
oMLX
Mac向けに最適化されたLLM推論サーバー
連続バッチングと階層型KVキャッシュを、メニューバーから直接管理します。




junkim.dot@gmail.com · https://omlx.ai/me
インストール ·
クイックスタート ·
機能 ·
モデル ·
CLI 設定 ·
ベンチマーク ·
oMLX.ai
English ·
中文 ·
한국어 ·
日本語
---
> *これまで試したLLMサーバーは、利便性とコントロールのどちらかを選ばせるものでした。よく使うモデルをメモリにピン留めし、重いモデルは必要に応じて自動スワップし、コンテキスト制限を設定して、すべてをメニューバーから管理したかったのです。*
>
> *oMLXはKVキャッシュをホットなメモリ層とコールドなSSD層の2階層で永続化します。会話中にコンテキストが変わっても、すべての過去のコンテキストはキャッシュされ、リクエスト間で再利用可能です。これによりClaude Codeのようなツールでの実際のコーディング作業において、ローカルLLMが実用的になります。だから作りました。*
## インストール
### macOSアプリ
[Releases](https://github.com/jundot/omlx/releases)から`.dmg`をダウンロードし、Applicationsにドラッグするだけです。アプリ内自動アップデートに対応しているので、以降のアップグレードはワンクリックで完了します。macOSアプリには`omlx` CLIコマンドは含まれていません。ターミナルで使用するにはHomebrewまたはソースからインストールしてください。
### Homebrew
```bash
brew tap jundot/omlx https://github.com/jundot/omlx
brew install omlx
# 最新バージョンへアップグレード
brew update && brew upgrade omlx
# バックグラウンドサービスとして実行(クラッシュ時に自動再起動)
brew services start omlx
# オプション: MCP(Model Context Protocol)サポート
/opt/homebrew/opt/omlx/libexec/bin/pip install mcp
```
### ソースからインストール
```bash
