TP4 - Document automatique
Initiation a R - STID 1ère année
Nous allons voir dans ce TP comment on peut produire un document (HTML, PDF voire Word) incluant à la fois le texte et les commandes R pour produire les éléments pour appuyer les commentaires (importation de données, tableaux, graphiques, …). Ce type de document peut être produit sous R avec rmarkdown
ce document a été écrit en
R markdown. Vous pouvez voir le fichier source ici. Pour mieux comprendre le langage, il est préférable de regarder le fichier source et ce document qui est donc la traduction du source en HTML.
Librairies
R fonctionne sur le principe d’un moteur de base, avec des fonctionnalités limitées. Celles-ci peuvent être augmentées grâce à l’ajout de librairies (appelées aussi packages). Il en existe de nombreuses, disponibles sur le site du CRAN (Comprehensive R Archive Network).
Chemin(s) de recherche des librairies
La commande .libPaths() permet de lister les différents répertoires dans lesquels R va pouvoir chercher les librairies. Si nous voulons en installer de nouvelles, et pouvoir les réutiliser plus tard, il faut donc spécifier un répertoire dans lequel nous avons les droits d’écriture.
Premièrement, il vous faut créer un répertoire dans votre "Z:/" qui contiendra les librairies R, par exemple nommé "Rlib", directement à la racine de votre "Z:/". Une fois celui-ci créé, vous pouvez indiquez à R qu’il doit aussi prendre en compte ce répertoire pour la recherche de librairies. Pour cela, vous devez exécuter la commande .libPaths("z:/Rlib"). Afin de vérfier que le répertoire a bien été ajouté, vous pouvez de nouveau lister les dossiers connus de R avec .libPaths(). Normalement, votre répertoire (ici "Z:/Rlib") doit être affiché en premier.
Voici donc les commandes à exécutées ici.
.libPaths()
.libPaths("z:/Rlib")
.libPaths()Attention. Cet ajout du répertoire "Z:/Rlib" aux chemins connus de R, via la commande .libPaths(), devra être effectué à chaque nouvelle session (i.e. à chaque fois que vous relancez RStudio donc).
Installation d’une librairie
Une fois le répertoire ajouté, nous pouvons installer les librairies directement dans R avec la commande install.packages(), en y listant les librairies voulues. Nous allons utilsier ici la librairie rmarkdown. Vous devez donc executer la commande suivante.
install.packages("rmarkdown")Quand vous l’exécuterez, vous verrez qu’il doit aussi installer d’autres librairies, appelées ici dépendances. Tout ceci est géré automatiquement par R sans que nous ayons à connaître la liste de ces dépendances.
Attention. L’installation d’une librairie n’est à faire qu’une seule fois.
Chargement d’une librairie
Une fois les librairies installées, il sera donc possible de les utiliser. Mais pour ceci, il faut tout d’abord les charger, à chaque session grâce à la fonction library(). Pour charger une librairie, il faudra donc exécuter un code de type :
library(rmarkdown)Attention. Le chargement d’une librairie via library() devra être effectuée à chaque nouvelle session, pour les librairies dont vous avez besoin.
Langage markdown
L’idée d’un document de type R markdown est donc d’inclure les commentaires et les commandes permettant d’obtenir les différents résultats. La syntaxe pour l’écriture du document est le langage markdown. Il a l’avantage d’être très simple à utiliser et à lire. Voici quelques éléments de base. Il a été fait pour ensuite être traduit en HTML.
Titres
Il y a deux façons d’écrire des titres. La première avec des "#" en début de ligne, pour produire des titres de niveau 1 (<h1>) à 6 (<h6>).
# Titre de niveau 1
## Titre de niveau 2
...
###### Titre de niveau 6L’autre ne concerne que les titres de niveau 1 et 2.
Titre de niveau 1
=================
Titre de niveau 2
-----------------Paragraphes et divers
Les paragraphes s’écrivent simplement, sans notation particulière. Un passage à la ligne seule ne sera pas suffisant pour un changement de paragraphe, il est nécessaire de laisser (au moins) une ligne entre deux paragraphes.
