Recorriendo el árbol DOM
- Artículo anterior—Objetos en JavaScript
- Artículo siguiente—Creando y modificando HTML
- Índice de contenidos
Introducción
Es difícil encontrarse con un ejemplo de código JavaScript usable en la Web que no interaccione de alguna manera con un documento HTML. Generalmente, el código va a necesitar leer valores de la página, procesarlos de alguna forma, y entonces, generar una salida en forma de cambios visibles en la página, o como mensajes informativos. Dado que nuestro siguiente paso es el objetivo de crear interfaces más receptivos para nuestras páginas y aplicaciones, este artículo y el siguiente presentarán el DOM - Document Object Model, que provee mecanismos para inspeccionar y manipular las capas de semántica y presentación que hayamos creado.
Después de leer este artículo, tendremos un buen conocimiento de que es DOM, y cómo podemos utilizarlo para navegar a traves de una página HTML, con objeto de encontrar el sitio exacto donde necesitamos recoger algún dato, o hacer un cambio. El siguiente artículo de la serie ( Creando y modificando HTML) recogerá el testigo ahí, mostrando los métodos mediante los cuales podremos modificar los datos de la página, cambiando valores ó creando completamente nuevos elementos y atributos.
La estructura de este artículo es la siguiente:
Plantando las semillas
DOM, como se puede suponer de Document Object Model, es un modelo de documento HTML que es creado por el navegador cuando este carga una página Web. JavaScript tiene acceso a toda la información de este modelo. Vayamos atrás un momento, y tengamos en cuenta que es lo que exactamente estamos modelando.
Cuando construimos una página, el objetivo es añadir contenido mediante el mapeo a los tags HTML que tenemos disponibles.
Algo de contenido puede ser un párrafo, así que podemos usar el tag p; el siguiente es un enlace,
así que podemos usar el tag a, y continuar así. También podemos codificar relaciones entre elementos:
los campos input tienen un label, y pueden estar juntos dentro de un fieldset.
Además, se puede ir más allá del conjunto básico de tags de HTML, añadiendo los atributos id y class
donde sea apropiado, para inculcar en la página estructuras que se pueden usar para manipular ó estilizar la página.
Una vez esté construido el contenido y la semántica HTML, podemos usar CSS para estilizar la presentación de la página.
Et voilà, habremos creado una página que hará las delicias de los usuarios.
Pero esto no es todo. Habremos creado un documento que estará empapado de meta-información que podremos manipular usando JavaScript. Podemos encontrar elementos específicos o grupos de elementos que añadir, eliminar, y modificar, de acuerdo a variables definidas por el usuario; podemos encontrar información de presentación (CSS) y modificar estilos al vuelo; podemos validar la información que los usuarios han introducido en formularios; y una gran cantidad de otras cosas. Para que JavaScript pueda hacer estas cosas, necesitamos acceso a información, y el árbol DOM provee a JavaScript justo lo que necesita.
Es importante hacer notas que un CSS y HTML bien formados son la semilla desde la que el modelo JavaScript para la página podrá crecer. El modelo de un documento pobremente construido diferirá de muchas maneras de nuestras expectativas, y tendrá inconsistencias entre los navegadores. Es, por tanto, vital, que nuestros CSS y HTML estén bien formados y válidos para garantizar que JavaScript se encuentra con el modelo exacto que nosotros hayamos pensado.
Generando árboles
Después de crear y estilizar nuestro documento, el siguiente paso es mostrarlo en un navegador a los usuarios. Aquí es donde el árbol DOM entra en juego, se lee el documento que hemos escrito, y se genera dinámicamente el árbol DOM que podemos utilizar en nuestros programas. Especificamente, el árbol DOM representa la página HTML como un árbol, de la misma forma que nosotros podemos representar nuestros antepasados como el árbol familiar. Cada elemento en la página es contenido en el árbol DOM como un nodo, que tendrá ramas enlazadas a elementos que él mismo contiene (sus hijos), y a los elementos que directamente le contienen a él (sus padres). Echemos un vistazo a un documento HTML simple, para ver claramente estas relaciones:
<html>
<head>
<title>Esto es un Documento</title>
</head>
<body>
<h1>Esto es una cabecera</h1>
<p id="TextoExcitante">
Esto es un párrafo! <em>Excitante</em>!
</p>
<p>
Esto también es un párrafo, pero no es ni de lejos tan excitante como el último.