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e . # コアのみ
pip install -e ".[mcp]" # MCP(Model Context Protocol)サポート付き
```
Python 3.10+とApple Silicon(M1/M2/M3/M4)が必要です。
## クイックスタート
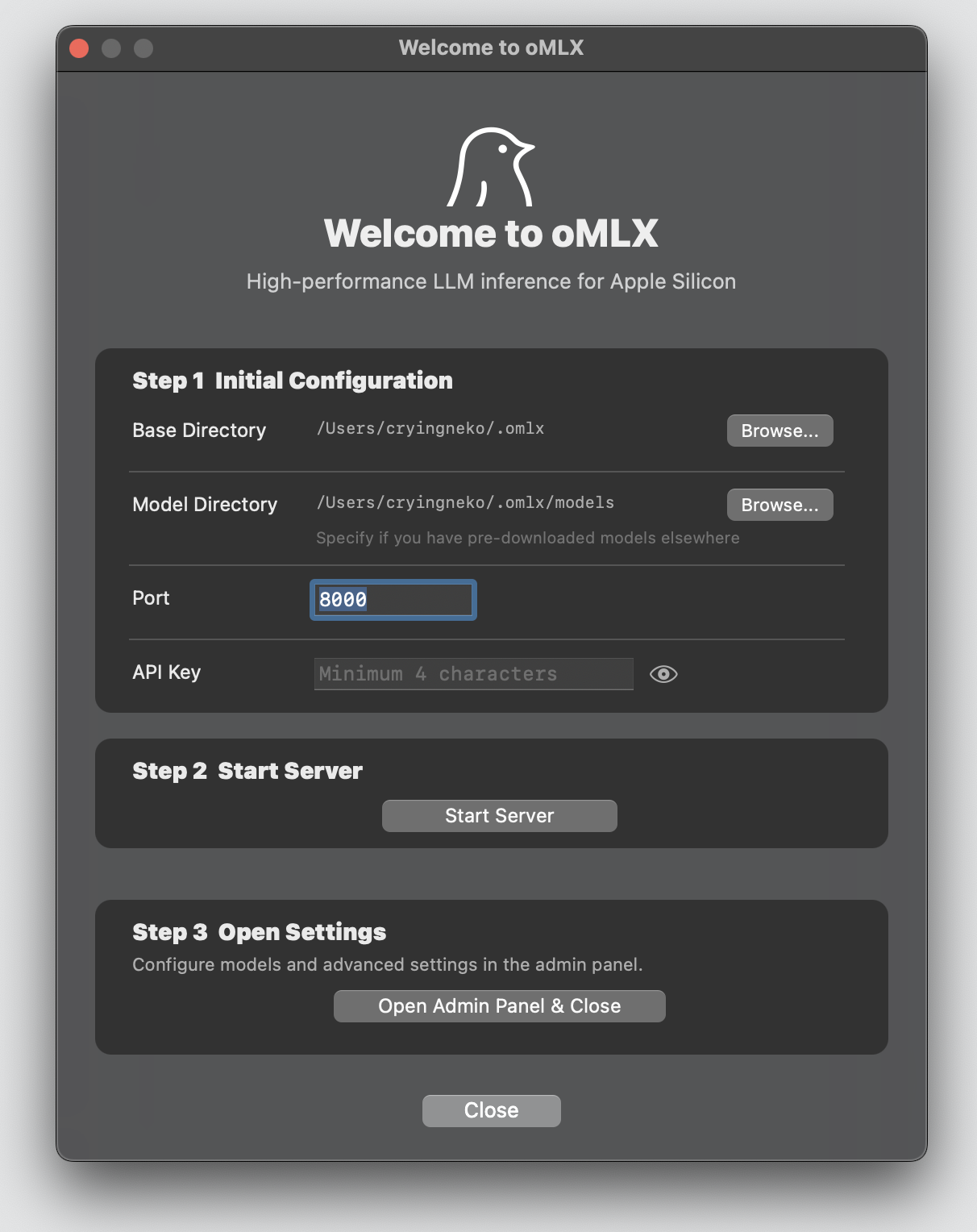
### macOSアプリ
ApplicationsフォルダからoMLXを起動します。ウェルカム画面が3つのステップを案内します — モデルディレクトリの設定、サーバー起動、最初のモデルダウンロード。以上です。OpenClaw、OpenCode、Codex、Copilotに接続するには、[統合](#統合)を参照してください。
### CLI
```bash
omlx serve --model-dir ~/models
```
サーバーがサブディレクトリからLLM、VLM、エンベディングモデル、リランカーを自動的に検出します。OpenAI互換クライアントから`http://localhost:8000/v1`に接続できます。内蔵チャットUIも`http://localhost:8000/admin/chat`で利用可能です。
### Homebrewサービス
Homebrewでインストールした場合、oMLXをマネージドバックグラウンドサービスとして実行できます:
```bash
brew services start omlx # 起動(クラッシュ時に自動再起動)
brew services stop omlx # 停止
brew services restart omlx # 再起動
brew services info omlx # ステータス確認
```
サービスはデフォルト設定で`omlx serve`を実行します(`~/.omlx/models`、ポート8000)。カスタマイズするには、環境変数(`OMLX_MODEL_DIR`、`OMLX_PORT`など)を設定するか、`omlx serve --model-dir /your/path`を一度実行して`~/.omlx/settings.json`に設定を保存してください。
ログは2か所に記録されます:
- **サービスログ**: `$(brew --prefix)/var/log/omlx.log`(stdout/stderr)
