 |
Caffe2 - C++ API
A deep learning, cross platform ML framework
|
|
Caffe2 - C++ API
A deep learning, cross platform ML framework
|
Public Member Functions | |
| CudnnConvOp (const OperatorDef &operator_def, Workspace *ws) | |
| template<typename T_X , typename T_W , typename T_B , typename T_Y > | |
| bool | DoRunWithType () |
| bool | RunOnDevice () override |
 Public Member Functions inherited from caffe2::CudnnConvOpBase Public Member Functions inherited from caffe2::CudnnConvOpBase | |
| CudnnConvOpBase (const OperatorDef &operator_def, Workspace *ws) | |
| Public Member Functions inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| ConvPoolOpBase (const OperatorDef &operator_def, Workspace *ws) | |
| vector< int > | GetDims (const Tensor< CUDAContext > &input) |
| int | GetDimsSize (const Tensor< CUDAContext > &input) |
| void | SetOutputSize (const Tensor< AlternativeContext > &input, Tensor< AlternativeContext > *output, int output_channel) |
| void | ComputePads (const vector< int > &dims) |
| void | SetDeviceTensor (const std::vector< int > &data, Tensor< CUDAContext > *tensor) |
| void | SetBiasMultiplier (const int size, Tensor< CUDAContext > *bias_multiplier_) |
| bool | RunOnDevice () override |
| virtual bool | RunOnDeviceWithOrderNHWC () |
| virtual bool | RunOnDeviceWithOrderNCHW () |
| Public Member Functions inherited from caffe2::Operator< CUDAContext > | |
| Operator (const OperatorDef &operator_def, Workspace *ws) | |
| const Tensor< CUDAContext > & | Input (int idx) |
| Tensor< CUDAContext > * | Output (int idx) |
| void | WaitEvent (const Event &ev, int stream_id=-1) final |
| void | WaitEvents (const std::vector< const Event * > &events, int stream_id=-1) final |
| bool | Run (int stream_id=0) final |
| bool | RunAsync (int stream_id=0) final |
| bool | IsStreamFree (int stream_id) const override |
| bool | HasAsyncPart () const override |
| bool | SupportsAsyncScheduling () const override |
| const CUDAContext * | getContext () const |
| Public Member Functions inherited from caffe2::OperatorBase | |
| OperatorBase (const OperatorDef &operator_def, Workspace *ws) | |
| bool | HasArgument (const string &name) const |
| Checks if the operator has an argument of the given name. | |
| template<typename T > | |
| T | GetSingleArgument (const string &name, const T &default_value) const |
| template<typename T > | |
| bool | HasSingleArgumentOfType (const string &name) const |
| template<typename T > | |
| vector< T > | GetRepeatedArgument (const string &name, const vector< T > &default_value={}) const |
| template<typename T > | |
| const T & | Input (int idx) |
| template<typename T > | |
| T * | Output (int idx) |
| template<typename T > | |
| T * | Output (int idx, T *allocated) |
| const Blob & | InputBlob (int idx) |
| Blob * | OutputBlob (int idx) |
| template<typename T > | |
| bool | InputIsType (int idx) |
| template<typename T > | |
| bool | OutputIsType (int idx) |
| int | InputSize () const |
| int | OutputSize () const |
| const vector< const Blob * > & | Inputs () const |
| const vector< Blob * > & | Outputs () |
| vector< TensorShape > | InputTensorShapes () |
| void | Wait (const OperatorBase &other, int stream_id=-1) |
| virtual void | Finish () |
| virtual void | AddRelatedBlobInfo (EnforceNotMet *err) |
| const OperatorDef & | debug_def () const |
| void | set_debug_def (const std::shared_ptr< const OperatorDef > &operator_def) |
| bool | has_debug_def () const |
| void | RecordLastFailedOpNetPosition () |
| int | net_position () const |
| void | set_net_position (int idx) |
| const DeviceOption & | device_option () const |
| const Event & | event () const |
| Event & | event () |
| void | ResetEvent () |
| void | DisableEvent () |
| bool | IsEventDisabled () const |
| const std::string & | type () const |
| void | annotate_engine (const std::string &engine) |
| const std::string & | engine () const |
| Public Member Functions inherited from caffe2::Observable< OperatorBase > | |
| const Observer * | AttachObserver (std::unique_ptr< Observer > observer) |
| std::unique_ptr< Observer > | DetachObserver (const Observer *observer_ptr) |
| Returns a unique_ptr to the removed observer. More... | |
| virtual size_t | NumObservers () |
| void | StartAllObservers () |
| void | StopAllObservers () |
Additional Inherited Members | |
