# Skill Seekers
[English](README.md) | [简体中文](README.zh-CN.md) | [日本語](README.ja.md) | [한국어](README.ko.md) | [Español](README.es.md) | [Français](README.fr.md) | Deutsch | [Português](README.pt-BR.md) | [Türkçe](README.tr.md) | [العربية](README.ar.md) | [हिन्दी](README.hi.md) | [Русский](README.ru.md)
> ⚠️ **Hinweis zur maschinellen Übersetzung**
>
> Dieses Dokument wurde automatisch durch KI übersetzt. Trotz Bemühungen um Qualität können ungenaue Ausdrücke vorkommen.
>
> Gerne können Sie über [GitHub Issue #260](https://github.com/yusufkaraaslan/Skill_Seekers/issues/260) zur Verbesserung der Übersetzung beitragen! Ihr Feedback ist uns sehr wertvoll.
[](https://github.com/yusufkaraaslan/Skill_Seekers/releases)
[](https://opensource.org/licenses/MIT)
[](https://www.python.org/downloads/)
[](https://modelcontextprotocol.io)
[](tests/)
[](https://github.com/users/yusufkaraaslan/projects/2)
[](https://pypi.org/project/skill-seekers/)
[](https://pypi.org/project/skill-seekers/)
[](https://pypi.org/project/skill-seekers/)
[](https://pepy.tech/projects/skill-seekers)
[](https://skillseekersweb.com/)
[](https://x.com/_yUSyUS_)
[](https://github.com/yusufkaraaslan/Skill_Seekers)
**Die Datenschicht für KI-Systeme.** Skill Seekers verwandelt Dokumentationswebsites, GitHub-Repositories, PDFs, Videos, Jupyter-Notebooks, Wikis und über 10 weitere Quelltypen in strukturierte Wissensressourcen — bereit für KI-Skills (Claude, Gemini, OpenAI), RAG-Pipelines (LangChain, LlamaIndex, Pinecone) und KI-Programmierassistenten (Cursor, Windsurf, Cline) in Minuten statt Stunden.
> **[Besuchen Sie SkillSeekersWeb.com](https://skillseekersweb.com/)** - Durchsuchen Sie über 24 vorgefertigte Konfigurationen, teilen Sie Ihre Konfigurationen und greifen Sie auf die vollständige Dokumentation zu!
> **[Entwicklungsroadmap und Aufgaben ansehen](https://github.com/users/yusufkaraaslan/projects/2)** - 134 Aufgaben in 10 Kategorien — wählen Sie eine beliebige zum Mitwirken!
## 🌐 Ökosystem
Skill Seekers ist ein Multi-Repository-Projekt. Hier finden Sie alles:
| Repository | Beschreibung | Links |
|-----------|-------------|-------|
| **[Skill_Seekers](https://github.com/yusufkaraaslan/Skill_Seekers)** | Kern-CLI & MCP-Server (dieses Repo) | [PyPI](https://pypi.org/project/skill-seekers/) |
| **[skillseekersweb](https://github.com/yusufkaraaslan/skillseekersweb)** | Website & Dokumentation | [Web](https://skillseekersweb.com/) |
| **[skill-seekers-configs](https://github.com/yusufkaraaslan/skill-seekers-configs)** | Community-Konfigurationsrepository | |
| **[skill-seekers-action](https://github.com/yusufkaraaslan/skill-seekers-action)** | GitHub Action für CI/CD | |
| **[skill-seekers-plugin](https://github.com/yusufkaraaslan/skill-seekers-plugin)** | Claude Code Plugin | |
| **[homebrew-skill-seekers](https://github.com/yusufkaraaslan/homebrew-skill-seekers)** | Homebrew Tap für macOS | |
> **Möchten Sie beitragen?** Die Website- und Konfigurations-Repos sind ideale Einstiegspunkte für neue Mitwirkende!
## Die Datenschicht für KI-Systeme
**Skill Seekers ist die universelle Vorverarbeitungsschicht**, die zwischen Rohdokumentation und jedem KI-System steht, das diese konsumiert. Ob Sie Claude-Skills, eine LangChain-RAG-Pipeline oder eine Cursor-`.cursorrules`-Datei erstellen — die Datenaufbereitung ist identisch. Sie führen sie einmal durch und exportieren für alle Zielplattformen.
```bash
# Ein Befehl → strukturierte Wissensressource
skill-seekers create https://docs.react.dev/
# oder: skill-seekers create facebook/react
# oder: skill-seekers create ./my-project
# Export in jedes KI-System
skill-seekers package output/react --target claude # → Claude AI Skill (ZIP)
skill-seekers package output/react --target langchain # → LangChain Documents
skill-seekers package output/react --target llama-index # → LlamaIndex TextNodes
skill-seekers package output/react --target cursor # → .cursorrules
skill-seekers package output/react --target ibm-bob # → IBM Bob Skill-Verzeichnis
```
### Was erstellt wird
| Ausgabe | Ziel | Einsatzbereich |
|---------|------|---------------|
| **Claude Skill** (ZIP + YAML) | `--target claude` | Claude Code, Claude API |
| **Gemini Skill** (tar.gz) | `--target gemini` | Google Gemini |
| **OpenAI / Custom GPT** (ZIP) | `--target openai` | GPT-4o, benutzerdefinierte Assistenten |
| **LangChain Documents** | `--target langchain` | QA-Chains, Agenten, Retriever |
| **LlamaIndex TextNodes** | `--target llama-index` | Query Engines, Chat Engines |
| **Haystack Documents** | `--target haystack` | Enterprise-RAG-Pipelines |
| **Pinecone-ready** (Markdown) | `--target markdown` | Vektor-Upsert |
| **ChromaDB / FAISS / Qdrant** | `--target chroma/faiss/qdrant` | Lokale Vektordatenbanken |
| **IBM Bob Skill** (Verzeichnis) | `--target ibm-bob` | IBM Bob Projekt-/globale Skills |
| **Cursor** `.cursorrules` | `--target markdown` → SKILL.md kopieren | Cursor IDE `.cursorrules` |
| **Windsurf / Cline / Continue** | `--target claude` → kopieren | VS Code, IntelliJ, Vim |
### Warum Skill Seekers
- **99 % schneller** — Tage manueller Datenaufbereitung → 15–45 Minuten
- **KI-Skill-Qualität** — Über 500 Zeilen SKILL.md-Dateien mit Beispielen, Mustern und Anleitungen
- **RAG-fertige Chunks** — Intelligentes Chunking bewahrt Codeblöcke und Kontext
- **18 Quelltypen** — Dokumentation + GitHub + PDF + Videos + Notebooks + Wikis u. v. m. zu einer Wissensressource vereinen
- **Einmal aufbereiten, überall exportieren** — Export auf 21 Plattformen ohne erneutes Scrapen
- **Videos** — Code, Transkripte und strukturiertes Wissen aus YouTube- und lokalen Videos extrahieren
- **Kampferprobt** — Über 3.700 Tests, 24+ Framework-Presets, produktionsreif
## Schnellstart (3 Befehle)
```bash
# 1. Installieren
pip install skill-seekers
# 2. Skill aus beliebiger Quelle erstellen
skill-seekers create https://docs.django.com/
# 3. Für Ihre KI-Plattform paketieren
skill-seekers package output/django --target claude
```
**Das war's!** Sie haben nun `output/django-claude.zip` einsatzbereit.
```bash
# Einen anderen KI-Agenten für die Verbesserung verwenden (Standard: claude)
skill-seekers create https://docs.django.com/ --agent kimi
skill-seekers create https://docs.django.com/ --agent codex
skill-seekers create https://docs.django.com/ --agent-cmd "my-custom-agent run"
```
### KI-gestützter Projekt-Scan (neu)
Richten Sie `scan` auf ein beliebiges Projekt: Ein KI-Agent liest dessen Manifeste, README,
Dockerfile/CI und gesampelte Quellcode-Imports — und erstellt dann eine Konfiguration pro
erkanntem Framework sowie eine `-codebase.json` für Ihren eigenen Code. Die erkannte
Version wird festgehalten, sodass ein erneuter Lauf Versionssprünge meldet:
```bash
skill-seekers scan ./my-react-app --out ./configs/scanned/
# → react.json, vite.json, tailwind.json, jest.json, my-react-app-codebase.json
# Anschließend beliebige davon erstellen
skill-seekers create ./configs/scanned/react.json
```
Gibt es für eine Erkennung kein vorhandenes Preset, generiert die KI eine neue Konfiguration;
beim Beenden können Sie diese optional in die [Community-Registry](https://github.com/yusufkaraaslan/skill-seekers-configs) zurückveröffentlichen.