- **サーバーログ**: `~/.omlx/logs/server.log`(構造化アプリケーションログ)
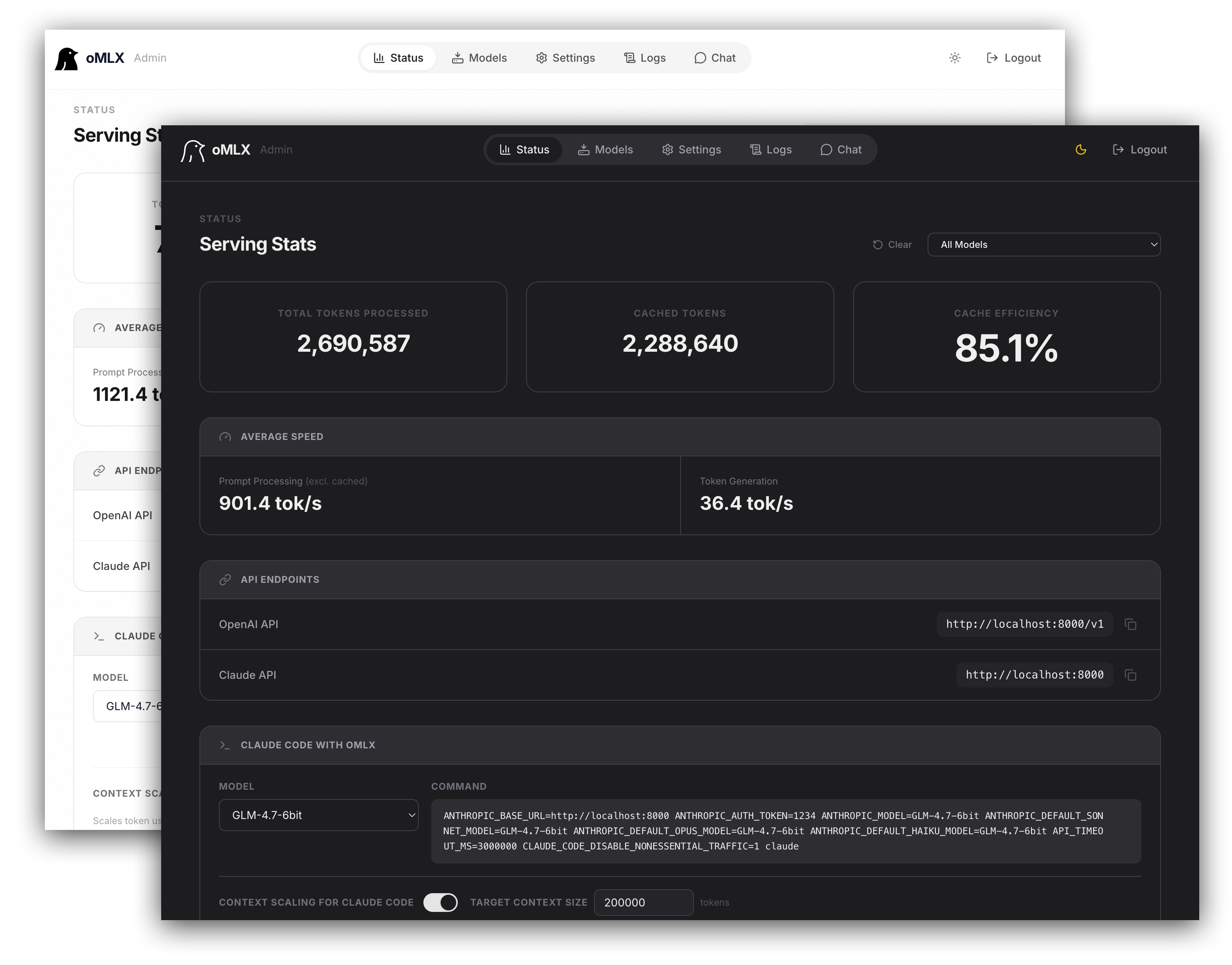
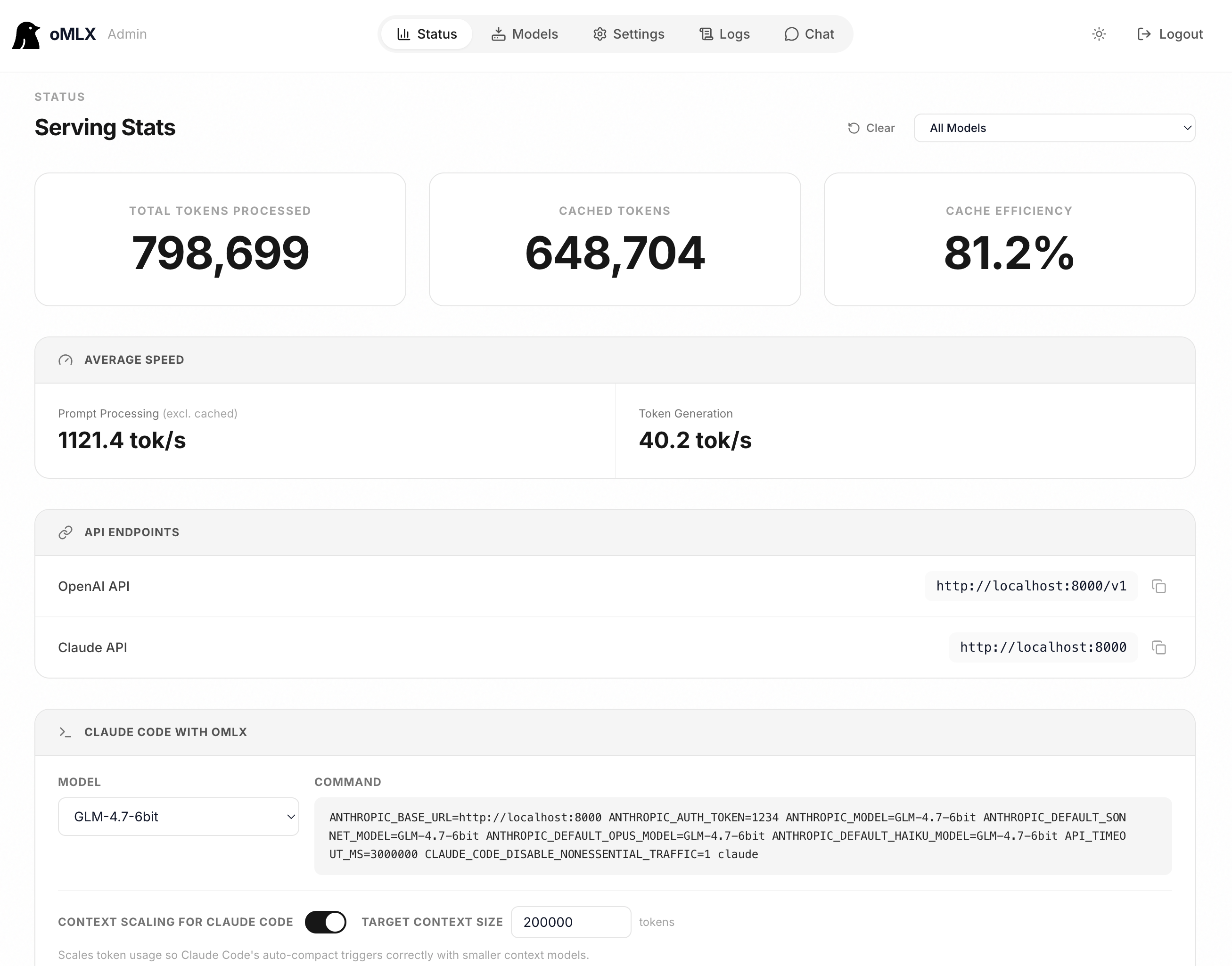
## 機能
Apple SiliconでテキストLLM、ビジョン言語モデル(VLM)、OCRモデル、エンベディング、リランカーをサポートします。
### 管理画面
`/admin`でリアルタイム監視、モデル管理、チャット、ベンチマーク、モデル別設定のためのWeb UIを提供します。英語、韓国語、日本語、中国語、ロシア語に対応。すべてのCDN依存関係がバンドルされ、完全オフラインでの運用が可能です。
### ビジョン言語モデル
テキストLLMと同じ連続バッチング・階層型KVキャッシュスタックでVLMを実行します。マルチ画像チャット、base64/URL/ファイル画像入力、ビジョンコンテキストを活用したツール呼び出しをサポートします。OCRモデル(DeepSeek-OCR、DOTS-OCR、GLM-OCR)は最適化されたプロンプトで自動検出されます。
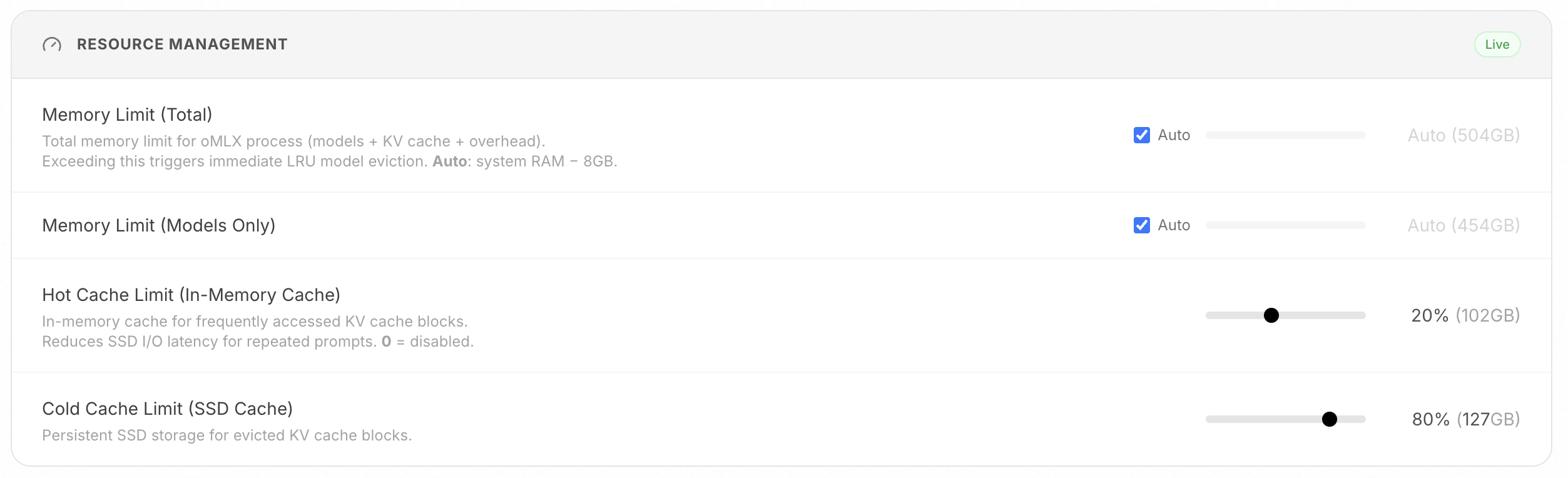
### 階層型KVキャッシュ(ホット+コールド)
vLLMにインスパイアされたブロックベースのKVキャッシュ管理で、プレフィックス共有とCopy-on-Writeをサポートします。キャッシュは2つの階層で動作します:
- **ホットキャッシュ(RAM)**: 頻繁にアクセスされるブロックをメモリに保持し、高速アクセスを実現します。
- **コールドキャッシュ(SSD)**: ホットキャッシュが満杯になると、ブロックがsafetensors形式でSSDにオフロードされます。次のリクエストで一致するプレフィックスがあれば、最初から再計算する代わりにディスクから復元されます — サーバー再起動後も維持されます。
### 連続バッチング
mlx-lmのBatchGeneratorを通じて同時リクエストを処理します。最大同時リクエスト数はCLIまたは管理パネルで設定できます。
### Claude Code最適化
Claude Codeで小さなコンテキストモデルを実行するためのコンテキストスケーリングをサポートします。報告されるトークン数をスケーリングすることで自動圧縮が適切なタイミングでトリガーされ、長いプリフィル中の読み取りタイムアウトを防ぐSSE keep-aliveを提供します。
