> *Every LLM server I tried made me choose between convenience and control. I wanted to pin everyday models in memory, auto-swap heavier ones on demand, set context limits - and manage it all from a menu bar.*
>
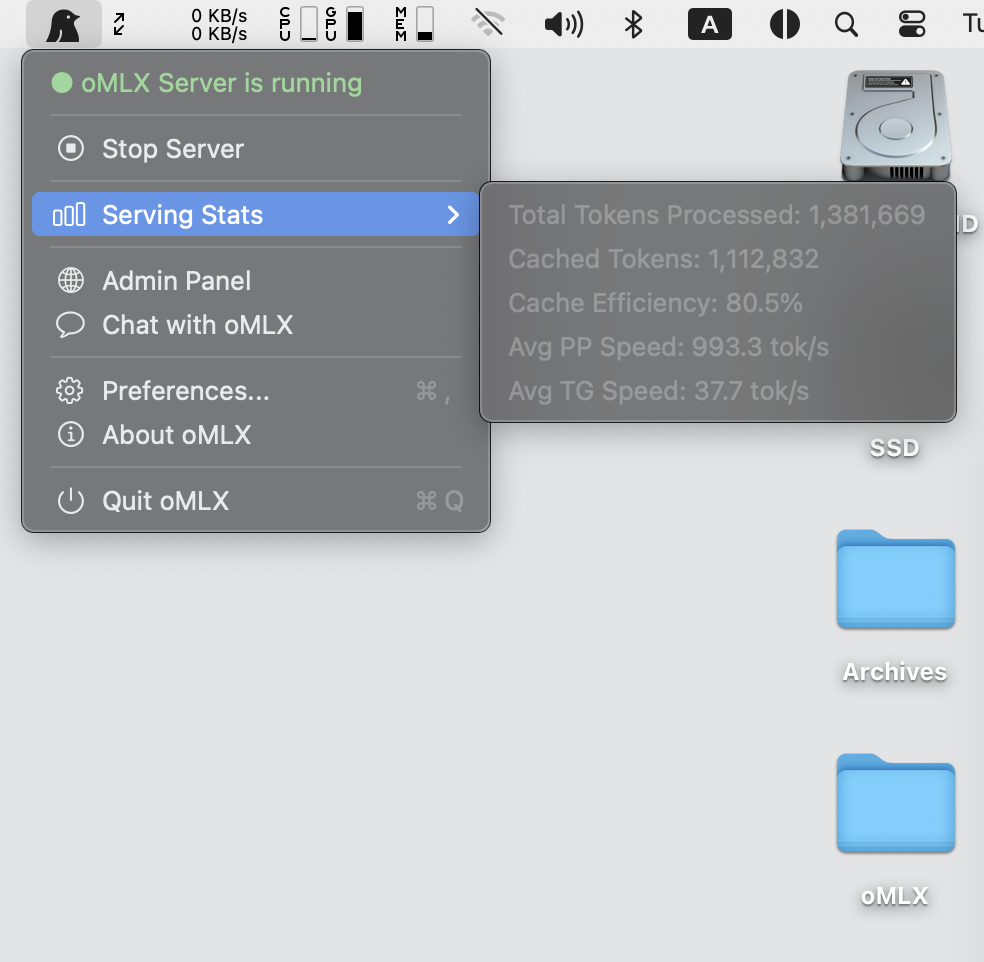
> *oMLX persists KV cache across a hot in-memory tier and cold SSD tier - even when context changes mid-conversation, all past context stays cached and reusable across requests, making local LLMs practical for real coding work with tools like Claude Code. That's why I built it.*
## Install
### macOS App
Download the `.dmg` from [Releases](https://github.com/jundot/omlx/releases), drag to Applications, done. The app includes in-app auto-update, so future upgrades are just one click. Note that the macOS app does not install the `omlx` CLI command. For terminal usage, install via Homebrew or from source.
### Homebrew
```bash
brew tap jundot/omlx https://github.com/jundot/omlx
brew install omlx
# Upgrade to the latest version
brew update && brew upgrade omlx
# Run as a background service (auto-restarts on crash)
brew services start omlx
# Optional: MCP (Model Context Protocol) support
/opt/homebrew/opt/omlx/libexec/bin/pip install mcp
```
### From Source
```bash
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e . # Core only
pip install -e ".[mcp]" # With MCP (Model Context Protocol) support
```
Requires macOS 15.0+ (Sequoia), Python 3.10+, and Apple Silicon (M1/M2/M3/M4).
