“泛型”的字面意思就是广泛的类型。类、接口和方法代码可以应用于非常广泛的类型,代码与它们能够操作的数据类型不再绑定在一起,同一套代码可以用于多种数据类型,这样,不仅可以复用代码,降低耦合,而且可以提高代码的可读性和安全性。在实际开发中,经常会使用到泛型,但语法非常令人费解,而且容易混淆对于其中的一些细节的地方,所以翻书去回顾下。
泛型类
首先看一段简单代码:
public class Pair<T> {
T first;
T second;
public Pair(T first, T second) {
this.first = first;
this.second = second;
}
public T getFirst() {
return first;
}
public T getSecond() {
return second;
}
}
这就是一个简单的泛型类,T 表示类型参数,泛型就是类型参数化,处理的数据类型不是固定的,而是可以作为参数传入。如下代码所示,对于构造方法 Pair(T first, T second) 既可以传 Integer 类型的参数,也可以传 String 类型的参数:
Pair<Integer> minmax = new Pair<Integer>(1,100);
Pair<String> kv = new Pair<String>("name", "老王");
参数类型也可以多种,类 Pair 可以改成如下所示:
public class Pair<U, V> {
U first;
V second;
public Pair(U first, V second) {
this.first = first;
this.second = second;
}
public U getFirst() {
return first;
}
public V getSecond() {
return second;
}
}
这样一来,构造方法 Pair(U first, V second) 就可以接收不同类型的参数了,既可以是 Integer,也可以是 String:
Pair<String> kv = new Pair<String>(1, "老王");
那假如我们不用泛型类,参数类型直接用 Oeject ,其实也可以满足基本的需求,将类 Pair 修改成如下的方式:
public class Pair {
Object first;
Object second;
public Pair(Object first, Object second) {
this.first = first;
this.second = second;
}
public Object getFirst() {
return first;
}
public Object getSecond() {
return second;
}
}
Pair minmax = new Pair(1,100);
Integer min = (Integer)minmax.getFirst();
Integer max = (Integer)minmax.getSecond();
但是这样会有什么坏处呢,假如我们在写代码的时候,不小心把类型弄错,但是编译器在编译的时候是不会有任何问题,在运行时候,就会抛类型转换异常:
Pair minmax = new Pair("王二狗",100);
Integer min = (Integer)minmax.getFirst();//其实这里已经类型转换异常,但是编译器编译的时候不会报错
Integer max = (Integer)minmax.getSecond();
但是如果使用了泛型的话,就可以避免这类错误,在编译期间,编译器就会报错:
Pair<String, Integer> pair = new Pair<>("王二狗",1);
Integer min = minmax.getFirst();//提示编译错误,String 类型,无法转换为 Integer 类型
Integer max = minmax.getSecond();
总结一下就是:Java 泛型是通过擦除实现的,对于泛型类,Java 编译器会将泛型代码转换为普通的非泛型代码,就像上面的普通 Pair 类代码及其使用代码一样,将类型参数 T 擦除,替换为 Object,插入必要的强制类型转换,泛型的两个好处就是:更好的安全性,更好的可读性。
泛型接口
接口也是可以泛型的,比如 Comparator 接口都是泛型的:
public interface Comparator<T> {
int compare(T o1, T o2);
}
那么在实现这两个类的时候,实现方法里面就得指定具体的参数类型:
public class StringComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
// 业务逻辑...