### マルチモデルサービング
同一サーバーでLLM、VLM、エンベディングモデル、リランカーをロードします。自動と手動の制御を組み合わせてモデルを管理します:
- **LRU退去**: メモリが不足すると、最も使用されていないモデルが自動的にアンロードされます。
- **手動ロード/アンロード**: 管理画面のステータスバッジからモデルをオンデマンドでロード・アンロードできます。
- **モデルのピン留め**: よく使うモデルをピン留めして常にロード状態を維持します。
- **モデル別TTL**: モデルごとにアイドルタイムアウトを設定し、一定時間の非活動後に自動アンロードします。
- **プロセスメモリ制限**: 合計メモリ制限(デフォルト:システムRAM - 8GB)でシステム全体のOOMを防止します。
### モデル別設定
管理画面からサンプリングパラメータ、チャットテンプレート引数、TTL、モデルエイリアス、モデルタイプオーバーライドなどをモデルごとに設定します。サーバー再起動なしで即座に適用されます。
- **モデルエイリアス**: カスタムAPI表示名を設定します。`/v1/models`でエイリアスが返され、リクエスト時にエイリアスとディレクトリ名の両方が使用可能です。
- **モデルタイプオーバーライド**: 自動検出に関係なく、LLMまたはVLMとして手動設定します。
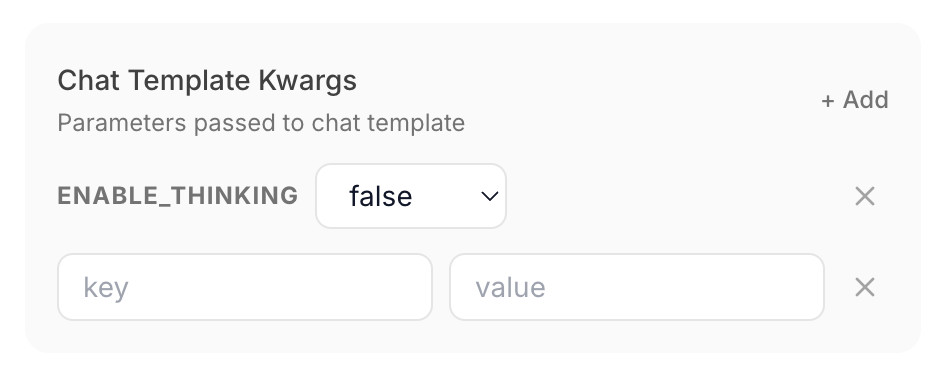
### 内蔵チャット
管理画面からロード済みモデルと直接チャットします。会話履歴、モデル切り替え、ダークモード、推論モデル出力、および VLM/OCR モデルの画像アップロード をサポートします。

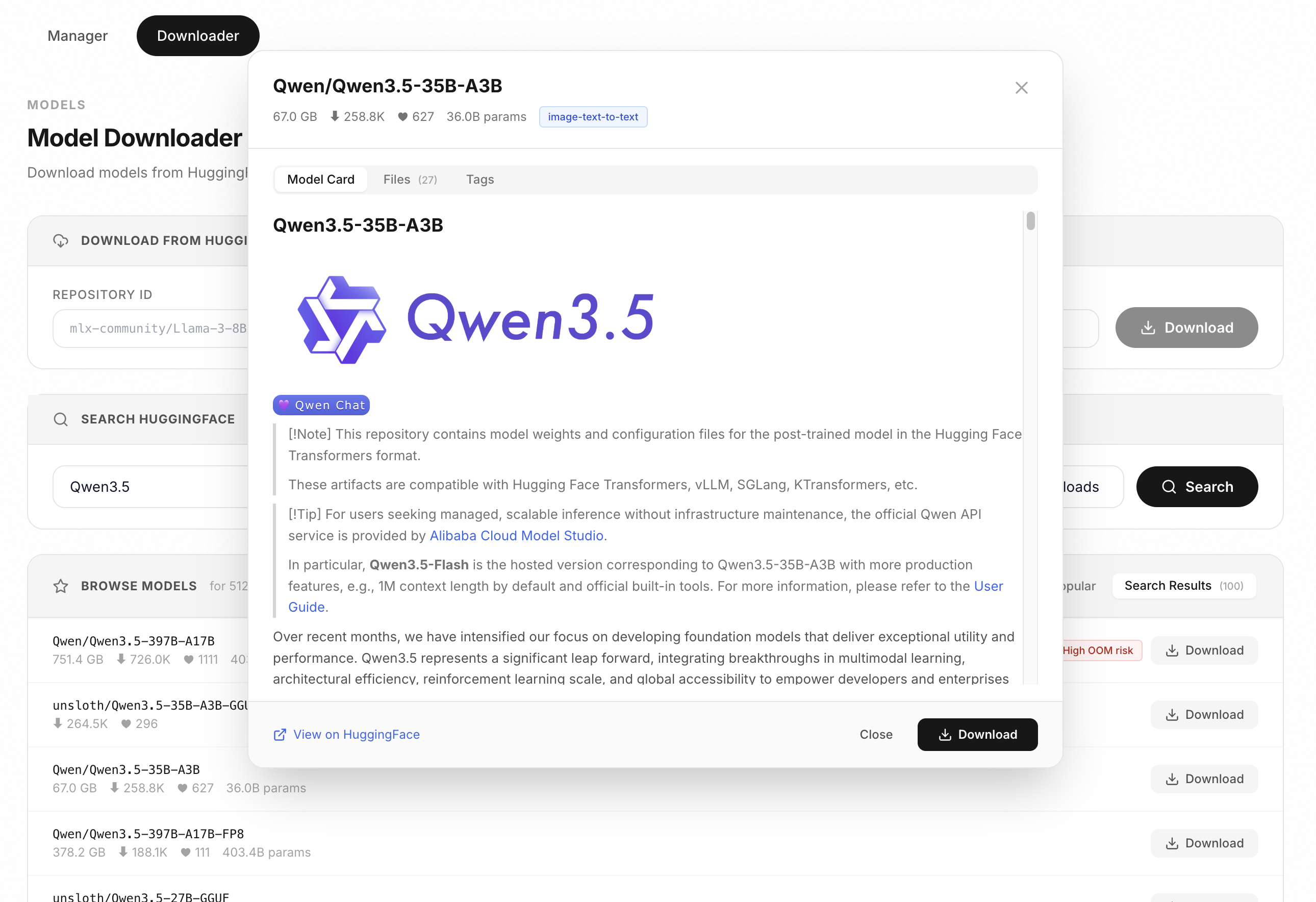
### モデルダウンロード
管理画面からHuggingFaceのMLXモデルを直接検索してダウンロードします。モデルカードの確認、ファイルサイズの確認、ワンクリックダウンロードが可能です。
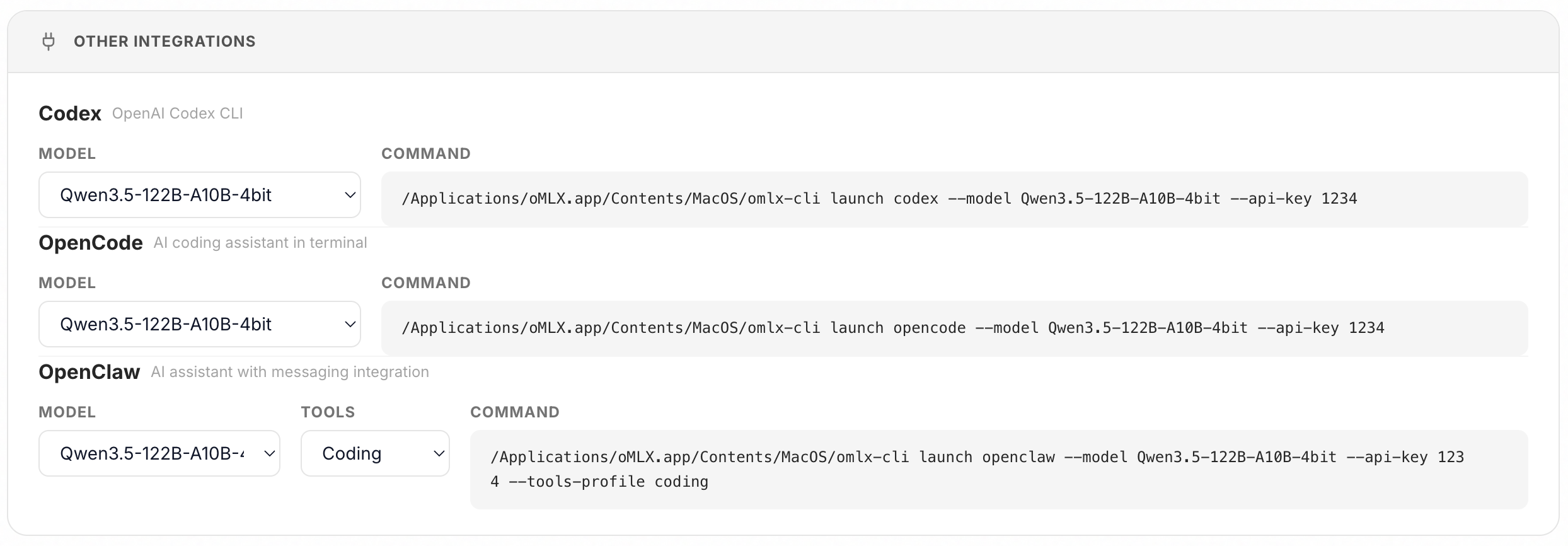
### 統合
管理画面からOpenClaw、OpenCode、Codex、Copilot、Piをワンクリックで設定できます。設定ファイルを手動で編集する必要はありません。
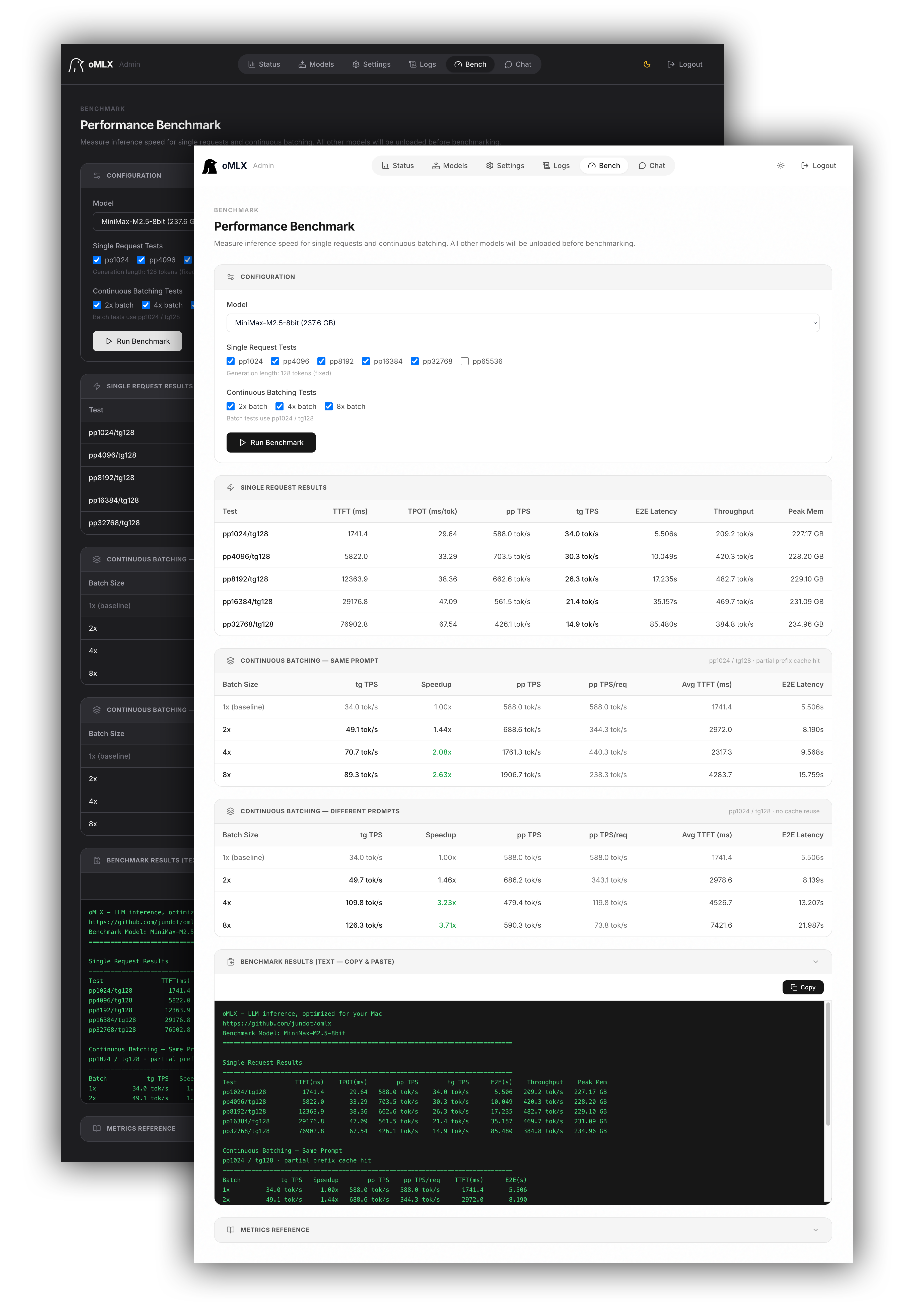