## Quickstart
### macOS App
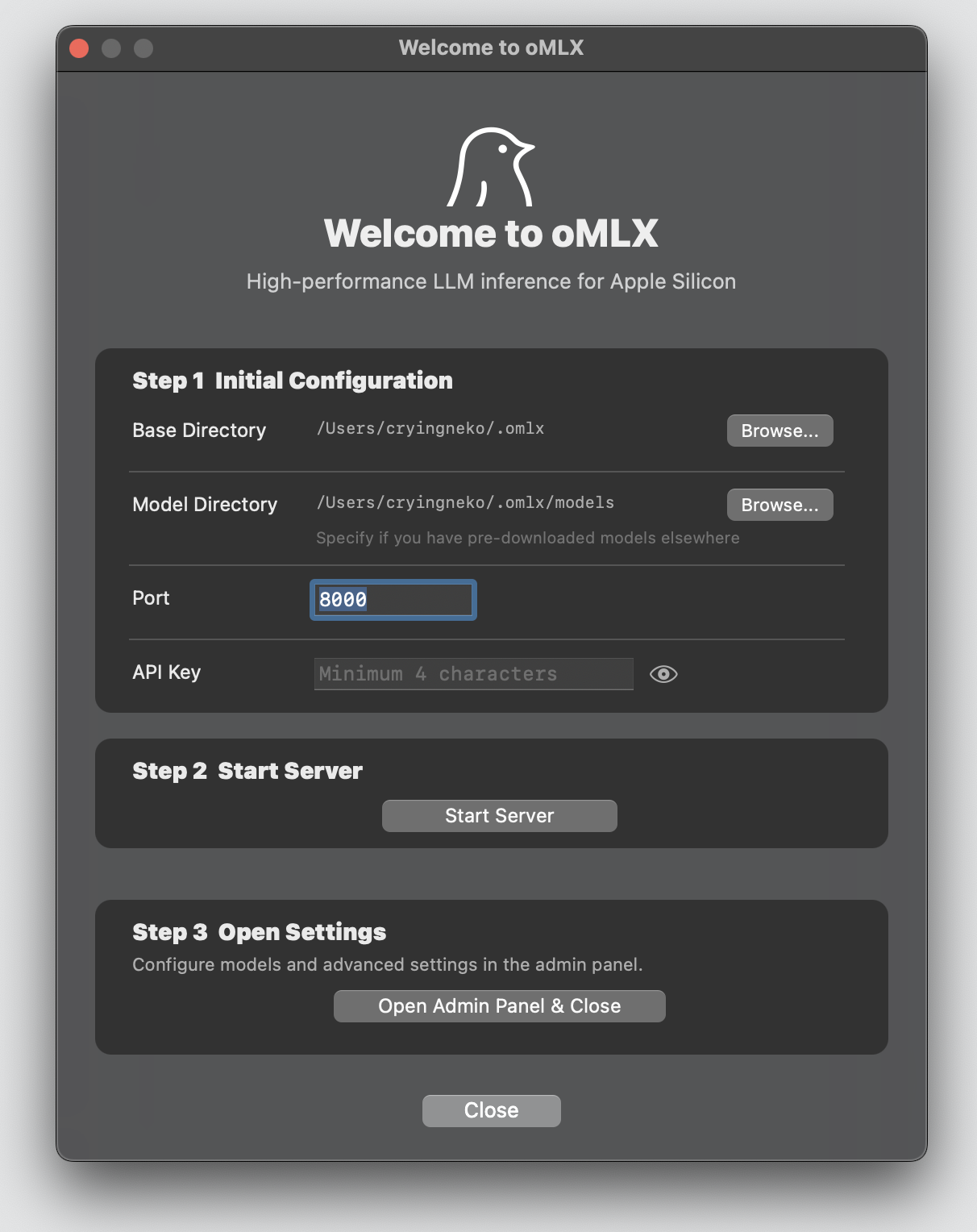
Launch oMLX from your Applications folder. The Welcome screen guides you through three steps - model directory, server start, and first model download. That's it. To connect OpenClaw, OpenCode, Codex, or Copilot, see [Integrations](#integrations).
### CLI
```bash
omlx serve --model-dir ~/models
```
The server discovers LLMs, VLMs, embedding models, and rerankers from subdirectories automatically. Any OpenAI-compatible client can connect to `http://localhost:8000/v1`. A built-in chat UI is also available at `http://localhost:8000/admin/chat`.
### Homebrew Service
If you installed via Homebrew, you can run oMLX as a managed background service:
```bash
brew services start omlx # Start (auto-restarts on crash)
brew services stop omlx # Stop
brew services restart omlx # Restart
brew services info omlx # Check status
```
The service runs `omlx serve` with zero-config defaults (`~/.omlx/models`, port 8000). To customize, either set environment variables (`OMLX_MODEL_DIR`, `OMLX_PORT`, etc.) or run `omlx serve --model-dir /your/path` once to persist settings to `~/.omlx/settings.json`.
Logs are written to two locations:
- **Service log**: `$(brew --prefix)/var/log/omlx.log` (stdout/stderr)
- **Server log**: `~/.omlx/logs/server.log` (structured application log)
## Features
Supports text LLMs, vision-language models (VLM), OCR models, embeddings, and rerankers on Apple Silicon.