### Weitere Quellen (18 unterstützt)
```bash
# GitHub-Repository
skill-seekers create facebook/react
# Lokales Projekt
skill-seekers create ./my-project
# PDF-Dokument
skill-seekers create manual.pdf
# Word-Dokument
skill-seekers create report.docx
# EPUB-E-Book
skill-seekers create book.epub
# Jupyter Notebook
skill-seekers create notebook.ipynb
# OpenAPI-Spezifikation
skill-seekers create openapi.yaml
# PowerPoint-Präsentation
skill-seekers create presentation.pptx
# AsciiDoc-Dokument
skill-seekers create guide.adoc
# Lokale HTML-Datei (automatisch anhand der Erweiterung erkannt)
skill-seekers create page.html
# Ganzes Verzeichnis mit HTML-Dateien (automatisch erkannt bei HTML-dominanten Verzeichnissen)
skill-seekers create ./mirror_output/site/
# HTML-Modus für gemischte/code-lastige Verzeichnisse erzwingen
skill-seekers create ./repo/ --html-path ./repo/docs/build/html/
# RSS-/Atom-Feed
skill-seekers create feed.rss
# Man-Page
skill-seekers create curl.1
# Video (YouTube, Vimeo oder lokale Datei — erfordert skill-seekers[video])
skill-seekers create --video-url https://www.youtube.com/watch?v=... --name mytutorial
# Erstmalig? Automatische Installation GPU-bewusster visueller Abhängigkeiten:
skill-seekers create --setup
# Confluence-Wiki
skill-seekers create --space-key TEAM --name wiki
# Notion-Seiten
skill-seekers create --database-id ... --name docs
# Slack-/Discord-Chatexport
skill-seekers create --chat-export-path ./slack-export --name team-chat
```
### Überallhin exportieren
```bash
# Für mehrere Plattformen paketieren
for platform in claude gemini openai langchain; do
skill-seekers package output/django --target $platform
done
```
## Was ist Skill Seekers?
Skill Seekers ist die **Datenschicht für KI-Systeme** und transformiert 18 Quelltypen — Dokumentationswebsites, GitHub-Repositories, PDFs, Videos, Jupyter-Notebooks, Word-/EPUB-/AsciiDoc-Dokumente, OpenAPI/Swagger-Spezifikationen, PowerPoint-Präsentationen, RSS/Atom-Feeds, Man-Pages, Confluence-Wikis, Notion-Seiten, Slack-/Discord-Chatexporte und mehr — in strukturierte Wissensressourcen für jedes KI-Ziel:
| Anwendungsfall | Ergebnis | Beispiele |
|----------------|----------|-----------|
| **KI-Skills** | Umfassende SKILL.md + Referenzdateien | Claude Code, Gemini, GPT |
| **RAG-Pipelines** | Dokumenten-Chunks mit reichhaltigen Metadaten | LangChain, LlamaIndex, Haystack |
| **Vektordatenbanken** | Vorformatierte, upload-bereite Daten | Pinecone, Chroma, Weaviate, FAISS |
| **KI-Programmierassistenten** | Kontextdateien, die Ihre IDE-KI automatisch liest | Cursor, Windsurf, Cline, Continue.dev |
## Dokumentation
| Ich möchte... | Lesen Sie dies |
|---------------|----------------|
| **Schnell loslegen** | [Schnellstart](docs/getting-started/02-quick-start.md) - 3 Befehle bis zum ersten Skill |
| **Konzepte verstehen** | [Kernkonzepte](docs/user-guide/01-core-concepts.md) - So funktioniert es |
| **Quellen scrapen** | [Scraping-Anleitung](docs/user-guide/02-scraping.md) - Alle Quelltypen |
| **Skills verbessern** | [Verbesserungs-Anleitung](docs/user-guide/03-enhancement.md) - KI-Verbesserung |
| **Skills exportieren** | [Paketierungs-Anleitung](docs/user-guide/04-packaging.md) - Plattform-Export |
| **Befehle nachschlagen** | [CLI-Referenz](docs/reference/CLI_REFERENCE.md) - Alle 20 Befehle |
| **Konfigurieren** | [Konfigurationsformat](docs/reference/CONFIG_FORMAT.md) - JSON-Spezifikation |
| **Probleme beheben** | [Fehlerbehebung](docs/user-guide/06-troubleshooting.md) - Häufige Probleme |
**Vollständige Dokumentation:** [docs/README.md](docs/README.md)
Anstatt tagelange manuelle Vorverarbeitung durchzuführen, erledigt Skill Seekers dies:
1. **Erfassen** — Dokumentation, GitHub-Repos, lokale Codebasen, PDFs, Videos, Jupyter-Notebooks, Wikis und über 10 weitere Quelltypen
2. **Analysieren** — Tiefgreifendes AST-Parsing, Mustererkennung, API-Extraktion
3. **Strukturieren** — Kategorisierte Referenzdateien mit Metadaten
4. **Verbessern** — KI-gestützte SKILL.md-Generierung (Claude, Gemini oder lokal)
5. **Exportieren** — 16 plattformspezifische Formate aus einer Ressource
## Warum Skill Seekers nutzen?
### Für KI-Skill-Ersteller (Claude, Gemini, OpenAI)
- **Produktionsreife Skills** — Über 500 Zeilen SKILL.md-Dateien mit Codebeispielen, Mustern und Anleitungen
- **Verbesserungsworkflows** — `security-focus`, `architecture-comprehensive` oder eigene YAML-Presets anwenden
- **Jede Domäne** — Game-Engines (Godot, Unity), Frameworks (React, Django), interne Tools
- **Teamarbeit** — Interne Dokumentation + Code zu einer einzigen Wissensquelle vereinen
- **Hohe Qualität** — KI-verbessert mit Beispielen, Kurzreferenz und Navigationshinweisen
### Für RAG-Entwickler und KI-Ingenieure
- **RAG-fertige Daten** — Vorgesplittete LangChain `Documents`, LlamaIndex `TextNodes`, Haystack `Documents`
- **99 % schneller** — Tage der Vorverarbeitung → 15–45 Minuten
- **Intelligente Metadaten** — Kategorien, Quellen, Typen → höhere Abrufgenauigkeit
- **Multi-Source** — Dokumentation + GitHub + PDFs in einer Pipeline kombinieren
- **Plattformunabhängig** — Export in jede Vektordatenbank oder jedes Framework ohne erneutes Scrapen
### Für KI-Programmierassistenten-Nutzer
- **Cursor / Windsurf / Cline** — `.cursorrules` / `.windsurfrules` / `.clinerules` automatisch generieren
- **Dauerhafter Kontext** — Die KI „kennt" Ihre Frameworks ohne wiederholtes Prompting
- **Immer aktuell** — Kontext in Minuten aktualisieren, wenn sich die Dokumentation ändert
## Kernfunktionen
### Dokumentations-Scraping
- **Intelligente SPA-Erkennung** - Dreischichtige Erkennung für JavaScript-SPA-Websites (sitemap.xml → llms.txt → Headless-Browser-Rendering)
- **llms.txt-Unterstützung** - Erkennt und nutzt automatisch LLM-bereite Dokumentationsdateien (10x schneller)
- **Universal-Scraper** - Funktioniert mit JEDER Dokumentationswebsite
- **Intelligente Kategorisierung** - Organisiert Inhalte automatisch nach Themen
- **Code-Spracherkennung** - Erkennt Python, JavaScript, C++, GDScript usw.
