Initiation à R
DU Analyste Big Data
Dans ce document sont présentés les concepts principaux du logiciel R (éléments de langage, données manipulées, manipulation de données, …).
Données et éléments de langage
Types de données
R permet de manipuler différents types de données tel que :
- scalaire : une valeur de type
numeric,character,logical,date vector: tableau de scalaires de même type (numeric,character,logical,date,factor)matrix: tableau à deux dimensions de scalaires de même type (numeric,logicialoucharacter)array: extension dematrixà \(d\) dimensionsdata.frame: ensemble de lignes (entités, parfois nommées) décrites par des colonnes nommées (dites variables aussi), pouvant être de types différents - très proche de la définition d’une table dans un SGBD classiquelist: liste d’éléments (nommés ou non, et pas forcément de même type)
Voici un exemple avec le jeu de données mtcars déjà présent dans le logiciel R :
# Type de la variable mtcars
class(mtcars) ## [1] "data.frame"# Dimensions
dim(mtcars)## [1] 32 11nrow(mtcars)## [1] 32ncol(mtcars)## [1] 11# Données en elles-mêmes
mtcars## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2Typage faible
R est un langage de programmation à typage faible : le type de la variable est déterminée par la valeur qui lui est affectée. Ce qui veut dire qu’il est possible d’affecter une chaîne de caractères à une variable numérique. Celle-ci deviendra automatique de type chaîne de caractère. Et il n’y a pas d’opérateurs de déclaration de variables. Celle-ci est créée à sa première utilisation, dans l’environnement actuel.
Création d’une variable numérique
a = 1
print(a)## [1] 1class(a)## [1] "numeric"Affectation d’une chaîne de caractère à une variable numérique
a = "bonjour"
print(a)## [1] "bonjour"class(a)## [1] "character"Conclusion
Attention donc lors de l’écriture des programmes…
Langage scripté
R est un langage scripté : il faut exécuter les commandes les unes après les autres dans la console. Mais il est possible d’écrire des scripts dans des fichiers (souvent avec l’extension .R), puis de les appeler via la commande source()
source("chemin/vers/mon/fichier.R")Accès aux données
Voici quelques éléments pour accéder aux différentes valeurs présentes dans le data.frame mtcars :
Valeurs de la 1ère ligne -> vector
mtcars[1,]## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21 6 160 110 3.9 2.62 16.46 0 1 4 4Valeurs de la 1ère colonne (nommée mpg) -> vector
mtcars[,1]## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.4mtcars$mpg## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.4mtcars[1] # en mode data.frame## mpg
## Mazda RX4 21.0
## Mazda RX4 Wag 21.0
## Datsun 710 22.8
## Hornet 4 Drive 21.4
## Hornet Sportabout 18.7
## Valiant 18.1
## Duster 360 14.3
## Merc 240D 24.4
## Merc 230 22.8
## Merc 280 19.2
## Merc 280C 17.8
## Merc 450SE 16.4
## Merc 450SL 17.3
## Merc 450SLC 15.2
## Cadillac Fleetwood 10.4
## Lincoln Continental 10.4
## Chrysler Imperial 14.7
## Fiat 128 32.4
## Honda Civic 30.4
## Toyota Corolla 33.9
## Toyota Corona 21.5
## Dodge Challenger 15.5
## AMC Javelin 15.2
## Camaro Z28 13.3
## Pontiac Firebird 19.2
## Fiat X1-9 27.3
## Porsche 914-2 26.0
## Lotus Europa 30.4
## Ford Pantera L 15.8
## Ferrari Dino 19.7
## Maserati Bora 15.0
## Volvo 142E 21.4Valeur à la cellule (1,1)
mtcars[1,1]## [1] 21mtcars$mpg[1]## [1] 21Noms des variables
names(mtcars)## [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
## [11] "carb"colnames(mtcars)## [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
## [11] "carb"Nom des lignes
rownames(mtcars)## [1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710"
## [4] "Hornet 4 Drive" "Hornet Sportabout" "Valiant"
## [7] "Duster 360" "Merc 240D" "Merc 230"
## [10] "Merc 280" "Merc 280C" "Merc 450SE"
## [13] "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood"
## [16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128"
## [19] "Honda Civic" "Toyota Corolla" "Toyota Corona"
## [22] "Dodge Challenger" "AMC Javelin" "Camaro Z28"
## [25] "Pontiac Firebird" "Fiat X1-9" "Porsche 914-2"
## [28] "Lotus Europa" "Ford Pantera L" "Ferrari Dino"
## [31] "Maserati Bora" "Volvo 142E"Descriptif de chaque variable d’un data.frame
str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...Eléments de langage
Voici quelques commandes utiles
Création d’un vecteur et d’une matrice
# vecteur de numériques
c(1, 3, 5)## [1] 1 3 5# vecteur de chaînes de caractères
c("a", "b")## [1] "a" "b"# vecteur de type et de taille définie
vector('logical', 5)## [1] FALSE FALSE FALSE FALSE FALSE# séquence de base
1:5## [1] 1 2 3 4 5# idem
seq(1, 5)## [1] 1 2 3 4 5# séquence avec définition de la taille du vecteur
seq(1, 5, length = 10)## [1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667
## [8] 4.111111 4.555556 5.000000# séquence avec définition du pas
seq(0, 1, by = 0.1)## [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0# répétition d'une valeur
rep(1, 5)## [1] 1 1 1 1 1# répétition d'un vecteur
rep(1:2, 5)## [1] 1 2 1 2 1 2 1 2 1 2# répétition d'un vecteur, 2ème version
rep(1:2, each = 5)## [1] 1 1 1 1 1 2 2 2 2 2# matrice
matrix(1:10, 2, 5)## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10# création d'un vecteur et redimensionnement de celui-ci -> résultat identique à précédemment
m = 1:10
dim(m) = c(2,5)
print(m)## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10Fonction sur les lignes ou les colonnes d’une matrice
Application d’une fonction (sum() ici) sur les lignes (1) ou sur les colonnes (2) d’une matrice.
apply(m, 1, sum) # somme sur les lignes## [1] 25 30apply(m, 2, sum) # somme sur les colonnes## [1] 3 7 11 15 19Fonction sur les parties d’un vecteur
Application d’une fonction (ici mean()) sur les groupes de valeurs d’un vecteur, groupes déterminés par les modalités d’un autre vecteur.
# Consommation des voitures (Miles/(US) gallon)
mtcars$mpg## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.4# Transmission (0 = automatic, 1 = manual)
mtcars$am## [1] 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1# Consommation moyenne par type de transmission
tapply(mtcars$mpg, mtcars$am, mean)## 0 1
## 17.14737 24.39231Combinaison des deux fonctions précédentes
En combinant les deux méthodes vu avant, on peut effectuer des opérations de type moyenne de plusieurs variables d’un jeu de données, pour chaque modalité d’une variable qualitative.
# Moyenne par type de moteurs (en terme de nombre de cylindres)
# sur les variables quantitatives de mtcars
apply(mtcars[,c("mpg", "disp", "hp", "drat", "wt", "qsec")], 2, tapply, mtcars$cyl, mean)## mpg disp hp drat wt qsec
## 4 26.66364 105.1364 82.63636 4.070909 2.285727 19.13727
## 6 19.74286 183.3143 122.28571 3.585714 3.117143 17.97714
## 8 15.10000 353.1000 209.21429 3.229286 3.999214 16.77214Interrogation de données
Il est fait référence ici aux principes de l’interrogation de données au sens SQL (et plus particulièrement la partie requêtage).
Restriction et projection
La fonction subset() permet d’effectuer les deux opérations. Dans le paramètre subset, on indique la condition (simple ou combinée) permet de faire la restriction. Et dans le paramètre select, on liste les variables de la projection.
subset(mtcars, subset = cyl == 4, select = c(cyl, mpg))## cyl mpg
## Datsun 710 4 22.8
## Merc 240D 4 24.4
## Merc 230 4 22.8
## Fiat 128 4 32.4
## Honda Civic 4 30.4
## Toyota Corolla 4 33.9
## Toyota Corona 4 21.5
## Fiat X1-9 4 27.3
## Porsche 914-2 4 26.0
## Lotus Europa 4 30.4
## Volvo 142E 4 21.4Il est aussi possible de faire ces deux opérations dans les [] avec un test logique et en indiquant la liste des variables à prendre.
mtcars[mtcars$cyl == 4, c("cyl", "mpg")]## cyl mpg
## Datsun 710 4 22.8
## Merc 240D 4 24.4
## Merc 230 4 22.8
## Fiat 128 4 32.4
## Honda Civic 4 30.4
## Toyota Corolla 4 33.9
## Toyota Corona 4 21.5
## Fiat X1-9 4 27.3
## Porsche 914-2 4 26.0
## Lotus Europa 4 30.4
## Volvo 142E 4 21.4Calcul de nouvelles variables
La fonction tranform() permet d’ajouter de nouvelles variables, soit résultantes d’un calcul (cf ci-dessous), soit permettant seulement un renommage d’une variable.
transform(mtcars[,c("cyl", "disp")], disp_cyl = round(disp / cyl, 2))## cyl disp disp_cyl
## Mazda RX4 6 160.0 26.67
## Mazda RX4 Wag 6 160.0 26.67
## Datsun 710 4 108.0 27.00
## Hornet 4 Drive 6 258.0 43.00
## Hornet Sportabout 8 360.0 45.00
## Valiant 6 225.0 37.50
## Duster 360 8 360.0 45.00
## Merc 240D 4 146.7 36.67
## Merc 230 4 140.8 35.20
## Merc 280 6 167.6 27.93
## Merc 280C 6 167.6 27.93
## Merc 450SE 8 275.8 34.48
## Merc 450SL 8 275.8 34.48
## Merc 450SLC 8 275.8 34.48
## Cadillac Fleetwood 8 472.0 59.00
## Lincoln Continental 8 460.0 57.50
## Chrysler Imperial 8 440.0 55.00
## Fiat 128 4 78.7 19.68
## Honda Civic 4 75.7 18.93
## Toyota Corolla 4 71.1 17.77
## Toyota Corona 4 120.1 30.02
## Dodge Challenger 8 318.0 39.75
## AMC Javelin 8 304.0 38.00
## Camaro Z28 8 350.0 43.75
## Pontiac Firebird 8 400.0 50.00
## Fiat X1-9 4 79.0 19.75
## Porsche 914-2 4 120.3 30.07
## Lotus Europa 4 95.1 23.77
## Ford Pantera L 8 351.0 43.88
## Ferrari Dino 6 145.0 24.17
## Maserati Bora 8 301.0 37.62
## Volvo 142E 4 121.0 30.25Calcul d’agrégat
On peut déjà se servir de la combinaison des fonctions apply() et tapply() comme vu précédemment. Il existe aussi la fonction aggregate(), où l’on définit explicitement les agrégats à effectuer et les calculs à produire (un seul type de calcul par fonction néanmoins).
# Agrégat simple : consommation moyenne générale
aggregate(mpg ~ 1, data = mtcars, mean)## mpg
## 1 20.09062# Agrégat classique : consommation moyenne en fonction du nombre de cylindres
aggregate(mpg ~ cyl, data = mtcars, mean)## cyl mpg
## 1 4 26.66364
## 2 6 19.74286
## 3 8 15.10000# Agrégat à deux variables : idem en fonction en plus de la transmission
aggregate(mpg ~ cyl + am, data = mtcars, mean)## cyl am mpg
## 1 4 0 22.90000
## 2 6 0 19.12500
## 3 8 0 15.05000
## 4 4 1 28.07500
## 5 6 1 20.56667
## 6 8 1 15.40000# Agrégat sur deux variables : idem mais pour la puissance aussi
aggregate(cbind(mpg, hp) ~ cyl + am, data = mtcars, mean)## cyl am mpg hp
## 1 4 0 22.90000 84.66667
## 2 6 0 19.12500 115.25000
## 3 8 0 15.05000 194.16667
## 4 4 1 28.07500 81.87500
## 5 6 1 20.56667 131.66667
## 6 8 1 15.40000 299.50000Jointures
Pour effectuer tout type de jointure, nous utilisons la fonction merge(), dans laquelle on indique les deux tables (correspondant à x et y respectivement). Les paramètres booléens all, all.x et all.y permettent de dire, s’ils sont à la valeur TRUE, quelle type de jointure externe on désire (resp. FULL, LEFT et RIGHT). Par défaut, la jointure se faire sur l’égalité des variables de mêmes noms entre les deux data.frame. On peut spécifier les variables à utiliser dans les paramètres by, by.x et by.y.
