---
title: Introduction to HPCC Cluster and Linux
author: "Thomas Girke"
date: last-modified
sidebar: tutorials
engine: knitr
---



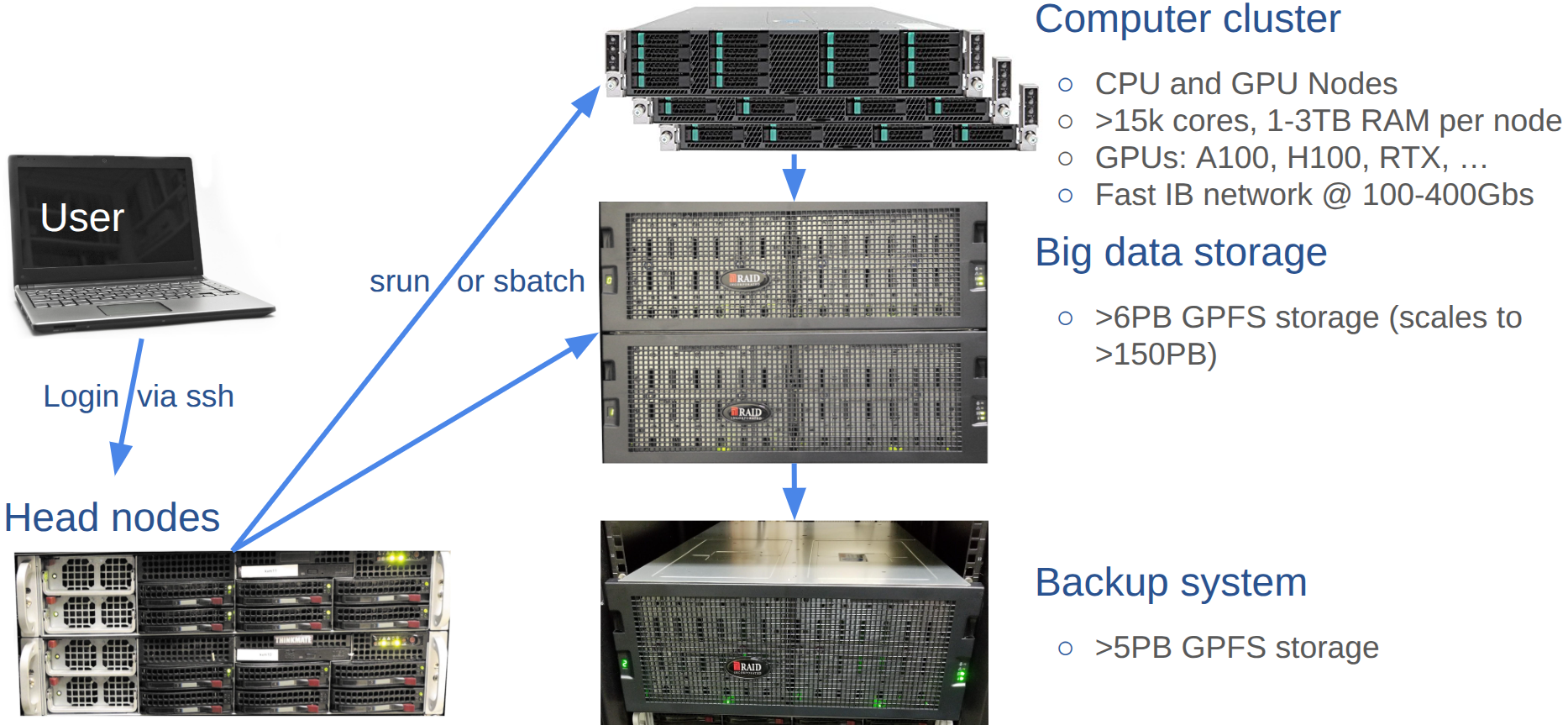
## HPCC Cluster Overview
The HPCC Cluster (formerly called biocluster) is a shared research computing system available at UCR. The HPCC website is available [here](http://hpcc.ucr.edu/index.html).
### What Is a Computer Cluster?
* A computer cluster is an assembly of CPU units, so called computer nodes that work together to perform many computations in parallel. To achieve this, an internal network (e.g. Infiniband interconnect) connects the nodes to a larger unit, while one or more head nodes controls the load and traffic across the entire system.
* Usually, users log into one of the head nodes via `ssh` to submit their computing requests to a queuing system provided by resource management and scheduling software, such as Slurm, SGE, or TORQUE/MAUI. The queuing system distributes the processes to the computer nodes in a controlled fashion.
* Because the head node controls the entire system, users should never run computing jobs on the head node directly!
* For code testing purposes, one can log into one of the nodes via `srun` (see below) and run jobs interactively.
{width=70%}
### Hardware Infrastructure
### Computer nodes
- Over 15,000 CPU cores
- 130 Intel, AMD and GPU nodes
- 32-256 CPU cores per node
- 1-3 TB of RAM per node
- 64 GPUs including NVIDIA K80, P100, RTX, A100 and H100
### Interconnect
- NDR IB 100-400Gbs
### Storage
- Parallel GPFS storage system with 5.0 PB usable space
- File system scales to over 50 PB
- Backup of same architecture and similar amount
### User traffic
- Computing tasks need to be submitted via `sbatch` or `srun`
- HPCC Cluster headnode only for login, not for computing tasks!
- Monitor cluster activity: `squeue` or `jobMonitor` (`qstatMonitor`)
### Manuals
- [HPCC Cluster Manual](https://hpcc.ucr.edu/manuals/hpc_cluster/)
- [Linux Manual](https://hpcc.ucr.edu/manuals/linux_basics/)
## Linux Basics
### Log into HPCC Cluster via SSH Terminal
Terminal-based login is the most feature-rich method for accessing remote Linux systems. Web-based alternatives via [JupyterHub](https://hpcc.ucr.edu/manuals/access/login/#b-web-based-access) and
[RStudio Server](https://hpcc.ucr.edu/manuals/access/login/#b-web-based-access) are also possible. To access the HPCC
cluster with the standard `ssh` protocol, users want to follow steps 1-3. Only
step 1 is required after setting up SSH Key-based access.
__1.__ Type the following `ssh` login command from a terminal application, where `` needs to be replaced by the actual account name of a user. The `<>` characters indicate a placeholder and need to be removed. Next, press enter to execute the `ssh` command.
```bash
ssh -X @cluster.hpcc.ucr.edu
```
After this a user is logged in to one of the headnodes, which are `skylark` or `bluejay`.
The `-X` argument enables X11 support, which is required for opening GUI applications on remote systems.
__2.__ Type your password and hit enter. Note, when typing the password the cursor will not move and nothing is printed to the screen. If SSH Key access is enabled, both the password and Duo steps will be skipped automatically during the log in process.
__3.__ Follow the [Duo multifactor authenication](https://hpcc.ucr.edu/manuals/access/login/#passwordduo) instructions printed to the screen. As external users do not have access to UCR's Duo system, they can only log in via the alternative SSH Key method. How to enable SSH Keys is described [here](https://hpcc.ucr.edu/manuals/access/login/#ssh-keys). Note, Duo will be bypassed if SSH Key based login is enabled. This can be more conveniet than Duo when accessing the cluster frequently.
If the login is performed via a GUI application, which is an option in MobaXterm,
then one can provide the same login information given under the above `ssh`
commad in the corresponding fields of the login window as follows:
+ Host name: `cluster.hpcc.ucr.edu`
+ User name: ...
+ Password: ...
__Importantly__, after the first login into a new account (or a password reset),
users need to change their password with the `passwd` command and then follow
the on-screen instructions. This requires to enter the current password once
and the new password twice. New passwords need to be at least 8 characters
long and meet at least 3 of the following requirments: lowercase character,
uppercase character, number, and punctuation character.
__What to do if password/Duo is not working?__ If this happens then most often the login is blocked because a password was typed too many times incorrectly, or
not changed after the first login (see above). To correct this, please request a password reset by emailing [support@hpcc.ucr.edu](mailto:support@hpcc.ucr.edu).
Remember, password/Duo based access is only possible if a user's UCR NetID matches the corresponding HPCC username. If this is not the case then
UCR users can request to change their HPCC user account name to their NetID or use the [SSH key](https://hpcc.ucr.edu/manuals/access/login/#ssh-keys) based access method.