Il est possible de mettre en avant des mots de deux façons :
**mot(s) important(s)**: un ou plusieurs mots encadrés par des**(ou des__) seront transformés en balisestrong(souvent mis en gras)*mot(s) moins importants*: idem que précédement mais avec*(ou_), transformés en baliseem(souvent mis en italique)
Pour faire un lien vers une page ou une URL, il est possible d’utiliser plusieurs syntaxes :
<url>: lien mis directement (par exemple http://fxjollois.github.io)[texte](lien "texte optionnel"): lien mis sur un texte (par exemple ma page web)[texte][label]: lien mis sur un texte aussi, avec un pied de page ajouté plus tard avec[label]: url "texte optionnel"(par exemple page perso)
Pour intégrer des images dans un document markdown, on utilise un formalisme similaire aux liens, avec un !avant :
: le texte sert à contextualiser l’image
![texte][label]: on définit le label par la suite avec[label]: lien "texte optionnel"
re bla
On peut aussi ajouter des lignes horizontales, pour découper le texte. Pour cela, il est nécessaire d’écrire une ligne avec
- soit au moins 3 caractères identiques (
"*"ou"-") - soit 3 caractères identiques (toujours
"*"ou"-") séparés d’un espace.
Voici les quatre façons de faire donc, qui produiront le même résultat :
***
---
* * *
- - -Et un exemple de séparation
On peut aussi créer des blocs de citations (équivalent à la balise blockquote), en commençant les lignes par ">".
Voici un exemple de bloc de citation, permettant de mettre en avant des éléments importants.
Listes
Il est possible de créer deux types de listes (non-ordonnées et ordonnées). Il faut noter cependant que les listes doivent être séparées des paragraphes par (au moins) une ligne au-dessus et en-dessous. De plus, pour les sous-listes, il faut mettre une tabulation (ou deux si sous-sous-liste, et ainsi de suite).
Il est bien évidemment totalement possible de mélanger les deux types de listes si besoin.
Non-ordonnées
Ce sont les plus simples à écrire. Les items commencent tous par le même caractère. Le caractère utilisé ici ("-") peut être remplacé par "*" ou "+".
- 1er élément
- 2ème élément
- sous-élement A
- sous-élément B
- …
- etc…
Ordonnées
Pour avoir une liste ordonnée, il est nécessaire de commencer la ligne par un chiffre suivi de ".". Par contre, le chiffre indiqué n’est pas pris en compte. Ce qui fait que la sous-liste ici produira bien 1, 2 et 3.
- élément 1
- élément 2
- sous-élément 1
- sous-élément 2
- sous-élément 3
Tableaux
On peut définir un tableau directement, en précisant d’abord le nom des colonnes (séparés par "|"). Il faut ensuite faire une séparation via une ligne avec "---" (au moins) pour chaque colonne et toujours des séparations ("|") entre les colonnes. Ensuite, les valeurs de chaque ligne doivent être toujours séparées par des "|".
Le style de chaque colonne (aligné à gauche - par défaut, aligné à droite ou centré) peut être indiqué dans la ligne de séparation entre les noms de colonnes et les valeurs, avec
---(ou:--) : aligné à gauche--:: aligné à droite:-:: centré
Voici un exemple de tableau, dans lequel nous avons défini le style de chaque colonne
| col 1 | col 2 | … | col n |
|---|---|---|---|
| Ligne | complète | sur 4 | colonnes |
| Ligne | incomplète | à la fin | |
| ligne | incomplète | au début |
Codes
L’intérêt de ce langage est aussi de pouvoir intégrer des éléments de code (soit des blocs complets, soit des éléments en ligne), permettant de présenter le travail fait.
Bloc de code
Pour créer un bloc de code, il faut soit le précéder et le suivre d’une ligne avec ```, soit le faire commencer par une indentation (une tabulation ou 4 espaces).
# premier code quelconque
d = read.table("d")
summary(d)# deuxième code quelconque
dd = subset(d, var1 == valeur)
summary(dd)Code en ligne
Il est aussi possible d’écrire du code (par exemple un nom de fonction ou autre) dans une phrase, en encadrant ce code entre deux `, ce qui donne par exemple fonction().