</p>
</body>
</html>Como podemos ver, el documento completo está contenido en un elemento html. Este elemento directamente
contiene otros dos: head y body. Estos se muestran en el modelo como sus hijos, y ellos apuntan
hacia html como su padre. Y así continua, bajando a través de la jerarquía del documento, en el que cada
elemento apunta a sus descendientes directos como hijos, y a su ancestro directo como su padre:
titlees el hijo dehead.bodytiene tres hijos — dos elementospy un elementoh1.- El elemento
pconid="TextoExcitante"tiene un hijo, — el elementoem. - El texto plano de los elementos (por ejemplo “Esto es un Documento!”) tambien se representa en el DOM, como nodos de texto. No tienen hijos propios, pero apuntan a sus contenedores como su padre.
Así que la jerarquía del árbol DOM del documento HTML que hemos presentado anteriormente, se puede resumir visualmente en la Figura 1:
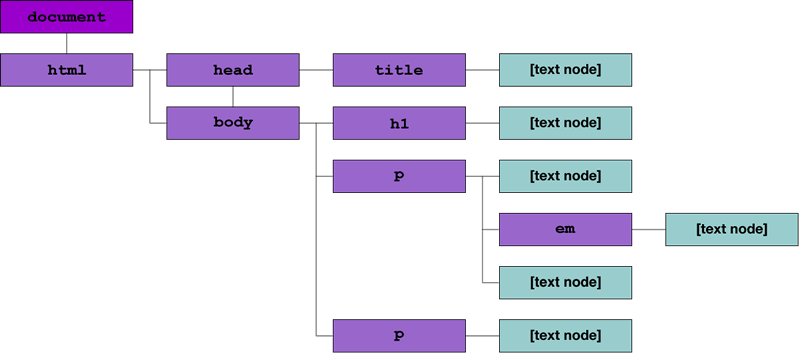
Figura 1: El anterior documento HTML representado visualmente mediante su árbol DOM.
Es un mapeo sencillo desde un documento HTML a su estructura tipo árbol, que resume brevemente las
relaciones directas entre elementos de la página, clarificando la jerarquía del árbol. Se puede notar,
no obstante, que se ha añadido un nodo llamado document sobre el nodo html.
Esta es la raíz del documento, y actúa como el elemento de primer nivel accesible por JavaScript.
Nodos
Antes de que empezemos a bailar por el árbol, y a balancearnos de rama en rama, tomemos un momento para reflexionar sobre que tenemos realmente entre manos.
Cada nodo en el árbol DOM es un objeto, representando un elemento simple en la página. Los nodos mantienen relaciones con sus nodos inmediatamente vecinos, y contienen una gran cantidad de información sobre ellos mismos. De la misma forma que un niño puede trepar de una rama a la siguiente más cercana en un roble de un patio trasero, podemos recoger toda la información de un nodo que nosotros necesitemos de su padre ó de sus hijos.
Como se puede esperar, dada la orientación a objetos de JavaScript, la información que estamos
buscando en este caso, es proporcionada vía las propiedades de los nodos. Específicamente, las propiedades
parentNode y childNodes. Como cada elemento en la página tiene al menos un padre,
la propiedad parentNode está clara: nos da accceso al nodo padre. Los nodos pueden tener
cualquier número de hijos, por tanto, la propiedad childNodes es un array realmente. Cada
elemento del array es un hijo, en el mismo orden que aparecen en el documento. En el ejemplo de documento,
el elemento body tiene un array childNodes conteniendo primero h1,
después el primer p, y luego el segundo p, en ese orden.
Éstas no son las únicas propiedades interesantes de los nodos, claro. Pero es un buén comienzo. Así que, ¿que nodo utilizaremos cuando pongamos nuestras manos por primera vez encima de ellos? ¿Por donde empezaremos la exploración?.
Rama a rama
La mejor forma de empezar es por la raíz del documento, accesible mediante un objeto creativamente
llamado document. Como document es la raíz, no tiene parentNode,
y además sólo tiene un hijo: el nodo html, al que tenemos acceso mediante el array
childNodes de document:
var nodoHtml = document.childNodes[0];Esta línea de código crea una nueva variable llamada nodoHtml, y le asígna un valor, el
del primer hijo del objeto document (recordar que los arrays en JavaScript empiezan en 0, no en 1).
