# Gortex
### Code graph and intelligence engine that indexes repositories
#### and exposes it via CLI, MCP Server, and web UI.
---
[](https://github.com/zzet/gortex/actions/workflows/ci.yml)
[](https://goreportcard.com/report/github.com/zzet/gortex)
[](https://github.com/zzet/gortex/releases/latest)
[](https://pkg.go.dev/github.com/zzet/gortex)
[](https://scorecard.dev/viewer/?uri=github.com/zzet/gortex)
[](docs/installation.md#verifying-releases-supply-chain-security)
[](https://slsa.dev/spec/v1.0/levels#build-l3)
[](https://www.virustotal.com/gui/url/00e1094b39c9bd7db4d5a179b1d56173f85c915075057fd3cc64bfbb9b735b11/detection)
[](#)
[](#)
[](#)
[](#)
[](#)
[](#)
[](#)
[](#)
Drastically reduce tokens usage (**up to 50× fewer tokens per response**, check [benchmarks](BENCHMARK.md) or reproduce yourself.
Built for 15 AI coding agents (Claude Code, Kiro, Cursor, Windsurf, VS Code (and [VS Code Plugin](https://marketplace.visualstudio.com/items?itemName=Gortex.gortex)) / Copilot, Continue.dev, Cline, OpenCode, Antigravity, Codex CLI, Gemini CLI, Zed, Aider, Kilo Code, OpenClaw). See [docs/agents.md](docs/agents.md) for the adapter matrix, per-agent schema notes, and the `gortex init --agents=` CLI contract.
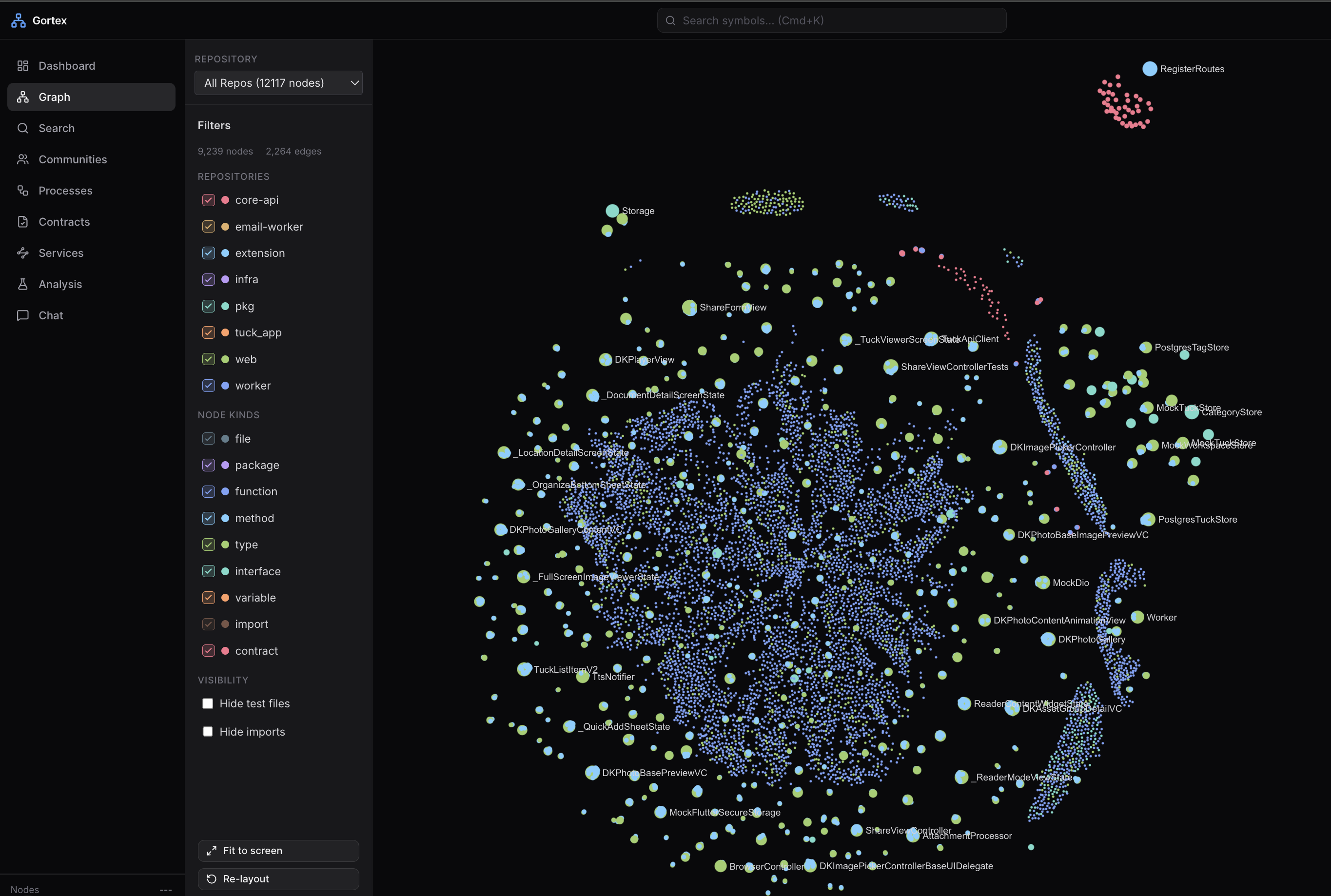
Gortex Web UI — force-directed knowledge graph visualization
## Installation
```bash
# macOS / Linux
curl -fsSL https://get.gortex.dev | sh
```
```powershell
# Windows (PowerShell)
irm https://get.gortex.dev/install.ps1 | iex
```
> Detects OS/arch, downloads the signed release archive, verifies the SHA256 against `checksums.txt` (and cosign if installed), installs the binary, and puts it on your PATH. Re-runs upgrade in place. No silent sudo. Linux + macOS + Windows, amd64 + arm64. On Windows, `scoop install gortex` works too.
For Homebrew, package managers (`.deb` / `.rpm` / `.apk`), direct binary download, supply-chain verification (cosign + SLSA-3 + VirusTotal), and from-source builds — see [docs/installation.md](docs/installation.md).
**New to Gortex?** After installing, see [docs/onboarding.md](docs/onboarding.md) for the 15-minute walkthrough:
`gortex install` (once per machine) → `gortex daemon start --detach` → `gortex track ` → your AI assistant uses graph tools
## Features
- **Knowledge graph** — every file, symbol, import, call chain, and type relationship in one queryable structure
- **Multi-repo workspaces** — index multiple repositories into a single graph with cross-repo symbol resolution, project grouping, reference tags, and per-repo scoping. A dedicated cross-repo edge layer materialises `cross_repo_calls` / `cross_repo_implements` / `cross_repo_extends` edges whenever a relation's endpoints live in different repos — surfaced via `analyze` `kind: "cross_repo"`. Resolution is evidence-gated: cross-repo links are only drawn when the symbol evidence clears a confidence bar, so unrelated same-named symbols don't get wired together
- **Per-session workspace isolation** — under the daemon, each MCP session's queries are scoped to the workspace it connected from; sessions on different repos never see each other's graph slices even though they share one process
- **257 languages** across three tiers — bespoke tree-sitter extractors (~30) for the deep-resolution tier (Go, TypeScript, Python, Rust, Java, C#, Kotlin, Swift, C, C++, Ruby, Elixir, OCaml, …), regex extractors (~60) for niche/legacy (ABAP, COBOL, Verse, AL, AutoHotkey, …), and forest-backed signature-only (~165 via `alexaandru/go-sitter-forest`) for the long tail (Vue, Svelte, Astro, GraphQL, Prisma, Latex, Typst, Agda, Idris, Hack, Haxe, MLIR, LLVM, SystemVerilog, Cedar, CEL, TLA+, Robot, Hurl, …) — plus **notebook-style sources**: Jupyter `.ipynb` (nbformat 3 + 4) and Databricks notebooks (`.dbc` archives + source-format `.py` / `.scala` / `.sql` / `.R` with `# COMMAND ----------` separators) extract each cell as its own graph node (code → `KindFunction`, markdown/raw → `KindVariable`) tagged with `cell_index` / `cell_kind` / `cell_language` so `%%sql` / `%%scala` cell magics and Databricks `%magic` directives surface as language-routed symbols. See [docs/languages.md](docs/languages.md) for the full table
- **111 MCP tools** — symbol lookup, call chains, blast radius, community/process discovery, contract detection, unified `analyze` (dead code, hotspots with novelty + directional ranking modes, cycles, channel-ops, goroutine-spawns, field-writers, config-readers, event-emitters, error-surface, external-calls, routes, models, components, k8s_resources, images, kustomize, cross-repo, dbt_models, unsafe_patterns, health_score, **role** (six-class classifier), **constructors_missing_fields** (literal-site field-completeness check), **clusters** (community projections with density + spread + language mix; `algorithm` selects `leiden` (default), `louvain`, or recursive-spectral-bisection `spectral`), **concepts** (LLM-or-heuristic cluster theme labels), **impact** (composite per-symbol change-impact score 0..100 + risk label from PageRank centrality + transitive reach + cyclomatic complexity + co-change coupling + community span), **named** (runs named detector bundles from the `.gortex.yaml::queries` block — 10 built-in security bundles ship), **tests_as_edges** (first-class view over the test→code edge layer, grouped by symbol or by test)), near-duplicate clone detection (`find_clones`), structural code search (`search_ast` with bundled detectors), CPG-lite dataflow (`flow_between` / `taint_paths` over value-flow / arg-of / returns-to edges), four proactive push channels — diagnostics, workspace readiness, daemon health, stale refs (`subscribe_diagnostics` / `subscribe_workspace_readiness` / `subscribe_daemon_health` / `subscribe_stale_refs` and their `unsubscribe_*` pairs) — plus code actions (`get_code_actions` / `apply_code_action` / `fix_all_in_file`) wired across every running language server, scaffolding, inline editing, symbol renaming, read-free file writes (`edit_file` / `write_file`) with path-traversal guard + `dry_run`, multi-axis structured retrieval (`winnow_symbols`), multi-repo management, agent feedback loop, context export, graph-validated config hygiene (`audit_agent_config`), opening-move routing (`plan_turn`), narrative repo overview (`get_repo_outline`), cold-start query suggestions (`suggest_queries` — 5-10 starter queries from entry points, hubs, bridges, and subsystems), test-coverage gaps (`get_untested_symbols`), session memory (`save_note` / `query_notes` / `distill_session` — per-repo notes auto-linked to symbols, survive context compactions), **cross-session development memories** with workspace + global scopes (`store_memory` / `query_memories` / `surface_memories` / `edit_memory` / `rename_memory` — symbol-anchored, deterministically ranked; compound across sessions and teammates; promote workspace-local invariants to user-level with one call), **repository-local persistent notebook** (`notebook_save` / `notebook_find` / `notebook_list` / `notebook_show` / `notebook_used` — markdown entries committed to git so agent journal entries surface in PR review), composed workflow primitives — `get_architecture` (single-shot snapshot: outline + communities + hotspots + entry points + processes + cross-repo + contracts), `replay_episode` (incident investigation walking callers + timeline + coverage gaps + incident memories from a symptom anchor), `get_knowledge_gaps` (disconnected nodes + thin communities + single-file communities + untested hotspots), `get_surprising_connections` (composite anomaly scorer over five signals), `safe_delete_symbol` (atomic dead-code removal with graph-aware safety gate), `verify_citation` (git-show + substring check at a SHA), `check_onboarding_performed` (boolean readiness probe over essential memory kinds), `check_references` (one-call composite over imports + name search + usage graph), `generate_skill` (bundle a directory into `.claude/skills//SKILL.md` + references/), `gortex_wakeup` (paste-ready ~500-token codebase digest; matched `gortex wakeup` CLI for MCP-less users), `get_churn_rate` (per-symbol commit density from blame), `find_co_changing_symbols` (ranked git co-change neighbours over mined `co_change` edges), `search_artifacts` / `get_artifact` (full-text + by-id lookup over the context-artifacts manifest — schemas, API specs, infra configs, ADRs), `get_coupling_metrics` (Robert C. Martin Ca/Ce/instability per package or community), `get_extraction_candidates` (ranked refactor suggestions from log-scaled size × callers × fan-out), `list_inspections` / `run_inspections` (uniform inspector surface composing existing analyzers), `graph_completion_search` (consumes the pluggable Retriever protocol for vector-or-graph hybrid candidate sets), and an optional in-process LLM research agent (`ask`)
- **Semantic search** — hybrid BM25 + vector search with RRF fusion. Hugot (pure-Go ONNX runtime with MiniLM-L6-v2) is bundled by default and auto-downloads the model on first use — zero-config, no native dependencies. GloVe word vectors remain as fallback. Optional build tags switch to ONNX or GoMLX for higher throughput
- **Language-agnostic concurrency analyzers** — `analyze kind=race_writes` flags struct-field writes from inside a goroutine-reachable function whose writer has no detected lock acquisition (`Lock` / `RLock` / `Acquire` / `WithLock` / `synchronized` / `Do` recognised across Go, Rust, Java, TS, Python, C#); `analyze kind=unclosed_channels` flags channels with sends but no `close()` call from any sender or receiver, classified high / medium / low risk based on sender count + receiver presence. Rides existing `EdgeSpawns` / `EdgeSends` / `EdgeRecvs` / `EdgeWrites` / `EdgeCalls` edges — no LSP dependency, works on every language whose extractor emits the substrate (Go full; TS, Python, Kotlin, Rust, C# for spawns + writes). Pairs with the existing `channel_ops` + `goroutine_spawns` + `field_writers` producer-side analyzers
- **Bundled unsafe-patterns scan** — `analyze kind=unsafe_patterns` fans out seven tree-sitter detectors over the whole indexed file set in one call: Go `panic`, Rust `.unwrap` / `.expect` / `panic!` / `todo!` / `unimplemented!` / `unreachable!` / `assert!` (+ `debug_assert*`) / `unsafe { }` / `unsafe fn`, Python `assert` (stripped by `-O` in production), JS / TS `throw`. Filters by `language` / `detector` / `severity` / `path_prefix`; severity-ranked rows (`error` > `warning` > `info`) with a per-detector count summary; `exclude_tests` defaults to true so test asserts don't drown real findings. Each rule is also invocable individually via `search_ast detector=…`
