## 📰 What's New
- **🔌 MCP Server** — Query your knowledge abstracts from Claude Desktop and IDE agents with `he-mcp`. *(PR #40)*
- **🧠 Anthropic Claude Support** — Use `claude-opus-4-8`, `claude-sonnet-4-6`, and `claude-haiku-4-5` directly as your LLM provider. *(PR #38)*
- **📝 Obsidian Export** — Turn any graph into an Obsidian vault with Markdown notes linked by `[[wikilinks]]`. *(PR #37)*
- **🧹 `he clean`** — Remove a KA's index or the whole knowledge abstract in one command. *(PR #39)*
- **🔧 Reliability Fixes** — True mean for multi-chunk embeddings, capped OpenAI-compatible batch sizes, and resolved multi-word `llm_*` merge strategies. *(PRs #35, #36, #41)*
See the full changelog in the [GitHub releases](https://github.com/yifanfeng97/hyper-extract/releases).
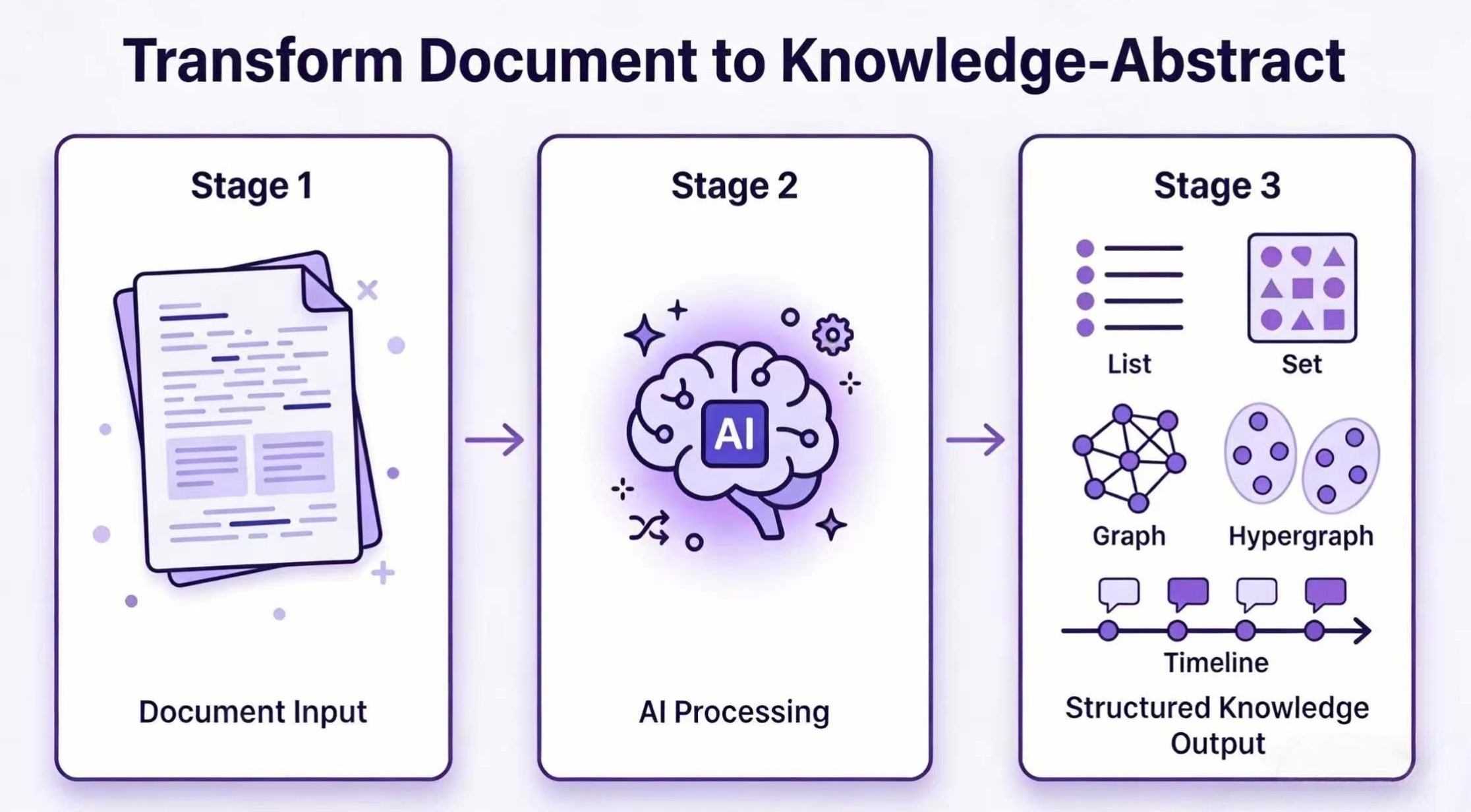
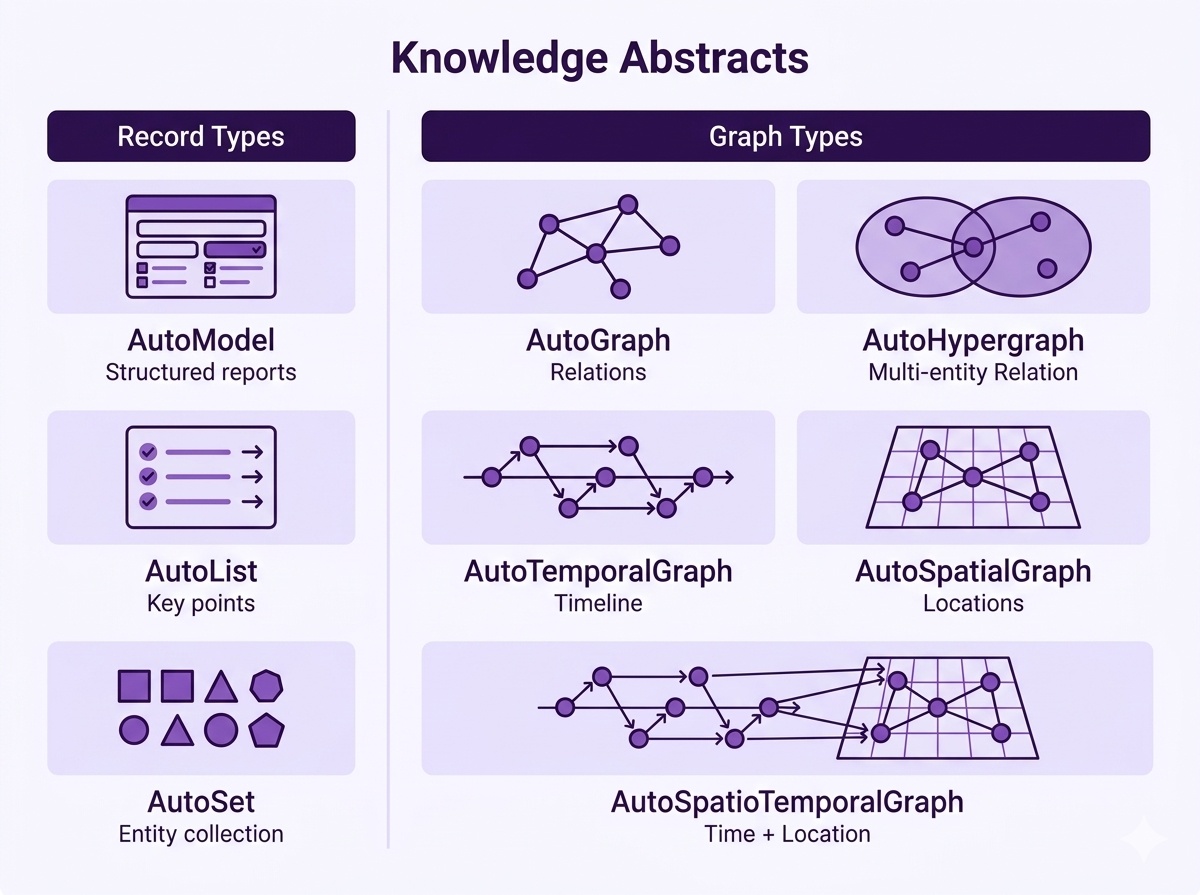
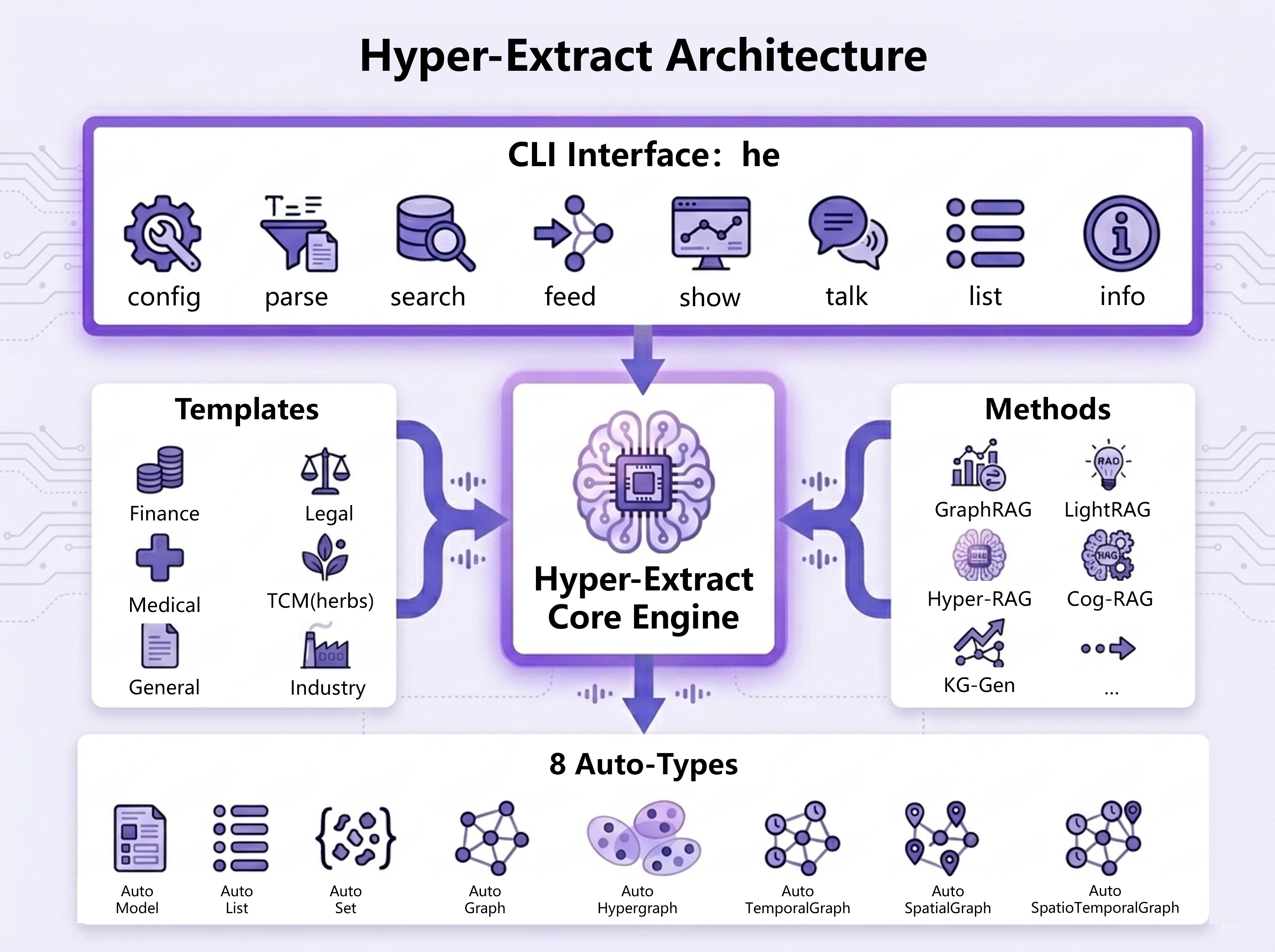
Hyper-Extract is an intelligent, LLM-powered knowledge extraction and evolution framework. It radically simplifies transforming highly unstructured texts into persistent, predictable, and strongly-typed **Knowledge Abstracts**. It effortlessly extracts information into a wide spectrum of formats—ranging from simple **Collections** (Lists/Sets) and **Pydantic Models**, to complex **Knowledge Graphs**, **Hypergraphs**, and even **Spatio-Temporal Graphs**.
## ✨ Core Features
| | |
|:---|:---|
| 🔷 **8 Knowledge Structures** | From simple Lists to advanced Graphs, Hypergraphs, and Spatio-Temporal Graphs |
| 🧠 **10+ Extraction Engines** | GraphRAG, LightRAG, Hyper-RAG, KG-Gen, and more — ready to use |
| 📝 **80+ YAML Templates** | Zero-code extraction across Finance, Legal, Medical, TCM, Industry, and General domains |
| 🔄 **Incremental Evolution** | Feed new documents anytime to expand and refine your knowledge base |
| 📤 **Obsidian Export** | Turn any extracted graph into an Obsidian vault — Markdown notes linked by `[[wikilinks]]` |