#### Terminal Options
Various ssh terminal applications are available for all major operating systems. Examples include:
+ macOS: built-in macOS [Terminal](https://support.apple.com/guide/terminal/welcome/mac) or [iTerm2](https://iterm2.com/)
+ Windows: [MobaXterm](http://mobaxterm.mobatek.net/) is a feature rich terminal option for Windows users. [Here](https://mobaxterm.mobatek.net/demo.html) are annimated usage introductions for MobaXterm. Additional useful manuals for MobaXterm are here: [SSH-Key Generation (HPCC Manual)](https://hpcc.ucr.edu/manuals/hpc_cluster/sshkeys/sshkeys_winos/#create-ssh-keys-mobaxterm), [SSH Key Generation (Main MobaXterm Manual)](https://mobaxterm.mobatek.net/documentation.html#6_3) and [Connect to Remote Systems (UNL Manual)](https://hcc.unl.edu/docs/connecting/mobaxterm/).
+ __Install:__ When downloading MobaXterm users want to choose the Installer edition (green button [here](https://mobaxterm.mobatek.net/download-home-edition.html)). This avoids home directory configuration issues and is the recommended option.
+ To find out where MobaXterm stores its files (incl. SSH Keys), type in the MobaXterm terminal `open ~`. This will open a user's home directory in the Windows file browser.
+ Linux: a wide range of Terminal applications is available for Linux. Usually, the default terminal available on a Linux distribution will be sufficient.
+ ChromeOS: after enabling Linux apps on Chromebooks one can use the default terminal that is similar to those on Linux systems.
+ Additional login information can be found on the corresponding HPCC manuals:
+ Login page: [here](https://hpcc.ucr.edu/manuals/hpc_cluster/login/)
+ SSH Keys: [here](https://hpcc.ucr.edu/manuals/access/login/#ssh-keys)
+ Duo Multifactor Authenication: [here](https://hpcc.ucr.edu/manuals/access/login/#passwordduo)
+ UCR Duo Manual: [here](https://its.ucr.edu/sites/g/files/rcwecm321/files/2018-06/Multi-Factor%20Authentication%20Handout.pdf)
#### Remote Graphics Support
X11 support is included in the terminal applications of most OSs. This includes MobaXterm on Windows, Linux and ChromeOS terminals. On macOS systems, users need to run XQuartz
in the background to enable X11 graphics display support. XQuartz can be downloaded from [here](https://www.xquartz.org/) (also see this video [here](https://www.youtube.com/watch?v=uS4zTqfwSSQ)).
Note, XQuartz is optional if remote graphics support is not needed. The next section
covers the XQuartz install.
## Setting Up a Linux Computing Environment on a Laptop
All major operating systems can provide a Linux command-line environment
with minimal setup. Thus, users may want to enable such an environment on their own
laptop or desktop computer (optional for this class).
For the installation users want to follow the instructions under the tab below
that matches their operating system.
::: {.panel-tabset}
## 👆 Select your OS
::: {style="padding: 1em; border: 1px solid #e0e0e0; border-radius: 8px; color: #666;"}
Select the tab above that matches your operating system:
- **Windows** — use MobaXterm to get a Linux-like terminal environment
- **macOS** — use the native Terminal or iTerm2 with Homebrew for package management
- **Linux / ChromeOS** — use your existing terminal and `apt` for package management
With the exception of a terminal app this setup is optional for this class.
:::
## Windows (MobaXterm)
MobaXterm is the recommended terminal environment for Windows users. It
provides a full Linux-like bash shell, built-in SSH client, file browser,
and a package manager — all without requiring a separate Linux installation.
**1. Download and install MobaXterm**
Download the **Installer edition** from
[mobaxterm.mobatek.net](https://mobaxterm.mobatek.net/download.html)
(green button). If your IT department does not allow software installation,
use the Portable edition instead — but make sure to configure a persistent
home directory under `Settings` → `General` → `Persistent home directory`.
**2. Open MobaXterm's local terminal**
Click **Start local terminal** in the MobaXterm home screen. This opens a
bash shell running locally on your Windows machine.
**3. Verify Git is available**
Git is included in MobaXterm's built-in Unix toolkit and should work
immediately:
```{bash}
#| eval: false
git --version
```
If for any reason Git is not found, install it via MobaXterm's package
manager:
```{bash}
#| eval: false
apt-get install git
```
**4. Install additional Unix tools via MobaXterm's package manager**
MobaXterm includes its own `apt-get` for installing additional command-line
tools:
```{bash}
#| eval: false
## Search for a package
apt-get search
## Install a package
apt-get install
## Examples
apt-get install tree
apt-get install wget
```
**5. Configure your Git identity (first time only)**
```{bash}
#| eval: false
git config --global user.name "Your Name"
git config --global user.email "your_github_email@example.com"
```
**Note on WSL:** If you have Windows Subsystem for Linux (WSL) installed on
your machine, your setup will be identical to the **Linux** tab below and
you do not need MobaXterm. WSL provides a full Linux distribution (e.g.
Ubuntu) running natively on Windows and is an excellent alternative for
more advanced users.
## macOS
macOS is Unix-based, so most tools work natively with minimal setup. The
main steps are to install the Xcode command-line tools, Homebrew as a
package manager, and optionally a more feature-rich terminal.
**1. Open Terminal**
The built-in Terminal app is located at:
```
Applications → Utilities → Terminal
```
Alternatively, install **iTerm2** from [iterm2.com](https://iterm2.com) for
a more feature-rich terminal with better split panes, search, and
customization. Both work identically for the purposes of this course.
**2. Install Xcode Command Line Tools**
Xcode provides essential compilers and development tools including Git.
Run the following and follow the on-screen prompts:
```{bash}
#| eval: false
xcode-select --install
```
Verify Git was installed:
```{bash}
#| eval: false
git --version
```
**3. Install Homebrew**
Homebrew is the standard package manager for macOS and allows easy
installation of bioinformatics and command-line tools:
```{bash}
#| eval: false
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
Verify the installation:
```{bash}
#| eval: false
brew --version
```
**4. Install software with Homebrew**
```{bash}
#| eval: false
## Search for a package
brew search
## Install a package
brew install
## Examples
brew install git # install or update Git via Homebrew
brew install wget
brew install tree
## Update all installed packages
brew upgrade
```
**5. Install XQuartz (for graphical applications)**
Some bioinformatics tools require an X11 display server to render graphical
output over SSH. Install XQuartz from
[xquartz.org](https://www.xquartz.org):
```{bash}
#| eval: false
## Or install via Homebrew
brew install --cask xquartz
```
After installation, log out and back in for XQuartz to take effect.
**6. Configure your Git identity (first time only)**
```{bash}
#| eval: false
git config --global user.name "Your Name"
git config --global user.email "your_github_email@example.com"
```
## Linux / ChromeOS
Linux users already have everything they need. The main steps are to verify
the required tools are installed and set up Git.
**1. Open a Terminal**
Most Linux desktop environments provide a terminal via:
- **Ubuntu/Debian:** search for `Terminal` in the application menu, or press `Ctrl+Alt+T`
- **Fedora/RHEL:** search for `Terminal` or `Konsole`
- **ChromeOS:** enable Linux (Crostini) under `Settings` → `Advanced` →
`Developers` → `Linux development environment` → **Turn on**. This installs
a Debian-based Linux container with a full terminal.
**2. Verify Git is installed**
```{bash}
#| eval: false
git --version
```
If not installed:
```{bash}
#| eval: false
## Ubuntu/Debian/ChromeOS
sudo apt-get update
sudo apt-get install git
## Fedora/RHEL
sudo dnf install git
```
**3. Install additional software with apt-get**
```{bash}
#| eval: false
## Search for a package
apt-cache search
## Install a package
sudo apt-get install
## Examples
sudo apt-get install wget
sudo apt-get install tree
sudo apt-get install build-essential # installs compilers and dev tools
## Update all installed packages
sudo apt-get update && sudo apt-get upgrade
```
**4. Install XQuartz / X11 (for graphical applications over SSH)**
To display graphical applications forwarded from HPCC over SSH:
```{bash}
#| eval: false
sudo apt-get install xorg
```
**5. Configure your Git identity (first time only)**
```{bash}
#| eval: false
git config --global user.name "Your Name"
git config --global user.email "your_github_email@example.com"
```
:::
### Important Linux Commands
The following provides a short overview of important shell commands. Much more detailed information can be found on [HPCC's Linux tutorials](https://hpcc.ucr.edu/manuals/linux_basics/).
