---
## 📰 News
- **[2026-05-14]** 🏆 AHE (on GPT-5.5) ranked **#3** on the [Terminal-Bench 2.0 leaderboard](https://www.tbench.ai/leaderboard/terminal-bench/2.0) with **84.7%** — ranking as of 2026-05-15
- **[2026-04-30]** ✍️ Blog post on Dawning Road (English & Chinese) — a more detailed account of the exploration behind AHE: [Agentic Harness Engineering](https://dawning-road.github.io/blog/agentic-harness-engineering)
- **[2026-04-28]** 📄 Paper released on arXiv: [Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses](https://arxiv.org/abs/2604.25850)
- **[2026-04]** 🎉 Framework released
---
## 🎯 Overview
**AHE (Agentic Harness Engineering)** is an open **observability system** for automatically evolving the harness around a coding agent. The base model is held fixed; what evolves are the harness components — system prompts, tool descriptions, tool implementations, middleware, skills, sub-agents, and long-term memory.
AHE rests on three observability layers:
- **Component observability** — [**NexAU**](https://github.com/nex-agi/NexAU.git) decomposes the harness into seven orthogonal, file-level components, each git-tracked so every edit is auditable and revertible.
- **Experience observability** — *Agent Debugger* distills ~10M-token raw traces into layered, sourced reports; the optimizer reads digests by default but can always drill back to any rollout's raw trace.
- **Decision observability** — *Evolve Agent* proposes evidence-backed edits, predicts their impact, and is automatically falsified by the next iteration's flipped tasks.
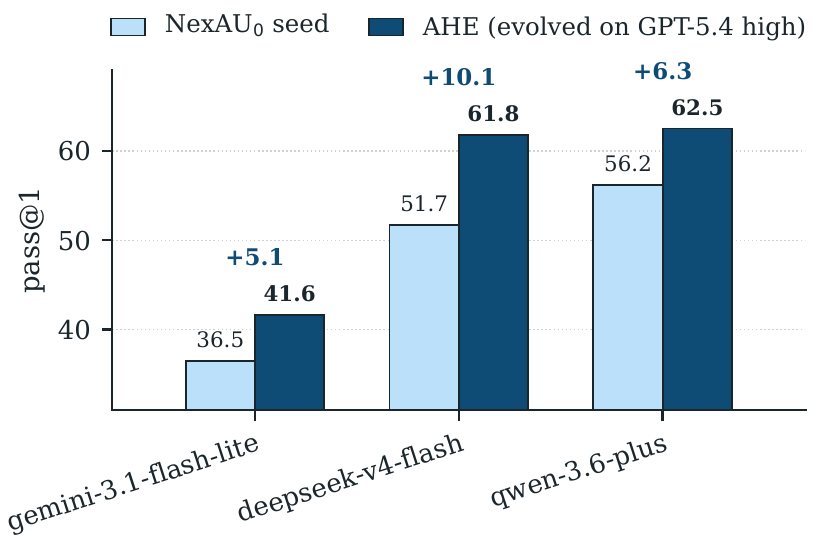
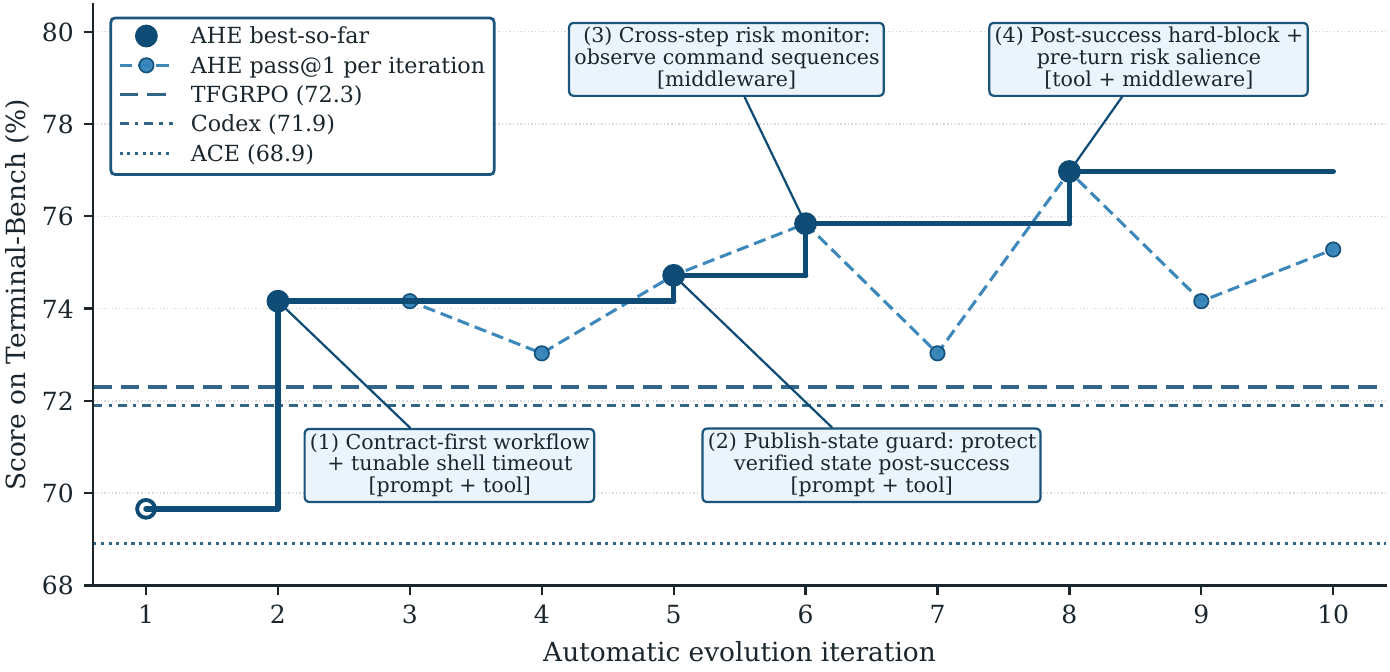
Across ten `evaluate → analyze → improve` iterations, **AHE (Agentic Harness Engineering)** lifts Terminal-Bench 2 pass@1 from **69.7% to 77.0%** on GPT-5.4, surpasses the hand-written Codex (71.9%) and the self-evolving ACE and TF-GRPO baselines, and produces a frozen harness that transfers without re-evolution to SWE-bench-verified and to four alternate base models, indicating that the evolved components encode general engineering experience rather than benchmark-specific tuning.
---
## 🚀 Quick Start
### 0. Prerequisites
- Python ≥ 3.13
- [uv](https://docs.astral.sh/uv/)