- **Über 24 fertige Presets** - Godot, React, Vue, Django, FastAPI und mehr
### PDF-Unterstützung
- **Grundlegende PDF-Extraktion** - Text, Code und Bilder aus PDFs extrahieren
- **OCR für gescannte PDFs** - Text aus gescannten Dokumenten extrahieren
- **Passwortgeschützte PDFs** - Verschlüsselte PDFs verarbeiten
- **Tabellenextraktion** - Komplexe Tabellen aus PDFs extrahieren
- **Parallelverarbeitung** - 3x schneller bei großen PDFs
- **Intelligentes Caching** - 50 % schneller bei Wiederholungen
### Videoextraktion
- **YouTube und lokale Videos** - Transkripte, Bildschirmcode und strukturiertes Wissen aus Videos extrahieren
- **Visuelle Frameanalyse** - OCR-Extraktion aus Code-Editoren, Terminals, Folien und Diagrammen
- **GPU-Autoerkennung** - Installiert automatisch den richtigen PyTorch-Build (CUDA/ROCm/MPS/CPU)
- **KI-Verbesserung** - Zwei Durchläufe: OCR-Artefakte bereinigen + ausgefeilte SKILL.md generieren
- **Zeitausschnitte** - Bestimmte Abschnitte mit `--start-time` und `--end-time` extrahieren
- **Playlist-Unterstützung** - Alle Videos einer YouTube-Playlist stapelweise verarbeiten
- **Vision-API-Fallback** - Claude Vision für OCR-Frames mit niedriger Konfidenz verwenden
### GitHub-Repository-Analyse
- **Tiefgreifende Codeanalyse** - AST-Parsing für Python, JavaScript, TypeScript, Java, C++, Go
- **API-Extraktion** - Funktionen, Klassen, Methoden mit Parametern und Typen
- **Repository-Metadaten** - README, Dateibaum, Sprachverteilung, Stars/Forks
- **GitHub Issues und PRs** - Offene/geschlossene Issues mit Labels und Meilensteinen abrufen
- **CHANGELOG und Releases** - Versionshistorie automatisch extrahieren
- **Konflikterkennung** - Dokumentierte APIs mit tatsächlicher Code-Implementierung vergleichen
- **MCP-Integration** - Natürliche Sprache: „Scrape GitHub Repo facebook/react"
### Vereinheitlichtes Multi-Source-Scraping
- **Mehrere Quellen kombinieren** - Dokumentation + GitHub + PDF in einem Skill vereinen
- **Konflikterkennung** - Automatische Erkennung von Abweichungen zwischen Dokumentation und Code
- **Intelligentes Zusammenführen** - Regelbasierte oder KI-gesteuerte Konfliktlösung
- **Transparente Berichte** - Nebeneinander-Vergleich mit Warnhinweisen
- **Dokumentationslückenanalyse** - Erkennt veraltete Dokumentation und undokumentierte Funktionen
- **Einzelne Wahrheitsquelle** - Ein Skill zeigt sowohl Absicht (Dokumentation) als auch Realität (Code)
- **Abwärtskompatibel** - Bestehende Einzelquellen-Konfigurationen funktionieren weiterhin
### Multi-LLM-Plattformunterstützung
- **12 LLM-Plattformen** - Claude AI, Google Gemini, OpenAI ChatGPT, MiniMax AI, Generisches Markdown, OpenCode, Kimi (Moonshot AI), DeepSeek AI, Qwen (Alibaba), OpenRouter, Together AI, Fireworks AI
- **Universelles Scraping** - Dieselbe Dokumentation funktioniert für alle Plattformen
- **Plattformspezifische Paketierung** - Optimierte Formate für jedes LLM
- **Ein-Befehl-Export** - `--target`-Flag wählt die Plattform
- **Optionale Abhängigkeiten** - Nur installieren, was Sie benötigen
- **100 % abwärtskompatibel** - Bestehende Claude-Workflows bleiben unverändert
| Plattform | Format | Upload | Verbesserung | API Key | Benutzerdefinierter Endpunkt |
|-----------|--------|--------|-------------|---------|------------------------------|
| **Claude AI** | ZIP + YAML | Auto | Ja | ANTHROPIC_API_KEY | ANTHROPIC_BASE_URL |
| **Google Gemini** | tar.gz | Auto | Ja | GOOGLE_API_KEY | - |
| **OpenAI ChatGPT** | ZIP + Vector Store | Auto | Ja | OPENAI_API_KEY | - |
| **MiniMax AI** | ZIP + Knowledge Files | Auto | Ja | MINIMAX_API_KEY | - |
| **Generisches Markdown** | ZIP | Manuell | Nein | - | - |
```bash
# Claude (Standard - keine Änderungen nötig!)
skill-seekers package output/react/
skill-seekers upload react.zip
# Google Gemini
pip install skill-seekers[gemini]
skill-seekers package output/react/ --target gemini
skill-seekers upload react-gemini.tar.gz --target gemini
# OpenAI ChatGPT
pip install skill-seekers[openai]
skill-seekers package output/react/ --target openai
skill-seekers upload react-openai.zip --target openai
# MiniMax AI
pip install skill-seekers[minimax]
skill-seekers package output/react/ --target minimax
skill-seekers upload react-minimax.zip --target minimax
# Generisches Markdown (universeller Export)
skill-seekers package output/react/ --target markdown
# Die Markdown-Dateien direkt in jedem LLM verwenden
```
Eigenen KI-Anbieter verwenden (OpenAI-kompatible Endpunkte + Abonnements, keine Anthropic-Credits nötig)
Der optionale KI-**Verbesserungsschritt** (verwendet von `create`, `scan` und `enhance`) erfordert **keinen** Anthropic-Key. Sie haben drei Möglichkeiten, ihn zu betreiben:
**1. Ein Abonnement nutzen, das Sie bereits bezahlen — ganz ohne API-Credits (LOCAL-Agentenmodus)**
Skill Seekers kann eine Coding-Agent-CLI aufrufen, bei der Sie bereits angemeldet sind, sodass die Verbesserung über Ihren bestehenden Tarif läuft statt über abgerechnete API-Tokens:
```bash
skill-seekers create --agent codex # OpenAI Codex CLI → Ihr ChatGPT Plus
skill-seekers create --agent claude # Claude Code → Ihr Claude Pro/Max
```
Unterstützte Agenten: `claude`, `codex`, `copilot`, `opencode`, `kimi` und `custom`
(kombinieren Sie `--agent custom` mit `--agent-cmd " ..."`, um jedes andere Tool anzusteuern).
**2. Jeder OpenAI-kompatible Anbieter (OpenRouter, Groq, Cerebras, Mistral, NVIDIA NIM, …)**
Alle diese Anbieter stellen einen OpenAI-kompatiblen `/v1`-Endpunkt bereit. Richten Sie Skill Seekers mit drei Umgebungsvariablen darauf aus — es erkennt `OPENAI_API_KEY`, und das OpenAI SDK berücksichtigt `OPENAI_BASE_URL` automatisch:
```bash
export OPENAI_API_KEY=""
export OPENAI_BASE_URL="https://openrouter.ai/api/v1" # Anbieter-Endpunkt (siehe Tabelle)
export OPENAI_MODEL="" # erforderlich — der Standard gpt-4o existiert anderswo nicht
skill-seekers create
```
| Anbieter | `OPENAI_BASE_URL` |
|--------------|--------------------------------------------|
| OpenRouter | `https://openrouter.ai/api/v1` |
| Groq | `https://api.groq.com/openai/v1` |
| Cerebras | `https://api.cerebras.ai/v1` |
| Mistral | `https://api.mistral.ai/v1` |
| NVIDIA NIM | `https://integrate.api.nvidia.com/v1` |
> Die Anbieter-Erkennung wählt die **erste** gefundene API-Key-Umgebungsvariable (`ANTHROPIC_API_KEY` → `GOOGLE_API_KEY` → `OPENAI_API_KEY` → `MOONSHOT_API_KEY`). Setzen Sie `SKILL_SEEKER_PROVIDER`, um einen bestimmten Anbieter zu erzwingen, oder stellen Sie sicher, dass die höher priorisierten Keys nicht gesetzt sind.
**3. Claude-kompatible Endpunkte (z. B. GLM, Proxys)**
```bash
export ANTHROPIC_API_KEY="your-key"
export ANTHROPIC_BASE_URL="https://your-claude-compatible-endpoint/v1"
```
Google Gemini (`GOOGLE_API_KEY`) und Kimi/Moonshot (`MOONSHOT_API_KEY`) werden ebenfalls nativ unterstützt. Die vollständige Liste — einschließlich anbieterspezifischer Modell-Overrides — finden Sie in der **[Umgebungsvariablen-Referenz](docs/reference/ENVIRONMENT_VARIABLES.md#llm-provider-selection)**.
