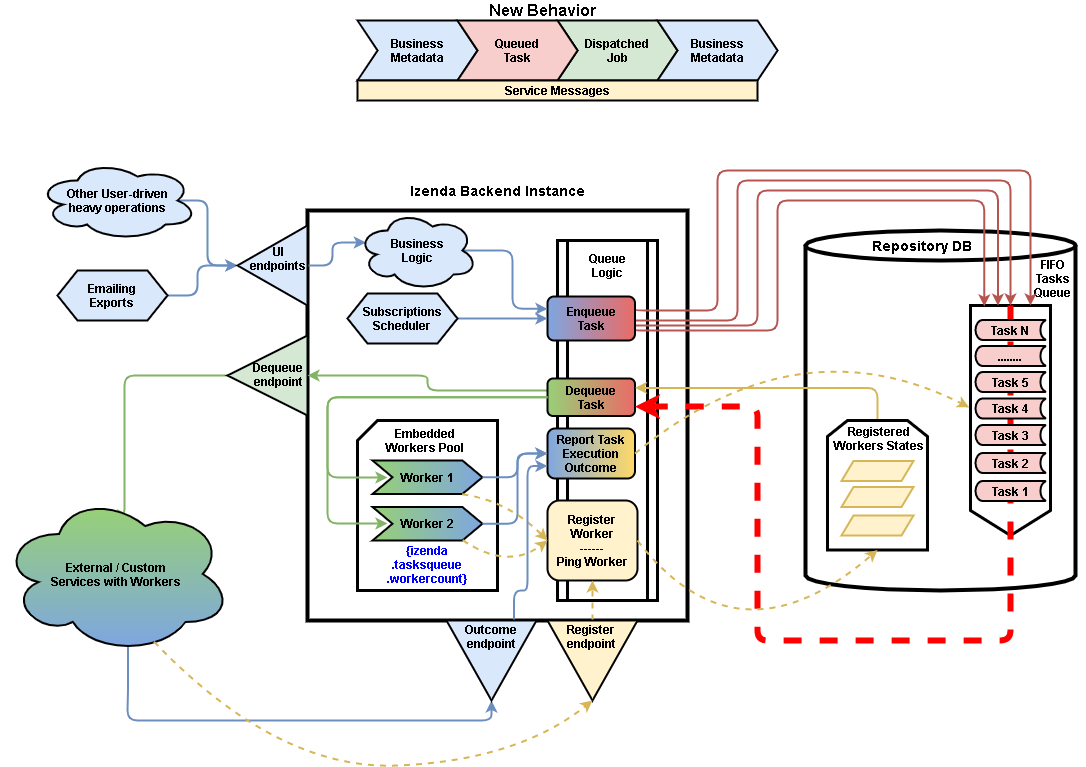
Generic Queue mechanism for heavy load operations¶
Izenda implemented a scalable solution to support the Task queue job where alerts and subscriptions which start at the same time will be performed sequentially to handle the load of the server.
The Queue mechanism provides the possibility for execution of heavy load operations:
- Sequentially, one by one, occupying strictly predetermined number of threads to avoid Izenda instance (or service node) overload
- Allowing for both embedded (native) workers, and easily implementable external workers, to distribute load related to jobs execution across dynamically spun-up services/nodes
- In a failproof manner:
- Failed/crashed workers get re-instantiated;
- Halfway terminated jobs will be executed again;
- Jobs exceeded execution timeout, get “timedOut” flag to avoid repeat tries to execute;
The implemented Queue mechanism consists of two storages (tables) in Repository DB.
First one is Queued Tasks storage, which both keeps, and orders (prioritizes) Tasks for sequential execution. Currently it behaves as a simple FIFO buffer, so Tasks are dispatched for processing in the order, in which they were inserted into Queue.
Second is Registered Workers, which keeps IDs of “known” Workers, and tracks their health by regular “alive” pings issued by Workers. Worker can be any service/node/routine/webapp, which is able to process some of Izenda jobs, and implements simplest interactions with Queue Logic module in Izenda. Each Worker can request and serve either one kind of Task/Job, or a few of them, or even all of them - whatever is its implementation.