- **Composite code-health score** — `analyze kind=health_score` aggregates `coverage_pct` + complexity (fan-in/out + community-crossings) + recency (`last_authored`) + session churn into one `0..100` value per symbol plus an A..F grade. Missing axes are skipped (not zero-imputed) so a repo with no blame enrichment still produces meaningful scores from the axes that are available. Every response carries a population distribution (mean / median / std-dev / **Gini coefficient over risk inequality** / per-grade counts). Pass `roll_up=file` or `roll_up=repo` for per-file / per-repo averages with min/max bands. Filters: `path_prefix`, `kinds`, `grade`, `min_score`, `max_score`, `min_axes`, `limit`. Sorted ascending so the worst symbols surface first under truncation
- **Scope-based static resolver for C / C++ / Java / PHP** — beyond tree-sitter's local match, the resolver knows about each language's scope rules and uses them to disambiguate same-named symbols before falling back to directory-locality. C prefers a same-file `static` function over a same-name extern; C++ prefers a same-namespace candidate and walks Argument-Dependent Lookup (Koenig) namespaces harvested from the call's argument types when same-namespace lookup misses; Java pins unqualified calls to the enclosing class first, then walks the `extends` chain up to 8 hops; PHP resolves `parent::`/`self::`/`static::` against the inheritance chain. Scope-resolved edges stamp `OriginASTResolved` + `Meta["resolution"]="scope"` so the per-edge tier surface tells scope wins from generic-locality wins. No LSP dependency on these languages — pure static analysis from the tree-sitter parse
- **Sub-millisecond impact analysis** — `explain_change_impact`, `detect_changes`, `flow_between` step-impact, and the prompt `safe_to_change` / `pre_commit` flows all share a precomputed reach index that walks every node's incoming edges to depth 3 at index time and stamps the result on `Node.Meta`. Blast-radius queries become O(seeds × reach) map lookups instead of a depth-3 BFS, the representative in-edge confidence + label ride alongside each tier entry so consumers don't pay a second `GetInEdges` per result, and the daemon snapshot persists the index so warm-starts skip the build cost entirely. Bounded incremental rebuilds keep AnalyzeImpact correct after every file watcher patch; queries on nodes added after the last build (or any depth >3 query) transparently fall back to the live walk so consumers never see a stale result
- **LSP-enriched call-graph tiers** — every edge carries an `origin` tier (`lsp_resolved` / `lsp_dispatch` / `ast_resolved` / `ast_inferred` / `text_matched`) plus a coarse `tier` label (`lsp` / `ast` / `heuristic`) derived from it, so agents can group or filter by provenance without recomputing the mapping; pass `min_tier` to `get_callers`, `find_usages`, `find_implementations`, `flow_between`, `taint_paths`, etc. to restrict results to compiler-verified edges for high-stakes refactors. `flow_between` prunes below-tier edges during BFS (no broken paths) and emits per-step `origins` / `tiers` plus a per-path `worst_tier` in the GCX1 wire format so reviewers see the weakest link without decoding every step. For TS/JS/JSX/TSX, the cross-file resolver consults `typescript-language-server` **on the hot path** (not just as an after-the-fact enricher), so LSP-grade precision lands on the first query rather than waiting for the enrichment pass. Opt-out with `GORTEX_LSP_RESOLVER=0`
- **MCP progress notifications** — long-running indexing and track_repository calls emit `notifications/progress` with stage messages (walking files → parsing → resolving → semantic enrichment → search index → contracts → done) so hosts show real progress bars on large repos
- **Four proactive push channels** — per-session opt-in subscribe/unsubscribe tools, delta-filtered, initial replay, auto-cleanup on disconnect. `notifications/diagnostics` (LSP `publishDiagnostics` fan-out; filter by `min_severity` / `path_prefix`), `notifications/workspace_readiness` (daemon warmup phase transitions: snapshot_loaded → parallel_parse → deferred_passes_all → global_resolve → end_batch → watcher_started → ready), `notifications/daemon_health` (periodic ticker — default 15 s, clampable 1 s..5 min — snapshots uptime, alloc/sys/heap, num_goroutine, num_gc, tracked_repos, sessions, lsp_alive, graph nodes/edges; only runs while ≥1 subscriber is attached), `notifications/stale_refs` (per-session intersect of watcher symbol-change events against the session's viewed/modified working set — fires only when a change actually touches what *this* session has consumed). Subscriber counts + last-known states surface in `graph_stats` under `notifications` for debugging
- **Type-aware resolution** — infers receiver types from variable declarations, composite literals, and Go constructor conventions to disambiguate same-named methods across types
- **On-disk persistence** — snapshots the graph on shutdown, restores on startup with incremental re-indexing of only changed files (~200ms vs 3-5s full re-index). Snapshots are keyed by `(repo, branch)`, so switching branches reuses each branch's cached index, and git worktrees of one repo share that base. Change detection is mtime-based by default, with an opt-in BLAKE3 Merkle-tree mode (`index.merkle` / `GORTEX_MERKLE`) that diffs by content hash — a touched-but-unchanged file is skipped. A cross-process advisory lock guards the index store against concurrent writers
- **HTTP server (`gortex server`)** — versioned `/v1/*` JSON API exposing all MCP tools (`/v1/health`, `/v1/tools`, `/v1/tools/{name}`, `/v1/stats`, `/v1/graph`, `/v1/events` SSE) for IDE plugins, CI, and the Next.js web UI. Localhost bind + bearer-token auth (`--auth-token` / `$GORTEX_SERVER_TOKEN`) by default; CORS configurable for separate frontend origins
- **MCP 2026 Streamable HTTP transport (`/mcp`)** — the wire format the June 2026 MCP spec locks in. One endpoint (`POST/GET/DELETE /mcp`), per-request session replay via `Mcp-Session-Id` and an in-memory `streamable.SessionStore` (swap for Redis to run multiple workers behind a load balancer), JSON-RPC batching, SSE upstream for server-initiated notifications, multi-server router reuse so `tools/call` frames still proxy across the federation. Always-on for `gortex server`; opt-in on the daemon via `gortex daemon start --http-addr 127.0.0.1:7411 [--http-auth-token ]`
- **Semantic enrichment** — pluggable SCIP, go/types, and LSP providers upgrade edge confidence from ~70-85% (tree-sitter) to 95-100% (compiler-verified). Additive — graceful degradation when external tools unavailable. The SCIP provider has a definitions-only fast path (`mode: definitions`) for a C# / .NET (`scip-dotnet`) coverage helper that wants compiler-grade symbol coverage without paying for full reference ingestion; per-server `command` / `args` / `env` overrides in `.gortex.yaml` let heavyweight servers (notably jdtls) be pinned to a specific JRE
- **Crash-resilient indexing** — opt-in (`index.crash_isolation`) tree-sitter extraction in worker subprocesses, so a grammar SIGSEGV / OOM / hang on one pathological file is contained: the bad file is quarantined with `Meta["parse_error"]`, the quarantine persists across daemon restarts, and the index pass still completes. The worker pool is long-lived — reused across single-file re-indexes so the watcher path never re-spawns a worker per file. A per-file extraction budget (`index.max_extract_millis`) and the size cap both leave a synthetic node carrying `skipped_due_to_timeout` / `skipped_due_to_size` telemetry instead of dropping the file silently. Pluggable pre-ingestion content transforms (`index.transforms`) rewrite bytes before parsing — built-in BOM stripping, plus user external-command processors (minified-bundle expansion, SVG/TOON, PDF→markdown) that can even re-type a file to a language its extension does not natively map to
- **Framework-aware extraction** — first-class **entry points** (Alembic migrations, Next.js pages / App-Router files, ASP.NET host files) stamped so the dead-code analyzer never flags runtime-invoked symbols; Swift HTTP routes (Vapor provider + Alamofire consumer); a **XAML / AXAML** extractor (`x:Class` code-behind link, named controls, `{Binding}` expressions); .NET DI registrations + COM-interop flags on C# files; Lombok / MapStruct / Kotlin / CommunityToolkit.Mvvm source-generated members surfaced via `has_generated_members`. New `analyze` kinds — `env_var_users`, `sql_call_sites`, `fixes_history` (git bug-fix-commit hotspots), `edge_audit` (graph-completeness self-diagnostic), `domain` (user-pluggable TOML extractor rules), `impact` (quad-signal change-impact composite), `named` (named detector bundles from `.gortex.yaml::queries`), and `tests_as_edges` (test→code edge-layer view). pyrefly and tsgo join the language-server registry
- **Agent feedback loop** — unified `feedback` tool (`action: "record"` / `"query"`) lets agents report which symbols were useful/missing. Cross-session persistence improves future `smart_context` quality via feedback-aware reranking
- **Context export** — `export_context` tool + `gortex context` CLI render graph context as portable markdown/JSON briefings for sharing outside MCP (Slack, PRs, docs, non-MCP AI tools)
- **ETag conditional fetch** — content-hash based `if_none_match` on source-reading tools avoids re-transmitting unchanged symbols during iterative editing
- **Token savings tracking** — per-call `tokens_saved` field on source-reading tools + session-level metrics in `graph_stats` (calls counted, tokens returned, tokens saved, efficiency ratio). `gortex savings` renders a three-bucket dashboard (Today / Last 7 days / All time) with 16-cell `█/░` bars, percentage saved, raw token counts, and USD cost avoided priced against the headline model. Per-call JSONL log at `/savings.jsonl` powers windowed buckets and the `--verbose` per-tool breakdown (`get_symbol_source` / `batch_symbols` / `smart_context`)