- tmux
```bash
# macOS
brew install uv tmux
# Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
sudo apt install -y tmux
```
### 1. Clone + install dependencies
```bash
git clone https://github.com/Curry09/agentic-harness-engineering.git
cd agentic-harness-engineering
uv sync
```
> `uv sync` installs every dependency declared in `pyproject.toml`.
### 2. Configure environment variables
```bash
cp .env.example .env
```
Edit `.env`. At minimum, set:
| Variable | Purpose |
|---|---|
| `LLM_API_KEY` / `LLM_BASE_URL` | Main LLM endpoint (`code_agent` and `evolve_agent` both consume it) |
| `E2B_API_KEY` | [E2B](https://e2b.dev/) sandbox — see the next subsection for SaaS vs. self-hosted |
| `SERPER_API_KEY` | Web search used by `evolve_agent` |
`ADB_LLM_*` and `GPT54_LLM_*` are optional — leave them unset to fall back to `LLM_*`, or set them to point ADB / the gpt-5.4 experiment at a stronger model. `LANGFUSE_*`, `BP_HTML_PARSER_*`, and `FEISHU_WEBHOOK` are all optional observability / convenience hooks; see `.env.example` for the full list.
#### E2B sandbox: SaaS vs. self-hosted
AHE runs every rollout inside an E2B sandbox. Two deployment modes are supported:
- **SaaS E2B (default).** Set **only** `E2B_API_KEY` and leave `E2B_API_URL` / `E2B_DOMAIN` unset (or commented out). The SDK talks to `e2b.dev` automatically.
> ⚠️ **Concurrency cap.** SaaS E2B enforces a per-account **concurrent sandbox limit** tied to your tier. If harbor tries to spawn more sandboxes than the cap allows, the extra sandboxes fail to start and the iteration stalls. Before raising parallelism in your harbor / experiment config, check your tier's quota and stay safely under it.
- **Self-hosted E2B cluster.** Set `E2B_API_KEY` **and** point the SDK at your cluster:
```dotenv
E2B_API_KEY="your_e2b_key"
E2B_API_URL="https://your-e2b-host.example.com"
E2B_DOMAIN="your-e2b-host.example.com"
```
No shared concurrency cap applies, but the cluster's hardware capacity still does.
### 3. Build E2B templates (one-time per dataset)
The dataset here is a pack from [`laude-institute/harbor-datasets`](https://github.com/laude-institute/harbor-datasets) — clone the subset you need and point `--dataset-dir` at its directory.
