# AI Research `Skills` Library
> **The most comprehensive open-source skills library enabling AI agents to autonomously conduct AI research — from idea to paper**
---
## Table of Contents
- [Our Mission](#our-mission)
- [Path Towards AI Research Agent](#path-towards-ai-research-agent)
- [Available AI Research Engineering Skills](#available-ai-research-engineering-skills)
- [Demos](#demos)
- [Skill Structure](#skill-structure)
- [Roadmap](#roadmap)
- [Repository Structure](#repository-structure)
- [Use Cases](#use-cases)
- [Contributors](#contributors)
- [Citation](#citation)
- [Community](#community)
## Our Mission
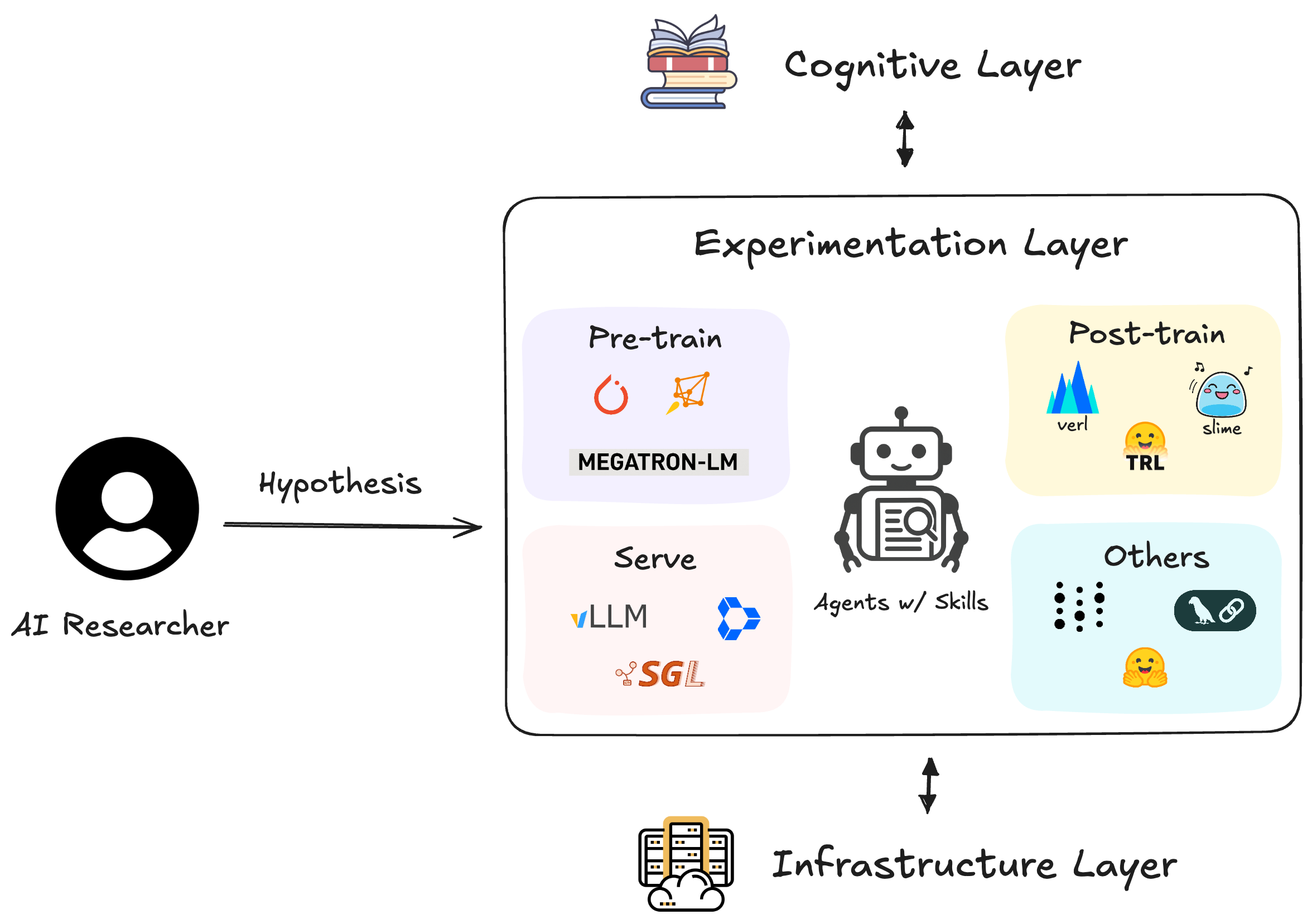
We enable AI agents to **autonomously conduct AI research** — from literature survey and idea generation through experiment execution to paper writing. The library provides both the **research orchestration layer** (autoresearch, ideation, paper writing) and the **engineering skills** (training, evaluation, deployment) needed at each stage.
System diagram of an AI research agent
## Path Towards AI Research Agent
Modern AI research requires mastering dozens of specialized tools and frameworks.
AI Researchers spend more time debugging infrastructure than testing hypotheses — slowing the pace of scientific discovery.
We provide a comprehensive skills library that enables AI agents to autonomously conduct the full research lifecycle — from brainstorming ideas to writing the paper.
- Autonomous Research - The **autoresearch** skill orchestrates the entire research workflow using a two-loop architecture, routing to domain skills as needed
- Specialized Expertise - Each domain skill provides deep, production-ready knowledge of a specific framework (Megatron-LM, vLLM, TRL, etc.)
- End-to-End Coverage - 87 skills spanning the full AI research lifecycle, from ideation and literature survey to experiments and paper writing
- Research-Grade Quality - Documentation sourced from official repos, real GitHub issues, and battle-tested production workflows
## Available AI Research Engineering Skills
**Quality over quantity**: Each skill provides comprehensive, expert-level guidance with real code examples, troubleshooting guides, and production-ready workflows.