Document R markdown
Un document R markdown (généralement enregistré avec l’extension .rmd ou .Rmd) permet d’une part d’utiliser la syntaxe markdown pour écrire du texte, mais aussi d’inclure des commandes R directement dans le document. Ainsi, un seul document contient le code et le commentaire, ce qui est un atout non négligeable pour des rapports ou présentations devant être mises à jour ou refaits régulièrement.
Il est possible d’inclure les commandes R soit dans un bloc de code, appelé chunck dans R Studio, ou en ligne, appelé inline chunck.
Pour créer un document R markdown dans R Studio, vous pouvez cliquer sur l’icône ![]() , puis sur R markdown…. Vous devez voir apparaître une interface vous demandant de choisir entre un document, une présentation, une application Shiny ou de choisir un template prédéfini. Nous allons rester sur le document pour le moment. De plus, vous pouvez indiquer le titre et l’auteur, ainsi que choisir le format de sortie (HTML, PDF ou Word). Nous allons garder HTML pour le moment.
, puis sur R markdown…. Vous devez voir apparaître une interface vous demandant de choisir entre un document, une présentation, une application Shiny ou de choisir un template prédéfini. Nous allons rester sur le document pour le moment. De plus, vous pouvez indiquer le titre et l’auteur, ainsi que choisir le format de sortie (HTML, PDF ou Word). Nous allons garder HTML pour le moment.
En-tête
Lors de la création d’un nouveau document R markdown, vous devez voir apparaître en début de document une partie d’en-tête, comme ci-dessous, au format YAML.
---
title: "Untitled"
author: "FX Jollois"
date: "17/10/2016"
output: html_document
---Dans cette en-tête, nous pouvons donc définir le titre, éventuellement un sous-titre (avec subtitle:), le ou les auteurs, la date et des options de sortie. Pour le moment, nous allons garder la sortie au format HTML. Pour passer au format PDF, il faut écrire pdf_document dans output (ainsi qu’avoir \(\LaTeX\) installé sur sa machine - ce qui n’est pas le cas à l’IUT). Pour créer un document de type Word, il faut choisir word_document pour output.
Il y a d’autres possibilités de sortie, ainsi que la possibilité d’ajouter d’autres paramètres de sortie, que nous ne verrons pas ici.
Chunck
Un chunck sera donc un bloc de commande R (ou autre langage possible) qui sera exécuté par R Studio. Pour cela, il faut indiquer sur la première ligne le langage utilisé. Pour R, voici donc un exemple simple
```{r}
# code R
summary(iris)
```Dans le document sera donc intégré à la fois le code, ainsi que le résultat de son exécution. L’exemple donnera donc
# code R
aggregate(. ~ Species, iris, mean)## Species Sepal.Length Sepal.Width Petal.Length Petal.Width
## 1 setosa 5.006 3.428 1.462 0.246
## 2 versicolor 5.936 2.770 4.260 1.326
## 3 virginica 6.588 2.974 5.552 2.026Il est possible de nommer le chunck en lui donnant un label (sans espace, sans accent) après r dans les {}. Ceci est intéressant surtout dans l’étape de développement, car si une erreur arrive lors de l’exécution, il sera plus facile de retrouver dans quel chunck est l’erreur (indiqué lors de l’affichage de l’erreur).
De plus, il est possible de mettre des options dans le chunck, toujours dans les {}, après une ",". Voici quelques options classiques et utiles (avec leur valeur par défaut indiquée, si elle existe) :
include = TRUE: siFALSE, le code est exécuté mais il n’est pas inclus dans le document (ni le code, ni son résultat)echo = TRUE: siFALSE, le code n’est pas affiché mais bien exécutéeval = TRUE: siFALSE, le code est affiché mais n’est pas exécutéresults = 'markup': permet de définir comment le résultat est affiché (intéressant pour les tableaux, cf plus loin)fig.cap: titre du graphique produit
Il est possible de mettre plusieurs options, toutes séparées par des ",".
Quelques exemples
Dans la suite, voici quelques exemples de chuncks avec options. Regardez le source pour mieux comprendre le fonctionnement.
Tout d’abord, on importe les données heart.txt, mais ce genre de code n’est souvent pas à inclure, dans le sens où l’on ne veut ni l’afficher, ni voir de résultat.