Every rollout runs inside an E2B sandbox spawned from a prebuilt template that already has `uv` and the NexAU/harbor venv at `/opt/nexau-venv`. Build those templates once before launching:
```bash
# Build every template declared by the dataset, 16 in parallel
uv run python scripts/build_templates.py --dataset-dir /path/to/dataset -j 16
# Resume after a failure: only retry tasks whose latest E2B build status is ERROR
uv run python scripts/build_templates.py --dataset-dir /path/to/dataset --retry-failed
# Build a specific subset of tasks
uv run python scripts/build_templates.py --dataset-dir /path/to/dataset task_a task_b
```
The dataset directory must contain one subdir per task with a `task.toml` declaring `[environment].docker_image` (or an `environment/Dockerfile` fallback). Each task's template alias is `` with `.` replaced by `-`.
The default packages baked into each template come from `scripts/build_templates.py:DEFAULT_NEXAU_PACKAGES` (a public NexAU + the in-sandbox `NexAU-harbor` variant, intentionally distinct from the host-side `harbor-LJH` in `pyproject.toml`). Override with one or more `--nexau-package ` flags if you need a different revision in the sandbox.
If your tasks pull from a private Docker registry, also export `DOCKER_REGISTRY_USERNAME` and `DOCKER_REGISTRY_PASSWORD` before invoking the script.
### 4. Launch
```bash
# Run a single experiment in the background via tmux
./scripts/evolve.sh configs/experiments/exp-003-simple-code-gpt54.yaml
# Launch and auto-attach to the log stream
./scripts/evolve.sh --attach configs/experiments/exp-003-simple-code-gpt54.yaml
# Batch: launch every experiment under configs/experiments/
./scripts/evolve.sh --batch
```
Common tmux operations after launch:
```bash
tmux ls # list sessions
tmux attach -t # attach to a session
# Ctrl-b d # detach (keeps running in background)
tmux kill-session -t # terminate
```
---
## 🔧 How It Works
The base model is held fixed; what evolves is the **harness around it**. Each outer iteration is `evaluate → analyze → improve`, built on the three observability layers from the Overview.
### 1. Evaluate — emit traces, not just scores
`harbor` runs the current `code_agent` over the dataset inside isolated E2B sandboxes. Per task it writes:
- `agent/nexau_in_memory_tracer.cleaned.json` — full step-level trace (messages, tool calls, middleware events)
- `agent/nexau.txt` — runtime log (middleware errors, crashes, warnings)
- `verifier/reward.txt` — pass/fail outcome
The **trace, not the pass rate**, is the unit every later step operates on.
### 2. Analyze — distill ~10M-token traces into sourced evidence
*Agent Debugger* compresses each iteration's raw traces (routinely >10M tokens) into layered reports:
- `analysis/overview.md` — cross-task root-cause summary
- `analysis/detail/{task}.md` — per-task deep analysis
The optimizer reads digests by default, but every claim links back to the originating raw trace, so it can drill down before committing to a change.
> **Note on Agent Debugger licensing.** The current release ships a *partially* open-sourced Agent Debugger; due to company strategy, it cannot be fully open-sourced at this time.
### 3. Improve — evidence-backed, falsifiable edits
*Evolve Agent* may only write inside `workspace/`, which exposes the seven NexAU components: `systemprompt.md`, `code_agent.yaml`, `tool_descriptions/`, `tools/`, `middleware/`, `skills/`, `sub_agents/` (plus `LongTermMEMORY.md`). For every edit it must commit four fields:
1. **Failure evidence** — the failing tasks and trace excerpts that motivate the change
2. **Root cause** — *why* it failed, not just *what* failed
3. **Targeted fix** — the change that directly addresses that cause
4. **Predicted impact** — which tasks should flip to pass, and which are at risk
### 4. Loop — staggered generations enable falsification
Each `runs/iteration_NNN/` mixes two generations: `input/` holds the workspace produced by loop `NNN-1` (just evaluated), `evolve/` holds what loop `NNN` writes (evaluated next loop). Flips (pass↔fail) on the next eval are attributed back to this loop's edits in `change_evaluation.json` — predictions that don't hold get rolled back or revised. The loop terminates on `target_pass_rate` or `max_iterations`.