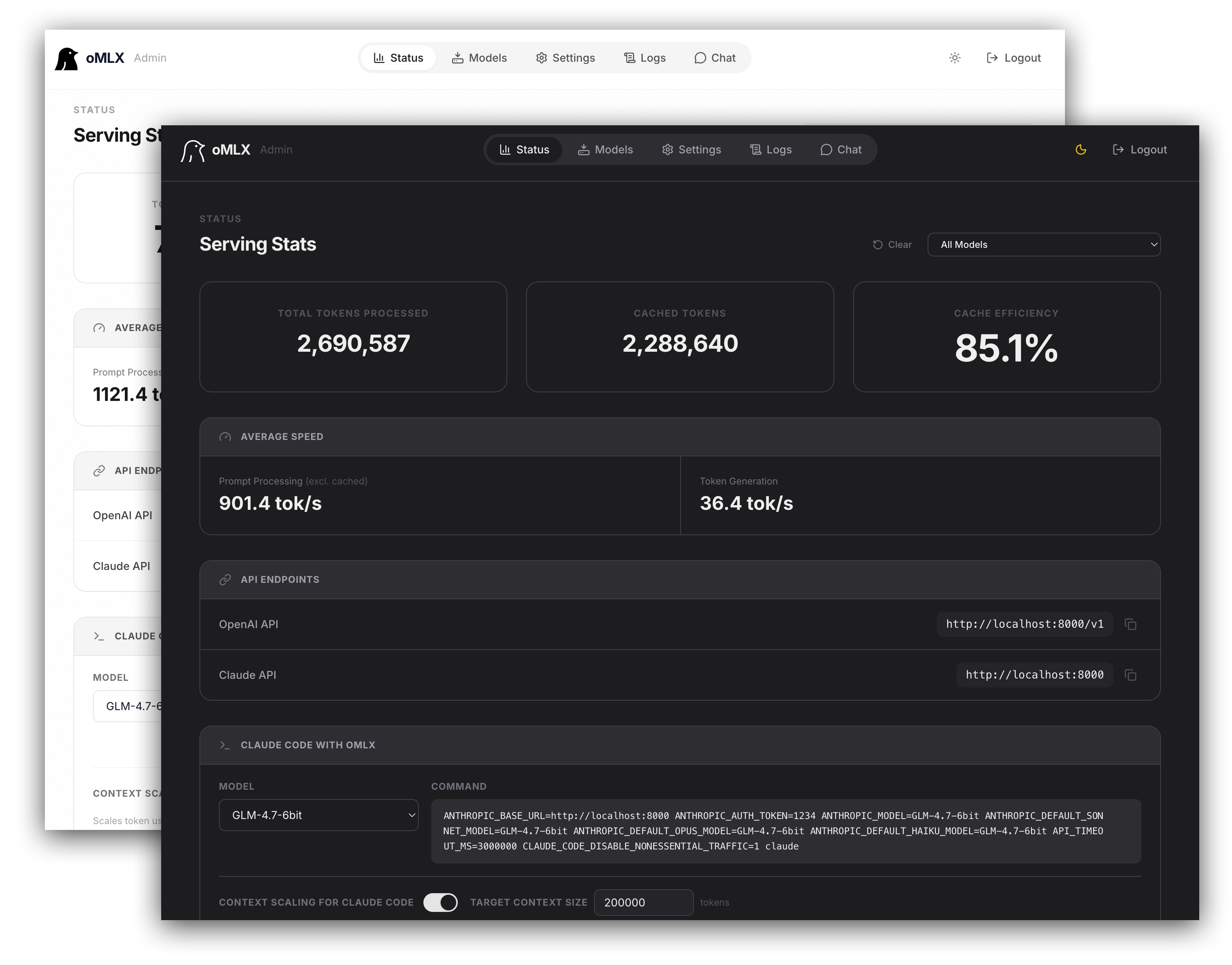
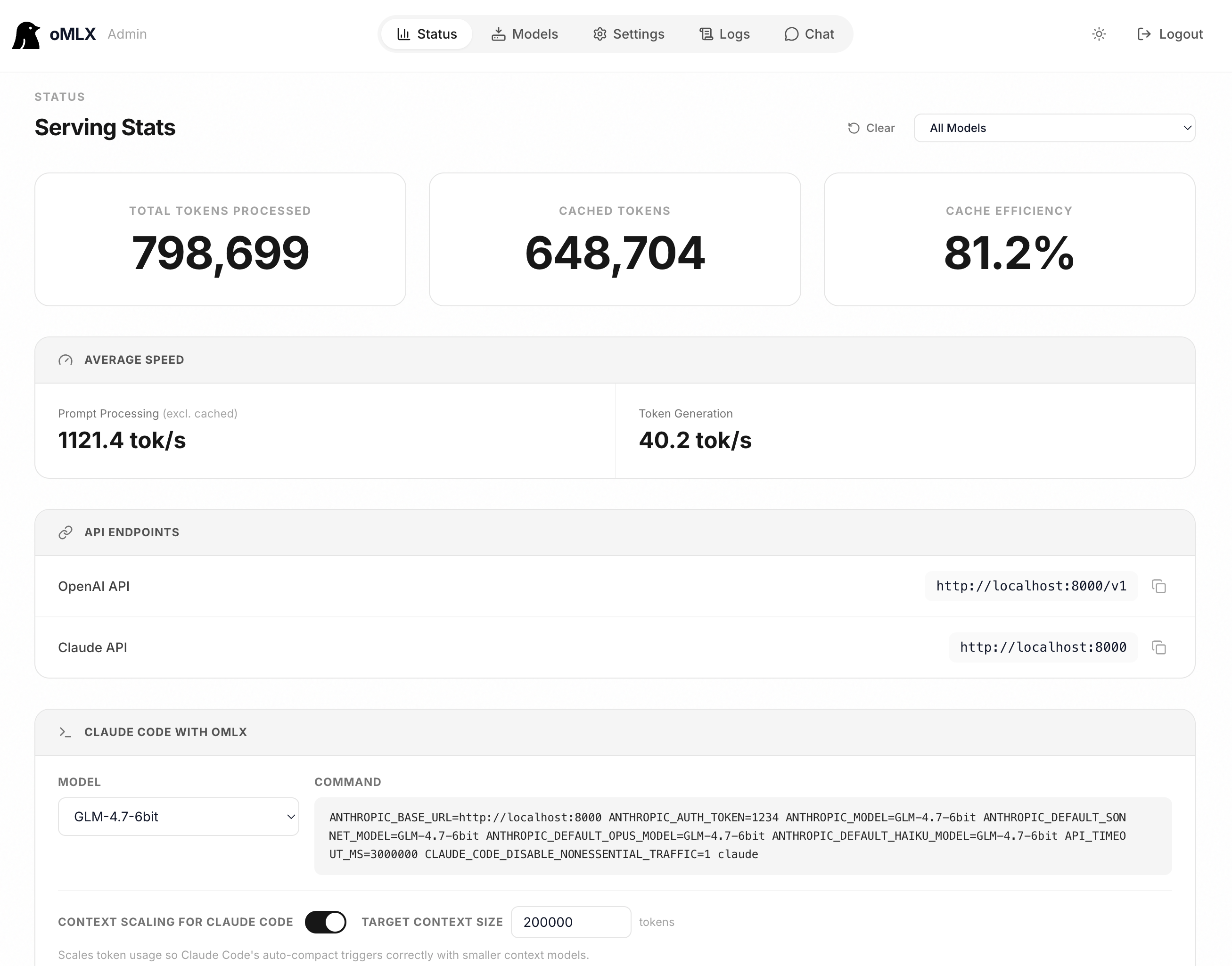
### Admin Dashboard
Web UI at `/admin` for real-time monitoring, model management, chat, benchmark, and per-model settings. Supports English, Korean, Japanese, Chinese, French, and Russian. All CDN dependencies are vendored for fully offline operation.
### Vision-Language Models
Run VLMs with the same continuous batching and tiered KV cache stack as text LLMs. Supports multi-image chat, base64/URL/file image inputs, and tool calling with vision context. OCR models (DeepSeek-OCR, DOTS-OCR, GLM-OCR) are auto-detected with optimized prompts.
