---
title: (翻译)Go 高性能研讨讲座 - High Performance Go Workshop
date: 2019-12-06T15:58:20.000Z
tags:
- go
- performance
- pprof
- translate
lastmod: 2019-12-07T07:21:07.000Z
categories:
- performance
- go
- translate
slug: high-performance-go-workshop
draft: false
---
> [原文地址](https://dave.cheney.net/high-performance-go-workshop/gopherchina-2019.html)
## Overview
本次研讨讲座的目标是让您能够诊断 `Go` 应用程序中的性能问题,并且修复这些问题。
这一天,我们将从小做起 - 学习如何编写基准测试,然后分析一小段代码。然后讨论代码执行跟踪器,垃圾收集器和跟踪运行的应用程序。最后会有剩下的时间,您可以提出问题,并尝试编写您自己的代码。
### Schedule
这里是这一天的时间安排表(大概)。
| 开始时间 | 描述 |
| -------- | ------------------------------------------ |
| 09:00 | [欢迎](#welcome) and [介绍](#introduction) |
| 09:30 | [Benchmarking](#benchmarking) |
| 10:45 | 休息 (15 分钟) |
| 11:00 | [性能评估和分析](#profiling) |
| 12:00 | 午餐 (90 分钟) |
| 13:30 | [编译优化](#compiler-optimisation) |
| 14:30 | [执行追踪器](#execution-tracer) |
| 15:30 | 休息 (15 分钟) |
| 15:45 | [内存和垃圾回收器](#memory-and-gc) |
| 16:15 | [提示和旅行](#tips-and-tricks) |
| 16:30 | 练习 |
| 16:45 | [最后的问题和结论](#conclusion) |
| 17:00 | 结束 |
## 欢迎 {#welcome}
你好,欢迎! 🎉
该研讨的目的是为您提供诊断和修复 `Go` 应用程序中的性能问题所需的工具。
在这一天里,我们将从一小部分开始 - **学习如何编写基准测试**,然后分析一小段代码。然后扩展到,讨论 `执行跟踪器`,`垃圾收集器` 和跟踪正在运行的应用程序。剩下的将是提问的时间,尝试自己使用代码来实践。
### 讲师
- Dave Cheney [dave@cheney.net](mailto:dave@cheney.net)
### 开源许可和材料
该研讨会是 [David Cheney](https://twitter.com/davecheney) 和 [Francesc Campoy](https://twitter.com/francesc)。
此文章以 [Creative Commons Attribution-ShareAlike 4.0 International](https://creativecommons.org/licenses/by-sa/4.0/) 作为开源协议。
### 预先工作
下面是您今天需要下载的几个软件
#### 讲习代码库
将源代码下载到本文档,并在以下位置获取代码示例 [high-performance-go-workshop](https://github.com/davecheney/high-performance-go-workshop)
#### 电脑执行环境
该项目工作环境目标为 `Go` 1.12。
[Download Go 1.12](https://golang.org/dl/)
> 如果您已经升级到 Go 1.13,也可以了。在次要的 Go 版本之间,优化选择总是会有一些小的变化,我会在继续进行时指出。
#### Graphviz
在 `pprof` 的部分需要 `dot` 程序,它附带的工具 `graphviz` 套件。
- Linux: `[sudo] apt-get install graphviz`
- OSX:
- MacPorts: `sudo port install graphviz`
- Homebrew: `brew install graphviz`
- [Windows](https://graphviz.gitlab.io/download/#Windows) (untested)
#### Google Chrome
执行跟踪器上的这一部分需要使用 Google Chrome。它不适用于 Safari,Edge,Firefox 或 IE 4.01。
[Download Google Chrome](https://www.google.com/chrome/)
#### 您的代码以进行分析和优化
当天的最后部分将是公开讲座,您可以在其中试验所学的工具。
### 还有一些事 …
这不是演讲,而是对话。我们将有很多时间来提问。
如果您听不懂某些内容,或认为听不正确,请提出询问。
## 1. 微处理器性能的过去,现在和未来 {#introduction}
这是一个有关编写高性能代码的研讨会。在其他研讨会上,我谈到了分离的设计和可维护性,但是今天我们在这里谈论性能。
今天,我想做一个简短的演讲,内容是关于我如何思考计算机发展历史以及为什么我认为编写高性能软件很重要。
现实是软件在硬件上运行,因此要谈论编写高性能代码,首先我们需要谈论运行代码的硬件。
### 1.1. Mechanical Sympathy

目前有一个常用术语,您会听到像马丁·汤普森(Martin Thompson)或比尔·肯尼迪(Bill Kennedy)这样的人谈论 `Mechanical Sympathy`。
`Mechanical Sympathy` 这个名字来自伟大的赛车 手杰基·斯图尔特(Jackie Stewart),他曾三度获得世界一级方程式赛车冠军。他认为,最好的驾驶员对机器的工作原理有足够的了解,以便他们可以与机器和谐地工作。
要成为一名出色的赛车手,您不需要成为一名出色的机械师,但您需要对汽车的工作原理有一个粗略的了解。
我相信我们作为软件工程师也是如此。我认为会议室中的任何人都不会是专业的 `CPU` 设计人员,但这并不意味着我们可以忽略 `CPU` 设计人员面临的问题。
### 1.2. 六个数量级
有一个常见的网络模型是这样的;

当然这是荒谬的,但是它强调了计算机行业发生了多少变化。
作为软件作者,我们这个会议室的所有人都受益于摩尔定律,即 40 年来,每 18 个月将芯片上可用晶体管的数量增加一倍。没有其他行业经历过 _六个数量级 _ 在一生的时间内改进其工具。
但这一切都在改变。
### 1.3. 计算机还在变快吗?{#are_computers_still_getting_faster}
因此,最基本的问题是,面对上图所示的统计数据,我们应该问这个问题吗 _计算机还在变快吗_ ?
如果计算机的速度仍在提高,那么也许我们不需要关心代码的性能,只需稍等一下,硬件制造商将为我们解决性能问题。
#### 1.3.1. 让我们看一下数据 {#lets_look_at_the_data}
这是经典的数据,您可以在 `John L. Hennessy` 和 `David A. Patterson` 的 _Computer Architecture, A Quantitative Approach_ 等教科书中找到。该图摘自第 5 版
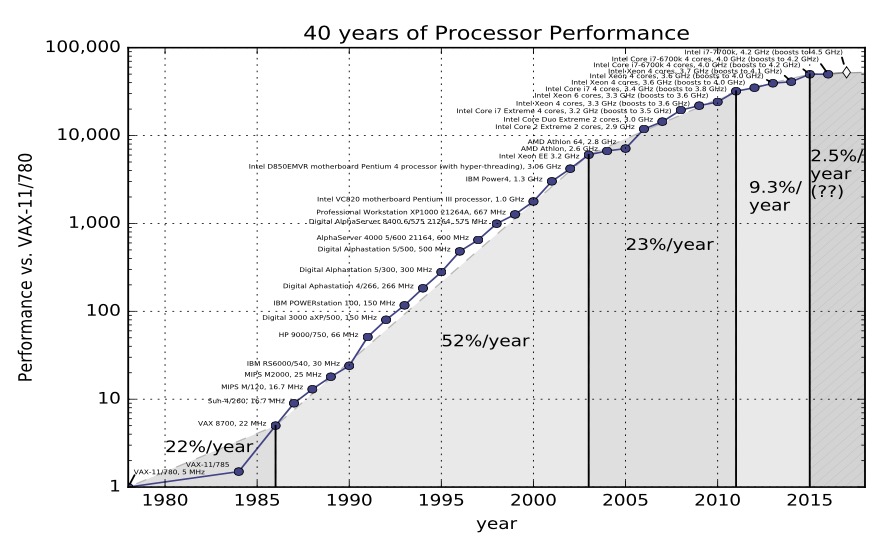
在第 5 版中,轩尼诗(Hennessy)和帕特森(Patterson)提出了计算性能的三个时代
1. 首先是 1970 年代和 80 年代初期,这是形成性的年代。我们今天所知道的微处理器实际上并不存在,计算机是由分立晶体管或小规模集成电路制造的。成本,尺寸以及对材料科学理解的限制是限制因素。
2. 从 80 年代中期到 2004 年,趋势线很明显。 计算机整数性能每年平均提高 52%。 计算机能力每两年翻一番,因此人们将摩尔定律(芯片上的晶体管数量增加一倍)与计算机性能混为一谈。
3. 然后我们进入计算机性能的第三个时代。 事情变慢了。 总变化率为每年 22%。
之前的图表仅持续到 2012 年,但幸运的是在 2012 年 [Jeff Preshing](https://preshing.com/20120208/a-look-back-at-single-threaded-cpu-performance/) 写了 [tool to scrape the Spec website and build your own graph](https://github.com/preshing/analyze-spec-benchmarks).
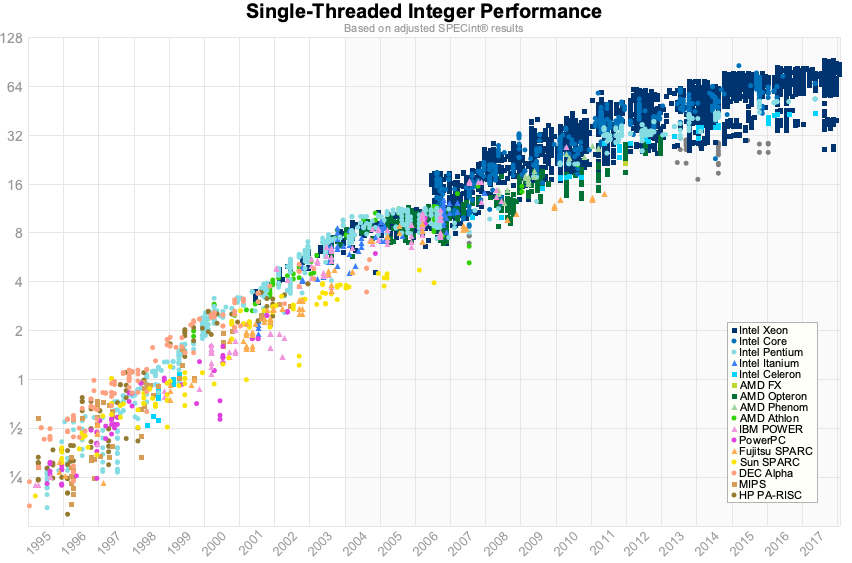
因此,这是使用 1995 年 到 2017 年 的 Spec 数据的同一图。
对我而言,与其说我们在 2012 年 的数据中看到的步伐变化,不如说是 _单核_ 性能已接近极限。 这些数字对于浮点数来说稍好一些,但是对于我们在做业务应用程序的房间中来说,这可能并不重要。
#### 1.3.2. 是的,计算机仍在变得越来越慢 {#yes_computer_are_still_getting_faster_slowly}
> 关于摩尔定律终结的第一件事要记住,就是戈登·摩尔告诉我的事情。他说:"所有指数都结束了"。 — [John Hennessy](https://www.youtube.com/watch?v=Azt8Nc-mtKM)
这是轩尼诗在 Google Next 18 及其图灵奖演讲中的引文。 他的观点是肯定的,CPU 性能仍在提高。 但是,单线程整数性能仍在每年提高 2-3% 左右。 以这种速度,它将需要 20 年的复合增长才能使整数性能翻倍。 相比之下,90 年代的表现每天每两年翻一番。
为什么会这样呢?
### 1.4. 时针速度
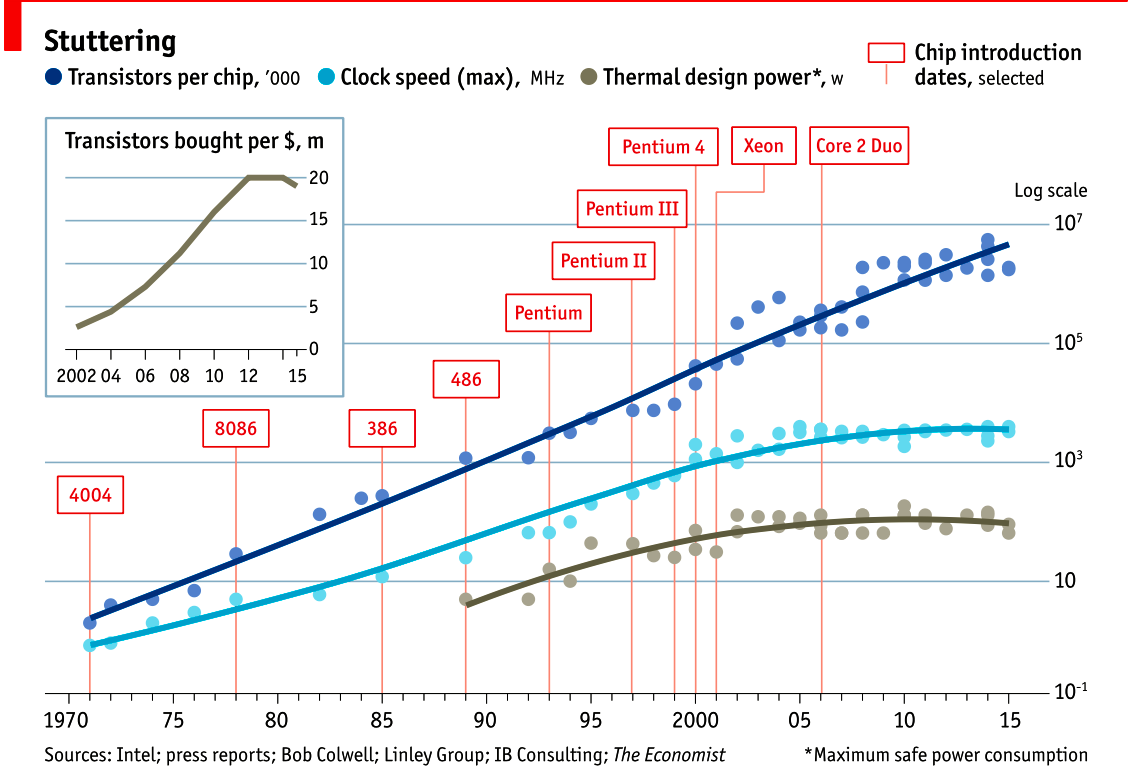
2015 年的这张图很好地说明了这一点。 第一行显示了芯片上的晶体管数量。 自 1970 年代以来,这种趋势一直以大致线性的趋势线持续。 由于这是对数/林线图,因此该线性序列表示指数增长。
但是,如果我们看中线,我们看到时钟速度十年来没有增加,我们看到 CPU 速度在 2004 年左右停滞了。
下图显示了散热功率; 即变成电能的电能遵循相同的模式-时钟速度和 cpu 散热是相关的。
### 1.5. 发热
为什么 CPU 会发热? 这是一台固态设备,没有移动组件,因此此处的摩擦等效果并不(直接)相关。
该图摘自 [data sheet produced by TI](https://www.ti.com/lit/an/scaa035b/scaa035b.pdf)。 在此模型中,N 型设备中的开关被吸引到正电压,P 型设备被正电压击退。
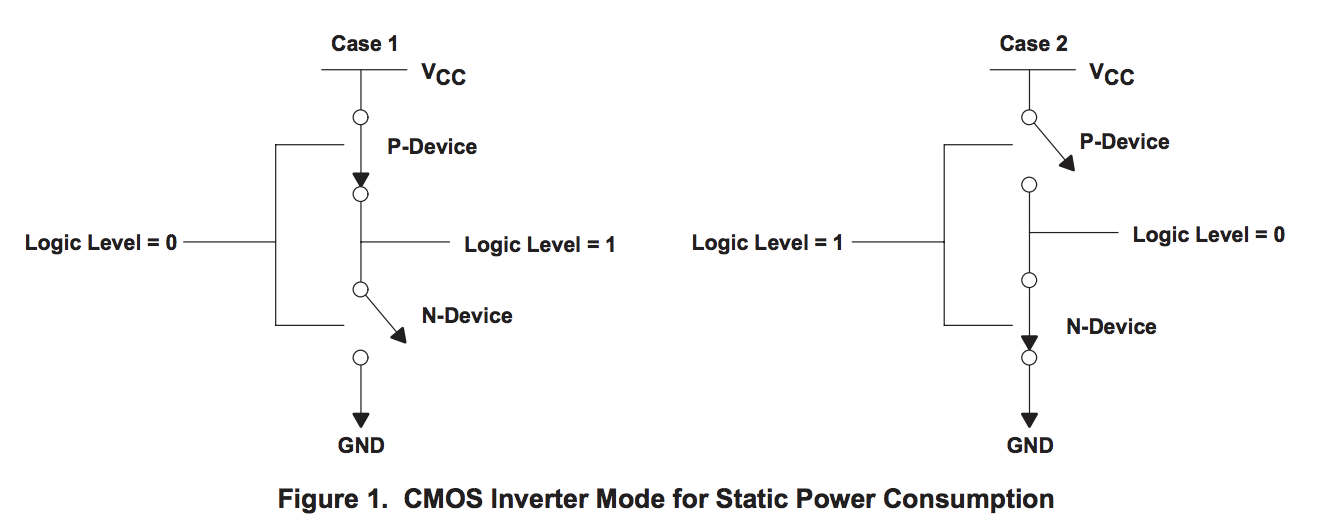
CMOS 设备的功耗是三个因素的总和,CMOS 功耗是房间,办公桌上和口袋中每个晶体管的功率。
1. 静态功率。当晶体管是静态的,即不改变其状态时,会有少量电流通过晶体管泄漏到地。 晶体管越小,泄漏越多。 泄漏量随温度而增加。当您拥有数十亿个晶体管时,即使是很小的泄漏也会加起来!
