Lance: Unified Multimodal Modeling by Multi-Task Synergy
Fengyi Fu*,
Mengqi Huang*,✉,
Shaojin Wu*,
Yunsheng Jiang*,
Yufei Huo,
Jianzhu Guo✉,§
Hao Li,
Yinghang Song,
Fei Ding,
Qian He,
Zheren Fu,
Zhendong Mao,
Yongdong Zhang
ByteDance
* 共同一作 ✉ 通讯作者 § Project lead




English | 简体中文
> **注意:** Lance 是一个研究项目,而不是经过充分产品化打磨的模型。当前开源 checkpoint 使用不超过 128 张 A100 GPU 训练,训练阶段覆盖到 768x768 图像生成和 480p、12 FPS 视频生成。我们希望将 Lance 作为一个研究参考,分享在较小模型规模和相对有限算力下统一图像/视频理解、生成和编辑的建模思路、训练流程和推理代码。模型效果可能会随 prompt、分辨率、时长、运动复杂度和编辑场景而波动,post-training recipe 仍有进一步改进空间。我们欢迎社区提供建设性反馈,帮助项目持续改进。
## 🔥 更新
- **`2026/06/03`**: 🚀 Lance 现已被 [vLLM-Omni](https://github.com/vllm-project/vllm-omni) 支持。查看 [recipe](https://github.com/vllm-project/vllm-omni/blob/main/recipes/ByteDance/Lance.md)!
- **`2026/05/29`**: 🔥 增加 image-to-video generation 代码支持:文本-图像到视频生成(首帧到视频)。[查看示例](assets/docs/changelog/2026-05-29.md)!
- **`2026/05/26`**: 🎨 Gradio 界面现已支持图像和视频生成、编辑与理解任务。[欢迎体验](assets/docs/changelog/2026-05-26.md)!
- **`2026/05/25`**: ✨ [Hugging Face Space](https://huggingface.co/spaces/bytedance-research/Lance) 已上线,感谢 HF 团队的支持!
- **`2026/05/19`**: 🤗 技术报告现已发布于 [arXiv](http://arxiv.org/abs/2605.18678)。
- **`2026/05/18`**: 🔥 我们发布了 [项目主页](https://lance-project.github.io/),并在 [GitHub](https://github.com/bytedance/Lance/) 和 [Hugging Face](https://huggingface.co/bytedance-research/Lance) 上开源了初版推理代码和模型权重。
## 🌟 亮点
**Lance** 是一个3B参数、原生统一的多模态模型,在单一框架下同时支持 **图像与视频的理解、生成和编辑**。
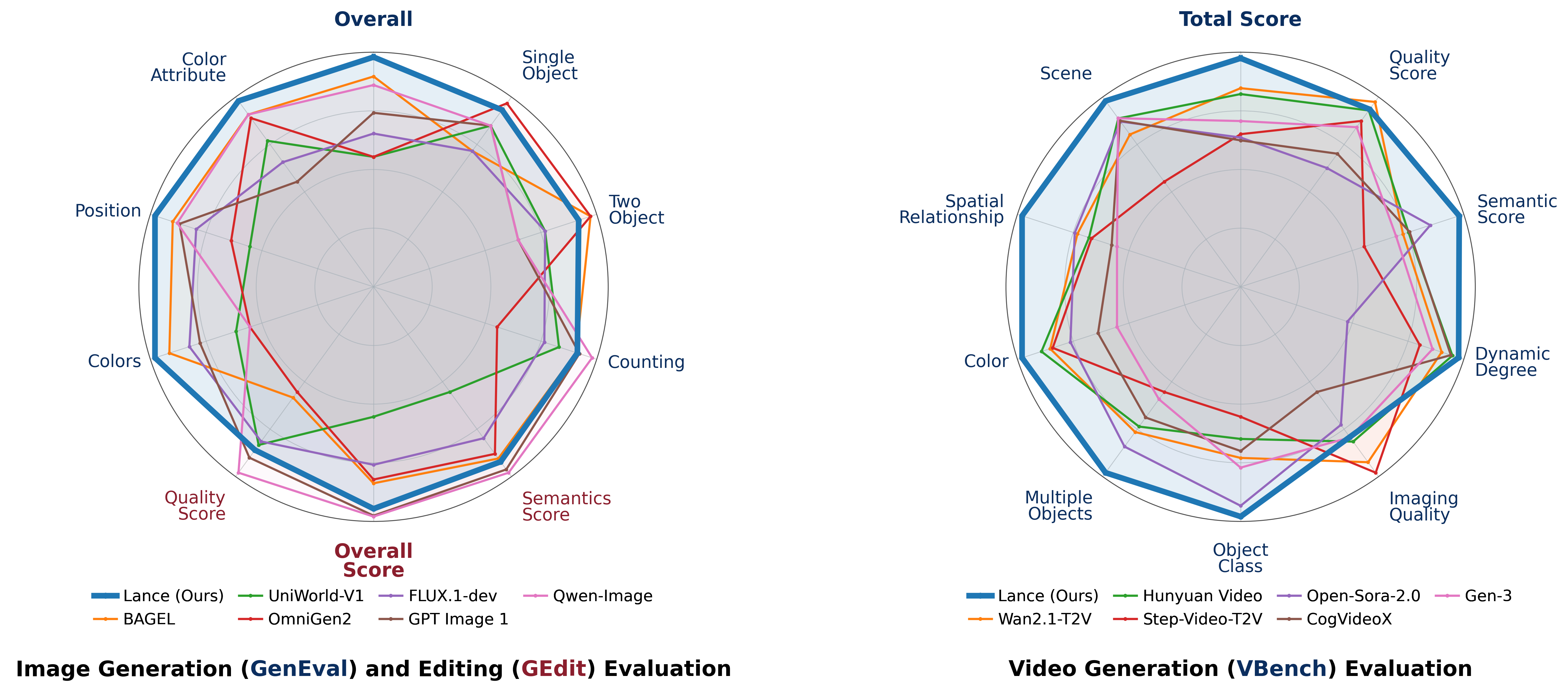
- **3B 规模高效。** 仅使用 **3B active parameters**,Lance 即可在图像生成、图像编辑和视频生成等基准上取得有竞争力的表现。
- **从零训练。** Lance 采用分阶段多任务训练配方从零训练,并在 **不超过 128 张 A100 GPU** 的预算内完成训练。
我们正在持续更新和改进本仓库。如果你发现任何问题或有改进建议,欢迎提出 issue 或提交 pull request(PR)💖。