moteur = data.frame(cyl = c(4, 6, 8, 12), def = c("petit moteur", "moteur moyen", "gros moteur", "encore plus gros moteur"))
print(moteur)## cyl def
## 1 4 petit moteur
## 2 6 moteur moyen
## 3 8 gros moteur
## 4 12 encore plus gros moteurmerge(
moteur,
aggregate(mpg ~ cyl, data = mtcars, mean),
all = TRUE
)## cyl def mpg
## 1 4 petit moteur 26.66364
## 2 6 moteur moyen 19.74286
## 3 8 gros moteur 15.10000
## 4 12 encore plus gros moteur NASinon, du SQL sur les data.frame
La librairie sqldf permet d’exécuter des requêtes SQL directement sur les data.frame présents dans R. Voici un exemple simple :
library(sqldf)## Loading required package: gsubfn## Loading required package: proto## Loading required package: RSQLitesqldf("
SELECT cyl, AVG(mpg), AVG(disp), AVG(hp), AVG(drat), AVG(wt), AVG(qsec)
FROM mtcars
GROUP BY cyl;
")## cyl AVG(mpg) AVG(disp) AVG(hp) AVG(drat) AVG(wt) AVG(qsec)
## 1 4 26.66364 105.1364 82.63636 4.070909 2.285727 19.13727
## 2 6 19.74286 183.3143 122.28571 3.585714 3.117143 17.97714
## 3 8 15.10000 353.1000 209.21429 3.229286 3.999214 16.77214Quelques statistiques descriptives
La fonction summary() calcule des statistiques basiques sur un vecteur, celles-ci étant dépendantes du type du vecteur. Si elle est appliquée sur un data.frame, elle s’applique sur chaque variable.
summary(mtcars)## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000summary(mtcars$mpg)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.40 15.43 19.20 20.09 22.80 33.90summary(mtcars$cyl)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.000 4.000 6.000 6.188 8.000 8.000summary(as.factor(mtcars$cyl))## 4 6 8
