.53 | 9.39 | **7.48** | 8.92 | 9.05 | 9.32 | 9.10 | 8.91 |
| | Qwen Max | 9.42 | 8.49 | 9.46 | 9.24 | 9.09 | 7.67 | 9.25 | 7.44 | 8.97 | 8.62 | 9.34 | 9.05 | 8.84 |
| | Qwen2.5-14B-Instruct | 9.08 | 8.28 | 9.20 | 8.82 | 8.98 | 7.16 | 8.87 | 6.86 | 8.20 | 8.57 | 9.02 | 8.51 | 8.46 |
| | Qwen2.5-7B-Instruct | 8.73 | 8.22 | 9.00 | 9.00 | 8.30 | 7.27 | 8.72 | 6.61 | 8.68 | 8.05 | 9.23 | 8.55 | 8.36 |
| **DeepSeek V3** | DeepSeek R1 | 9.51 | **8.75** | **9.44** | **9.45** | **7.61** | **8.53** | **9.47** | 7.76 | **9.64** | **8.85** | **9.14** | **9.06** | **8.93** |
| | DeepSeek V3 | **9.57** | 8.61 | 9.25 | 9.27 | 7.23 | 7.98 | 9.21 | 7.56 | 8.94 | 8.76 | 9.00 | 8.59 | 8.66 |
| | Qwen Max | 9.38 | 8.53 | 9.12 | 9.23 | 7.43 | 7.99 | 9.16 | **7.85** | 9.05 | 8.57 | 9.00 | 8.61 | 8.66 |
| | Qwen2.5-14B-Instruct | 9.28 | 8.50 | 9.03 | 9.14 | 7.14 | 7.81 | 8.94 | 7.55 | 8.71 | 8.35 | 8.82 | 8.25 | 8.46 |
| | Qwen2.5-7B-Instruct | 9.27 | 8.55 | 9.08 | 9.12 | 6.77 | 7.86 | 8.96 | 7.05 | 8.95 | 8.42 | 8.82 | 8.53 | 8.44 |
| **GPT-4o** | DeepSeek R1 | 9.48 | **8.73** | **9.59** | **9.17** | 9.05 | **8.35** | 9.13 | 8.45 | **9.18** | **8.89** | **9.11** | **8.65** | **8.98** |
| | DeepSeek V3 | 9.54 | 8.72 | 9.51 | 9.05 | **9.14** | 8.05 | **9.16** | **8.59** | 8.95 | 8.75 | 9.02 | 8.63 | 8.93 |
| | Qwen Max | **9.58** | 8.65 | 9.43 | 8.83 | 9.07 | 8.08 | 9.14 | 8.56 | 8.97 | 8.89 | 8.95 | 8.64 | 8.90 |
| | Qwen2.5-14B-Instruct | 9.45 | 8.51 | 9.44 | 8.88 | 8.93 | 7.83 | 9.02 | 8.20 | 8.88 | 8.60 | 9.07 | 8.43 | 8.77 |
| | Qwen2.5-7B-Instruct | 9.45 | 8.57 | 9.38 | 8.85 | 8.59 | 8.00 | 9.01 | 8.20 | 8.85 | 8.65 | 9.02 | **8.65** | 8.77 |
| **QwQ-Plus** | DeepSeek R1 | **9.78** | **8.47** | **9.78** | **9.82** | **9.70** | **8.19** | **9.65** | **8.35** | **9.86** | **9.61** | **9.70** | **9.58** | **9.37** |
| | DeepSeek V3 | 9.42 | 8.25 | 9.57 | 9.09 | 9.52 | 7.22 | 9.36 | 7.62 | 9.23 | 9.23 | 9.39 | 9.32 | 8.93 |
| | Qwen Max | 9.64 | 8.39 | 9.59 | 9.47 | 9.30 | 7.48 | 9.45 | 7.68 | 9.39 | 9.10 | 9.48 | 9.36 | 9.03 |
| | Qwen2.5-14B-Instruct | 9.49 | 8.20 | 9.48 | 8.98 | 9.20 | 7.10 | 9.15 | 7.64 | 8.77 | 8.83 | 9.41 | 9.06 | 8.78 |
| | Qwen2.5-7B-Instruct | 9.08 | 8.10 | 9.31 | 8.98 | 8.91 | 7.02 | 9.03 | 7.18 | 9.09 | 8.61 | 9.30 | 9.33 | 8.66 |
| **Human** | DeepSeek R1 | **8.97** | **8.60** | **8.98** | **8.94** | **8.86** | **8.56** | **8.77** | **8.20** | **9.26** | **7.95** | **8.91** | **8.92** | **8.74** |
| | DeepSeek V3 | 8.77 | 7.77 | 8.40 | 7.89 | 8.11 | 7.25 | 8.10 | 7.70 | 7.42 | 7.03 | 7.80 | 7.47 | 7.89 |
| | Qwen Max | 8.81 | 8.01 | 8.52 | 8.27 | 8.23 | 7.59 | 8.10 | 7.70 | 7.89 | 7.31 | 8.09 | 7.74 | 8.02 |
| | Qwen2.5-14B-Instruct | 8.74 | 7.76 | 8.26 | 7.79 | 7.86 | 6.88 | 7.77 | 6.97 | 7.02 | 7.01 | 7.59 | 7.03 | 7.56 |
| | Qwen2.5-7B-Instruct | 8.49 | 7.63 | 8.04 | 7.82 | 7.45 | 6.93 | 7.65 | 7.05 | 7.38 | 5.90 | 7.82 | 7.35 | 7.46 |
Table 2: Shows the average scores at the metric level under different evaluators.