return 0;
}
}
泛型方法
除了泛型类,方法也可以是泛型的,而且,一个方法是不是泛型的,与它所在的类是不是泛型没有什么关系。我们看个例子就知道了:
public static < U, V > Pair<U, V> makePair( U first, V second ){
Pair<U, V> pair = new Pair<>( first, second );
return(pair);
}
参数类型的限定
上界为指定的类
如果没有参数类型的限定,那么类型参数 T 在擦除的时候,只能把它当作 Object,但 Java 支持限定这个参数的一个上界,也就是说,参数必须为给定的上界类型或其子类型,这个限定是通过 extends 关键字来表示的。例如,上面的 Pair 类,可以定义一个子类NumberPair,限定两个类型参数必须为 Number:
public class NumberPair<U extends Number, V extends Number> extends Pair<U, V> {
public NumberPair(U first, V second) {
super(first, second);
}
}
限定类型后,如果类型使用错误,编译器会提示。指定边界后,类型擦除时就不会转换为 Object 了,而是会转换为它的边界类型 Number,这也是容易理解的。
上界为指定的接口
上面看到上界是指定的类,当然了,上界也可以是指定的接口,那么类型 T,就必须实现该上界接口,如下所示:
public static < T extends Comparable<T> > T max( T[] arr ){
T max = arr[0];
for ( int i = 1; i < arr.length; i++ ){
if ( arr[i].compareTo( max ) > 0 ){
max = arr[i];
}
}
return(max);
}
max 方法计算一个泛型数组中的最大值,计算最大值需要进行元素之间的比较,要求元素实现 Comparable 接口,所以给类型参数设置了一个上边界 Comparable, T 必须实现 Comparable 接口。
上界为其他类型
上界类型,除了类、接口,也可以是其他类型,举个例子:
public class DynamicArray<E> {
private static final int DEFAULT_CAPACITY = 10;
private int size;
private Object[] elementData;
public DynamicArray() {
this.elementData = new Object[DEFAULT_CAPACITY];
}
private void ensureCapacity(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity >= minCapacity) {
return;
}
int newCapacity = oldCapacity * 2;
if (newCapacity < minCapacity) {
newCapacity = minCapacity;
}
elementData = Arrays.copyOf(elementData, newCapacity);
}
public void add(E e) {
ensureCapacity(size + 1);
elementData[size++] = e;
}
public E get(int index) {
return (E) elementData[index];
}
public int size() {
return size;
}
public E set(int index, E element) {
E oldValue = get(index);
elementData[index] = element;
return oldValue;
}
}
public class DynamicArray<E> {
public < T extends E > void addAll( DynamicArray<T> c ){
for ( int i = 0; i < c.size; i++ ){
// 业务逻辑...
}
}
}
E 是 DynamicArray 的类型参数,T 是 addAll 的类型参数,T 的上界限定为 E。
解析通配符
有限定通配符
<? extends E> 表示有限定通配符,匹配 E 或 E 的某个子类型,具体什么子类型是未知的,如:
public class DynamicArray<E> {
public < T extends E > void addAll( DynamicArray<T> c ){
for ( int i = 0; i < c.size; i++ ){
// 业务逻辑...
}
}
}
改成有限定通配符方式:
public class DynamicArray<E> {
public void addAll( DynamicArray<? extends E> c ){
for ( int i = 0; i < c.size; i++ ){
// 业务逻辑...
}
}
}
那 <T extends E> 和 <? extends E> 到底有什么关系?
<T extends E> 用于定义类型参数,它声明了一个类型参数T,可放在泛型类定义中类名后面、泛型方法返回值前面。<? extends E> 用于实例化类型参数,它用于实例化泛型变量中的类型参数,只是这个具体类型是未知的,只知道它是E或E的某个子类型。
无限定通配符
形如 DynamicArray<? > ,称为无限定通配符,举个例子,在 DynamicArray 中查找指定的元素:
public static int indexOf(DynamicArray<?> arr, Object elm){
for (int i=0; i<arr.size(); i++){
if(arr.get(i).equals(elm)){
return i;
}
}
return -1;
}
无限定通配符,也可以改成类型参数,如下,两者写法是等价的:
public static <T> int indexOf(DynamicArray<T> arr, Object elm){
for (int i=0; i<arr.size(); i++){
if(arr.get(i).equals(elm)){
return i;
}
}
return -1;
}
但是通配符形式是比较简洁,但是有一个重要的限制:只能读,不能写,如下所示:
DynamicArray<Integer> ints = new DynamicArray<>();
DynamicArray<? extends Number> numbers = ints;
Integer a = 200;
numbers.add(a);//错误!
numbers.add((Number)a);//错误!
numbers.add((Object)a);//错误!