### パフォーマンスベンチマーク
管理画面からワンクリックでベンチマークを実行します。プリフィル(PP)とトークン生成(TG)の毎秒トークン数を測定し、現実的なパフォーマンス数値のための部分的プレフィックスキャッシュヒットテストも含まれます。
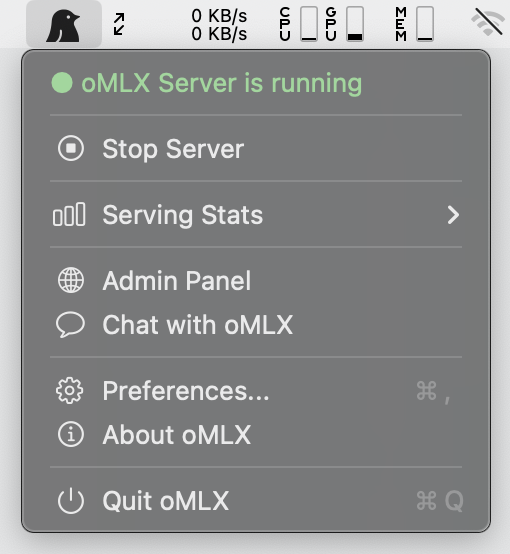
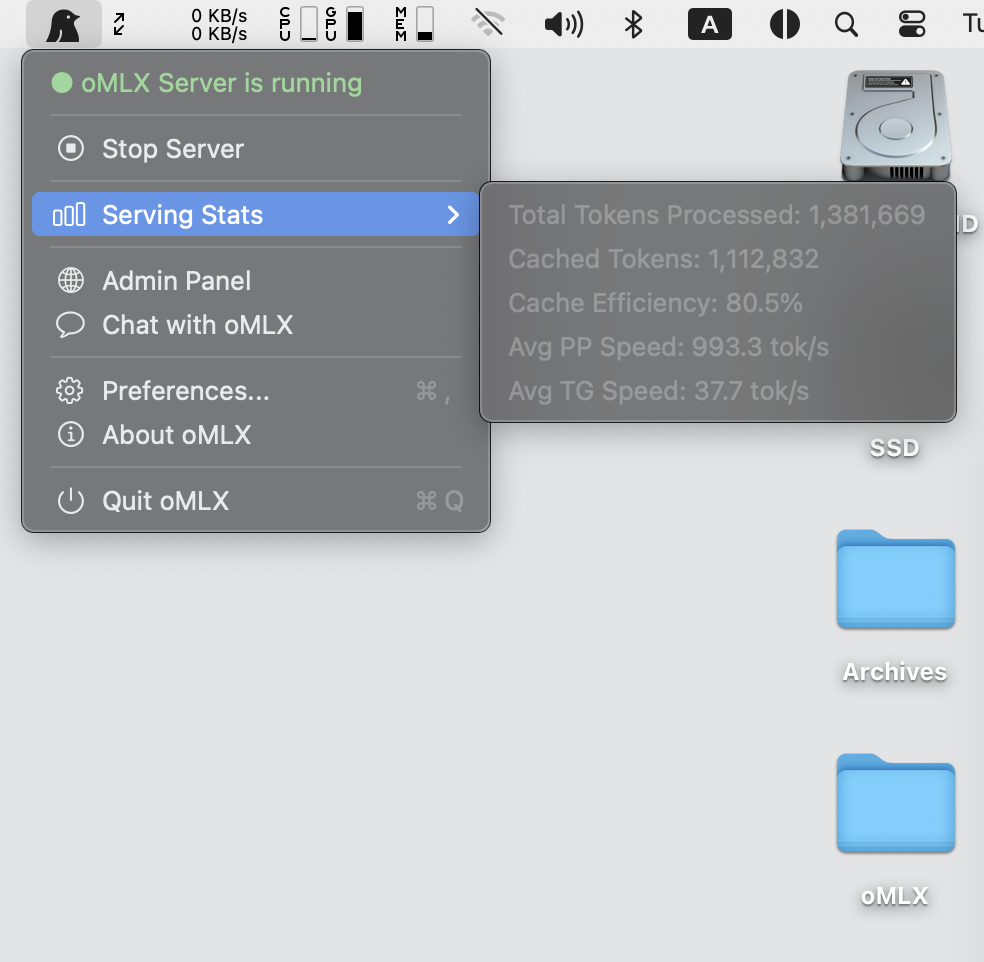
### macOSメニューバーアプリ
ネイティブPyObjCメニューバーアプリ(Electronではありません)。ターミナルを開かずにサーバーの起動、停止、監視が可能です。永続的な配信統計(再起動後も維持)、クラッシュ時の自動再起動、アプリ内自動アップデートを含みます。
### API互換性
OpenAIとAnthropic APIのドロップイン代替です。ストリーミング使用統計(`stream_options.include_usage`)、Anthropic adaptive thinking、ビジョン入力(base64、URL)をサポートします。
| エンドポイント | 説明 |
|----------|------|
| `POST /v1/chat/completions` | チャット補完(ストリーミング) |
| `POST /v1/completions` | テキスト補完(ストリーミング) |
| `POST /v1/messages` | Anthropic Messages API |
| `POST /v1/embeddings` | テキストエンベディング |
| `POST /v1/rerank` | ドキュメントリランキング |
| `GET /v1/models` | 利用可能なモデル一覧 |
### ツール呼び出し&構造化出力
mlx-lmで利用可能なすべての関数呼び出し形式、JSONスキーマバリデーション、MCPツール統合をサポートします。ツール呼び出しにはモデルのチャットテンプレートが`tools`パラメータをサポートしている必要があります。以下のモデルファミリーがmlx-lmの内蔵ツールパーサーを通じて自動検出されます:
| モデルファミリー | 形式 |
|---|---|
| Llama、Qwen、DeepSeek等 | JSON `` |
| Qwen3.5シリーズ | XML `` |
| Gemma | `` |
| GLM (4.7, 5) | `/` XML |
| MiniMax | Namespaced `` |