## 11 7 14Univarié
On peut accéder aux fonctions de calculs des statistiques descriptives directement. Pour les variables quantitatives, nous allons utiliser comme exemple mpg qui représente la consommation.
mean(mtcars$mpg)## [1] 20.09062sum(mtcars$mpg)## [1] 642.9var(mtcars$mpg)## [1] 36.3241sd(mtcars$mpg)## [1] 6.026948min(mtcars$mpg)## [1] 10.4max(mtcars$mpg)## [1] 33.9range(mtcars$mpg)## [1] 10.4 33.9median(mtcars$mpg)## [1] 19.2quantile(mtcars$mpg)## 0% 25% 50% 75% 100%
## 10.400 15.425 19.200 22.800 33.900quantile(mtcars$mpg, probs = 0.99)## 99%
## 33.435quantile(mtcars$mpg, probs = c(0.01, 0.1, 0.9, 0.99))## 1% 10% 90% 99%
## 10.400 14.340 30.090 33.435Il existe tout un ensemble de fonctions graphiques, dont voici quelques exemples.
hist(mtcars$mpg)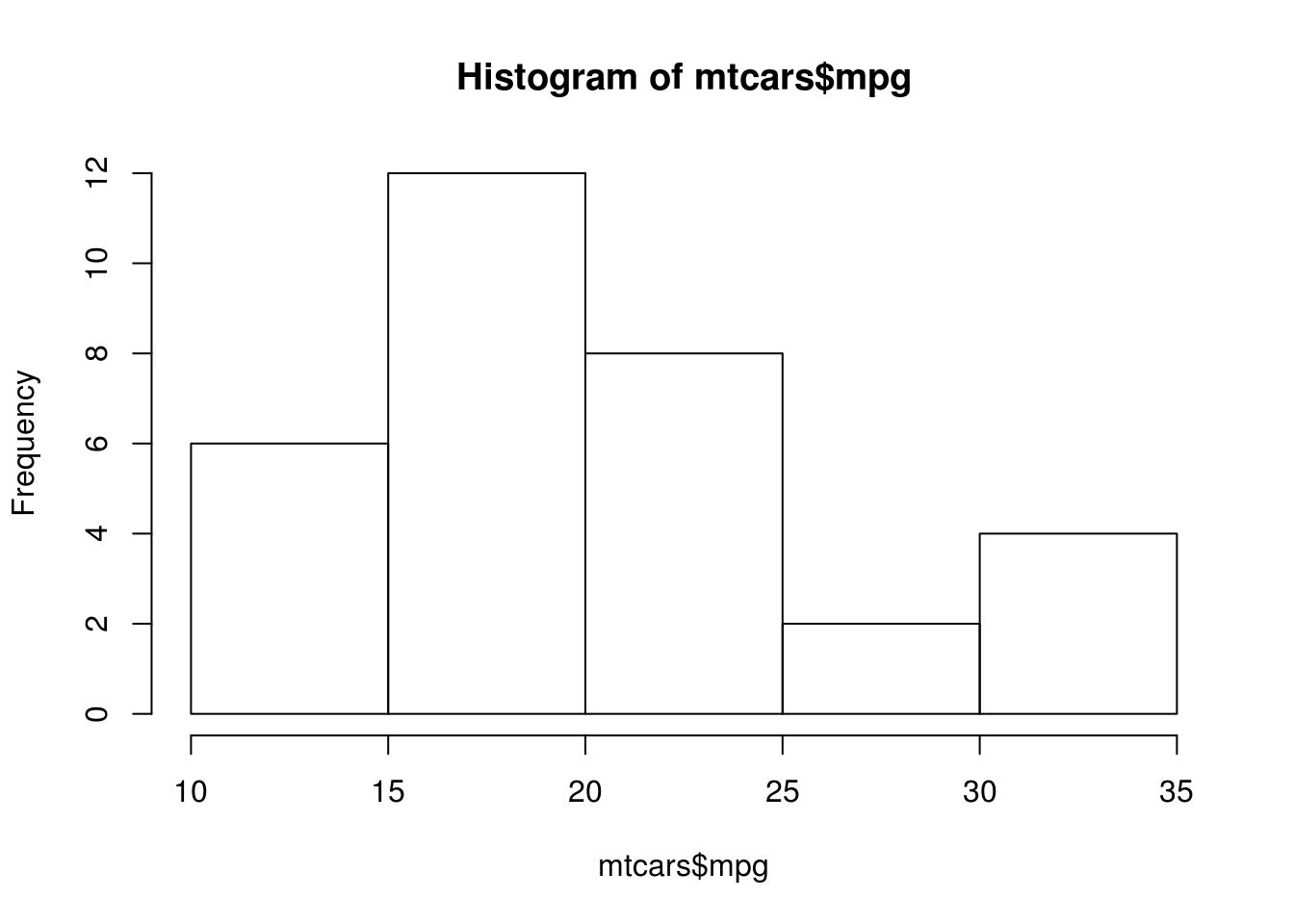
hist(mtcars$mpg, breaks = 20)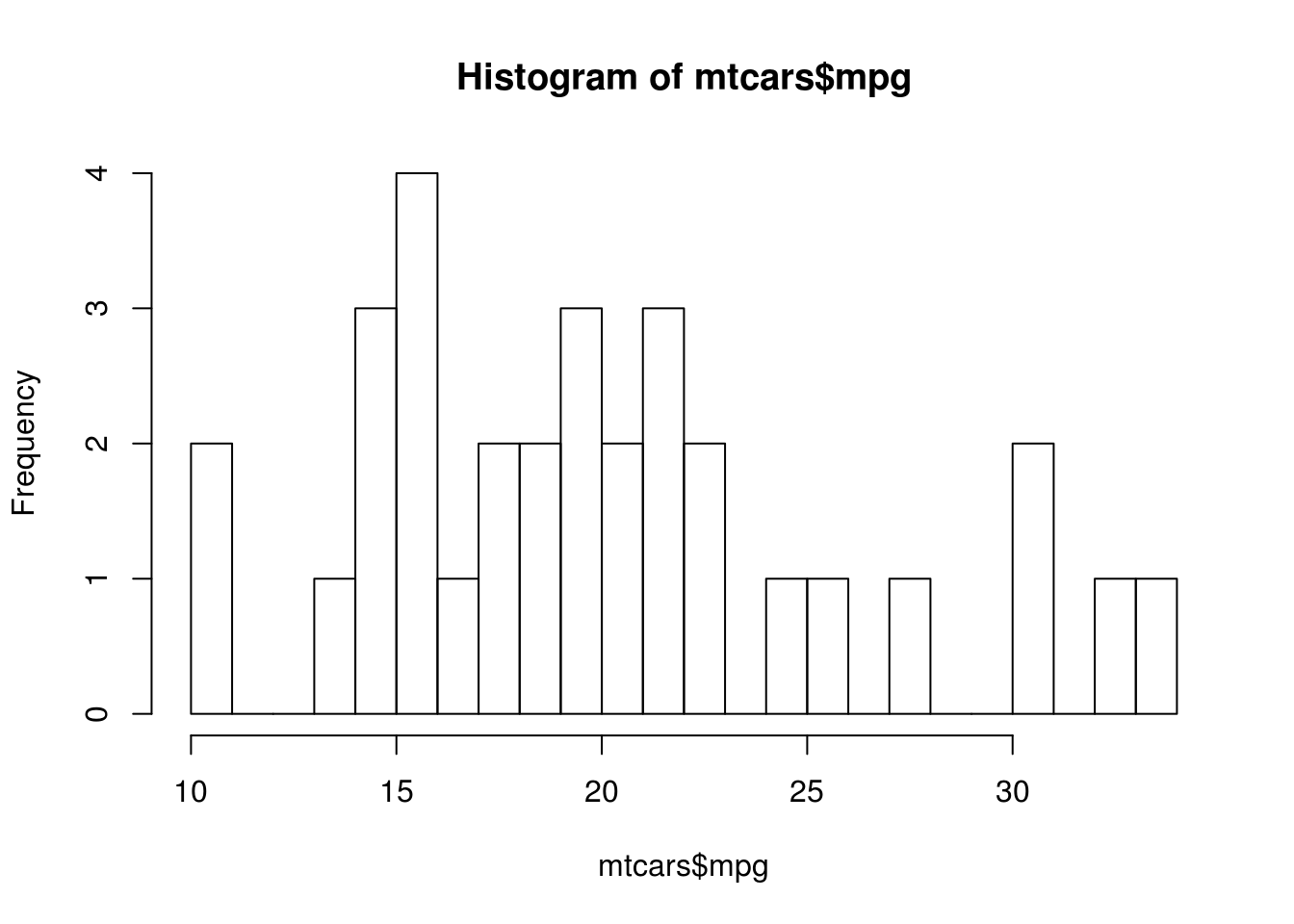
hist(mtcars$mpg, breaks = c(10, 15, 18, 20, 22, 25, 35))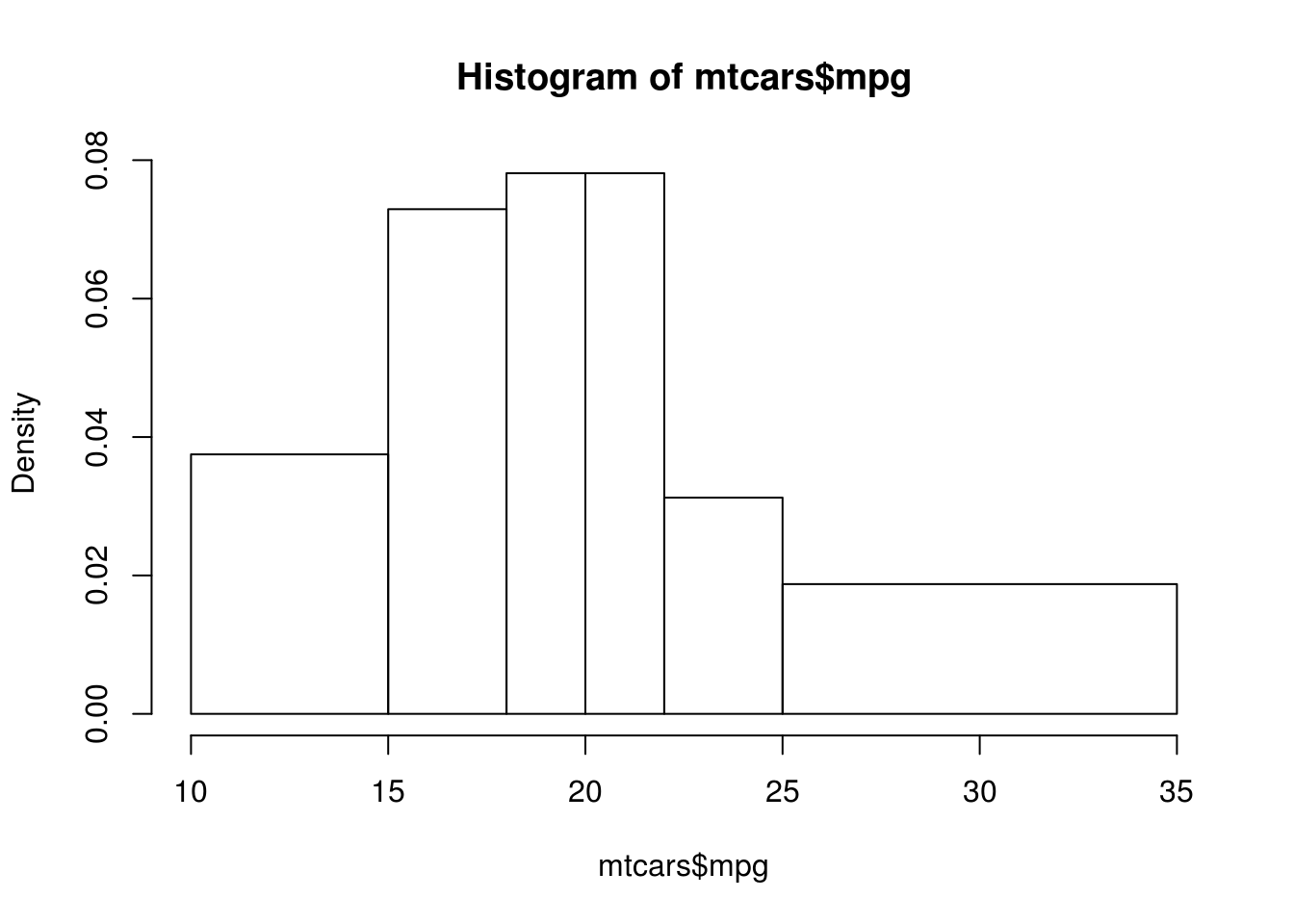
boxplot(mtcars$mpg)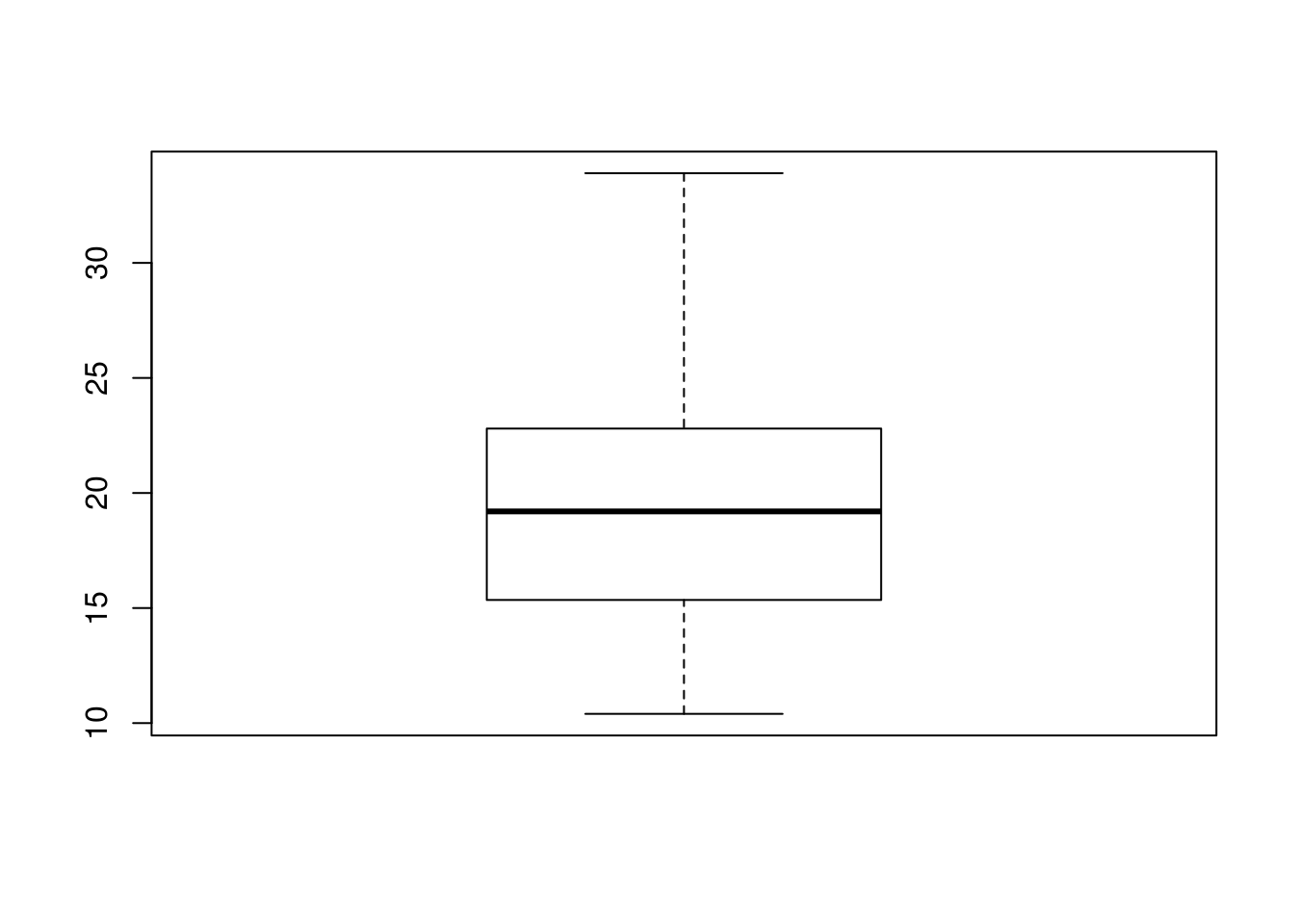
qqnorm(mtcars$mpg)
qqline(mtcars$mpg)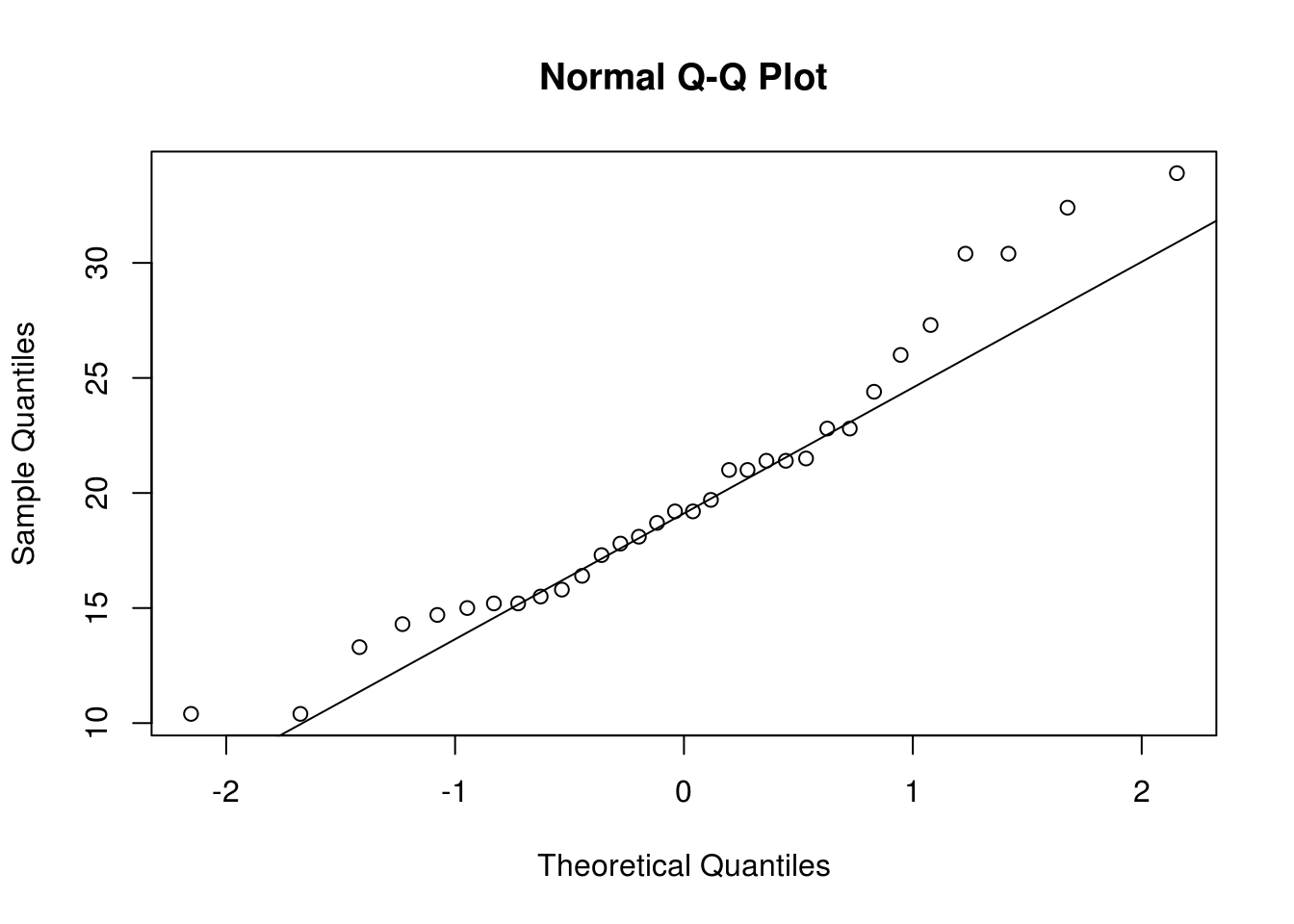
Pour les variables qualitatives, nous allons utiliser la variable cyl qui représente le nombre de cylindre. Celle-ci étant codée numériquement, toutes les fonctions vues précédemment pour s’appliquer (mais n’avoir aucun sens).
table(mtcars$cyl)##
## 4 6 8
## 11 7 14prop.table(table(mtcars$cyl))##
## 4 6 8
## 0.34375 0.21875 0.43750barplot(table(mtcars$cyl))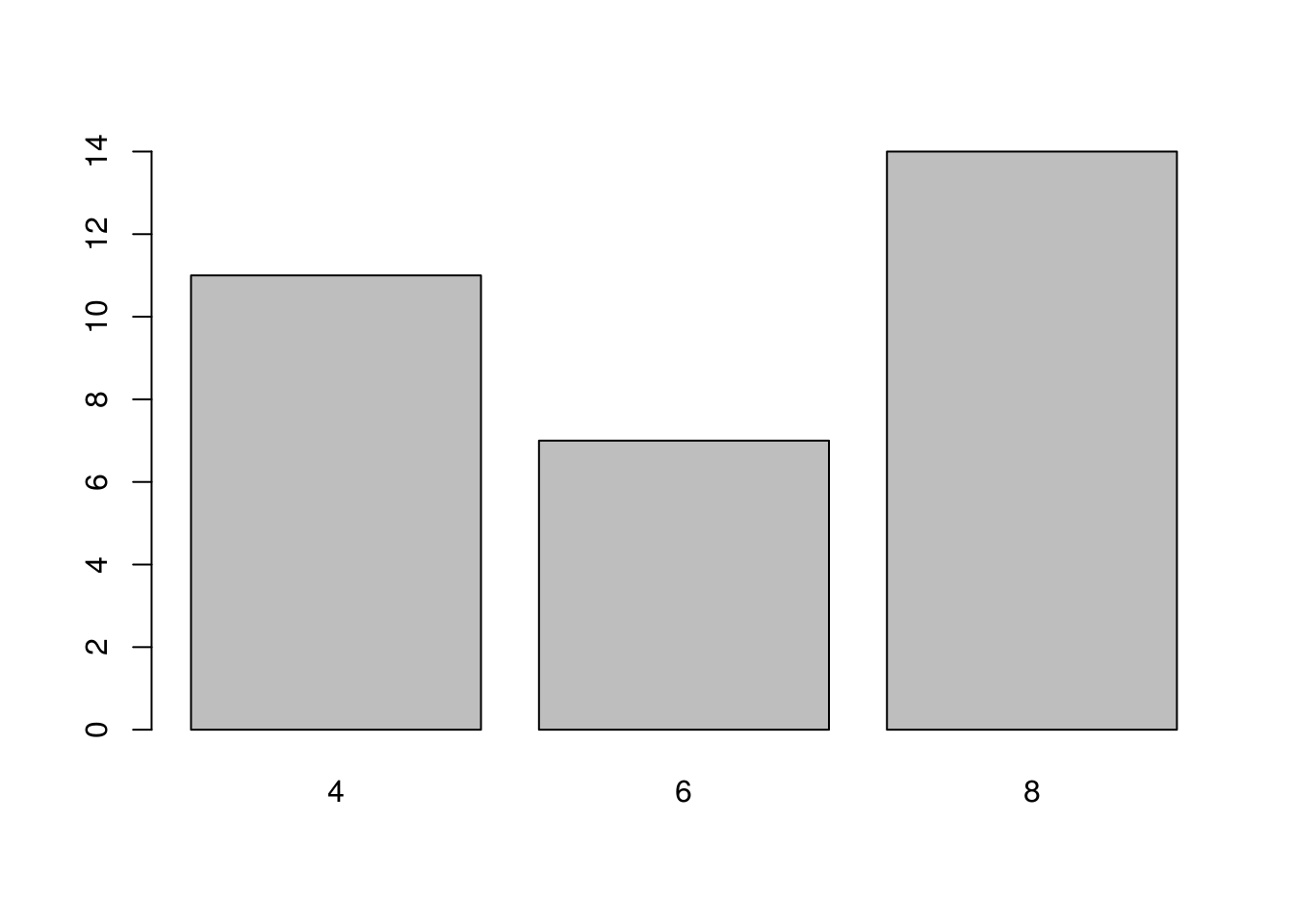
pie(table(mtcars$cyl))
Bivarié
Quanti - Quanti
Dans ce cadre, on peut bien évidemment calculer les statistiques usuelles (covariance, corrélation) et le nuage de points.