Podemos confirmar que tenemos las manos encima del nodo html accediendo a la propiedad
nodeName de nodoHtml, que nos da informacíón vital sobre el tipo de nodo
con el que estamos tratando:
alert( "nodoHtml es un nodo " + nodoHtml.nodeName + " !" );Este codigo muestra un pop-up de alerta que dice “nodoHtml es un nodo HTML !”. La propiedad
nodeName nos da acceso al tipo de nodo que es. Para nodos que son elementos, la propiedad
contiene el nombre del tag en mayúsculas: es el “HTML”; para un enlace tendría que ser
“A”, para un párrafo “P”, y así. Para un nodo de texto, la propiedad nodeName
es “#text”, y la propiedad nodeName de document es “#document”.
Además, sabemos que nodoHtml debería contener una referencia a su padre. Podemos chequear
que esto funciona, y que tiene una referencia a su padre, de la siguiente forma, con el siguiente test:
if ( nodoHtml.parentNode == document ) {
alert( "Ooooh! El padre del nodo HTML es el objeto document!" );
}Esto es justo lo que nosotros esperábamos. Utilizando esta información, podemos escribir determinado
código para obtener la referencia al primer párrafo en el cuerpo del documento de ejemplo. Es el segundo
hijo del elemento body element, que a su vez es el segundo hijo del elemento html,
que es el primer hijo del objeto document. Vaya.
var nodoHtml = document.childNodes[0];
var nodoBody = nodoHtml.childNodes[1];
var nodoParrafo = nodoBody.childNodes[1];
alert( "nodoParrafo es el nodo " + nodoParrafo.nodeName + " !" );Estupendo. Esto hace exactamente lo que nosotros necesitamos. Pero es un poco excesivo en cuanto a código escrito, y efectivamente hay una manera mejor de escribir esto mismo. En el artículo de objetos aprendimos como se pueden encadenar las referencias a objetos; aquí podemos hacer la misma cosa, obviando las variables intermedias, podemos escribir lo siguiente:
var nodoParrafo = document.childNodes[0].childNodes[1].childNodes[1];
alert( "nodoParrafo es el nodo " + nodoParrafo.nodeName + " !" );Esto es mucho más compacto, se ahorra bastante código
El primer hijo de un nodo es siempre node.childNodes[0], y el último hijo es siempre
node.childNodes[node.childNodes.length - 1]. Se suele acceder bastante a ellos, y son
un poco pesados de escribir una y otra vez. Es por eso que el árbol DOM nos da, explícitamente, dos
formas reducidas de escribir ambas: .firstChild y .lastChild respectivamente.
Como el nodo html es el primer hijo del objeto document, y el nodo
body es el último hijo del nodo html, podemos reescribir el código anterior
de una forma mucho más clara, así:
var nodoParrafo = document.firstChild.lastChild.childNodes[1];
alert( "nodoParrafo es el nodo " + nodoParrafo.nodeName + " !" );El método de navegacion a traves de arrays de los nodos es bastante útil, y nos permitirá acceder a donde queramos en el documento, pero suele ser bastante pesado. Aún en este ejemplo mínimo, se puede ver que es bastante laborioso el conseguir navegar desde la raíz del árbol hacia dentro de las profundidades del documento. ¡Es por eso que existe una forma mucho mejor de hacerse!.
Acceso directo
La verdad es que es muy difícil el tener especificar rutas de cada uno de los elementos de una página en los que estamos interesados. Más aún, se convierte en una tarea completamente imposible, si la página en la que estamos trabajando es generada dinámicamente de alguna forma (por ejemplo, utilizando un lenguaje en el servidor como PHP ó ASP.NET), porque no podemos garantizar que, por ejemplo, el párrafo que estamos buscando sea siempre el segundo hijo del nodo body. Así que es necesario un mejor modo de acceder a un elemento específico sin que haya que tener conocimiento de los nodos de su entorno.
Echando un vistazo al documento HTML del ejemplo anterior, podemos ver que hay un atributo id
en el párrafo del que estamos hablando. Este id es único, identifica una localización
específica en el documento, y nos permite eludir el tener que usar una ruta completa, mediante la
utilización del método getElementById del objeto document. Este metodo
hace exactamente lo que esperamos de él, nos retorna null si le proporcionamos un id que
no existe en la página, ó el elemento que hemos pedido si el id existe. Para ver esto,
comparemos los resultados del método viejo con el nuevo:
var nodoParrafo = document.getElementById('TextoExcitante');
if ( document.firstChild.lastChild.childNodes[1] == nodoParrafo ) {
alert( "nodoParrafo es exactamente lo que buscamos!" );
}Este código mostrará un diálogo confirmando que los dos métodos nos dan resultados idénticos para
este documento HTML de ejemplo. getElementById es la forma más eficiente de tener acceso
a una pieza en particular de la página: si nosotros sabemos que vamos a necesitar hacer algun proceso
sobre una página (sobre todo si no podemos garantizar donde), añadir un atributo id en
el sitio apropiado nos ahorrará mucho tiempo.