| Mistral | `[TOOL_CALLS]` |
| Kimi K2 | `<\|tool_calls_section_begin\|>` |
| Longcat | `` |
上記に記載されていないモデルでも、チャットテンプレートが`tools`を受け入れ、出力が認識可能な`` XML形式を使用していれば動作する可能性があります。ツール呼び出しを含むストリーミングリクエストはすべてのコンテンツをバッファリングし、完了時に結果を送信します。
## モデル
`--model-dir`をMLX形式のモデルサブディレクトリを含むディレクトリに指定します。2階層の構造フォルダ(例:`mlx-community/model-name/`)もサポートされています。
```
~/models/
├── Step-3.5-Flash-8bit/
├── Qwen3-Coder-Next-8bit/
├── gpt-oss-120b-MXFP4-Q8/
├── Qwen3.5-122B-A10B-4bit/
└── bge-m3/
```
モデルはタイプ別に自動検出されます。管理画面から直接モデルをダウンロードすることもできます。
| タイプ | モデル |
|------|------|
| LLM | [mlx-lm](https://github.com/ml-explore/mlx-lm)がサポートするすべてのモデル |
| VLM | Qwen3.5シリーズ、GLM-4V、Pixtralおよびその他の[mlx-vlm](https://github.com/Blaizzy/mlx-vlm)モデル |
| OCR | DeepSeek-OCR、DOTS-OCR、GLM-OCR |
| エンベディング | BERT、BGE-M3、ModernBERT |
| リランカー | ModernBERT、XLM-RoBERTa |
## CLI 設定
```bash
# ロード済みモデルのメモリ上限
omlx serve --model-dir ~/models --max-model-memory 32GB
# プロセスレベルのメモリ上限(デフォルト: auto = RAM - 8GB)
omlx serve --model-dir ~/models --max-process-memory 80%
# KVブロック用SSDキャッシュを有効化
omlx serve --model-dir ~/models --paged-ssd-cache-dir ~/.omlx/cache