### 📦 Quick Install (Recommended)
**For humans** — interactive installer with one command:
```bash
npx @orchestra-research/ai-research-skills
```
**For AI agents** — point your agent to the welcome doc and it handles the rest:
```
Read https://www.orchestra-research.com/ai-research-skills/welcome.md and follow the instructions to install and use AI Research Skills.
```
This installs all 87 skills, loads the **autoresearch** orchestration layer, and starts autonomous research.
What the installer does
- **Auto-detects** your installed coding agents
- **Installs** skills to `~/.orchestra/skills/` with symlinks to each agent (falls back to copy on Windows)
- **Offers** everything, quickstart bundle, by category, or individual skills
- **Updates** installed skills with latest versions
- **Uninstalls** all or selected skills
CLI Commands
```bash
# Interactive installer (recommended)
npx @orchestra-research/ai-research-skills
# Direct commands
npx @orchestra-research/ai-research-skills list # View installed skills
npx @orchestra-research/ai-research-skills update # Update installed skills
```
Claude Code Marketplace (Alternative)
Install skill categories directly using the **Claude Code CLI**:
```bash
# Add the marketplace
/plugin marketplace add orchestra-research/AI-research-SKILLs
# Install by category (22 categories available)
/plugin install fine-tuning@ai-research-skills # Axolotl, LLaMA-Factory, PEFT, Unsloth
/plugin install post-training@ai-research-skills # TRL, GRPO, OpenRLHF, SimPO, verl, slime, miles, torchforge
/plugin install inference-serving@ai-research-skills # vLLM, TensorRT-LLM, llama.cpp, SGLang
/plugin install distributed-training@ai-research-skills
/plugin install optimization@ai-research-skills
```
### All 22 Categories (87 Skills)
| Category | Skills | Included |
|----------|--------|----------|
| **Autoresearch** | **1** | **Autonomous research orchestration — central layer that manages the full lifecycle and routes to all other skills** |
| Ideation | 2 | Research Brainstorming, Creative Thinking |
| ML Paper Writing | 2 | ML Paper Writing (LaTeX templates, citation verification), Academic Plotting |
| Model Architecture | 5 | LitGPT, Mamba, NanoGPT, RWKV, TorchTitan |
| Tokenization | 2 | HuggingFace Tokenizers, SentencePiece |
| Fine-Tuning | 4 | Axolotl, LLaMA-Factory, PEFT, Unsloth |
| Mech Interp | 4 | TransformerLens, SAELens, pyvene, nnsight |
| Data Processing | 2 | NeMo Curator, Ray Data |
| Post-Training | 8 | TRL, GRPO, OpenRLHF, SimPO, verl, slime, miles, torchforge |
| Safety | 4 | Constitutional AI, LlamaGuard, NeMo Guardrails, Prompt Guard |
| Distributed | 6 | DeepSpeed, FSDP, Accelerate, Megatron-Core, Lightning, Ray Train |
| Infrastructure | 3 | Modal, Lambda Labs, SkyPilot |
| Optimization | 6 | Flash Attention, bitsandbytes, GPTQ, AWQ, HQQ, GGUF |
| Evaluation | 3 | lm-eval-harness, BigCode, NeMo Evaluator |
| Inference | 4 | vLLM, TensorRT-LLM, llama.cpp, SGLang |
| MLOps | 3 | W&B, MLflow, TensorBoard |
| Agents | 4 | LangChain, LlamaIndex, CrewAI, AutoGPT |
| RAG | 5 | Chroma, FAISS, Pinecone, Qdrant, Sentence Transformers |
| Prompt Eng | 4 | DSPy, Instructor, Guidance, Outlines |
| Observability | 2 | LangSmith, Phoenix |
| Multimodal | 7 | CLIP, Whisper, LLaVA, BLIP-2, SAM, Stable Diffusion, AudioCraft |
| Emerging | 6 | MoE, Model Merging, Long Context, Speculative Decoding, Distillation, Pruning |
View All 87 Skills in Details
### 🔬 Autoresearch (1 skill) — Central Orchestration Layer
- **[Autoresearch](0-autoresearch-skill/)** - Autonomous research orchestration using a two-loop architecture (inner optimization + outer synthesis). Manages the full lifecycle from literature survey to paper writing, routing to all domain-specific skills. Supports Claude Code /loop and OpenClaw heartbeat for continuous operation (390 lines + 3 refs)
### 🏗️ Model Architecture (5 skills)
- **[LitGPT](01-model-architecture/litgpt/)** - Lightning AI's 20+ clean LLM implementations with production training recipes (462 lines + 4 refs)
- **[Mamba](01-model-architecture/mamba/)** - State-space models with O(n) complexity, 5× faster than Transformers (253 lines + 3 refs)
- **[RWKV](01-model-architecture/rwkv/)** - RNN+Transformer hybrid, infinite context, Linux Foundation project (253 lines + 3 refs)
- **[NanoGPT](01-model-architecture/nanogpt/)** - Educational GPT in ~300 lines by Karpathy (283 lines + 3 refs)
- **[TorchTitan](01-model-architecture/torchtitan/)** - PyTorch-native distributed training for Llama 3.1 with 4D parallelism
### 🔤 Tokenization (2 skills)
- **[HuggingFace Tokenizers](02-tokenization/huggingface-tokenizers/)** - Rust-based, <20s/GB, BPE/WordPiece/Unigram algorithms (486 lines + 4 refs)
- **[SentencePiece](02-tokenization/sentencepiece/)** - Language-independent, 50k sentences/sec, used by T5/ALBERT (228 lines + 2 refs)
### 🎯 Fine-Tuning (4 skills)
- **[Axolotl](03-fine-tuning/axolotl/)** - YAML-based fine-tuning with 100+ models (156 lines + 4 refs)