cov(mtcars$mpg, mtcars$wt)## [1] -5.116685cor(mtcars$mpg, mtcars$wt)## [1] -0.8676594plot(mtcars$mpg, mtcars$wt)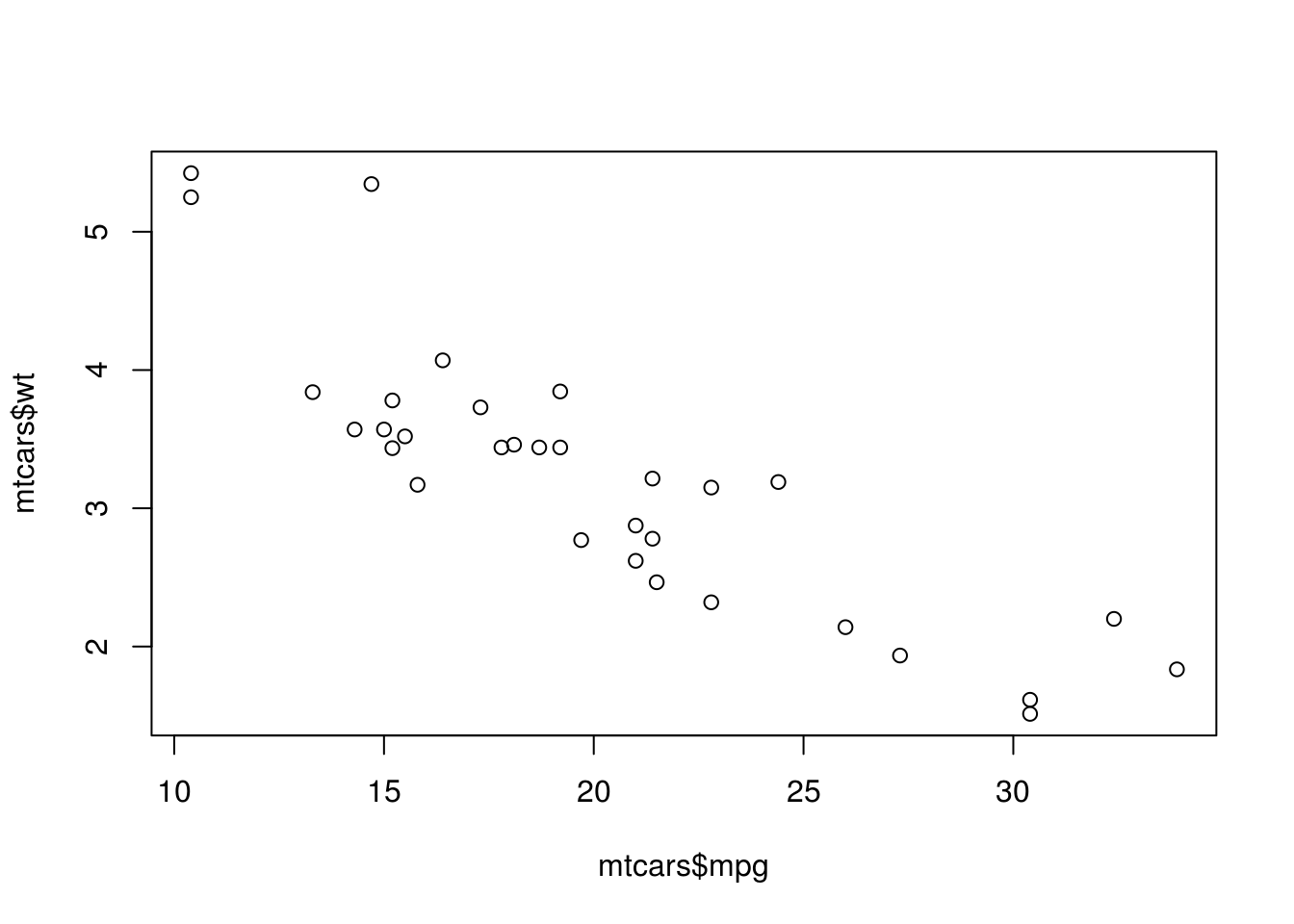
plot(mtcars$mpg ~ mtcars$wt)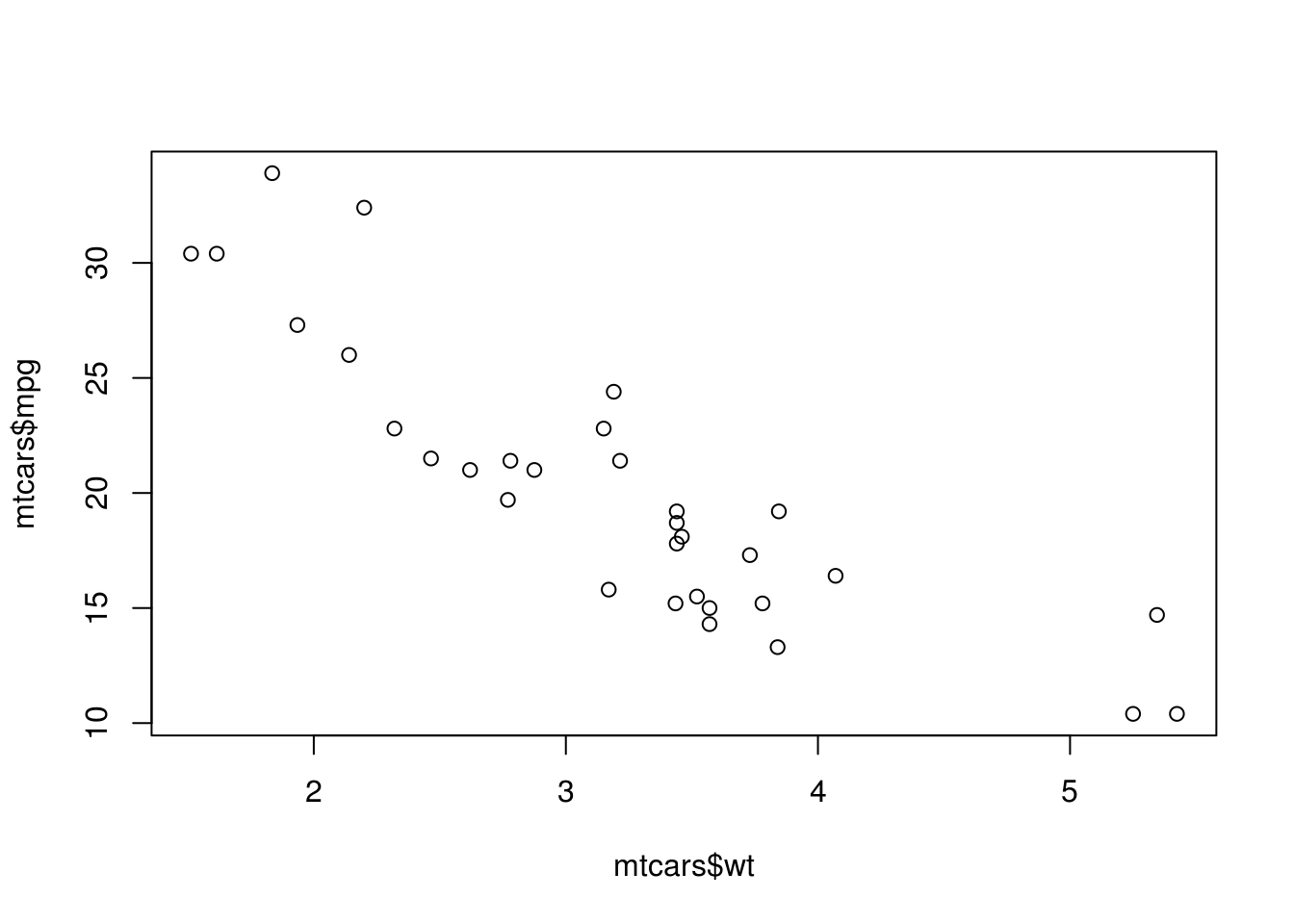
On peut aller plus loin en faisant un modéle linéaire simple.
m = lm(mpg ~ wt, data = mtcars)
m##
## Call:
## lm(formula = mpg ~ wt, data = mtcars)
##
## Coefficients:
## (Intercept) wt
## 37.285 -5.344summary(m)##
## Call:
## lm(formula = mpg ~ wt, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5432 -2.3647 -0.1252 1.4096 6.8727
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