# メモリ内ホットキャッシュサイズの設定
omlx serve --model-dir ~/models --hot-cache-max-size 20%
# 最大同時リクエスト数の調整(デフォルト: 8)
omlx serve --model-dir ~/models --max-concurrent-requests 16
# MCPツールの使用
omlx serve --model-dir ~/models --mcp-config mcp.json
# APIキー認証
omlx serve --model-dir ~/models --api-key your-secret-key
# Localhost専用: 管理画面のグローバル設定で検証をスキップ
```
すべての設定は`/admin`のWeb管理画面からも設定できます。設定は`~/.omlx/settings.json`に保存され、CLIフラグが優先されます。
アーキテクチャ
```
FastAPI Server (OpenAI / Anthropic API)
│
├── EnginePool (マルチモデル、LRU退去、TTL、手動ロード/アンロード)
│ ├── BatchedEngine (LLM、連続バッチング)
│ ├── VLMEngine (ビジョン言語モデル)
│ ├── EmbeddingEngine
│ └── RerankerEngine
│
├── ProcessMemoryEnforcer (合計メモリ制限、TTLチェック)
│
├── Scheduler (FCFS、設定可能な同時処理数)
│ └── mlx-lm BatchGenerator
│
└── Cache Stack
├── PagedCacheManager (GPU、ブロックベース、CoW、プレフィックス共有)
├── Hot Cache (メモリキャッシュ、write-back)
└── PagedSSDCacheManager (SSDコールドキャッシュ、safetensors形式)
```
## 開発
### CLIサーバー
```bash
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e ".[dev]"
pytest -m "not slow"
```