- **[LLaMA-Factory](03-fine-tuning/llama-factory/)** - WebUI no-code fine-tuning (78 lines + 5 refs)
- **[Unsloth](03-fine-tuning/unsloth/)** - 2x faster QLoRA fine-tuning (75 lines + 4 refs)
- **[PEFT](03-fine-tuning/peft/)** - Parameter-efficient fine-tuning with LoRA, QLoRA, DoRA, 25+ methods (431 lines + 2 refs)
### 🔬 Mechanistic Interpretability (4 skills)
- **[TransformerLens](04-mechanistic-interpretability/transformer-lens/)** - Neel Nanda's library for mech interp with HookPoints, activation caching (346 lines + 3 refs)
- **[SAELens](04-mechanistic-interpretability/saelens/)** - Sparse Autoencoder training and analysis for feature discovery (386 lines + 3 refs)
- **[pyvene](04-mechanistic-interpretability/pyvene/)** - Stanford's causal intervention library with declarative configs (473 lines + 3 refs)
- **[nnsight](04-mechanistic-interpretability/nnsight/)** - Remote interpretability via NDIF, run experiments on 70B+ models (436 lines + 3 refs)
### 📊 Data Processing (2 skills)
- **[Ray Data](05-data-processing/ray-data/)** - Distributed ML data processing, streaming execution, GPU support (318 lines + 2 refs)
- **[NeMo Curator](05-data-processing/nemo-curator/)** - GPU-accelerated data curation, 16× faster deduplication (375 lines + 2 refs)
### 🎓 Post-Training (8 skills)
- **[TRL Fine-Tuning](06-post-training/trl-fine-tuning/)** - Transformer Reinforcement Learning (447 lines + 4 refs)
- **[GRPO-RL-Training](06-post-training/grpo-rl-training/)** (TRL) - Group Relative Policy Optimization with TRL (569 lines, **gold standard**)
- **[OpenRLHF](06-post-training/openrlhf/)** - Full RLHF pipeline with Ray + vLLM (241 lines + 4 refs)
- **[SimPO](06-post-training/simpo/)** - Simple Preference Optimization, no reference model needed (211 lines + 3 refs)
- **[verl](06-post-training/verl/)** - ByteDance's HybridFlow RL framework, FSDP/Megatron + vLLM/SGLang backends (389 lines + 2 refs)
- **[slime](06-post-training/slime/)** - THUDM's Megatron+SGLang framework powering GLM-4.x models (464 lines + 2 refs)
- **[miles](06-post-training/miles/)** - Enterprise fork of slime with FP8, INT4, speculative RL for MoE training (315 lines + 2 refs)
- **[torchforge](06-post-training/torchforge/)** - Meta's PyTorch-native RL with Monarch+TorchTitan+vLLM (380 lines + 2 refs)
### 🛡️ Safety & Alignment (4 skills)
- **[Constitutional AI](07-safety-alignment/constitutional-ai/)** - AI-driven self-improvement via principles (282 lines)
- **[LlamaGuard](07-safety-alignment/llamaguard/)** - Safety classifier for LLM inputs/outputs (329 lines)
- **[NeMo Guardrails](07-safety-alignment/nemo-guardrails/)** - Programmable guardrails with Colang (289 lines)
- **[Prompt Guard](07-safety-alignment/prompt-guard/)** - Meta's 86M prompt injection & jailbreak detector, 99%+ TPR, <2ms GPU (313 lines)
### ⚡ Distributed Training (6 skills)
- **[Megatron-Core](08-distributed-training/megatron-core/)** - NVIDIA's framework for training 2B-462B param models with 47% MFU on H100 (359 lines + 4 refs)
- **[DeepSpeed](08-distributed-training/deepspeed/)** - Microsoft's ZeRO optimization (137 lines + 9 refs)
- **[PyTorch FSDP2](08-distributed-training/pytorch-fsdp2/)** - Fully Sharded Data Parallel v2 with `fully_shard` and DTensor (231 lines + 12 refs)
- **[Accelerate](08-distributed-training/accelerate/)** - HuggingFace's 4-line distributed training API (324 lines + 3 refs)
- **[PyTorch Lightning](08-distributed-training/pytorch-lightning/)** - High-level training framework with Trainer class (339 lines + 3 refs)
- **[Ray Train](08-distributed-training/ray-train/)** - Multi-node orchestration and hyperparameter tuning (399 lines + 1 ref)
### 🚀 Optimization (6 skills)
- **[Flash Attention](10-optimization/flash-attention/)** - 2-4x faster attention with memory efficiency (359 lines + 2 refs)
- **[bitsandbytes](10-optimization/bitsandbytes/)** - 8-bit/4-bit quantization for 50-75% memory reduction (403 lines + 3 refs)
- **[GPTQ](10-optimization/gptq/)** - 4-bit post-training quantization, 4× memory reduction, <2% accuracy loss (443 lines + 3 refs)
- **[AWQ](10-optimization/awq/)** - Activation-aware weight quantization, 4-bit with minimal accuracy loss (310 lines + 2 refs)
- **[HQQ](10-optimization/hqq/)** - Half-Quadratic Quantization, no calibration data needed, multi-backend (370 lines + 2 refs)
- **[GGUF](10-optimization/gguf/)** - llama.cpp quantization format, K-quant methods, CPU/Metal inference (380 lines + 2 refs)
### 📊 Evaluation (3 skills)
- **[lm-evaluation-harness](11-evaluation/lm-evaluation-harness/)** - EleutherAI's standard for benchmarking LLMs across 60+ tasks (482 lines + 4 refs)
- **[BigCode Evaluation Harness](11-evaluation/bigcode-evaluation-harness/)** - Code model benchmarking with HumanEval, MBPP, MultiPL-E, pass@k metrics (406 lines + 3 refs)
- **[NeMo Evaluator](11-evaluation/nemo-evaluator/)** - NVIDIA's enterprise platform for 100+ benchmarks across 18+ harnesses with multi-backend execution (454 lines + 4 refs)
