**智能知识提取 CLI** **一行命令,将文档转化为结构化知识。** [📖 English Version](./README.md) · [中文版](./README_ZH.md)


> **"Stop reading. Start understanding."** > *"告别文档焦虑,让信息一目了然"*
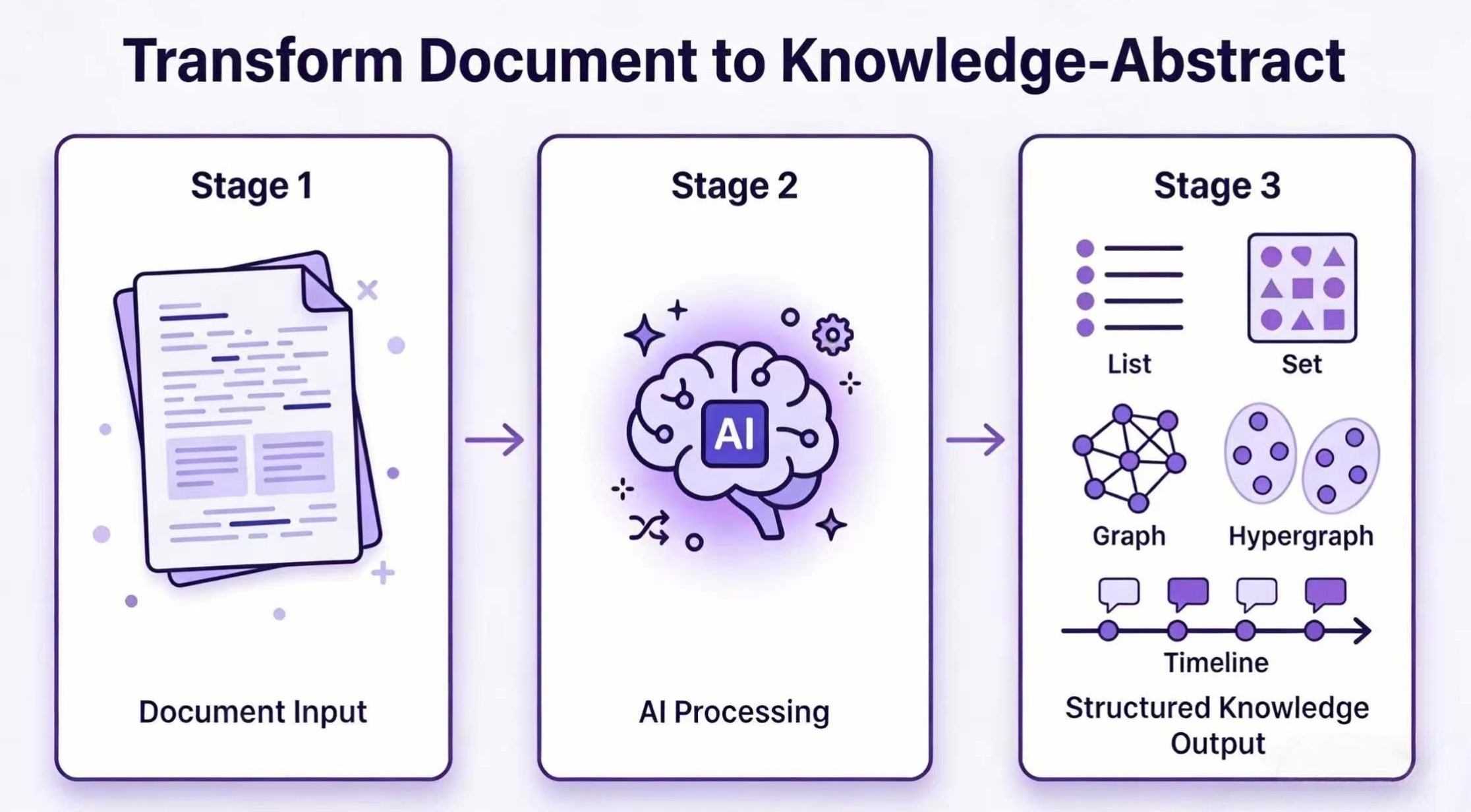
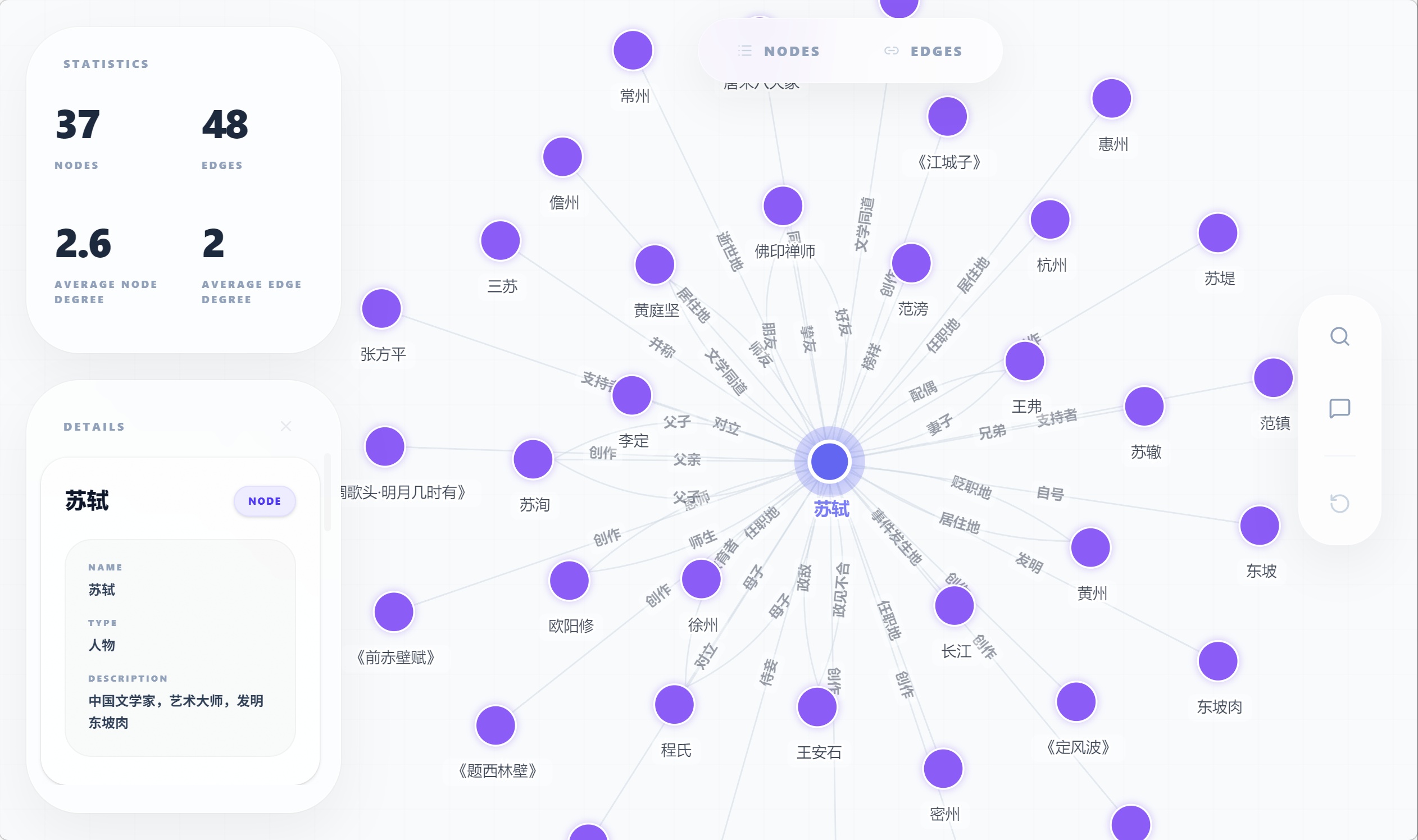