Finding help
```sh
man
```
List content of directories
```sh
ls
ls -l or ll # includes details about files and directories
ls -al # includes hidden files starting with a dot in their name
ll -d # lists permissions of specfic directory or file
```
Print current working directory
```sh
pwd
pwd -P # returns physical location in case one followed symbolic link
```
Search in files and directories
```sh
grep
```
Word count
```sh
wc
```
Create directory
```sh
mkdir
```
Change directory
```sh
cd # changes pwd to specified path
cd # changes pwd to root of home directory
cd - # switches to previous directory
```
Change directory
```sh
cd
```
Delete files and directories
```sh
rm
```
Move and rename files
```sh
mv
```
Copy files from internet to `pwd`
```sh
wget
```
Viewing files
```sh
less
```
### File Exchange
__GUI applications__
+ Windows: [WinSCP](http://winscp.net/eng/index.php) or [MobaXterm](https://mobaxterm.mobatek.net/features.html)
+ Mac OS X: [CyberDuck](http://cyberduck.en.softonic.com/mac)
+ Win/OS X/Linux: [FileZilla](https://filezilla-project.org/)

![]() Fig 2: FileZilla settings with an SSH key. For generating SSH keys see here.
Fig 2: FileZilla settings with an SSH key. For generating SSH keys see here.
__SCP: via command-line__ ([Manual](https://linux.die.net/man/1/scp))
Advantages of this method include: batch up/downloads and ease of automation.
```sh
scp file user@remotehost:/home/user/ # From local to remote
scp user@remotehost:/home/user/file . # From remote to local
```
__RSYNC: via command-line__ ([Manual](https://linux.die.net/man/1/rsync))
Advantages of this method include: same as SCP plus differential update options and viewing of directory content.
Print (view) content of remote directory
```sh
rsync user@remotehost:~/somedirectory/*
```
Download directory or file(s)
```sh
rsync -avzhe ssh user@remotehost:~/somedirectory .
# -a: recursive archive mode (thus -r not required), also preserves permissions, time stamps, etc
# -v: verbose
# -z: compress data during transfer
# -h: print messages in human-readable format
# -e: specifies transfer protocol; using ssh here provides encryption during transfer
# --delete: files that were deleted on source will be deleted also in backup-destination
# -n: for testing use this dry-run option, but drop '-e ssh' in this case
```
Upload directory or file(s)
```sh
rsync -avzhe ssh somedirectory user@hostname:~/
```
### Check Integrity of Files
To check the integrity of files (_e.g._ after downloading or copying them),
one can use their hash (checksum) values created by `md5sum`. These hash
values are specific to a file and very small in size. If a hash value for a
data file is identical with the hash value of the downloaded copy, then the
downloaded copy is usually identical with the source file. The following routine
assumes that a file named `myfile1.txt` was downloaded along with its
checksum (here `*.md5` created for testing). Next, the checksum values are compared.
```sh
md5sum myfile1.txt # generates checksum
md5sum myfile1.txt > myfile1.md5 # saves checksum to file
```
```
4c1ac93e1be5f77451fa909653b2404c myfile1.txt
```
```sh
md5sum -c myfile1.md5 # checks checksum value
```
```
myfile1.txt: OK
```
### Compare Differences Among Directories
Differences in files and content of two directories can be identified with
the `diff` command. The following also shows how to exclude certain files
in this comparison, here a file called `.git`.
```sh
diff -r --exclude=".git" dir1/ dir2/
```
### STD IN/OUT/ERR, Redirect & Wildcards
Wildcard `*` to specify many files
```sh
file.*
```
Redirect `ls` output to file
```sh
ls > file
```
Specify file as input to command
```sh
command < myfile
```
Append output of command to file
```sh
command >> myfile
```
Pipe `STDOUT` of one command to another command
```sh
command1 | command2
```
Turn off progress info
```sh
command > /dev/null
```
Pipe output of `grep` to `wc`
```sh
grep pattern file | wc
```
Print `STDERR` to file
```sh
grep pattern nonexistingfile 2 > mystderr
```
### Linux Path Notation and Special Characters
The following code box contains frequently used Linux notations. Use the scroll option of the code box to inspect all of them.
```{bash}
#| style: "max-height: 300px; overflow-y: auto;"
#| eval: false
## ~/ : Tilde - shortcut for the current user's home directory
## Expands to /home/ on Linux or /Users/ on macOS
echo ~ # prints your home directory path
ls ~/ # list contents of your home directory
ls ~/.ssh/ # list contents of the .ssh folder in your home directory
## / : Forward slash - root of the entire file system (the top level)
## All absolute paths start from here
ls / # list contents of the root directory
ls /home/ # list all user home directories on the system
## . : Single dot - refers to the current working directory
ls . # list contents of the current directory (same as just 'ls')
./script.sh # execute a script located in the current directory
## Without ./ the shell would not find the script unless it is in PATH
## .. : Double dot - refers to the parent directory (one level up)
ls .. # list contents of the parent directory
cd .. # move up one directory level
cd ../.. # move up two directory levels
## ../ : Double dot with slash - parent directory, used to build relative paths
ls ../data/ # list a 'data' folder that sits one level above current directory
cp ../data/file.txt . # copy file.txt from parent's data/ into current directory
## Absolute vs Relative paths
## Absolute: always starts with / and gives the full path from root
ls /home/username/project/data/
## Relative: starts from wherever you currently are (no leading /)
ls project/data/ # works if you are already in /home/username/
## Practical examples combining these notations
ls -al ~/ # list all files including hidden ones in home directory
cp ~/.ssh/id_rsa.pub . # copy your public SSH key into current directory
mv ./script.sh ../bin/ # move script up one level into a bin/ directory
cat ../../config/settings.txt # read a file two levels up in config/ directory
## Additional special notations
## - : Single dash - refers to the previous directory you were in
cd - # switch back to the last directory you were in
## * : Wildcard - matches any number of any characters in filenames
ls *.sh # list all files ending in .sh in current directory
ls data_*.txt # list all .txt files starting with 'data_'
## ? : Single character wildcard - matches exactly one character
ls file?.txt # matches file1.txt, fileA.txt but not file10.txt
## {} : Brace expansion - generate multiple strings at once
ls file{1,2,3}.txt # expands to: ls file1.txt file2.txt file3.txt
mkdir -p project/{data,code,results} # create three subdirectories at once
```
### Homework Assignment (HW1)
See HW1 page [here](https://girke.bioinformatics.ucr.edu/GEN242/assignments/homework/hw01/hw01.html).
### Permissions and ownership
List directories and files
```sh
ls -al
ls -ld # lists only specified dir/file
```
The previous command shows something like this for each file/dir: `drwxrwxrwx`. The
meaning of this syntax is as follows:
* `d`: directory
* `rwx`: read, write and execute permissions, respectively
* first triplet: user permissions (u)
* second triplet: group permissions (g)
* third triplet: world permissions (o)
Example for assigning write and execute permissions to user, group and world
```sh
chmod ugo+rx my_file
```
* `+` causes the permissions selected to be added
* `-` causes them to be removed
* `=` causes them to be the only permissions that the file has.
When performing the same operation on many files with subdirectories then one can
use `-R` for recursive behavior.
```sh
chmod -R ugo+rx my_dir
```
Since directories have to be executable the capital `X` option can be useful which
applies only to directories but not to files. The following will assign `drwxr-xr-x` to directories
and `-rw-r--r--` to files and hidden files.
```sh
chmod -R ugo-x,u+rwX,go+rX,go-w ./* ./.[!.]*
```
Syntax for changing user & group ownership
```sh
chown :
```
### Symbolic Links
Symbolic links are short nicknames to files and directories that save typing of their full paths.
```sh
ln -s original_filename new_nickname
```
## Software and module system
* Over 2,000 software tools are currently installed on the HPCC Cluster
* Custom installs in user accounts via various mechanisms, e.g. environment management systems such as [conda](https://conda.io/projects/conda/en/latest/index.html)
* Most common research databases used in bioinformatics are available
* Support of most common programming languages used in research computing
* A module system is used to facilitate the management of software tools. This includes any number of versions of each software.
* New software install requests can be sent to support@hpcc.ucr.edu.
* To use software manged under the module system, users need to learn using some basic commands. The most common commands are listed below.
Print available modules
```sh
module avail
```
Print available modules starting with letter 'R'
```sh
module avail R
```
Load default module R
```sh
module load R
```
Unload specific module R
```sh
module unload R/4.2.0
```
Load specific R version
```sh
module unload R/4.1.2
```
List loaded modules
```sh
module list
```
## Installs and package management with Conda:
See [here](https://hpcc.ucr.edu/manuals/hpc_cluster/package_manage/).
## Big data storage
Each user account on HPCC Cluster comes only with 20GB of disk space. Much more disk space is
available in a dedicated `bigdata` directory. How much space depends on the subscription
of each user group. The path of `bigdata` and `bigdata-shared` is as follows:
* `/bigdata/labname/username`
* `/bigdata/labname/shared`
All lab members share the same bigdata pool. The course number `gen242` is used as `labname`
for user accounts adminstered under GEN242 (here /bigdata/gen242/).
The disk usage of `home` and `bigdata` can be monitored on the [HPCC Cluster Dashboard](https://dashboard.hpcc.ucr.edu/).