### ☁️ Infrastructure (3 skills)
- **[Modal](09-infrastructure/modal/)** - Serverless GPU cloud with Python-native API, T4-H200 on-demand (342 lines + 2 refs)
- **[SkyPilot](09-infrastructure/skypilot/)** - Multi-cloud orchestration across 20+ providers with spot recovery (390 lines + 2 refs)
- **[Lambda Labs](09-infrastructure/lambda-labs/)** - Reserved/on-demand GPU cloud with H100/A100, persistent filesystems (390 lines + 2 refs)
### 🔥 Inference & Serving (4 skills)
- **[vLLM](12-inference-serving/vllm/)** - High-throughput LLM serving with PagedAttention (356 lines + 4 refs, **production-ready**)
- **[TensorRT-LLM](12-inference-serving/tensorrt-llm/)** - NVIDIA's fastest inference, 24k tok/s, FP8/INT4 quantization (180 lines + 3 refs)
- **[llama.cpp](12-inference-serving/llama-cpp/)** - CPU/Apple Silicon inference, GGUF quantization (251 lines + 3 refs)
- **[SGLang](12-inference-serving/sglang/)** - Structured generation with RadixAttention, 5-10× faster for agents (435 lines + 3 refs)
### 🤖 Agents (4 skills)
- **[LangChain](14-agents/langchain/)** - Most popular agent framework, 500+ integrations, ReAct pattern (658 lines + 3 refs, **production-ready**)
- **[LlamaIndex](14-agents/llamaindex/)** - Data framework for LLM apps, 300+ connectors, RAG-focused (535 lines + 3 refs)
- **[CrewAI](14-agents/crewai/)** - Multi-agent orchestration, role-based collaboration, autonomous workflows (498 lines + 3 refs)
- **[AutoGPT](14-agents/autogpt/)** - Autonomous AI agent platform, visual workflow builder, continuous execution (400 lines + 2 refs)
### 🔍 RAG (5 skills)
- **[Chroma](15-rag/chroma/)** - Open-source embedding database, local/cloud, 24k stars (385 lines + 1 ref)
- **[FAISS](15-rag/faiss/)** - Facebook's similarity search, billion-scale, GPU acceleration (295 lines)
- **[Sentence Transformers](15-rag/sentence-transformers/)** - 5000+ embedding models, multilingual, 15k stars (370 lines)
- **[Pinecone](15-rag/pinecone/)** - Managed vector database, auto-scaling, <100ms latency (410 lines)
- **[Qdrant](15-rag/qdrant/)** - High-performance vector search, Rust-powered, hybrid search with filtering (493 lines + 2 refs)
### 🎨 Multimodal (7 skills)
- **[CLIP](18-multimodal/clip/)** - OpenAI's vision-language model, zero-shot classification, 25k stars (320 lines)
- **[Whisper](18-multimodal/whisper/)** - Robust speech recognition, 99 languages, 73k stars (395 lines)
- **[LLaVA](18-multimodal/llava/)** - Vision-language assistant, image chat, GPT-4V level (360 lines)
- **[Stable Diffusion](18-multimodal/stable-diffusion/)** - Text-to-image generation via HuggingFace Diffusers, SDXL, ControlNet (380 lines + 2 refs)
- **[Segment Anything](18-multimodal/segment-anything/)** - Meta's SAM for zero-shot image segmentation with points/boxes (500 lines + 2 refs)
- **[BLIP-2](18-multimodal/blip-2/)** - Vision-language pretraining with Q-Former, image captioning, VQA (500 lines + 2 refs)
- **[AudioCraft](18-multimodal/audiocraft/)** - Meta's MusicGen/AudioGen for text-to-music and text-to-sound (470 lines + 2 refs)
### 🎯 Prompt Engineering (4 skills)
- **[DSPy](16-prompt-engineering/dspy/)** - Declarative prompt programming with optimizers, Stanford NLP, 22k stars (438 lines + 3 refs)
- **[Instructor](16-prompt-engineering/instructor/)** - Structured LLM outputs with Pydantic validation, 15k stars (726 lines + 3 refs)
- **[Guidance](16-prompt-engineering/guidance/)** - Constrained generation with regex/grammars, Microsoft Research, 18k stars (485 lines + 3 refs)
- **[Outlines](16-prompt-engineering/outlines/)** - Structured text with FSM, zero-overhead, 8k stars (601 lines + 3 refs)
### 📊 MLOps (3 skills)
- **[Weights & Biases](13-mlops/weights-and-biases/)** - Experiment tracking, sweeps, artifacts, model registry (427 lines + 3 refs)
- **[MLflow](13-mlops/mlflow/)** - Model registry, tracking, deployment, autologging (514 lines + 3 refs)
- **[TensorBoard](13-mlops/tensorboard/)** - Visualization, profiling, embeddings, scalars/images (538 lines + 3 refs)
### 👁️ Observability (2 skills)
- **[LangSmith](17-observability/langsmith/)** - LLM observability, tracing, evaluation, monitoring for AI apps (422 lines + 2 refs)
- **[Phoenix](17-observability/phoenix/)** - Open-source AI observability with OpenTelemetry tracing and LLM evaluation (380 lines + 2 refs)
### 🔬 Emerging Techniques (6 skills)
- **[MoE Training](19-emerging-techniques/moe-training/)** - Mixture of Experts training with DeepSpeed, Mixtral 8x7B, 5× cost reduction (515 lines + 3 refs)
- **[Model Merging](19-emerging-techniques/model-merging/)** - Combine models with TIES, DARE, SLERP using mergekit (528 lines + 3 refs)
- **[Long Context](19-emerging-techniques/long-context/)** - Extend context windows with RoPE, YaRN, ALiBi, 32k-128k tokens (624 lines + 3 refs)
- **[Speculative Decoding](19-emerging-techniques/speculative-decoding/)** - 1.5-3.6× faster inference with Medusa, Lookahead (379 lines)