- **GCX1 compact wire format** — published, round-trippable text format for MCP tool responses. Opt-in per call via `format: "gcx"` on every list-shaped tool (~17). Auto-served as the default for known clients (Claude Code, Cursor, VS Code, Zed, Aider, Kilo Code, OpenCode, OpenClaw, Codex) when no `format` is passed; explicit `format` always wins. **Median −27.4% savings vs JSON** across a 20-case benchmark under tiktoken `cl100k_base` (Claude 3 / Opus 4 / Sonnet 4 / Haiku 4.5 / GPT-4o family) and a parallel **−27.3% under Claude Opus 4.7** input-token counts (best case −38.3%), 100% round-trip integrity. Spec: [`docs/wire-format.md`](docs/wire-format.md). Standalone MIT-licensed reference implementations: Go ([`github.com/gortexhq/gcx-go`](https://github.com/gortexhq/gcx-go)) and TypeScript ([`github.com/gortexhq/gcx-ts`](https://github.com/gortexhq/gcx-ts), npm [`@gortex/wire`](https://www.npmjs.com/package/@gortex/wire)). Reproducible harness: [`bench/wire-format/`](bench/wire-format/) (dual-tokenizer scorecard; `--use-api` for exact Opus 4.7 counts via Anthropic `count_tokens`)
- **TOON fallback wire format** — second-tier compact text (~10–15% smaller than JSON, lossy but human-friendly) on every list-shaped tool for clients that don't yet speak GCX. Pass `format: "toon"`
- **Budget-by-default MCP responses** — list-shaped tools cap each page at the project default budget and return `next_cursor` for the tail. Pagination, sparse fieldsets, and graceful degradation built in. Per-call caps via `max_bytes` *and* `max_tokens` (composable — tighter wins; ~3.5 bytes/token heuristic calibrated across JSON / TOON / GCX1). Truncation rides on the response as `_truncated_by_budget` / `_truncated_by_tokens` / `_max_returned_` markers (JSON) or a `# truncated_by_budget=true` / `# max_tokens=N truncated_by_tokens=true` comment (GCX)
- **16 MCP resources** — bootstrap state (`gortex://stats`, `gortex://workspace`, `gortex://repos`, `gortex://active-project`, `gortex://schema`, `gortex://session`, `gortex://index-health`), community / process rollups (`gortex://communities`, `gortex://community/{id}`, `gortex://processes`, `gortex://process/{id}`), and analyzer-backed summaries (`gortex://report`, `gortex://god-nodes`, `gortex://surprises`, `gortex://audit`, `gortex://questions`). Read-only, URI-addressable, push `notifications/resources/updated` after each graph re-warm — no polling
- **Framework graph layer** — handler→route edges from HTTP / gRPC / GraphQL / WebSocket / Phoenix / Kafka topic registrations; ORM model→table edges across GORM, SQLAlchemy, Django, ActiveRecord, JPA, TypeORM, Ecto; component-tree edges for JSX/TSX and Phoenix HEEx. Surfaced via `analyze` `kind: "routes" / "models" / "components"`
- **Infrastructure graph layer** — first-class `KindResource` (Kubernetes Deployments, Services, Ingresses, ConfigMaps, Secrets, CronJobs), `KindKustomization` (overlay tree), and `KindImage` (Dockerfile FROM targets and K8s `container.image`) with `depends_on` / `configures` / `mounts` / `exposes` / `uses_env` edges. Cross-references with code-side `os.Getenv` calls automatically. Surfaced via `analyze` `kind: "k8s_resources" / "kustomize" / "images"`
- **CPG-lite dataflow** — `value_flow` (intra-procedural assignment / return / range), `arg_of` (caller arg → callee param), and `returns_to` (callee → assignment LHS) edges built at index time. `flow_between` returns ranked dataflow paths between two symbol IDs; `taint_paths` does pattern-driven source→sink sweeps for security audits
- **Near-duplicate clone detection** — every substantial function body is reduced to a 64-slot token-normalised MinHash signature at index time, LSH banding finds candidate pairs, and a Jaccard threshold filter keeps the true clones — emitted as symmetric `similar_to` edges. `find_clones` surfaces the clusters; `find_clones {dead_only: true}` yields the Gortex-unique "dead duplicates of live code" diagnostic. Gated behind the `clones` coverage domain (default on, threshold tunable in `.gortex.yaml`)
- **Stratified test classification** — test symbols are classified by role (unit / integration / e2e / benchmark / fixture) and the `tests` edges carry that role, so `winnow_symbols` can filter "production functions only, no tests" and coverage analyzers can reason per-tier
- **Local LLM research agent (optional)** — built with `-tags llama` and a configured `llm.model`, the `ask` MCP tool runs a small GGUF model in-process via llama.cpp that navigates the graph with gortex tools and returns a synthesized answer — one call replaces a long chain of `search_symbols` / `get_callers` / `contracts` calls. `chain: true` traces a request across repos (consumer → contract → provider → downstream). Falls through to direct tools when the build tag or model is absent
- **3 MCP prompts** — `pre_commit`, `orientation`, `safe_to_change` for guided workflows
- **LLM features (optional)** — opt-in `ask` research agent + LLM-assisted `search_symbols` ranking, behind a pluggable provider (`local` llama.cpp / Anthropic / OpenAI / Ollama). Off by default; the HTTP providers need no native dependencies. See [LLM Features](#llm-features-optional)
- **Two-tier config** — global config (`~/.config/gortex/config.yaml`) for projects and repo lists, per-repo `.gortex.yaml` for guards, excludes, and local overrides
- **Guard rules** — project-specific constraints (co-change, boundary) enforced via `check_guards`, plus an `architecture:` block: declarative `rules:` (`max_fan_out` dependency-cone limits, `deny_callers_outside` caller boundaries) and named `layers:` (path globs with directional `allow`/`deny` dependency lists)
- **Watch mode** — surgical graph updates on file change across all tracked repos, live sync with agents
- **Web UI** — standalone Next.js 15 app at [`gortexhq/web`](https://github.com/gortexhq/web) (separate repo so it deploys independently) that talks to `gortex server` over `/v1/*`, with Sigma.js 2D graphs and five react-three-fiber 3D views (City, Strata, Galaxies, Constellation, Graph3D)
- **IMPLEMENTS inference** — structural interface satisfaction for Go, TypeScript, Java, Rust, C#, Scala, Swift, Protobuf
- **PreToolUse + PostToolUse + PreCompact + Stop hooks** — two postures, picked at install (`gortex install --hook-mode={deny,enrich}`): **`deny` (default)** has PreToolUse enrich Read/Grep/Glob/Bash with graph context and **redirect by deny** to Gortex MCP tools (matching `Task` also briefs spawned subagents with an inline tool-swap table + task-scoped `smart_context`); **`enrich`** never denies — PreToolUse downgrades the deny rationale to soft `additionalContext` and a **PostToolUse hook augments the actual tool output** with graph context (enclosing symbols for Grep hits, file footprints for Read, indexed-vs-unindexed summary for Glob), trading enforcement for easier onboarding. PreCompact injects a condensed orientation snapshot (index stats, recently-modified symbols, top hotspots, feedback-ranked symbols) before Claude Code compacts the conversation. Stop runs post-task diagnostics (`detect_changes` → `get_test_targets`, `check_guards`, `analyze dead_code`, `contracts check` on modified symbols) so the agent self-corrects before handoff. All hooks degrade silently when the server is unreachable
- **Long-living daemon (optional)** — `gortex daemon start` runs a single shared process that holds the graph for every tracked repo. Each Claude Code / Cursor / Kiro window connects as a thin stdio proxy over a Unix socket, getting per-client session isolation (recent activity, token stats) + cross-repo queries by default. Live fsnotify watching on every tracked repo so file edits flow into the graph without manual reload. `gortex install` sets up user-level config; `gortex daemon install-service` installs a LaunchAgent (macOS) or systemd `--user` unit (Linux) so the OS supervises lifecycle and auto-starts at login — no sudo required. Binaries fall back to embedded mode if the daemon isn't running; the feature is additive
- **Benchmarked** — per-language parsing, query engine, indexer benchmarks
- **Per-community skills** — `gortex init --skills` (default on) auto-generates SKILL.md per detected community with key files, entry points, cross-community connections, and MCP tool invocations for Claude Code auto-discovery; the same routing table lands in every detected agent's per-repo instructions file
- **Eval framework** — SWE-bench harness for A/B benchmarking tool effectiveness with Docker-based environments and multi-model support
- **`gortex eval` CLI** — first-class evaluation harness. Subcommands: `recall` (fixture-driven any-hit R@1/5/20 + MRR per ranker, per-tier breakdown, p50/p95 latency, tokens-returned, optional LLM judge for CQS-style dual-judge scoring), `embedders` (ONNX variant comparison — size + init + embed latency + end-to-end quality across MiniLM variants, BGE, Jina; `list` subcommand surfaces the next-gen Python-backed model registry — EmbeddingGemma / Qwen3-Embedding-8B / NV-Embed-v2 / potion-code-16m — with availability + install hints), `baselines` (NDCG@10 + latency vs ripgrep / probe / colgrep / grepai / coderankembed / semble; `--smoke` verifies wiring without paying for heavy Python deps), `quality {drift|confidence|replay|tune}` (measurement infra: embedder drift detector + per-query confidence summary + ranker-config replay + rerank weight-tuning suggestion), `swebench` (passthrough), `stdbench` (CoIR / SWE-ContextBench / ContextBench standardized-benchmark loaders — Recall@K / NDCG@10 / MRR), `tokens` (GCX1 wire-format bench). Seed fixture at [`bench/fixtures/retrieval.yaml`](bench/fixtures/retrieval.yaml); published BM25 baseline on Gortex: **R@1 42.3% · R@5 55.1% · R@20 63.5% · exact R@5 96.8%**. Published reproducible benches in [`BENCHMARK.md`](BENCHMARK.md); SWE-bench results template in [`BENCHMARK-SWE.md`](BENCHMARK-SWE.md); methodology in [`docs/04-evaluation/`](docs/04-evaluation/).
- **Zero dependencies** — everything runs in-process, in memory, no external services
## Quick Start
Setup is split into two commands — `gortex install` runs once per machine, `gortex init` runs once per repo:
- **`gortex install`** writes user-level artifacts: `~/.claude.json` MCP config, `~/.claude/skills/gortex-*` (tool-usage skills), `~/.claude/commands/gortex-*.md` (slash commands), `~/.claude/agents/gortex-*.md` (Claude Code sub-agents — graph-only tool allowlist), `~/.gemini/antigravity/` Knowledge Items, and (optionally) user-level Claude Code hooks. Codebase-agnostic content lives here so it isn't duplicated into every repo.
- **`gortex init`** writes per-repo artifacts: `.mcp.json`, `.claude/settings.{json,local.json}`, `CLAUDE.md` with the codebase overview and community routing, `.claude/skills/generated/` per-community SKILL.md files, and a marker-guarded community routing block in every other detected agent's per-repo instructions file (`AGENTS.md`, `.windsurfrules`, `GEMINI.md`, `.cursor/rules/gortex-communities.mdc`, etc.).