2. 动态功率。当晶体管从一种状态转换到另一种状态时,它必须对连接到栅极的各种电容进行充电或放电。 每个晶体管的动态功率是电压乘以电容和变化频率的平方。 降低电压可以减少晶体管消耗的功率,但是较低的电压会使晶体管的开关速度变慢。
3. 撬棍或短路电流。我们喜欢将晶体管视为数字设备,无论其处于开启状态还是处于原子状态,都占据一种状态或另一种状态。 实际上,晶体管是模拟设备。 当开关时,晶体管开始几乎全部截止,并转变或切换到几乎全部导通的状态。 这种转换或切换时间非常快,在现代处理器中约为皮秒,但是当从 Vcc 到地的电阻路径很低时,这仍然代表了一段时间。 晶体管切换的速度越快,其频率就会耗散更多的热量。
### 1.6. Dennard 扩展的终结
要了解接下来发生的事情,我们需要查看 [Robert H. Dennard](https://en.wikipedia.org/wiki/Robert_H._Dennard) 于 1974 年共同撰写的论文。 丹纳德的缩放定律大致上指出,随着晶体管的变小,它们的 [power density](https://en.wikipedia.org/wiki/Power_density) 保持恒定。 较小的晶体管可以在较低的电压下运行,具有较低的栅极电容,并且开关速度更快,这有助于减少动态功率。
那么,结果如何呢?
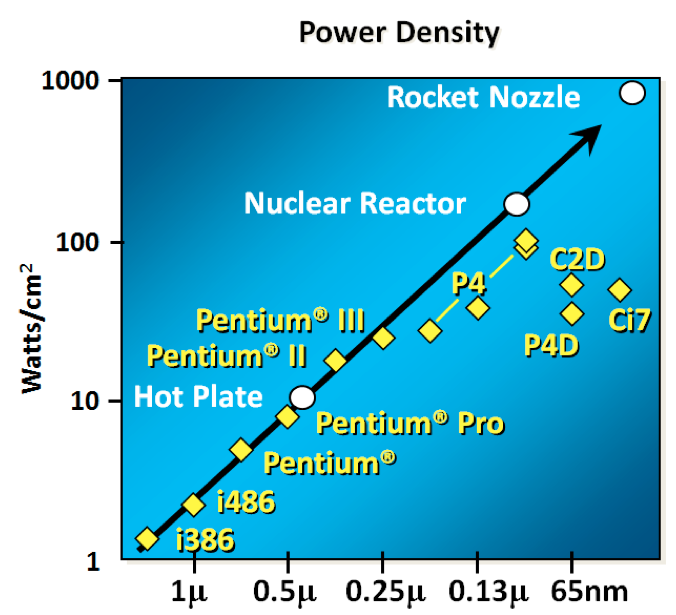
事实并非如此。 当晶体管的栅极长度接近几个硅原子的宽度时,晶体管尺寸,电压与重要的泄漏之间的关系就破裂了。
它是在 [Micro-32 conference in 1999](https://pdfs.semanticscholar.org/6a82/1a3329a60def23235c75b152055c36d40437.pdf) 假定的,如果我们遵循了提高时钟速度和缩小晶体管尺寸的趋势线,那么在处理器一代之内晶体管结将接近核反应堆堆芯的温度。显然,这是荒谬的。奔腾 4 [marked the end of the line](https://arstechnica.com/uncategorized/2004/10/4311-2/) 适用于单核高频消费类 CPU。
返回此图,我们看到时钟速度停止的原因是 `CPU` 超出了我们冷却时钟的能力。 到 2006 年,减小晶体管的尺寸不再提高其功率效率。
现在我们知道,减小 CPU 功能的大小主要是为了降低功耗。 降低功耗不仅意味着“绿色”,例如回收利用,还可以拯救地球。 主要目标是保持功耗,从而保持散热,[below levels that will damage the CPU](https://en.wikipedia.org/wiki/Electromigration#Practical_implications_of_electromigration).

但是,图中的一部分在不断增加,即管芯上的晶体管数量。cpu 的行进具有尺寸特征,在相同的给定面积内有更多的晶体管,既有正面影响,也有负面影响。
同样,如您在插入物中所看到的,直到大约 5 年前,每个晶体管的成本一直在下降,然后每个晶体管的成本又开始回升。

制造较小的晶体管不仅变得越来越昂贵,而且变得越来越困难。 2016 年 的这份报告显示了芯片制造商认为在 2013 年 会发生什么的预测。两年后,他们错过了所有预测,尽管我没有此报告的更新版本,但没有迹象表明他们将能够扭转这一趋势。
英特尔,台积电,AMD 和三星都要花费数十亿美元,因为它们必须建造新的晶圆厂,购买所有新的工艺工具。因此,尽管每个芯片的晶体管数量持续增加,但其单位成本却开始增加。
> 甚至以纳米为单位的术语 `栅极长度` 也变得模棱两可。 各种制造商以不同的方式测量其晶体管的尺寸,从而使它们在没有交付的情况下可以展示比竞争对手少的数量。这是 CPU 制造商的非 GAAP 收益报告模型。
### 1.7. 更多的核心

达到温度和频率限制后,不再可能使单个内核的运行速度快两倍。 但是,如果添加另一个内核,则可以提供两倍的处理能力-如果软件可以支持的话。
实际上,CPU 的核心数量主要由散热决定。 Dennard 缩放的末尾意味着 CPU 的时钟速度是 1 到 4 Ghz 之间的任意数字,具体取决于它的温度。在谈论基准测试时,我们会很快看到这一点。
### 1.8. 阿姆达尔定律 {#amdahls_law}
CPU 并没有变得越来越快,但是随着超线程和多核它们变得越来越宽。 移动部件为双核,台式机部件为四核,服务器部件为数十个内核。 这将是计算机性能的未来吗? 不幸的是没有。
阿姆达尔定律以 IBM/360 的设计者吉姆·阿姆达尔(Gene Amdahl)的名字命名,它是一个公式,它给出了在固定工作负载下任务执行延迟的理论上的加速,这可以通过改善资源的系统来实现。

阿姆达尔定律告诉我们,程序的最大速度受程序顺序部分的限制。 如果您编写的程序的执行力的 95% 可以并行运行,即使有成千上万的处理器,则程序执行的最大速度也将限制为 20 倍。
考虑一下您每天使用的程序,它们的执行量中有多少是可以解析的?
### 1.9. 动态优化
由于时钟速度停滞不前,并且由于抛出额外的内核而产生的回报有限,因此,提速来自何处? 它们来自芯片本身的体系结构改进。 这些是五到七年的大型项目,名称如下 [Nehalem, Sandy Bridge, and Skylake](https://en.wikipedia.org/wiki/List_of_Intel_CPU_microarchitectures#Pentium_4_/_Core_Lines).
在过去的二十年中,性能的改善大部分来自体系结构的改善:
#### 1.9.1. 乱序执行
乱序,也称为超标量,执行是一种从 CPU 正在执行的代码中提取所谓的 _指令级并行性_ 的方法。 现代 CPU 在硬件级别有效地执行 SSA,以识别操作之间的数据依赖性,并在可能的情况下并行运行独立的指令。
但是,任何一段代码固有的并行性数量是有限的。它也非常耗电。大多数现代 CPU 在每个内核上都部署了六个执行单元,因为在流水线的每个阶段将每个执行单元连接到所有其他执行单元的成本为 n 平方。
#### 1.9.2. 预测执行
除最小的微控制器外,所有 CPU 均使用 _指令管道_ 来重叠指令 获取/解码/执行/提交 周期中的部分。
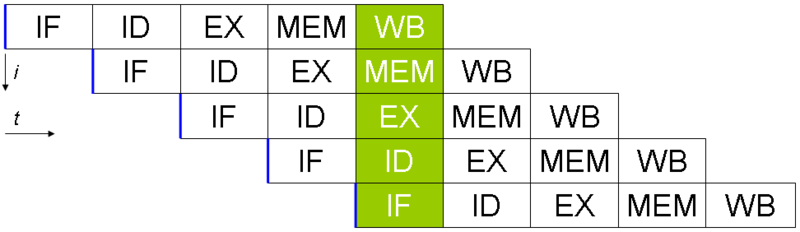
指令流水线的问题是分支指令,平均每 5 到 8 条指令出现一次。当 CPU 到达分支时,它不能在分支之外寻找其他指令来执行,并且直到知道程序计数器也将在何处分支之前,它才能开始填充其管道。推测执行使 CPU 可以“猜测”分支仍要处理的路径,_同时仍在处理分支指令!_
如果 CPU 正确预测了分支,则它可以保持其指令流水线满。如果 CPU 无法预测正确的分支,则当它意识到错误时,必须回滚对其 _architectural state_ 所做的任何更改。由于我们都在通过 Spectre 样式漏洞进行学习,因此有时这种回滚并没有像希望的那样无缝。
当分支预测率较低时,投机执行可能会非常耗电。如果分支预测错误,不仅 CPU 回溯到预测错误的地步,而且浪费在错误分支上的能量也被浪费了。
所有这些优化导致我们看到的单线程性能的提高,但要付出大量晶体管和功率的代价。
> Cliff Click 的 [精彩演讲](https://www.youtube.com/watch?v=OFgxAFdxYAQ) 认为乱序,并且推测性执行对于尽早开始缓存未命中最有用,从而减少了观察到的缓存延迟。
### 1.10. 现代 CPU 已针对批量操作进行了优化
> 现代处理器就像是由硝基燃料驱动的有趣的汽车,它们在四分之一英里处表现出色。不幸的是,现代编程语言就像蒙特卡洛一样,充满了曲折。- 大卫·昂加(David Ungar)
这是来自有影响力的计算机科学家,SELF 编程语言的开发人员 David Ungar 的引言,在很旧的演讲中就引用了 [I found online](http://www.ai.mit.edu/projects/dynlangs/wizards-panels.html).
因此,现代 CPU 已针对批量传输和批量操作进行了优化。 在每个级别,操作的设置成本都会鼓励您进行大量工作。 一些例子包括
- 内存不是按字节加载,而是按高速缓存行的倍数加载,这就是为什么对齐变得不再像以前的计算机那样成为问题的原因。
- MMX 和 SSE 等向量指令允许一条指令同时针对多个数据项执行,前提是您的程序可以以这种形式表示。
### 1.11. 现代处理器受内存延迟而不是内存容量的限制
如果 CPU 占用的状况还不够糟,那么从内存方面来的消息就不会好多了。
连接到服务器的物理内存在几何上有所增加。 我在 1980 年代的第一台计算机具有数千字节的内存。 当我读高中时,我所有的论文都是用 3.8 MB 的 386 写在 386 上的。 现在,查找具有数十或数百 GB RAM 的服务器已变得司空见惯,而云提供商则将其推向了 TB 的 TB。

但是,处理器速度和内存访问时间之间的差距继续扩大。
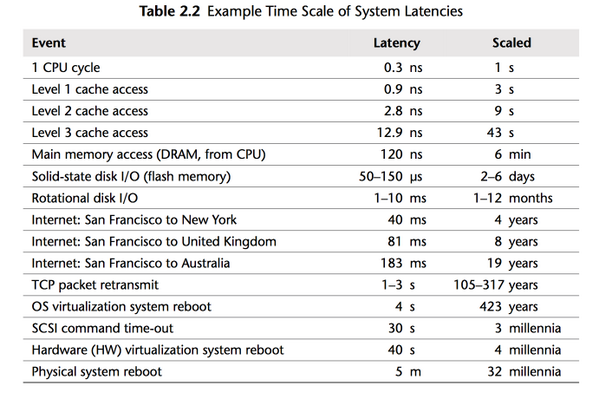
但是,就丢失处理器等待内存的处理器周期而言,物理内存仍与以往一样遥不可及,因为内存无法跟上 CPU 速度的提高。
因此,大多数现代处理器受内存延迟而不是容量的限制。
### 1.12. 缓存控制着我们周围的一切

几十年来,解决处理器/内存上限的解决方案是添加缓存-一块较小的快速内存,位置更近,现在直接集成到 CPU 中。
但;
- 数十年来,L1 一直停留在每个核心 32kb
- L2 在最大的英特尔部分上已缓慢爬升到 512kb
- L3 现在在 4-32mb 范围内,但其访问时间可变

受高速缓存限制的大小是因为它们 [physically large on the CPU die](https://www.itrs.net/Links/2000UpdateFinal/Design2000final.pdf),会消耗大量功率。 要使缓存未命中率减半,您必须将缓存大小提高 _四倍_。
### 1.13. 免费午餐结束了
2005 年,C++ 委员会负责人 Herb Sutter 撰写了一篇题为 [免费午餐结束](http://www.gotw.ca/publications/concurrency-ddj.htm) 的文章。 萨特(Sutter)在他的文章中讨论了我涵盖的所有要点,并断言未来的程序员将不再能够依靠较快的硬件来修复较慢的程序或较慢的编程语言。
十多年后的今天,毫无疑问,赫伯·萨特(Herb Sutter)是正确的。内存很慢,缓存太小,CPU 时钟速度倒退了,单线程 CPU 的简单世界早已一去不复返了。
摩尔定律仍然有效,但是对于我们这个房间里的所有人来说,免费午餐已经结束。
### 1.14. 结束
> 我要引用的数字是到 2010 年:30GHz,100 亿个晶体管和每秒 1 兆指令。— [Pat Gelsinger, Intel CTO, April 2002](https://www.cnet.com/news/intel-cto-chip-heat-becoming-critical-issue/)
很明显,如果没有材料科学方面的突破,CPU 性能恢复到同比 52% 增长的可能性几乎很小。普遍的共识是,故障不在于材料科学本身,而在于晶体管的使用方式。用硅表示的顺序指令流的逻辑模型导致了这种昂贵的最终结果。
在线上有许多演示文稿可以重述这一点。 它们都具有相同的预测-将来的计算机将不会像今天这样编程。 有人认为它看起来更像是带有数百个非常笨拙,非常不连贯的处理器的图形卡。 其他人则认为,超长指令字(VLIW)计算机将成为主流。 所有人都同意,我们当前的顺序编程语言将与此类处理器不兼容。
我的观点是这些预测是正确的,此时硬件制造商挽救我们的前景严峻。 但是,我们可以为今天拥有的硬件优化当前程序的范围是 _巨大的_。 里克·哈德森(Rick Hudson)在 GopherCon 2015 大会上谈到 [以"良好的循环"重新参与](https://talks.golang.org/2015/go-gc.pdf),该软件可以与我们今天拥有的硬件一起工作,而不是仅适用于这种硬件 。
查看我之前显示的图表,从 2015 年到 2018 年,整数性能最多提高了 5-8%,而内存延迟却最多,Go 团队将垃圾收集器的暂停时间减少了 [两个数量级](https://blog.golang.org/ismmkeynote)。 与使用 Go 1.6 的相同硬件上的同一程序相比,Go 1.11 程序具有更好的 GC 延迟。 这些都不是来自硬件。
因此,为了在当今世界的当今硬件上获得最佳性能,您需要一种编程语言,该语言应:
- 之所以编译而不是解释,是因为解释后的编程语言与 CPU 分支预测变量和推测性执行之间的交互作用很差。
- 您需要一种语言来允许编写有效的代码,它需要能够谈论位和字节,并且必须有效地说明整数的长度,而不是假装每个数字都是理想的浮点数。
- 您需要一种使程序员能够有效地谈论内存,思考结构与 Java 对象的语言,因为所有的指针追逐都会给 CPU 高速缓存带来压力,而高速缓存未命中会消耗数百个周期。
- 随应用程序的性能而扩展到多个内核的编程语言取决于它使用缓存的效率以及在多个内核上并行化工作的效率。
显然,我们在这里谈论 Go,我相信 Go 拥有了我刚才描述的许多特征。
#### 1.14.1. 这对我们意味着什么? {#what_does_that_mean_for_us}
> 只有三种优化:少做些。少做一次。更快地做。
>
> 最大的收益来自 1,但我们将所有时间都花在 3 上。 — [Michael Fromberger](https://twitter.com/creachadair/status/1039602865831010305)
本讲座的目的是说明,当您谈论程序或系统的性能时,完全是在软件中。等待更快的硬件来挽救一天真是愚蠢的事情。
但是有个好消息,我们可以在软件上进行大量改进,而这就是我们今天要讨论的。
#### 1.14.2. 进一步阅读
- [The Future of Microprocessors, Sophie Wilson](https://www.youtube.com/watch?v=zX4ZNfvw1cw) JuliaCon 2018
- [50 Years of Computer Architecture: From Mainframe CPUs to DNN TPUs, David Patterson](https://www.youtube.com/watch?v=HnniEPtNs-4)
- [The Future of Computing, John Hennessy](https://web.stanford.edu/~hennessy/Future%20of%20Computing.pdf)
- [The future of computing: a conversation with John Hennessy](https://www.youtube.com/watch?v=Azt8Nc-mtKM) (Google I/O '18)
## 2. Benchmarking {#benchmarking}
> 测量两次,取一次。 — Ancient proverb
在尝试改善一段代码的性能之前,首先我们必须了解其当前性能。
本节重点介绍如何使用 Go 测试框架构建有用的基准,并提供了避免陷阱的实用技巧。
### 2.1. 标杆基准规则
在进行基准测试之前,必须具有稳定的环境才能获得可重复的结果。
- 机器必须处于闲置状态-不要在共享硬件上进行配置,不要在等待较长基准测试运行时浏览网络。
- 注意节能和热缩放。这些在现代笔记本电脑上几乎是不可避免的。
- 避免使用虚拟机和共享云托管;对于一致的测量,它们可能太嘈杂。
如果负担得起,请购买专用的性能测试硬件。机架安装,禁用所有电源管理和热量缩放功能,并且永远不要在这些计算机上更新软件。 最后一点是从系统管理的角度来看糟糕的建议,但是如果软件更新改变了内核或库的执行方式 -想想 Spectre 补丁- 这将使以前的任何基准测试结果无效。
对于我们其他人,请进行前后采样,然后多次运行以获取一致的结果。
### 2.2\. Using the testing package for benchmarking
`testing` 包内置了对编写基准测试的支持。 如果我们有一个简单的函数,像这样:
```go
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
default:
return Fib(n-1) + Fib(n-2)
}
}
```
我们可以使用 `testing` 包通过这种形式为函数编写一个 _基准_。
```go
func BenchmarkFib20(b *testing.B) {
for n := 0; n < b.N; n++ {
Fib(20) // run the Fib function b.N times
}
}
```
> 基准测试功能与您的测试一起存在于 `_test.go` 文件中。
Benchmarks are similar to tests, the only real difference is they take a `*testing.B` rather than a `*testing.T`. Both of these types implement the `testing.TB` interface which provides crowd favorites like `Errorf()`, `Fatalf()`, and `FailNow()`.