## 🎯 What Can You Do With It?


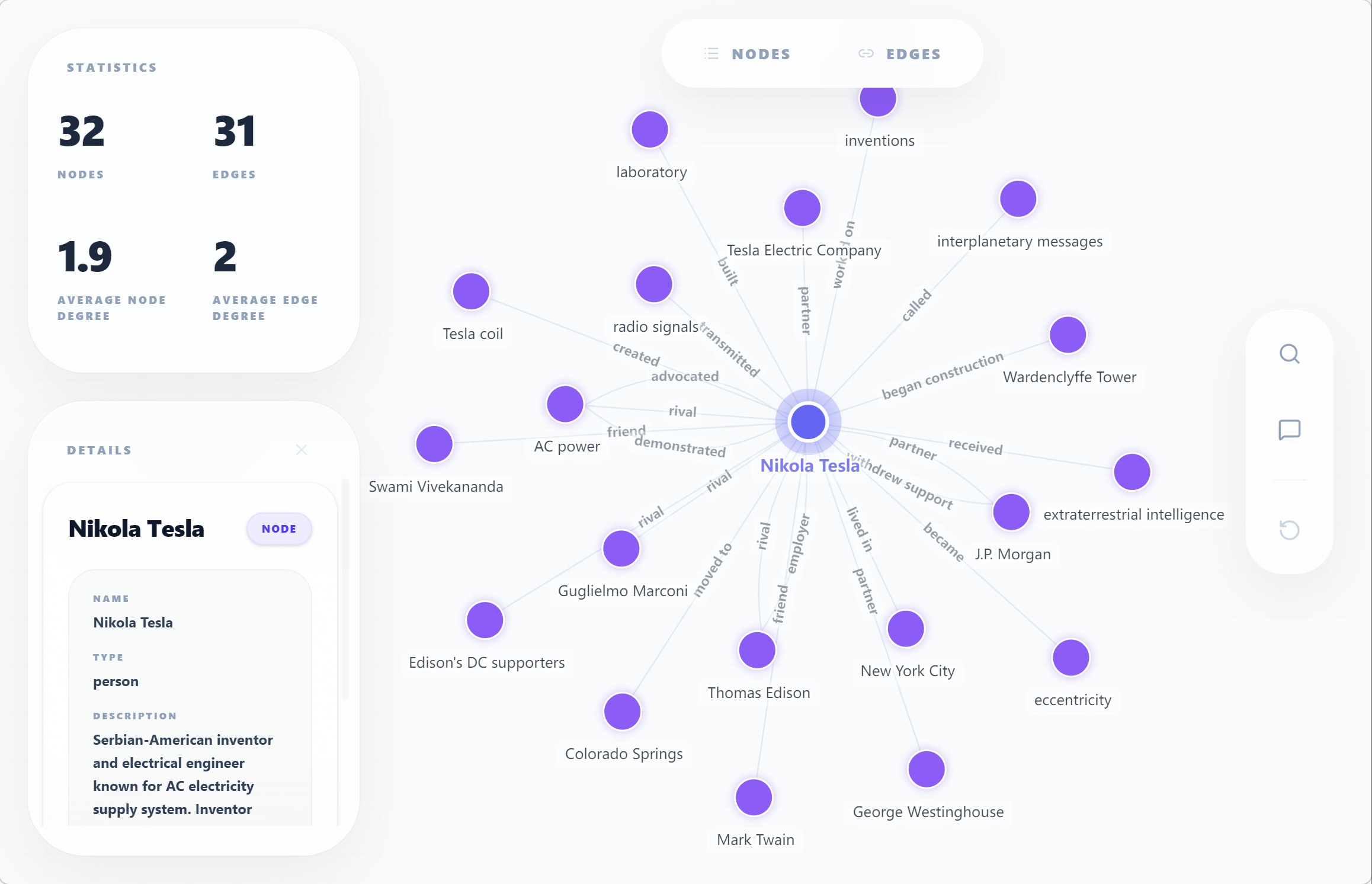
 **Example — AutoGraph visualization:**
**Example — AutoGraph visualization:**
 **Template example (Graph type):**
```yaml
language: en
name: Knowledge Graph
type: graph
tags: [general]
description: 'Extract entities and their relationships.'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [Browse all 80+ templates](./hyperextract/templates/presets/)
- [Create custom templates](./hyperextract/templates/DESIGN_GUIDE.md)
**Template example (Graph type):**
```yaml
language: en
name: Knowledge Graph
type: graph
tags: [general]
description: 'Extract entities and their relationships.'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [Browse all 80+ templates](./hyperextract/templates/presets/)
- [Create custom templates](./hyperextract/templates/DESIGN_GUIDE.md)