## wt -5.3445 0.5591 -9.559 1.29e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.046 on 30 degrees of freedom
## Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
## F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10plot(m)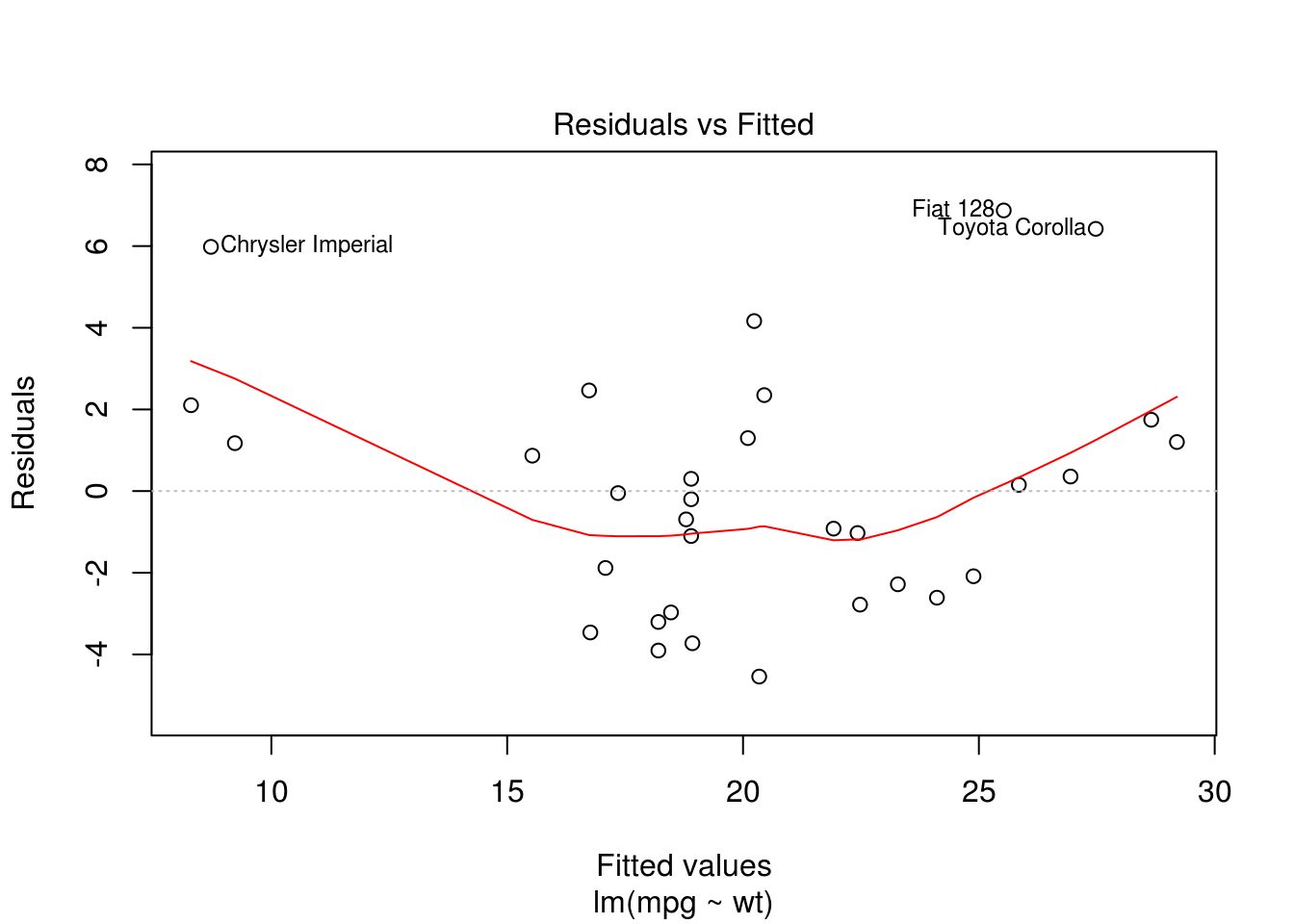
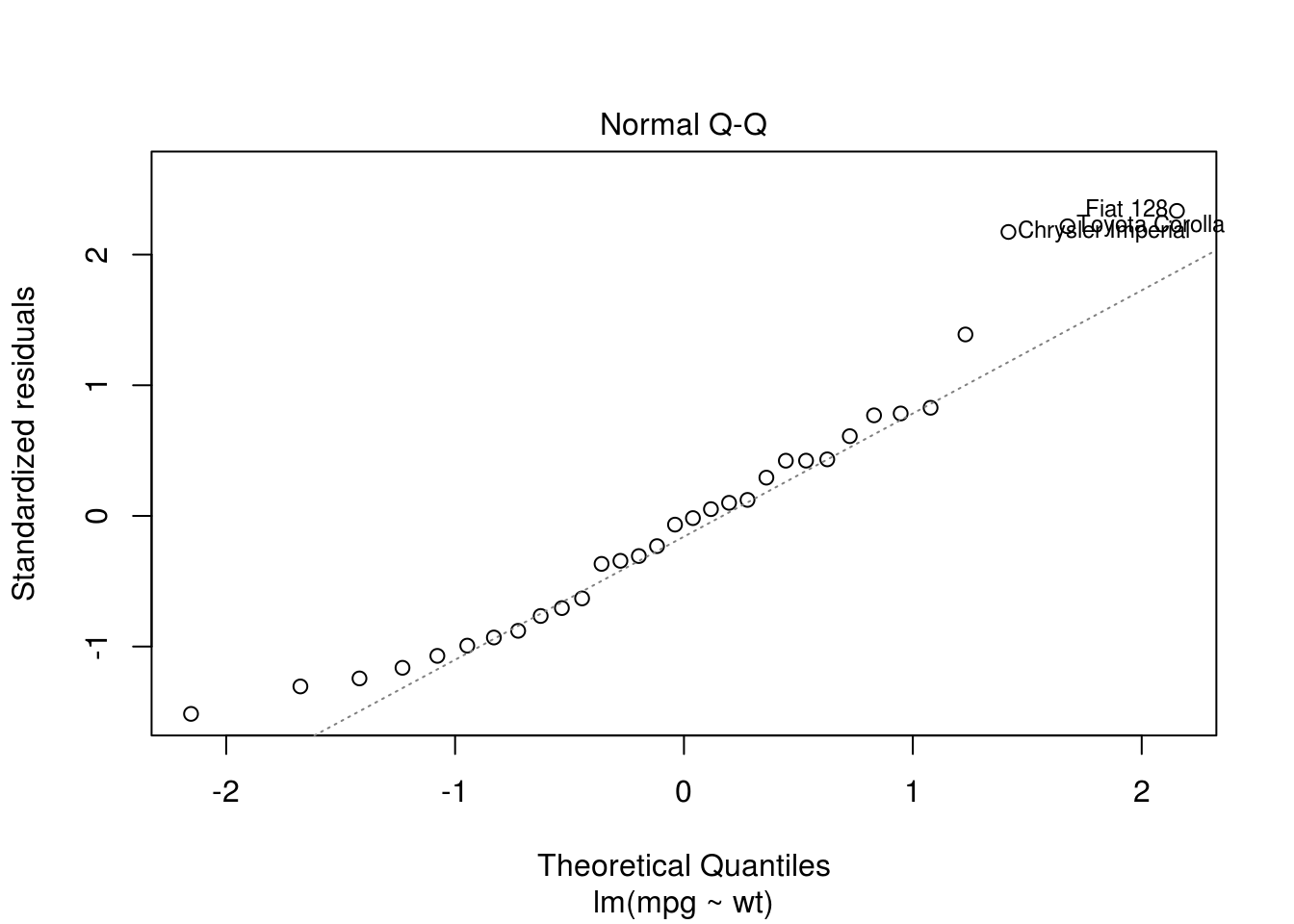
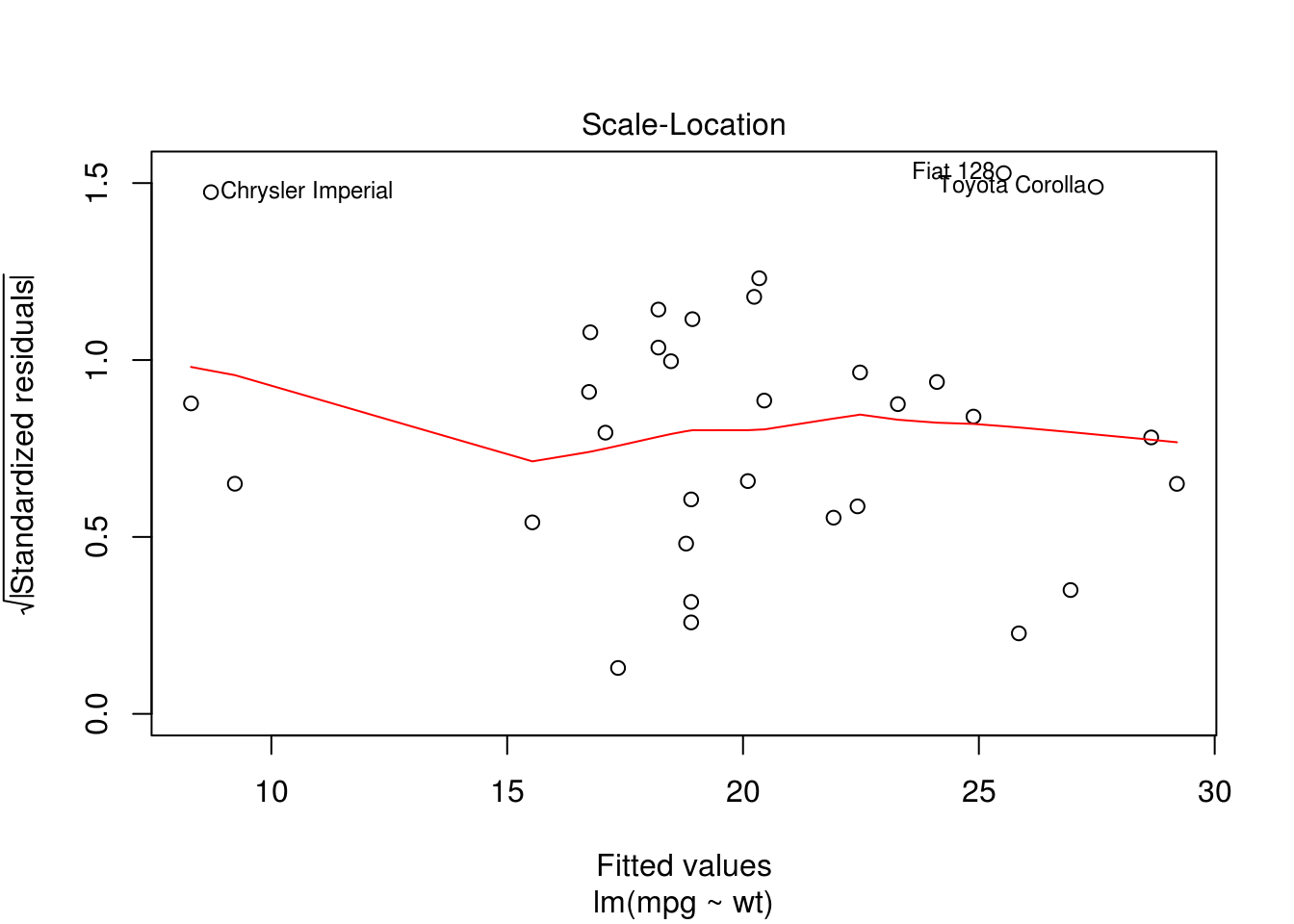
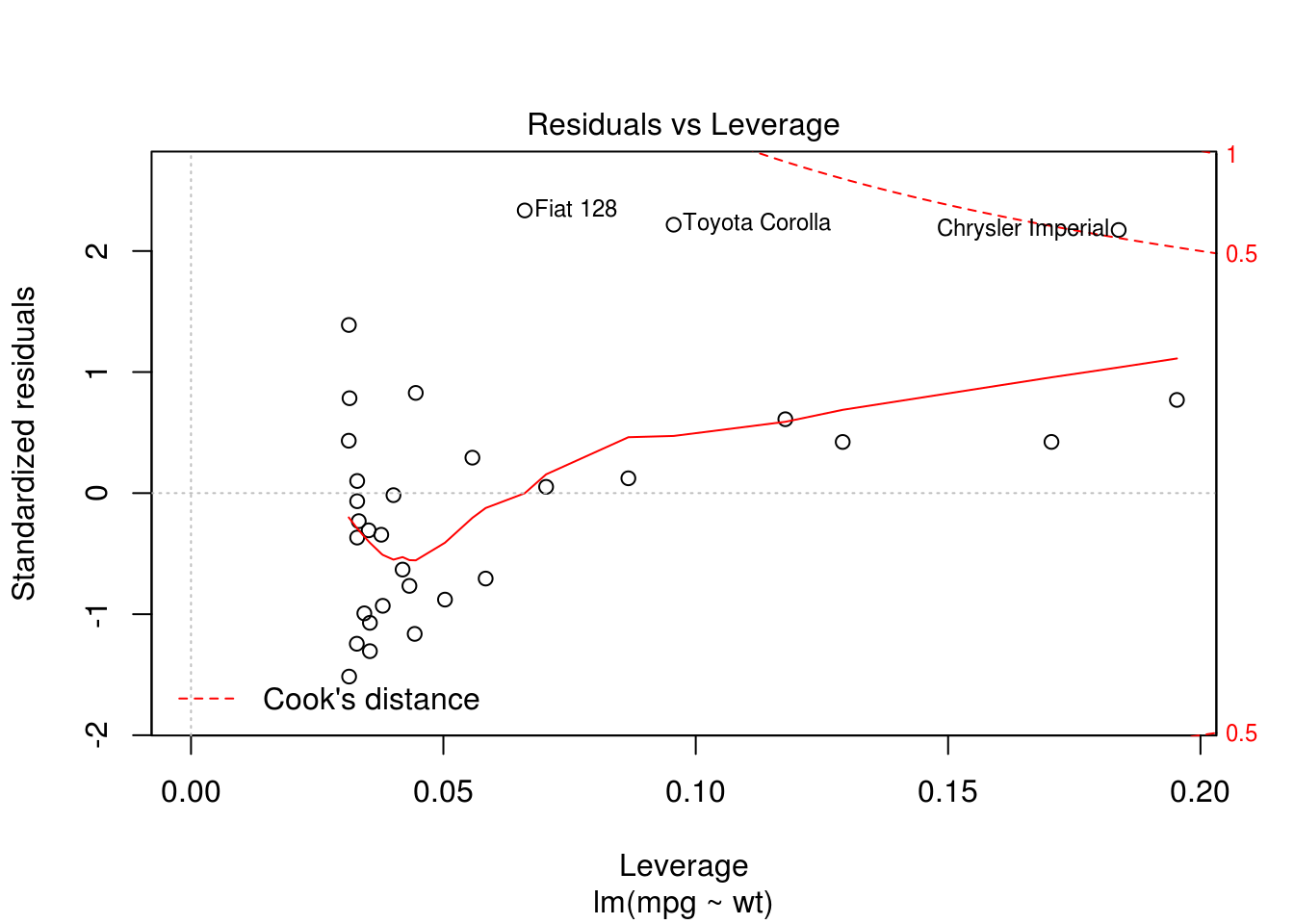
plot(mpg ~ wt, data = mtcars)
abline(m, col = "red")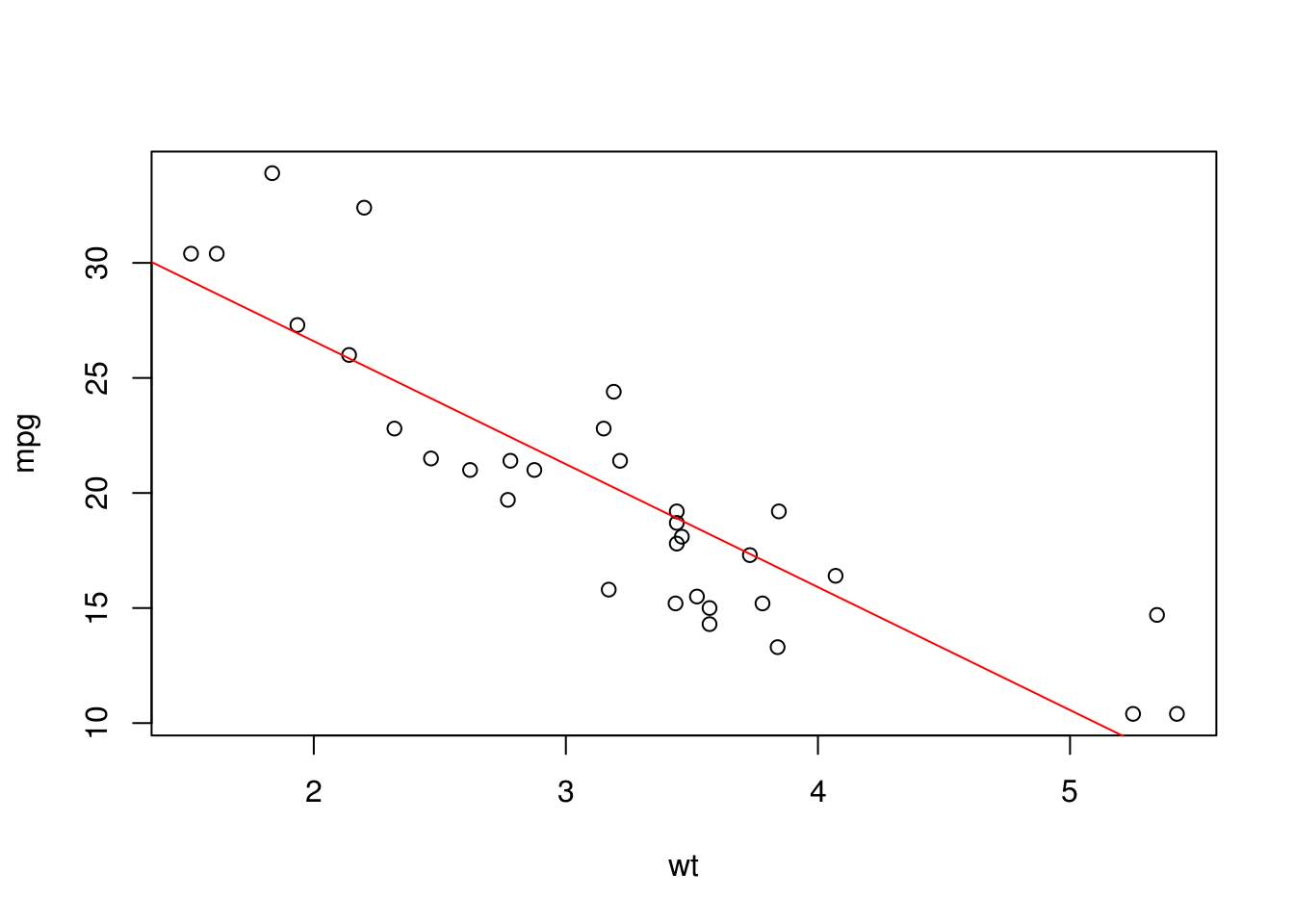
Quali - Quali
Ici, on calcule bien évidemment la table de contingence, mais aussi les fréquences totales et marginales (en lignes et en colonnes).
