OpenTalking
面向实时对话的开源数字人产线:LLM、TTS、WebRTC、角色音色与可插拔模型后端
English ·
文档站 ·
GitHub






效果展示 ·
部署路线 ·
快速开始 ·
模型支持 ·
Roadmap ·
文档与社区
---
## 项目简介
OpenTalking 是一个开源实时数字人对话编排框架,目标是构建 **数字人对话产品** 的核心链路:前端交互、会话状态、LLM 回复、STT、TTS / 音色选择、打断控制、字幕事件、WebRTC 音视频播放,以及本地或远端模型服务调用。
OpenTalking 更偏向可落地的数字人产线:前端 WebUI、形象 / 音色资产库、知识库、记忆、多会话状态、LLM / STT / TTS provider、WebRTC 播放和模型后端都在同一套工程里组织。你可以从最轻量的 Mock 模式开始,也可以接入本地 QuickTalk / Wav2Lip,或通过 OmniRT 使用 FlashTalk、FasterLivePortrait 等更高质量或更复杂的模型工作流。
- **快速体验**:`mock / 无驱动模式`,适合第一次打通 API、TTS、WebRTC 全链路。
- **实时对话**:接入 `QuickTalk`、`Wav2Lip`、`FlashTalk` 等模型,完成可交互数字人对话。
- **视频创作与克隆**:复用 FasterLivePortrait runtime,支持语音/文字驱动视频创作和摄像头/上传视频驱动的视频克隆。
- **私有化部署**:支持本地 STT/TTS、OpenAI-compatible LLM、知识库 / 记忆、OmniRT 远端推理和 Docker / 分布式部署。
更多文档:
- 在线文档:
- 英文文档:
## WebUI 与效果展示
OpenTalking 提供 Web 服务界面,用于管理数字人对话链路:可以选择或新建数字人物,配置音色、LLM、TTS、STT 和数字人驱动模型,查看模型连接状态,并在同一页面完成实时对话、字幕和音视频播放验证。
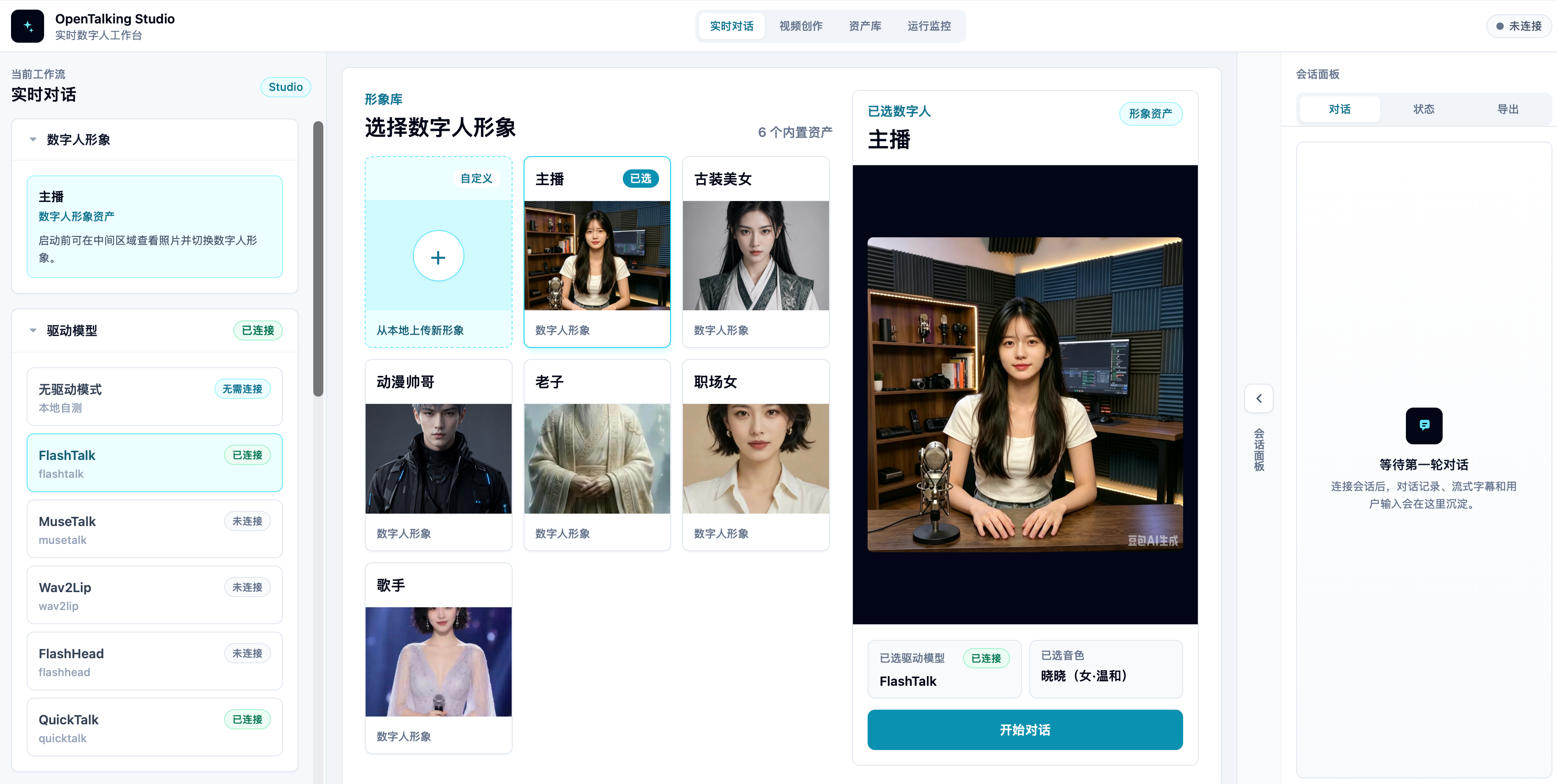
### Demo 视频
以下是 OpenTalking 典型场景演示视频,覆盖实时对话、视频创作和视频克隆三类前端工作流。
| 精选产品场景 |
医疗导诊助手
|
电商直播
|
黄山文旅导览
|
| B. 视频创作 |
语音 drive
|
文字 drive
|
克隆音色 drive
|
## 选择部署路线
OpenTalking 的 **编排层**(API / Worker / 前端)和 **数字人合成后端**(`mock`、`local`、`direct_ws` 或 [OmniRT](https://github.com/datascale-ai/omnirt))可以独立部署。第一次接触项目时,建议先用 Mock 模式跑通完整链路,再按显卡、模型和私有化需求切换到真实视频渲染模型。
| 路线 | 推荐模型 / 后端 | 设备参考 | 适合场景 | 详细文档 |
| --- | --- | --- | --- | --- |
| 快速体验 | `mock` | CPU / 无 GPU | 不下载模型权重,先验证 API、LLM、TTS、WebRTC 与浏览器播放链路 | [快速开始](https://datascale-ai.github.io/opentalking/latest/quick-start/) |
| 入门验证 | `quicktalk` / `wav2lip` | RTX 3050 Laptop、RTX 3060、RTX 4060 | 能跑通真实视频渲染,适合功能演示和部署验证;低显存设备建议降低分辨率 | [QuickTalk](https://datascale-ai.github.io/opentalking/latest/avatar_models/deployment/quicktalk-local/) / [Wav2Lip](https://datascale-ai.github.io/opentalking/latest/avatar_models/deployment/wav2lip-local/) |
| 消费级显卡单机 | `quicktalk` / `wav2lip` / `musetalk` | RTX 3090、RTX 4090 | 更接近实时体验,适合本地 demo、私有化验证和轻量生产前评估 | [模型与后端选择](https://datascale-ai.github.io/opentalking/latest/model-support/selection/) |