**Installation:**
```bash
# Mit Gemini-Unterstützung installieren
pip install skill-seekers[gemini]
# Mit OpenAI-Unterstützung installieren
pip install skill-seekers[openai]
# Mit MiniMax-Unterstützung installieren
pip install skill-seekers[minimax]
# Mit allen LLM-Plattformen installieren
pip install skill-seekers[all-llms]
```
### RAG-Framework-Integrationen
- **LangChain Documents** - Direkter Export ins `Document`-Format mit `page_content` + Metadaten
- Geeignet für: QA-Chains, Retriever, Vektorspeicher, Agenten
- Beispiel: [LangChain RAG-Pipeline](examples/langchain-rag-pipeline/)
- Anleitung: [LangChain-Integration](docs/integrations/LANGCHAIN.md)
- **LlamaIndex TextNodes** - Export ins `TextNode`-Format mit eindeutigen IDs + Embeddings
- Geeignet für: Query Engines, Chat Engines, Storage Context
- Beispiel: [LlamaIndex Query Engine](examples/llama-index-query-engine/)
- Anleitung: [LlamaIndex-Integration](docs/integrations/LLAMA_INDEX.md)
- **Pinecone-fertiges Format** - Optimiert für Vektordatenbank-Upsert
- Geeignet für: Produktions-Vektorsuche, semantische Suche, Hybridsuche
- Beispiel: [Pinecone Upsert](examples/pinecone-upsert/)
- Anleitung: [Pinecone-Integration](docs/integrations/PINECONE.md)
**Schnellexport:**
```bash
# LangChain Documents (JSON)
skill-seekers package output/django --target langchain
# → output/django-langchain.json
# LlamaIndex TextNodes (JSON)
skill-seekers package output/django --target llama-index
# → output/django-llama-index.json
# Markdown (Universal)
skill-seekers package output/django --target markdown
# → output/django-markdown/SKILL.md + references/
```
**Vollständige RAG-Pipeline-Anleitung:** [RAG-Pipelines-Dokumentation](docs/integrations/RAG_PIPELINES.md)
---
### KI-Programmierassistenten-Integrationen
Verwandeln Sie beliebige Framework-Dokumentation in Experten-Programmierkontext für über 4 KI-Assistenten:
- **Cursor IDE** - `.cursorrules` für KI-gestützte Codevorschläge generieren
- Geeignet für: Framework-spezifische Codegenerierung, konsistente Muster
- Anleitung: [Cursor-Integration](docs/integrations/CURSOR.md)
- Beispiel: [Cursor React Skill](examples/cursor-react-skill/)
- **Windsurf** - Windsurf-KI-Assistentenkontext mit `.windsurfrules` anpassen
- Geeignet für: IDE-native KI-Unterstützung, Flow-basiertes Programmieren
- Anleitung: [Windsurf-Integration](docs/integrations/WINDSURF.md)
- Beispiel: [Windsurf FastAPI Kontext](examples/windsurf-fastapi-context/)
- **Cline (VS Code)** - System-Prompts + MCP für VS Code Agenten
- Geeignet für: Agentische Codegenerierung in VS Code
- Anleitung: [Cline-Integration](docs/integrations/CLINE.md)
- Beispiel: [Cline Django Assistent](examples/cline-django-assistant/)
- **Continue.dev** - Kontextserver für IDE-unabhängige KI
- Geeignet für: Multi-IDE-Umgebungen (VS Code, JetBrains, Vim), benutzerdefinierte LLM-Anbieter
- Anleitung: [Continue-Integration](docs/integrations/CONTINUE_DEV.md)
- Beispiel: [Continue Universal Kontext](examples/continue-dev-universal/)
**Schnellexport (für KI-Programmiertools):**
```bash
# Für jeden KI-Programmierassistenten (Cursor, Windsurf, Cline, Continue.dev)
skill-seekers create --config configs/django.json
skill-seekers package output/django --target claude
# In Ihr Projekt kopieren (Beispiel für Cursor)
cp output/django-claude/SKILL.md my-project/.cursorrules
# Oder für Windsurf
cp output/django-claude/SKILL.md my-project/.windsurf/rules/django.md
# Oder für Cline
cp output/django-claude/SKILL.md my-project/.clinerules
```
**Integrations-Hub:** [Alle KI-System-Integrationen](docs/integrations/INTEGRATIONS.md)
---
### Drei-Stream-GitHub-Architektur
- **Triple-Stream-Analyse** - GitHub-Repos in Code-, Dokumentations- und Insights-Streams aufteilen
- **Vereinheitlichter Codebase-Analyzer** - Funktioniert mit GitHub-URLs UND lokalen Pfaden
- **C3.x als Analysetiefe** - „basic" (1–2 Min.) oder „c3x" (20–60 Min.) Analyse wählen
- **Erweiterte Router-Generierung** - GitHub-Metadaten, README-Schnellstart, häufige Probleme
- **Issue-Integration** - Häufigste Probleme und Lösungen aus GitHub Issues
- **Intelligente Routing-Schlüsselwörter** - GitHub-Labels 2x gewichtet für bessere Themenerkennung
**Drei Streams erklärt:**
- **Stream 1: Code** - Tiefgreifende C3.x-Analyse (Muster, Beispiele, Anleitungen, Konfigurationen, Architektur)
- **Stream 2: Dokumentation** - Repository-Dokumentation (README, CONTRIBUTING, docs/*.md)
- **Stream 3: Insights** - Community-Wissen (Issues, Labels, Stars, Forks)
```python
from skill_seekers.cli.unified_codebase_analyzer import UnifiedCodebaseAnalyzer
# GitHub-Repo mit allen drei Streams analysieren
analyzer = UnifiedCodebaseAnalyzer()
result = analyzer.analyze(
source="https://github.com/facebook/react",
depth="c3x", # oder "basic" für schnelle Analyse
fetch_github_metadata=True
)
print(f"Design patterns: {len(result.code_analysis['c3_1_patterns'])}")
print(f"Stars: {result.github_insights['metadata']['stars']}")
```
**Vollständige Dokumentation**: [Drei-Stream-Implementierungszusammenfassung](docs/archive/historical/IMPLEMENTATION_SUMMARY_THREE_STREAM.md)
### Intelligentes Rate-Limit-Management und Konfiguration
- **Multi-Token-Konfigurationssystem** - Mehrere GitHub-Konten verwalten (Privat, Arbeit, Open Source)
- Sichere Konfigurationsspeicherung unter `~/.config/skill-seekers/config.json` (Berechtigung 600)
- Rate-Limit-Strategien pro Profil: `prompt`, `wait`, `switch`, `fail`
- Intelligente Fallback-Kette: CLI-Argument → Umgebungsvariable → Konfigurationsdatei → Abfrage
- **Interaktiver Konfigurationsassistent** - Ansprechende Terminal-UI für einfache Einrichtung
- **Intelligenter Rate-Limit-Handler** - Kein endloses Warten mehr!
- Echtzeit-Countdown, automatischer Profilwechsel
- Vier Strategien: prompt (fragen), wait (Countdown), switch (wechseln), fail (abbrechen)
- **Wiederaufnahme-Funktion** - Unterbrochene Aufgaben fortsetzen
- **CI/CD-Unterstützung** - `--non-interactive`-Flag für Automatisierung
**Schnelleinrichtung:**
```bash
# Einmalige Konfiguration (5 Minuten)
skill-seekers config --github
# Spezifisches Profil für private Repositories verwenden
skill-seekers create mycompany/private-repo --profile work
# CI/CD-Modus (schnelles Abbrechen, keine Abfragen)
skill-seekers create owner/repo --non-interactive
# Unterbrochenen Job fortsetzen
skill-seekers resume --list
skill-seekers resume github_react_20260117_143022
```
**Rate-Limit-Strategien erklärt:**
- **prompt** (Standard) - Fragt bei Erreichen des Limits, was zu tun ist (warten, wechseln, Token einrichten, abbrechen)
- **wait** - Wartet automatisch mit Countdown (respektiert das Timeout)
- **switch** - Versucht automatisch das nächste verfügbare Profil (für Multi-Konto-Setups)
- **fail** - Bricht sofort mit klarer Fehlermeldung ab (ideal für CI/CD)
### Bootstrap-Skill - Selbst-Hosting
Skill Seekers selbst als Skill generieren, um es innerhalb Ihres KI-Agenten zu verwenden (Claude Code, Kimi, Codex usw.):
```bash
# Skill generieren
./scripts/bootstrap_skill.sh
# In Claude Code installieren
cp -r output/skill-seekers ~/.claude/skills/
```
**Was Sie erhalten:**
- **Vollständige Skill-Dokumentation** - Alle CLI-Befehle und Nutzungsmuster
- **CLI-Befehlsreferenz** - Jedes Tool und seine Optionen dokumentiert
- **Schnellstart-Beispiele** - Gängige Workflows und Best Practices
- **Auto-generierte API-Dokumentation** - Codeanalyse, Muster und Beispiele
### Private Konfigurations-Repositories
- **Git-basierte Konfigurationsquellen** - Konfigurationen aus privaten/Team-Git-Repositories abrufen
- **Multi-Source-Verwaltung** - Unbegrenzte GitHub-, GitLab-, Bitbucket-Repositories registrieren
- **Team-Zusammenarbeit** - Benutzerdefinierte Konfigurationen in 3–5-Personen-Teams teilen
- **Enterprise-Unterstützung** - Skalierung auf 500+ Entwickler
- **Sichere Authentifizierung** - Umgebungsvariablen-Tokens (GITHUB_TOKEN, GITLAB_TOKEN)
### Codebase-Analyse (C3.x)
**C3.4: Konfigurationsmuster-Extraktion (mit KI-Verbesserung)**
- **9 Konfigurationsformate** - JSON, YAML, TOML, ENV, INI, Python, JavaScript, Dockerfile, Docker Compose
- **7 Mustertypen** - Datenbank-, API-, Logging-, Cache-, E-Mail-, Auth-, Server-Konfigurationen
- **KI-Verbesserung** - Optionale Dual-Modus-KI-Analyse (API + LOCAL)
- **Sicherheitsanalyse** - Hartcodierte Geheimnisse und offengelegte Anmeldedaten finden
**C3.3: KI-verbesserte Anleitungen**
- **Umfassende KI-Verbesserung** - Grundanleitungen in professionelle Tutorials verwandeln
- **5 automatische Verbesserungen** - Schrittbeschreibungen, Fehlerbehebung, Voraussetzungen, nächste Schritte, Anwendungsfälle
- **Dual-Modus-Unterstützung** - API-Modus (Claude API) oder LOCAL-Modus (Claude Code CLI)
- **LOCAL-Modus kostenlos** - Kostenlose Verbesserung mit Ihrem Claude Code Max Plan
**Verwendung:**
```bash
# Schnellanalyse (1–2 Minuten, nur Grundfunktionen)
skill-seekers scan tests/ --quick
# Umfassende Analyse (mit KI, 20–60 Minuten)
skill-seekers scan tests/ --comprehensive
# Mit KI-Verbesserung
skill-seekers scan tests/ --enhance
```
**Vollständige Dokumentation:** [docs/features/HOW_TO_GUIDES.md](docs/features/HOW_TO_GUIDES.md#ai-enhancement-new)
### Verbesserungs-Workflow-Presets
Wiederverwendbare YAML-definierte Verbesserungspipelines, die steuern, wie KI Ihre Rohdokumentation in einen ausgefeilten Skill transformiert.