基准测试类似于测试,唯一的不同是基准测试采用的是 `*testing.B`,而不是 `*testing.T`。这两种类型都实现了 `testing.TB` 接口,该接口提供了诸如 `Errorf()`,`Fatalf()` 和 `FailNow()` 之类的方法。
#### 2.2.1. 运行软件包的基准测试 {#running_a_packages_benchmarks}
As benchmarks use the `testing` package they are executed via the `go test` subcommand. However, by default when you invoke `go test`, benchmarks are excluded.
当基准测试使用 `测试` 软件包时,它们通过 `go test` 子命令执行。 但是,默认情况下,当您调用 `go test` 时,将排除基准测试。
要在包中显式运行基准测试,请使用 `-bench` 标志。`-bench` 采用与您要运行的基准测试名称匹配的正则表达式,因此调用包中所有基准测试的最常见方法是 `-bench=.` 这是一个例子:
```bash
% go test -bench=. ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 30000 40865 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 1.671s
```
> `go test` 还将在匹配基准之前运行软件包中的所有测试,因此,如果软件包中有很多测试,或者它们花费很长时间,则可以通过 `go test` 提供的 `-run` 参数来排除它们,正则表达式不匹配; 即。
>
> ```bash
> go test -run=^$
> ```
>
#### 2.2.2. 基准如何运作
每个基准函数调用的 `b.N` 值都不同,这是基准应运行的迭代次数。
如果基准功能在 1 秒内(默认值)在 1 秒内完成,则 `b.N` 从 1 开始,然后 `b.N` 增加,基准功能再次运行。
`b.N` increases in the approximate sequence; 1, 2, 3, 5, 10, 20, 30, 50, 100, and so on. The benchmark framework tries to be smart and if it sees small values of `b.N` are completing relatively quickly, it will increase the the iteration count faster.
`b.N` 以近似顺序增加;1, 2, 3, 5, 10, 20, 30, 50, 100 等。基准框架试图变得聪明,如果看到较小的 `b.N` 值相对较快地完成,它将更快地增加迭代次数。
查看上面的示例,`BenchmarkFib20-8` 发现循环的大约 30,000 次迭代花费了超过一秒钟的时间。从那里基准框架计算得出,每次操作的平均时间为 40865ns。
> 后缀 `-8` 与用于运行此测试的 `GOMAXPROCS` 的值有关。 该数字 `GOMAXPROCS` 默认为启动时 Go 进程可见的 CPU 数。 您可以使用 `-cpu` 标志来更改此值,该标志带有一个值列表以运行基准测试。
>
> ```bash
> % go test -bench=. -cpu=1,2,4 ./examples/fib/
> goos: darwin
> goarch: amd64
> BenchmarkFib20 30000 39115 ns/op
> BenchmarkFib20-2 30000 39468 ns/op
> BenchmarkFib20-4 50000 40728 ns/op
> PASS
> ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 5.531s
> ```
>
> 这显示了以 1、2 和 4 核运行基准测试。 在这种情况下,该标志对结果几乎没有影响,因为该基准是完全顺序的。
>
#### 2.2.3. 提高基准精度
`fib` 功能是一个稍作设计的示例-除非您编写 TechPower Web 服务器基准测试-否则您的业务不太可能会因您能够快速计算出斐波那契序列中的第 20 个数字而受到限制。但是,基准确实提供了有效基准的忠实示例。
具体来说,您希望基准测试可以运行数万次迭代,以便每个操作获得良好的平均值。如果您的基准测试仅运行 100 或 10 次迭代,则这些运行的平均值可能会有较高的标准偏差。如果您的基准测试运行了数百万或数十亿次迭代,则平均值可能非常准确,但会受到代码布局和对齐方式的影响。
为了增加迭代次数,可以使用 `-benchtime` 标志来增加基准时间。 例如:
```bash
% go test -bench=. -benchtime=10s ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 300000 39318 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 20.066s
```
运行相同的基准,直到达到 `b.N` 的值,并花费了超过 10 秒的时间才能返回。由于我们的运行时间增加了 10 倍,因此迭代的总数也增加了 10 倍。 结果并没有太大变化,这就是我们所期望的。
```
为什么报告的总时间是 20 秒,而不是 10 秒?
```
如果您有一个基准运行数百万或数十亿次迭代,导致每次操作的时间在微秒或纳秒范围内,则您可能会发现基准值不稳定,因为热缩放,内存局部性,后台处理,gc 活动等。
对于每次操作以 10 纳秒或一位数纳秒为单位的时间,指令重新排序和代码对齐的相对论效应将对基准时间产生影响。
要使用 `-count` 标志来多次运行基准测试:
```bash
% go test -bench=Fib1 -count=10 ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 1.95 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.97 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.96 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 2.01 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 2.00 ns/op
```
`Fib(1)` 基准测试大约需要 2 纳秒,方差为 +/- 2%。
Go 1.12 中的新增功能是 `-benchtime` 标志,现在需要进行多次迭代,例如。`-benchtime=20x`,它将准确地运行您的代码 `benchtime` 的时间。
```
尝试以10倍,20倍,50倍,100倍和300倍的 `-benchtime` 运行上面的 fib 测试。 你看到了什么?
```
> If you find that the defaults that `go test` applies need to be tweaked for a particular package, I suggest codifying those settings in a `Makefile` so everyone who wants to run your benchmarks can do so with the same settings.
>
> 如果您发现需要针对特定的软件包调整 `go test` 的默认设置,我建议将这些设置编入 `Makefile` 中,这样,每个想要运行基准测试的人都可以使用相同的设置。
### 2.3. 将基准与 Benchstat 进行比较
在上一节中,我建议多次运行基准测试以使更多数据平均。由于本章开头提到的电源管理,后台过程和热管理的影响,这对于任何基准测试都是很好的建议。
我将介绍 Russ Cox 的一个工具 [benchstat](https://godoc.org/golang.org/x/perf/cmd/benchstat).
```bash
% go get golang.org/x/perf/cmd/benchstat
```
Benchstat 可以进行一系列基准测试,并告诉您它们的稳定性。 这是有关电池供电的 `Fib(20)` 示例。
```bash
% go test -bench=Fib20 -count=10 ./examples/fib/ | tee old.txt
goos: darwin
goarch: amd64
BenchmarkFib20-8 50000 38479 ns/op
BenchmarkFib20-8 50000 38303 ns/op
BenchmarkFib20-8 50000 38130 ns/op
BenchmarkFib20-8 50000 38636 ns/op
BenchmarkFib20-8 50000 38784 ns/op
BenchmarkFib20-8 50000 38310 ns/op
BenchmarkFib20-8 50000 38156 ns/op
BenchmarkFib20-8 50000 38291 ns/op
BenchmarkFib20-8 50000 38075 ns/op
BenchmarkFib20-8 50000 38705 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 23.125s
% benchstat old.txt
name time/op
Fib20-8 38.4µs ± 1%
```
`benchstat` 告诉我们平均值为 38.8 微秒,样本之间的变化为 +/- 2%。这对于电池供电来说相当不错。
- 第一次运行是最慢的,因为操作系统已降低 CPU 时钟以节省电量。
- 接下来的两次运行是最快的,因为操作系统确定这不是工作的短暂高峰,并且提高了时钟速度以尽快完成工作,从而希望能够返回睡觉。
- 其余运行是操作系统和供热生产的 BIOS 交互功耗。
#### 2.3.1. Improve `Fib` {#improve_fib}
确定两组基准之间的性能差异可能是乏味且容易出错的。`benchstat` 可以帮助我们。
>
> Saving the output from a benchmark run is useful, but you can also save the _binary_ that produced it. This lets you rerun benchmark previous iterations. To do this, use the `-c` flag to save the test binary—I often rename this binary from `.test` to `.golden`.
>
> 保存来自基准运行的输出很有用,但是您也可以保存产生它的 _二进制文件_。 这使您可以重新运行基准测试以前的迭代。 为此,请使用 `-c`标志保存测试二进制文件我经常将此二进制文件从 `.test` 重命名为 `.golden`。
>
> ```bash
> % go test -c
> % mv fib.test fib.golden
> ```
>
先前的 `Fib` 功能具有斐波那契系列中第 0 和第 1 个数字的硬编码值。之后,代码以递归方式调用自身。今天晚些时候,我们将讨论递归的成本,但是目前,假设递归的成本是很高的,尤其是因为我们的算法使用的是指数时间。
对此的简单解决方法是对斐波那契数列中的另一个数字进行硬编码,从而将每个可回溯调用的深度减少一个。
```go
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
case 2:
return 1
default:
return Fib(n-1) + Fib(n-2)
}
}
```
> 该文件还包含对 `Fib` 的综合测试。如果没有通过验证当前行为的测试,请勿尝试提高基准。
为了比较我们的新版本,我们编译了一个新的测试二进制文件并对其进行了基准测试,并使用 `benchstat` 来比较输出。
```bash
% go test -c
% ./fib.golden -test.bench=. -test.count=10 > old.txt
% ./fib.test -test.bench=. -test.count=10 > new.txt
% benchstat old.txt new.txt
name old time/op new time/op delta
Fib20-8 44.3µs ± 6% 25.6µs ± 2% -42.31% (p=0.000 n=10+10)
```
比较基准时需要检查三件事
- 旧时代和新时期的方差 ±。 1-2% 是好的,3-5% 是可以的,大于 5%,并且您的某些样本将被认为不可靠。 比较一侧差异较大的基准时,请注意不要有所改善。
- p 值。 p 值小于 0.05 表示良好,大于 0.05 表示基准可能没有统计学意义。
- 缺少样本。`benchstat` 将报告它认为有效的旧样本和新样本中的多少个,有时即使您执行了 `-count=10`,也可能只报告了 9 个。 10% 或更低的拒绝率是可以的,高于 10% 可能表明您的设置不稳定,并且您可能比较的样本太少。
### 2.4. 避免基准化启动成本
有时,您的基准测试具有一次运行设置成本。`b.ResetTimer()` 将用于忽略设置中的时间。
```go
func BenchmarkExpensive(b *testing.B) {
boringAndExpensiveSetup()
b.ResetTimer() // (1)
for n := 0; n < b.N; n++ {
// function under test
}
}
```
| **1** | 重置基准计时器 |
如果 _每个循环_ 迭代都有一些昂贵的设置逻辑,请使用 `b.StopTimer()` 和 `b.StartTimer()` 暂停基准计时器。
```go
func BenchmarkComplicated(b *testing.B) {
for n := 0; n < b.N; n++ {
b.StopTimer() // (1)
complicatedSetup()
b.StartTimer() // (2)
// function under test
}
}
```
| **1** | 暂停基准测试计时器 |
| **2** | 恢复计时器 |
### 2.5. 基准分配
分配数量和大小与基准时间密切相关。 您可以告诉 `testing` 框架记录被测代码分配的数量。
```go
func BenchmarkRead(b *testing.B) {
b.ReportAllocs()
for n := 0; n < b.N; n++ {
// function under test
}
}
```
这是一个使用 `bufio` 软件包基准测试的示例。
```bash
% go test -run=^$ -bench=. bufio
goos: darwin
goarch: amd64
pkg: bufio
BenchmarkReaderCopyOptimal-8 20000000 103 ns/op
BenchmarkReaderCopyUnoptimal-8 10000000 159 ns/op
BenchmarkReaderCopyNoWriteTo-8 500000 3644 ns/op
BenchmarkReaderWriteToOptimal-8 5000000 344 ns/op
BenchmarkWriterCopyOptimal-8 20000000 98.6 ns/op
BenchmarkWriterCopyUnoptimal-8 10000000 131 ns/op
BenchmarkWriterCopyNoReadFrom-8 300000 3955 ns/op
BenchmarkReaderEmpty-8 2000000 789 ns/op 4224 B/op 3 allocs/op
BenchmarkWriterEmpty-8 2000000 683 ns/op 4096 B/op 1 allocs/op
BenchmarkWriterFlush-8 100000000 17.0 ns/op 0 B/op 0 allocs/op
```
>
> You can also use the `go test -benchmem` flag to force the testing framework to report allocation statistics for all benchmarks run.