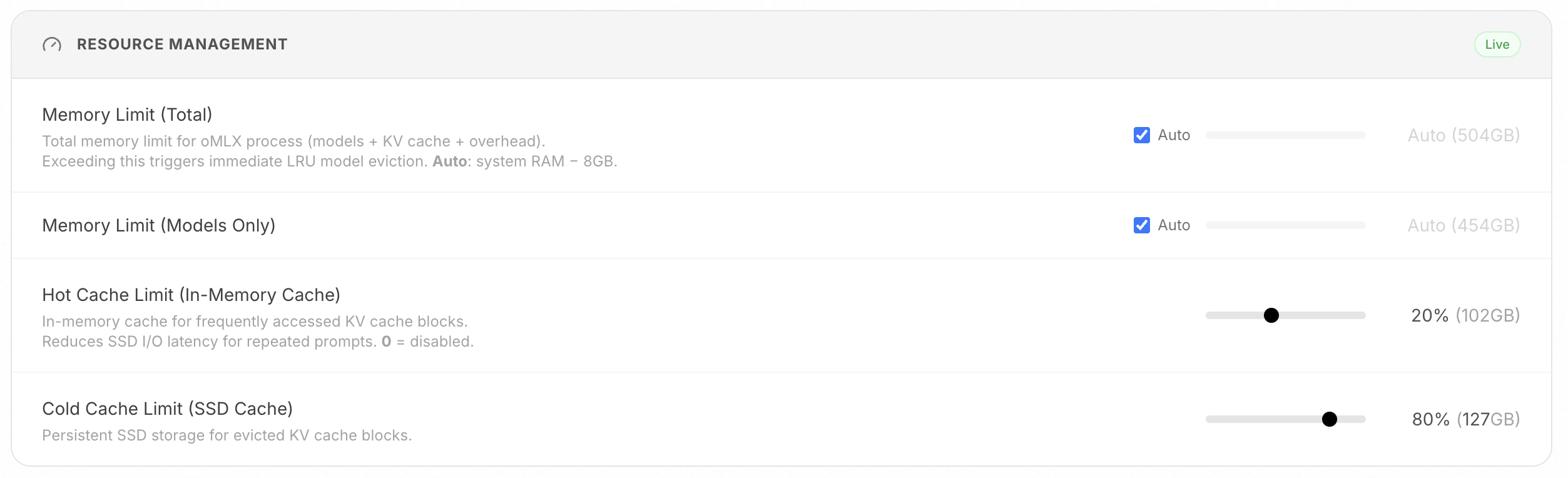
### Tiered KV Cache (Hot + Cold)
Block-based KV cache management inspired by vLLM, with prefix sharing and Copy-on-Write. The cache operates across two tiers:
- **Hot tier (RAM)**: Frequently accessed blocks stay in memory for fast access.
- **Cold tier (SSD)**: When the hot cache fills up, blocks are offloaded to SSD in safetensors format. On the next request with a matching prefix, they're restored from disk instead of recomputed from scratch - even after a server restart.