| 全本地私有化 | `sensevoice` + `local_cosyvoice` + `quicktalk` | RTX 3090 / 4090 或同级 GPU | STT、TTS、视频驱动都走本地;OpenTalking 使用主 `.venv`,CosyVoice 使用独立 sidecar venv | [本地 STT/TTS + QuickTalk](https://datascale-ai.github.io/opentalking/latest/recipes/local-quicktalk-audio/) |
| 高质量远端推理 | `flashtalk` / `flashhead` / `fasterliveportrait` + OmniRT | 多卡 GPU、Ascend 910B2、远端 GPU 服务 | 多卡、GPU/NPU、生产隔离、更高画质或视频克隆 | [FlashTalk](https://datascale-ai.github.io/opentalking/latest/avatar_models/flashtalk/) / [FasterLivePortrait](https://datascale-ai.github.io/opentalking/latest/avatar_models/fasterliveportrait/) |
| Docker / 生产部署 | API、Web、Worker、外部模型服务分离 | 单机 GPU、远端 GPU、分布式集群 | 服务化部署、远端 GPU、分布式和生产验证 | [部署文档](https://datascale-ai.github.io/opentalking/latest/deployment/) |
## 快速开始
先按目标选择一条快速开始路径:
| 路线 | 适合场景 | 需要准备 | 验证内容 |
| --- | --- | --- | --- |
| 优云镜像 | 想先体验 OpenTalking,不想配置依赖或下载模型权重。 | 使用已发布镜像创建优云实例,并开放 `5173` 端口。 | WebUI、LLM 回复、流式 TTS、字幕事件、WebRTC 传输和预置镜像工作流。 |
| 自己部署 | 想在自己的机器或服务器运行仓库、调整配置,或继续接本地/远端真实模型。 | Python、Node.js、FFmpeg、`.env` provider 配置;真实模型还需要 GPU、运行时和模型权重。 | 先跑通 Mock 首次运行链路,再切到本地 QuickTalk 或远端 OmniRT。 |
### 1. 优云
如果你只是想先体验 OpenTalking + OmniRT + QuickTalk 的实时数字人链路,可以直接使用我们在优云智算发布的社区镜像:
- 镜像地址:[镜像链接](https://www.compshare.cn/images/TdDwmKZUZebI?referral_code=Hid5KUhcqlZEptmMEwKy2F)
- 对外端口:`5173`(WebUI,内部自动代理 API)
- 操作文档:[优云智算镜像快速体验](https://datascale-ai.github.io/opentalking/latest/quick-start/)
镜像内已预置 OpenTalking、OmniRT、QuickTalk 运行环境和模型文件。部署实例后开放 `5173` 端口,在浏览器访问平台提供的实例地址即可进入 WebUI;如需手动重启服务,请按操作文档中的命令执行。
### 2. 自己部署
适用:想从源码运行 OpenTalking。第一次部署时可以先用 Mock 模式,不下载视频模型权重;Mock 模式使用内置静态帧,LLM 回复、流式 TTS、字幕事件和 WebRTC 传输仍是完整链路。
```bash
git clone https://github.com/datascale-ai/opentalking.git
cd opentalking
uv sync --extra dev --python 3.11
source .venv/bin/activate
cp .env.example .env
```
编辑 `.env`,至少配置 LLM;TTS 默认可使用不需要 key 的 `edge` 语音。LLM、STT、TTS 是独立 provider,常见配置见 [配置说明](https://datascale-ai.github.io/opentalking/latest/reference/configuration/) 和 [LLM / STT 文档](https://datascale-ai.github.io/opentalking/latest/speech_models/llm-stt/)。
```bash
bash scripts/start_unified.sh --mock
```
默认前端地址是 `http://localhost:5173`。如果需要指定端口:
```bash
bash scripts/start_unified.sh --mock --api-port 8210 --web-port 5280
```
停止服务:
```bash