>
> ```bash
> % go test -run=^$ -bench=. -benchmem bufio
> goos: darwin
> goarch: amd64
> pkg: bufio
> BenchmarkReaderCopyOptimal-8 20000000 93.5 ns/op 16 B/op 1 allocs/op
> BenchmarkReaderCopyUnoptimal-8 10000000 155 ns/op 32 B/op 2 allocs/op
> BenchmarkReaderCopyNoWriteTo-8 500000 3238 ns/op 32800 B/op 3 allocs/op
> BenchmarkReaderWriteToOptimal-8 5000000 335 ns/op 16 B/op 1 allocs/op
> BenchmarkWriterCopyOptimal-8 20000000 96.7 ns/op 16 B/op 1 allocs/op
> BenchmarkWriterCopyUnoptimal-8 10000000 124 ns/op 32 B/op 2 allocs/op
> BenchmarkWriterCopyNoReadFrom-8 500000 3219 ns/op 32800 B/op 3 allocs/op
> BenchmarkReaderEmpty-8 2000000 748 ns/op 4224 B/op 3 allocs/op
> BenchmarkWriterEmpty-8 2000000 662 ns/op 4096 B/op 1 allocs/op
> BenchmarkWriterFlush-8 100000000 16.9 ns/op 0 B/op 0 allocs/op
> PASS
> ok bufio 20.366s
> ```
>
### 2.6. 注意编译器的优化
这个例子来自 [issue 14813](https://github.com/golang/go/issues/14813#issue-140603392).
```go
const m1 = 0x5555555555555555
const m2 = 0x3333333333333333
const m4 = 0x0f0f0f0f0f0f0f0f
const h01 = 0x0101010101010101
func popcnt(x uint64) uint64 {
x -= (x >> 1) & m1
x = (x & m2) + ((x >> 2) & m2)
x = (x + (x >> 4)) & m4
return (x * h01) >> 56
}
func BenchmarkPopcnt(b *testing.B) {
for i := 0; i < b.N; i++ {
popcnt(uint64(i))
}
}
```
您认为该功能将以多快的速度进行基准测试? 让我们找出答案。
```bash
% go test -bench=. ./examples/popcnt/
goos: darwin
goarch: amd64
BenchmarkPopcnt-8 2000000000 0.30 ns/op
PASS
```
0.3 纳秒;这基本上是一个时钟周期。即使假设每个时钟周期中 CPU 可能正在运行一些指令,该数字似乎也过低。发生了什么?
To understand what happened, we have to look at the function under benchmake, `popcnt`. `popcnt` is a leaf function — it does not call any other functions — so the compiler can inline it.
要了解发生了什么,我们必须查看 benchmake 下的函数 `popcnt`。`popcnt` 是 `叶函数(它不调用任何其他函数)` 因此编译器可以内联它。
因为该函数是内联的,所以编译器现在可以看到它没有副作用。 popcnt 不会影响任何全局变量的状态。 因此,消除了该调用。这是编译器看到的:
```go
func BenchmarkPopcnt(b *testing.B) {
for i := 0; i < b.N; i++ {
// optimised away
}
}
```
在我测试过的所有 `Go` 编译器版本中,仍然会生成循环。 但是英特尔 `CPU` 确实擅长优化循环,尤其是空循环。
#### 2.6.1\. 练习,实践 {#exercise_look_at_the_assembly}
在继续之前,让我们实践一下以确认我们所看到的
```
% go test -gcflags=-S
```
```
使用 `gcflags="-l -S"` 禁用内联,这可以影响程序输出
```
> 要消除的事情是与通过消除不必要的计算来使实际代码相同的优化,即消除了没有可观察到的副作用的基准测试。
> 随着 Go 编译器的改进,这只会变得越来越普遍。
#### 2.6.2. 修复基准
禁用内联以使基准测试有效是不现实的;我们希望在优化的基础上构建代码。
为了修正这个基准,我们必须确保编译器无法 _证明_ `BenchmarkPopcnt` 的主体不会引起全局状态的改变。
```go
var Result uint64
func BenchmarkPopcnt(b *testing.B) {
var r uint64
for i := 0; i < b.N; i++ {
r = popcnt(uint64(i))
}
Result = r
}
```
这是确保编译器无法优化循环主体的推荐方法。
首先,我们通过将其存储在 `r` 中来使用调用 `popcnt` 的结果。其次,由于一旦基准测试结束,`r` 就在 `BenchmarkPopcnt` 的范围内局部声明,所以 `r` 的结果对于程序的另一部分永远是不可见的,因此作为最后的动作,我们将 `r` 的值赋值储存到包公共变量 `Result`。
Because `Result` is public the compiler cannot prove that another package importing this one will not be able to see the value of `Result` changing over time, hence it cannot optimise away any of the operations leading to its assignment.
What happens if we assign to `Result` directly? Does this affect the benchmark time? What about if we assign the result of `popcnt` to `_`?
由于 `Result` 是公开的,因此编译器无法证明导入该软件包的另一个包将无法看到 `Result` 的值随时间变化,因此它无法优化导致其赋值的任何操作。
如果直接分配给 `Result` 会怎样?这会影响基准时间吗?如果将 `popcnt` 的结果赋给 `_` 会怎么样?
> 在我们之前的 `Fib` 基准测试中,我们没有采取这些预防措施,应该这样做吗?
### 2.7. 基准误差
`for` 循环对于基准测试的运行至关重要。
这是两个不正确的基准,您能解释一下它们有什么问题吗?
```go
func BenchmarkFibWrong(b *testing.B) {
Fib(b.N)
}
```
```go
func BenchmarkFibWrong2(b *testing.B) {
for n := 0; n < b.N; n++ {
Fib(n)
}
}
```
运行这些基准测试,您会看到什么?
### 2.8. 分析基准
`testing` 包内置了对生成 `CPU`,内存和块配置文件的支持。
- `-cpuprofile=$FILE` 将 `CPU` 分析写入 `$FILE`.
- `-memprofile=$FILE`, 将内存分析写入 `$FILE`, `-memprofilerate=N` 将配置文件速率调整为 `1/N`.
- `-blockprofile=$FILE`, 将块分析写入 `$FILE`.
使用这些标志中的任何一个也会保留二进制文件。
```bash
% go test -run=XXX -bench=. -cpuprofile=c.p bytes
% go tool pprof c.p
```
### 2.9. 讨论
有没有问题?
也许是时候休息一下了。
## 3. 性能评估和性能分析 {#profiling}
在上一节中,我们研究了对单个函数进行基准测试,这对您提前知道瓶颈在哪里很有用。但是,通常您会发现自己有一个问题
> 为什么该程序需要这么长时间才能运行?
对 _整个_ 程序进行概要分析,对于回答诸如此类的高级问题很有用。在本部分中,我们将使用 `Go` 内置的性能分析工具从内部调查程序的运行情况。
### 3.1. pprof
今天我们要讨论的第一个工具是 _pprof_. [pprof](https://github.com/google/pprof) 来自 [Google Perf Tools](https://github.com/gperftools/gperftools) 这套工具套件,自最早的公开发布以来已集成到 Go 运行时中。
`pprof` 由两部分组成:
- `runtime/pprof` 每个 Go 程序内置的软件包
- `go tool pprof` 用于调查性能分析。
### 3.2\. 性能分析文件类型
pprof 支持多种类型的性能分析,今天我们将讨论其中的三种:
- CPU profiling.
- Memory profiling.
- Block (or blocking) profiling.
- Mutex contention profiling.
#### 3.2.1. CPU profiling
CPU 分析文件是最常见的配置文件类型,也是最明显的配置文件。
启用 CPU 性能分析后,运行时将每 10 毫秒中断一次,并记录当前正在运行的 goroutine 的堆栈跟踪。
分析文件完成后,我们可以对其进行分析以确定最热门的代码路径。
函数在分析文件中出现的次数越多,代码路径花费的时间就越多。
#### 3.2.2. memory profiling
进行 _堆_ 分配时,memory profiling 记录堆栈跟踪。
堆栈分配假定为空闲,并且在内存性能分析文件中 _未跟踪_。
像 CPU 分析一样,memory profiling 都是基于样本的,默认情况下,每 1000 个分配中的内存分析样本为 1。 此速率可以更改。
由于 memory profiling 是基于样本的,且它跟踪的是已分配的内存而不是使用中的内存,所以很难使用 memory profiling 来确定应用程序的整体内存使用情况。
_个人想法:_ 我发现 memory profiling 对发现内存泄漏没有帮助。有更好的方法来确定您的应用程序正在使用多少内存。 我们将在演示文稿的后面讨论这些。
#### 3.2.3. Block profiling.
块分析是 `Go` 特有的。
块概要文件类似于 `CPU` 概要文件,但是它记录 `goroutine` 等待共享资源所花费的时间。
这对于确定应用程序中的 _并发_ 瓶颈很有用。
块性能分析可以向您显示何时有大量 `goroutine` _可以_ 取得进展,但被 _阻塞_ 了。包括阻止
- 在无缓冲的通道上发送或接收。
- 正在发送到完整频道,从空频道接收。
- 试图 `锁定` 被另一个 `goroutine` 锁定的 `sync.Mutex`。
块分析是一种非常专业的工具,在您确信消除了所有 `CPU` 和内存使用瓶颈之后,才应该使用它。
#### 3.2.4. Mutex profiling
互斥锁概要分析与块概要分析类似,但专门针对导致互斥锁争用导致延迟的操作。
我对这种类型的个人资料没有很多经验,但是我建立了一个示例来演示它。我们将很快看一下该示例。
### 3.3. 同一时间只使用一种性能分析
性能分析不是免费的。
分析对程序性能有中等但可测量的影响,尤其是如果您增加内存配置文件采样率。
大多数工具不会阻止您一次启用多个性能分析。
> 一次不要启用多种性能分析。
>
> 如果您同时启用多个个人资料,他们将观察自己的互动并放弃您的结果。
### 3.4. 收集性能分析
Go 运行时的配置文件界面位于 `runtime/pprof` 包中。`runtime/pprof` 是一个非常基础的工具,由于历史原因,与各种配置文件的接口并不统一。
正如我们在上一节中看到的那样,pprof 概要分析内置于 `testing` 包中,但是有时将您要分析的代码放在 `testing.B` 基准测试环境中是不便或困难的,并且必须使用直接使用 `runtime/pprof` API。
几年前,我写了一个 [small package](https://github.com/pkg/profile),以便更轻松地描述现有应用程序。
```go
import "github.com/pkg/profile"
func main() {
defer profile.Start().Stop()
// ...
}
```
在本节中,我们将使用 `profile` 包。 稍后,我们将直接使用 `runtime/pprof` 接口。
### 3.5. Analysing a profile with pprof
既然我们已经讨论了 `pprof` 可以测量的内容以及如何生成配置文件,那么我们就来讨论如何使用 `pprof` 分析配置文件。
分析由 `go pprof` 子命令驱动
```bash
% go tool pprof /path/to/your/profile
```
该工具提供了概要数据的几种不同表示形式。文字,图形甚至火焰图。
> 如果您使用 `Go` 已有一段时间,则可能会被告知 `pprof` 有两个参数。从 Go 1.9 开始,配置文件包含渲染配置文件所需的所有信息。您不再需要生成性能分析的二进制文件。🎉
#### 3.5.1. 进一步阅读
- [Profiling Go programs](https://blog.golang.org/profiling-go-programs) (Go Blog)
- [Debugging performance issues in Go programs](https://software.intel.com/en-us/blogs/2014/05/10/debugging-performance-issues-in-go-programs)
#### 3.5.2. CPU profiling (exercise) {#cpu_profiling_exercise}
让我们编写一个计算单词数的程序:
```go
package main
import (
"fmt"
"io"
"log"
"os"
"unicode"
)
func readbyte(r io.Reader) (rune, error) {
var buf [1]byte
_, err := r.Read(buf[:])
return rune(buf[0]), err
}
func main() {
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatalf("could not open file %q: %v", os.Args[1], err)
}
words := 0
inword := false
for {
r, err := readbyte(f)
if err == io.EOF {
break
}
if err != nil {
log.Fatalf("could not read file %q: %v", os.Args[1], err)
}
if unicode.IsSpace(r) && inword {
words++
inword = false
}
inword = unicode.IsLetter(r)
}
fmt.Printf("%q: %d words\n", os.Args[1], words)
}
```
让我们看看赫尔曼·梅尔维尔经典小说中有多少个单词 [Moby Dick](https://www.gutenberg.org/ebooks/2701) (来自古腾堡计划)
```bash
% go build && time ./words moby.txt
"moby.txt": 181275 words
real 0m2.110s
user 0m1.264s
sys 0m0.944s
```
让我们将其与 `unix` 的 `wc -w` 进行比较
```bash
% time wc -w moby.txt
215829 moby.txt
real 0m0.012s
user 0m0.009s
sys 0m0.002s
```
所以数字不一样。 `wc` 大约高出 `19%`,因为它认为单词与我的简单程序不同。这并不重要-两个程序都将整个文件作为输入,并在一次通过中计算从单词到非单词的过渡次数。
让我们研究一下为什么使用 `pprof` 这些程序的运行时间不同。
#### 3.5.3. 添加 CPU 分析
首先,编辑 `main.go` 并启用分析
```go
import (
"github.com/pkg/profile"
)
func main() {
defer profile.Start().Stop()
// ...
```
现在,当我们运行程序时,将创建一个 `cpu.pprof` 文件。
```bash
% go run main.go moby.txt
2018/08/25 14:09:01 profile: cpu profiling enabled, /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile239941020/cpu.pprof
"moby.txt": 181275 words
2018/08/25 14:09:03 profile: cpu profiling disabled, /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile239941020/cpu.pprof
```
现在我们有了配置文件,可以使用 `go pprof` 工具对其进行分析。
```bash
% go tool pprof /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile239941020/cpu.pprof
Type: cpu
Time: Aug 25, 2018 at 2:09pm (AEST)
Duration: 2.05s, Total samples = 1.36s (66.29%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 1.42s, 100% of 1.42s total
flat flat% sum% cum cum%
1.41s 99.30% 99.30% 1.41s 99.30% syscall.Syscall
0.01s 0.7% 100% 1.42s 100% main.readbyte
0 0% 100% 1.41s 99.30% internal/poll.(*FD).Read
0 0% 100% 1.42s 100% main.main
0 0% 100% 1.41s 99.30% os.(*File).Read
0 0% 100% 1.41s 99.30% os.(*File).read
0 0% 100% 1.42s 100% runtime.main
0 0% 100% 1.41s 99.30% syscall.Read
0 0% 100% 1.41s 99.30% syscall.read
```
`top` 命令是您最常使用的命令。 我们可以看到该程序有 99% 的时间花费在 `syscall.Syscall` 中,而一小部分花费在`main.readbyte` 中。
我们还可以使用 `web` 命令来可视化此调用。这将从配置文件数据生成有向图。 在后台,这使用了 Graphviz 的 `dot` 命令。
但是,在 Go 1.10(也可能是 1.11)中,Go 附带了本身支持 `HTTP` 服务器的 `pprof` 版本
```bash
% go tool pprof -http=:8080 /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile239941020/cpu.pprof
```
将会打开网络浏览器;
- 图形模式
- 火焰图模式
在图形上,占用 _最多_ CPU 时间的框是最大的框,我们看到 `syscall.Syscall` 占程序总时间的 99.3%。导致 `syscall.Syscall` 的字符串表示立即调用者,如果多个代码路径在同一函数上收敛,则可以有多个。箭头的大小代表在一个盒子的子元素上花费了多少时间,我们可以看到,从 `main.readbyte` 开始,它们占了该图分支中 1.41 秒所用时间的接近 0。
_问题_: 谁能猜出为什么我们的版本比 `wc` 慢得多?