### Continuous Batching
Handles concurrent requests through mlx-lm's BatchGenerator. Max concurrent requests is configurable via CLI or admin panel.
### Claude Code Optimization
Context scaling support for running smaller context models with Claude Code. Scales reported token counts so that auto-compact triggers at the right timing, and SSE keep-alive prevents read timeouts during long prefill.
### Multi-Model Serving
Load LLMs, VLMs, embedding models, and rerankers within the same server. Models are managed through a combination of automatic and manual controls:
- **LRU eviction**: Least-recently-used models are evicted automatically when memory runs low.
- **Manual load/unload**: Interactive status badges in the admin panel let you load or unload models on demand.
- **Model pinning**: Pin frequently used models to keep them always loaded.
- **Per-model TTL**: Set an idle timeout per model to auto-unload after a period of inactivity.
- **Process memory enforcement**: Total memory limit (default: system RAM - 8GB) prevents system-wide OOM.
### Per-Model Settings
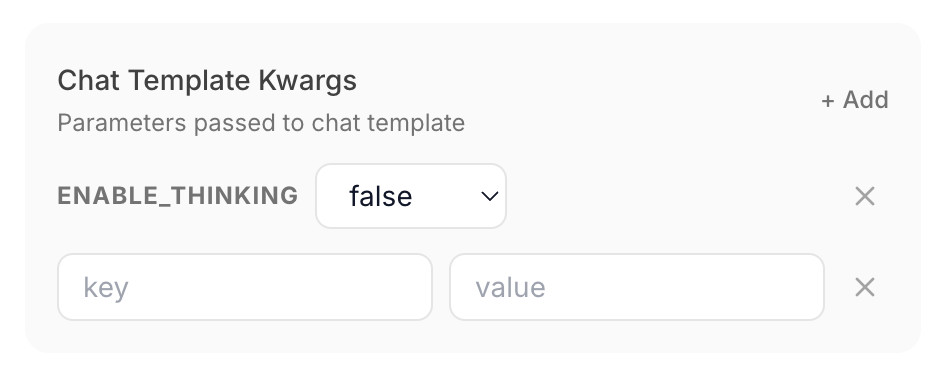
Configure sampling parameters, chat template kwargs, TTL, model alias, model type override, and more per model directly from the admin panel. Changes apply immediately without server restart.
- **Model alias**: set a custom API-visible name. `/v1/models` returns the alias, and requests accept both the alias and directory name.
- **Model type override**: manually set a model as LLM or VLM regardless of auto-detection.
### Built-in Chat
Chat directly with any loaded model from the admin panel. Supports conversation history, model switching, dark mode, reasoning model output, and image upload for VLM/OCR models.
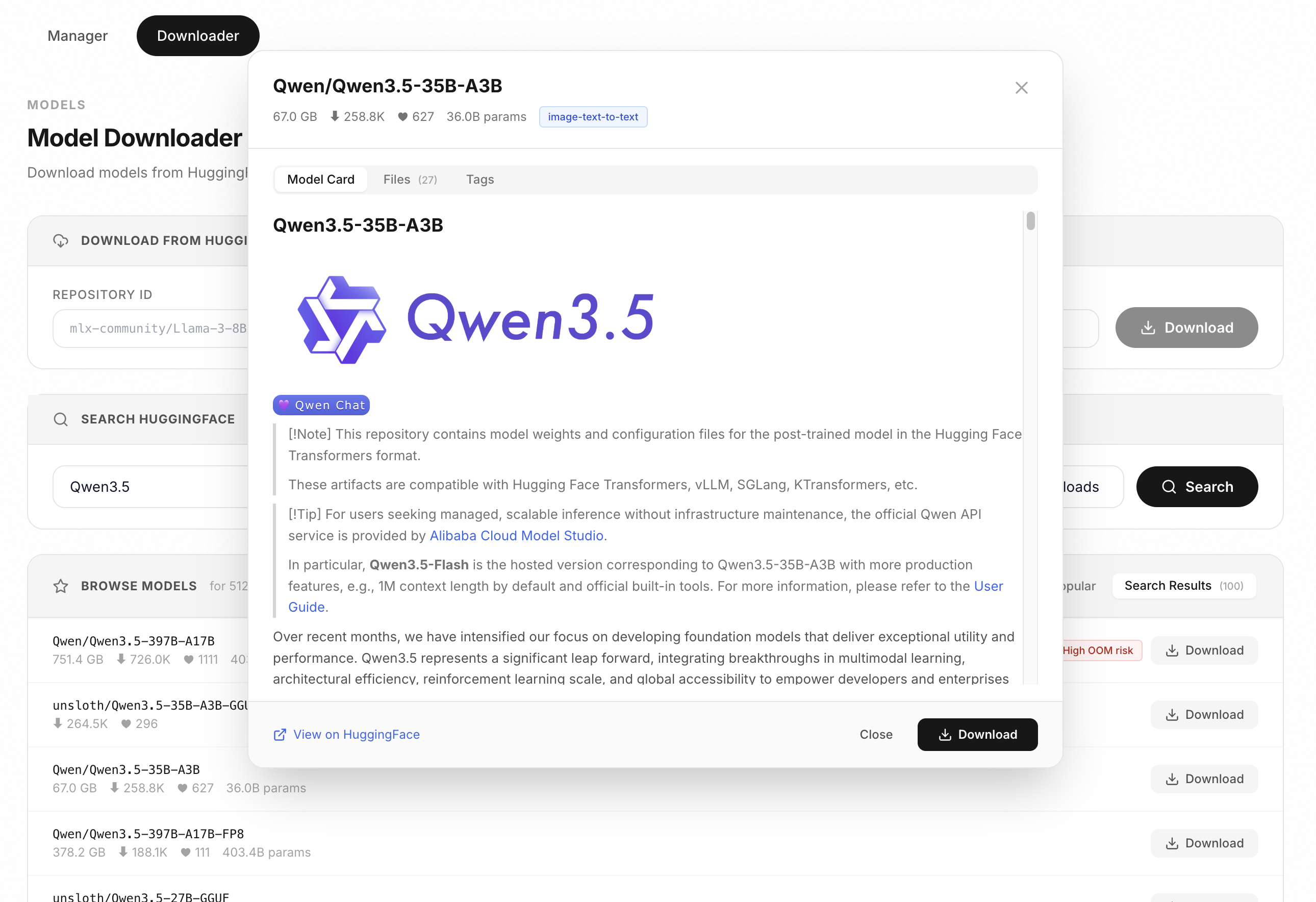
### Model Downloader
Search and download MLX models from HuggingFace directly in the admin dashboard. Browse model cards, check file sizes, and download with one click.