- **[Knowledge Distillation](19-emerging-techniques/knowledge-distillation/)** - Compress models 70B→7B with MiniLLM, temperature scaling (424 lines)
- **[Model Pruning](19-emerging-techniques/model-pruning/)** - 50% sparsity with Wanda, SparseGPT, <1% accuracy loss (417 lines)
### 📝 ML Paper Writing (2 skills)
- **[ML Paper Writing](20-ml-paper-writing/)** - Write publication-ready papers for NeurIPS, ICML, ICLR, ACL, AAAI, COLM with LaTeX templates, citation verification, and writing best practices (532 lines + 5 refs)
- **[Academic Plotting](20-ml-paper-writing/academic-plotting/)** - Generate publication-quality figures for ML papers: architecture diagrams via Gemini AI and data-driven charts via matplotlib/seaborn with venue-specific styling (479 lines + 3 refs)
### 💡 Ideation (2 skills)
- **[Research Brainstorming](21-research-ideation/brainstorming-research-ideas/)** - Structured ideation frameworks for discovering high-impact research directions with 10 complementary lenses (384 lines)
- **[Creative Thinking](21-research-ideation/creative-thinking-for-research/)** - Cognitive science frameworks (bisociation, structure-mapping, constraint manipulation) for genuinely novel research ideas (366 lines)
## Demos
All 87 skills in this repo are automatically synced to [Orchestra Research](https://www.orchestra-research.com/research-skills), where you can add them to your projects with one click and use them with AI research agents.
**See skills in action → [demos/](demos/README.md)**
We maintain a curated collection of demo repositories showing how to use skills for real AI research tasks:
| Demo | Skills Used | What It Does |
|------|-------------|--------------|
| **[Norm Heterogeneity → LoRA Brittleness](demos/autoresearch-norm-heterogeneity/)** | Autoresearch, ML Paper Writing, Ideation | Agent autonomously discovered norm heterogeneity predicts fine-tuning difficulty (r=-0.99), pivoting from a null result on ETF overlaps |
| **[RL Algorithm Brain Scan](demos/autoresearch-rl-brain-scan/)** | Autoresearch, GRPO, TRL, SAELens, TransformerLens, ML Paper Writing | Agent found DPO is a rank-1 perturbation (95.6% recovery from one SVD direction) while online RL is distributed and structure-preserving |
| **[NeMo Eval: GPQA Benchmark](https://github.com/zechenzhangAGI/Nemo-Eval-Skill-Demo)** | NeMo Evaluator | Compare Llama 8B/70B/405B on graduate-level science questions |
| **[LoRA Without Regret Reproduction](https://www.orchestra-research.com/perspectives/LLM-with-Orchestra)** | GRPO, TRL | Reproduce SFT + GRPO RL experiments via prompting |
| **[Layer-Wise Quantization Experiment](https://github.com/AmberLJC/llama-quantization-experiment)** | llama.cpp, GGUF | Investigate optimal layer precision allocation—early layers at Q8 achieve 1.9× compression with 1.3% perplexity loss |
| **[Cross-Lingual Alignment Analysis](https://github.com/AmberLJC/faiss-demo)** | FAISS | Quantify how well multilingual embeddings align semantic concepts across 8 languages using FAISS similarity search |
| **[Scientific Plotting Demo](demos/scientific-plotting-demo/)** | Academic Plotting | Generate publication-quality figures for the Andes QoE-aware LLM serving paper — Gemini AI architecture diagrams + matplotlib data charts (CDF, multi-panel grids, bar charts) |
**Featured Demos**: Two papers produced entirely by AI agents using the **autoresearch** skill. The [Norm Heterogeneity paper](demos/autoresearch-norm-heterogeneity/) demonstrates autonomous research pivoting — the agent refuted its own hypothesis and discovered a stronger finding. The [RL Brain Scan paper](demos/autoresearch-rl-brain-scan/) demonstrates multi-skill orchestration — the agent trained RL models, analyzed internals with interpretability tools, and synthesized the insight that "DPO is rank-1 alignment." Both papers written end-to-end by the agent.
## Skill Structure
Each skill follows a battle-tested format for maximum usefulness:
```
skill-name/
├── SKILL.md # Quick reference (50-150 lines)
│ ├── Metadata (name, description, version)
│ ├── When to use this skill
│ ├── Quick patterns & examples
│ └── Links to references
│
├── references/ # Deep documentation (300KB+)
│ ├── README.md # From GitHub/official docs
│ ├── api.md # API reference
│ ├── tutorials.md # Step-by-step guides
│ ├── issues.md # Real GitHub issues & solutions
│ ├── releases.md # Version history & breaking changes
│ └── file_structure.md # Codebase navigation
│
├── scripts/ # Helper scripts (optional)
└── assets/ # Templates & examples (optional)
```
Quality Standards
- 300KB+ documentation from official sources
- Real GitHub issues & solutions (when available)
- Code examples with language detection
- Version history & breaking changes
- Links to official docs
## Roadmap
We're building towards 80 comprehensive skills across the full AI research lifecycle. See our [detailed roadmap](docs/ROADMAP.md) for the complete development plan.