#### 3.5.4\. 改进
我们的程序运行缓慢的原因不是因为 `Go` 的 `syscall.Syscall` 运行缓慢。 这是因为系统调用通常是昂贵的操作(并且随着发现更多 Spectre 系列漏洞而变得越来越昂贵)。
每次对 `readbyte` 的调用都会导致一个 `syscall.Read` 的缓冲区大小为 1。因此,我们的程序执行的 `syscall` 数量等于输入的大小。我们可以看到,在 `pprof` 图中,读取输入的内容占主导地位。
```go
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
// defer profile.Start(profile.MemProfile).Stop()
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatalf("could not open file %q: %v", os.Args[1], err)
}
b := bufio.NewReader(f)
words := 0
inword := false
for {
r, err := readbyte(b)
if err == io.EOF {
break
}
if err != nil {
log.Fatalf("could not read file %q: %v", os.Args[1], err)
}
if unicode.IsSpace(r) && inword {
words++
inword = false
}
inword = unicode.IsLetter(r)
}
fmt.Printf("%q: %d words\n", os.Args[1], words)
}
```
通过在 `readbyte` 之前使用 `bufio.Reader` 包装输入文件
```
将此修订程序的时间与 `wc` 比较。有多少差距?进行性能分析,看看还剩下什么。
```
#### 3.5.5. 内存分析
新的单词配置文件表明在 `readbyte` 函数内部分配了一些东西。我们可以使用 `pprof` 进行调查。
```go
defer profile.Start(profile.MemProfile).Stop()
```
然后照常运行程序
```go
% go run main2.go moby.txt
2018/08/25 14:41:15 profile: memory profiling enabled (rate 4096), /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile312088211/mem.pprof
"moby.txt": 181275 words
2018/08/25 14:41:15 profile: memory profiling disabled, /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile312088211/mem.pprof
```

由于我们怀疑分配来自 `readbyte`,这不是那么复杂,`readbyte` 只有三行:
```
使用 `pprof` 确定分配来自何处。
```
```go
func readbyte(r io.Reader) (rune, error) {
var buf [1]byte // (1)
_, err := r.Read(buf[:])
return rune(buf[0]), err
}
```
| 1 | 分配在这里 |
在下一节中,我们将详细讨论为什么会发生这种情况,但是目前,我们看到对 `readbyte` 的每个调用都在分配一个新的一字节长的 _array_ ,并且该数组正在堆上分配。
有什么方法可以避免这种情况?试试看,并使用 CPU 和内存性能分析进行验证。
##### Alloc 对象与 inuse 对象
内存性能分析有两种,分别以 `go tool pprof` 标志区分。
- `-alloc_objects` 报告进行分配的呼叫站点。
- `-inuse_objects` 报告在性能分析末尾可以访问的呼叫站点。
为了演示这一点,这是一个人为设计的程序,它将以受控方式分配一堆内存。
```go
const count = 100000
var y []byte
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
y = allocate()
runtime.GC()
}
// allocate allocates count byte slices and returns the first slice allocated.
func allocate() []byte {
var x [][]byte
for i := 0; i < count; i++ {
x = append(x, makeByteSlice())
}
return x[0]
}
// makeByteSlice returns a byte slice of a random length in the range [0, 16384).
func makeByteSlice() []byte {
return make([]byte, rand.Intn(2^14))
}
```
该程序是带有 `profile` 包的注释,我们将内存配置文件速率设置为 `1`,也就是说,记录每次分配的堆栈跟踪。这会大大减慢该程序的速度,但是您很快就会知道原因。
```bash
% go run main.go
2018/08/25 15:22:05 profile: memory profiling enabled (rate 1), /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile730812803/mem.pprof
2018/08/25 15:22:05 profile: memory profiling disabled, /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile730812803/mem.pprof
```
让我们看一下已分配对象的图,这是默认设置,并显示导致在概要文件期间分配每个对象的调用图。
```bash
% go tool pprof -http=:8080 /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile891268605/mem.pprof
```

不足为奇的是,超过 99% 的分配位于 `makeByteSlice` 内部。 现在让我们使用 `-inuse_objects` 查看相同的配置文件
```bash
% go tool pprof -http=:8080 /var/folders/by/3gf34_z95zg05cyj744_vhx40000gn/T/profile891268605/mem.pprof
```

我们看到的不是在概要文件期间 _分配_ 的对象,而是在获取概要文件时 _仍在使用_ 的对象,这将忽略已由垃圾收集器回收的对象的堆栈跟踪。
#### 3.5.6. Block profiling
我们要查看的最后一个配置文件类型是区块分析。 我们将使用来自 `net/http` 包的 `ClientServer` 基准测试
```
% go test -run=XXX -bench=ClientServer$ -blockprofile=/tmp/block.p net/http
% go tool pprof -http=:8080 /tmp/block.p
```

#### 3.5.7. 线程创建分析
Go 1.11 (?) 增加了对操作系统线程创建的分析支持。
```
将线程创建分析添加到 `godoc` 中,并观察分析 `godoc -http =:8080 -index` 的结果。
```
#### 3.5.8. Framepointers
Go 1.7 已发布,并且与用于 amd64 的新编译器一起,现在默认情况下编译器启用了帧指针。
帧指针是一个始终指向当前堆栈帧顶部的寄存器。
帧指针使诸如 `gdb(1)` 和 `perf(1)` 之类的工具能够理解 Go 调用堆栈。
在本研讨会中,我们不会介绍这些工具,但是您可以阅读和观看我的演讲,该演讲以七种不同的方式介绍 Go 程序。
- [分析 Go 程序的七种方法](https://talks.godoc.org/github.com/davecheney/presentations/seven.slide) (slides)
- [分析 Go 程序的七种方法](https://www.youtube.com/watch?v=2h_NFBFrciI) (video, 30 mins)
- [分析 Go 程序的七种方法](https://www.bigmarker.com/remote-meetup-go/Seven-ways-to-profile-a-Go-program) (webcast, 60 mins)
#### 3.5.9. 练习
- 根据您熟悉的一段代码生成一个性能分析。如果您没有代码示例,请尝试对 `godoc` 进行分析。
```
% go get golang.org/x/tools/cmd/godoc
% cd $GOPATH/src/golang.org/x/tools/cmd/godoc
% vim main.go
```
- 如果要在一台计算机上生成性能分析,然后在另一台计算机上检查性能分析,您将如何处理?
## 4. 编译优化 {#compiler-optimisation}
本节介绍了 Go 编译器执行的一些优化。
例如;
- 逃逸分析
- 内联
- 消除死代码
全部在编译器的前端处理,而代码仍为 `AST` 形式; 然后将代码传递给 `SSA` 编译器进行进一步优化。
### 4.1\. History of the Go compiler
Go 编译器大约在 2007 时作为 Plan9 编译器工具链的分支而开始的。当时的编译器与 Aho 和 Ullman 的 _[Dragon Book](https://www.goodreads.com/book/show/112269.Principles_of_Compiler_Design)_ 非常相似。
在 2015 年,当时的 Go 1.5 编译器为 [C 转换为 Go](https://golang.org/doc/go1.5#c)。
一年后,Go 1.7 引入了一种基于 [SSA](https://en.wikipedia.org/wiki/Static_single_assignment_form) 技术的 [new compiler backend](https://blog.golang.org/go1.7) 以前的 Plan9 样式代码生成。这个新的后端为通用和特定于架构的优化引入了许多机会。
### 4.2. 逃逸优化
我们正在讨论的第一个优化是 _逃逸优化_。
为了说明逃逸分析的作用,我们回想起 [Go spec](https://golang.org/ref/spec) 并未提及堆或堆栈。它仅提及该语言是在引言中被垃圾收集的,并没有提示如何实现该语言。
Go 规范的兼容 Go 实现 _可以_ 将每个分配存储在堆上。这将对垃圾收集器施加很大压力,但是这绝不是不正确的。多年来,gccgo 对逃逸分析的支持非常有限,因此可以有效地认为它在这种模式下运行。
但是,goroutine 的堆栈作为存储局部变量的廉价场所而存在。无需在堆栈上进行垃圾收集。因此,在安全的情况下,放置在堆栈上的分配将更有效。
在某些语言中,例如 `C` 和 `C++`,选择在堆栈上还是在堆上分配是程序员的手动操作。堆分配是通过 `malloc` 和 `free` 进行的,栈分配是通过 `alloca` 进行的。使用这些机制的错误是导致内存损坏错误的常见原因。
在 Go 中,如果值的寿命超出了函数调用的寿命,则编译器会自动将其移动到堆中。 说明该值 _逃逸_ 到堆。
```go
type Foo struct {
a, b, c, d int
}
func NewFoo() *Foo {
return &Foo{a: 3, b: 1, c: 4, d: 7}
}
```
在这个例子中,在 `NewFoo` 中分配的 `Foo` 将被移到堆中,因此在 `NewFoo` 返回后其内容仍然有效。
自 Go 成立以来,这种情况就一直存在。与其说是自动纠正功能,还不如说是一种优化。在 Go 中意外返回堆栈分配变量的地址是不可能的。
但是编译器也可以做相反的事情。它可以找到假定在堆上分配的东西,并将它们移到堆栈中。
让我们看一个例子
```go
func Sum() int {
const count = 100
numbers := make([]int, count)
for i := range numbers {
numbers[i] = i + 1
}
var sum int
for _, i := range numbers {
sum += i
}
return sum
}
func main() {
answer := Sum()
fmt.Println(answer)
}
```
`sum` 将 1 与 100 之间的 `int` 相加并返回结果。
由于 `numbers` 切片仅在 `Sum` 内部引用,因此编译器将安排将该切片的 100 个整数存储在堆栈中,而不是堆中。无需垃圾回收 `numbers`,它会在 `Sum` 返回时自动释放。
#### 4.2.1. 证明它! {#prove_it}
要打印编译器的逃逸分析结果,请使用 `-m` 标志。
```
% go build -gcflags=-m examples/esc/sum.go
# command-line-arguments
examples/esc/sum.go:22:13: inlining call to fmt.Println
examples/esc/sum.go:8:17: Sum make([]int, count) does not escape
examples/esc/sum.go:22:13: answer escapes to heap
examples/esc/sum.go:22:13: io.Writer(os.Stdout) escapes to heap
examples/esc/sum.go:22:13: main []interface {} literal does not escape
:1: os.(*File).close .this does not escape
```
第 8 行显示编译器已正确推断出 `make([]int, 100)` 的结果不会逸出到堆中。没有的原因
第 22 行报告 `answer` 转储到堆中是 `fmt.Println` 是一个可变函数。可变参数函数的参数装在切片中,在本例中为 `[]interface {}`,因此将 `answer` 放入接口值中,因为它是由对 `fmt.Println` 的调用引用的。由于 Go 1.6 的垃圾回收器要求通过接口传递的所有值都是指针,因此编译器优化后的代码的大致是:
```go
var answer = Sum()
fmt.Println([]interface{&answer}...)
```
我们可以使用 `-gcflags="-m -m"` 标志来确认。在哪返回了
```bash
% go build -gcflags='-m -m' examples/esc/sum.go 2>&1 | grep sum.go:22
examples/esc/sum.go:22:13: inlining call to fmt.Println func(...interface {}) (int, error) { return fmt.Fprintln(io.Writer(os.Stdout), fmt.a...) }
examples/esc/sum.go:22:13: answer escapes to heap
examples/esc/sum.go:22:13: from ~arg0 (assign-pair) at examples/esc/sum.go:22:13
examples/esc/sum.go:22:13: io.Writer(os.Stdout) escapes to heap
examples/esc/sum.go:22:13: from io.Writer(os.Stdout) (passed to call[argument escapes]) at examples/esc/sum.go:22:13
examples/esc/sum.go:22:13: main []interface {} literal does not escape
```
简而言之,不必担心第 22 行的逃逸,这对本次讨论并不重要。
#### 4.2.2. 练习
- 这种优化对所有 `count` 的值都适用吗?
- 如果 `count` 是变量而不是常量,此优化是否成立?
- 如果 `count` 是 `Sum` 的参数,此优化是否成立?
#### 4.2.3. Escape analysis (continued) {#escape_analysis_continued}
这个例子是人为造的。它不旨在成为真实的代码,仅是示例。
```go
type Point struct{ X, Y int }
const Width = 640
const Height = 480
func Center(p *Point) {
p.X = Width / 2
p.Y = Height / 2
}
func NewPoint() {
p := new(Point)
Center(p)
fmt.Println(p.X, p.Y)
}
```
`NewPoint` creates a new `*Point` value, `p`. We pass `p` to the `Center` function which moves the point to a position in the center of the screen. Finally we print the values of `p.X` and `p.Y`.
`NewPoint` 创建一个新的 `*Point` 值 `p`。 我们将 `p` 传递给 `Center` 函数,该函数将点移动到屏幕中心的位置。 最后,我们输出 `p.X` 和 `p.Y` 的值。
```bash
% go build -gcflags=-m examples/esc/center.go
# command-line-arguments
examples/esc/center.go:11:6: can inline Center
examples/esc/center.go:18:8: inlining call to Center
examples/esc/center.go:19:13: inlining call to fmt.Println
examples/esc/center.go:11:13: Center p does not escape
examples/esc/center.go:19:15: p.X escapes to heap
examples/esc/center.go:19:20: p.Y escapes to heap
examples/esc/center.go:19:13: io.Writer(os.Stdout) escapes to heap
examples/esc/center.go:17:10: NewPoint new(Point) does not escape
examples/esc/center.go:19:13: NewPoint []interface {} literal does not escape
:1: os.(*File).close .this does not escape
```
即使使用新函数分配了 `p`,也不会将其存储在堆中,因为没有引用 `p` 会逸出 `Center` 函数。
_问题_: 那第 19 行,如果 `p` 不逃逸,那是什么逃逸到了堆呢?
> 编写一个基准,以规定 `Sum` 不分配。
### 4.3. 内联
在 Go 函数中,调用具有固定的开销;堆栈和抢占检查。
硬件分支预测器可以改善其中的一些功能,但是就功能大小和时钟周期而言,这仍然是一个代价。
内联是避免这些成本的经典优化方法。
直到 Go 1.11 内联仅在 _叶函数_ 上起作用,该函数不会调用另一个函数。这样做的理由是:
- 如果您的函数做了很多工作,那么前导开销将可以忽略不计。这就是为什么功能要达到一定的大小(目前有一些指令,加上一些阻止全部内联的操作,例如,在 Go 1.7 之前进行切换)
- 另一方面,小的功能为执行的相对少量的有用工作支付固定的开销。这些是内联目标的功能,因为它们最大程度地受益。
另一个原因是过多的内联使堆栈跟踪更难遵循。
#### 4.3.1. Inlining (example) {#inlining_example}
```go
func Max(a, b int) int {
if a > b {
return a
}
return b
}
func F() {
const a, b = 100, 20
if Max(a, b) == b {
panic(b)
}
}
```
同样,我们使用 `-gcflags=-m` 标志来查看编译器的优化决策。
```
% go build -gcflags=-m examples/inl/max.go
# command-line-arguments
examples/inl/max.go:4:6: can inline Max
examples/inl/max.go:11:6: can inline F
examples/inl/max.go:13:8: inlining call to Max
examples/inl/max.go:20:6: can inline main
examples/inl/max.go:21:3: inlining call to F
examples/inl/max.go:21:3: inlining call to Max
```
编译器打印了两行。
- 第 3 行中的第一个是 `Max` 的声明,告诉我们可以内联。
- 第二个报告说,`Max` 的主体已在第 12 行内联到调用方中。
> 在不使用 `//go:noinline comment` 的情况下,重写 `Max` 使得它仍然返回正确的答案,但是编译器不再认为它是可内联的。
#### 4.3.2. 内联是什么样的? {#what_does_inlining_look_like}
编译 `max.go`,看看 `F()` 的优化版本是什么。
```bash
% go build -gcflags=-S examples/inl/max.go 2>&1 | grep -A5 '"".F STEXT'
"".F STEXT nosplit size=2 args=0x0 locals=0x0
0x0000 00000 (/Users/dfc/devel/high-performance-go-workshop/examples/inl/max.go:11) TEXT "".F(SB), NOSPLIT|ABIInternal, $0-0
0x0000 00000 (/Users/dfc/devel/high-performance-go-workshop/examples/inl/max.go:11) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (/Users/dfc/devel/high-performance-go-workshop/examples/inl/max.go:11) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (/Users/dfc/devel/high-performance-go-workshop/examples/inl/max.go:11) FUNCDATA $3, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (/Users/dfc/devel/high-performance-go-workshop/examples/inl/max.go:13) PCDATA $2, $0
```
一旦将 `Max` 内联到其中,它就是 `F` 的主体, 此功能没有任何反应。 我知道屏幕上有很多文本,但是什么也没说,但请您相信,唯一发生的是 `RET`。 实际上,F 变为:
```go
func F() {
return
}
```
> `-S` 的输出不是二进制文件中的最终机器代码。链接器在最终链接阶段进行一些处理。像 `FUNCDATA` 和 `PCDATA` 这样的行是垃圾收集器的元数据,它们在链接时会移到其他位置。如果您正在读取 `-S` 的输出,则只需忽略 `FUNCDATA` 和 `PCDATA` 行;它们不是最终二进制文件的一部分。
#### 4.3.3. 讨论
为什么在 `F()` 中声明 `a` 和 `b` 为常数?