### One-time machine setup
```bash
gortex install # interactive-free: MCP + skills + slash commands + sub-agents at ~/.claude/
gortex install --start --track # also spawn the daemon and track the current directory
gortex install --no-hooks # skip user-level hook installation
# Daemon lifecycle (also spawned by `gortex install --start`):
gortex daemon start --detach # spawn in background
gortex daemon status # PID, uptime, memory, tracked repos, sessions, server roster
gortex daemon stop # graceful shutdown + final snapshot
gortex daemon restart # stop + start
gortex daemon reload # re-read config, pick up new/removed repos
gortex daemon logs -n 50 # tail the log file
# Multi-server roster — let the daemon route to additional Gortex servers (local sockets or remote HTTPS):
gortex daemon server list # show ~/.gortex/servers.toml
gortex daemon server add work --url https://gortex.work.example --auth-token-env WORK_TOK
gortex daemon server remove work
# Auto-start at login (launchd on macOS, systemd --user on Linux):
gortex daemon install-service
gortex daemon service-status
gortex daemon uninstall-service
# Track / untrack repos (daemon-first dispatch; falls back to config-only when no daemon):
gortex track ~/projects/backend
gortex untrack backend
# Per-repo status + daemon-wide status share the same command — it picks:
gortex status
```
### Per-repo setup
```bash
cd ~/projects/myapp
gortex init # writes .mcp.json, .claude/settings.*, CLAUDE.md with community routing
gortex init --analyze # also index first for a richer CLAUDE.md overview
gortex init --no-skills # skip community-routing generation
gortex init --skills-min-size 5 --skills-max 10 # tune the generator
gortex init --hooks-only # (re)install repo-local hooks only, skip everything else
gortex init --no-hooks # full init but skip hook installation
# Run the MCP server standalone (auto-detects daemon via stdio; --no-daemon forces embedded):
gortex mcp --index /path/to/repo --watch
gortex mcp --no-daemon --watch # explicit embedded mode
```
### Other commands
```bash
gortex server --index . # HTTP/JSON API on :4747 (/v1/*). UI lives at github.com/gortexhq/web.
gortex savings [--verbose] [--json] # Today / Last 7 days / All time bar-chart dashboard + $ avoided
gortex bench # user-facing benchmark suite (recall / tokens / tokens-efficiency / perf / daemon-latency / embedders / swebench / all)
gortex audit [--badge|--format svg|json|text] # A-F repo health grade + README-ready SVG shield
gortex gain [--since 7d] # forward-looking per-call USD savings + optional history slice
gortex version
```
## Multi-Repo Workspaces
Gortex can index multiple repositories into a single shared graph, enabling cross-repo symbol resolution, impact analysis, and navigation.
### Workspace boundary
Every node and contract is keyed on a **workspace slug**, which is the hard graph boundary for cross-repo work. Two repos that should pair their contracts (an HTTP server and the client that calls it, a Kafka producer and its consumer, etc.) must declare the same `workspace:` in their `.gortex.yaml` — otherwise contract matching stops at the boundary and they look like orphans.
Slug resolution precedence (first match wins):
1. `RepoEntry.workspace` in `~/.config/gortex/config.yaml` — overrides everything, ideal for OSS / read-only repos where you don't want to leave an artifact in the tree
2. `workspace:` in the repo's own `.gortex.yaml` — the default for first-party repos
3. The repo prefix — fallback when neither is set, so each unconfigured repo gets its own isolated workspace
The same chain applies to the optional `project:` slug (a sub-bucket inside a workspace). On `gortex server`, the `--workspace` and `--scope-project` flags filter both indexing and queries: `gortex server --workspace api` will only load repos that resolve to the `api` workspace, and a typo'd value errors out at startup rather than producing an empty graph.
### Configuration
Two-tier config hierarchy:
- **Global config** (`~/.config/gortex/config.yaml`) — projects, repo lists, active project, reference tags
- **Workspace config** (`.gortex.yaml` per repo) — guards, excludes, local overrides
Excludes are layered — builtin → repo's own `.gitignore` → global → per-repo entry → workspace — with gitignore semantics. The repo's `.gitignore` is respected by default so you don't have to re-declare entries already curated for git; opt out per-workspace with `respect_gitignore: false` in `.gortex.yaml` (useful for repos that intentionally index otherwise-ignored generated code). Use `!pattern` in a later layer to re-include something an earlier layer excluded. Beyond `.gitignore`, the index walk also honors per-directory `.gortexignore` files (Gortex's own ignore file, a sibling to `.gitignore`) and ripgrep's `.ignore` / `.rgignore` — each scoped to the directory that contains it.
```yaml
# ~/.config/gortex/config.yaml
active_project: my-saas
exclude: # Applies to every tracked repo
- "**/*.generated.*"
- "node_modules/" # Already in the builtin baseline
repos:
- path: /home/user/projects/gortex
name: gortex
exclude: # Extra patterns just for this repo
- "results/**"
projects:
my-saas:
repos:
- path: /home/user/projects/frontend
name: frontend
ref: work
- path: /home/user/projects/backend
name: backend
ref: work
- path: /home/user/projects/shared-lib
name: shared-lib
ref: opensource
```
### Daemon tuning (optional)
The daemon's defaults handle typical workflows without configuration. These knobs exist for monorepos, branch-heavy workflows, or filesystems without fsnotify support.
```yaml
# ~/.config/gortex/config.yaml (or per-repo .gortex.yaml)
watch:
debounce_ms: 150 # per-file patch debounce (default 150)
# Storm mode — when more than N events land within the window,
# switch from per-file debounced patching to a batched reconcile
# that defers cross-file resolver + search work until a quiet
# period has passed. Amortises the cost of bulk operations
# (rsync, npm install, branch checkout, bulk format-on-save,
# find-and-replace). Zero = disabled (default).
storm_threshold: 0 # 0 disables; try 50 on monorepos
storm_window_ms: 500
storm_quiet_period_ms: 500
```
Environment variables:
- `GORTEX_RECONCILE_INTERVAL` — janitor tick that walks every tracked repo and runs `IncrementalReindex` against disk. Insurance against fsnotify gaps on NFS/SMB mounts, inotify watch-limit exhaustion, or daemon downtime where edits happened offline. Default `1h`; `"0"` or `"off"` disables; otherwise any Go duration string (e.g., `15m`).
- The daemon also watches each tracked repo's `.git/HEAD`, so branch switches and rebases reconcile incrementally (via `git diff --name-status`) rather than by re-indexing every changed file individually — no configuration needed.
### CLI
```bash
gortex track /path/to/repo # Add a repo to the workspace
gortex untrack /path/to/repo # Remove a repo from the workspace
gortex mcp --track /path/to/repo # Track additional repos on startup
gortex mcp --project my-saas # Set active project scope
gortex index repo-a/ repo-b/ # Index multiple repos
gortex status # Per-repo and per-project stats
# Stamp workspace / project slugs across tracked repos (migration helper)
gortex workspace list # Show what each tracked repo currently declares
gortex workspace set backend api # Write workspace=api to backend's .gortex.yaml
gortex workspace set upstream-lib api --global # OSS-friendly: pin to api in ~/.config/gortex/config.yaml
gortex workspace set-all api --root ~/projects/work --yes # Bulk: stamp every tracked repo under a prefix
# Manage the effective ignore list used by indexing + watching
gortex config exclude list # Show all layers (builtin, global, repo entry, workspace)
gortex config exclude add pkg/generated # Default target: workspace .gortex.yaml
gortex config exclude add '**/*.bak' --global # Write to ~/.config/gortex/config.yaml
gortex config exclude add testdata/ --repo backend # Write to a RepoEntry
gortex config exclude remove pkg/generated # Remove from the same target
```
### MCP Tools
Agents can manage repos at runtime without CLI access:
| Tool | Description |
|------|-------------|
| `track_repository` | Add a repo, index immediately, persist to config |
| `untrack_repository` | Remove a repo, evict nodes/edges, persist to config |
| `set_active_project` | Switch project scope for all subsequent queries |
| `get_active_project` | Return current project name and repo list |
All query tools (`search_symbols`, `get_symbol`, `find_usages`, `get_file_summary`, `get_call_chain`, `smart_context`) accept optional `repo`, `project`, and `ref` parameters for scoping. When an active project is set, it applies as the default scope.
### How It Works
- **Qualified Node IDs** — in multi-repo mode, IDs become `/::` (e.g., `frontend/src/app.ts::App`). Single-repo mode keeps the existing `::` format.
- **Cross-repo edges** — the resolver links symbols across repo boundaries with same-repo preference. Cross-repo edges carry a `cross_repo: true` flag.
- **Impact analysis** — `explain_change_impact`, `verify_change`, and `get_test_targets` follow cross-repo edges automatically, grouping results by repository.
- **Shared repos** — the same repo can appear in multiple projects with different reference tags. It's indexed once and shared across projects.
- **Auto-detection** — set `workspace.auto_detect: true` in `.gortex.yaml` to auto-discover Git repos in a parent directory.
## Usage with Claude Code
After `gortex install` (once per machine) and `gortex init` (once per repo), Claude Code automatically starts Gortex via `.mcp.json`. The agent gets:
- **Slash commands (19):** installed to `~/.claude/commands/` by `gortex install`. Three groups:
- *Discovery & analysis (8)* — `/gortex-guide`, `/gortex-explore`, `/gortex-debug`, `/gortex-impact`, `/gortex-dataflow-trace`, `/gortex-cross-repo-usage`, `/gortex-co-change`, `/gortex-onboarding`
- *Refactor & edit (enforce tool-call order) (6)* — `/gortex-refactor`, `/gortex-safe-edit`, `/gortex-rename`, `/gortex-extract-function`, `/gortex-fix-all`, `/gortex-add-test`. These wrap the speculative-execution (`preview_edit` / `simulate_chain`) and LSP code-actions (`get_code_actions` / `apply_code_action` / `fix_all_in_file`) paths so the agent does not bypass the safety steps by calling `Edit` / `Write` directly.
- *Review & operate (graph-grounded playbooks) (5)* — `/gortex-pr-review`, `/gortex-architecture-review`, `/gortex-quality-audit`, `/gortex-incident-investigation`, `/gortex-episode-replay`. These wrap the discovery + impact + memory surfaces into ordered playbooks so postmortems, audits, and PR reviews are graph-grounded.
- **Tool-usage skills:** the same 19 are installed as model-invoked skills to `~/.claude/skills/` by `gortex install` — one copy per user, used across every repo
- **Sub-agents (2):** installed to `~/.claude/agents/` by `gortex install`. Claude Code auto-routes matching prompts to them; each runs in a fresh context window and returns a single summary, keeping the parent's context clean. Tool allowlists are pinned to gortex graph tools only — Bash / Grep / Glob are unavailable to the sub-agent by construction.
- `gortex-search` — locate code, trace call paths, explore architecture
- `gortex-impact` — assess blast radius before editing (`verify_change`, `simulate_chain`, `check_guards`, `get_test_targets`)
- **PreToolUse hook:** automatic graph context + graph-tool suggestions on Read/Grep/Glob
- **PreCompact hook:** condensed orientation snapshot injected before context compaction so the agent resumes without re-exploring
- **Stop hook:** post-task diagnostics — tests to run, guard violations, dead code, and contract issues on the changed symbols — injected as context before the agent hands off
- **CLAUDE.md:** per-repo codebase overview (via `--analyze`) plus a marker-guarded community routing block written by `gortex init --skills`
## Usage with other agents
`gortex install` (user-level) and `gortex init` (repo-level) together auto-detect and configure 14 other AI coding assistants — Kiro, Cursor, VS Code / Copilot, Windsurf, Continue.dev, Cline, OpenCode, Antigravity, Codex CLI, Gemini CLI, Zed, Aider, Kilo Code, OpenClaw. Each adapter writes only when its host is present on the machine, and every re-run is idempotent.