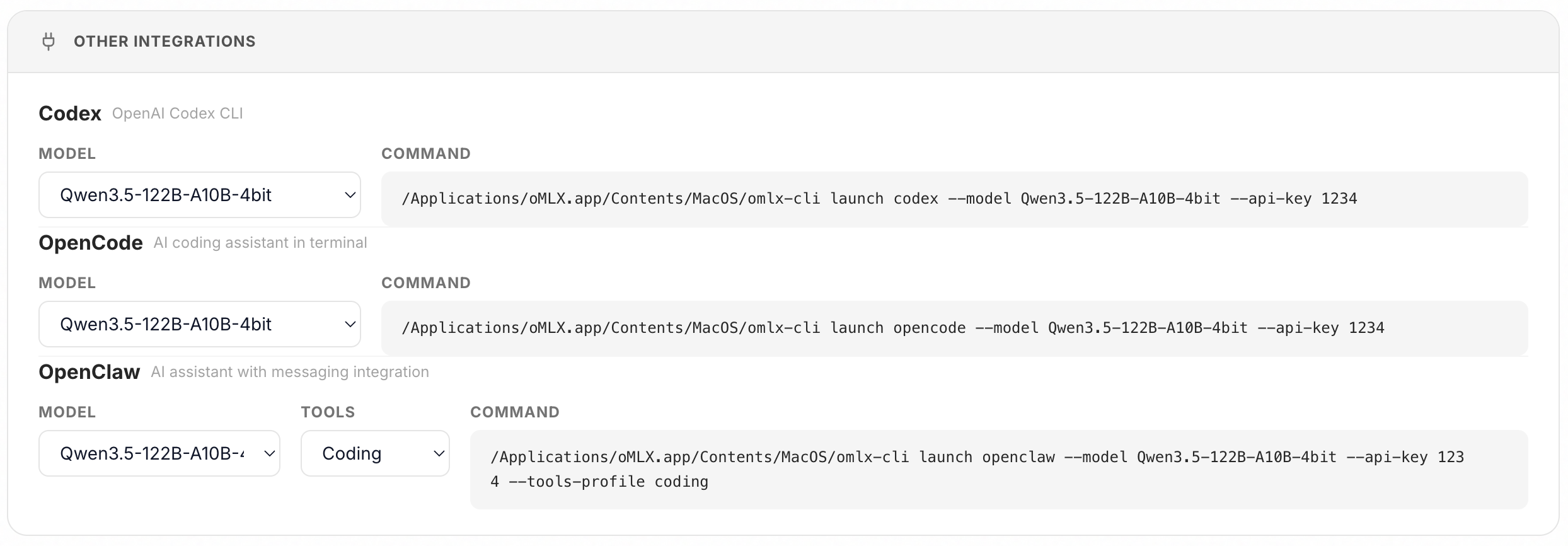
### Integrations
Set up OpenClaw, OpenCode, Codex, Copilot, and Pi directly from the admin dashboard with a single click. No manual config editing required.