实验输出以下内容:如果将 a 和 b 声明为变量,会发生什么? 如果 `a` 和 `b` 作为参数传递给 `F()` 会怎样?
> `-gcflags=-S` 不会阻止在您的工作目录中构建最终的二进制文件。如果发现随后的 `go build …` 运行没有输出,请删除工作目录中的 `./max` 二进制文件。
#### 4.3.4. 调整内联级别
调整 _内联级别_ 是通过 `-gcflags = -l` 标志执行的。有些令人困惑的传递单个 `-l` 将禁用内联,而两个或多个将启用更激进的设置的内联。
- `-gcflags=-l`, 禁用内联.
- 没有,正常内联。
- `-gcflags='-l -l'` 内联级别 2,更具攻击性,可能更快,可能会生成更大的二进制文件。
- `-gcflags='-l -l -l'` 内联 3 级,再次更具攻击性,二进制文件肯定更大,也许再次更快,但也可能有问题。
- `-gcflags=-l=4` Go 1.11 中的(四个 `-l`)将启用实验性 [mid stack inlining optimisation](https://github.com/golang/go/issues/19348#issuecomment-393654429)。我相信从 Go 1.12 开始它没有任何作用。
#### 4.3.5. 中栈内联
由于 Go 1.12 已启用所谓的 _中栈_ 内联(以前在 Go 1.11 中的预览中带有 `-gcflags ='-l -l -l -l'` 标志)。
我们可以在前面的示例中看到中栈内联的示例。在 Go 1.11 和更早的版本中,`F` 不会是叶子函数,它称为 `max`。但是由于内联的改进,现在将 `F` 内联到其调用方中。这有两个原因。当将 `max` 内联到 `F` 中时,`F` 不包含其他函数调用,因此,如果未超过其复杂性预算,它将成为潜在的 `叶函数`。由于 `F` 是一个简单的函数,内联和消除死代码消除了许多复杂性预算-它有资格进行 _中栈_ 内联,而与调用`max`无关。
> 中栈内联可用于内联函数的快速路径,从而消除了快速路径中的函数调用开销。[最近进入 Go 1.13 的 CL](https://go-review.googlesource.com/c/go/+/152698) 显示了此技术应用于 `sync.RWMutex.Unlock()`。
### 4.4. 消除无效代码
为什么 `a` 和 `b` 是常量很重要?
要了解发生了什么,让我们看一下编译器将其 `Max` 内联到 `F` 中后看到的内容。我们很难从编译器中获得此信息,但是直接手动完成是很简单的。
Before:
```go
func Max(a, b int) int {
if a > b {
return a
}
return b
}
func F() {
const a, b = 100, 20
if Max(a, b) == b {
panic(b)
}
}
```
After:
```go
func F() {
const a, b = 100, 20
var result int
if a > b {
result = a
} else {
result = b
}
if result == b {
panic(b)
}
}
```
因为 `a` 和 `b` 是常量,所以编译器可以在编译时证明该分支永远不会为假。`100` 始终大于 `20`。 因此,编译器可以进一步优化 `F` 以
```go
func F() {
const a, b = 100, 20
var result int
if true {
result = a
} else {
result = b
}
if result == b {
panic(b)
}
}
```
现在已经知道了分支的结果,那么 `result` 的内容也就知道了。这就是 _消除分支_.
```go
func F() {
const a, b = 100, 20
const result = a
if result == b {
panic(b)
}
}
```
现在消除了分支,我们知道 `result` 总是等于 `a`,并且因为 `a` 是常数,所以我们知道 `result` 是常数。编译器将此证明应用于第二个分支
```go
func F() {
const a, b = 100, 20
const result = a
if false {
panic(b)
}
}
```
再次使用分支消除,最终形式为 `F`。
```go
func F() {
const a, b = 100, 20
const result = a
}
```
最后就是
```go
func F() {
}
```
#### 4.4.1. 消除无效代码(续){#dead_code_elimination_cont}
分支消除是称为 _无效代码消除_ 的优化类别之一。实际上,使用静态证明来显示,段代码是永远无法访问的,俗称 _无效_,因此不需要在最终二进制文件中对其进行编译,优化或发出。
我们看到了无效代码消除如何与内联一起工作,以减少通过删除证明无法访问的循环和分支而减少的代码量。
您可以利用此优势实施昂贵的调试,并将其隐藏
```go
const debug = false
```
与构建标签结合使用,这可能非常有用。
#### 4.4.2. 进一步阅读
- [Using // +build to switch between debug and release builds](https://dave.cheney.net/2014/09/28/using-build-to-switch-between-debug-and-release)
- [How to use conditional compilation with the go build tool](https://dave.cheney.net/2013/10/12/how-to-use-conditional-compilation-with-the-go-build-tool)
### 4.5. 编译器标识练习
```bash
% go build -gcflags=$FLAGS
```
研究以下编译器功能的操作:
- `-S` 打印正在编译的程序包的 (Go 风格) 程序集。
- `-l` 控制内联的行为; `-l` 禁用内联,`-l -l` 增加内联(更多 `-l` 增加编译器对内联代码的需求)。尝试编译时间,程序大小和运行时间的差异。
- `-m` 控制诸如内联,转义分析之类的优化决策的打印。`-m -m` 打印有关编译器思想的更多详细信息。
- `-l -N` 禁用所有优化。
> 如果发现随后的 `go build …` 运行没有输出,请删除工作目录中的 `./max` 二进制文件。
#### 4.5.1 进一步阅读
- [Codegen Inspection by Jaana Burcu Dogan](https://go-talks.appspot.com/github.com/rakyll/talks/gcinspect/talk.slide#1)
### 4.6. 边界检查消除 {#bounds_check_elimination}
Go 是一种边界检查语言。这意味着将检查数组和切片下标操作,以确保它们在相应类型的范围内。
对于数组,这可以在编译时完成。对于切片,这必须在运行时完成。
```go
var v = make([]int, 9)
var A, B, C, D, E, F, G, H, I int
func BenchmarkBoundsCheckInOrder(b *testing.B) {
for n := 0; n < b.N; n++ {
A = v[0]
B = v[1]
C = v[2]
D = v[3]
E = v[4]
F = v[5]
G = v[6]
H = v[7]
I = v[8]
}
}
```
> 使用 `-gcflags=-S` 来拆解 `BenchmarkBoundsCheckInOrder`。每个循环执行多少个边界检查操作?
```go
func BenchmarkBoundsCheckOutOfOrder(b *testing.B) {
for n := 0; n < b.N; n++ {
I = v[8]
A = v[0]
B = v[1]
C = v[2]
D = v[3]
E = v[4]
F = v[5]
G = v[6]
H = v[7]
}
}
```
重新安排我们通过 `I` 分配 `A` 的顺序是否会影响装配。分解 `BenchmarkBoundsCheckOutOfOrder` 并找出。
#### 4.6.1. 练习
- 重新排列下标操作的顺序是否会影响函数的大小?它会影响功能的速度吗?
- 如果将 `v` 移入 `基准` 函数内部会怎样?
- 如果 `v` 被声明为数组,`var v [9] int` 会发生什么?
## 5. 执行追踪器 {#execution-tracer}
执行跟踪程序是由 [Dmitry Vyukov](https://github.com/dvyukov) 为 Go 1.5 开发的,并且仍处于记录和使用状态,已有好几年了。
与基于样本的分析不同,执行跟踪器集成到 `Go` 运行时中,因此它只知道 Go 程 序在特定时间点正在做什么,但是 _为什么_。
### 5.1. 什么是执行跟踪器,为什么需要它?
我认为,通过查看一段代码 `go tool pprof` 的效果不好,可以最容易地解释执行跟踪器的功能,以及为什么这样做很重要。
`examples/mandelbrot` 目录包含一个简单的 `mandelbrot` 生成器。该代码来自 [Francesc Campoy’s mandelbrot package](https://github.com/campoy/mandelbrot)。
```bash
% cd examples/mandelbrot
% go build && ./mandelbrot
```
如果我们构建它,然后运行它,它将生成如下内容

#### 5.1.1. 多久时间?
那么,此程序需要多长时间才能生成 `1024 * 1024` 像素的图像?
我知道如何执行此操作的最简单方法是使用 `time(1)` 之类的东西。
```bash
% time ./mandelbrot
real 0m1.654s
user 0m1.630s
sys 0m0.015s
```
> 不要使用 `time go run mandebrot.go`,否则您将花费 _编译_ 程序以及运行该程序所需的时间。
#### 5.1.2. 该程序在做什么?
在此示例中,程序花费了 `1.6` 秒来生成 `mandelbrot` 并写入 `png`。
这样好吗?我们可以加快速度吗?
回答该问题的一种方法是使用 `Go` 内置的 `pprof` 来分析程序。
让我们尝试一下。
### 5.2. 生成性能分析
要生成性能分析,我们需要
1. 直接使用 `runtime/pprof` 软件包。
2. 使用类似 `github.com/pkg/profile` 的包装器自动执行此操作。
### 5.3. 使用 runtime/pprof 生成性能分析
为了告诉您我没有使用黑科技(魔法),让我们修改程序以将 `CPU` 性能分析写入 `os.Stdout`。
```go
import "runtime/pprof"
func main() {
pprof.StartCPUProfile(os.Stdout)
defer pprof.StopCPUProfile()
```
By adding this code to the top of the `main` function, this program will write a profile to `os.Stdout`.
通过将此代码添加到 `main` 函数的顶部,该程序会将配置文件写入 `os.Stdout`。
```bash
% cd examples/mandelbrot-runtime-pprof
% go run mandelbrot.go > cpu.pprof
```
> 在这种情况下,我们可以使用 `go run`,因为 cpu 配置文件将仅包含 `mandelbrot.go` 的执行,而不包括其编译。
#### 5.3.1. 使用 github.com/pkg/profile 生成性能分析
上一张幻灯片显示了一种生成配置文件的超级简便的方法,但是存在一些问题。
- 如果您忘记了将输出重定向到文件,则会破坏该终端会话。😞(提示:`reset(1)` 是您的朋友)
- 如果您向 `os.Stdout` 中写入其他内容 (例如,`fmt.Println`),则会破坏跟踪。
推荐使用 `runtime/pprof` 的方法是 [将跟踪信息写入文件](https://godoc.org/runtime/pprof#hdr-Profiling_a_Go_program)。 但是,您必须确保跟踪已停止,并且在程序停止之前 (包括有人 `^C`) 关闭了文件。
因此,几年前,我写了一个 [package](https://godoc.org/github.gom/pkg/profile) 来处理它。
```go
import "github.com/pkg/profile"
func main() {
defer profile.Start(profile.CPUProfile, profile.ProfilePath(".")).Stop()
```
如果运行此版本,则将配置文件写入当前工作目录
```bash
% go run mandelbrot.go
2017/09/17 12:22:06 profile: cpu profiling enabled, cpu.pprof
2017/09/17 12:22:08 profile: cpu profiling disabled, cpu.pprof
```
> 使用 `pkg/profile` 不是强制性的,但是它会处理收集和记录跟踪信息的许多样板,因此我们将在本讲习班的其余部分中使用它。
#### 5.3.2. 分析性能
现在我们有了一个性能分析,我们可以使用 `go tool pprof` 对其进行分析。
```bash
% go tool pprof -http=:8080 cpu.pprof
```
在此运行中,我们看到程序运行了 1.81 秒 (分析增加了少量开销)。我们还可以看到 pprof 仅捕获了 1.53 秒的数据,因为 `pprof` 基于示例,它依赖于操作系统的 `SIGPROF` 计时器。
> 从 1.9 开始,`pprof` 跟踪包含分析跟踪所需的所有信息。您不再需要生成跟踪的匹配二进制文件。🎉
我们可以使用 `top` pprof 函数对跟踪记录的函数进行排序
```bash
% go tool pprof cpu.pprof
Type: cpu
Time: Mar 24, 2019 at 5:18pm (CET)
Duration: 2.16s, Total samples = 1.91s (88.51%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 1.90s, 99.48% of 1.91s total
Showing top 10 nodes out of 35
flat flat% sum% cum cum%
0.82s 42.93% 42.93% 1.63s 85.34% main.fillPixel
0.81s 42.41% 85.34% 0.81s 42.41% main.paint
0.11s 5.76% 91.10% 0.12s 6.28% runtime.mallocgc
0.04s 2.09% 93.19% 0.04s 2.09% runtime.memmove
0.04s 2.09% 95.29% 0.04s 2.09% runtime.nanotime
0.03s 1.57% 96.86% 0.03s 1.57% runtime.pthread_cond_signal
0.02s 1.05% 97.91% 0.04s 2.09% compress/flate.(*compressor).deflate
0.01s 0.52% 98.43% 0.01s 0.52% compress/flate.(*compressor).findMatch
0.01s 0.52% 98.95% 0.01s 0.52% compress/flate.hash4
0.01s 0.52% 99.48% 0.01s 0.52% image/png.filter
```
我们看到,当 `pprof` 捕获堆栈时,`main.fillPixel` 函数在 `CPU` 上的数量最多。
在堆栈上找到 `main.paint` 并不奇怪,这就是程序的作用。它绘制像素。但是,是什么导致 `paint` 花费大量时间呢? 我们可以通过将 _cummulative_ 标志设置为 `top` 来进行检查。
```bash
(pprof) top --cum
Showing nodes accounting for 1630ms, 85.34% of 1910ms total
Showing top 10 nodes out of 35
flat flat% sum% cum cum%
0 0% 0% 1840ms 96.34% main.main
0 0% 0% 1840ms 96.34% runtime.main
820ms 42.93% 42.93% 1630ms 85.34% main.fillPixel
0 0% 42.93% 1630ms 85.34% main.seqFillImg
810ms 42.41% 85.34% 810ms 42.41% main.paint
0 0% 85.34% 210ms 10.99% image/png.(*Encoder).Encode
0 0% 85.34% 210ms 10.99% image/png.Encode
0 0% 85.34% 160ms 8.38% main.(*img).At
0 0% 85.34% 160ms 8.38% runtime.convT2Inoptr
0 0% 85.34% 150ms 7.85% image/png.(*encoder).writeIDATs
```
这暗示着 `main.fillPixed` 实际上正在完成大部分工作。
> 您也可以使用 `web` 命令来形象化配置文件,如下所示:
>
> 
### 5.4. 跟踪和性能分析
希望此示例显示了分析的局限性。性能分析告诉我们探查器看到的内容;`fillPixel` 正在完成所有工作。似乎没有很多事情可以做。
因此,现在是引入执行跟踪程序的好时机,该跟踪程序可以为同一程序提供不同的视图。
#### 5.4.1. 使用执行跟踪器
使用跟踪程序就只需要改变为 `profile.TraceProfile` 即可。
```go
import "github.com/pkg/profile"
func main() {
defer profile.Start(profile.TraceProfile, profile.ProfilePath(".")).Stop()
```
当我们运行程序时,我们在当前工作目录中得到一个 `trace.out` 文件。
```bash
% go build mandelbrot.go
% time ./mandelbrot
2017/09/17 13:19:10 profile: trace enabled, trace.out
2017/09/17 13:19:12 profile: trace disabled, trace.out
real 0m1.740s
user 0m1.707s
sys 0m0.020s
```
就像 `pprof` 一样,`go` 命令中有一个工具可以分析跟踪。
```bash
% go tool trace trace.out
2017/09/17 12:41:39 Parsing trace...