bash scripts/quickstart/stop_all.sh
```
#### 真实模型启动入口
完成 Mock 验证后,再按机器条件选择真实模型路线。权重下载、目录结构、国内镜像、校验、故障排查都放在文档站中维护,README 只保留启动入口:
```bash
# 本地 QuickTalk:消费级显卡单机路线
export OPENTALKING_TORCH_DEVICE=cuda:0
export OPENTALKING_QUICKTALK_ASSET_ROOT="$PWD/models/quicktalk"
export OPENTALKING_QUICKTALK_WORKER_CACHE=1
bash scripts/start_unified.sh --backend local --model quicktalk --api-port 8210 --web-port 5280
# 远端 OmniRT / FlashTalk:高质量或多卡路线
bash scripts/start_unified.sh \
--backend omnirt \
--model flashtalk \
--api-port 8210 \
--web-port 5280 \
--omnirt http://:9000
```
更多入口:
- [QuickTalk 本地部署](https://datascale-ai.github.io/opentalking/latest/avatar_models/deployment/quicktalk-local/)
- [Wav2Lip 本地部署](https://datascale-ai.github.io/opentalking/latest/avatar_models/deployment/wav2lip-local/)
- [FasterLivePortrait / JoyVASA](https://datascale-ai.github.io/opentalking/latest/avatar_models/fasterliveportrait/)
- [视频克隆使用说明](https://datascale-ai.github.io/opentalking/latest/usage/webui/video-clone/)
- [WebUI 使用说明](https://datascale-ai.github.io/opentalking/latest/usage/webui/basic/)
- [Docker Compose 与生产部署](https://datascale-ai.github.io/opentalking/latest/deployment/)
## 模型支持
| 模型 | 输入 | 推荐 backend | 资源建议 |
| --- | --- | --- | --- |
| `mock` | 参考图 / 静态帧 | `mock` | 不需要 GPU |
| `quicktalk` | template video + audio | `local` | CUDA GPU,推荐 3090 / 4090 |
| `wav2lip` | 参考图 / frames + audio | `local` / `omnirt` | `>= 8 GB` GPU / NPU memory |
| `musetalk` | full frames + audio | `omnirt` / `local` | `>= 12 GB` GPU memory |
| `soulx-flashtalk-14b` | portrait + audio | `omnirt` | 多卡 GPU / NPU |
| `soulx-flashhead-1.3b` | portrait + audio | `omnirt` | 多卡 GPU / NPU |
| `fasterliveportrait` | portrait / driving video / audio | `omnirt` | 单卡实时头像贴回、视频创作、视频克隆 |
### 消费级显卡参考
| 模型 | 硬件 | 输入 | 输出 | 显存占用 | 生成吞吐 |
| --- | --- | --- | --- | --- | --- |
| `quicktalk` | RTX 3090 | template video + audio | 720x900 / 25fps | 约 3.8 GiB | 约 35 fps |
更多权重下载、Docker、故障排查和模型配置见 [模型部署索引](https://datascale-ai.github.io/opentalking/latest/model-deployment/)。