因为 ?问号就是表示类型安全无知, ? extends Number 表示是Number的某个子类型,但不知道具体子类型,如果允许写入,Java 就无法确保类型安全性,所以干脆禁止。现在我们再来看泛型方法到底应该用通配符的形式还是加类型参数。两者到底有什么关系?我们总结如下:
- 通配符形式都可以用类型参数的形式来替代,通配符能做的,用类型参数都能做。
- 通配符形式可以减少类型参数,形式上往往更为简单,可读性也更好,所以,能用通配符的就用通配符。
- 如果类型参数之间有依赖关系,或者返回值依赖类型参数,或者需要写操作,则只能用类型参数。
- 通配符形式和类型参数往往配合使用。
超类型通配符
<? super E> ,称为超类型通配符,表示E的某个父类型,它与 <? extends E> 正好相反,有了它,可以灵活的进行写入。我们给 DynamicArray 添加一个方法,将当前容器中的元素添加到传入的目标容器中:
public void copyTo(DynamicArray<E> dest){
for (int i=0; i<size; i++){
dest.add(get(i));
}
}
DynamicArray<Integer> ints = new DynamicArray<Integer>();
ints.add(100);
ints.add(34);
DynamicArray<Number> numbers = new DynamicArray<Number>();
ints.copyTo(numbers);
Integer 是 Number 的子类,将 Integer 对象拷贝入 Number 容器,这种用法应该是合情合理的,但 Java会 提示编译错误,理由我们之前也说过了,期望的参数类型是 DynamicArray<Number> , DynamicArray<Integer> 并不适用。这里使用超类型通配符就可以解决这个问题:
public void copyTo(DynamicArray<? super E> dest){
for (int i=0; i<size; i++){
dest.add(get(i));
}
}
这样,编译器就不会报错了,所以总结一下:
<? super E> 用于灵活写入或比较,使得对象可以写入父类型的容器,使得父类型的比较方法可以应用于子类对象,它不能被类型参数形式替代。<? > 和 <? extends E> 用于灵活读取,使得方法可以读取E或E的任意子类型的容器对象,它们可以用类型参数的形式替代,但通配符形式更为简洁。
局限性
-
基本类型不能用于实例化类型参数
-
Pair<int> minmax = new Pair<int>(1,100); 是不支持的,解决方法是使用基本类型对应的包装类。