2017/09/17 12:41:40 Serializing trace...
2017/09/17 12:41:40 Splitting trace...
2017/09/17 12:41:40 Opening browser. Trace viewer s listening on http://127.0.0.1:57842
```
这个工具和 `go tool pprof` 有点不同。执行跟踪器正在重用 `Chrome` 内置的许多配置文件可视化基础结构,因此 `go tool trace` 充当服务器将原始执行跟踪转换为 Chome 可以本地显示的数据。
#### 5.4.2. 分析追踪
从跟踪中我们可以看到该程序仅使用一个 cpu。
```go
func seqFillImg(m *img) {
for i, row := range m.m {
for j := range row {
fillPixel(m, i, j)
}
}
}
```
这并不奇怪,默认情况下,`mandelbrot.go` 会按顺序为每一行中的每个像素调用 `fillPixel`。
绘制完图像后,查看执行切换为写入 `.png` 文件。这会在堆上生成垃圾,因此跟踪在那时发生了变化,我们可以看到垃圾收集堆的经典锯齿模式。
跟踪性能分析可提供低至 _毫秒_ 级别的时序分辨率。 这是您使用外部性能分析无法获得的。
> 在继续之前,我们需要谈谈跟踪工具的用法。
>
> - 抱歉,该工具使用 `Chrome` 内置的 `javascript` 调试支持。跟踪配置文件只能在 `Chrome` 中查看,而不能在 `Firefox, Safari, IE/Edge` 中使用。
> - 因为这是 Google 产品,所以它支持键盘快捷键。使用 `WASD` 导航,使用 `?` 获取列表。
> - 查看追踪可能会占用大量内存。 认真地说,4Gb 不会削减它,8Gb 可能是最小值,更多肯定更好。
> - 如果您是从 Fedora 之类的 OS 发行版中安装 Go 的,则跟踪查看器的支持文件可能不是主 `golang` deb/rpm 的一部分,它们可能位于某些 `-extra` 软件包中。
### 5.5. 使用多个 CPU
从前面的跟踪中我们可以看到程序正在按顺序运行,并且没有利用该计算机上的其他 CPU。
Mandelbrot 的生成称为 _embarassingly_parallel_ 。每个像素彼此独立,都可以并行计算。所以,让我们尝试一下。
```bash
% go build mandelbrot.go
% time ./mandelbrot -mode px
2017/09/17 13:19:48 profile: trace enabled, trace.out
2017/09/17 13:19:50 profile: trace disabled, trace.out
real 0m1.764s
user 0m4.031s
sys 0m0.865s
```
因此,运行时间基本上是相同的。我们使用了所有 CPU,因此有更多的用户时间,这是有道理的,但是实 际(挂钟) 时间大致相同。
让我们看一下追踪。
如您所见,此跟踪生成了 _更多_ 的数据。
- 似乎需要完成很多工作,但是如果您放大放大,就会发现差距。据信这是调度程序。
- 虽然我们使用所有四个内核,但是由于每个 `fillPixel` 的工作量相对较小,因此我们在调度开销方面花费了大量时间。
### 5.6. 整理工作
每个像素使用一个 `goroutine` 太细粒度。没有足够的工作来证明 `goroutine` 的成本合理。
相反,让我们尝试为每个 `goroutine` 处理一行。
```bash
% go build mandelbrot.go
% time ./mandelbrot -mode row
2017/09/17 13:41:55 profile: trace enabled, trace.out
2017/09/17 13:41:55 profile: trace disabled, trace.out
real 0m0.764s
user 0m1.907s
sys 0m0.025s
```
这看起来是一个不错的改进,我们几乎将程序的运行时间减少了一半。 让我们看一下痕迹。
如您所见,轨迹现在更小,更易于使用。我们可以看到跨度的整个轨迹,这是一个不错的奖励。
- 在程序开始时,我们看到 `goroutine` 的数量大约为 `1000` 这是对上一条跟踪中看到的 `1 << 20` 的改进。
- 放大后,我们看到 `onePerRowFillImg` 运行时间更长,并且由于 `goroutine` _生产_ 工作尽早完成,调度程序有效地处理了其余可运行的 `goroutine`。
### 5.7. 使用 workers
`mandelbrot.go` 支持另一种模式,请尝试一下
```bash
% go build mandelbrot.go
% time ./mandelbrot -mode workers
2017/09/17 13:49:46 profile: trace enabled, trace.out
2017/09/17 13:49:50 profile: trace disabled, trace.out
real 0m4.207s
user 0m4.459s
sys 0m1.284s
```
因此,运行时比以前任何时候都差。让我们看一下追踪,看看是否可以弄清楚发生了什么。
观察痕迹,您会发现只有一个 worker 处理器,生产者和消费者往往会轮换,因为只有一个 worker 处理器和一个消费者。 让我们增加 worker 处理器数量
```bash
% go build mandelbrot.go
% time ./mandelbrot -mode workers -workers 4
2017/09/17 13:52:51 profile: trace enabled, trace.out
2017/09/17 13:52:57 profile: trace disabled, trace.out
real 0m5.528s
user 0m7.307s
sys 0m4.311s
```
这样就更糟了! 更多实时,更多 CPU 时间。让我们看一下追踪,看看发生了什么。
那条痕迹是一团糟。 有更多的 worker 处理器可用,但是似乎所有的时间都花在处理器执行上。
这是因为通道是 _无缓存的_。只有在有人准备接收之前,无缓冲的通道才能发送。
- 在没有 worker 处理器准备接收之前,生产者无法发送作品。
- worker 处理器要等到有人准备派遣后才能接受工作,因此他们在等待时会互相竞争。
- 发送者没有特权,它不能比已经运行的工作者享有优先权。
我们在这里看到的是无缓冲通道带来的大量延迟。调度程序内部有很多停止和启动,并且在等待工作时可能会锁定和互斥,这就是为什么我们看到 sys 时间更长的原因。
### 5.8. 使用缓冲通道
```go
import "github.com/pkg/profile"
func main() {
defer profile.Start(profile.TraceProfile, profile.ProfilePath(".")).Stop()
```
```bash
% go build mandelbrot.go
% time ./mandelbrot -mode workers -workers 4
2017/09/17 14:23:56 profile: trace enabled, trace.out
2017/09/17 14:23:57 profile: trace disabled, trace.out
real 0m0.905s
user 0m2.150s
sys 0m0.121s
```
这与上面的每行模式非常接近。
使用缓冲的通道,跟踪显示出:
- 生产者不必等待 worker 处理器的到来,它可以迅速填补渠道。
- worker 处理器可以快速从通道中取出下一个物品,而无需休眠等待生产。
使用这种方法,我们使用通道进行每个像素的工作传递的速度几乎与之前在每行 `goroutine` 上进行调度的速度相同。
修改 `nWorkersFillImg` 以每行工作。计时结果并分析轨迹。
### 5.9. Mandelbrot 微服务
在 2019 年,除非您可以将 Internet 作为无服务器微服务提供,否则生成 Mandelbrots 毫无意义。 因此,我向您介绍 _Mandelweb_
```bash
% go run examples/mandelweb/mandelweb.go
2017/09/17 15:29:21 listening on http://127.0.0.1:8080/
```
[http://127.0.0.1:8080/mandelbrot](http://127.0.0.1:8080/mandelbrot)
#### 5.9.1\. 跟踪正在运行的应用程序
在前面的示例中,我们对整个程序进行了跟踪。
如您所见,即使在很短的时间内,跟踪也可能非常大,因此,连续收集跟踪数据将产生太多的数据。同样,跟踪可能会影响程序的速度,特别是在活动很多的情况下。
我们想要的是一种从正在运行的程序中收集简短跟踪的方法。
幸运的是,`net/http/pprof` 软件包具有这样的功能。
#### 5.9.2. 通过 http 收集跟踪
希望每个人都知道 `net/http/pprof` 软件包。
```go
import _ "net/http/pprof"
```
导入后,`net/http/pprof` 将向 `http.DefaultServeMux` 注册跟踪和分析路由。从 Go 1.5 开始,这包括跟踪分析器。
> `net/http/pprof` 向 `http.DefaultServeMux` 注册。如果您隐式或显式地使用该 `ServeMux`,则可能会无意间将 `pprof` 端点公开到 `Internet`。这可能导致源代码泄露。您可能不想这样做。
我们可以使用 `curl`(或`wget`)从 mandelweb 中获取五秒钟的跟踪记录
```bash
% curl -o trace.out http://127.0.0.1:8080/debug/pprof/trace?seconds=5
```
#### 5.9.3. 产生一些负载
前面的示例很有趣,但是根据定义,空闲的 Web 服务器没有性能问题。我们需要产生一些负载。为此,我使用的是 [`hey` by JBD](https://github.com/rakyll/hey)。
```bash
% go get -u github.com/rakyll/hey
```
让我们从每秒一个请求开始。
```bash
% hey -c 1 -n 1000 -q 1 http://127.0.0.1:8080/mandelbrot
```
然后运行,在另一个窗口中收集跟踪
```bash
% curl -o trace.out http://127.0.0.1:8080/debug/pprof/trace?seconds=5
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 66169 0 66169 0 0 13233 0 --:--:-- 0:00:05 --:--:-- 17390
% go tool trace trace.out
2017/09/17 16:09:30 Parsing trace...
2017/09/17 16:09:30 Serializing trace...
2017/09/17 16:09:30 Splitting trace...
2017/09/17 16:09:30 Opening browser.
Trace viewer is listening on http://127.0.0.1:60301
```
#### 5.9.4. 模拟过载
让我们将速率提高到每秒 5 个请求。
```bash
% hey -c 5 -n 1000 -q 5 http://127.0.0.1:8080/mandelbrot
```
然后运行,在另一个窗口中收集跟踪
```bash
% curl -o trace.out http://127.0.0.1:8080/debug/pprof/trace?seconds=5
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 66169 0 66169 0 0 13233 0 --:--:-- 0:00:05 --:--:-- 17390
% go tool trace trace.out
2017/09/17 16:09:30 Parsing trace...
2017/09/17 16:09:30 Serializing trace...
2017/09/17 16:09:30 Splitting trace...
2017/09/17 16:09:30 Opening browser. Trace viewer is listening on http://127.0.0.1:60301
```
#### 5.9.5. 额外的信誉,Eratosthenes 的筛子
[concurrent prime sieve](https://github.com/golang/go/blob/master/doc/play/sieve.go) 是最早编写的 Go 程序之一。
Ivan Daniluk [撰写了一篇关于可视化的很棒的文章](https://divan.github.io/posts/go_concurrency_visualize/)。
让我们看一下使用执行跟踪器的操作。
#### 5.9.6. 更多资源
- Rhys Hiltner, [Go’s execution tracer](https://www.youtube.com/watch?v=mmqDlbWk_XA) (dotGo 2016)
- Rhys Hiltner, [An Introduction to "go tool trace"](https://www.youtube.com/watch?v=V74JnrGTwKA) (GopherCon 2017)
- Dave Cheney, [Seven ways to profile Go programs](https://www.youtube.com/watch?v=2h_NFBFrciI) (GolangUK 2016)
- Dave Cheney, [High performance Go workshop](https://dave.cheney.net/training#high-performance-go)]
- Ivan Daniluk, [Visualizing Concurrency in Go](https://www.youtube.com/watch?v=KyuFeiG3Y60) (GopherCon 2016)
- Kavya Joshi, [Understanding Channels](https://www.youtube.com/watch?v=KBZlN0izeiY) (GopherCon 2017)
- Francesc Campoy, [Using the Go execution tracer](https://www.youtube.com/watch?v=ySy3sR1LFCQ)
## 6. 内存和垃圾收集器 {#memory-and-gc}
Go 是一种 `gc` 语言。这是设计原则,不会改变。
作为 `gc` 语言,Go 程序的性能通常取决于它们与 `gc` 的交互。
除了选择算法之外,内存消耗是决定应用程序性能和可伸缩性的最重要因素。
本节讨论垃圾收集器的操作,如何测量程序的内存使用情况以及在垃圾收集器性能成为瓶颈的情况下降低内存使用量的策略。
### 6.1. gc 的世界观
任何垃圾收集器的目的都是为了给程序一种幻想,即存在无限数量的可用内存。
您可能不同意此声明,但这是垃圾收集器设计者如何工作的基本假设。
令人震惊的是,就总运行时间而言,标记扫描 `GC` 是最有效的;很好,适用于批处理,模拟等。但是,随着时间的流逝,Go GC 已从纯粹的停止世界收集器转变为并发的非压缩收集器。这是因为 Go GC 专为低延迟服务器和交互式应用程序而设计。
Go GC 的设计倾向于在 _最大吞吐量_ 上 _降低延迟_。它将一些分配成本移到了 mutator 上,以减少以后的清理成本。
### 6.2. 垃圾收集器设计
多年来,Go GC 的设计发生了变化
- Go 1.0, 停止大量基于 `tcmalloc` 的世界标记清除收集器。
- Go 1.3, 完全精确的收集器,不会将堆上的大数字误认为是指针,从而不会浪费内存。
- Go 1.5, 新的 GC 设计,着重于 _吞吐量_ _延迟_。
- Go 1.6, GC 的改进,以较低的延迟处理较大的堆。
- Go 1.7, 较小的 GC 改进,主要是重构。
- Go 1.8, 进一步工作以减少 `STW` 时间,现在已降至 `100` 微秒范围。
- Go 1.10+, [摆脱纯粹的合作 Goroutine 调度](https://github.com/golang/proposal/blob/master/design/24543-non-cooperative-preemption.md) 以降低触发整个GC周期时的延迟。
### 6.3. 垃圾收集器监控
一种获得垃圾收集器工作量的总体思路的简单方法是启用 GC 日志记录的输出。
这些统计信息始终会收集,但通常会被禁止显示,您可以通过设置环境变量 `GODEBUG` 启用它们。
```bash
% env GODEBUG=gctrace=1 godoc -http=:8080
gc 1 @0.012s 2%: 0.026+0.39+0.10 ms clock, 0.21+0.88/0.52/0+0.84 ms cpu, 4->4->0 MB, 5 MB goal, 8 P
gc 2 @0.016s 3%: 0.038+0.41+0.042 ms clock, 0.30+1.2/0.59/0+0.33 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 3 @0.020s 4%: 0.054+0.56+0.054 ms clock, 0.43+1.0/0.59/0+0.43 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 4 @0.025s 4%: 0.043+0.52+0.058 ms clock, 0.34+1.3/0.64/0+0.46 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 5 @0.029s 5%: 0.058+0.64+0.053 ms clock, 0.46+1.3/0.89/0+0.42 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 6 @0.034s 5%: 0.062+0.42+0.050 ms clock, 0.50+1.2/0.63/0+0.40 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 7 @0.038s 6%: 0.057+0.47+0.046 ms clock, 0.46+1.2/0.67/0+0.37 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 8 @0.041s 6%: 0.049+0.42+0.057 ms clock, 0.39+1.1/0.57/0+0.46 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
gc 9 @0.045s 6%: 0.047+0.38+0.042 ms clock, 0.37+0.94/0.61/0+0.33 ms cpu, 4->4->1 MB, 5 MB goal, 8 P
```
跟踪输出给出了GC活性的一般度量。[the `runtime` package documentation](https://golang.org/pkg/runtime/#hdr-Environment_Variables) 中描述了 `gctrace=1` 的输出格式。
DEMO: 显示启用了 `GODEBUG=gctrace=1` 的 `godoc`
> 在生产环境中使用此环境变量,不会对性能产生影响。
当您知道有问题时,使用 `GODEBUG=gctrace=1` 很好,但是对于Go应用程序上的常规遥测,我建议使用 `net/http/pprof` 接口。
```go
import _ "net/http/pprof"
```
导入 `net/http/pprof` 软件包将在 `/debug/pprof` 注册一个具有各种运行时指标的处理程序,包括:
- A list of all the running goroutines, `/debug/pprof/heap?debug=1`.