### 云端模型 API:Atlas Cloud

> 🎁 **[Atlas Cloud](https://www.atlascloud.ai/?utm_source=github&utm_medium=link&utm_campaign=opentalking)** 是一个全模态 AI 推理平台,用一套 API 即可访问视频生成、图像生成和 LLM,无需分别对接多家厂商,一次接入即可统一调用全模态的 300+ 精选模型。
OpenTalking 的 LLM 走 OpenAI-compatible 接口,把 `OPENTALKING_LLM_BASE_URL` 指向 `https://api.atlascloud.ai/v1` 即可直接使用 Atlas 托管的 DeepSeek / Qwen 等模型,配置见 [LLM 与 STT](https://datascale-ai.github.io/opentalking/latest/speech_models/llm-stt/)。更多预算友好的 API 方案见 Atlas Cloud [coding plan](https://www.atlascloud.ai/console/coding-plan)。
## 能力进展与 Roadmap
- [ ] **更自然的实时对话体验**
继续打磨打断、低延迟响应、音画同步、长会话恢复和运行状态可见性。
- [ ] **消费级显卡多模型路线**
完善 QuickTalk / Wav2Lip / MuseTalk local 的资产检查、预热、缓存复用、低显存参数和更多 3090 / 4090 / WSL2 benchmark,并继续补齐 FasterLivePortrait 的视频创作与视频克隆评测数据。
- [ ] **Windows / WSL2 一键化部署**
在现有 Windows 部署文档和测试记录基础上,继续降低模型下载、运行时安装、环境检查和诊断门槛。
- [ ] **高质量私有化部署**
完善外部 OmniRT 推理服务、多模型 endpoint、容量调度、健康检查、生产监控和 GPU / NPU 部署指引。
- [ ] **更多云端语音与多模态 provider**
在现有 OpenAI-compatible、DashScope、Xiaomi MiMo 等 profile 基础上,继续扩展可插拔 STT / TTS / LLM provider、统一前端选择体验和 provider 级健康检查。
- [ ] **Agent、记忆与平台能力**
继续产品化资产库、知识库、记忆、多会话调度、工具调用和 OpenClaw / 外部 Agent 对接,并逐步补齐观测指标、安全合规、授权音色和合成内容标识。
### 近期进展
- **2026-06-25:微信记忆导入与角色工作流**
新增微信记忆角色导入能力、配套操作文档和角色工作流;前端不再把 persona 选择和驱动模型选择视为互斥,用户可以把导入的记忆 / 角色上下文与当前选择的 Avatar 驱动模型组合使用。
- **2026-06-23:本地 CosyVoice TRT sidecar 部署**
补齐本地 CosyVoice sidecar 部署路线,包含 TensorRT / FP16 加速说明、运行时参数调优、独立环境隔离、启动检查,以及本地 TTS 搭配 QuickTalk 的实测部署说明。
- **2026-06-22:运行时配置、记忆刷新与沉浸式场景**
新增 runtime API 配置页,优化 runtime refresh 时 mem0 provider 的释放逻辑,并扩展场景资产链路:场景资产 API、资产库集成、沉浸式对话模式、场景 / Avatar 锚点、透明背景处理,以及切换视图时的实时媒体保持。
- **2026-06-12:QuickTalk 本地资产修复与 Apple Silicon 支持**
梳理 QuickTalk 本地权重、HuBERT、InsightFace 等资产路径,补充缺失资产检查、缓存准备和健康检查;新增 Apple Silicon 部署文档,支持在 macOS arm64 上使用 `quicktalk-cpu` 与 MPS / CPU 路线验证。
- **2026-06-12:IndexTTS、QuickTalk 与 FlashTalk 视频创作增强**
增加本地 IndexTTS 与 OmniRT IndexTTS provider、系统音色、音色预览和音色标签;完善 QuickTalk / IndexTTS 视频创作链路,并加入 FlashTalk reference video 生成和默认 reference driver。
- **2026-06-02/10:Persona Package、知识库检索与角色记忆**
新增 Persona Package API / CLI / WebUI 入口,可把角色设定、知识材料和提示词打包复用;接入 LightRAG 知识检索、会话级知识选择、角色记忆面板,以及 BM25 / mem0 / SQLite 等记忆 provider。
- **2026-06-05:资产库与知识库工作流**