t <- table(mtcars$cyl, mtcars$am)
print(t)##
## 0 1
## 4 3 8
## 6 4 3
## 8 12 2prop.table(t)##
## 0 1
## 4 0.09375 0.25000
## 6 0.12500 0.09375
## 8 0.37500 0.06250prop.table(t, margin = 1)##
## 0 1
## 4 0.2727273 0.7272727
## 6 0.5714286 0.4285714
## 8 0.8571429 0.1428571prop.table(t, margin = 2)##
## 0 1
## 4 0.1578947 0.6153846
## 6 0.2105263 0.2307692
## 8 0.6315789 0.1538462mosaicplot(t) 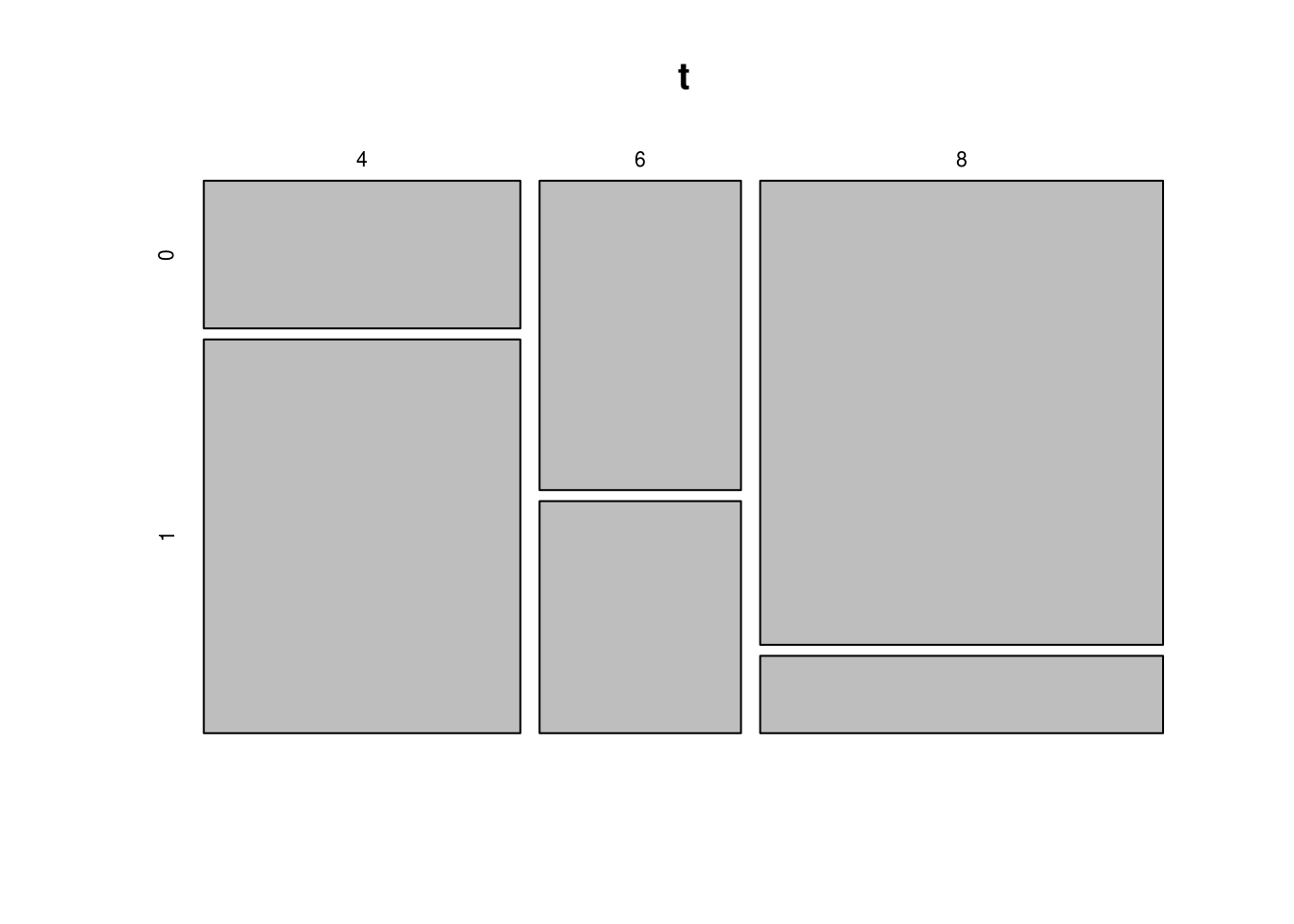
assocplot(t)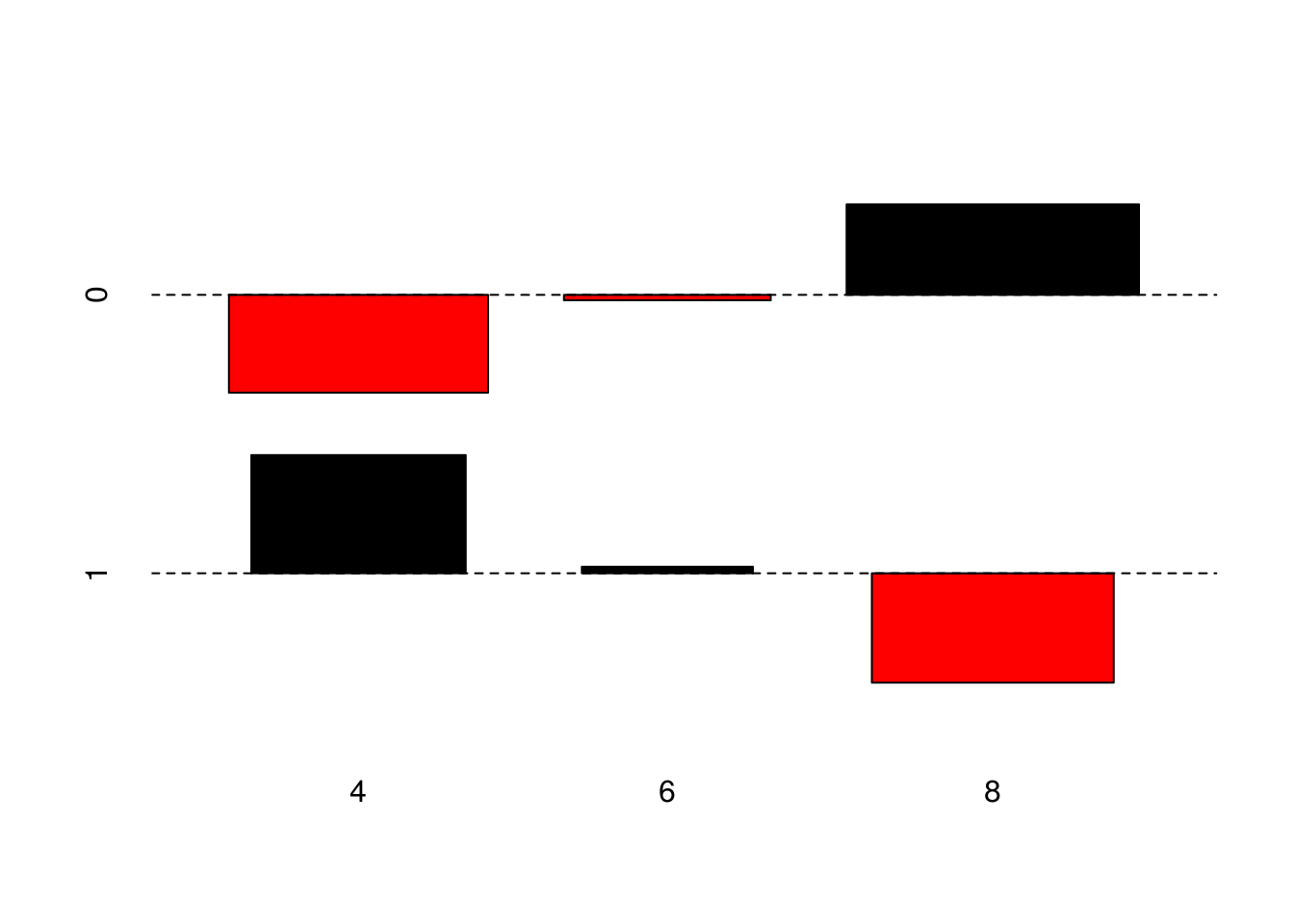