### Main components
| Component | Role |
|---|---|
| `evolve.py` | Main-loop orchestrator |
| `agents/code_agent_simple/` | The coding agent that is being evaluated and evolved |
| `agents/evolve_agent/` | The meta-agent that performs the improvement step (built on the [NexAU](https://github.com/nex-agi/NexAU.git) framework) |
| `agents/explore_agent/` | Upstream dataset / source-code exploration agent |
| `configs/` | `base.yaml` (shared defaults) + `experiments/` (per-experiment overlays) |
| `scripts/` | tmux launcher wrappers (`evolve.sh`, `evolve-resume.sh`) |
### Directory layout
```
agentic-harness-engineering/
├── evolve.py # main loop
├── trace_converter.py # rollout trace → debugger-friendly JSON
├── agents/
│ ├── code_agent_simple/ # the coding agent under evolution
│ ├── evolve_agent/ # the evolution meta-agent
│ │ ├── evolve_prompt.md
│ │ ├── middleware/ # context compaction / failover / ralph loop …
│ │ ├── skills/ # agent-debugger-cli / nexau-evolution-guide
│ │ └── tools/ # file / shell / web / session tools
│ └── explore_agent/ # exploration agent (sources + web)
├── configs/
│ ├── base.yaml # shared defaults
│ └── experiments/ # one overlay per experiment
├── scripts/
│ ├── evolve.sh # tmux launcher
│ └── evolve-resume.sh # resume helper
└── .env.example
```
---
## Configuration (base + overlay)
`configs/base.yaml` holds the shared defaults. Each `configs/experiments/exp-*.yaml` inherits it via a leading `_base: ../base.yaml` line and overrides only the fields that differ. Any `${ENV_NAME}` reference inside a YAML file is substituted from `.env`.
**Key fields in `base.yaml`:**
| Field | Description |
|---|---|
| `path` | Dataset path |
| `target_pass_rate` | Stop once reached (default 0.95) |
| `max_iterations` | Maximum number of iterations (default 100) |
| `harbor_job_timeout_minutes` | Per-harbor-evaluation timeout (0 = unlimited) |
| `experiment_timeout_minutes` | Total wall-clock budget for the experiment (0 = unlimited) |
| `llm.api_key / base_url / model` | Main LLM config (usually left as `${LLM_*}`) |
| `agent_debugger.llm` | Dedicated LLM for ADB (can use a stronger model for debugging) |
| `notify.feishu_webhook` | Optional Feishu webhook for experiment milestones |
### Dataset configuration
An experiment's data source is specified via `path` **or** `dataset` — pick one:
| Form | Meaning | Example |
|---|---|---|
| `path: "./dataset/xxx"` | Local dataset directory (relative to the AHE root) | `./dataset/terminal-bench-2` |
| `path: "/abs/path/xxx"` | Local dataset directory (absolute path) | `/root/dataset/terminal-bench-2` |
| `dataset: "@"` | Reference a harbor built-in dataset (no local files required) | `terminal-bench@2.0` |
Public dataset packs (in the layout AHE expects under `path:`) are published at [`laude-institute/harbor-datasets`](https://github.com/laude-institute/harbor-datasets) — clone or download the subset you need and point `path` at its directory.
The default `path` values in `base.yaml` and `configs/experiments/*.yaml` are **placeholders only** — adjust them for your environment, or comment out `path` and uncomment the `dataset` line to use a harbor built-in dataset instead.
---
## CLI reference
### `python evolve.py`
| Flag | Description |
|---|---|
| `--config ` | Config file (overlay takes precedence) |
| `--batch [dir\|files...]` | Batch mode; defaults to scanning `configs/experiments/` |
| `--experiment ` | Resume an existing experiment (pass the directory name under `experiments/`) |
| `--start-iteration N` | Start from iteration N (default 1) |
| `--skip-eval` | Skip evaluation and reuse existing rollouts (for debugging) |
### `./scripts/evolve.sh`
A thin wrapper around `uv run python evolve.py` + tmux.
| Flag | Description |
|---|---|
| `` | Positional argument: path to the config file |
| `--experiment ` | Resume an existing experiment |
| `--start-iteration N` | Starting iteration |
| `--skip-eval` | Skip evaluation |
| `--session ` | Custom tmux session name |
| `--batch` | Launch every overlay in batch mode |
| `--attach` | Auto-attach after launch |
---
## Common scenarios
**Resume an interrupted experiment from iteration 16:**
```bash
./scripts/evolve.sh \
--experiment 2026-04-10__23-20-14__gpt54 \
--start-iteration 16 \
configs/experiments/exp-003-simple-code-gpt54.yaml
```
**Run only evolve_agent without re-running evaluation:**
```bash
./scripts/evolve.sh \
--experiment \
--skip-eval \
configs/experiments/exp-003-simple-code-gpt54.yaml
```
---
## License
MIT
---
## Star History