[View Full Roadmap →](docs/ROADMAP.md)
View Detailed Statistics
| Metric | Current | Target |
|--------|---------|--------|
| **Skills** | **87** (high-quality, standardized YAML) | 80 ✅ |
| **Avg Lines/Skill** | **420 lines** (focused + progressive disclosure) | 200-600 lines |
| **Documentation** | **~130,000 lines** total (SKILL.md + references) | 100,000+ lines |
| **Gold Standard Skills** | **65** with comprehensive references | 50+ |
| **Contributors** | 1 | 100+ |
| **Coverage** | Architecture, Tokenization, Fine-Tuning, Mechanistic Interpretability, Data Processing, Post-Training, Safety, Distributed, Optimization, Evaluation, Infrastructure, Inference, Agents, RAG, Multimodal, Prompt Engineering, MLOps, Observability, ML Paper Writing, Ideation, Autoresearch | Full Lifecycle ✅ |
**Recent Progress**: npm package `@orchestra-research/ai-research-skills` for one-command installation across all coding agents
**Philosophy**: Quality > Quantity. Following [Anthropic official best practices](anthropic_official_docs/best_practices.md) - each skill provides 200-500 lines of focused, actionable guidance with progressive disclosure.
## Repository Structure
```
claude-ai-research-skills/
├── README.md ← You are here
├── CONTRIBUTING.md ← Contribution guide
├── demos/ ← Curated demo gallery (links to demo repos)
├── docs/
├── 0-autoresearch-skill/ (1 skill ✓ - Autonomous research orchestration)
├── 01-model-architecture/ (5 skills ✓ - LitGPT, Mamba, RWKV, NanoGPT, TorchTitan)
├── 02-tokenization/ (2 skills ✓ - HuggingFace Tokenizers, SentencePiece)
├── 03-fine-tuning/ (4 skills ✓ - Axolotl, LLaMA-Factory, Unsloth, PEFT)
├── 04-mechanistic-interpretability/ (4 skills ✓ - TransformerLens, SAELens, pyvene, nnsight)
├── 05-data-processing/ (2 skills ✓ - Ray Data, NeMo Curator)
├── 06-post-training/ (8 skills ✓ - TRL, GRPO, OpenRLHF, SimPO, verl, slime, miles, torchforge)
├── 07-safety-alignment/ (4 skills ✓ - Constitutional AI, LlamaGuard, NeMo Guardrails, Prompt Guard)
├── 08-distributed-training/ (6 skills ✓ - Megatron-Core, DeepSpeed, FSDP, Accelerate, Lightning, Ray Train)
├── 09-infrastructure/ (3 skills ✓ - Modal, SkyPilot, Lambda Labs)
├── 10-optimization/ (6 skills ✓ - Flash Attention, bitsandbytes, GPTQ, AWQ, HQQ, GGUF)
├── 11-evaluation/ (3 skills ✓ - lm-evaluation-harness, BigCode, NeMo Evaluator)
├── 12-inference-serving/ (4 skills ✓ - vLLM, TensorRT-LLM, llama.cpp, SGLang)
├── 13-mlops/ (3 skills ✓ - Weights & Biases, MLflow, TensorBoard)
├── 14-agents/ (4 skills ✓ - LangChain, LlamaIndex, CrewAI, AutoGPT)
├── 15-rag/ (5 skills ✓ - Chroma, FAISS, Sentence Transformers, Pinecone, Qdrant)
├── 16-prompt-engineering/ (4 skills ✓ - DSPy, Instructor, Guidance, Outlines)
├── 17-observability/ (2 skills ✓ - LangSmith, Phoenix)
├── 18-multimodal/ (7 skills ✓ - CLIP, Whisper, LLaVA, Stable Diffusion, SAM, BLIP-2, AudioCraft)
├── 19-emerging-techniques/ (6 skills ✓ - MoE, Model Merging, Long Context, Speculative Decoding, Distillation, Pruning)
├── 20-ml-paper-writing/ (2 skills ✓ - ML Paper Writing with LaTeX templates, Academic Plotting)
├── 21-research-ideation/ (2 skills ✓ - Research Brainstorming, Creative Thinking)
└── packages/ai-research-skills/ (npm package for one-command installation)
```
## Use Cases
### For Researchers
"I need to fine-tune Llama 3 with custom data"
→ **03-fine-tuning/axolotl/** - YAML configs, 100+ model support
### For ML Engineers
"How do I optimize inference latency?"
→ **12-inference-serving/vllm/** - PagedAttention, batching
### For Students
"I want to learn how transformers work"
→ **01-model-architecture/litgpt/** - Clean implementations
### For Teams
"We need to scale training to 100 GPUs"
→ **08-distributed-training/deepspeed/** - ZeRO stages, 3D parallelism
## License
MIT License - See [LICENSE](LICENSE) for details.
**Note**: Individual skills may reference libraries with different licenses. Please check each project's license before use.
## Citation
If you use AI Research Skills in your work or find it helpful for a publication, we'd appreciate a citation:
**BibTeX**
```bibtex
@software{ai_research_skills,
title = {AI Research Skills Library},
author = {{Orchestra Research}},
year = {2025},
url = {https://github.com/orchestra-research/AI-research-SKILLs},
note = {Open-source skills library enabling AI agents to autonomously conduct AI research}
}
```
**APA**
> Orchestra Research. (2025). *AI Research Skills Library* [Computer software]. https://github.com/orchestra-research/AI-research-SKILLs
**Chicago**
> Orchestra Research. "AI Research Skills Library." GitHub, 2025. https://github.com/orchestra-research/AI-research-SKILLs.