Tool-usage guidance for agents that have a user-level surface (Claude Code, Antigravity) lives once per user; for the rest, MCP tool descriptions carry the teaching and `gortex init` adds only a per-repo community-routing block — no more duplicated instructions blocks in every repo.
- **Adapter matrix + per-agent schema notes:** [`docs/agents.md`](docs/agents.md)
- **Audit what's currently configured:** `gortex init doctor` (zero-op; `--json` for CI consumers)
- **Constrain setup:** `gortex init --agents=claude-code,cursor` or `--agents-skip=antigravity` (same flags accepted by `gortex install`)
- **CI / scripted install:** `gortex install --yes --json` then `gortex init --yes --json --dry-run`
## CLI Commands
```
gortex install One-time machine-wide setup (user-level MCP, skills, hooks, daemon wiring)
gortex init [path] Per-repo setup (.mcp.json, hooks, community routing, per-community SKILL.md)
gortex init doctor Zero-op drift report across all detected agents (human or --json)
gortex mcp [flags] Start the MCP stdio server (auto-detects daemon; --no-daemon / --proxy; --server adds HTTP API)
gortex server [flags] Start the HTTP/JSON API under /v1/* (--bind, --auth-token, --watch, --cors-origin)
gortex daemon start / stop / restart / reload / status / logs / install-service / service-status / uninstall-service / server (multi-server roster)
gortex eval Retrieval + token benchmarks — recall / embedders / swebench / tokens / baselines / quality (substrate; prefer `gortex bench` for the user-facing surface). `eval embedders list` shows the next-gen model registry; `eval quality {drift|confidence|replay|tune}` runs the measurement-infra analyzers; `eval baselines --against ripgrep,...` runs the NDCG@10 adapter harness
gortex eval-server [flags] HTTP server used by the swebench harness
gortex bench User-facing benchmark suite — recall / tokens / tokens-efficiency / embedders / perf / daemon-latency / swebench / all; `bench tokens` adds a USD-per-model card (per-day + per-month projections); `bench perf` runs the reference-repo perf table with budget gates; `bench tokens-efficiency` runs the 3-pipeline vs-ripgrep comparison with recall@k; `bench daemon-latency` measures per-MCP-tool dispatch latency (p50/p95/p99); `--out-dir DIR` writes per-run artifacts
gortex audit [flags] A-F repo health grade derived from per-symbol complexity-axis health score; emits a shields.io-style SVG (default `.gortex/badge.svg`) for the README, JSON with per-grade counts + worst-5 symbols, or a one-line ` · ` text form
gortex gain [flags] Forward-looking per-call USD savings projection from the latest bench tokens output; optional `--since DURATION` cumulative-history slice
gortex context [flags] Generate portable context briefing for a task
gortex savings [flags] Token-savings dashboard (Today / Last 7 days / All time bars + USD avoided; --verbose, --json, --model, --utc, --reset)
gortex index [path...] Index one or more repositories and print stats
gortex status [flags] Show index status (per-repo and per-project in multi-repo mode)
gortex track Add a repository to the tracked workspace
gortex untrack Remove a repository from the tracked workspace
gortex workspace list / set / set-all — manage workspace + project slugs across tracked repos
gortex config exclude ... add / list / remove entries in the effective ignore list
gortex query Query the knowledge graph from the CLI
gortex wiki [path] Generate a multi-page markdown wiki (per-community + processes + analysis)
gortex docs [path] Generate a "living docs" bundle (recent changes + ownership + stale + blame)
gortex export [path] Export the graph to Cypher, GraphML, or Mermaid (--format mermaid --scope all)
gortex githook install / uninstall / status — manage the post-commit hook
gortex clean Remove Gortex files from a project
gortex version Print version
```
### Generated Wiki + Living Diagrams
Run `gortex wiki .` to produce a Markdown wiki under `wiki//`:
```
wiki/
index.md # top-level (single repo today, multi-repo extension point)
/
index.md # community navigation
architecture.md # community-level system overview
communities/-.md # one page per detected community
processes/.md # one page per discovered execution flow (Mermaid sequenceDiagram)
contracts/api-surface.md # HTTP / gRPC / GraphQL contracts
analysis/{hotspots,cycles,semantic}.md
_assets/community-graph.mermaid
_workspace/ # reserved for multi-repo pages
```
Pair with `gortex githook install post-commit --regen-mermaid --regen-wiki`
to keep diagrams and docs in sync after every commit. The hook is idempotent
and preserves any non-gortex content in the existing hook file.
For CI, drop `examples/.github/workflows/gortex-architecture.yml` into your
repo: it re-runs `gortex export --format mermaid --scope all` on every push
and opens a PR when the diagrams drift.
`gortex wiki --enhance` enables LLM-augmented narrative summaries via the
configured `llm.provider` (claudecli for MVP — uses your local Claude Code
subscription). Results are cached by `(node, content_hash)` so re-runs on
unchanged inputs produce byte-identical output without re-invoking the LLM.
### Query Subcommands
```
gortex query symbol Find symbols matching name
gortex query deps Show dependencies
gortex query dependents Show blast radius
gortex query callers Show who calls a function
gortex query calls Show what a function calls
gortex query implementations Show interface implementations
gortex query usages Show all usages
gortex query stats Show graph statistics
```
All query commands support `--format text|json|dot` (DOT output for Graphviz visualization).
## MCP Tools (95+, lazy-loaded)
### Tool surface — lazy discovery (N50)
By default the server publishes only the 25 hot tools listed below at session
start; the remaining ~70 schemas stay hidden in a deferred catalog and are
fetched on demand via the `tools_search` discovery tool. Cold `tools/list`
drops from ~88 tools down to ~28 — roughly 68% fewer schema bytes on the
first round-trip — without giving up access to anything: the full surface is
one `tools_search` call away.
```jsonc
// Browse — list deferred tool names without schemas.
{"name":"tools_search","arguments":{}}
// Fetch schemas for specific tools by name (auto-promotes them into tools/list).
{"name":"tools_search","arguments":{"query":"select:flow_between,taint_paths,find_clones"}}
// Keyword search with required-token filter, ranked, capped at max_results.
{"name":"tools_search","arguments":{"query":"+overlay drop","max_results":5}}
// Fuzzy keyword match across name + description.
{"name":"tools_search","arguments":{"query":"memories invariants"}}
```
Returned tools are auto-promoted (`promote:false` opts out) and the server
fires `notifications/tools/list_changed` for any client that subscribes.
Set `GORTEX_LAZY_TOOLS=0` to opt every tool back into eager registration —
useful for older MCP clients that don't speak the discovery flow.
### Core Navigation
| Tool | Description |
|------|-------------|
| `graph_stats` | Node/edge counts by kind, language, per-repo stats, and session token savings |
| `search_symbols` | Find symbols by name (replaces Grep). Inline `kind:`/`lang:`/`path:` field clauses + `query_class` / `max_per_file` tuning; accepts `repo`, `project`, `ref` params |
| `search_text` | Trigram-accelerated literal code search across the repo — the alt grep backbone. Returns file/line/text rows |
| `winnow_symbols` | Structured constraint-chain retrieval — `kind`, `language`, `community`, `path_prefix`, `min_fan_in`, `min_fan_out`, `min_churn`, `text_match` with per-axis score contributions |
| `get_symbol` | Symbol location and signature (replaces Read). Accepts `repo`, `project`, `ref` params |
| `get_file_summary` | All symbols and imports in a file. Accepts `repo`, `project`, `ref`, `max_bytes` / `max_tokens` budget caps |
| `get_editing_context` | **Primary pre-edit tool** — symbols, signatures, callers, callees. Accepts `max_bytes` / `max_tokens` budget caps |
| `get_repo_outline` | Narrative single-call repo overview — top languages, communities, hotspots, most-imported files, entry points |
| `plan_turn` | Opening-move router — returns ranked next calls with pre-filled args for a task description (~200 tokens) |
### Graph Traversal
| Tool | Description |
|------|-------------|
| `get_dependencies` | What a symbol depends on |
| `get_dependents` | What depends on a symbol (blast radius) |
| `get_call_chain` | Forward call graph. Accepts `max_bytes` / `max_tokens` budget caps |
| `get_callers` | Reverse call graph |
| `find_usages` | Every reference to a symbol. Accepts `max_bytes` / `max_tokens` budget caps |
| `find_implementations` | Types implementing an interface |
| `find_overrides` | Methods that override (children) or are overridden by (parents) a method — backed by `EdgeOverrides` |
| `get_class_hierarchy` | Multi-hop inheritance subgraph around a type, interface, or method — walks `EdgeExtends` + `EdgeImplements` + `EdgeComposes` (type nodes) and `EdgeOverrides` (method nodes); `direction` ∈ up / down / both, `include_methods` pulls members + their override chain |
| `get_cluster` | Bidirectional neighborhood |
### Dataflow (CPG-lite)
| Tool | Description |
|------|-------------|
| `flow_between` | Ranked dataflow paths between two symbols — walks `value_flow` / `arg_of` / `returns_to` edges |
| `taint_paths` | Pattern-driven source→sink dataflow sweep for security and architecture audits |
### Structural Search
| Tool | Description |
|------|-------------|
| `search_ast` | Cross-language structural search by AST shape — raw tree-sitter S-expression `pattern` or a bundled `detector` (e.g. `sql-string-concat`, `weak-crypto`, `hardcoded-secret`) |
### Diagnostics & Code Actions
Wired across every running language server (gopls, tsserver, pyright, rust-analyzer, …).
| Tool | Description |
|------|-------------|
| `subscribe_diagnostics` | Opt the session into push `notifications/diagnostics`; initial state replays immediately, deltas thereafter. Filter by `min_severity` / `path_prefix` |
| `unsubscribe_diagnostics` | Opt back out — idempotent, fires automatically on session disconnect |
| `get_diagnostics` | Latest stored diagnostics for a file; `wait: true` blocks on the first publish |
| `get_code_actions` | LSP code actions (quickfix / organizeImports / refactor / source) at a file location |
| `apply_code_action` | Apply a single code action to disk — atomic temp+rename |
| `fix_all_in_file` | Loop codeAction → apply → re-collect until convergence over the whole file |
### Proactive Notifications
Three additional push channels modeled on `subscribe_diagnostics` — per-session opt-in, delta-filtered, initial replay, auto-cleanup on disconnect. Subscriber counts and last-known states surface in `graph_stats` under `notifications`.
