Data Wrangling
Data Wrangling is the process of cleaning ,structuring and enriching raw data into desired data format for better decision making in less time.With the amount of data and data sources rapidly growing and expanding, it is getting more and more essential for the large amounts of available data to be organized for analysis.
This process typically includes manually converting/mapping data from one raw form into another format to allow for more convenient consumption and organization of the data.
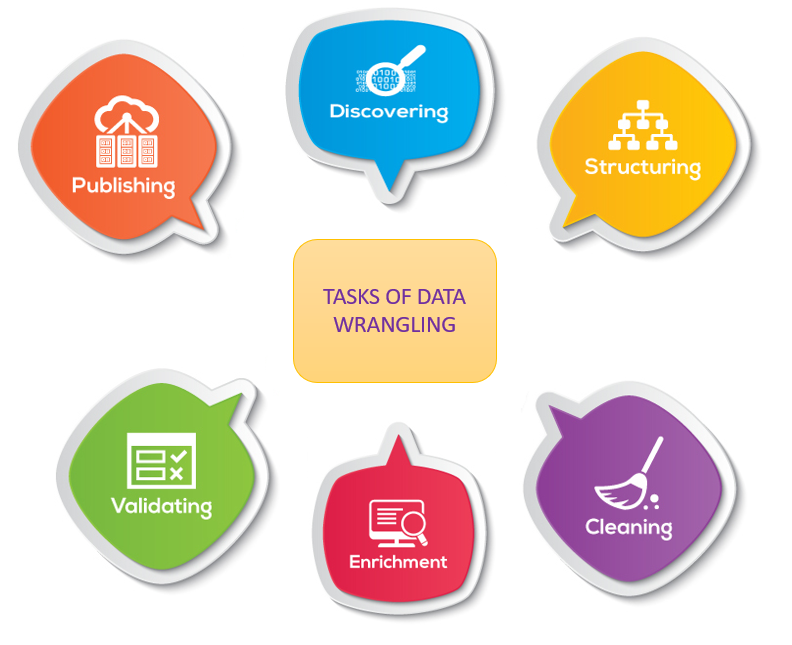
Steps to perform Data Wrangling:
There are six iterative steps that make up the data wrangling process.
- Discovering:
Before you can dive deeply, you must better understand what is in your data, which will inform how you want to analyze it. How you wrangle customer data.
- Structuring:
This means we have to organize the data this is due to the raw data is of different size or shapes. A single column may turn into several rows for easier analysis.One column may become two. Movement of data is made for easier computation and analysis.
- Cleaning:
Cleaning the data means removing null values because it is necessary to remove the null values for performing algorithm on datasets like random forest and it will also helps in increasing the performance of analysis.
- Enrichment
Extract new features or data from the given data set to optimize the performance of the applied model.
- Validating
This approach is used for improving the quality of data and consistency rules so that transformations that are applied to the data could be verified.
- Publishing
After completing the steps of Data Wrangling, the steps can be documented so that similar steps can be performed for the same kind of data to save time.