barplot(t)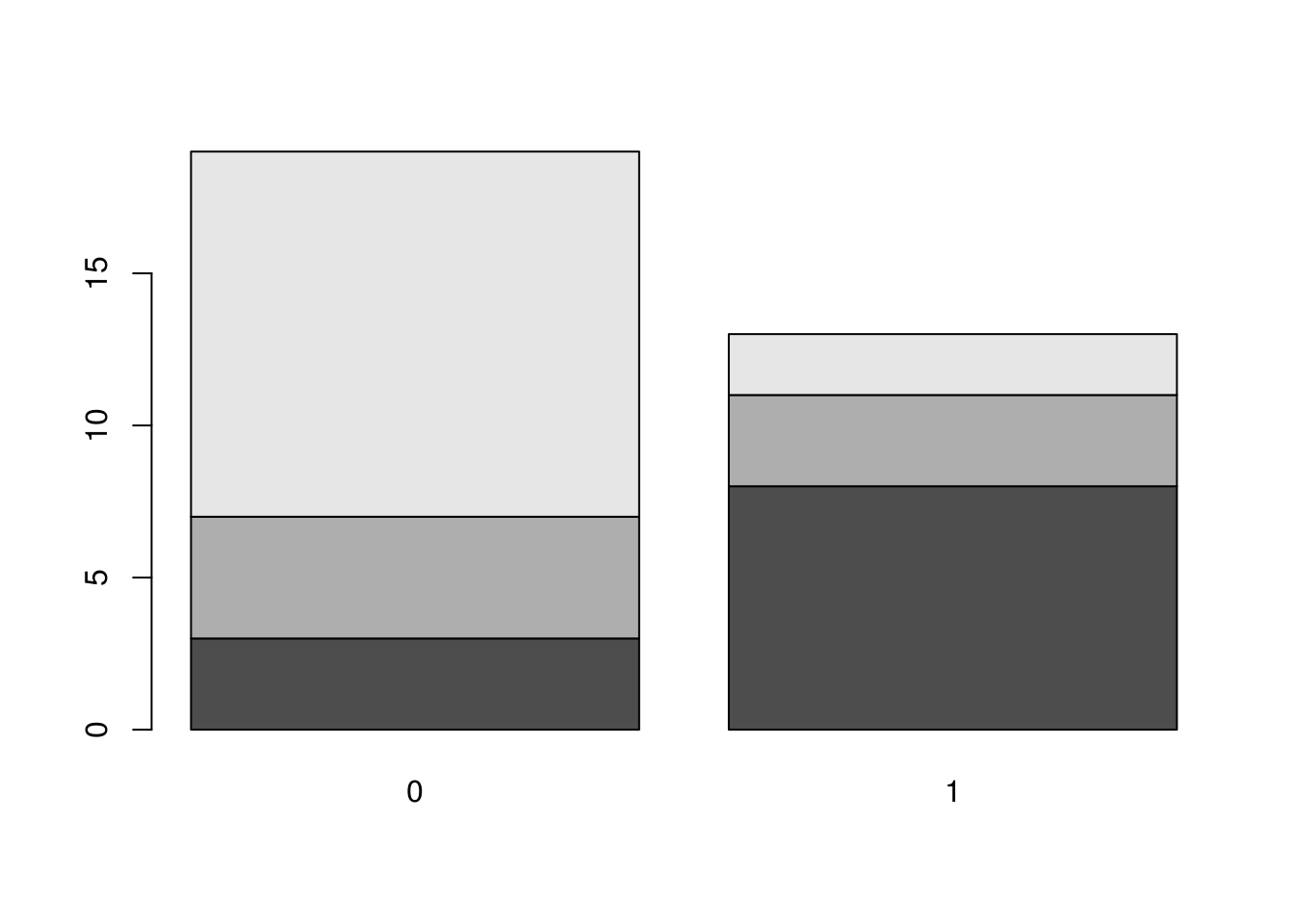
barplot(prop.table(t, margin = 2))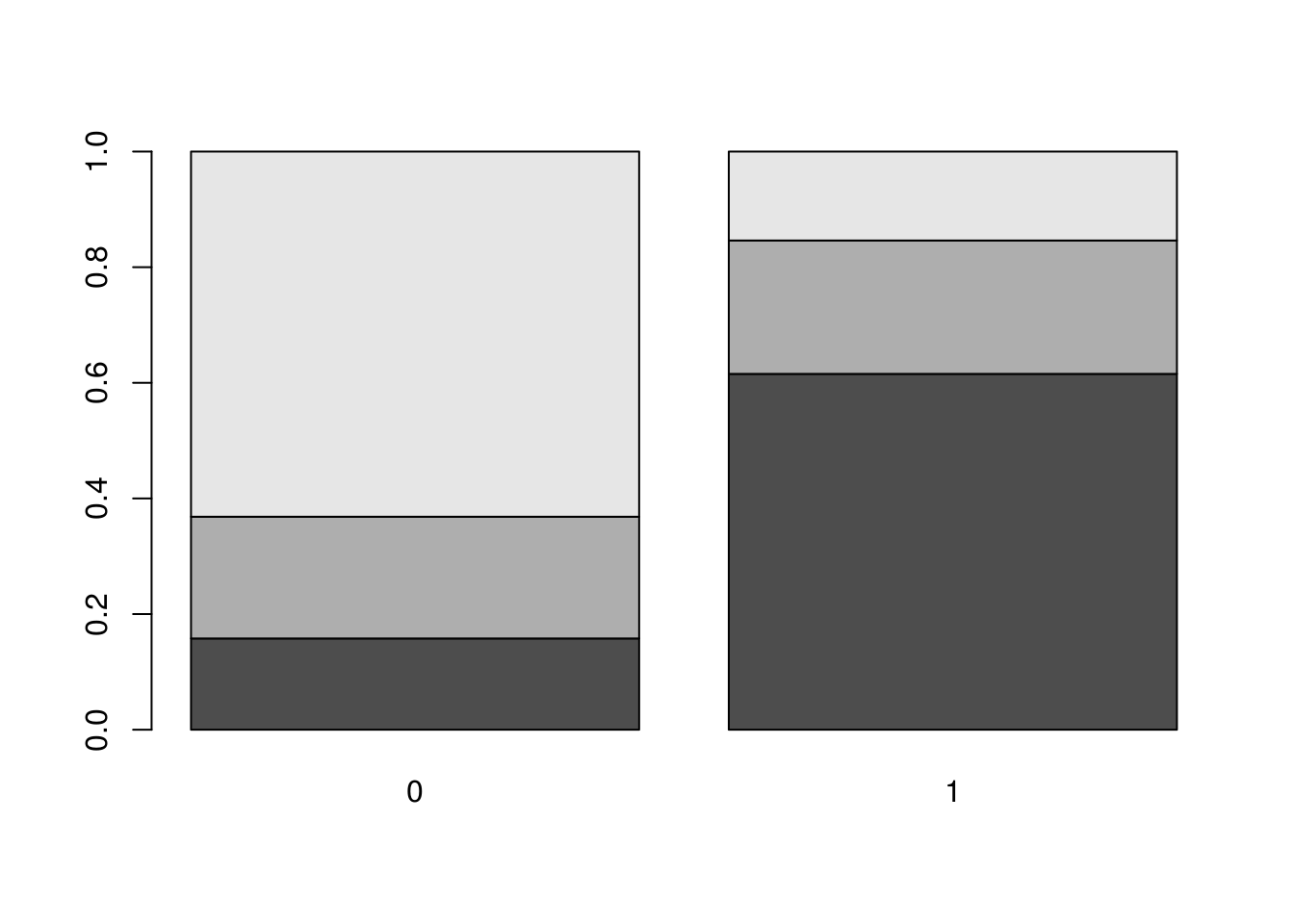
barplot(t, beside = T)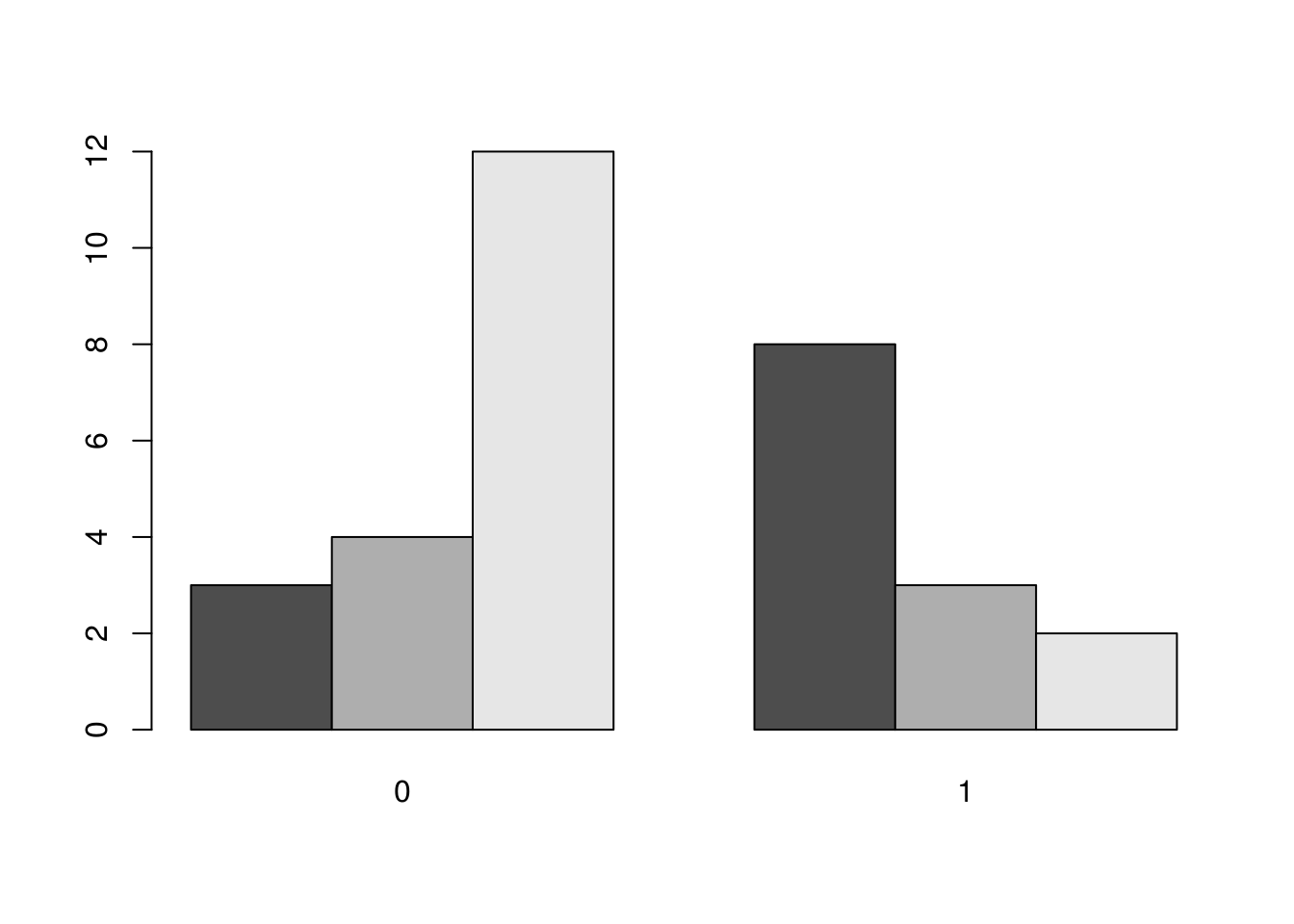
barplot(prop.table(t, margin = 2), beside = T)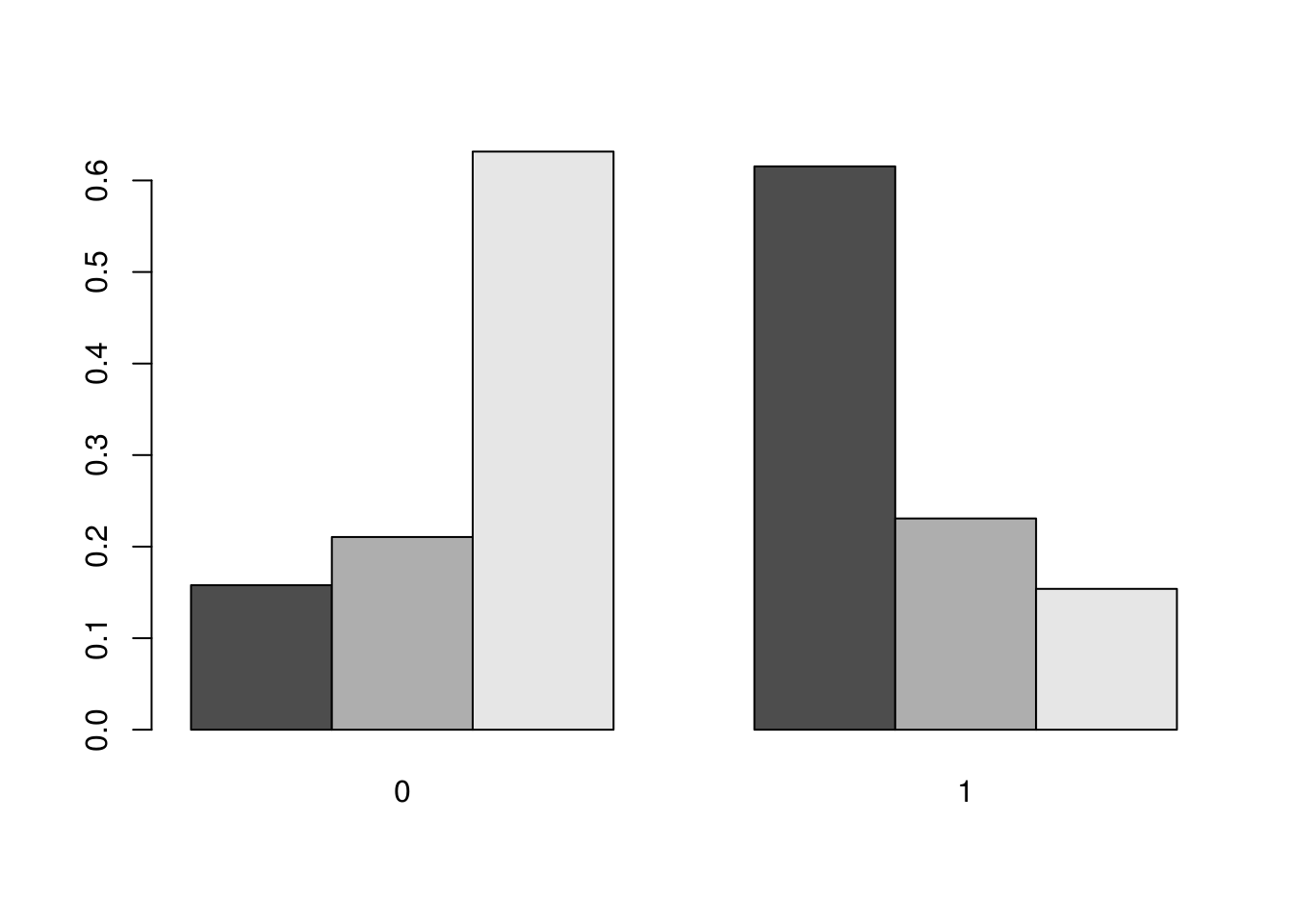
Quali - Quanti
En plus d’obtenir les statistiques par modalité de la variable qualitative, on peut représenter les boîtes à moustaches.
