Computer vision technology allows us to develop software with applications such as object tracking, industrial quality, people counting and even the sports world. Detecting, classifying or segmenting objects is one of our company's specializations, allowing us to obtain valuable information from the images and videos that your business produces.
Single Shot MultiBox Detector is a deep learning model used to detect objects in an image or from a video source. Single Shot Detector is a simple approach to solve the problem but it is very effective till now. SSD has two components and they are the Backbone Model and the SSD Head
We are Building Optical character recognition (OCR) allows you to extract printed or handwritten text from images, such as photos of street signs and products, as well as from documents—invoices, bills, financial reports, articles, and more. Microsoft's OCR technologies support extracting printed text in different languages
A Safe Search system is a technology capable of matching a human face from a digital image or a video frame against a database of faces, typically employed to authenticate users through ID verification services, works by pinpointing and measuring facial features from a given image.
This is what puts the "deep" in deep learning. Each layer categorizes some kind of information, refines it, and passes it along to the next. The parallel computing nature of GPUs accelerates this process to enable breakthroughs like facial recognition, real-time voice translation, and self-driving cars.
Visual search is a type of perceptual task requiring attention that typically involves an active scan of the visual environment for a particular object or feature (the target) among other objects or features (the distractors). Visual search can take place with or without eye movements.
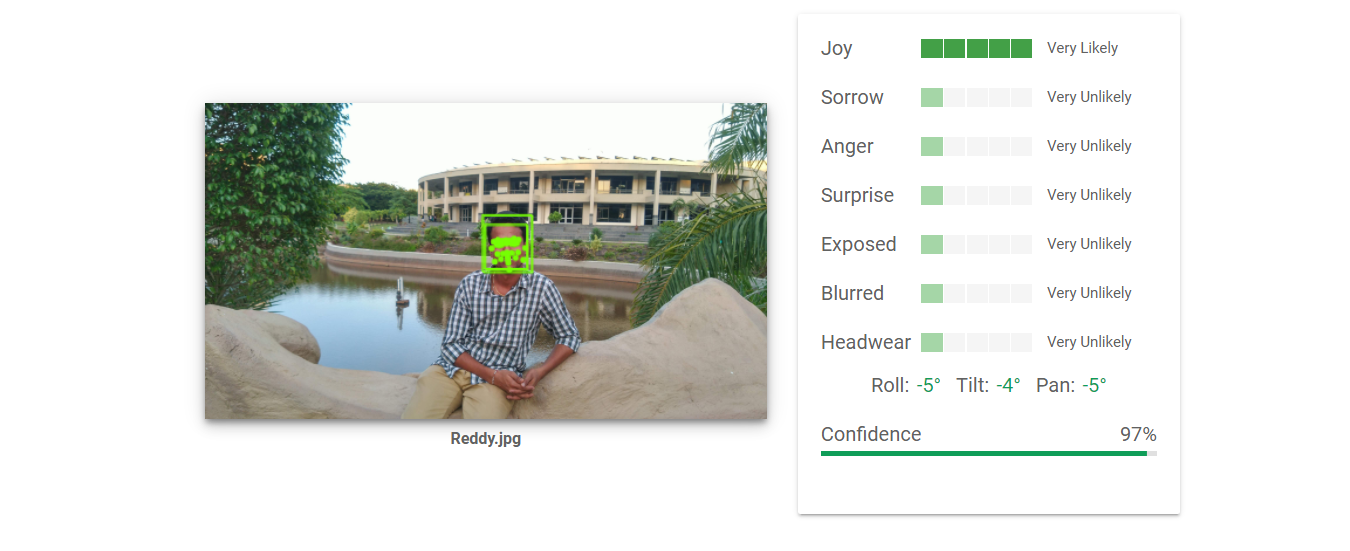
It can continuously perform emotional state recognition in real-time at a frame rate of 30. A graphical user interface was designed to display the participant’s video in real-time and two-dimensional predict labels of the emotion at the same time.
Dense captioning is a newly emerging computer vision topic for understanding images with dense language descriptions. The goal is to densely detect visual concepts (e.g., objects, object parts, and interactions between them) from images, labeling each with a short descriptive phrase.
We build An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition Keras implementation of Convolutional Recurrent Neural Network for text recognition.
The ClientoClarify.AI network of partners includes business software providers, niche technology developers, and platform and IT infrastructure vendors.