**IEEE**
> Orchestra Research, "AI Research Skills Library," 2025. [Online]. Available: https://github.com/orchestra-research/AI-research-SKILLs
> **Tip**: You can also click **"Cite this repository"** in the GitHub sidebar for auto-formatted citations.
## Acknowledgments
Built with:
- **[Claude Code](https://www.claude.com/product/claude-code)** - AI pair programming
- **[Skill Seeker](https://github.com/yusufkaraaslan/Skill_Seekers)** - Automated doc scraping
- **Open Source AI Community** - For amazing tools and docs
Special thanks to:
- EleutherAI, HuggingFace, NVIDIA, Lightning AI, Meta AI, Anthropic
- All researchers who maintain excellent documentation
## Contributors
Thanks to all the people who have contributed to the AI Research Skills Library:
We welcome contributions from the AI research community! See [CONTRIBUTING.md](CONTRIBUTING.md) for detailed guidelines on:
- Adding new skills
- Improving existing skills
- Quality standards and best practices
- Submission process
## Recent Updates
March 2026 - v1.4.0 🔬 Autoresearch & 86 Skills — Full Research Lifecycle
- 🔬 **NEW SKILL**: **Autoresearch** — autonomous research orchestration using a two-loop architecture (inner optimization loop + outer synthesis loop)
- 🧠 Manages the full research lifecycle: literature survey → ideation → experiments → synthesis → paper writing
- 🔄 Routes to all 86 domain skills automatically — agents don't need to know which skill to use
- ⏰ Mandatory `/loop` (Claude Code) and cron job (OpenClaw) for continuous autonomous operation
- 📊 Generates research presentations (HTML/PDF) with optimization trajectory plots for human review
- 📝 Findings.md as persistent project memory across sessions with "Lessons and Constraints" tracking
- 🗂️ Structured workspace: research-state.yaml, findings.md, research-log.md, literature/, experiments/, src/, data/, to_human/
- 📄 **Two demo papers produced by autoresearch**: [Norm Heterogeneity → LoRA Brittleness](demos/autoresearch-norm-heterogeneity/) and [RL Algorithm Brain Scan](demos/autoresearch-rl-brain-scan/)
- 🚀 WELCOME.md for cold-start agent bootstrap — one URL to go from zero to autonomous research
- 📦 npm v1.4.x with Windows symlink fallback, all 22 categories installable
- 📊 **87 total skills** across **22 categories** — complete research lifecycle coverage
February 2026 - v0.15.0 🛡️ Prompt Guard & 83 Skills
- 🛡️ **NEW SKILL**: Prompt Guard - Meta's 86M prompt injection & jailbreak detector
- ⚡ 99%+ TPR, <1% FPR, <2ms GPU latency, multilingual (8 languages)
- 🔒 3 workflows: user input filtering, third-party data filtering, batch RAG processing
- 📊 **83 total skills** across 20 categories
January 2026 - v0.14.0 📦 npm Package & 82 Skills
- 📦 **NEW**: `npx @orchestra-research/ai-research-skills` - One-command installation for all coding agents
- 🤖 **Supported agents**: Claude Code, OpenCode, Cursor, Codex, Gemini CLI, Qwen Code
- ✨ Interactive installer with category/individual skill selection
- 🔄 Update installed skills, selective uninstall
- 📊 **82 total skills** (5 new post-training skills: verl, slime, miles, torchforge + TorchTitan)
- 🏗️ Megatron-Core moved to Distributed Training category
January 2026 - v0.13.0 📝 ML Paper Writing & Demos Gallery
- 📝 **NEW CATEGORY**: ML Paper Writing (20th category, 77th skill)
- 🎯 Write publication-ready papers for NeurIPS, ICML, ICLR, ACL, AAAI, COLM
- 📚 Writing philosophy from top researchers (Neel Nanda, Farquhar, Gopen & Swan, Lipton, Perez)
- 🔬 Citation verification workflow - never hallucinate references
- 📄 LaTeX templates for 6 major conferences
- 🎪 **NEW**: Curated demos gallery (`demos/`) showcasing skills in action
- 🔗 Demo repos: NeMo Evaluator benchmark, LoRA Without Regret reproduction
- 📖 936-line comprehensive SKILL.md with 4 workflows
January 2026 - v0.12.0 📊 NeMo Evaluator SDK
- 📊 **NEW SKILL**: NeMo Evaluator SDK for enterprise LLM benchmarking
- 🔧 NVIDIA's evaluation platform with 100+ benchmarks from 18+ harnesses (MMLU, HumanEval, GSM8K, safety, VLM)
- ⚡ Multi-backend execution: local Docker, Slurm HPC, Lepton cloud
- 📦 Container-first architecture for reproducible evaluation
- 📝 454 lines SKILL.md + 4 comprehensive reference files (~48KB documentation)
December 2025 - v0.11.0 🔬 Mechanistic Interpretability
- 🔬 **NEW CATEGORY**: Mechanistic Interpretability (4 skills)
- 🔍 TransformerLens skill: Neel Nanda's library for mech interp with HookPoints, activation caching, circuit analysis
- 🧠 SAELens skill: Sparse Autoencoder training and analysis for feature discovery, monosemanticity research
- ⚡ pyvene skill: Stanford's causal intervention library with declarative configs, DAS, activation patching
- 🌐 nnsight skill: Remote interpretability via NDIF, run experiments on 70B+ models without local GPUs
- 📝 ~6,500 new lines of documentation across 16 files
- **76 total skills** (filling the missing 04 category slot)
November 25, 2025 - v0.10.0 🎉 70 Skills Complete!
- 🎉 **ROADMAP COMPLETE**: Reached 70-skill milestone!