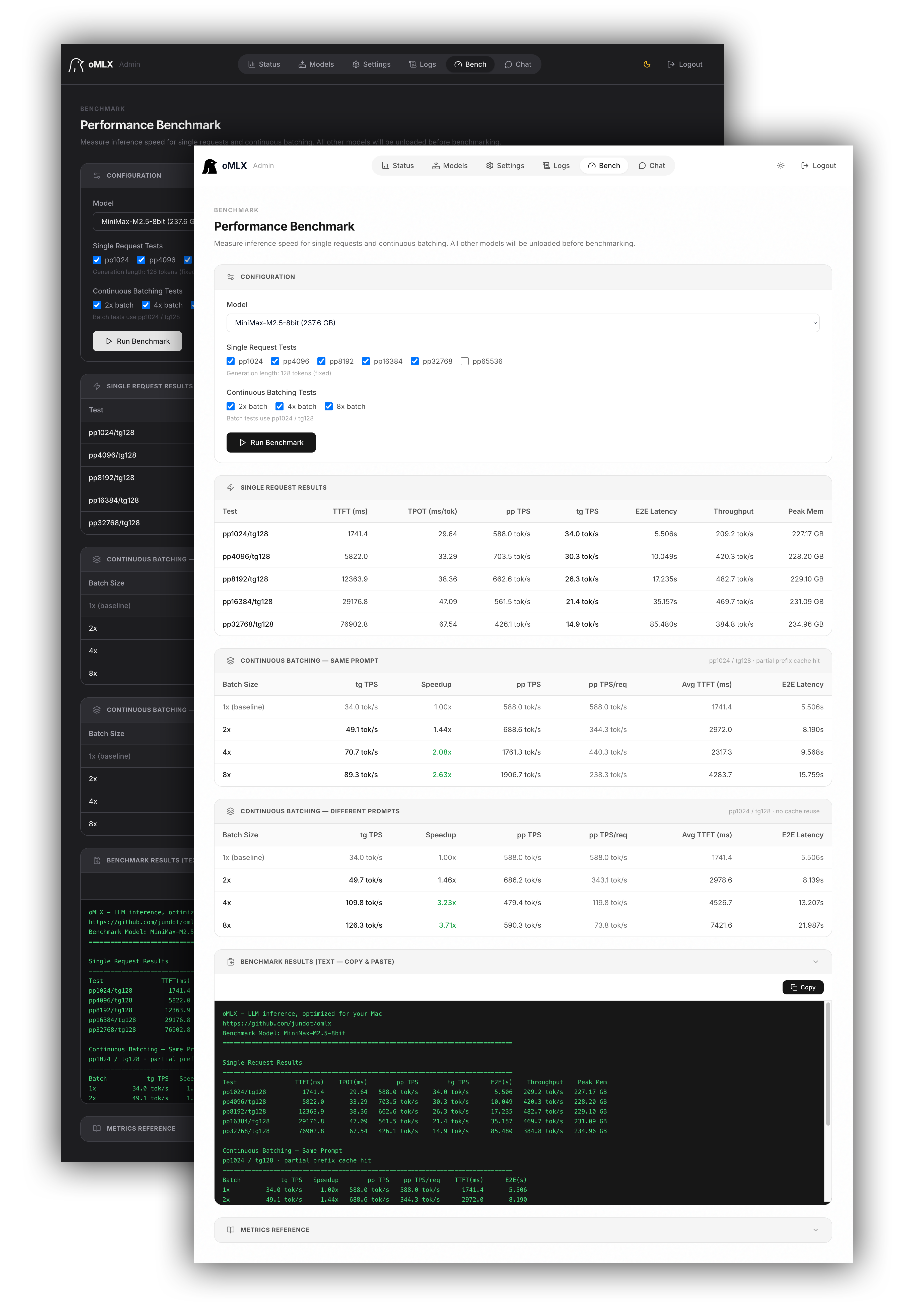
### Performance Benchmark
One-click benchmarking from the admin panel. Measures prefill (PP) and text generation (TG) tokens per second, with partial prefix cache hit testing for realistic performance numbers.
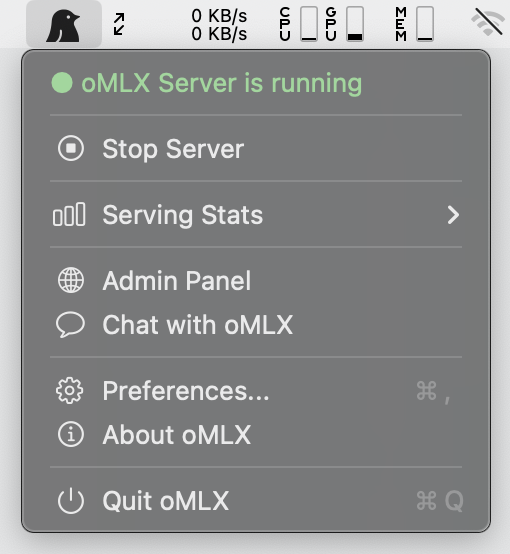
### macOS Menubar App
Native PyObjC menubar app (not Electron). Start, stop, and monitor the server without opening a terminal. Includes persistent serving stats (survives restarts), auto-restart on crash, and in-app auto-update.
### API Compatibility
Drop-in replacement for OpenAI and Anthropic APIs. Supports streaming usage stats (`stream_options.include_usage`), Anthropic adaptive thinking, and vision inputs (base64, URL).
| Endpoint | Description |
|----------|-------------|
| `POST /v1/chat/completions` | Chat completions (streaming) |
| `POST /v1/completions` | Text completions (streaming) |
| `POST /v1/messages` | Anthropic Messages API |
| `POST /v1/embeddings` | Text embeddings |
| `POST /v1/rerank` | Document reranking |
| `GET /v1/models` | List available models |
### Tool Calling & Structured Output
Supports all function calling formats available in mlx-lm, JSON schema validation, and MCP tool integration. Tool calling requires the model's chat template to support the `tools` parameter. The following model families are auto-detected via mlx-lm's built-in tool parsers:
| Model Family | Format |
|---|---|
| Llama, Qwen, DeepSeek, etc. | JSON `` |
| Qwen3.5 Series | XML `` |
| Gemma | `` |
| GLM (4.7, 5) | `/` XML |
| MiniMax | Namespaced `` |
| Mistral | `[TOOL_CALLS]` |
| Kimi K2 | `<\|tool_calls_section_begin\|>` |
| Longcat | `` |
Models not listed above may still work if their chat template accepts `tools` and their output uses a recognized `` XML format. For tool-enabled streaming, assistant text is emitted incrementally while known tool-call control markup is suppressed from visible content; structured tool calls are emitted after parsing the completed turn.