**Model Evaluation Results**
DeepSeek R1 demonstrates the best overall performance across different metrics, while Qwen2.5-7B-Instruct performs the worst in Table 2.
**Human Evaluation Results**
In Table 2, DeepSeek R1 and Qwen2.5-7B-Instruct still show the best and worst performances, respectively, which are consistent with the model-based evaluation results.
---
### Consistency Analysis Between Model and Human Evaluation
| Model | DeepSeek R1 | GPT-4o | QwQ-Plus | DeepSeek V3 | Human |
|----------------|-------------|--------|----------|-------------|-------|
| **DeepSeek R1** | - | 0.55 | 0.61 | **0.65** | 0.63 |
| **GPT-4o** | 0.55 | - | 0.57 | **0.58** | 0.56 |
| **QwQ-Plus** | 0.61 | 0.57 | - | **0.62** | 0.63 |
| **DeepSeek V3** | 0.65 | 0.58 | 0.62 | - | 0.63 |
| **Human** | 0.63 | 0.56 | 0.63 | **0.63** | - |
Kendall's W between different evaluation models and human evaluation. We observe the following:
- **Consistency among evaluation models**: The models show high consistency, with almost all Kendall's W values above 0.5 and most around 0.6, indicating strong agreement.
- **Consistency between humans and models**: The model evaluations do not fully align with human judgments, which may be due to limited understanding of the evaluation criteria by the models.
---
### Model Distillation
| Model | BFA | CSI | CRSC | DKA | EICP | HOTS | IFTC | MGP | PAS | RPR | RTC | SEI | Average |
|------------------------|------|------|------|------|------|------|------|------|------|------|------|------|---------|
| DeepSeek R1 | _9.51_ | **8.75** | **9.44** | **9.45** | **7.61** | **8.53** | **9.47** | _7.76_ | **9.64** | _8.85_ | **9.14** | **9.06** | **8.93** |
| DeepSeek V3 | **9.57** | _8.61_ | 9.25 | _9.27_ | 7.23 | 7.98 | 9.21 | 7.56 | 8.94 | 8.76 | 9.00 | 8.59 | 8.66 |
| Qwen Max | 9.38 | 8.53 | 9.12 | 9.23 | _7.43_ | 7.99 | 9.16 | **7.85** | 9.05 | 8.57 | 9.00 | 8.61 | 8.66 |
| Qwen2.5-14B-Instruct | 9.28 | 8.50 | 9.03 | 9.14 | 7.14 | 7.81 | 8.94 | 7.55 | 8.71 | 8.35 | 8.82 | 8.25 | 8.46 |
| Qwen2.5-7B-Instruct | 9.27 | 8.55 | 9.08 | 9.12 | 6.77 | 7.86 | 8.96 | 7.05 | 8.95 | 8.42 | 8.82 | 8.53 | 8.44 |
| Distillation Qwen2.5-7B| 9.26 | 8.56 | _9.27_ | 8.95 | 6.89 | _8.43_ | _9.41_ | 7.32 | _9.56_ | **9.26** | _9.09_ | _8.95_ | _8.75_ |
Performance of the distillation model and other models across different metrics:
- **Dataset Construction**: To fully leverage the strengths of different generative models across various educational scenarios, we adopt a multi-source distillation pipeline. For each task, we select the model with the best performance on the test set as the answer generator and use it to answer questions in the educational domain, thereby constructing the training dataset for the distillation model. Through this distillation process, we obtained a training set containing 4,000 samples, covering all subtasks across the 9 educational scenarios.
- **Performance Improvement**: After distillation, the 7B model shows significant improvements on 10 out of the 12 metrics. Its overall performance is now comparable to that of the current state-of-the-art models.