| Tool | Description |
|------|-------------|
| `subscribe_workspace_readiness` | `notifications/workspace_readiness` — fans daemon warmup phase transitions (snapshot_loaded → parallel_parse → deferred_passes_all → global_resolve → end_batch → watcher_started → ready). Last-known phase replayed to late subscribers |
| `unsubscribe_workspace_readiness` | Opt back out — idempotent |
| `subscribe_daemon_health` | `notifications/daemon_health` — periodic ticker (default 15 s, `interval_ms` clamped to 1 s..5 min) snapshots uptime, alloc/sys/heap, num_goroutine, num_gc, tracked_repos, sessions, lsp_alive, graph nodes/edges. Ticker only runs while ≥1 subscriber is attached |
| `unsubscribe_daemon_health` | Opt back out — idempotent; stops the ticker when the last subscriber leaves |
| `subscribe_stale_refs` | `notifications/stale_refs` — per-session intersect of watcher symbol-change events against the session's viewed/modified symbols + files. Fires only when a change actually touches what *this* session has consumed |
| `unsubscribe_stale_refs` | Opt back out — idempotent |
### Coding Workflow
| Tool | Description |
|------|-------------|
| `get_symbol_source` | Source code of a single symbol (80% fewer tokens than Read). Returns `tokens_saved` per call |
| `batch_symbols` | Multiple symbols with source/callers/callees in one call |
| `find_import_path` | Correct import path for a symbol |
| `explain_change_impact` | Risk-tiered blast radius with affected processes |
| `get_recent_changes` | Files/symbols changed since timestamp |
| `edit_symbol` | Edit a symbol's source directly by ID — no Read needed |
| `edit_file` | Edit any file (markdown, config, spec, template, source) by exact string replacement — accepts absolute paths or repo-rooted paths. Kills the Read-before-Edit stall on files not in the graph |
| `write_file` | Create or overwrite any file with given content — atomic temp+rename, re-indexes on write |
| `rename_symbol` | Coordinated multi-file rename with all references |
### Agent-Optimized (token efficiency)
| Tool | Description |
|------|-------------|
| `smart_context` | Task-aware minimal context — replaces 5-10 exploration calls |
| `get_edit_plan` | Dependency-ordered edit sequence for multi-file refactors |
| `get_test_targets` | Maps changed symbols to test files and run commands |
| `get_untested_symbols` | Inverse of `get_test_targets` — functions/methods not reached from any test file, ranked by fan-in |
| `suggest_pattern` | Extracts code pattern from an example — source, registration, tests |
| `export_context` | Portable markdown/JSON context briefing for sharing outside MCP |
| `feedback` | `action: "record"`: report useful/missing symbols. `action: "query"`: aggregated stats — most useful, most missed, accuracy metrics |
| `ask` | Optional in-process LLM research agent (`-tags llama` + `llm.model`) — navigates the graph and returns a synthesized answer; `chain: true` for cross-repo call-chain tracing |
### Analysis
| Tool | Description |
|------|-------------|
| `get_communities` | Functional clusters (Louvain). Without `id`: list all. With `id`: members and cohesion for one community |
| `get_processes` | Discovered execution flows. Without `id`: list all. With `id`: step-by-step trace |
| `detect_changes` | Git diff mapped to affected symbols |
| `index_repository` | Index or re-index a repository path |
| `contracts` | API contracts. `action: "list"` (default): detected HTTP/gRPC/GraphQL/topics/WebSocket/env/OpenAPI. `action: "check"`: orphan providers/consumers |
| `find_co_changing_symbols` | Ranked git co-change neighbours for a symbol — files that historically change together, over the mined cosine-weighted `co_change` edge layer |
| `search_artifacts` | Full-text search over the context-artifacts manifest — DB schemas, API specs, infra configs, ADRs registered via the `.gortex.yaml::artifacts` block |
| `get_artifact` | Fetch one context artifact by id, with its content and the symbols it references |
### Proactive Safety
| Tool | Description |
|------|-------------|
| `verify_change` | Check proposed signature changes against all callers and interface implementors |
| `check_guards` | Evaluate project guard rules (`.gortex.yaml`) against changed symbols |
| `audit_agent_config` | Scan CLAUDE.md / AGENTS.md / `.cursor/rules` / `.github/copilot-instructions.md` / `.windsurf/rules` / `.antigravity/rules` for stale symbol references, dead file paths, and bloat — validated against the Gortex graph (no other competitor does this) |
### Code Quality
| Tool | Description |
|------|-------------|
| `analyze` | Unified graph analysis dispatcher. `kind` ∈ `dead_code`, `hotspots`, `cycles`, `would_create_cycle`, `todos`, `blame`, `coverage`, `coverage_gaps`, `coverage_summary`, `stale_code`, `stale_flags`, `ownership`, `releases`, `cgo_users`, `wasm_users`, `orphan_tables`, `unreferenced_tables`, `channel_ops`, `goroutine_spawns`, `field_writers`, `race_writes`, `unclosed_channels`, `unsafe_patterns`, `health_score`, `impact`, `annotation_users`, `config_readers`, `env_var_users`, `sql_call_sites`, `fixes_history`, `edge_audit`, `domain`, `named`, `tests_as_edges`, `clusters`, `event_emitters`, `pubsub`, `string_emitters`, `error_surface`, `log_events`, `sql_rebuild`, `external_calls`, `routes`, `models`, `components`, `k8s_resources`, `images`, `kustomize`, `cross_repo`, `dbt_models`. `clusters` takes an `algorithm` arg (`leiden` / `louvain` / `spectral`) |
| `find_clones` | Near-duplicate function/method clusters from the MinHash + LSH `similar_to` layer; `dead_only: true` finds dead duplicates of live code |
| `index_health` | Health score, parse failures, stale files, language coverage |
| `get_symbol_history` | Symbols modified this session with counts; flags churning (3+ edits) |
### Code Generation
| Tool | Description |
|------|-------------|
| `scaffold` | Generate code, registration wiring, and test stubs from an example symbol |
| `batch_edit` | Apply multiple edits in dependency order, re-index between steps |
| `diff_context` | Git diff enriched with callers, callees, community, processes, per-file risk |
| `prefetch_context` | Predict needed symbols from task description and recent activity. Accepts `max_bytes` / `max_tokens` budget caps |
### Multi-Repo Management
| Tool | Description |
|------|-------------|
| `track_repository` | Add a repo at runtime — indexes immediately, persists to global config |
| `untrack_repository` | Remove a repo — evicts nodes/edges, persists to global config |
| `set_active_project` | Switch active project scope for all subsequent queries |
| `get_active_project` | Return current project name and its member repositories |
| `list_repos` | List every project/repo in the active workspace |
| `workspace_info` | Workspace identity — bind mode, root directory, marker contents, discovered member set |
### Live Editor Buffers (Shadow-Graph Overlay Sessions)
Editor extensions push in-flight (unsaved) buffers as **overlays**. Gortex composes a per-request **shadow view** on top of the immutable base graph and threads it through the tool dispatch context — every subsequent `tools/call` from the same MCP session reads through the shadow. Graph-walking tools (`find_usages`, `get_call_chain`, `analyze`, …) and source-reading tools (`get_symbol_source`, `get_editing_context`, …) all see the editor-buffer state without per-tool changes.
**Base is never mutated by overlay flow.** Concurrent sessions (multiple users, multiple windows of the same user) each see their own view; the file watcher's reindex passes don't race with overlay queries; cross-file edges from non-overlaid files into overlaid symbols (`Caller → Target`) are preserved.
| Tool | Description |
|------|-------------|
| `overlay_register` | Bind an overlay session to the current MCP session ID (idempotent) |
| `overlay_push` | Push (or update) a single file overlay; `base_sha` enables drift detection, `deleted: true` previews a delete |
| `overlay_list` | List every overlay attached to the session — path / size / deleted / base_sha |
| `overlay_delete` | Remove one overlay from the session |
| `overlay_drop` | Tear down the session and discard every overlay |
| `overlay_keepalive` | Refresh the session's idle timer without re-pushing buffer content; cheap option for debugger / wizard pauses |
| `compare_with_overlay` | Run `find_usages` / `get_callers` / `get_call_chain` / `get_dependencies` / `get_dependents` against base AND overlay; returns added / removed / common ID sets |
HTTP transport mirrors the surface at `/v1/overlay/sessions/*`; the `/v1/tools/` entry point reads the overlay session from `Mcp-Session-Id` (preferred), `X-Gortex-Overlay-Session`, or `?session_id=`. **Overlays are bound to their MCP session** — when the session ends the overlay is dropped synchronously, so abandoned buffers never linger. Idle TTL is a fail-safe (default 30 min, configurable via `GORTEX_OVERLAY_IDLE_TTL`); every tool call against a live overlay refreshes it.
### MCP 2026 Streamable HTTP transport (`/mcp`)
`gortex server` and `gortex daemon --http-addr ` both expose the **MCP 2026 Streamable HTTP transport** — the wire format the June 2026 MCP release locks in.
| Verb | Path | Behaviour |
|------|------|-----------|
| `POST` | `/mcp` | One or more JSON-RPC frames in, one or a JSON-RPC array out. Notification-only batches return 202. |
| `GET` | `/mcp` | Opens an SSE stream the server uses to push server-initiated notifications (progress, sampling) onto the bound session. |
| `DELETE` | `/mcp` | Terminates a session. Idempotent — returns 204 even when the id is unknown. |
| `OPTIONS` | `/mcp` | CORS preflight; advertises the allowed methods. |
**Stateless per request.** Every POST carries `Mcp-Session-Id`; the transport replays the matching state out of a `streamable.SessionStore` (the default in-memory `MemoryStore` is TTL-evicted; swap for a Redis-backed adapter to share state across replicas behind a load balancer). `initialize` mints the id and returns it on the response header; an unknown id replies with a JSON-RPC `-32001 session not found` envelope. The `Mcp-Protocol-Version` header is echoed when provided; absent, the transport advertises its default. `tools/call` frames flow through the same multi-server router that serves `/v1/tools/`, so workspace scoping carries over unchanged.
**Daemon enablement.** `gortex daemon start --http-addr 127.0.0.1:7411 [--http-auth-token ]` brings the transport up alongside the unix-socket dispatcher. Non-localhost binds require an auth token (or `$GORTEX_DAEMON_HTTP_TOKEN`). `/healthz` is exempt so liveness probes work. `gortex server` mounts `/mcp` unconditionally alongside the legacy `/v1/*` surface — no flag needed.
### Speculative Execution (Simulation Sessions)
Built on the same shadow-graph substrate, `preview_edit` and `simulate_chain` answer **"what would change if I applied this WorkspaceEdit?"** without ever touching disk or mutating the base graph. The input is a standard LSP `WorkspaceEdit` (`changes` / `documentChanges`), so any agent that already produces WorkspaceEdits for code actions can speculate on them directly. Per-step impact: touched files, added / removed / renamed symbols (non-trivial-signature rename heuristic), broken callers, broken interface implementors, blast-radius rollup, suggested test targets, and (when an LSP is configured) round-trip diagnostics restored to the on-disk state at simulation end.
| Tool | Description |
|------|-------------|
| `preview_edit` | Single-shot WorkspaceEdit → impact report. Optional `diagnostics: false` skips the LSP round-trip. `inherit_overlay: true` layers on top of the caller's current overlay. |
| `simulate_chain` | Ordered sequence of WorkspaceEdits applied in order with per-step impact + cumulative rollup + per-step diagnostics delta. `stop_on_error: true` (default) aborts on the first new ERROR-severity diagnostic. `keep: true` promotes the final simulated state into a real overlay session bound to the caller — the response carries `overlay_session_id` for follow-up commit / discard / `compare_with_overlay`. |
**First-of-segment:** no graph-intel competitor has predictive impact + WorkspaceEdit-driven simulation + diagnostics round-trip in one MCP surface.