Igualmente útil es el método getElementsByTagName, que retorna una coleccion de todos
los elementos de una página de un tipo particular. Por ejemplo, podemos obtener todos los elementos
p en una página. El siguiente ejemplo nos muestra tanto el párrafo excitante, como su
menos interesante hermano:
var todosLosParrafos = document.getElementsByTagName('p');Lo mejor para procesar la colección resultante almacenada en todosLosParrafos
es usar un for : podemos trabajar con ella como si fuera un array:
for (var i=0; i < todosLosParrafos.length; i++ ) {
// hacer aquí nuestro procesamiento, usando
// "todosLosParrafos[i]" para referenciar
// el elemento actual de la colección.
alert( "Este es el parrafo " + i + "!" );
}Para documentos más complejos, retornar todos los elementos de un tipo puede ser abrumador.
En vez de trabajar con unos 200 divs en una página grande, es más lógico que queramos
trabajar con los divs de una sección específica. En este caso, podemos combinar dos métodos
para filtrar los resultados: obtener un elemento usando su id, y preguntar por todos los
elementos de un determinado tipo que contenga. Como ejemplo, podemos obtener todos los
elementos em del párrafo emocionante, preguntando por lo siguiente:
document.getElementById('TextoExcitante').getElementsByTagName('em')Resumen
El árbol DOM es la base de casí todo lo que JavaScript puede hacer por nosotros en la Web. Es el interfaz que nos permite interaccionar con el contenido de nuestra página, y es esencial para entender como trabajar con ese modelo.
Este artículo nos da las herramientas base para este trabajo. Ahora, podemos acceder y recorrer
el árbol DOM facilmente, utilizando document para obtener la raíz del árbol DOM, y
usando childNodes y parentNode para subir y bajar por el árbol accediendo
a los familiares de los nodos. Podemos obviar intermediarios, y evitar tener que codificar rutas
largas codificadas como tal en el documento, mediante la utilización de getElementById
y getElementsByTagName para crear nuestros propios enlaces. De todas formas, en relación
a viajar por la estructura del árbol DOM, esto es sólo el principio.
El siguiente paso lógico es empezar a hacer algo interesante con los resultados que JavaScript nos devuelve. Necesitamos recoger esos datos para alimentar nuestros scripts, y tendremos que manipular datos de la página para crear emocionantes interacciones con el usuario. Exploraremos estos aspectos en el siguiente artículo, que nos mostrará cómo debemos usar los métodos que el árbol DOM provee para manipular los nodos y sus atributos, y cómo construir las interacciones entre los scripts y los interfaces que crearemos en el futuro.
Ejercicios
- Utilizando el documento de ejemplo de este artículo, escribir tres rutas diferentes que acaben
en el elemento
head. Recordar que podemos encadenarchildNodesyparentNodetanto como queramos. - Dado un nodo cualquiera, ¿cómo podemos determinar su tipo?
- Dado un nodo cualquiera, ¿cómo podemos ir al objeto
documentobject? Pista: Recordar que la propiedadparentNodedel objetodocumentretornanull.
- Artículo anterior — Objetos JavaScript
- Siguiente artículo — Creando y modificando HTML
- Índice de contenidos
Acerca del autor

Mike West es un estudiante de filosofía habilmente disfrazado como un experimentado y exitoso desarrollador web. Él ha estado trabajando en la web durante una década, más recientemente en el equipo responsable de la construcción del sitio de noticias de Yahoo Europa.
Después de abandonar las llanuras de suburbios de Texas en 2005, Mike se estableció en Munich, Alemania, donde lidia (cada vez menos) cada dia con el idioma. mikewest.org es su página personal en la web, donde, despacio, reúne sus escritos y enlaces juntos para la posteridad. Él mantiene su código en GitHub.
This article is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported license.
Comments
The forum archive of this article is still available on My Opera.
No new comments accepted.