## Queuing system: `Slurm`
The HPCC cluster uses `Slurm` as queuing and load balancing system. To control user traffic, any
type of compute intensive jobs need to be submitted via `sbatch` or `srun` (see below) to the computer
nodes. Much more detailed information on this topic can be found on these sites:
+ [UCR HPCC Manual](http://hpcc.ucr.edu/manuals_linux-cluster_jobs.html)
+ [Slurm Documentation](https://slurm.schedmd.com/documentation.html)
+ [Torque/Slurm Comparison](http://www.nersc.gov/users/computational-systems/cori/running-jobs/for-edison-users/torque-moab-vs-slurm-comparisons/)
+ [Switching from Torque to Slurm](https://sites.google.com/a/case.edu/hpc-upgraded-cluster/slurm-cluster-commands)
+ [Slurm Quick Start Tutorial](http://www.ceci-hpc.be/slurm_tutorial.html)

![]() Fig 3: Overview of Slurm on HPCC cluster.
### Job submission with `sbatch`
Print information about queues/partitions available on a cluster.
```sh
sinfo
```
Compute jobs are submitted with `sbatch` via a submission script (here `script_name.sh`).
```sh
sbatch script_name.sh
```
The following sample submission script (`script_name.sh`) executes an R script named `my_script.R`.
```sh
#!/bin/bash -l
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem-per-cpu=1G
#SBATCH --time=1-00:15:00 # 1 day and 15 minutes
#SBATCH --mail-user=useremail@address.com
#SBATCH --mail-type=ALL
#SBATCH --job-name="some_test"
#SBATCH --partition="gen242" # Choose alternative partitions from: intel, batch, highmem, gpu, short
#SBATCH --account="gen242" # Same as above
Rscript my_script.R
```
`STDOUT` and `STDERROR` of jobs will be written to files named
`slurm-.out` or to a custom file specified under `#SBATCH --output` in
the submission script.
### Interactive sessions with `srun`
This option logs a user in to a computer node of a specified partition (queue), while Slurm monitors and controls the resource request.
```sh
srun --pty bash -l
```
Interactive session with specific resource requests. Additional information about partitions is [here](https://hpcc.ucr.edu/manuals/hpc_cluster/jobs/).
```sh
srun --x11 --partition=gen242 --account=gen242 --mem=2gb --cpus-per-task 4 --ntasks 1 --time 1:00:00 --pty bash -l
```
The argument `--mem` limits the amount of RAM, `--cpus` the number of CPU
cores, `--time` the time how long a session will be active. Under
`--parition` one can choose among different queues and node architectures.
Current options under `--partition` for most users of the HPCC cluster are: `intel`, `batch`, `highmem`, `gpu`,
and `short`. The latter has a time limit of 2 hours. Note, `--x11` will only work when logged in with X11 support.
This requires the `-X` argument when logging in via `ssh` (see above). On macOS systems X11 support is provided
by [XQuartz](https://www.xquartz.org/) which needs to be installed and running on a system prior to loging in to
a remote system. If X11 support is not available or broken then one can still connect via `srun` by dropping the
`--x11` argument form the `srun` command.
To run your most frequently used `srun` command quickly, one can place the following line
in a user's `~/.bashrc` file. After the next login or sourcing the `.bashrc` file, one can
execute the command with its alias, here: `srun_gen242`. In this case `echo` is used to print the command to the screen rather
than executing it right away. This way one can copy and paste it, make changes as needed and
then execute it.
```sh
alias srun_gen242='echo "srun --x11 --partition=gen242 --account=gen242 --mem=20gb --cpus-per-task 8 --ntasks 1 --time 20:00:00 --pty bash -l"'
```
### Monitoring jobs with `squeue`
List all jobs in queue
```sh
squeue
```
List jobs of a specific user
```sh
squeue -u
```
Print more detailed information about a job
```sh
scontrol show job
scontrol show jobid -dd
```
Custom command to summarize and visualize cluster activity
```sh
jobMonitor
```
### Deleting and altering jobs
Delete a single job
```sh
scancel -i
```
Delete all jobs of a user
```sh
scancel -u
```
Delete all jobs of a certain name
```sh
scancel --name
```
Altering jobs with `scontrol update`. The below example changes the walltime (``) of a specific job (``).
```sh
scontrol update jobid= TimeLimit=
```
### Resource limits
Resourse limits for users can be viewed as follows.
```sh
sacctmgr show account $GROUP format=Account,User,Partition,GrpCPUs,GrpMem,GrpNodes --ass | grep $USER
```
Similarly, one can view the limits of the group a user belongs to.
```sh
sacctmgr show account $GROUP format=Account,User,Partition,GrpCPUs,GrpMem,GrpNodes,GrpTRES%30 --ass | head -3
```
## Code editors and IDEs
The following list includes examples of several widely used code editors.
* __Vi/Vim/Neovim__: Non-graphical (terminal-based) editor. Vi is guaranteed to be available on any system. Vim and Nvim (Neovim) are the improved versions of vi.
* __Emacs__: Non-graphical or window-based editor. You still need to know keystroke commands to use it. Installed on all Linux distributions and on most other Unix systems.
* __VS Code__: Widely used code editor developed by Microsoft. Provides wide range of functionalities.
* __Pico__: Simple terminal-based editor available on most versions of Unix. Uses keystroke commands, but they are listed in logical fashion at bottom of screen.
* __Nano__: A simple terminal-based editor which is default on modern Debian systems.
### Why use a terminal-based environment on HPC?
HPCC provides several excellent web-based GUI environments via
[OnDemand](https://hpcc.ucr.edu/manuals/hpc_cluster/selected_software/ondemand/)
including RStudio Server (Posit), VS Code, JupyterHub, and Matlab. These
run directly on compute nodes through Slurm and are great for interactive
data exploration and visualization.
nvim-R-Tmux complements rather than replaces these tools. The two approaches
serve different purposes and are often used together in the same workflow:
**Key differences**
| | nvim-R-Tmux | OnDemand (RStudio, VS Code, Jupyter) |
|---|---|---|
| Access | Any SSH terminal | Browser (available anywhere) |
| Availability | Any Linux system | Only where OnDemand (or alternative web instance) is deployed |
| Resource needed | Login node (no Slurm required) or compute node | Slurm compute node allocation usually required |
| Languages | R, Python, Bash, and more | Tool-specific (RStudio=R, Jupyter=Python/R, MATLAB) |
| Install overhead | Minimal (config files only) | Server-side setup required |
| Bandwidth | Minimal (text only) | Higher (browser-based) |
A typical HPC workflow combines both: use nvim-R-Tmux as the persistent
backbone for writing code, submitting and monitoring Slurm jobs, and quick
interactive R/Python work on the login node; switch to OnDemand RStudio or
JupyterHub when you need interactive visualization on a compute node.
The core advantage of nvim-R-Tmux for HPC work is robustness — a tmux
session on the login node persists indefinitely regardless of network
interruptions, VPN drops, or closing your laptop. Your R session, open
files, and command history are exactly where you left them when you
reconnect.
### Basic usage of nvim (vim)
The following opens a file (here `myfile`) with nvim (or vim)
```sh
nvim myfile.txt # for neovim (or 'vim myfile.txt' for vim)
```
Once you are in Nvim, there are three main modes: normal, insert and command mode (visual mode included here). The most important commands for switching between the three modes are:
* `i`: The `i` key brings you from the normal mode to the insert mode. The latter is used for typing.
* `Esc`: The `Esc` key brings you from the insert mode back to the normal mode.
* `:`: The `:` key starts the command mode at the bottom of the screen.
Use the arrow keys to move your cursor in the text. Using `Fn Up/Down key` allows to page through
the text quicker. In the following command overview, all commands starting with `:` need to be typed in the command mode.
All other commands are typed in the normal mode after pushing the `Esc` key.
Important modifier keys to control vim/nvim
* `:w`: save changes to file. If you are in editing mode you have to hit `Esc` first.
