Lance: Unified Multimodal Modeling by Multi-Task Synergy
Fengyi Fu*,
Mengqi Huang*,✉,
Shaojin Wu*,
Yunsheng Jiang*,
Yufei Huo,
Jianzhu Guo✉,§
Hao Li,
Yinghang Song,
Fei Ding,
Qian He,
Zheren Fu,
Zhendong Mao,
Yongdong Zhang
ByteDance
* Equal contribution ✉ Corresponding authors § Project lead




English | 简体中文
> **Note:** Lance is a research project rather than a polished product model. The released checkpoint was trained with up to 128 A100 GPUs, with training conducted up to 768x768 image generation and 480p, 12 FPS video generation. Our goal is to share a research artifact for studying unified image/video understanding, generation, and editing under a relatively small model and limited compute budget. Output quality may vary across prompts, resolutions, duration, motion complexity, and editing scenarios, and we see further opportunities to improve the post-training recipe. We appreciate constructive feedback from the community as we continue improving the project.
## 🔥 Updates
- **`2026/06/03`**: 🚀 Lance is now supported in [vLLM-Omni](https://github.com/vllm-project/vllm-omni). See the [recipe](https://github.com/vllm-project/vllm-omni/blob/main/recipes/ByteDance/Lance.md)!
- **`2026/05/29`**: 💪 Added support for Image-to-Video generation. [More to see](assets/docs/changelog/2026-05-29.md)!
- **`2026/05/26`**: 🎨 The Gradio interface now supports image and video generation, editing, and understanding. [Try it out](assets/docs/changelog/2026-05-26.md)!
- **`2026/05/25`**: ✨ The [Hugging Face Space](https://huggingface.co/spaces/bytedance-research/Lance) is now live, thanks to the HF team!
- **`2026/05/19`**: 🤗 The technical report is now available on [arXiv](http://arxiv.org/abs/2605.18678).
- **`2026/05/18`**: 🔥 We launched the [project homepage](https://lance-project.github.io/) and released the initial inference code and model weights on [GitHub](https://github.com/bytedance/Lance/) and [Hugging Face](https://huggingface.co/bytedance-research/Lance).
## 🌟 Highlights
**Lance** is a 3B native unified multimodal model that supports **image and video understanding, generation, and editing** within a single framework.
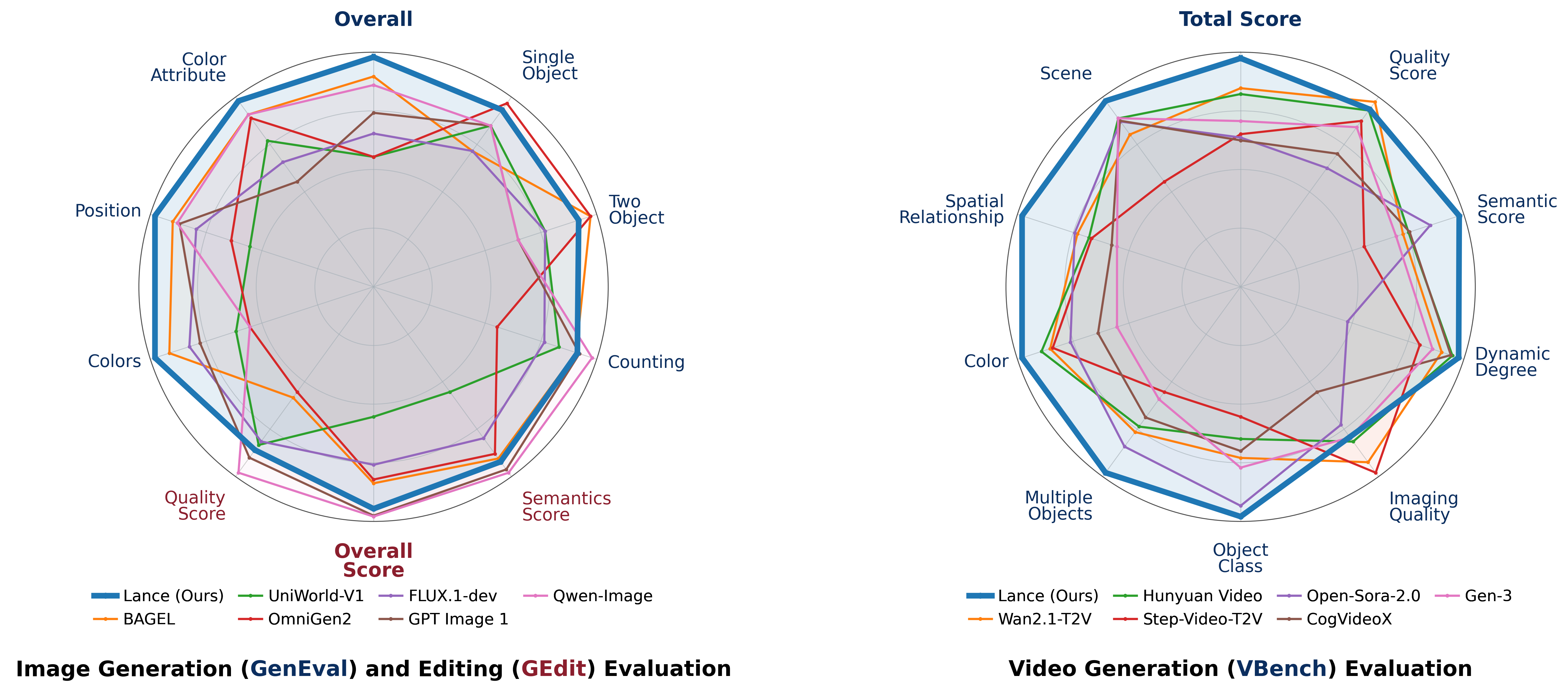
- **Efficient at 3B scale.** With only **3B active parameters**, Lance achieves competitive performance across image generation, image editing, and video generation benchmarks.
- **Training from scratch.** Lance is trained from scratch with a staged multi-task recipe and within a budget of **up to 128 A100 GPUs**.
We are actively updating and improving this repository. If you find any bugs or have suggestions, please feel free to open an issue or submit a pull request (PR) 💖.