Pair<Integer> minmax = new Pair<Integer>(1,100);
-
运行时类型信息不适用于泛型
Pair<Integer>.class 不支持-
if(p1 instanceof Pair<Integer>) 不支持
if(p1 instanceof Pair<? >) 支持
- 类型擦除可能会引发一些冲突
-
不能通过类型参数创建对象
T elm = new T(); 不支持,但是可以借助反射机制实现:
public static <T> T create(Class<T> type){
try {
return type.newInstance();
}
catch (Exception e) {
return null;
}
}
- 泛型类类型参数不能用于静态变量和方法,如下则是非法的:
public class Singleton<T> {
private static T instance;
public synchronized static T getInstance(){
if(instance==null){
//创建实例
}
return instance;
}
}
- Java 不支持创建泛型数组
-
Java中还支持多个上界,多个上界之间以&分隔,类似这样:
T extends Base & Comparable & Serializable - Base 为上界类,Comparable 和 Serializable 为上界接口。如果有上界类,类应该放在第一个,当类型擦除时,会用第一个上界替换。
]]>

 注: "trade-assets-service" 根据自己目录名变化
注: "trade-assets-service" 根据自己目录名变化











 {:height 321, :width 716}
{:height 321, :width 716}
 {:height 259, :width 716}
{:height 259, :width 716}
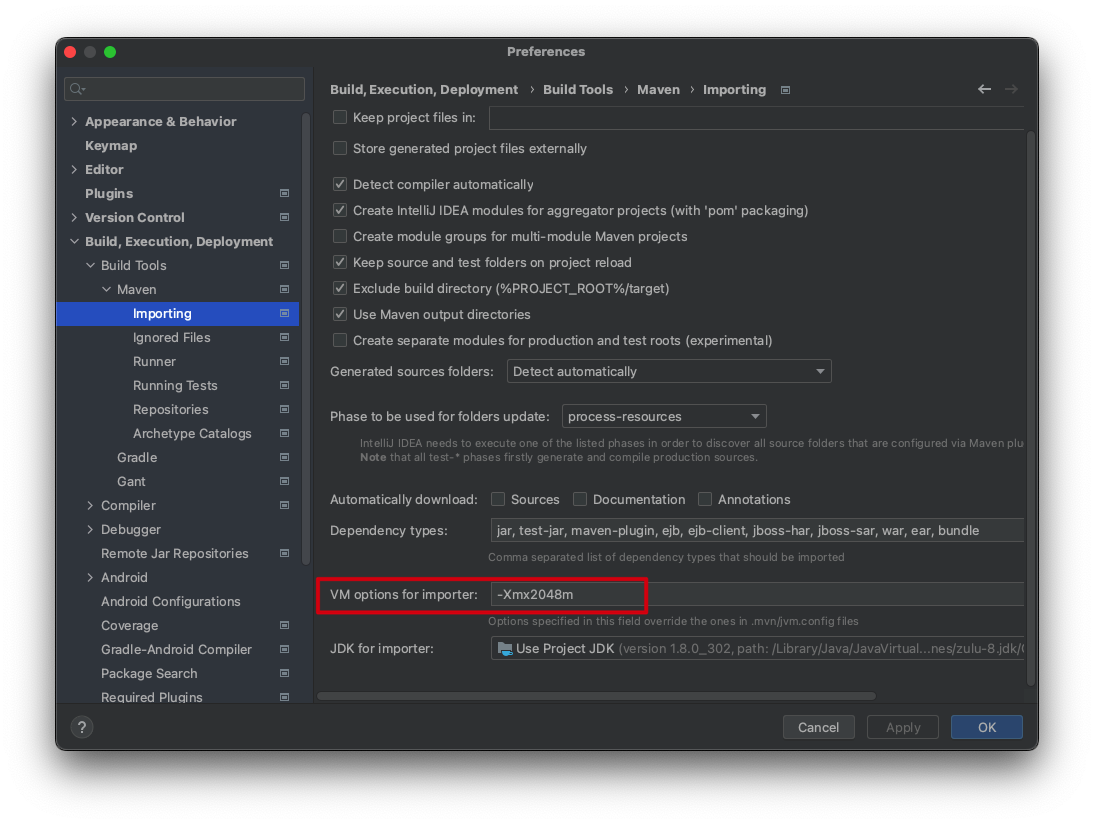
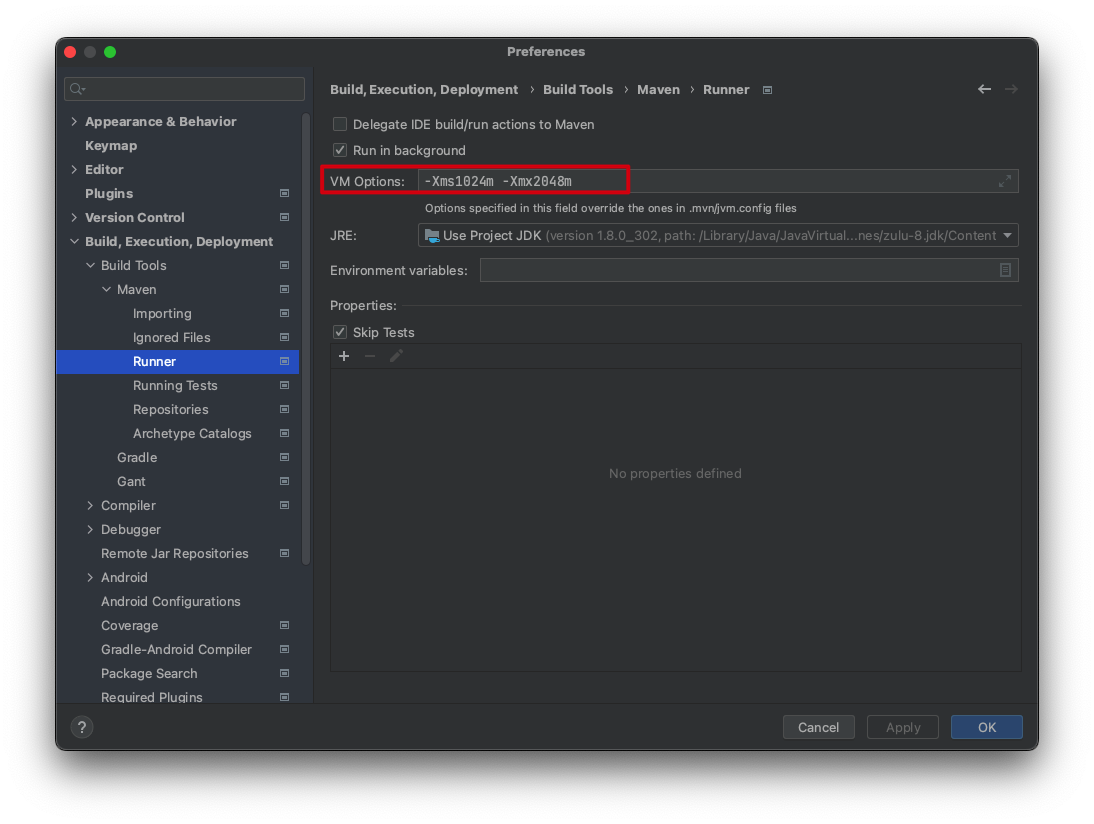 然后重新刷新下,就不会报内存不足了。
然后重新刷新下,就不会报内存不足了。 作者:迈克尔·莫斯
时间:2022-04-02 09:45:26
数量:24个笔记
作者:迈克尔·莫斯
时间:2022-04-02 09:45:26
数量:24个笔记 作者:吉姆·洛尔 托尼·施瓦茨
时间:2022-01-13 17:33:43
数量:14 个笔记
作者:吉姆·洛尔 托尼·施瓦茨
时间:2022-01-13 17:33:43
数量:14 个笔记
















{kind=link}