| Public Types inherited from caffe2::Observable< OperatorBase > | |
| using | Observer = ObserverBase< OperatorBase > |
| Static Public Member Functions inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| static void | InferOutputSize (vector< TIndex > input_dims, int, StorageOrder order, bool global_pooling, LegacyPadding legacy_pad, int, vector< int > &kernel, vector< int > &output_dims, const vector< int > &dilation, const vector< int > &stride, vector< int > &pads, bool &channel_first) |
| static struct OpSchema::Cost | CostInferenceForConv (const OperatorDef &def, const vector< TensorShape > &inputs) |
| static vector< TensorShape > | TensorInferenceForSchema (const OperatorDef &def, const vector< TensorShape > &in, int output_channel) |
| static vector< TensorShape > | TensorInferenceForConv (const OperatorDef &def, const vector< TensorShape > &in) |
| static vector< TensorShape > | TensorInferenceForPool (const OperatorDef &def, const vector< TensorShape > &in) |
| Data Fields inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| USE_OPERATOR_CONTEXT_FUNCTIONS | |
| Static Public Attributes inherited from caffe2::OperatorBase | |
| static constexpr int | kNoNetPositionSet = -1 |
| Protected Member Functions inherited from caffe2::CudnnConvOpBase | |
| template<typename T > | |
| void | SetTensorNdDescriptorWithGroup (int size, cudnnTensorDescriptor_t tensorDesc, int N, int C, int H, int W, int D) |
| void | DuplicateConvDesc (cudnnConvolutionDescriptor_t input, size_t kernelDims, size_t dilationDims, cudnnConvolutionDescriptor_t copy) |
| template<typename T > | |
| cudnnDataType_t | DetermineComputeTypeFromInput (const T &X) |
| void | SetConvDescFromArguments () |
| void | SetConvDescComputeType (cudnnConvolutionDescriptor_t conv_desc, cudnnDataType_t math) |
| Protected Member Functions inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| int | pad_t () const |
| int | pad_l () const |
| int | pad_b () const |
| int | pad_r () const |
| int | kernel_h () const |
| int | kernel_w () const |
| int | stride_h () const |
| int | stride_w () const |
| int | dilation_h () const |
| int | dilation_w () const |
| Protected Member Functions inherited from caffe2::Operator< CUDAContext > | |
| void | RecordEvent (const char *err_msg=nullptr) final |
| std::string | getErrorMsg () |
| Protected Member Functions inherited from caffe2::OperatorBase | |
| DISABLE_COPY_AND_ASSIGN (OperatorBase) | |
| Static Protected Member Functions inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| static void | ComputeSizeAndPad (const int in_size, const int stride, const int kernel, const int dilation, LegacyPadding legacy_pad, int *pad_head, int *pad_tail, int *out_size) |
| Protected Attributes inherited from caffe2::CudnnConvOpBase | |
| vector< TIndex > | cudnn_input_dims_ |
| vector< TIndex > | cudnn_filter_dims_ |
| CuDNNWrapper | cudnn_wrapper_ |
| cudnnTensorDescriptor_t | bottom_desc_ |
| cudnnFilterDescriptor_t | filter_desc_ |
| cudnnTensorDescriptor_t | bias_desc_ |
| cudnnTensorDescriptor_t | top_desc_ |
| cudnnTensorDescriptor_t | top_desc_for_bias_ |
| cudnnConvolutionDescriptor_t | conv_desc_ |
| const size_t | cudnn_ws_nbytes_limit_ |
| size_t | cudnn_ws_nbytes_ |
| bool | exhaustive_search_ |
| bool | deterministic_ |
| size_t | cudnn_state_ |
| vector< int > | force_algo_ |
| bool | enable_tensor_core_ |
| cudnnDataType_t | compute_type_ |
| Protected Attributes inherited from caffe2::ConvPoolOpBase< CUDAContext > | |
| LegacyPadding | legacy_pad_ |
| bool | global_pooling_ |
| vector< int > | kernel_ |
| vector< int > | dilation_ |
| vector< int > | stride_ |
| vector< int > | pads_ |
| bool | float16_compute_ |
| Tensor< CUDAContext > | kernel_device_ |
| Tensor< CUDAContext > | dilation_device_ |
| Tensor< CUDAContext > | stride_device_ |
| Tensor< CUDAContext > | pads_device_ |
| int | group_ |
| StorageOrder | order_ |
| bool | shared_buffer_ |
| Workspace * | ws_ |
| Protected Attributes inherited from caffe2::Operator< CUDAContext > | |
| CUDAContext | context_ |
| Protected Attributes inherited from caffe2::OperatorBase | |
| std::unique_ptr< Event > | event_ |
| Protected Attributes inherited from caffe2::Observable< OperatorBase > | |
| std::vector< std::unique_ptr< Observer > > | observers_list_ |
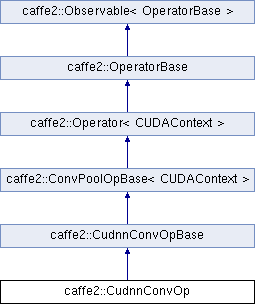
Definition at line 426 of file conv_op_cudnn.cc.
 1.8.11
1.8.11