## MCP Resources (16)
Read-only, URI-addressable, no args. Clients that speak resources can `resources/subscribe` once and receive `notifications/resources/updated` after each graph re-warm — no polling.
| Resource | Description |
|----------|-------------|
| `gortex://session` | Current session state and activity |
| `gortex://stats` | Graph statistics (node/edge counts) |
| `gortex://schema` | Graph schema reference |
| `gortex://index-health` | Health score, parse failures, stale files |
| `gortex://workspace` | Workspace identity and discovered member set |
| `gortex://repos` | Tracked repo / project list |
| `gortex://active-project` | Active project name and member repos |
| `gortex://communities` | Community list with cohesion scores |
| `gortex://community/{id}` | Single community detail |
| `gortex://processes` | Execution flow list |
| `gortex://process/{id}` | Single process trace |
| `gortex://report` | High-level orientation — graph size, top languages/kinds, hotspot / dead-code / todo counts |
| `gortex://god-nodes` | Top 20 hotspots |
| `gortex://surprises` | Cycles + dead code + cross-community call hubs |
| `gortex://audit` | `audit_agent_config` with discovery defaults |
| `gortex://questions` | TODO / FIXME / XXX / HACK / QUESTION rollup grouped by tag and assignee |
## MCP Prompts (3)
| Prompt | Description |
|--------|-------------|
| `pre_commit` | Review uncommitted changes — shows changed symbols, blast radius, risk level, affected tests |
| `orientation` | Orient in an unfamiliar codebase — graph stats, communities, execution flows, key symbols |
| `safe_to_change` | Analyze whether it's safe to change specific symbols — blast radius, edit plan, affected tests |
## Web UI
The web UI lives in its own repo at [`gortexhq/web`](https://github.com/gortexhq/web) so it can be deployed independently of the backend (Vercel / a static host / your own Next.js deployment). It's a standalone Next.js 15 app that talks to `gortex server` over `/v1/*`:
```bash
# 1) Start the HTTP backend (localhost:4747 by default, bearer-auth in non-localhost binds)
gortex server --index /path/to/repo --watch
# 2) Clone and run the UI in another terminal
git clone https://github.com/gortexhq/web.git gortex-web && cd gortex-web
echo 'NEXT_PUBLIC_GORTEX_URL=http://localhost:4747' > .env.local
npm install && npm run dev
# Open http://localhost:3000
```
| Page | Features |
|------|----------|
| **Dashboard** | Health, stats, language pie chart, node kind bar chart |
| **Graph Explorer** | Sigma.js 2D + five react-three-fiber 3D modes (City / Strata / Galaxies / Constellation / Graph3D), node filters, selection, detail panel |
| **Search** | Semantic + BM25 search via `/v1/*`, results grouped by kind |
| **Symbol Detail** | Source code, signature, callers/callees/usages/deps tabs |
| **Communities** | Community cards with cohesion bars, expandable members |
| **Processes** | Collapsible call-tree steps, product vs test process split |
| **Analysis** | Dead code, hotspots, cycles, index health — 4 tabs |
| **Contracts** | API contracts (HTTP, gRPC, GraphQL, topics, WebSocket, env vars) with provider/consumer matching, request/response type tracing, `yours / tests / deps / all` scope filter |
| **Services** | Service-level graph visualization with per-repo stats |
| **AI Chat** | LLM-powered chat with code context (placeholder) |
## Server Mode
The `gortex server` command exposes all MCP tools as an HTTP/JSON API under versioned `/v1/*` routes:
```bash
# Standalone HTTP backend (default bind 127.0.0.1:4747)
gortex server --index /path/to/repo --watch
# Non-localhost bind requires an auth token
gortex server --index . --bind 0.0.0.0 --auth-token "$(openssl rand -hex 32)"
# HTTP API alongside MCP stdio (same process)
gortex mcp --index /path/to/repo --server --port 8765
```
**Endpoints (all under `/v1/`):**
| Endpoint | Method | Description |
|----------|--------|-------------|
| `/v1/health` | GET | Status, node/edge counts, uptime |
| `/v1/tools` | GET | List all available tools with descriptions |
| `/v1/tools/{name}` | POST | Invoke any MCP tool with JSON arguments. Accepts `?format=gcx` or top-level `"format"` in the body |
| `/v1/stats` | GET | Graph statistics by kind and language, plus `server_id` + `started_at` |
| `/v1/graph` | GET | Full brief-graph dump (nodes + edges + stats); accepts `?project=` and/or `?repo=` for scoping |
| `/v1/events` | GET | SSE stream of graph-change events (requires `--watch`). Accepts `?token=` for `EventSource` auth |
**Auth & binding.** The server defaults to `--bind 127.0.0.1` and runs unauthenticated on localhost only (logs `server: unauthenticated mode; localhost only`). Set `--auth-token ` or `$GORTEX_SERVER_TOKEN` to require `Authorization: Bearer ` on every `/v1/*` request (constant-time compare; CORS preflights bypass). Non-localhost binds without a token are rejected at startup. CORS origin is configurable via `--cors-origin` (default `*`). `--bind` also accepts `unix:///path/to.sock` for a Unix-domain socket.
**Scoping the graph.** Pass `--workspace ` to restrict both indexing and queries to repos that resolve to that workspace, and `--scope-project ` to narrow further. A scope that matches zero tracked repos errors out at startup rather than silently producing an empty graph.
**Multi-server roster.** When the daemon is running, it can route MCP traffic across multiple Gortex servers — a local Unix socket for the repos on this machine, plus one or more remote HTTPS servers for shared / cloud indexes. The roster lives at `~/.gortex/servers.toml`; manage it with `gortex daemon server list / add / remove`. Auth tokens can be embedded directly (`--auth-token`) or pulled from an env var the daemon reads at request time (`--auth-token-env`, preferred). Restart the daemon to pick up roster changes.
## Cross-Repo API Contracts
Gortex detects API contracts across repos and matches providers to consumers:
```bash
# After indexing, contracts are auto-detected
gortex server --index .
# Via MCP tools
contracts # list all detected contracts (default action)
contracts {action: "check"} # find mismatches and orphans
```
| Contract Type | Detection | Provider | Consumer |
|--------------|-----------|----------|----------|
| **HTTP Routes** | Framework annotations (gin, Express, FastAPI, Spring, etc.) | Route handler | HTTP client calls (fetch, http.Get) |
| **gRPC** | Proto service definitions | Service RPC | Client stub calls |
| **GraphQL** | Schema type/field definitions | Schema | Query/mutation strings |
| **Message Topics** | Pub/sub patterns (Kafka, NATS, RabbitMQ) | Publish calls | Subscribe calls |
| **WebSocket** | Event emit/listen patterns | emit() | on() |
| **Env Vars** | os.Getenv, process.env, .env files | Setenv / .env | Getenv / process.env |
| **OpenAPI** | Swagger/OpenAPI spec files | Spec paths | (linked to HTTP routes) |
| **Temporal Workflows** | Go SDK `worker.RegisterActivity` / Java `@ActivityInterface` / `@WorkflowInterface` annotations | Activity / workflow function (carries `temporal_role` Meta) | `workflow.ExecuteActivity` / `ExecuteChildWorkflow` / `newActivityStub` calls |
Contracts are normalized to canonical IDs (e.g., `http::GET::/api/users/{id}`) and matched across repos to detect orphan providers/consumers and mismatches.
## Per-Community Skills
`gortex init --skills` (default on) analyzes your codebase, detects functional communities via Louvain clustering, and generates targeted SKILL.md files that Claude Code auto-discovers:
```bash
# Runs as part of `gortex init` by default — community generation is folded in
gortex init
# Tune or disable:
gortex init --skills-min-size 5 --skills-max 10
gortex init --no-skills
```
Each generated skill includes:
- **Community metadata** — size, file count, cohesion score
- **Key files table** — files and their symbols
- **Entry points** — main functions, handlers, controllers detected via process analysis
- **Cross-community connections** — which other areas this community interacts with
- **MCP tool invocations** — pre-written `get_communities`, `smart_context`, `find_usages` calls
For Claude Code, skills are written to `.claude/skills/generated//SKILL.md`, and a routing table is inserted into `CLAUDE.md` between `` markers. Every other detected agent gets the same routing table inside its per-repo instructions surface (`AGENTS.md` for Codex/OpenCode, `.windsurfrules` for Windsurf, `GEMINI.md` for Gemini CLI, `.cursor/rules/gortex-communities.mdc` for Cursor, etc.) — so the routing is consistent across tools on the same repo.
## Semantic Search
Hybrid BM25 + vector search with Reciprocal Rank Fusion (RRF). Multiple embedding tiers:
```bash
# Built-in word vectors (always available, zero setup)
gortex mcp --index . --embeddings
# Ollama (best quality, local)
ollama pull nomic-embed-text
gortex mcp --index . --embeddings-url http://localhost:11434
# OpenAI (best quality, cloud)
gortex mcp --index . --embeddings-url https://api.openai.com/v1 \
--embeddings-model text-embedding-3-small
```
| Tier | Flag | Quality | Offline | Default build? |
|------|------|---------|---------|----------------|
| Hugot (pure Go) | `--embeddings` | Good (MiniLM-L6-v2) | Yes (model auto-downloads on first use) | **Yes** |
| Built-in | `--embeddings` (when Hugot unavailable) | Basic (GloVe word averaging) | Yes | Yes |
| API | `--embeddings-url` | Best (transformer model) | No | Yes |
| ONNX | `--embeddings` + build tag | Best | Yes (model + libonnxruntime required) | No |
| GoMLX | `--embeddings` + build tag | Good | Yes (XLA plugin auto-downloads) | No |
The default build ships with Hugot using the pure-Go ONNX runtime — no native dependencies, no manual model placement. The MiniLM-L6-v2 model downloads to `~/.cache/gortex/models/` on first use (~90 MB).
Opt-in faster backends via build tags:
```bash
go build -tags embeddings_onnx ./cmd/gortex/ # needs: brew install onnxruntime
go build -tags embeddings_gomlx ./cmd/gortex/ # auto-downloads XLA plugin
```
## LLM Features (optional)
Gortex can delegate code-intelligence work to an LLM. Two features, both **off by default** and gated on configuring a provider:
- **`ask` MCP tool** — a research agent that drives Gortex's own tools (search, callers, contracts, dependencies) to answer an open-ended question and returns a synthesized answer, instead of the calling agent issuing many tool calls itself. `chain: true` traces cross-system call chains.
- **`search_symbols` `assist` arg** — LLM-assisted ranking on `search_symbols`: `auto` (engage on natural-language queries only), `on`, `off`, `deep` (adds a body-grounded verification pass that reads candidate code + callers and honestly drops irrelevant matches).
### Providers
The backend is chosen by the `llm.provider` key. Seven of the eight providers are pure Go — available in any build; only `local` needs a `-tags llama` build (it embeds llama.cpp).
| `llm.provider` | Backend | Needs |
|----------------|---------|-------|
| `local` | in-process llama.cpp | a `-tags llama` build + a `.gguf` model file |
| `anthropic` | Anthropic Messages API | `ANTHROPIC_API_KEY` |
| `openai` | OpenAI Chat Completions | `OPENAI_API_KEY` |
| `ollama` | Ollama daemon | a running Ollama + a pulled model |
| `claudecli` | Claude Code CLI subprocess | the `claude` binary on `$PATH` (signed in once). **No API key — reuses your Claude Code subscription.** |
| `gemini` | Google Gemini `generateContent` REST | `GEMINI_API_KEY` |
| `bedrock` | AWS Bedrock Converse API (SigV4-signed, no AWS SDK) | `AWS_ACCESS_KEY_ID` + `AWS_SECRET_ACCESS_KEY` (+ optional `AWS_SESSION_TOKEN`) |
| `deepseek` | DeepSeek Chat Completions (OpenAI-compatible) | `DEEPSEEK_API_KEY` |
### Configuration
The `llm:` block goes in `~/.config/gortex/config.yaml` or a per-repo `.gortex.yaml` (repo-local wins per field, global fills the rest). Configure only the provider you use:
```yaml
# ~/.config/gortex/config.yaml (or per-repo .gortex.yaml)
llm:
provider: local # local | anthropic | openai | ollama | claudecli | gemini | bedrock | deepseek
max_steps: 16 # agent tool-loop cap (provider-agnostic)
local: # provider: local — requires a `-tags llama` build
model: ~/models/qwen2.5-coder-7b-instruct-q4_k_m.gguf
ctx: 4096 # context window in tokens
gpu_layers: 999 # layers to offload to GPU (0 = CPU-only)
template: chatml # chatml | llama3
anthropic: # provider: anthropic
model: claude-sonnet-4-6
api_key_env: ANTHROPIC_API_KEY # env var holding the key (this is the default)
# base_url: https://api.anthropic.com
openai: # provider: openai
model: gpt-4o
api_key_env: OPENAI_API_KEY
ollama: # provider: ollama
model: qwen2.5-coder:7b
host: http://localhost:11434
claudecli: # provider: claudecli — spawns the `claude` CLI per call
# binary: claude # binary name or absolute path (resolved via $PATH; default "claude")
model: sonnet # optional — forwarded as `--model`; empty = CLI default
# args: ["--allowed-tools", ""] # extra args appended after our flags (disable tools, etc.)
# timeout_seconds: 180 # cap per Complete call; 0 → 120s
gemini: # provider: gemini — Google Gemini generateContent REST
model: gemini-2.5-pro
api_key_env: GEMINI_API_KEY
# base_url: https://generativelanguage.googleapis.com
bedrock: # provider: bedrock — AWS Bedrock Converse API (SigV4-signed)
model_id: anthropic.claude-sonnet-4-20250514-v1:0
region: us-east-1
# access_key_env: AWS_ACCESS_KEY_ID
# secret_key_env: AWS_SECRET_ACCESS_KEY
# session_token_env: AWS_SESSION_TOKEN # optional — for STS-issued creds
# base_url: https://bedrock-runtime.us-east-1.amazonaws.com # override for VPC endpoints
deepseek: # provider: deepseek — OpenAI-compatible Chat Completions
model: deepseek-chat
api_key_env: DEEPSEEK_API_KEY
# base_url: https://api.deepseek.com
```
Env overrides: `GORTEX_LLM_PROVIDER`, `GORTEX_LLM_MODEL` (targets the active provider's model — including `gemini`, `bedrock` (sets `model_id`), `deepseek`, `claudecli`), `GORTEX_LLM_MAX_STEPS`, `GORTEX_LLM_CLAUDECLI_BINARY`, and `GORTEX_LLM_BEDROCK_REGION`. API keys are read from the env var named by `api_key_env` — never stored in the config file.