- A report on the memory allocation statistics, `/debug/pprof/heap?debug=1`.
> `net/http/pprof` 将使用默认的 `http.ServeMux` 注册自己。
>
> 请小心,因为如果您使用 `http.ListenAndServe(address, nil)`,这将是可见的。
DEMO: `godoc -http=:8080`, 会显示 `/debug/pprof`。
#### 6.3.1. 垃圾收集器调整
Go 运行时提供了一个用于调整 GC 的环境变量 `GOGC`。
GOGC 的公式是
$$
goal = reachabl\e * (1 + (GOGC)/100)
$$
例如,如果我们当前有一个256MB的堆,并且 `GOGC=100` (默认值),当堆填满时,它将增长到
$$
512MB = 256MB * (1 + 100/100)
$$
- `GOGC` 的值大于100会使堆增长更快,从而减轻了 GC 的压力。
- 小于 100 的 `GOGC` 值会导致堆缓慢增长,从而增加了 GC 的压力。
默认值 100 _仅作为参考_。 在使用生产负载对应用程序进行性能分析 _之后,您应该选择自己的值_。
### 6.4. 减少分配
确保您的 API 允许调用方减少生成的垃圾量。
考虑这两种读取方法
```go
func (r *Reader) Read() ([]byte, error)
func (r *Reader) Read(buf []byte) (int, error)
```
第一个 `Read` 方法不带任何参数,并以 `[]byte` 的形式返回一些数据。第二个接收一个 `[]byte` 缓冲区,并返回读取的字节数。
第一个 `Read` 方法将 _始终_ 分配缓冲区,从而给GC带来压力。第二个填充它给定的缓冲区。
您可以在标准库中命名遵循此模式的示例吗?
### 6.5. strings 和 []bytes
在 Go 中,`string` 的值是不可变的,`[]byte` 是可变的。
大多数程序都喜欢使用 `string`,但是大多数 IO 是使用 `[]byte` 来完成的。
尽可能避免将 `[]byte` 转换为字符串,这通常意味着选择一种表示形式,即 `string` 或 `[]byte` 作为值。如果您从网络或磁盘读取数据,通常为 `[]byte`。
[`bytes`](https://golang.org/pkg/bytes/) 包包含许多与 [`strings`](https://golang.org/pkg/strings/) 软件包相同的操作 - `Split`, `Compare`, `HasPrefix`,`Trim` 等。
在底层,`strings` 与 `bytes`包使用相同的汇编原语。
### 6.6\. 使用 `[]byte` 作为 map 的 key
使用 `string` 作为映射键是很常见的,但是通常您会使用 `[]byte`。
编译器针对这种情况实现了特定的优化
```go
var m map[string]string
v, ok := m[string(bytes)]
```
这将避免将字节切片转换为用于映射查找的字符串。这是非常具体的操作,如果您执行以下操作将无法正常工作
```go
key := string(bytes)
val, ok := m[key]
```
让我们看看这是否仍然正确。编写一个基准,比较使用 `[]byte` 作为 `string` 映射键的这两种方法。
### 6.7. 避免字符串连接
转到字符串是不可变的。连接两个字符串会生成第三个字符串。 以下哪项是最快的?
```go
s := request.ID
s += " " + client.Addr().String()
s += " " + time.Now().String()
r = s
```
```go
var b bytes.Buffer
fmt.Fprintf(&b, "%s %v %v", request.ID, client.Addr(), time.Now())
r = b.String()
```
```go
r = fmt.Sprintf("%s %v %v", request.ID, client.Addr(), time.Now())
```
```go
b := make([]byte, 0, 40)
b = append(b, request.ID...)
b = append(b, ' ')
b = append(b, client.Addr().String()...)
b = append(b, ' ')
b = time.Now().AppendFormat(b, "2006-01-02 15:04:05.999999999 -0700 MST")
r = string(b)
```
```go
var b strings.Builder
b.WriteString(request.ID)
b.WriteString(" ")
b.WriteString(client.Addr().String())
b.WriteString(" ")
b.WriteString(time.Now().String())
r = b.String()
```
DEMO: `go test -bench=. ./examples/concat`
### 6.8. 如果长度已知,则预分配片
追加很方便,但是很浪费。
切片通过将多达 1024 个元素加倍而增长,然后增加约 25%。我们再追加一项后,`b` 的容量是多少?
```go
func main() {
b := make([]int, 1024)
b = append(b, 99)
fmt.Println("len:", len(b), "cap:", cap(b))
}
```
如果使用 `append` 模式,则可能会复制大量数据并创建大量垃圾。
如果知道事先知道切片的长度,则可以预先分配目标,以避免复制并确保目标大小正确。
Before
```go
var s []string
for _, v := range fn() {
s = append(s, v)
}
return s
```
After
```go
vals := fn()
s := make([]string, len(vals))
for i, v := range vals {
s[i] = v
}
return s
```
### 6.9. 使用 sync.Pool
`sync` 软件包带有 `sync.Pool` 类型,用于重用公共对象。
`sync.Pool` 没有固定大小或最大容量。您添加到它并从中取出直到发生 `GC`,然后将其无条件清空。这是 [by design](https://groups.google.com/forum/#!searchin/golang-dev/gc-aware/golang-dev/kJ_R6vYVYHU/LjoGriFTYxMJ):
> 如果在垃圾回收之前为时过早而在垃圾回收之后为时过晚,则排空池的正确时间必须在垃圾回收期间。也就是说,池类型的语义必须是它在每个垃圾回收时都消耗掉。— Russ Cox
使用 `sync.Pool`
```go
var pool = sync.Pool{
New: func() interface{} {
return make([]byte, 4096)
},
}
func fn() {
buf := pool.Get().([]byte) // takes from pool or calls New
// do work
pool.Put(buf) // returns buf to the pool
}
```
> `sync.Pool` 不是缓存。它可以并且将在任何时间清空。
>
> 不要将重要项目放在 `sync.Pool` 中,它们将被丢弃。
> Go 1.13 中可能会更改在每个 GC 上清空的 `sync.Pool` 的设计,这将有助于提高其实用性。
>
> > 此 CL 通过引入受害者缓存机制来解决此问题。代替清除池,将删除受害缓存,并将主缓存移至受害缓存。 结果,在稳定状态下,(几乎)没有新分配,但是如果 Pool 使用率下降,对象仍将在两个 GC(而不是一个)中收集。— Austin Clements
>
> [https://go-review.googlesource.com/c/go/+/166961/](https://go-review.googlesource.com/c/go/+/166961/)
### 6.10. 练习
- 使用 `godoc`(或其他程序)观察使用 `GODEBUG=gctrace=1` 改变 `GOGC` 的结果。
- 使用 bytes, string 作为 map key 并检查基准。
- 不同字符串连接策略的基准分配。
## 7. 提示和旅行 {#tips-and-tricks}
随机获取提示和建议
最后一部分包含一些微优化 Go 代码的技巧。
### 7.1. Goroutines
`Goroutines` 是使其非常适合现代硬件的关键功能。
`Goroutines` 易于使用,而且创建成本低廉,您可以将它们视为 _几乎_ 免费。
Go 运行时已针对具有成千上万个 `goroutine` 作为标准的程序而编写,数十万个并不意外。
但是,每个 `goroutine` 确实消耗了 `goroutine` 堆栈的最小内存量,目前至少为2k。
2048 * 1,000,000 个 `goroutines` == 2GB 的内存,他们还没有做任何事情。
可能很多,但未提供应用程序的其他用法。
#### 7.1.1. 知道何时停止 goroutine
Goroutine 的启动方便,运行也很方便,但是在内存占用方面确实有一定的成本。您不能创建无限数量的它们。
每次您在程序中使用`go`关键字启动 `goroutine` 时,您都必须 **知道** 该 `goroutine` 如何以及何时退出。
在您的设计中,某些 `goroutine` 可能会运行直到程序退出。这些 `goroutine` 非常罕见,不会成为规则的例外。
如果您不知道答案,那将是潜在的内存泄漏,因为 `goroutine` 会将其堆栈的内存以及可从堆栈访问的所有堆分配变量固定在堆栈上。
> 切勿在不知道如何停止 `goroutine` 的情况下启动它。
#### 7.1.2. 进一步阅读
- [Concurrency Made Easy](https://www.youtube.com/watch?v=yKQOunhhf4A&index=16&list=PLq2Nv-Sh8EbZEjZdPLaQt1qh_ohZFMDj8) (video)
- [Concurrency Made Easy](https://dave.cheney.net/paste/concurrency-made-easy.pdf) (slides)
- [Never start a goroutine without knowning when it will stop](https://dave.cheney.net/practical-go/presentations/qcon-china.html#_never_start_a_goroutine_without_knowning_when_it_will_stop) (Practical Go, QCon Shanghai 2018)
### 7.2. Go 对某些请求使用有效的网络轮询
Go 运行时使用有效的操作系统轮询机制(kqueue,epoll,windows IOCP等)处理网络IO。一个单一的操作系统线程将为许多等待的 goroutine 提供服务。
但是,对于本地文件 `IO`,Go 不会实现任何 `IO` 轮询。 `*os.File` 上的每个操作在进行中都会消耗一个操作系统线程。
大量使用本地文件 `IO` 可能会导致您的程序产生数百或数千个线程。可能超出您的操作系统所允许的范围。
您的磁盘子系统不希望能够处理成百上千的并发 `IO` 请求。
>
> 要限制并发阻塞 `IO` 的数量,请使用工作程序 `goroutine` 池或缓冲通道作为信号灯。
>
> ```go
> var semaphore = make(chan struct{}, 10)
>
> func processRequest(work *Work) {
> semaphore <- struct{}{} // acquire semaphore
> // process request
> <-semaphore // release semaphore
> }
> ```
### 7.3. 注意您的应用程序中的 IO multipliers
如果您正在编写服务器进程,那么它的主要工作是多路复用通过网络连接的客户端和存储在应用程序中的数据。
大多数服务器程序接受请求,进行一些处理,然后返回结果。这听起来很简单,但是根据结果,它可能会使客户端消耗服务器上大量(可能是无限制的)资源。 这里有一些注意事项:
- 每个传入请求的 IO 请求数量;单个客户端请求生成多少个IO事件?它可能平均为 1,或者如果从缓存中提供了许多请求,则可能小于一个。
- 服务查询所需的读取量;它是固定的,N + 1还是线性的(读取整个表以生成结果的最后一页)。
相对而言,如果内存很慢,那么IO太慢了,您应该不惜一切代价避免这样做。最重要的是,避免在请求的上下文中进行IO,不要让用户等待您的磁盘子系统写入磁盘甚至读取磁盘。
### 7.4. 使用流式 IO 接口
尽可能避免将数据读取到 `[]byte` 中并将其传递。
根据请求,您可能最终将兆字节(或更多!)的数据读取到内存中。这给 GC 带来了巨大压力,这将增加应用程序的平均延迟。
而是使用 `io.Reader` 和 `io.Writer` 来构造处理管道,以限制每个请求使用的内存量。
为了提高效率,如果您使用大量的 `io.Copy`,请考虑实现 `io.ReaderFrom`/`io.WriterTo`。 这些接口效率更高,并且避免将内存复制到临时缓冲区中。
### 7.5. 超时, 超时, 超时
在不知道所需的最长时间之前,切勿启动 IO 操作。
您需要使用 `SetDeadline`, `SetReadDeadline`, `SetWriteDeadline` 对每个网络请求设置超时。
### 7.6. defer 消耗很大,还是?
`defer` 消耗很高,因为它必须记录下 `defer` 的论点。
```go
defer mu.Unlock()
```
相当于
```go
defer func() {
mu.Unlock()
}()
```
如果完成的工作量很小,则 `defer` 会很昂贵,经典的例子是 `defer` 围绕结构变量或映射查找进行互斥解锁。在这种情况下,您可以选择避免 `defer`。
在这种情况下,为了获得性能而牺牲了可读性和维护性。
始终重新审视这些决定。
### 7.7. 避免 Finalisers
Finalisation 是一种将行为附加到即将被垃圾回收的对象的技术。
因此,最终确定是不确定的。
要运行 `finalizer`,该对象不得通过任何物体到达。 如果您不小心在地图上保留了对该对象的引用,则该对象不会被最终确定。
`finalizer` 是 gc 周期的一部分,这意味着它们何时运行将是不可预测的,并且与减少 gc 操作的目标相矛盾。
如果堆很大并且已调整应用程序以创建最少的垃圾,则 `finalizer` 可能不会运行很长时间。
### 7.8. 减少 cgo
cgo 允许 Go 程序调用 C 库。
C 代码和 Go 代码生活在两个不同的世界中,cgo 穿越了它们之间的边界。
这种转换不是免费的,并且取决于它在代码中的位置,其成本可能很高。
cgo 调用类似于阻塞 IO,它们在操作期间消耗线程。
不要在紧密循环中调用 C 代码。
#### 7.8.1. 其实,也许避免 cgo
cgo 的开销很高。
为了获得最佳性能,我建议您在应用程序中避免使用 cgo。
- 如果C代码花费很长时间,则 cgo 开销并不重要。
- 如果您使用 cgo 调用非常短的 C 函数(其开销最明显),请在 Go 中重写该代码 - 根据定义,这很短。
- 如果您在紧密的循环中使用了大量昂贵的 C 代码,那么为什么要使用 Go?
是否有人使用 cgo 频繁调用昂贵的 C 代码?
##### 进一步阅读
- [cgo is not Go](https://dave.cheney.net/2016/01/18/cgo-is-not-go)
### 7.9. 始终使用最新发布的Go版本
旧版本的 Go 永远不会变得更好。他们将永远不会得到错误修复或优化。
- Go 1.4 不应该使用。
- Go 1.5 和 1.6 编译器速度较慢,但生成的代码更快,GC更快。
- Go 1.7 与 1.6 相比,编译速度提高了约 30%,链接速度提高了 2 倍(比任何以前的Go版本都要好)。
- Go 1.8 (此时)将提供较小的编译速度改进,但非英特尔架构的代码质量将得到显着改进。
- Go 1.9-1.12 继续提高所生成代码的性能,修复错误,并改善内联和改进调试。
> 旧版本的Go没有更新。**请勿使用**。使用最新版本,您将获得最佳性能。
#### 7.9.1. 进一步阅读
- [Go 1.7 toolchain improvements](https://dave.cheney.net/2016/04/02/go-1-7-toolchain-improvements)
- [Go 1.8 performance improvements](https://dave.cheney.net/2016/09/18/go-1-8-performance-improvements-one-month-in)
#### 7.9.2. 将热点字段移动到 struct 顶部
### 7.10. 讨论
Any questions?
## 8. 最后的问题和结论 {#conclusion}
> 可读意味着可靠 — Rob Pike
从最简单的代码开始。
_测量_。 分析您的代码以识别瓶颈,_请不要猜测_。
如果性能良好,请 _停止_。您无需优化所有内容,只需优化代码中最热的部分。
随着应用程序的增长或流量模式的发展,性能热点将发生变化。
不要留下对性能不重要的复杂代码,如果瓶颈转移到其他地方,请使用更简单的操作将其重写。
始终编写最简单的代码,编译器针对 _正规_ 代码进行了优化。
较短的代码是较快的代码; Go 不是 C++,不要指望编译器能够解开复杂的抽象。
代码越短,代码 _越小_;这对于CPU的缓存很重要。
非常注意分配,尽可能避免不必要的分配。
> 如果事情不一定正确,我可以将事情做得很快。— Russ Cox
性能和可靠性同样重要。
我认为制作一个非常快速的服务器但是却定期 panics,死锁或 OOM 毫无价值。
不要为了可靠性而牺牲性能。