tapply(mtcars$mpg, mtcars$cyl, mean)## 4 6 8
## 26.66364 19.74286 15.10000tapply(mtcars$mpg, mtcars$cyl, summary)## $`4`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 21.40 22.80 26.00 26.66 30.40 33.90
##
## $`6`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 17.80 18.65 19.70 19.74 21.00 21.40
##
## $`8`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.40 14.40 15.20 15.10 16.25 19.20boxplot(mpg ~ cyl, data = mtcars)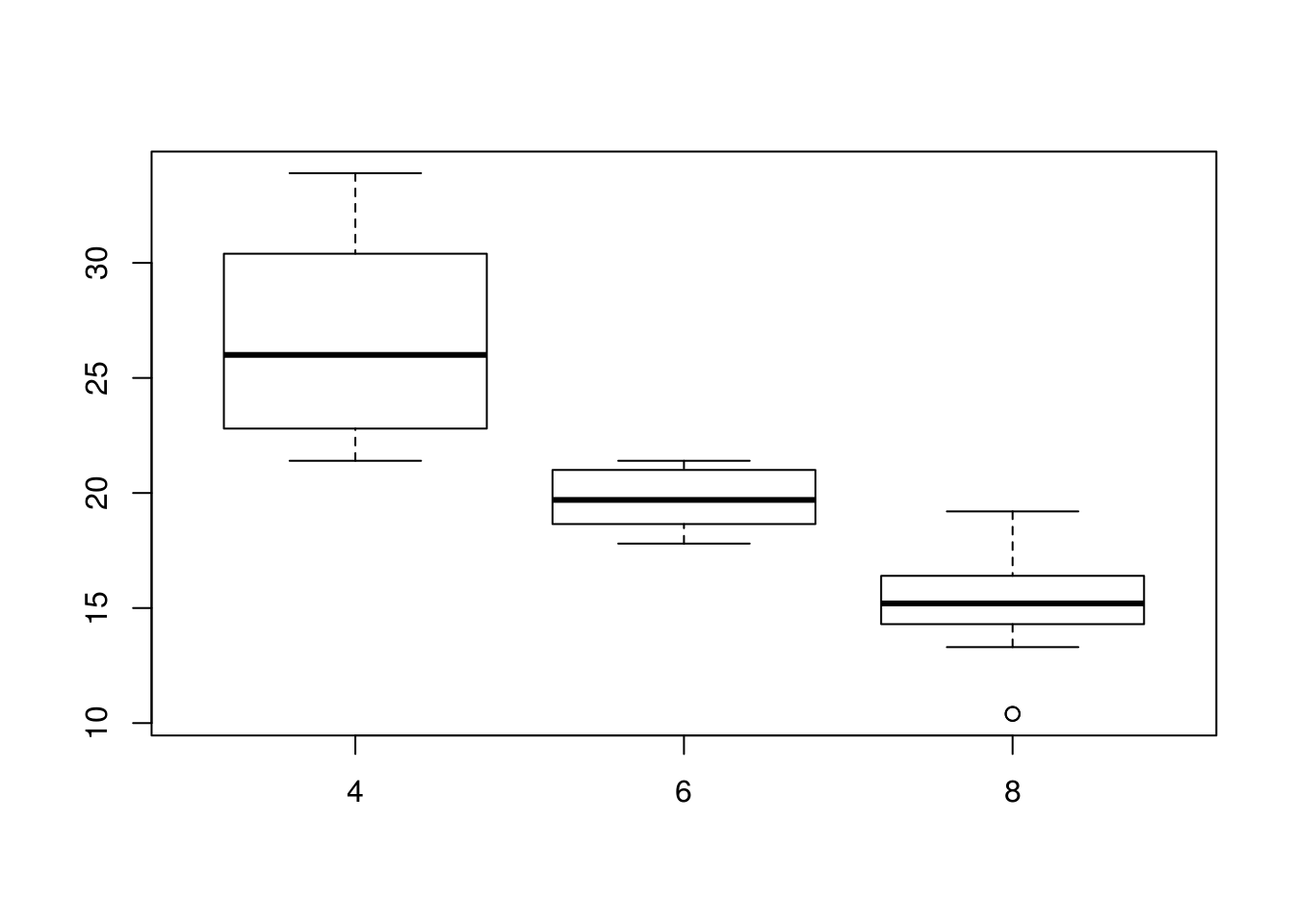
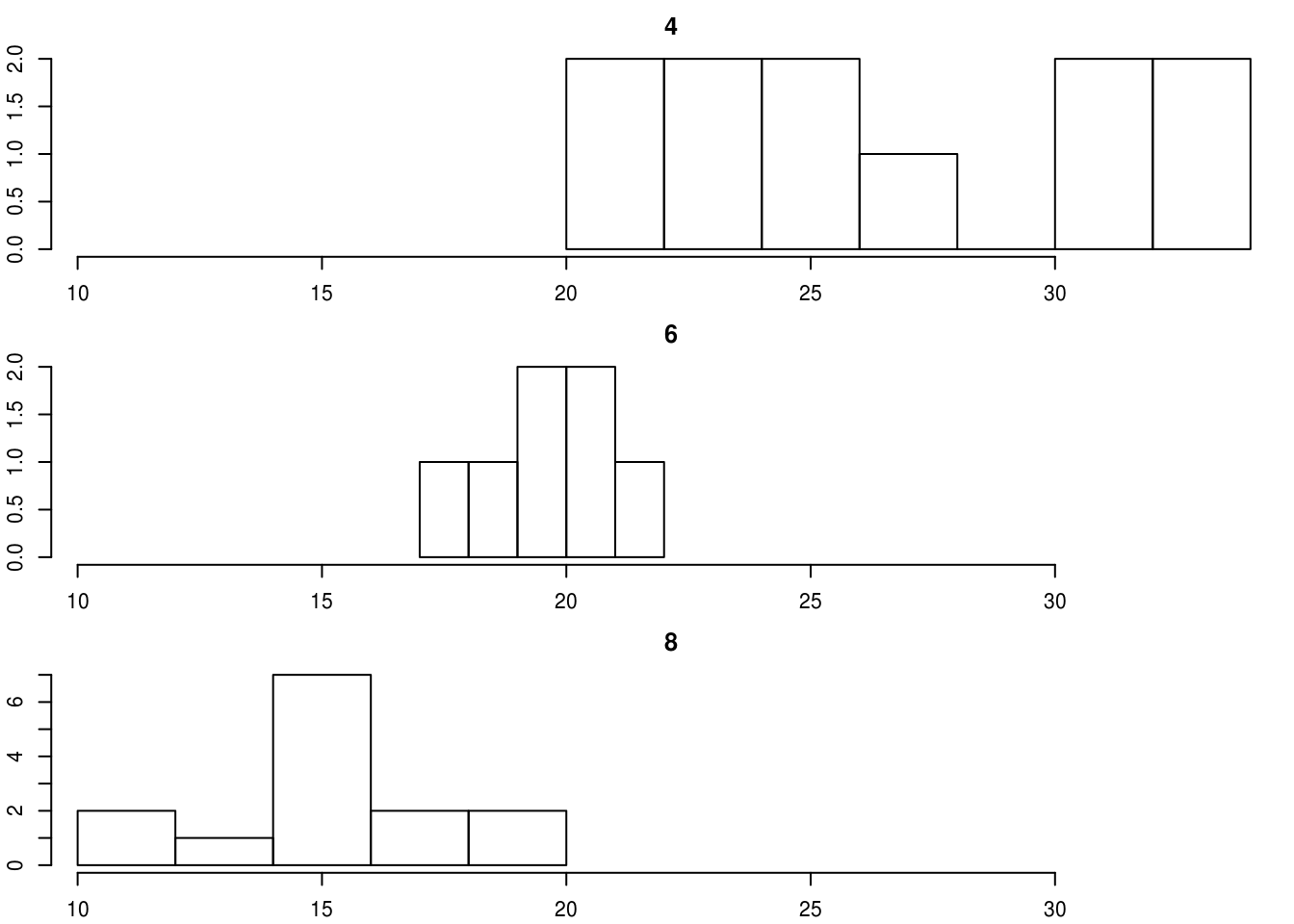
par(mfrow = c(3, 1), mar = c(2, 2, 2, 0) + 0.1)
for (c in c(4, 6, 8)) {
hist(mtcars$mpg[mtcars$cyl == c], xlim = range(mtcars$mpg), main = c)
}
Manipulation de listes
Il existe un type list en R, permettant de représenter un ensemble d’objets complexes, éventuellement avec des schémas différents et pouvant contenir eux-mêmes toutes sortes d’objets (vector, matrix, data.frame, list, …).
l = list(a = "chaîne",
b = 12,
c = 1:10,
d = head(mtcars),
e = list(x = 1:10, y = log(1:10)))
length(l)## [1] 5names(l)## [1] "a" "b" "c" "d" "e"l[1]## $a
## [1] "chaîne"l[[1]]## [1] "chaîne"l$a## [1] "chaîne"l[1:2]## $a
## [1] "chaîne"
##
## $b
## [1] 12l[c("a", "c")]## $a
## [1] "chaîne"
##
## $c
## [1] 1 2 3 4 5 6 7 8 9 10l[sapply(l, length) == 1]## $a
## [1] "chaîne"
##
## $b
## [1] 12lapply et autres
La fonction lapply() permet d’exécuter une fonction (passée en deuxième paramètre) à chaque élément d’une liste (passée en premier paramètre), ou un vecteur. Il existe aussi les fonctions sapply() et vapply(), qui sont similaires mais qui cherchent à simplifier le résultat (la deuxième permet de spécifier le nom des retours de la fonctions, si ceux-ci sont multiples).
lapply(l, class)## $a
## [1] "character"
##
## $b
## [1] "numeric"
##
## $c
## [1] "integer"
##
## $d
## [1] "data.frame"
##
## $e
## [1] "list"sapply(l, class)## a b c d e
## "character" "numeric" "integer" "data.frame" "list"Fonction particulière
On a parfois (voire souvent) besoin d’utiliser une fonction spécifique dans les fonctions comme lapply(). On peut soit la définir avant et l’utiliser comme une autre.
infoElement <- function(e) {
return(c(classe = class(e), longueur = length(e)))
}
lapply(l, infoElement)## $a
## classe longueur
## "character" "1"
##
## $b
## classe longueur
## "numeric" "1"
##
## $c
## classe longueur
## "integer" "10"
##
## $d
## classe longueur
## "data.frame" "11"
##
## $e
## classe longueur
## "list" "2"sapply(l, infoElement)## a b c d e
## classe "character" "numeric" "integer" "data.frame" "list"
## longueur "1" "1" "10" "11" "2"vapply(l, infoElement, c(CLASSE = "", LONG = ""))## a b c d e
## CLASSE "character" "numeric" "integer" "data.frame" "list"
## LONG "1" "1" "10" "11" "2"Fonction anonyme
Mais puisqu’on ne l’utilise généralement que dans cette fonction, il est possible de la déclarer directement dans la fonction lapply(). On parle alors de fonction anonyme (comme en JavaScript par exemple).
sapply(l, function(e) {
return(c(classe = class(e), longueur = length(e)))
})## a b c d e
## classe "character" "numeric" "integer" "data.frame" "list"
## longueur "1" "1" "10" "11" "2"Fonctionnement invisible
On a parfois besoin d’appliquer une fonction qui ne retourne rien à une liste, par exemple pour afficher l’élément ou une partie de celui-ci. Dans l’exemple ci-dessous, on remarque que le code affiche bien chaque élément, mais renvoie aussi une liste contenant les éléments (qui est donc identique à la liste passée en paramètre). Ce comportement est dû au fait que la fonction ne renvoie pas de résultat.
lapply(l, function (e) { print(e); })## [1] "chaîne"
## [1] 12
## [1] 1 2 3 4 5 6 7 8 9 10
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
## $x
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $y
## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851## $a
## [1] "chaîne"
##
## $b
## [1] 12
##
## $c
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $d
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
##
## $e
## $e$x
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $e$y
## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851Dans ce type de cas, si on veut éviter ce comportement, on peut utiliser la fonction invisibile(). Ceci va rendre invisible l’exécution du code et on ne verra donc pas la liste retournée par lapply().
invisible(lapply(l, function (e) { print(e); }))## [1] "chaîne"
## [1] 12
## [1] 1 2 3 4 5 6 7 8 9 10
## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
## $x
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $y
## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851Fonctions autres
Recherche
Il est possible de faire une recherche dans une liste (ou un vecteur) avec les fonctions Find() et Position(). Celles-ci renvoient le premier élément trouvé (ou le dernier car il est possible de partir de la droite). La fonction passée en premier paramètre doit renvoyer les valeurs TRUE ou FALSE.
On cherche par exemple ici le premier (ou dernier) élément de type vector dans la liste précédemment créée.
Find(is.vector, l)## [1] "chaîne"Find(is.vector, l, right = TRUE)## $x
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $y
## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851Position(is.vector, l)## [1] 1Position(is.vector, l, right = TRUE)## [1] 5Filtre
Pour récupérer tous les éléments d’une liste respectant une condition (grâce à la fonction passée en paramètre donc), on dispose de la fonction Filter(). Nous récupérons ici tous les éléments de la liste qui sont de type vector.
Filter(is.vector, l)## $a
## [1] "chaîne"
##
## $b
## [1] 12
##
## $c
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $e
## $e$x
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $e$y
## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851Réduction
On peut opérer une opération de réduction d’une liste à l’aide d’une fonction binaire (à deux paramètres donc).
Reduce(function(a, b) return(a + b), 1:5, 0)## [1] 15Pour fonctionner correctement, la fonction doit retourner un objet utilisable dans la fonction. Dans l’exemple ci-dessous, nous transformons mtcars en une liste de 32 éléments, chacune étant une liste nommée des caractéristiques de la voiture (avec en plus le nom de celle-ci).
mt = lapply(1:nrow(mtcars), function(i) {
return(c(nom = rownames(mtcars)[i], as.list(mtcars[i,])))
})
unlist(mt[[1]]) # unlist() utilisé pour améliorer l'affichage ## nom mpg cyl disp hp drat
## "Mazda RX4" "21" "6" "160" "110" "3.9"
## wt qsec vs am gear carb
## "2.62" "16.46" "0" "1" "4" "4"Imaginons qu’on souhaite faire la somme des consommations, il nous faut créer une liste initiale avec la valeur 0 pour l’élément mpg. Ensuite, on additionne les deux valeurs qu’on stocke dans a (qui aura pour première valeur init) et on retourne celle-ci.
init = list(mpg = 0)
Reduce(function(a, b) { a$mpg = a$mpg + b$mpg; return(a)}, mt, init)## $mpg
## [1] 642.9A faire
A partir des données présentes dans le fichier world-liste.RData, répondre aux questions suivantes. Ces données concernent les pays dans le monde (à la fin du siècle dernier), et sont représentées sous forme de liste dans l’objet Country.liste.
- Donner le nombre de pays représentés
- Trouver les informations concernant la
France - Lister les pays du continent
Antarctica - Calculer la population mondiale
- Afficher quelques informations pour chaque pays (un pays par ligne) :
- si l’année d’indépendance (
IndepYear) estNA, alors on affichera
pays (continent)- sinon, on affichera :
pays (continent - indépendance en XXXX) - si l’année d’indépendance (
- Créer une nouvelle liste avec le de ratio de la population des villes du pays (voir
City) sur la population du pays (Population) Identifier (donner leur nom) les pays ayant un ratio supérieur à
1avec la nouvelle liste créée