Also, there are internal (embedded) Workers in Izenda backend, which can process all kinds of Tasks/Jobs, in case when customer doesn’t want to deploy external services/Workers.
The Queue Logic module in the Izenda backend exposes following methods (endpoints) for Workers:
- Enqueue Task
- It accepts (enum) JobKind, (Guid) JobEntityId and (string) JobData values, representing / describing data related to job to be performed.
- Note that sometimes Workers will need be able to pull some additional data.
- For example, pull the Subscription object from WebAPI / Repository by its Id provided in JobEntityId.
- It returns the (Guid) Id of the enqueued Task, to allow for its progress tracking.
- Register Worker
- It accepts just an empty request, and returns the (Guid) Id, which will identify given worker
- Alive Ping
- It accepts the request with (Guid) Id identifying given Worker, and prolongs its “health / validity” for another period of time (specified in Queue mechanism configuration).
- It returns (bool) True if Worker validity was successfully prolonged, and (bool) False if Worker was somehow considered expired / corrupted, and should recycle.
- Dequeue Task
- It accepts the request with Worker-identifying (Guid) Id, checks for Worker “health / validity” in RegisteredWorkers table, and if it’s fine, then picks “oldest” Task from QueueTasks table and returns it to given Worker in response for processing
- Set Job Execution Outcome
- It accepts the (Guid) Id of Task, the (enum) Outcome (which can be Succeeded, Failed, or TimedOut), and the (Guid) Id of the Worker, (because there is possibility that some Worker implementations can dequeue and process a few Tasks simultaneously).
- Then it checks for given Worker validity, and if it’s fine, then updates Task, effectively removing it from the Queue.
Recommended Workflow¶
There are no strict requirements for Workers implementations apart from mentioned above communication with Izenda backend. However, there is a recommended workflow for any Worker implementation. The Izenda internal (embedded) ones do follow this workflow as well:
- Send Register Worker request
- Repeat Alive Ping requests every N seconds (60 seconds in current configuration of Izenda embedded Workers) in parallel with all activity in #2 - #7 items
- If Alive Ping request got “False” response, abandon all work, and reinitialize Worker / Jump to #1
- Send Task Dequeue request
- If there is no Task dispatched, then jump to #6
- Process the dispatched Task
- Send Task Outcome Report request
- Return to #2
- Sleep for N seconds (60 seconds in current configuration of Izenda embedded Workers)
- Return to #2
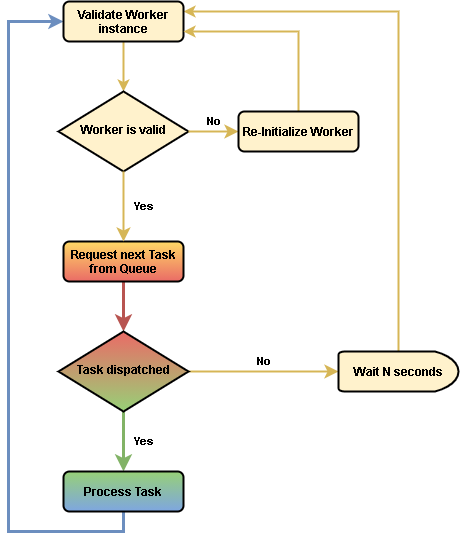
Such behavior provides the most efficient approach to Tasks dispatching/processing - while some Tasks exist in Queue, the Worker processes them continuously, one after another without delays, but at the same time sequentially, thus occupying only one thread, without risk of overloading whole machine / node. Once Tasks ended and the Queue empty, Worker will wait for new Tasks to appear, hitting RepositoryDB just one time per N seconds to check new Tasks presence, but don’t provide load on the RepositoryDB.
On the standalone / dedicated service node, the number of Workers can be equal (or even exceed) the number of CPU cores.
On the Izenda backend instance, each embedded Worker always uses only one thread/core. Thus, the value of setting for number of simultaneously acting Workers (“izenda.tasksqueue.workercount”) is recommended to be ~25% - 50% of total CPU cores amount on the machine, to always have a spare resources for WebAPI/UI requests processing.