Ensuite, la librairie knitr contient une fonction kable() permettant d’afficher un data.frame au format markdown. Cela permet d’avoir un résultat plus lisible qu’une sortie de console R classique.
knitr::kable(head(heart))| age | sexe | type_douleur | pression | cholester | sucre | electro | taux_max | angine | depression | pic | vaisseau | coeur |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 70 | masculin | D | 130 | 322 | A | C | 109 | non | 2.4 | 2 | D | presence |
| 67 | feminin | C | 115 | 564 | A | C | 160 | non | 1.6 | 2 | A | absence |
| 57 | masculin | B | 124 | 261 | A | A | 141 | non | 0.3 | 1 | A | presence |
| 64 | masculin | D | 128 | 263 | A | A | 105 | oui | 0.2 | 2 | B | absence |
| 74 | feminin | B | 120 | 269 | A | C | 121 | oui | 0.2 | 1 | B | absence |
| 65 | masculin | D | 120 | 177 | A | A | 140 | non | 0.4 | 1 | A | absence |
Enfin, on peut vouloir faire un graphique, ce qui pourrait donner ce qui suit. Pour ce genre de présentation, nous pouvons décider de ne pas afficher le code permettant de les obtenir.
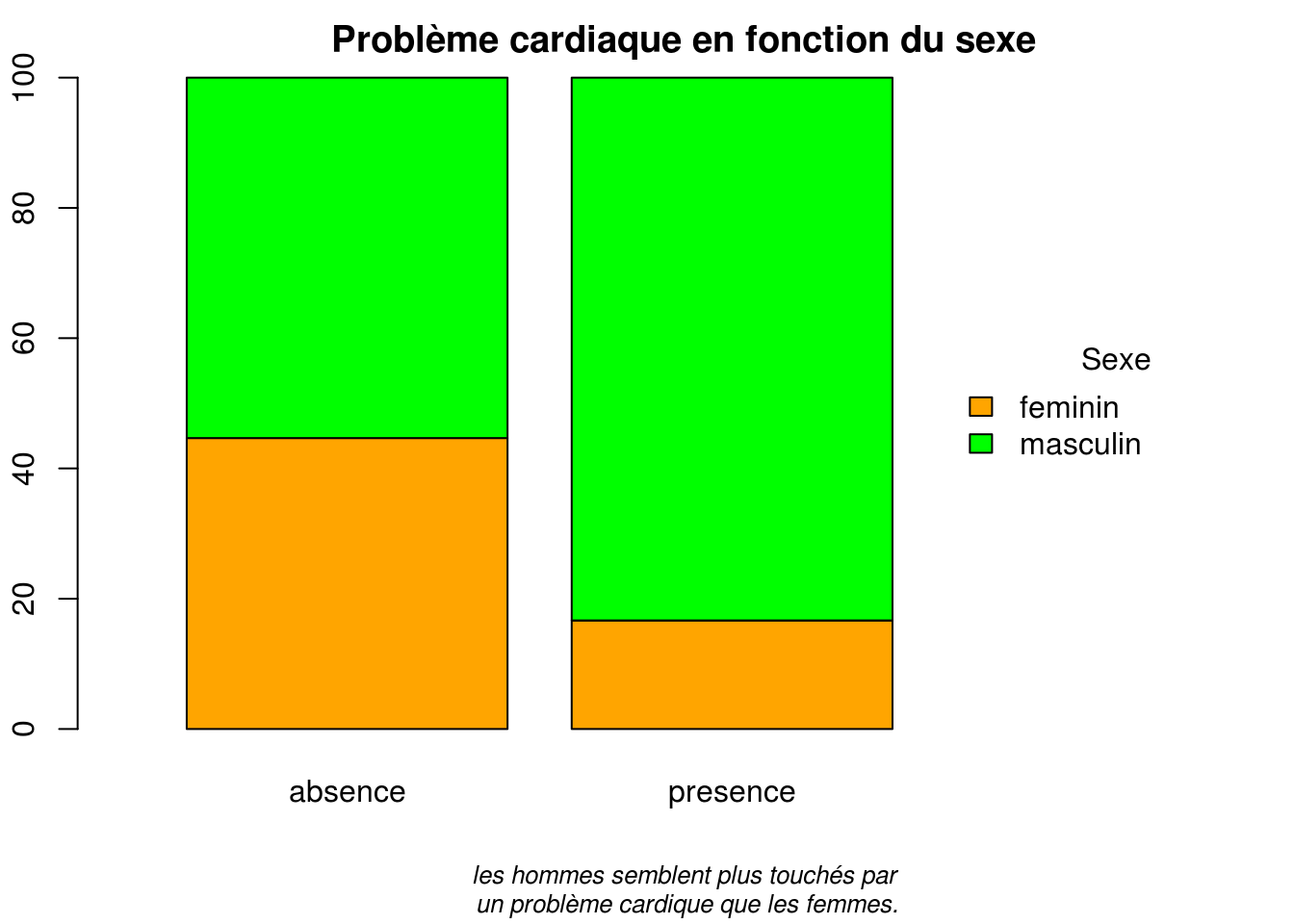
Répartition du sexe des individus selon le problème cardiaque
Inline chunck
On peut faire des chuncks en ligne en encadrant le code avec des ` et en commencant le code par un r. Par exemple, on peut dire que dans le jeu de données heart sont présentés 270 individus et 13 variables.