* `:q`: quit file that has not been changed
* `:wq`: save and quit file
* `:!q`: quit file without saving any changes
### Useful resources for learning vim/nvim
* [Interactive Vim Tutorial](http://www.openvim.com)
* [Official Neovim Documentation](https://neovim.io/doc/)
* [HPCC Vim/Nvim Overview](https://hpcc.ucr.edu/manuals/hpc_cluster/terminalide/#vimnvim-overview)
* [HPCC Linux Manual (old)](http://hpcc.ucr.edu/manuals_linux-basics_vim.html)
## nvim-R-Tmux Essentials
Terminal-based Working Environment for R, Python and Bash:
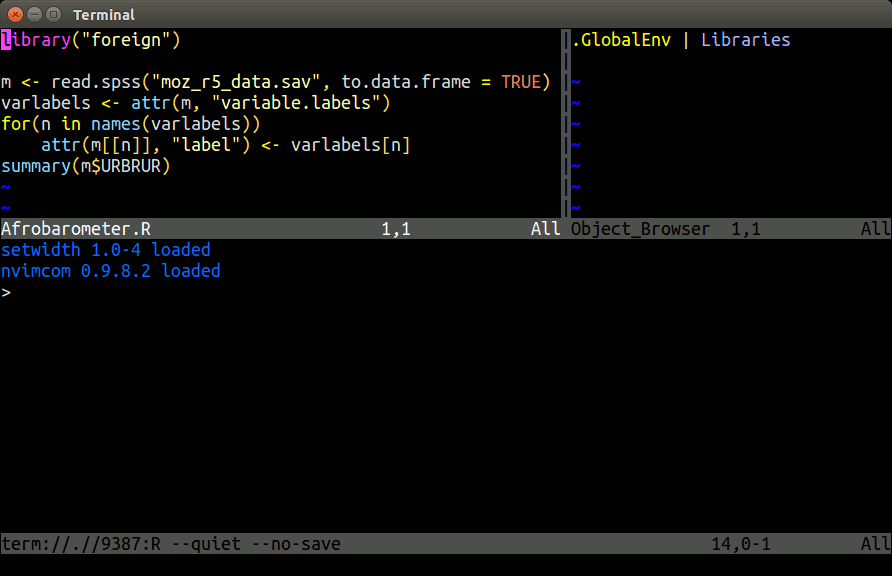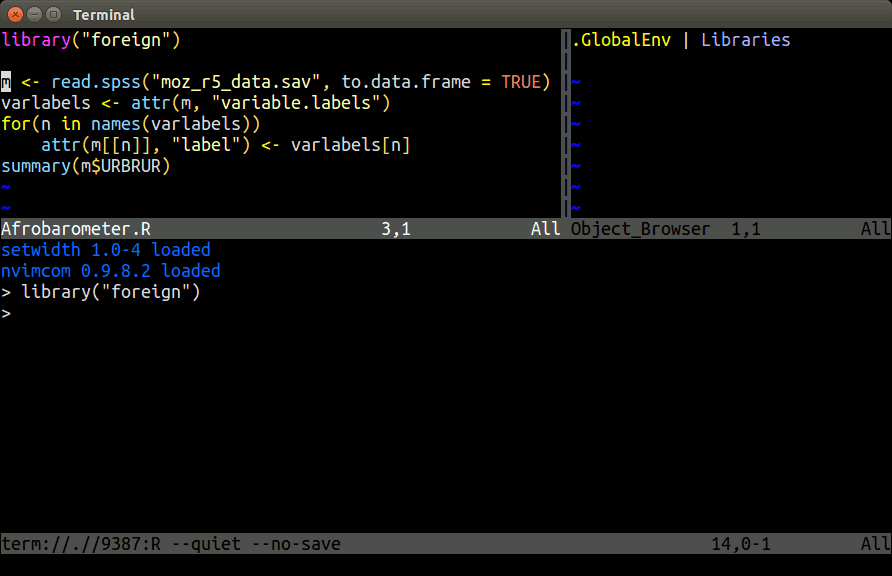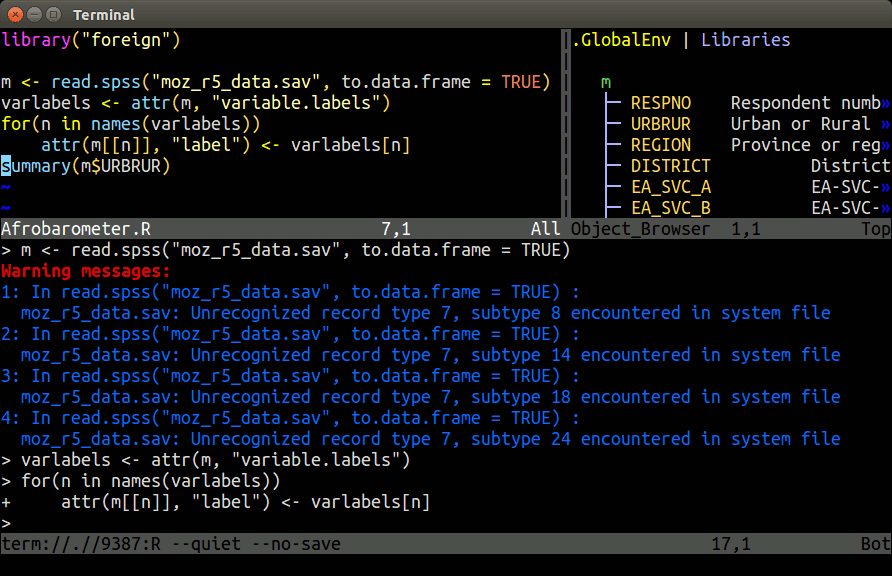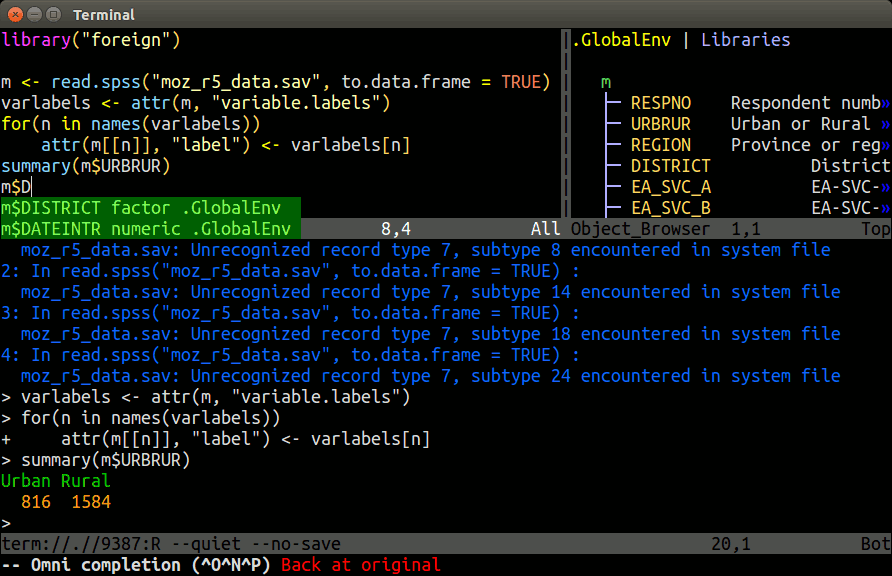{fig-align="center" width=80%}.
### Basics
[Tmux](https://github.com/tmux/tmux) is a terminal multiplexer that allows splitting a single terminal window
into multiple panes and detaching/reattaching to existing terminal sessions —
making it possible to run an interactive R or Python console alongside your
script editor without needing a graphical interface. Combined with the [R.nvim](https://github.com/R-nvim/R.nvim)
plugin, it provides a powerful command-line working environment for R where
users can send code directly from a script to a live R console. The [hlterm](https://github.com/jalvesaq/hlterm)
plugin provides the same functionality for Python and Bash scripts. Together,
these tools replicate the interactive "script + console" workflow found in
desktop IDEs like RStudio, but entirely within the terminal — which is
especially useful on remote systems like HPCC Cluster where graphical
applications may be unavailable or impractical. All three tools need to be
installed on a system. On HPCC Cluster they can be configured in each user
account by following the instructions below.
### Quick configuration on UCR's HPCC
Skip these steps if nvim-R-Tmux is already configured in your account. Or
follow the [detailed step-wise install
instructions](https://github.com/tgirke/nvim-R-Tmux#step-wise-install)
to install nvim-R-Tmux from scratch on your own system (e.g. laptop).
1. Log in to your user account on HPCC and clone the repository:
```bash
git clone https://github.com/tgirke/nvim-R-Tmux.git
cd nvim-R-Tmux
module load neovim/0.11.4 tmux R && bash install_nvim_r_tmux.sh
# bash install_nvim_r_tmux.sh # when installing on your local computer, omit the previous line and run this command instead
```
2. Install plugins on first launch. This must be done on the **login node**:
```bash
nvim # wait until plugin install finishes
:Lazy sync # run under command mode in nvim
:qa # closes nvim
```
3. Log in to a compute node with `srun` and follow the usage instructions in the next section.
```bash
srun --partition=short --mem=2gb --cpus-per-task 4 --ntasks 1 --time 1:00:00 --pty bash -l
```
### Basic usage of nvim-R-Tmux
The official and much more detailed user manual for R.nvim is available
[here](https://github.com/R-nvim/R.nvim/blob/main/doc/R.nvim.txt). The
following gives a short introduction into the basic usage of nvim-R-Tmux.