- **5 mitgelieferte Presets** — `default`, `minimal`, `security-focus`, `architecture-comprehensive`, `api-documentation`
- **Benutzerdefinierte Presets** — Eigene Workflows unter `~/.config/skill-seekers/workflows/` hinzufügen
- **Mehrere Workflows** — Zwei oder mehr Workflows in einem Befehl verketten
- **Vollständige CLI-Verwaltung** — Workflows auflisten, anzeigen, kopieren, hinzufügen, entfernen und validieren
```bash
# Einzelnen Workflow anwenden
skill-seekers create ./my-project --enhance-workflow security-focus
# Mehrere Workflows verketten (werden der Reihe nach angewendet)
skill-seekers create ./my-project \
--enhance-workflow security-focus \
--enhance-workflow minimal
# Presets verwalten
skill-seekers workflows list # Alle auflisten (mitgeliefert + benutzerdefiniert)
skill-seekers workflows show security-focus # YAML-Inhalt anzeigen
skill-seekers workflows copy security-focus # Zum Benutzerverzeichnis kopieren (zum Bearbeiten)
skill-seekers workflows add ./my-workflow.yaml # Benutzerdefiniertes Preset installieren
skill-seekers workflows remove my-workflow # Benutzerdefiniertes Preset entfernen
skill-seekers workflows validate security-focus # Preset-Struktur validieren
# Mehrere gleichzeitig kopieren
skill-seekers workflows copy security-focus minimal api-documentation
# Mehrere Dateien gleichzeitig hinzufügen
skill-seekers workflows add ./wf-a.yaml ./wf-b.yaml
# Mehrere gleichzeitig entfernen
skill-seekers workflows remove my-wf-a my-wf-b
```
**YAML-Preset-Format:**
```yaml
name: security-focus
description: "Security-focused review: vulnerabilities, auth, data handling"
version: "1.0"
stages:
- name: vulnerabilities
type: custom
prompt: "Review for OWASP top 10 and common security vulnerabilities..."
- name: auth-review
type: custom
prompt: "Examine authentication and authorisation patterns..."
uses_history: true
```
### Leistung und Skalierung
- **Async-Modus** - 2–3x schnelleres Scraping mit async/await (Flag `--async` verwenden)
- **Unterstützung großer Dokumentationen** - 10K–40K+ Seiten mit intelligentem Aufteilen verarbeiten
- **Router-/Hub-Skills** - Intelligentes Routing zu spezialisierten Sub-Skills
- **Paralleles Scraping** - Mehrere Skills gleichzeitig verarbeiten
- **Checkpoint/Wiederaufnahme** - Bei langen Scraping-Vorgängen nie den Fortschritt verlieren
- **Caching-System** - Einmal scrapen, sofort neu erstellen
### Agenten-agnostische Skill-Generierung
- **Multi-Agenten-Unterstützung** - Skills für Claude, Kimi, Codex, Copilot, OpenCode oder beliebige eigene Agenten per `--agent`-Flag generieren
- **Eigene Agentenbefehle** - Mit `--agent-cmd` einen benutzerdefinierten Agenten-CLI-Befehl für die Verbesserung angeben
- **Universelle Flags** - `--agent` und `--agent-cmd` sind in allen Befehlen verfügbar (create, scrape, github, pdf usw.)
### Marketplace-Pipeline
- **Auf dem Marketplace veröffentlichen** - Skills in Claude Code Plugin-Marketplace-Repos veröffentlichen
- **End-to-End-Pipeline** - Von der Dokumentationsquelle bis zum veröffentlichten Marketplace-Eintrag
### Qualitätssicherung
- **Vollständig getestet** - Über 3.700 Tests mit umfassender Abdeckung
---
## Installation
```bash
# Basisinstallation (Dokumentations-Scraping, GitHub-Analyse, PDF, Paketierung)
pip install skill-seekers
# Mit Unterstützung aller LLM-Plattformen
pip install skill-seekers[all-llms]
# Mit MCP-Server
pip install skill-seekers[mcp]
# Alles
pip install skill-seekers[all]
```
**Hilfe bei der Auswahl nötig?** Starten Sie den Einrichtungsassistenten:
```bash
skill-seekers-setup
```
### Installationsoptionen
| Installation | Funktionen |
|-------------|-----------|
| `pip install skill-seekers` | Scraping, GitHub-Analyse, PDF, alle Plattformen |
| `pip install skill-seekers[gemini]` | + Google Gemini-Unterstützung |
| `pip install skill-seekers[openai]` | + OpenAI ChatGPT-Unterstützung |
| `pip install skill-seekers[all-llms]` | + Alle LLM-Plattformen |
| `pip install skill-seekers[mcp]` | + MCP-Server |
| `pip install skill-seekers[video]` | + YouTube-/Vimeo-Transkript- und Metadatenextraktion |
| `pip install skill-seekers[video-full]` | + Whisper-Transkription und visuelle Frameextraktion |
| `pip install skill-seekers[jupyter]` | + Jupyter-Notebook-Unterstützung |
| `pip install skill-seekers[pptx]` | + PowerPoint-Unterstützung |
| `pip install skill-seekers[confluence]` | + Confluence-Wiki-Unterstützung |
| `pip install skill-seekers[notion]` | + Notion-Seitenunterstützung |
| `pip install skill-seekers[rss]` | + RSS-/Atom-Feed-Unterstützung |
| `pip install skill-seekers[chat]` | + Slack-/Discord-Chatexport-Unterstützung |
| `pip install skill-seekers[asciidoc]` | + AsciiDoc-Dokumentunterstützung |
| `pip install skill-seekers[all]` | Alles aktiviert |
> **Visuelle Video-Abhängigkeiten (GPU-bewusst):** Nach der Installation von `skill-seekers[video-full]` führen Sie
> `skill-seekers create --setup` aus, um Ihre GPU automatisch zu erkennen und die richtige PyTorch-
> Variante + easyocr zu installieren. Dies ist der empfohlene Weg zur Installation visueller Extraktionsabhängigkeiten.
---
## Ein-Befehl-Installations-Workflow
**Der schnellste Weg von der Konfiguration zum hochgeladenen Skill — vollständig automatisiert:**
```bash
# React-Skill aus offiziellen Konfigurationen installieren (automatischer Upload zu Claude)
skill-seekers install --config react
# Aus lokaler Konfigurationsdatei installieren
skill-seekers install --config configs/custom.json
# Ohne Upload installieren (nur Paketierung)
skill-seekers install --config django --no-upload
# Workflow ohne Ausführung in der Vorschau anzeigen
skill-seekers install --config react --dry-run
```
**Dauer:** 20–45 Minuten insgesamt | **Qualität:** Produktionsreif (9/10) | **Kosten:** Kostenlos
**Ausgeführte Phasen:**
```
Phase 1: Konfiguration abrufen (falls Konfigurationsname angegeben)
Phase 2: Dokumentation scrapen
Phase 3: KI-Verbesserung (OBLIGATORISCH - kein Überspringen möglich)
Phase 4: Skill paketieren
Phase 5: Zu Claude hochladen (optional, erfordert API Key)
```
**Voraussetzungen:**
- Umgebungsvariable ANTHROPIC_API_KEY (für automatischen Upload)
- Claude Code Max Plan (für lokale KI-Verbesserung), oder mit `--agent` einen anderen KI-Agenten auswählen
---
## Funktionsmatrix
Skill Seekers unterstützt **12 LLM-Plattformen**, **8 RAG-/Vektor-Ziele**, **18 Quelltypen** und vollständige Funktionsparität für alle Ziele.
**Plattformen:** Claude AI, Google Gemini, OpenAI ChatGPT, MiniMax AI, Generisches Markdown, OpenCode, Kimi (Moonshot AI), DeepSeek AI, Qwen (Alibaba), OpenRouter, Together AI, Fireworks AI
**Quelltypen:** Dokumentationswebsites, GitHub-Repos, PDFs, Word (.docx), EPUB, Video, lokale Codebasen, Jupyter-Notebooks, lokales HTML, OpenAPI/Swagger, AsciiDoc, PowerPoint (.pptx), RSS-/Atom-Feeds, Man-Pages, Confluence-Wikis, Notion-Seiten, Slack-/Discord-Chatexporte
Vollständige Informationen finden Sie in der [vollständigen Funktionsmatrix](docs/reference/FEATURE_MATRIX.md).