Paramètres globaux des chuncks
Il est possible de déterminer des paramètres globaux pour tous les blocs chuncks du document (sauf paramètres locaux précisés). Ceci doit se faire comme suit, avec la fonction set() de l’objet opts_chunck de la librairie knitr. Il est par exemple possible de définir echo=FALSE pour n’avoir aucun code apparaissant dans le document.
knitr::opts_chunk$set(...)Exercice
Dans votre document, penser à nommer chaque chunck différement. Et n’hésiter pas à commenter le document pour le rendre plus conforme à ce qu’on pourrait vouloir produire comme document.
Vous trouverez sur le site rmarkdown beaucoup d’informations et de compléments sur cette librairie. Beaucoup sont résumées dans ce document.
- Créer un nouveau document
R markdown, intitulé"TP4", avec votre nom comme auteur - Sauvegarder ce document sous le nom
"TP4.Rmd" - Cliquer sur
 pour voir le résultat de l’exemple fourni
pour voir le résultat de l’exemple fourni - Supprimer le contenu du document, en gardant uniquement l’en-tête
- Paramétrer l’ensemble des chuncks pour ne pas voir apparaître le code des chuncks dans le résultat
- Créer 4 titres de niveau 2, avec le contenu suivant
- Données :
- écrire un texte introductif précisant (en ligne) le nombre de lignes et de colonnes du jeu de données
mtcars, et incluant un lien vers la pagede présentation https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/mtcars.html - afficher proprement l’ensemble du jeu de données
- écrire un texte introductif précisant (en ligne) le nombre de lignes et de colonnes du jeu de données
- Consommation
- Histogramme de la consommation (variable
mpg, fonctionhist()) - Boîte à moustache horizontale (fonction
boxplot())
- Histogramme de la consommation (variable
- Transmission :
- créer une nouvelle variable
transdans le jeu de donnéesmtcarsprenant comme valeur"automatic"pouram == 0et"manual"pouram == 1, en affichant le code pour la créer - afficher un tableau à deux colonnes :
"Transmission"avec les deux modalités detrans"Effectif"avec l’effectif pour chaque transmission
- afficher le diagramme circulaire de la répartition des voitures en fonction de leur transmission avec les paramètres suivants (fonction
pie()et fonctiontable()) :- un titre de figure indiquant ce qui est représenté (cf
fig.cap) - centrage dans le document (cf
fig.align) - largeur et hauteur de
2.5(cffig.widthetfig.height) - la couleur
"orange"pour"automatic"et"blue"pour"manual"(optioncolorde la fonctionpie())
- un titre de figure indiquant ce qui est représenté (cf
- créer une nouvelle variable
- Consommation et transmission : trois sous-parties (avec des titres de niveau 3 à mettre)
- Sous-tables : Faire deux sous-tables, une pour
"automatic", l’autre pour"manual" - Automatique : représenter l’histogramme et la boîte à moustaches de la consommation pour les voitures à transmission automatique
- Manuel : faire de même pour les voitures à transmission manuelle
- Sous-tables : Faire deux sous-tables, une pour
- Données :