A short overview of the typical usage routine on an HPC system is on this [slide](https://docs.google.com/presentation/d/1AYVON1pS-vBe5NLp89L2HMBZZjr6L-Z20zN6ZG9r7L0/edit#slide=id.p):
**1. Start tmux session**
Running Nvim from within a tmux session is strongly recommended for remote
work on HPCC — it allows re-attaching to sessions after disconnects. When
using tmux it is important to remember on which head node it was started (on
HPCC: `skylark` or `bluejay`), since it can only be restarted from the same
head node.
```bash
tmux a # starts a new tmux session with default layout or re-attaches to existing session
```
The default session opens five named windows that can be changed in a user's `~/.tmux.conf` file.
Switch between windows with `Ctrl-a 1` through `Ctrl-a 5`.
**2. Open nvim-connected R session**
Open an `*.R`, `*.Rmd` or `*.qmd` file with `nvim` and initialize a connected R session
with `\rf`. The resulting split window between Nvim and R behaves like a split
viewport in nvim, meaning `Ctrl-w w` followed by `i` and `Esc` is important
for navigation between panes. The same can be achieved with mouse clicks if
mouse support is enabled.
```bash
nvim myscript.R # open an R script (or *.Rmd / *.qmd file)
```
Then inside nvim press `\rf` to start the connected R session. The first time
an R script is opened it is best to do this on a compute node (log in with `srun`)
since it will create the omni completion database which can take some time on a compute
system with hundreds of installed packages (over 1,500 on HPCC cluster). Also, if there any messages
appearing during the first session, just confirm them with `Enter`.
**3. Send R code from nvim to the R pane**
Single lines of code can be sent from nvim to the R console by pressing
`Enter` in normal mode. Entire code chunks from `Rmd` and `qmd` can be sent with
`\cc`. To send a custom selection of several lines at once, select them in nvim's
visual mode (press `v` to start selection) and then press `Enter`. The default
keybinding for sending code in R.nvim is `\l` — this has been remapped in the
provided `init.lua` to `Enter` for consistency with other editors.
### Important keybindings for nvim
The following lists important keybindings. It uses the
following syntax: Keys connected with `-` need to be pressed simultaneously,
e.g. `Ctrl-w`. Any key after that (space separated) needs to be pressed after
releasing the combined keys. So `Ctrl-w w` means: press `Ctrl` and `w`
simultaneously, release both, then press `w`.
**Modes**
| Key | Action |
|-----|--------|
| `i` | enter insert mode (for typing) |
| `Esc` | return to normal mode |
| `:` | enter command mode |
**R.nvim commands** (in `.R` / `.Rmd` / `.qmd` files)
| Key / Command | Action |
|---------------|--------|
| `\rf` | open connected R session |
| `Enter` | send current line to R (normal mode) |
| `Enter` | send selection to R (visual mode) |
| `\fc` | send current function to R |
| `\cc` | send current chunk (Rmd/Quarto) |
| `\ch` | send all chunks above cursor |
| `\rh` | open R help for word under cursor |
| `\ro` | toggle object browser |
| `\rv` | view data frame under cursor with [VisiData](https://www.visidata.org/) |
| `:RMapsDesc` | list all R.nvim keybindings |
| `:RConfigShow` | show current R.nvim config |
**Viewport and split commands**
| Key / Command | Action |
|---------------|--------|
| `:split` or `:vsplit` | split viewport horizontally or vertically |
| `gz` | maximize size of viewport in normal mode |
| `Ctrl-w w` | jump cursor between splits |
| `Ctrl-w r` | swap viewports |
| `Ctrl-w =` | resize splits to equal size |
| `Ctrl-w H` or `Ctrl-w K` | toggle between horizontal/vertical split |
| `Ctrl-h/j/k/l` | jump to split in that direction |
| `Esc` | exit terminal insert mode |
| `Space-m` | quick toggle mouse on/off |
| `:set mouse=a` or `n` | alternative mouse on/off with `-n` or `-n` |
| `Space-i` | toggle indent lines on/off |
| `Space-md` | toggle markdown view on/off |
**Search and edit**
| Key / Command | Action |
|---------------|--------|
| `/` or `?` | search forward or backward |
| `:%s/search/replace/cg` | find and replace (with confirmation) |
| `:%s/\s\+$//` | remove trailing whitespace |
| `yy`, `dd`, `p` | copy, cut, paste current line |
| `:set spell` / `:set nospell` | toggle spell checking |
| `z=` | spelling suggestions for word under cursor |
**Completion and help**
| Key / Command | Action |
|---------------|--------|
| `Ctrl-Space` | omni completion for R objects/functions (insert mode) |
| `:h r-nvim` | open R.nvim user manual |
| `:Rhelp fct_name` | open help for a function with tab completion |
**Other useful commands**
| Key / Command | Action |
|---------------|--------|
| `:set tabstop=20` | table viewing with aligned columns |
### File browser: neo-tree
[neo-tree](https://github.com/nvim-neo-tree/neo-tree.nvim) provides file
browser functionality for Neovim, replacing the older NERDTree plugin. To
open the file browser, press `zz` in normal mode, and to close it, press `q`.
| Key | Action |
|-----|--------|
| `zz` | open file browser |
| `q` | close file browser |
| `Enter` | open selected file |
| `a` | create new file or directory |
| `s` | open file with vertical split |
| `S` | open file with horizontal split |
| `H` | toggle hidden files on/off |
| `?` | open neo-tree help |
| `Ctrl-w w` | jump cursor back to editor |
Hidden files (dotfiles) are not shown by default. Press `H` to toggle them.
### nvim IDEs for Python and Bash
For languages other than R, the
[hlterm](https://github.com/jalvesaq/hlterm) plugin provides REPL
integration for Neovim. It is the modern replacement for the older
`vimcmdline` plugin and is written by the same author as R.nvim (Jakson
Alves de Aquino). Supported languages include Python, Bash/Shell, Julia,
JavaScript, and many others.
The usage is very similar to R.nvim. Open a Python or Bash script with nvim,
start the interpreter with `\s`, and send lines with `Enter`:
```bash
nvim myscript.py # open Python script
nvim myscript.sh # open Bash script
```
| Key | Action |
|-----|--------|
| `\s` | start interpreter (Python or Bash) |
| `Enter` | send current line (normal mode) |
| `Enter` | send selection (visual mode) |
The `Enter` keybinding is buffer-local — R files use R.nvim's Enter and
Python/Bash files use hlterm's Enter without any conflict.
### Important keybindings for tmux
**Prefix key: `Ctrl-a`** (hold Ctrl and press a, release both, then press
the next key)
**Pane-level commands**
| Key | Action |
|-----|--------|
| `Ctrl-a \|` | split pane vertically |
| `Ctrl-a -` | split pane horizontally |
| `Ctrl-a` + arrow | move between panes |
| `Alt` + arrow | resize pane (no prefix needed) |
| `Ctrl-a z` | zoom/unzoom active pane (maximize) |
| `Ctrl-a o` | rotate pane arrangement |
| `Ctrl-a x` | close current pane |
| `Ctrl-a m` | toggle mouse on/off |
**Window-level commands**
| Key | Action |
|-----|--------|
| `Ctrl-a c` | create new window |
| `Ctrl-a n` / `Ctrl-a p` | next / previous window |
| `Ctrl-a 1`…`5` | jump to window by number |
| `Ctrl-a ,` | rename current window |
**Session-level commands**
| Key / Command | Action |
|---------------|--------|
| `Ctrl-a d` | detach from current session |
| `Ctrl-a s` | switch between sessions |
| `tmux` | start new session with default layout |
| `tmux a` | reattach to existing session |
| `tmux new -s NAME` | start new named session |
| `tmux a -t NAME` | reattach to named session |
| `tmux ls` | list active sessions |
| `Ctrl-a : kill-session` | kill current session |
| `Ctrl-a r` | reload tmux config |
Mouse support is enabled by default. Use `Ctrl-a m` to toggle it off when
you need to select text for terminal copy/paste. On most terminals,
`Shift+click` selects text even when mouse support is active.
Fig 3: Overview of Slurm on HPCC cluster.
### Job submission with `sbatch`
Print information about queues/partitions available on a cluster.
```sh
sinfo
```
Compute jobs are submitted with `sbatch` via a submission script (here `script_name.sh`).
```sh
sbatch script_name.sh
```
The following sample submission script (`script_name.sh`) executes an R script named `my_script.R`.
