![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

English | 简体中文
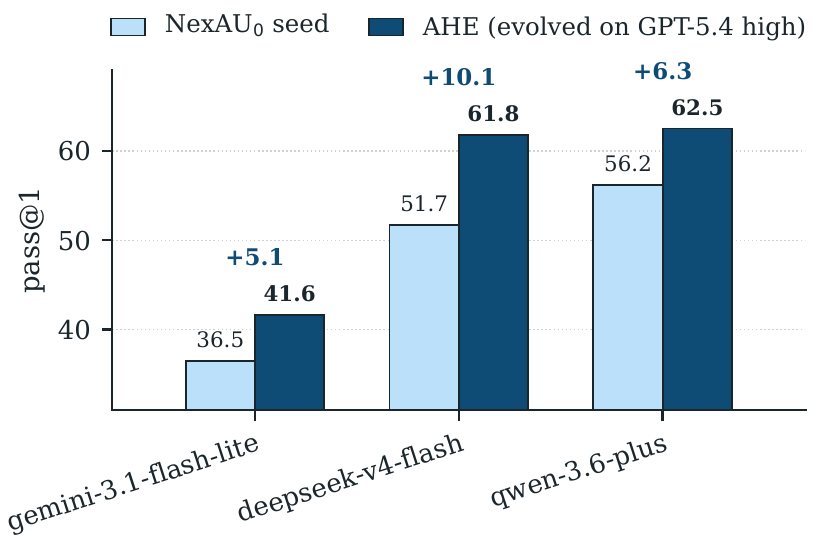
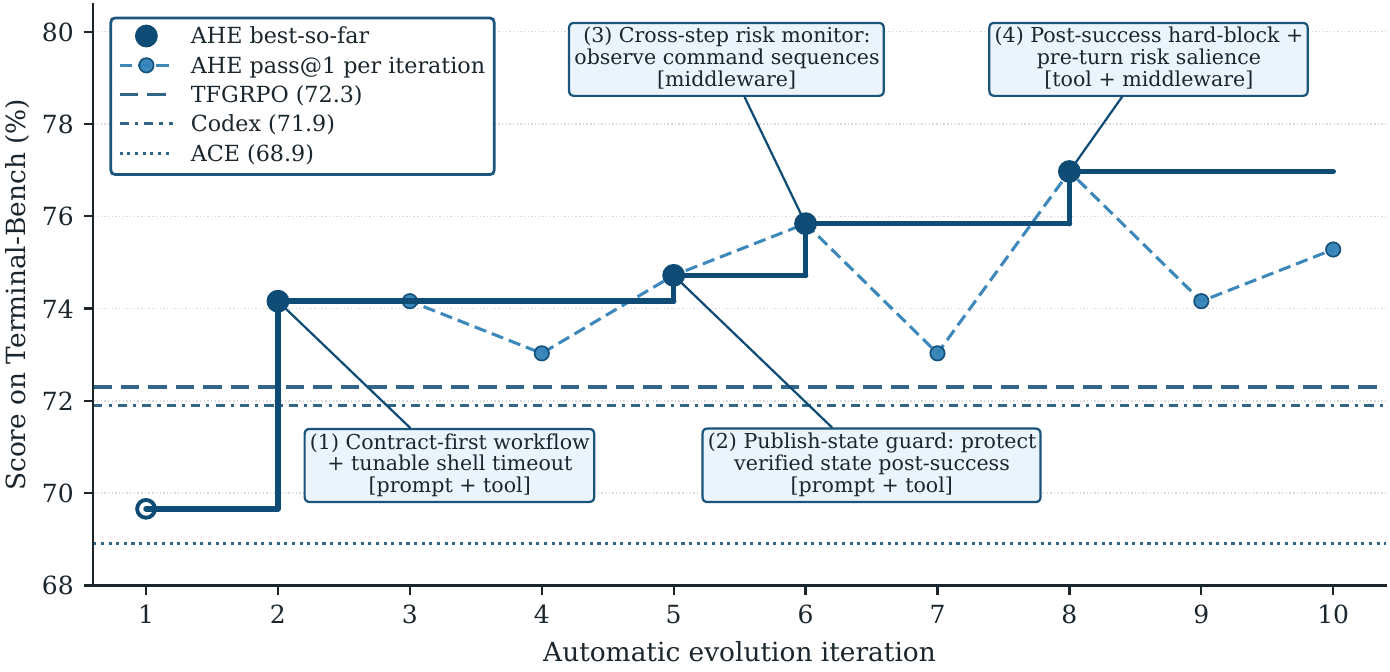
> 本文档为英文 [README.md](README.md) 的中文翻译,可能略有滞后;如有冲突以英文版为准。 --- ## 📰 动态 - **[2026-05-14]** 🏆 AHE(基于 GPT-5.5)以 **84.7%** 登上 [Terminal-Bench 2.0 榜单](https://www.tbench.ai/leaderboard/terminal-bench/2.0),位列**第 3 名**(榜单排名截至 2026-05-15) - **[2026-04-30]** ✍️ Dawning Road 上的博客(英文 & 中文)—— 关于 AHE 探索过程的更详细记述:[Agentic Harness Engineering](https://dawning-road.github.io/blog/agentic-harness-engineering) - **[2026-04-28]** 📄 论文已在 arXiv 发布:[Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses](https://arxiv.org/abs/2604.25850) - **[2026-04]** 🎉 框架开源 --- ## 🎯 概览 **AHE (Agentic Harness Engineering)** 是一个开放的**可观测性系统**,用于自动演化围绕在编码 agent 周围的 harness。基础模型保持不变,演化的是 harness 的各个组件——系统提示词、工具描述、工具实现、中间件、skill、子 agent、以及长期记忆。 AHE 建立在三层可观测性之上: - **组件可观测性 (Component observability)** —— [**NexAU**](https://github.com/nex-agi/NexAU.git) 把 harness 拆分为七个正交的文件级组件,每一项都纳入 git 追踪,因此每次修改都可审计、可回退。 - **经验可观测性 (Experience observability)** —— *Agent Debugger* 把 ~10M-token 的原始 trace 蒸馏成分层、可溯源的报告;优化器默认读 digest,但任何论断都可以下钻回某次 rollout 的原始 trace。 - **决策可观测性 (Decision observability)** —— *Evolve Agent* 提出有证据支撑的修改、预测其影响,并由下一轮迭代中翻转的任务自动证伪。 经过十轮 `评估 → 分析 → 改进` 迭代,**AHE** 在 GPT-5.4 上把 Terminal-Bench 2 的 pass@1 从 **69.7% 提升到 77.0%**,超过手写的 Codex (71.9%) 以及自演化的 ACE 与 TF-GRPO 基线;同时产出了一个无需重新演化即可迁移到 SWE-bench-verified 以及四个其他基础模型上的"冻结 harness",表明被演化出的组件编码的是通用工程经验,而非针对单一 benchmark 的调优。