### Schneller Plattformvergleich
| Funktion | Claude | Gemini | OpenAI | MiniMax | Markdown |
|----------|--------|--------|--------|---------|----------|
| Format | ZIP + YAML | tar.gz | ZIP + Vector | ZIP + Knowledge | ZIP |
| Upload | API | API | API | API | Manuell |
| Verbesserung | Sonnet 4 | 2.0 Flash | GPT-4o | M3 | Keine |
| Alle Skill-Modi | Ja | Ja | Ja | Ja | Ja |
---
## Verwendungsbeispiele
### Dokumentations-Scraping
```bash
# Dokumentationswebsite scrapen
skill-seekers create --config configs/react.json
# Schnelles Scraping (ohne Konfiguration)
skill-seekers create https://react.dev --name react
# Mit Async-Modus (3x schneller)
skill-seekers create --config configs/godot.json --async --workers 8
# Einen bestimmten KI-Agenten für die Verbesserung verwenden
skill-seekers create --config configs/react.json --agent kimi
```
### PDF-Extraktion
```bash
# Grundlegende PDF-Extraktion
skill-seekers create --pdf docs/manual.pdf --name myskill
# Erweiterte Funktionen
skill-seekers create --pdf docs/manual.pdf --name myskill \
--extract-tables \ # Tabellen extrahieren
--parallel \ # Schnelle Parallelverarbeitung
--workers 8 # 8 CPU-Kerne verwenden
# Gescannte PDFs (erfordert: pip install pytesseract Pillow)
skill-seekers create --pdf docs/scanned.pdf --name myskill --ocr
```
### Videoextraktion
```bash
# Video-Unterstützung installieren
pip install skill-seekers[video] # Transkripte + Metadaten
pip install skill-seekers[video-full] # + Whisper-Transkription + visuelle Frameextraktion
# GPU automatisch erkennen und visuelle Abhängigkeiten installieren (PyTorch + easyocr)
skill-seekers create --setup
# Aus YouTube-Video extrahieren
skill-seekers create --video-url https://www.youtube.com/watch?v=dQw4w9WgXcQ --name mytutorial
# Aus einer YouTube-Playlist extrahieren
skill-seekers create --video-playlist https://www.youtube.com/playlist?list=... --name myplaylist
# Aus einer lokalen Videodatei extrahieren
skill-seekers create --video-file recording.mp4 --name myrecording
# Mit visueller Frameanalyse extrahieren (erfordert video-full-Abhängigkeiten)
skill-seekers create --video-url https://www.youtube.com/watch?v=... --name mytutorial --visual
# Mit KI-Verbesserung (OCR bereinigen + ausgefeilte SKILL.md generieren)
skill-seekers create --video-url https://www.youtube.com/watch?v=... --visual --enhance-level 2
# Bestimmten Abschnitt eines Videos ausschneiden (unterstützt Sekunden, MM:SS, HH:MM:SS)
skill-seekers create --video-url https://www.youtube.com/watch?v=... --start-time 1:30 --end-time 5:00
# Vision API für OCR-Frames mit niedriger Konfidenz verwenden (erfordert ANTHROPIC_API_KEY)
skill-seekers create --video-url https://www.youtube.com/watch?v=... --visual --vision-ocr
# Skill aus zuvor extrahierten Daten neu erstellen (Download überspringen)
skill-seekers create --from-json output/mytutorial/video_data/extracted_data.json --name mytutorial
```
> **Vollständige Anleitung:** Siehe [docs/VIDEO_GUIDE.md](docs/VIDEO_GUIDE.md) für die vollständige CLI-Referenz,
> Details zur visuellen Pipeline, KI-Verbesserungsoptionen und Fehlerbehebung.
### GitHub-Repository-Analyse
```bash
# Grundlegendes Repository-Scraping
skill-seekers create facebook/react
# Mit Authentifizierung (höhere Rate-Limits)
export GITHUB_TOKEN=ghp_your_token_here
skill-seekers create facebook/react
# Inhalte anpassen
skill-seekers create django/django \
--include-issues \ # GitHub Issues extrahieren
--max-issues 100 \ # Issue-Anzahl begrenzen
--include-changelog # CHANGELOG.md extrahieren
```
### Vereinheitlichtes Multi-Source-Scraping
**Dokumentation + GitHub + PDF zu einem vereinheitlichten Skill mit Konflikterkennung kombinieren:**
```bash
# Vorhandene vereinheitlichte Konfigurationen verwenden
skill-seekers create --config configs/react_unified.json
# Oder vereinheitlichte Konfiguration erstellen
cat > configs/myframework_unified.json << 'EOF'
{
"name": "myframework",
"merge_mode": "rule-based",
"sources": [
{
"type": "documentation",
"base_url": "https://docs.myframework.com/",
"max_pages": 200
},
{
"type": "github",
"repo": "owner/myframework",
"code_analysis_depth": "surface"
}
]
}
EOF
skill-seekers create --config configs/myframework_unified.json
```
**Die Konflikterkennung findet automatisch:**
- **Im Code fehlend** (hoch): Dokumentiert, aber nicht implementiert
- **In der Dokumentation fehlend** (mittel): Implementiert, aber nicht dokumentiert
- **Signatur-Abweichung**: Unterschiedliche Parameter/Typen
- **Beschreibungs-Abweichung**: Unterschiedliche Erklärungen
**Vollständige Anleitung:** Siehe [docs/features/UNIFIED_SCRAPING.md](docs/features/UNIFIED_SCRAPING.md).
### Private Konfigurations-Repositories
**Benutzerdefinierte Konfigurationen über private Git-Repositories im Team teilen:**
```bash
# MCP-Tools verwenden, um das private Team-Repository zu registrieren
add_config_source(
name="team",
git_url="https://github.com/mycompany/skill-configs.git",
token_env="GITHUB_TOKEN"
)
# Konfiguration aus dem Team-Repository abrufen
fetch_config(source="team", config_name="internal-api")
```
**Unterstützte Plattformen:**
- GitHub (`GITHUB_TOKEN`), GitLab (`GITLAB_TOKEN`), Gitea (`GITEA_TOKEN`), Bitbucket (`BITBUCKET_TOKEN`)
**Vollständige Anleitung:** Siehe [docs/reference/GIT_CONFIG_SOURCES.md](docs/reference/GIT_CONFIG_SOURCES.md).
## Funktionsweise
```mermaid
graph LR
A[Dokumentationswebsite] --> B[Skill Seekers]
B --> C[Scraper]
B --> D[KI-Verbesserung]
B --> E[Paketierer]
C --> F[Geordnete Referenzdateien]
D --> F
F --> E
E --> G[KI-Skill .zip]
G --> H[Upload zur KI-Plattform]
```
0. **llms.txt erkennen** - Prüft zuerst auf llms-full.txt, llms.txt, llms-small.txt (Teil der intelligenten SPA-Erkennung)
1. **Scrapen**: Alle Seiten aus der Dokumentation extrahieren
2. **Kategorisieren**: Inhalte nach Themen organisieren (API, Anleitungen, Tutorials usw.)