```sh
#!/bin/bash -l
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem-per-cpu=1G
#SBATCH --time=1-00:15:00 # 1 day and 15 minutes
#SBATCH --mail-user=useremail@address.com
#SBATCH --mail-type=ALL
#SBATCH --job-name="some_test"
#SBATCH --partition="gen242" # Choose alternative partitions from: intel, batch, highmem, gpu, short
#SBATCH --account="gen242" # Same as above
Rscript my_script.R
```
`STDOUT` and `STDERROR` of jobs will be written to files named
`slurm-.out` or to a custom file specified under `#SBATCH --output` in
the submission script.
### Interactive sessions with `srun`
This option logs a user in to a computer node of a specified partition (queue), while Slurm monitors and controls the resource request.
```sh
srun --pty bash -l
```
Interactive session with specific resource requests. Additional information about partitions is [here](https://hpcc.ucr.edu/manuals/hpc_cluster/jobs/).
```sh
srun --x11 --partition=gen242 --account=gen242 --mem=2gb --cpus-per-task 4 --ntasks 1 --time 1:00:00 --pty bash -l
```
The argument `--mem` limits the amount of RAM, `--cpus` the number of CPU
cores, `--time` the time how long a session will be active. Under
`--parition` one can choose among different queues and node architectures.
Current options under `--partition` for most users of the HPCC cluster are: `intel`, `batch`, `highmem`, `gpu`,
and `short`. The latter has a time limit of 2 hours. Note, `--x11` will only work when logged in with X11 support.
This requires the `-X` argument when logging in via `ssh` (see above). On macOS systems X11 support is provided
by [XQuartz](https://www.xquartz.org/) which needs to be installed and running on a system prior to loging in to
a remote system. If X11 support is not available or broken then one can still connect via `srun` by dropping the
`--x11` argument form the `srun` command.
To run your most frequently used `srun` command quickly, one can place the following line
in a user's `~/.bashrc` file. After the next login or sourcing the `.bashrc` file, one can
execute the command with its alias, here: `srun_gen242`. In this case `echo` is used to print the command to the screen rather
than executing it right away. This way one can copy and paste it, make changes as needed and
then execute it.
```sh
alias srun_gen242='echo "srun --x11 --partition=gen242 --account=gen242 --mem=20gb --cpus-per-task 8 --ntasks 1 --time 20:00:00 --pty bash -l"'
```
### Monitoring jobs with `squeue`
List all jobs in queue
```sh
squeue
```
List jobs of a specific user
```sh
squeue -u
```
Print more detailed information about a job
```sh
scontrol show job
scontrol show jobid -dd
```
Custom command to summarize and visualize cluster activity
```sh
jobMonitor
```
### Deleting and altering jobs
Delete a single job
```sh
scancel -i
```
Delete all jobs of a user
```sh
scancel -u
```
Delete all jobs of a certain name
```sh
scancel --name
```
Altering jobs with `scontrol update`. The below example changes the walltime (``) of a specific job (``).
```sh
scontrol update jobid= TimeLimit=
```
### Resource limits
Resourse limits for users can be viewed as follows.
```sh
sacctmgr show account $GROUP format=Account,User,Partition,GrpCPUs,GrpMem,GrpNodes --ass | grep $USER
```
Similarly, one can view the limits of the group a user belongs to.
```sh
sacctmgr show account $GROUP format=Account,User,Partition,GrpCPUs,GrpMem,GrpNodes,GrpTRES%30 --ass | head -3
```
## Code editors and IDEs
The following list includes examples of several widely used code editors.
* __Vi/Vim/Neovim__: Non-graphical (terminal-based) editor. Vi is guaranteed to be available on any system. Vim and Nvim (Neovim) are the improved versions of vi.
* __Emacs__: Non-graphical or window-based editor. You still need to know keystroke commands to use it. Installed on all Linux distributions and on most other Unix systems.
* __VS Code__: Widely used code editor developed by Microsoft. Provides wide range of functionalities.
* __Pico__: Simple terminal-based editor available on most versions of Unix. Uses keystroke commands, but they are listed in logical fashion at bottom of screen.
* __Nano__: A simple terminal-based editor which is default on modern Debian systems.
### Why use a terminal-based environment on HPC?
HPCC provides several excellent web-based GUI environments via
[OnDemand](https://hpcc.ucr.edu/manuals/hpc_cluster/selected_software/ondemand/)
including RStudio Server (Posit), VS Code, JupyterHub, and Matlab. These
run directly on compute nodes through Slurm and are great for interactive
data exploration and visualization.
nvim-R-Tmux complements rather than replaces these tools. The two approaches
serve different purposes and are often used together in the same workflow:
**Key differences**
| | nvim-R-Tmux | OnDemand (RStudio, VS Code, Jupyter) |
|---|---|---|
| Access | Any SSH terminal | Browser (available anywhere) |
| Availability | Any Linux system | Only where OnDemand (or alternative web instance) is deployed |
| Resource needed | Login node (no Slurm required) or compute node | Slurm compute node allocation usually required |
| Languages | R, Python, Bash, and more | Tool-specific (RStudio=R, Jupyter=Python/R, MATLAB) |
| Install overhead | Minimal (config files only) | Server-side setup required |
| Bandwidth | Minimal (text only) | Higher (browser-based) |
A typical HPC workflow combines both: use nvim-R-Tmux as the persistent
backbone for writing code, submitting and monitoring Slurm jobs, and quick
interactive R/Python work on the login node; switch to OnDemand RStudio or
JupyterHub when you need interactive visualization on a compute node.
The core advantage of nvim-R-Tmux for HPC work is robustness — a tmux
session on the login node persists indefinitely regardless of network
interruptions, VPN drops, or closing your laptop. Your R session, open
files, and command history are exactly where you left them when you
reconnect.
### Basic usage of nvim (vim)
The following opens a file (here `myfile`) with nvim (or vim)
```sh
nvim myfile.txt # for neovim (or 'vim myfile.txt' for vim)
```
Once you are in Nvim, there are three main modes: normal, insert and command mode (visual mode included here). The most important commands for switching between the three modes are:
* `i`: The `i` key brings you from the normal mode to the insert mode. The latter is used for typing.
* `Esc`: The `Esc` key brings you from the insert mode back to the normal mode.
* `:`: The `:` key starts the command mode at the bottom of the screen.
Use the arrow keys to move your cursor in the text. Using `Fn Up/Down key` allows to page through
the text quicker. In the following command overview, all commands starting with `:` need to be typed in the command mode.
All other commands are typed in the normal mode after pushing the `Esc` key.
Important modifier keys to control vim/nvim
* `:w`: save changes to file. If you are in editing mode you have to hit `Esc` first.
* `:q`: quit file that has not been changed
* `:wq`: save and quit file
* `:!q`: quit file without saving any changes
### Useful resources for learning vim/nvim
* [Interactive Vim Tutorial](http://www.openvim.com)
* [Official Neovim Documentation](https://neovim.io/doc/)
* [HPCC Vim/Nvim Overview](https://hpcc.ucr.edu/manuals/hpc_cluster/terminalide/#vimnvim-overview)
* [HPCC Linux Manual (old)](http://hpcc.ucr.edu/manuals_linux-basics_vim.html)
## nvim-R-Tmux Essentials
Terminal-based Working Environment for R, Python and Bash:
{fig-align="center" width=80%}.
### Basics
[Tmux](https://github.com/tmux/tmux) is a terminal multiplexer that allows splitting a single terminal window
into multiple panes and detaching/reattaching to existing terminal sessions —
making it possible to run an interactive R or Python console alongside your
script editor without needing a graphical interface. Combined with the [R.nvim](https://github.com/R-nvim/R.nvim)
plugin, it provides a powerful command-line working environment for R where
users can send code directly from a script to a live R console. The [hlterm](https://github.com/jalvesaq/hlterm)
plugin provides the same functionality for Python and Bash scripts. Together,
these tools replicate the interactive "script + console" workflow found in
desktop IDEs like RStudio, but entirely within the terminal — which is
especially useful on remote systems like HPCC Cluster where graphical
applications may be unavailable or impractical. All three tools need to be
installed on a system. On HPCC Cluster they can be configured in each user
account by following the instructions below.
### Quick configuration on UCR's HPCC
Skip these steps if nvim-R-Tmux is already configured in your account. Or
follow the [detailed step-wise install
instructions](https://github.com/tgirke/nvim-R-Tmux#step-wise-install)
to install nvim-R-Tmux from scratch on your own system (e.g. laptop).