- 🚀 Added 4 skills: Lambda Labs, Segment Anything (SAM), BLIP-2, AudioCraft
- ☁️ Lambda Labs skill: Reserved/on-demand GPU cloud with H100/A100, persistent filesystems, 1-Click Clusters
- 🖼️ SAM skill: Meta's Segment Anything for zero-shot image segmentation with points/boxes/masks
- 👁️ BLIP-2 skill: Vision-language pretraining with Q-Former, image captioning, VQA
- 🎵 AudioCraft skill: Meta's MusicGen/AudioGen for text-to-music and text-to-sound generation
- 📝 ~10,000 new lines of documentation across 12 files
- **70 total skills** (100% roadmap complete!)
November 25, 2025 - v0.9.0
- 🚀 Added 2 infrastructure skills: Modal, SkyPilot
- ☁️ Modal skill: Serverless GPU cloud with Python-native API, T4-H200 on-demand, auto-scaling
- 🌐 SkyPilot skill: Multi-cloud orchestration across 20+ providers with spot recovery
- ✨ New Infrastructure category (2 skills - serverless GPU and multi-cloud orchestration)
- 📝 ~2,500 new lines of documentation across 6 files
- **66 total skills** (94% towards 70-skill target)
November 25, 2025 - v0.8.0
- 🚀 Added 5 high-priority skills: HQQ, GGUF, Phoenix, AutoGPT, Stable Diffusion
- ⚡ HQQ skill: Half-Quadratic Quantization without calibration data, multi-backend support
- 📦 GGUF skill: llama.cpp quantization format, K-quant methods, CPU/Metal inference
- 👁️ Phoenix skill: Open-source AI observability with OpenTelemetry tracing and LLM evaluation
- 🤖 AutoGPT skill: Autonomous AI agent platform with visual workflow builder
- 🎨 Stable Diffusion skill: Text-to-image generation via Diffusers, SDXL, ControlNet, LoRA
- 📝 ~9,000 new lines of documentation across 15 files
- **64 total skills** (91% towards 70-skill target)
November 25, 2025 - v0.7.0
- 🚀 Added 5 high-priority skills: PEFT, CrewAI, Qdrant, AWQ, LangSmith
- ✨ New Observability category with LangSmith for LLM tracing and evaluation
- 🎯 PEFT skill: Parameter-efficient fine-tuning with LoRA, QLoRA, DoRA, 25+ methods
- 🤖 CrewAI skill: Multi-agent orchestration with role-based collaboration
- 🔍 Qdrant skill: High-performance Rust vector search with hybrid filtering
- ⚡ AWQ skill: Activation-aware 4-bit quantization with minimal accuracy loss
- 📝 ~8,000 new lines of documentation across 15 files
- **59 total skills** (84% towards 70-skill target)
November 15, 2025 - v0.6.0
- 📊 Added 3 comprehensive MLOps skills: Weights & Biases, MLflow, TensorBoard
- ✨ New MLOps category (3 skills - experiment tracking, model registry, visualization)
- 📝 ~10,000 new lines of documentation across 13 files
- 🔧 Comprehensive coverage: experiment tracking, hyperparameter sweeps, model registry, profiling, embeddings visualization
- **54 total skills** (77% towards 70-skill target)
November 12, 2025 - v0.5.0
- 🎯 Added 4 comprehensive prompt engineering skills: DSPy, Instructor, Guidance, Outlines
- ✨ New Prompt Engineering category (4 skills - DSPy, Instructor, Guidance, Outlines)
- 📝 ~10,000 new lines of documentation across 16 files
- 🔧 Comprehensive coverage: declarative programming, structured outputs, constrained generation, FSM-based generation
- **47 total skills** (67% towards 70-skill target)
November 9, 2025 - v0.4.0
- 🤖 Added 11 comprehensive skills: LangChain, LlamaIndex, Chroma, FAISS, Sentence Transformers, Pinecone, CLIP, Whisper, LLaVA
- ✨ New Agents category (2 skills - LangChain, LlamaIndex)
- 🔍 New RAG category (4 skills - Chroma, FAISS, Sentence Transformers, Pinecone)
- 🎨 New Multimodal category (3 skills - CLIP, Whisper, LLaVA)
- 📝 ~15,000 new lines of documentation
- **43 total skills** (61% towards 70-skill target)
November 8, 2025 - v0.3.0
- 🚀 Added 8 comprehensive skills: TensorRT-LLM, llama.cpp, SGLang, GPTQ, HuggingFace Tokenizers, SentencePiece, Ray Data, NeMo Curator
- ⚡ Completed Inference & Serving category (4/4 skills)
- 🔤 New Tokenization category (2 skills)
- 📊 New Data Processing category (2 skills)
- 📝 9,617 new lines of documentation across 30 files
- **32 total skills** (45% towards 70-skill target)
November 6, 2025 - v0.2.0
- Added 10 skills from GitHub (Megatron-Core, Lightning, Ray Train, etc.)
- Improved skill structure with comprehensive references
- Created strategic roadmap to 70 skills
- Added contribution guidelines
November 3, 2025 - v0.1.0
- 🎉 Initial release with 5 fine-tuning skills
## Community
Join our community to stay updated, ask questions, and connect with other AI researchers:
- **[SkillEvolve Meta-Skill](https://github.com/Skill-Evolve/meta-skill)** - Connect your agent to the collective intelligence of the community. Captures techniques discovered during sessions and shares them back as curated skills.
- **[Slack Community](https://join.slack.com/t/orchestrarese-efu1990/shared_invite/zt-3iu6gr8io-zJvpkZTPToEviQ9KFZvNSg)** - Chat with the team and other users
- **[Twitter/X](https://x.com/orch_research)** - Follow for updates and announcements
- **[LinkedIn](https://www.linkedin.com/company/orchestra-research/)** - Connect professionally
## Star History