 **示例 — AutoGraph 可视化效果:**
**示例 — AutoGraph 可视化效果:**
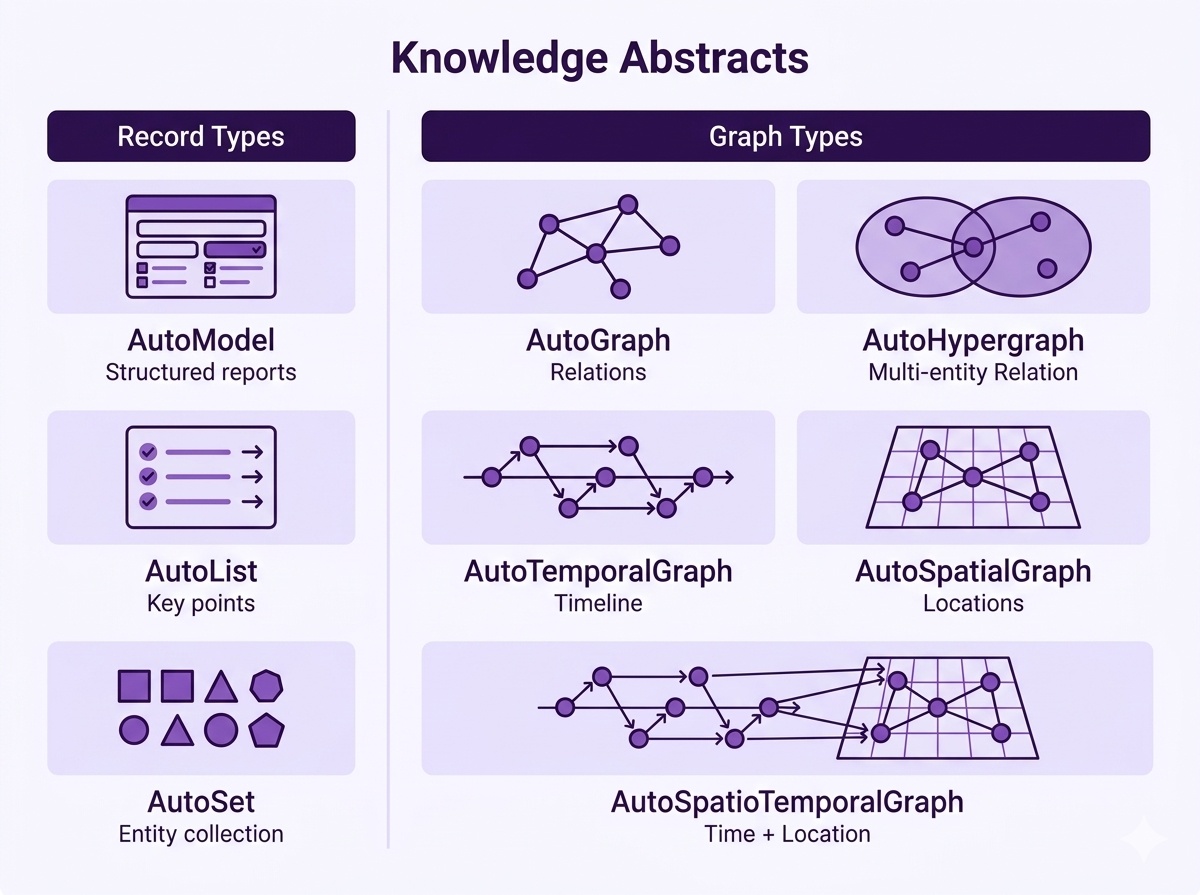
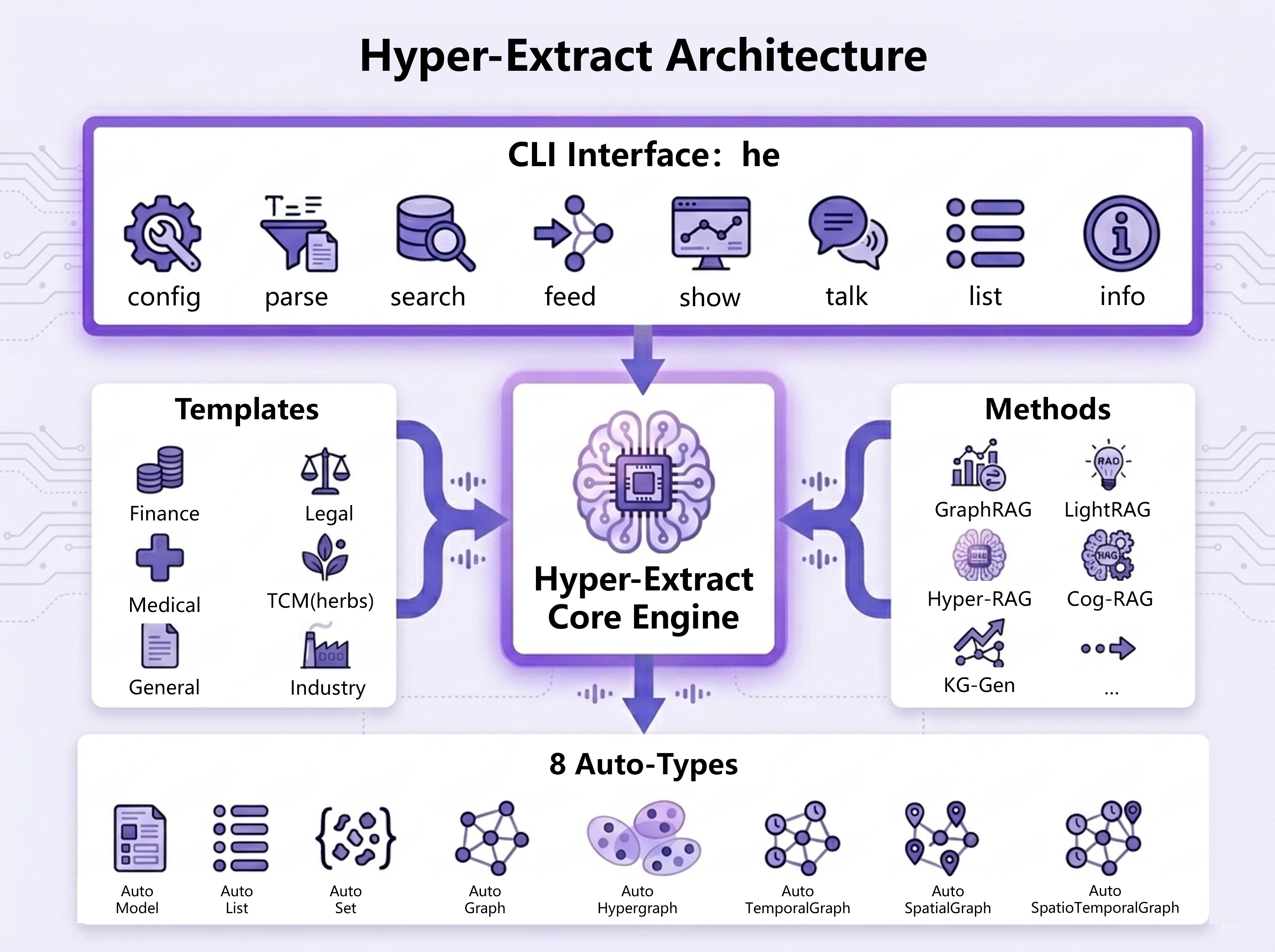 **模板示例(Graph 类型):**
```yaml
language: zh
name: 知识图谱
type: graph
tags: [general]
description: '从文本中提取实体及其关系。'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [浏览全部 80+ 模板](./hyperextract/templates/presets/)
- [创建自定义模板](./hyperextract/templates/DESIGN_GUIDE_ZH.md)
**模板示例(Graph 类型):**
```yaml
language: zh
name: 知识图谱
type: graph
tags: [general]
description: '从文本中提取实体及其关系。'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [浏览全部 80+ 模板](./hyperextract/templates/presets/)
- [创建自定义模板](./hyperextract/templates/DESIGN_GUIDE_ZH.md)