1. Log in to your user account on HPCC and clone the repository:
```bash
git clone https://github.com/tgirke/nvim-R-Tmux.git
cd nvim-R-Tmux
module load neovim/0.11.4 tmux R && bash install_nvim_r_tmux.sh
# bash install_nvim_r_tmux.sh # when installing on your local computer, omit the previous line and run this command instead
```
2. Install plugins on first launch. This must be done on the **login node**:
```bash
nvim # wait until plugin install finishes
:Lazy sync # run under command mode in nvim
:qa # closes nvim
```
3. Log in to a compute node with `srun` and follow the usage instructions in the next section.
```bash
srun --partition=short --mem=2gb --cpus-per-task 4 --ntasks 1 --time 1:00:00 --pty bash -l
```
### Basic usage of nvim-R-Tmux
The official and much more detailed user manual for R.nvim is available
[here](https://github.com/R-nvim/R.nvim/blob/main/doc/R.nvim.txt). The
following gives a short introduction into the basic usage of nvim-R-Tmux.
A short overview of the typical usage routine on an HPC system is on this [slide](https://docs.google.com/presentation/d/1AYVON1pS-vBe5NLp89L2HMBZZjr6L-Z20zN6ZG9r7L0/edit#slide=id.p):
**1. Start tmux session**
Running Nvim from within a tmux session is strongly recommended for remote
work on HPCC — it allows re-attaching to sessions after disconnects. When
using tmux it is important to remember on which head node it was started (on
HPCC: `skylark` or `bluejay`), since it can only be restarted from the same
head node.
```bash
tmux a # starts a new tmux session with default layout or re-attaches to existing session
```
The default session opens five named windows that can be changed in a user's `~/.tmux.conf` file.
Switch between windows with `Ctrl-a 1` through `Ctrl-a 5`.
**2. Open nvim-connected R session**
Open an `*.R`, `*.Rmd` or `*.qmd` file with `nvim` and initialize a connected R session
with `\rf`. The resulting split window between Nvim and R behaves like a split
viewport in nvim, meaning `Ctrl-w w` followed by `i` and `Esc` is important
for navigation between panes. The same can be achieved with mouse clicks if
mouse support is enabled.
```bash
nvim myscript.R # open an R script (or *.Rmd / *.qmd file)
```
Then inside nvim press `\rf` to start the connected R session. The first time
an R script is opened it is best to do this on a compute node (log in with `srun`)
since it will create the omni completion database which can take some time on a compute
system with hundreds of installed packages (over 1,500 on HPCC cluster). Also, if there any messages
appearing during the first session, just confirm them with `Enter`.
**3. Send R code from nvim to the R pane**
Single lines of code can be sent from nvim to the R console by pressing
`Enter` in normal mode. Entire code chunks from `Rmd` and `qmd` can be sent with
`\cc`. To send a custom selection of several lines at once, select them in nvim's
visual mode (press `v` to start selection) and then press `Enter`. The default
keybinding for sending code in R.nvim is `\l` — this has been remapped in the
provided `init.lua` to `Enter` for consistency with other editors.
### Important keybindings for nvim
The following lists important keybindings. It uses the
following syntax: Keys connected with `-` need to be pressed simultaneously,
e.g. `Ctrl-w`. Any key after that (space separated) needs to be pressed after
releasing the combined keys. So `Ctrl-w w` means: press `Ctrl` and `w`
simultaneously, release both, then press `w`.
**Modes**
| Key | Action |
|-----|--------|
| `i` | enter insert mode (for typing) |
| `Esc` | return to normal mode |
| `:` | enter command mode |
**R.nvim commands** (in `.R` / `.Rmd` / `.qmd` files)
| Key / Command | Action |
|---------------|--------|
| `\rf` | open connected R session |
| `Enter` | send current line to R (normal mode) |
| `Enter` | send selection to R (visual mode) |
| `\fc` | send current function to R |
| `\cc` | send current chunk (Rmd/Quarto) |
| `\ch` | send all chunks above cursor |
| `\rh` | open R help for word under cursor |
| `\ro` | toggle object browser |
| `\rv` | view data frame under cursor with [VisiData](https://www.visidata.org/) |
| `:RMapsDesc` | list all R.nvim keybindings |
| `:RConfigShow` | show current R.nvim config |
**Viewport and split commands**
| Key / Command | Action |
|---------------|--------|
| `:split` or `:vsplit` | split viewport horizontally or vertically |
| `gz` | maximize size of viewport in normal mode |
| `Ctrl-w w` | jump cursor between splits |
| `Ctrl-w r` | swap viewports |
| `Ctrl-w =` | resize splits to equal size |
| `Ctrl-w H` or `Ctrl-w K` | toggle between horizontal/vertical split |
| `Ctrl-h/j/k/l` | jump to split in that direction |
| `Esc` | exit terminal insert mode |
| `Space-m` | quick toggle mouse on/off |
| `:set mouse=a` or `n` | alternative mouse on/off with `-n` or `-n` |
| `Space-i` | toggle indent lines on/off |
| `Space-md` | toggle markdown view on/off |
**Search and edit**
| Key / Command | Action |
|---------------|--------|
| `/` or `?` | search forward or backward |
| `:%s/search/replace/cg` | find and replace (with confirmation) |
| `:%s/\s\+$//` | remove trailing whitespace |
| `yy`, `dd`, `p` | copy, cut, paste current line |
| `:set spell` / `:set nospell` | toggle spell checking |
| `z=` | spelling suggestions for word under cursor |
**Completion and help**
| Key / Command | Action |
|---------------|--------|
| `Ctrl-Space` | omni completion for R objects/functions (insert mode) |
| `:h r-nvim` | open R.nvim user manual |
| `:Rhelp fct_name` | open help for a function with tab completion |
**Other useful commands**
| Key / Command | Action |
|---------------|--------|
| `:set tabstop=20` | table viewing with aligned columns |
### File browser: neo-tree
[neo-tree](https://github.com/nvim-neo-tree/neo-tree.nvim) provides file
browser functionality for Neovim, replacing the older NERDTree plugin. To
open the file browser, press `zz` in normal mode, and to close it, press `q`.
| Key | Action |
|-----|--------|
| `zz` | open file browser |
| `q` | close file browser |
| `Enter` | open selected file |
| `a` | create new file or directory |
| `s` | open file with vertical split |
| `S` | open file with horizontal split |
| `H` | toggle hidden files on/off |
| `?` | open neo-tree help |
| `Ctrl-w w` | jump cursor back to editor |
Hidden files (dotfiles) are not shown by default. Press `H` to toggle them.
### nvim IDEs for Python and Bash
For languages other than R, the
[hlterm](https://github.com/jalvesaq/hlterm) plugin provides REPL
integration for Neovim. It is the modern replacement for the older
`vimcmdline` plugin and is written by the same author as R.nvim (Jakson
Alves de Aquino). Supported languages include Python, Bash/Shell, Julia,
JavaScript, and many others.
The usage is very similar to R.nvim. Open a Python or Bash script with nvim,
start the interpreter with `\s`, and send lines with `Enter`:
```bash
nvim myscript.py # open Python script
nvim myscript.sh # open Bash script
```
| Key | Action |
|-----|--------|
| `\s` | start interpreter (Python or Bash) |
| `Enter` | send current line (normal mode) |
| `Enter` | send selection (visual mode) |
The `Enter` keybinding is buffer-local — R files use R.nvim's Enter and
Python/Bash files use hlterm's Enter without any conflict.
### Important keybindings for tmux
**Prefix key: `Ctrl-a`** (hold Ctrl and press a, release both, then press
the next key)
**Pane-level commands**
| Key | Action |
|-----|--------|
| `Ctrl-a \|` | split pane vertically |
| `Ctrl-a -` | split pane horizontally |
| `Ctrl-a` + arrow | move between panes |
| `Alt` + arrow | resize pane (no prefix needed) |
| `Ctrl-a z` | zoom/unzoom active pane (maximize) |
| `Ctrl-a o` | rotate pane arrangement |
| `Ctrl-a x` | close current pane |
| `Ctrl-a m` | toggle mouse on/off |
**Window-level commands**
| Key | Action |
|-----|--------|
| `Ctrl-a c` | create new window |
| `Ctrl-a n` / `Ctrl-a p` | next / previous window |
| `Ctrl-a 1`…`5` | jump to window by number |
| `Ctrl-a ,` | rename current window |
**Session-level commands**
| Key / Command | Action |
|---------------|--------|
| `Ctrl-a d` | detach from current session |
| `Ctrl-a s` | switch between sessions |
| `tmux` | start new session with default layout |
| `tmux a` | reattach to existing session |
| `tmux new -s NAME` | start new named session |
| `tmux a -t NAME` | reattach to named session |
| `tmux ls` | list active sessions |
| `Ctrl-a : kill-session` | kill current session |
| `Ctrl-a r` | reload tmux config |
Mouse support is enabled by default. Use `Ctrl-a m` to toggle it off when
you need to select text for terminal copy/paste. On most terminals,
`Shift+click` selects text even when mouse support is active.