## Models
Point `--model-dir` at a directory containing MLX-format model subdirectories. Two-level organization folders (e.g., `mlx-community/model-name/`) are also supported.
```
~/models/
├── Step-3.5-Flash-8bit/
├── Qwen3-Coder-Next-8bit/
├── gpt-oss-120b-MXFP4-Q8/
├── Qwen3.5-122B-A10B-4bit/
└── bge-m3/
```
Models are auto-detected by type. You can also download models directly from the admin dashboard.
| Type | Models |
|------|--------|
| LLM | Any model supported by [mlx-lm](https://github.com/ml-explore/mlx-lm) |
| VLM | Qwen3.5 Series, GLM-4V, Pixtral, and other [mlx-vlm](https://github.com/Blaizzy/mlx-vlm) models |
| OCR | DeepSeek-OCR, DOTS-OCR, GLM-OCR |
| Embedding | BERT, BGE-M3, ModernBERT |
| Reranker | ModernBERT, XLM-RoBERTa |
## CLI Configuration
```bash
# Memory limit for loaded models
omlx serve --model-dir ~/models --max-model-memory 32GB
# Process-level memory limit (default: auto = RAM - 8GB)
omlx serve --model-dir ~/models --max-process-memory 80%
# Enable SSD cache for KV blocks
omlx serve --model-dir ~/models --paged-ssd-cache-dir ~/.omlx/cache
# Set in-memory hot cache size
omlx serve --model-dir ~/models --hot-cache-max-size 20%
# Adjust max concurrent requests (default: 8)
omlx serve --model-dir ~/models --max-concurrent-requests 16
# With MCP tools
omlx serve --model-dir ~/models --mcp-config mcp.json
# HuggingFace mirror endpoint (for restricted regions)
omlx serve --model-dir ~/models --hf-endpoint https://hf-mirror.com
# API key authentication
omlx serve --model-dir ~/models --api-key your-secret-key
# Localhost-only: skip verification via admin panel global settings
```
All settings can also be configured from the web admin panel at `/admin`. Settings are persisted to `~/.omlx/settings.json`, and CLI flags take precedence.
Architecture
```
FastAPI Server (OpenAI / Anthropic API)
│
├── EnginePool (multi-model, LRU eviction, TTL, manual load/unload)
│ ├── BatchedEngine (LLMs, continuous batching)
│ ├── VLMEngine (vision-language models)
│ ├── EmbeddingEngine
│ └── RerankerEngine
│
├── ProcessMemoryEnforcer (total memory limit, TTL checks)
│
├── Scheduler (FCFS, configurable concurrency)
│ └── mlx-lm BatchGenerator
│
└── Cache Stack
├── PagedCacheManager (GPU, block-based, CoW, prefix sharing)
├── Hot Cache (in-memory tier, write-back)
└── PagedSSDCacheManager (SSD cold tier, safetensors format)
```
## Development
### CLI Server
```bash
git clone https://github.com/jundot/omlx.git
cd omlx
pip install -e ".[dev]"
pytest -m "not slow"
```
### macOS App
Requires Python 3.11+ and [venvstacks](https://venvstacks.lmstudio.ai) (`pip install venvstacks`).
```bash
cd packaging
# Full build (venvstacks + app bundle + DMG)
python build.py
# Skip venvstacks (code changes only)
python build.py --skip-venv
# DMG only
python build.py --dmg-only
```
See [packaging/README.md](packaging/README.md) for details on the app bundle structure and layer configuration.
## Contributing
Contributions are welcome! See [Contributing Guide](docs/CONTRIBUTING.md) for details.
- Bug fixes and improvements
- Performance optimizations
- Documentation improvements
## License
[Apache 2.0](LICENSE)
## Acknowledgments
- [MLX](https://github.com/ml-explore/mlx) and [mlx-lm](https://github.com/ml-explore/mlx-lm) by Apple
- [mlx-vlm](https://github.com/Blaizzy/mlx-vlm) - Vision-language model inference on Apple Silicon
- [vllm-mlx](https://github.com/waybarrios/vllm-mlx) - oMLX started from vllm-mlx v0.1.0 and evolved significantly with multi-model serving, tiered KV caching, VLM with full paged cache support, an admin panel, and a macOS menu bar app
- [venvstacks](https://venvstacks.lmstudio.ai) - Portable Python environment layering for the macOS app bundle
- [mlx-embeddings](https://github.com/Blaizzy/mlx-embeddings) - Embedding model support for Apple Silicon
- [dflash-mlx](https://github.com/bstnxbt/dflash-mlx) - Block diffusion speculative decoding on Apple Silicon