If the active provider can't be constructed (missing model or API key, `local` without a `-tags llama` build, `claudecli` without the `claude` binary on `$PATH`, `bedrock` without AWS credentials), the daemon logs a warning and the LLM features stay absent — the rest of Gortex is unaffected. If the `ask` tool isn't in `tools/list`, no provider is configured.
The `assist` prompts are tiered automatically — terser for hosted frontier models, rule-heavy for small local ones. `deep` mode in particular benefits from a 7B-class or hosted model; small local models are unreliable on its disambiguation cases.
## Token Savings
Gortex tracks how many tokens it saves compared to naive file reads — per-call, per-session, and cumulative across restarts:
- **Per-call:** `get_symbol_source` and other source-reading tools include a `tokens_saved` field in the response, showing the difference between reading the full file vs the targeted symbol.
- **Session-level:** `graph_stats` returns a `token_savings` object with `calls_counted`, `tokens_returned`, `tokens_saved`, `efficiency_ratio`.
- **Cumulative (cross-session):** `graph_stats` also returns `cumulative_savings` when persistence is wired — includes `first_seen`, `last_updated`, and `cost_avoided_usd` per model (Claude Opus/Sonnet/Haiku, GPT-4o, GPT-4o-mini). Backed by `~/.cache/gortex/savings.json` (top-line totals + per-repo + per-language) and a sibling `~/.cache/gortex/savings.jsonl` event log (one line per call) used to render the windowed buckets and the per-tool breakdown.
`gortex savings` renders a three-bucket dashboard:
```text
Gortex Token Savings
====================
Cost avoided: $168.69 (claude-opus-4) across 1,878 calls · 11,246,094 tokens saved
Today ████████░░░░░░░░ 50.0% saved 9,200 / 18,400 tokens $0.14
Last 7 days ██████████░░░░░░ 62.5% saved 60,100 / 96,200 tokens $0.90
All time ███████████████░ 93.3% saved 11,246,094 / 12,050,716 tokens $168.69
```
```bash
# Three-bucket dashboard with USD on top
gortex savings
# Per-tool breakdown inside each bucket
gortex savings --verbose
# Headline a single model (fuzzy match: "opus" → claude-opus-4)
gortex savings --model opus
# Bucket "Today" by UTC instead of local time
gortex savings --utc
# Machine-readable output (mirrors the dashboard structure: buckets[].per_tool, cost_avoided_usd, etc.)
gortex savings --json
# Wipe cumulative totals and the JSONL event log
gortex savings --reset
# Override pricing (JSON array of {model, usd_per_m_input})
GORTEX_MODEL_PRICING_JSON='[{"model":"mycorp","usd_per_m_input":5}]' gortex savings
```
Token counts use **tiktoken (`cl100k_base`)** — the tokenizer Claude and GPT-4 actually use — via `github.com/pkoukk/tiktoken-go` with an embedded offline BPE loader, so no runtime downloads. The BPE is lazy-loaded on first call. If init fails for any reason, the package falls back to the legacy `chars/4` heuristic so metrics stay usable.
## Graph Persistence
Gortex snapshots the graph to disk on shutdown and restores it on startup, with incremental re-indexing of only changed files:
```bash
# Default cache directory: ~/.cache/gortex/
gortex mcp --index /path/to/repo
# Custom cache directory
gortex mcp --index /path/to/repo --cache-dir /tmp/gortex-cache
# Disable caching
gortex mcp --index /path/to/repo --no-cache
```
The persistence layer uses a pluggable backend interface (`persistence.Store`). The default backend serializes as gob+gzip. Cache is keyed by repo path + git commit hash, with version validation to invalidate on binary upgrades.
## Scale — battle-tested on large repos
Measured on an Apple Silicon laptop with the default CGO build:
| Repository | Files | Nodes | Edges | Index time | Throughput | Peak heap |
| ---------- | ----: | ----: | ----: | ---------: | ---------: | --------: |
| [torvalds/linux](https://github.com/torvalds/linux) | 70,333 | 1,690,174 | 6,239,570 | ~3 min | 300 files/s | 5.07 GB |
| [microsoft/vscode](https://github.com/microsoft/vscode) | 10,762 | 204,501 | 808,902 | ~1 min | 143 files/s | 580 MB |
| zzet/gortex (self) | 430 | 5,583 | 53,830 | 3.4s | 127 files/s | 52 MB |
Parsing dominates wall time (65–80%); reference resolution and search-index build scale sub-linearly. Everything runs in-process — no external services, no database, no network.
## Architecture
```
gortex binary
CLI (cobra) ──> MultiIndexer ──> In-Memory Graph (shared, per-repo indexed)
MCP (stdio) ──────────────────> Query Engine (repo/project/ref scoping)
HTTP /v1/* ──────────────────> same tools + /v1/graph + /v1/events (SSE)
Daemon (unix) ──────────────────> shared graph for every MCP client, session isolation
MCP Prompts ──────────────────> (pre_commit, orientation, safe_to_change)
MCP Resources ──────────────────> (16 read-only URIs — bootstrap state + analyzer rollups)
MultiWatcher <── filesystem events (fsnotify, per-repo)
CrossRepoResolver ──> cross-repo edge creation (type-aware)
Persistence ──> gob+gzip snapshot (pluggable backend)
```
**Data flow:**
1. On startup, loads cached graph snapshot if available; otherwise performs full indexing
2. MultiIndexer walks each repo directory concurrently, dispatches files to language-specific extractors (tree-sitter)
3. Extractors produce nodes (files, functions, types, etc.) and edges (calls, imports, defines, etc.) with type environment metadata
4. In multi-repo mode, nodes get `RepoPrefix` and IDs become `/::`
5. Resolver links cross-file references with type-aware method matching; CrossRepoResolver links cross-repo references with same-repo preference
6. Query Engine answers traversal queries with optional repo/project/ref scoping
7. MultiWatcher detects changes per-repo and surgically patches the graph (debounced per-file), then re-resolves cross-repo edges
8. On shutdown, persists graph snapshot for fast restart
## Graph Schema
**Node kinds:**
- Code structure: `file`, `package`, `function`, `method`, `type`, `interface`, `field`, `variable`, `constant`, `import`, `contract`, `param`, `closure`, `enum_member`, `generic_param`
- Coverage extensions: `module`, `table`, `column`, `config_key`, `flag`, `event`, `migration`, `fixture`, `todo`, `team`, `license`, `release`
- Infrastructure: `resource` (K8s manifest), `kustomization` (Kustomize overlay), `image` (Dockerfile FROM / K8s `container.image`)
**Edge kinds:**
- Calls / structure: `calls`, `imports`, `defines`, `implements`, `extends`, `overrides`, `references`, `member_of`, `instantiates`, `provides`, `consumes`, `composes`, `aliases`, `typed_as`, `returns`, `captures`, `param_of`
- Concurrency / mutation: `spawns`, `sends`, `recvs`, `reads`, `writes`, `reads_config`, `writes_config`
- Dataflow (CPG-lite): `value_flow`, `arg_of`, `returns_to`
- Metadata: `annotated`, `emits`, `throws`, `queries`, `reads_col`, `writes_col`, `toggles_flag`, `depends_on_module`, `matches`, `generated_by`, `tests`, `covered_by`, `owns`, `authored`, `licensed_as`
- Framework / infrastructure: `handles_route`, `models_table`, `renders_child`, `configures`, `mounts`, `exposes`, `depends_on`, `uses_env`
- Similarity: `similar_to` (MinHash + LSH near-duplicate clones; `Meta["similarity"]` carries the estimated Jaccard score)
- Cross-repo: `cross_repo_calls` / `cross_repo_implements` / `cross_repo_extends` — materialised whenever a `calls` / `implements` / `extends` edge's endpoints live in different repos
**Multi-repo fields:** Nodes carry `repo_prefix` (empty in single-repo mode). Edges carry `cross_repo` (true when connecting nodes in different repos). Node IDs use `/::` format in multi-repo mode.
**Test taxonomy:** functions and methods in test files carry `Meta["is_test"]` + `Meta["test_role"]` (`test` / `benchmark` / `fuzz` / `example`) + `Meta["test_runner"]`. The runner identifier is one of `gotest` / `pytest` / `unittest` / `rspec` / `minitest` / `test-unit` / `jest` / `vitest` / `mocha` / `bun-test` / `node-test` / `playwright` / `cypress`, resolved from parser-stamped imports (JS / TS) with a Mocha-TDD `suite()` byte fallback and language-default fill-in (Go is always `gotest`, Python defaults to `pytest`, Ruby uses the `_spec.rb` / `_test.rb` suffix). The owning `KindFile` also gets the same `test_runner` stamp so file-level queries can group tests by runner without walking functions.
## Language Support
Gortex indexes **257 languages** across three tiers (bespoke tree-sitter, regex, and forest-backed signature-only), plus cell-structured notebooks (Jupyter `.ipynb` + Databricks `.dbc` and source-format notebooks) — see **[docs/languages.md](docs/languages.md)** for the full table (extensions, engine, extracted symbols per language).
## Building
```bash
make build # Build with version from git tags
make test # go test -race ./...
make bench # Run all benchmarks
make lint # golangci-lint
make fmt # gofmt -s
make install # go install with version ldflags
```
Requires Go 1.26+ and CGO enabled (for tree-sitter C bindings).
## License
Gortex is **source-available** under a custom license based on PolyForm Small Business. See [LICENSE.md](LICENSE.md) for full terms.
**Free for:** individuals, open-source projects, small businesses (<50 employees / <$500K revenue), nonprofits, education, government, socially critical orgs.
**Commercial license required for:** organizations with 50+ employees or $500K+ revenue, competing products, resale/bundling. Contact [license@zzet.org](mailto:license@zzet.org).
**Contributors:** active contributors listed in [CONTRIBUTORS.md](CONTRIBUTORS.md) receive a free non-competing commercial license for their employer.
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines on adding features, language extractors, and submitting PRs. Active contributors receive a [contributor commercial license](LICENSE.md#part-3-contributor-license).