3. **Verbessern**: KI analysiert Dokumente und erstellt umfassende SKILL.md mit Beispielen (unterstützt mehrere Agenten via `--agent`)
4. **Paketieren**: Alles in eine plattformfertige `.zip`-Datei bündeln
## Architektur
Das System ist in **8 Kernmodule** und **5 Hilfsmodule** organisiert (~200 Klassen insgesamt):
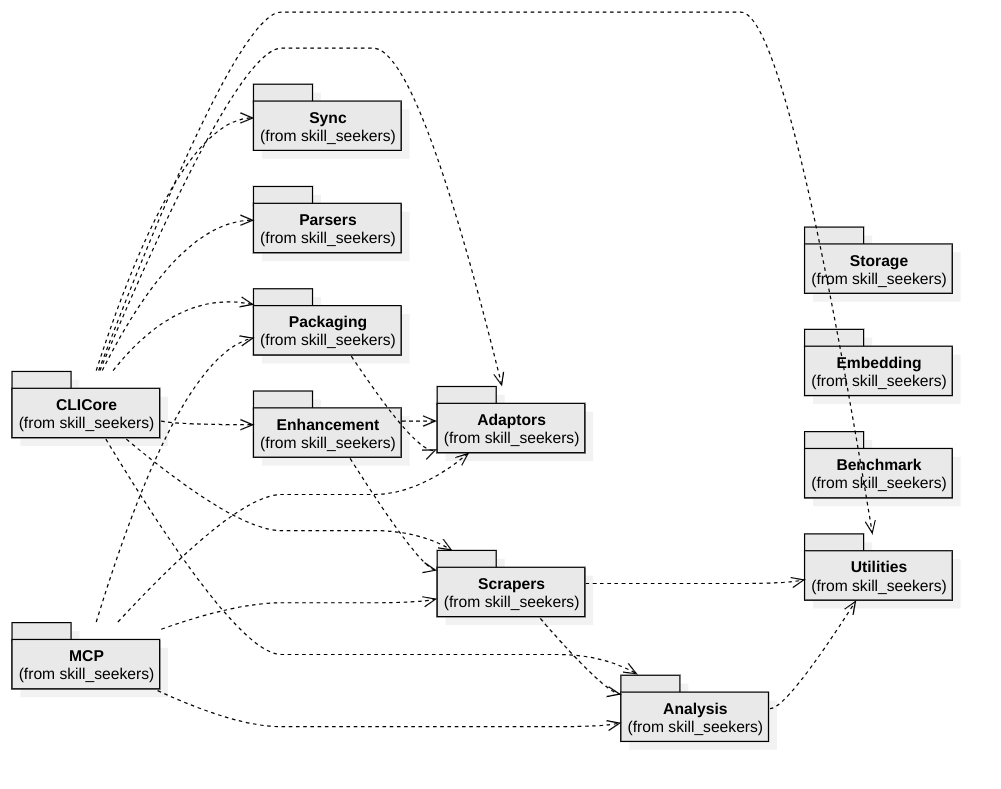
| Modul | Zweck | Wichtige Klassen |
|-------|-------|------------------|
| **CLICore** | Git-artiger Befehls-Dispatcher | `CLIDispatcher`, `SourceDetector`, `CreateCommand` |
| **Scrapers** | 18 Quelltyp-Extraktoren | `DocToSkillConverter`, `DocumentSkillBuilder` (gemeinsame Build-Schicht), `UnifiedScraper` |
| **Adaptors** | 20+ Ausgabeplattform-Formate | `SkillAdaptor` (ABC), `ClaudeAdaptor`, `LangChainAdaptor` |
| **Analysis** | C3.x-Codebase-Analysepipeline | `UnifiedCodebaseAnalyzer`, `PatternRecognizer`, 10 GoF-Detektoren |
| **Enhancement** | KI-gestützte Skill-Verbesserung via `AgentClient` | `AgentClient`, `AIEnhancer`, `UnifiedEnhancer`, `WorkflowEngine` |
| **Packaging** | Skills paketieren, hochladen, installieren | `PackageSkill`, `InstallAgent` |
| **MCP** | FastMCP-Server (40 Tools) | `SkillSeekerMCPServer`, 10 Tool-Module |
| **Sync** | Erkennung von Dokumentationsänderungen | `ChangeDetector`, `SyncMonitor`, `Notifier` |
Hilfsmodule: **Parsers** (28 CLI-Parser), **Storage** (S3/GCS/Azure), **Embedding** (Multi-Provider-Vektoren), **Benchmark** (Performance), **Utilities** (16 gemeinsame Helfer).
Vollständige UML-Diagramme: **[docs/UML_ARCHITECTURE.md](docs/UML_ARCHITECTURE.md)** | StarUML-Projekt: `docs/UML/skill_seekers.mdj` | HTML-API-Referenz: `docs/UML/html/`
## Voraussetzungen
**Bevor Sie beginnen, stellen Sie sicher, dass Sie Folgendes haben:**
1. **Python 3.10 oder höher** - [Herunterladen](https://www.python.org/downloads/) | Prüfen: `python3 --version`
2. **Git** - [Herunterladen](https://git-scm.com/) | Prüfen: `git --version`
3. **15–30 Minuten** für die erstmalige Einrichtung
**Erstmalig hier?** → **[Starten Sie hier: Narrensichere Schnellstartanleitung](BULLETPROOF_QUICKSTART.md)**
---
## Skills zu Claude hochladen
Sobald Ihr Skill paketiert ist, müssen Sie ihn zu Claude hochladen:
### Option 1: Automatischer Upload (API-basiert)
```bash
# API Key setzen (einmalig)
export ANTHROPIC_API_KEY=sk-ant-...
# Paketieren und automatisch hochladen
skill-seekers package output/react/ --upload
# ODER vorhandene .zip hochladen
skill-seekers upload output/react.zip
```
### Option 2: Manueller Upload (ohne API Key)
```bash
# Skill paketieren
skill-seekers package output/react/
# → Erstellt output/react.zip
# Dann manuell hochladen:
# - Gehen Sie zu https://claude.ai/skills
# - Klicken Sie auf „Skill hochladen"
# - Wählen Sie output/react.zip
```
### Option 3: MCP (Claude Code)
```
In Claude Code einfach fragen:
"Paketiere und lade den React-Skill hoch"
```
---
## Installation für KI-Agenten
Skill Seekers kann Skills automatisch für 19 KI-Programmieragenten installieren.
```bash
# Für einen bestimmten Agenten installieren
skill-seekers install-agent output/react/ --agent cursor
# Für IBM Bob installieren (projektlokal: .bob/skills/)
skill-seekers install-agent output/react/ --agent bob
# Für alle Agenten gleichzeitig installieren
skill-seekers install-agent output/react/ --agent all
# Vorschau ohne Installation
skill-seekers install-agent output/react/ --agent cursor --dry-run
```
### Unterstützte Agenten
| Agent | Pfad | Typ |
|-------|------|-----|
| **Claude Code** | `~/.claude/skills/` | Global |
| **Cursor** | `.cursor/skills/` | Projekt |
| **VS Code / Copilot** | `.github/skills/` | Projekt |
| **Amp** | `~/.amp/skills/` | Global |
| **Goose** | `~/.config/goose/skills/` | Global |
| **OpenCode** | `~/.opencode/skills/` | Global |
| **Windsurf** | `~/.windsurf/skills/` | Global |
| **Roo Code** | `.roo/skills/` | Projekt |
| **Cline** | `.cline/skills/` | Projekt |
| **Aider** | `~/.aider/skills/` | Global |
| **Bolt** | `.bolt/skills/` | Projekt |
| **Kilo Code** | `.kilo/skills/` | Projekt |
| **Continue** | `~/.continue/skills/` | Global |
| **Kimi Code** | `~/.kimi/skills/` | Global |
| **IBM Bob** | `.bob/skills/` | Projekt |
---
## MCP-Integration (40 Tools)
Skill Seekers liefert einen MCP-Server für die Verwendung mit Claude Code, Cursor, Windsurf, VS Code + Cline oder IntelliJ IDEA.
```bash
# stdio-Modus (Claude Code, VS Code + Cline)
python -m skill_seekers.mcp.server_fastmcp
# HTTP-Modus (Cursor, Windsurf, IntelliJ)
python -m skill_seekers.mcp.server_fastmcp --transport http --port 8765
# Alle Agenten automatisch konfigurieren
./setup_mcp.sh
```
**Alle 40 verfügbaren Tools:**
- **Kern (9):** `list_configs`, `generate_config`, `validate_config`, `estimate_pages`, `scrape_docs`, `package_skill`, `upload_skill`, `enhance_skill`, `install_skill`
- **Erweitert (10):** `scrape_github`, `scrape_pdf`, `unified_scrape`, `merge_sources`, `detect_conflicts`, `add_config_source`, `fetch_config`, `list_config_sources`, `remove_config_source`, `split_config`
- **Vektordatenbank (4):** `export_to_chroma`, `export_to_weaviate`, `export_to_faiss`, `export_to_qdrant`
- **Cloud (3):** `cloud_upload`, `cloud_download`, `cloud_list`
**Vollständige Anleitung:** [docs/guides/MCP_SETUP.md](docs/guides/MCP_SETUP.md)
---
## Konfiguration
### Verfügbare Presets (24+)
```bash
# Alle Presets auflisten
# skill-seekers list-configs # In v3.7.0 nicht verfügbar
```
| Kategorie | Presets |
|-----------|---------|
| **Web-Frameworks** | `react`, `vue`, `angular`, `svelte`, `nextjs` |
| **Python** | `django`, `flask`, `fastapi`, `sqlalchemy`, `pytest` |
| **Spieleentwicklung** | `godot`, `pygame`, `unity` |
| **Tools und DevOps** | `docker`, `kubernetes`, `terraform`, `ansible` |
| **Vereinheitlicht (Doku + GitHub)** | `react-unified`, `vue-unified`, `nextjs-unified` u. a. |
### Eigene Konfiguration erstellen
```bash
# Option 1: Interaktiv
skill-seekers create --interactive
# Option 2: Preset kopieren und bearbeiten
cp configs/react.json configs/myframework.json
nano configs/myframework.json
skill-seekers create --config configs/myframework.json
```
### Konfigurationsdatei-Struktur
```json
{
"name": "myframework",
"description": "When to use this skill",
"base_url": "https://docs.myframework.com/",
"selectors": {
"main_content": "article",
"title": "h1",
"code_blocks": "pre code"
},
"url_patterns": {
"include": ["/docs", "/guide"],
"exclude": ["/blog", "/about"]
},
"categories": {
"getting_started": ["intro", "quickstart"],
"api": ["api", "reference"]
},
"rate_limit": 0.5,
"max_pages": 500
}
```
### Speicherorte für Konfigurationen
Das Tool sucht in dieser Reihenfolge:
1. Exakter Pfad wie angegeben
2. `./configs/` (aktuelles Verzeichnis)
3. `~/.config/skill-seekers/configs/` (Benutzerkonfigurationsverzeichnis)
4. SkillSeekersWeb.com API (Preset-Konfigurationen)
---
## Was wird erstellt
```
output/
├── godot_data/ # Gescrapte Rohdaten
│ ├── pages/ # JSON-Dateien (eine pro Seite)
│ └── summary.json # Übersicht
│
└── godot/ # Der Skill
├── SKILL.md # Verbessert mit echten Beispielen
├── references/ # Kategorisierte Dokumentation
│ ├── index.md
│ ├── getting_started.md
│ ├── scripting.md
│ └── ...