扩展 WebUI 资产库,把形象资产、知识库材料、会话选择和 Agent 上下文构建串起来;同时补齐音频 / 视频导出,让演示、复盘和素材沉淀可以在同一套工作台完成。
- **2026-06-05/06:OpenAI-compatible 音频接口与 MuseTalk 部署优化**
新增 OpenAI-compatible STT / TTS 适配层、Xiaomi MiMo STT / TTS / voice clone profile、前端 provider 选择与音色列表,并把 `.env.example` 整理为 LLM / STT / TTS 独立 profile 模板。
同期优化 MuseTalk local / OmniRT 部署文档、资产准备脚本和 quickstart 启动脚本,降低 MuseTalk 路线的准备成本。
- **2026-06-04:FasterLivePortrait 视频创作与视频克隆**
新增 FasterLivePortrait 视频创作参数面板、视频克隆页面、自定义 source 资产上传、摄像头 / 上传视频 driving 输入和文档截图,复用 OmniRT + FasterLivePortrait runtime 路线。
- **2026-06-03:Web 录制导出、资产库与视频工作流**
新增 Web 录制导出、导出存储、视频创作入口和资产库工作台,打通从实时对话、素材管理到视频生成的基础流程。
- **2026-06-12/13:官网分析、GitHub 流量统计与部署文档**
补充官网英文页、部署路线展示、访问分析、GitHub traffic 统计、图表样式和统计周期修复;新增 Windows 部署中的 WSL2 网络模式选择指南,并持续更新 README 演示视频与文档站入口。
- **更早基础能力:实时对话主链路与模型 backend 解耦**
已建立 Web 控制台、LLM 对话、TTS、字幕事件、WebRTC 音视频播放、Avatar 资产预热缓存、统一 audio2video runner,以及 `mock` / `local` / `direct_ws` / `omnirt` 等可插拔模型后端。
## 文档与社区
- [快速开始](https://datascale-ai.github.io/opentalking/latest/quick-start/)
- [模型](https://datascale-ai.github.io/opentalking/latest/model-deployment/)(权重下载、国内源、启动、验证)
- [架构说明](https://datascale-ai.github.io/opentalking/latest/developer-guide/architecture/)
- [配置说明](https://datascale-ai.github.io/opentalking/latest/reference/configuration/)
- [部署文档](https://datascale-ai.github.io/opentalking/latest/deployment/)(Docker Compose、分布式部署)
- [模型适配](https://datascale-ai.github.io/opentalking/latest/developer-guide/model-adapter/)
- [贡献指南](CONTRIBUTING.md)(开发环境、CLI 工具、ruff / mypy / pytest)
欢迎加入 QQ / 微信交流群,讨论实时数字人、FlashTalk、OmniRT、模型部署和产品场景。
| QQ |
微信 |
 |
 |
AI 数字人交流群 · QQ 群号:1103327938 · 微信群
## 致谢
OpenTalking 参考并受益于实时数字人生态中的优秀项目:
- 感谢 [LINUX DO](https://linux.do/) 社区的支持与讨论。
- [SoulX-FlashTalk](https://github.com/Soul-AILab/SoulX-FlashTalk) 和 [SoulX-FlashTalk-14B](https://huggingface.co/Soul-AILab/SoulX-FlashTalk-14B)
- [LiveTalking](https://github.com/lipku/LiveTalking)
- [OmniRT](https://github.com/datascale-ai/omnirt)
- [Edge TTS](https://github.com/rany2/edge-tts)
- [aiortc](https://github.com/aiortc/aiortc)
- [Wan Video](https://github.com/Wan-Video)
## License
[Apache License 2.0](LICENSE)