### macOSアプリ
Python 3.11+と[venvstacks](https://venvstacks.lmstudio.ai)(`pip install venvstacks`)が必要です。
```bash
cd packaging
# フルビルド(venvstacks + アプリバンドル + DMG)
python build.py
# venvstacksをスキップ(コード変更のみ)
python build.py --skip-venv
# DMGのみ
python build.py --dmg-only
```
アプリバンドルの構造とレイヤー設定の詳細は[packaging/README.md](packaging/README.md)を参照してください。
## コントリビューション
コントリビューションを歓迎します!詳細は[コントリビューションガイド](docs/CONTRIBUTING.md)を参照してください。
- バグ修正と改善
- パフォーマンス最適化
- ドキュメント改善
## ライセンス
[Apache 2.0](LICENSE)
## 謝辞
- [MLX](https://github.com/ml-explore/mlx)と[mlx-lm](https://github.com/ml-explore/mlx-lm) by Apple
- [mlx-vlm](https://github.com/Blaizzy/mlx-vlm) - Apple Siliconでのビジョン言語モデル推論
- [vllm-mlx](https://github.com/waybarrios/vllm-mlx) - oMLXはvllm-mlx v0.1.0からスタートし、マルチモデルサービング、階層型KVキャッシュ、完全なページドキャッシュ対応のVLM、管理画面、macOSメニューバーアプリへと大きく進化しました
- [venvstacks](https://venvstacks.lmstudio.ai) - macOSアプリバンドルのためのポータブルPython環境レイヤリング
- [mlx-embeddings](https://github.com/Blaizzy/mlx-embeddings) - Apple Silicon向けエンベディングモデルサポート
- [dflash-mlx](https://github.com/bstnxbt/dflash-mlx) - Apple Siliconでのブロック拡散 speculative decoding