├── scripts/ # Leer (eigene hinzufügen)
└── assets/ # Leer (eigene hinzufügen)
```
---
## Fehlerbehebung
### Kein Inhalt extrahiert?
- Überprüfen Sie Ihren `main_content`-Selektor
- Versuchen Sie: `article`, `main`, `div[role="main"]`
### Daten vorhanden, aber werden nicht verwendet?
```bash
# Erneutes Scraping erzwingen
rm -rf output/myframework_data/
skill-seekers create --config configs/myframework.json
```
### Kategorien nicht gut?
Bearbeiten Sie den `categories`-Abschnitt in der Konfiguration mit besseren Schlüsselwörtern.
### Dokumentation aktualisieren?
```bash
# Alte Daten löschen und erneut scrapen
rm -rf output/godot_data/
skill-seekers create --config configs/godot.json
```
### Verbesserung funktioniert nicht?
```bash
# Prüfen, ob API Key gesetzt ist
echo $ANTHROPIC_API_KEY
# LOCAL-Modus versuchen (nutzt Claude Code Max, kein API Key nötig)
skill-seekers enhance output/react/ --mode LOCAL
# Hintergrund-Verbesserungsstatus überwachen
skill-seekers enhance-status output/react/ --watch
```
### GitHub-Rate-Limit-Probleme?
```bash
# GitHub Token setzen (5000 Anfragen/Stunde vs. 60/Stunde anonym)
export GITHUB_TOKEN=ghp_your_token_here
# Oder mehrere Profile konfigurieren
skill-seekers config --github
```
---
## Leistung
| Aufgabe | Dauer | Hinweise |
|---------|-------|----------|
| Scraping (synchron) | 15–45 Min. | Nur beim ersten Mal, thread-basiert |
| Scraping (asynchron) | 5–15 Min. | 2–3x schneller mit `--async`-Flag |
| Erstellen | 1–3 Min. | Schneller Neuaufbau aus Cache |
| Neuerstellen | <1 Min. | Mit `--skip-scrape` |
| Verbesserung (LOCAL) | 30–60 Sek. | Nutzt Claude Code Max |
| Verbesserung (API) | 20–40 Sek. | Erfordert API Key |
| Video (Transkript) | 1–3 Min. | YouTube/lokal, nur Transkript |
| Video (visuell) | 5–15 Min. | + OCR-Frameextraktion |
| Paketierung | 5–10 Sek. | Finale .zip-Erstellung |
---
## Neu in v3.6.0
### Workflow-Presets
Analysetiefe mit `--preset` steuern:
```bash
skill-seekers create https://docs.react.dev/ --preset quick # Schnell, oberflächlich
skill-seekers create https://docs.react.dev/ --preset standard # Ausgewogen (Standard)
skill-seekers create https://docs.react.dev/ --preset comprehensive # Tiefgehend, erschöpfend
```
### Lifecycle-Flags
```bash
skill-seekers create https://docs.react.dev/ --dry-run # Vorschau ohne Scraping
skill-seekers create https://docs.react.dev/ --fresh # Cache ignorieren, vollständiges Re-Scraping
skill-seekers create https://docs.react.dev/ --resume # Unterbrochenen Job fortsetzen
skill-seekers create https://docs.react.dev/ --skip-scrape # Bestehende Ausgabe neu paketieren
```
### Health Check & Utilities
```bash
skill-seekers doctor # Installation & Umgebung diagnostizieren
skill-seekers sync-config # Konfigurationsabweichung erkennen
skill-seekers stream # Streaming-Ingestion für große Dokumentationen
skill-seekers update output/react/ # Inkrementelles Update
skill-seekers multilang # Mehrsprachige Skill-Generierung
skill-seekers quality output/react/ # Qualitätsbericht (mit --threshold 7 als Gate: Exit-Code ungleich null unter 7/10)
```
### RAG-Chunking-Optionen (package)
```bash
skill-seekers package output/react/ --chunk-for-rag --chunk-tokens 512 --chunk-overlap-tokens 50
```
### Marketplace-Veröffentlichung
```bash
skill-seekers package output/react/ --marketplace --marketplace-category frontend
```
### Weitere optionale Abhängigkeiten
| Extra | Installation | Zweck |
|-------|--------------|-------|
| `browser` | `pip install "skill-seekers[browser]"` | Headless Playwright für SPA-Websites |
| `embedding` | `pip install "skill-seekers[embedding]"` | Embedding-Server-Unterstützung |
| `s3` / `gcs` / `azure` | `pip install "skill-seekers[s3]"` usw. | Cloud-Storage-Upload |
| `rag-upload` | `pip install "skill-seekers[rag-upload]"` | Kombinierte Vektordatenbank-Upload-Abhängigkeiten |
---
## Dokumentation
### Erste Schritte
- **[BULLETPROOF_QUICKSTART.md](BULLETPROOF_QUICKSTART.md)** - **Neue Nutzer starten hier!**
- **[QUICKSTART.md](docs/archive/legacy/QUICKSTART.md)** - Schnellstart für erfahrene Nutzer
- **[TROUBLESHOOTING.md](TROUBLESHOOTING.md)** - Häufige Probleme und Lösungen
- **[docs/archive/legacy/QUICK_REFERENCE.md](docs/archive/legacy/QUICK_REFERENCE.md)** - Einseiter-Kurzreferenz
### Architektur
- **[docs/UML_ARCHITECTURE.md](docs/UML_ARCHITECTURE.md)** - UML-Architekturübersicht mit 14 Diagrammen
- **[docs/UML/exports/](docs/UML/exports/)** - PNG-Diagramm-Exporte (Paketübersicht + 13 Klassendiagramme)
- **[docs/UML/html/](docs/UML/html/index.html/index.html)** - Vollständige HTML-API-Referenz (alle Klassen, Operationen, Attribute)
- **[docs/UML/skill_seekers.mdj](docs/UML/skill_seekers.mdj)** - StarUML-Projektdatei (mit [StarUML](https://staruml.io/) öffnen)
### Anleitungen
- **[docs/reference/LARGE_DOCUMENTATION.md](docs/reference/LARGE_DOCUMENTATION.md)** - 10K–40K+ Seiten verarbeiten
- **[docs/features/ENHANCEMENT_MODES.md](docs/features/ENHANCEMENT_MODES.md)** - KI-Verbesserungsmodi-Anleitung
- **[docs/guides/MCP_SETUP.md](docs/guides/MCP_SETUP.md)** - MCP-Integrations-Einrichtung
- **[docs/features/UNIFIED_SCRAPING.md](docs/features/UNIFIED_SCRAPING.md)** - Multi-Source-Scraping
- **[docs/VIDEO_GUIDE.md](docs/VIDEO_GUIDE.md)** - Vollständige Videoextraktions-Anleitung
### Integrationsanleitungen
- **[docs/integrations/LANGCHAIN.md](docs/integrations/LANGCHAIN.md)** - LangChain RAG
- **[docs/integrations/CURSOR.md](docs/integrations/CURSOR.md)** - Cursor IDE
- **[docs/integrations/WINDSURF.md](docs/integrations/WINDSURF.md)** - Windsurf IDE
- **[docs/integrations/CLINE.md](docs/integrations/CLINE.md)** - Cline (VS Code)
- **[docs/integrations/RAG_PIPELINES.md](docs/integrations/RAG_PIPELINES.md)** - Alle RAG-Pipelines
---
## Lizenz
MIT-Lizenz - siehe [LICENSE](LICENSE)-Datei für Details
---
Viel Erfolg beim Erstellen von Skills!
---
## Sicherheit
[](https://mseep.ai/app/yusufkaraaslan-skill-seekers)
---
## Sponsoren
[Atlas Cloud](https://www.atlascloud.ai/?utm_source=github&utm_medium=link&utm_campaign=skill_seekers) — eine vollmodale, OpenAI-kompatible KI-Inferenzplattform. Skill Seekers unterstützt sie als Paketierungs-/Verbesserungsziel via `--target atlas` mit `ATLAS_API_KEY`.