![]()
Qwen-VL 🤖 | 🤗 | Qwen-VL-Chat 🤖 | 🤗 | Qwen-VL-Chat-Int4 🤗
WeChat | Discord | Demo | Paper | Colab | Tutorial
Qwen-VL 시리즈의 두 모델을 출시합니다.
- Qwen-VL: 사전 훈련된 LVLM 모델로, Qwen-7B를 LLM의 초기화에 사용하며, 시각 인코더의 초기화로는 [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip)를 사용하여, 무작위로 초기화된 교차 어텐션 레이어(randomly initialized cross-attention layer)에 연결합니다.
- Qwen-VL-Chat: 정렬 기술로 훈련된 멀티모달 LLM 기반 AI 어시스턴트입니다. Qwen-VL-Chat은 여러 이미지 입력, 다중 라운드 질문 응답, 창의적 능력과 같은 더 유연한 상호작용을 지원합니다.
## 뉴스 및 업데이트
* ```2023.9.25``` 🚀🚀🚀 Qwen-VL-Chat을 더욱 강력한 중국어 지시 수행 능력, 웹페이지 및 표 이미지에 대한 개선된 이해력, 더 나은 대화 성능(TouchStone: CN: 401.2->481.7, EN: 645.2->711.6)으로 업데이트 되었습니다.
* ```2023.9.12``` 😃😃😃 이제 Qwen-VL 모델에 대한 파인튜닝을 지원합니다. 이에는 전체 파라미터 파인튜닝, LoRA 및 Q-LoRA가 포함됩니다.
* ```2023.9.8``` 👍👍👍 camenduru가 멋진 Colab을 기여해 주셔서 감사합니다. 모두가 12G GPU에서 로컬 또는 온라인 Qwen-VL-Chat-Int4 데모 튜토리얼로 사용할 수 있습니다.
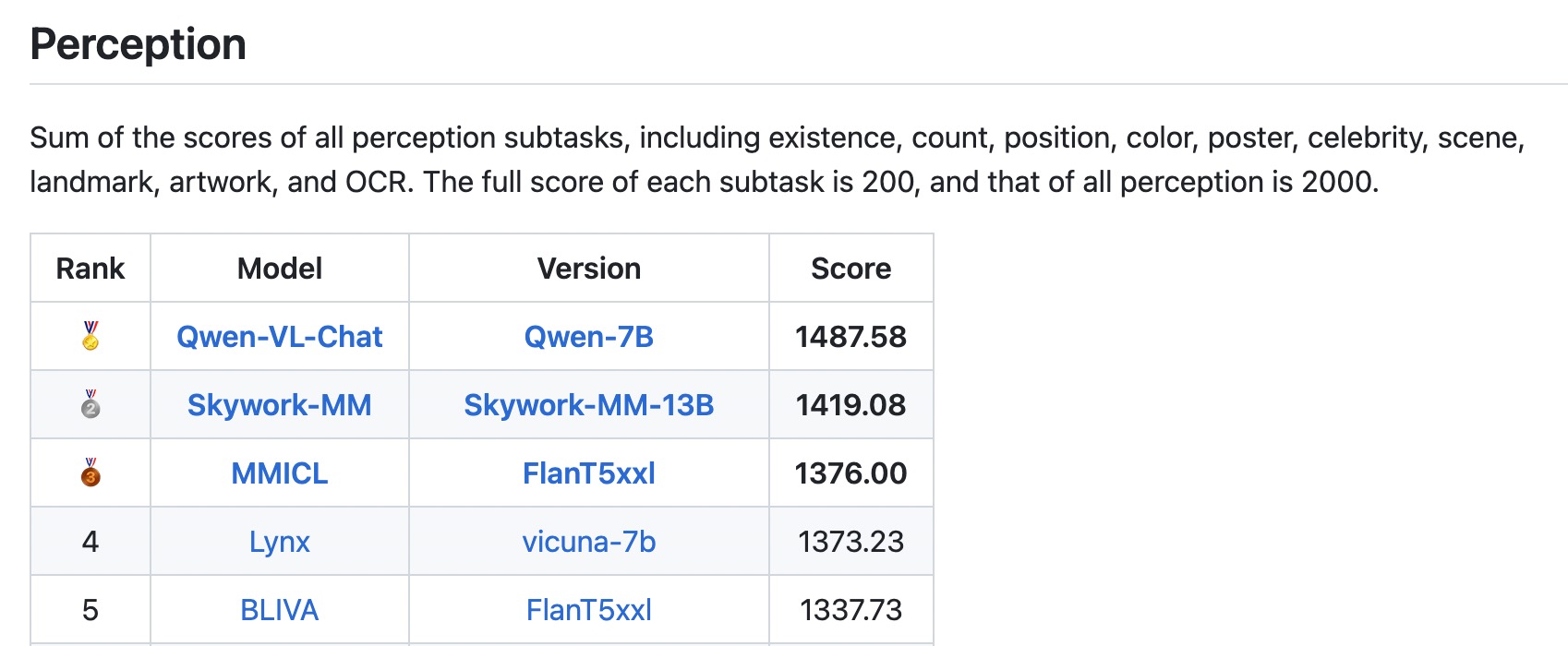
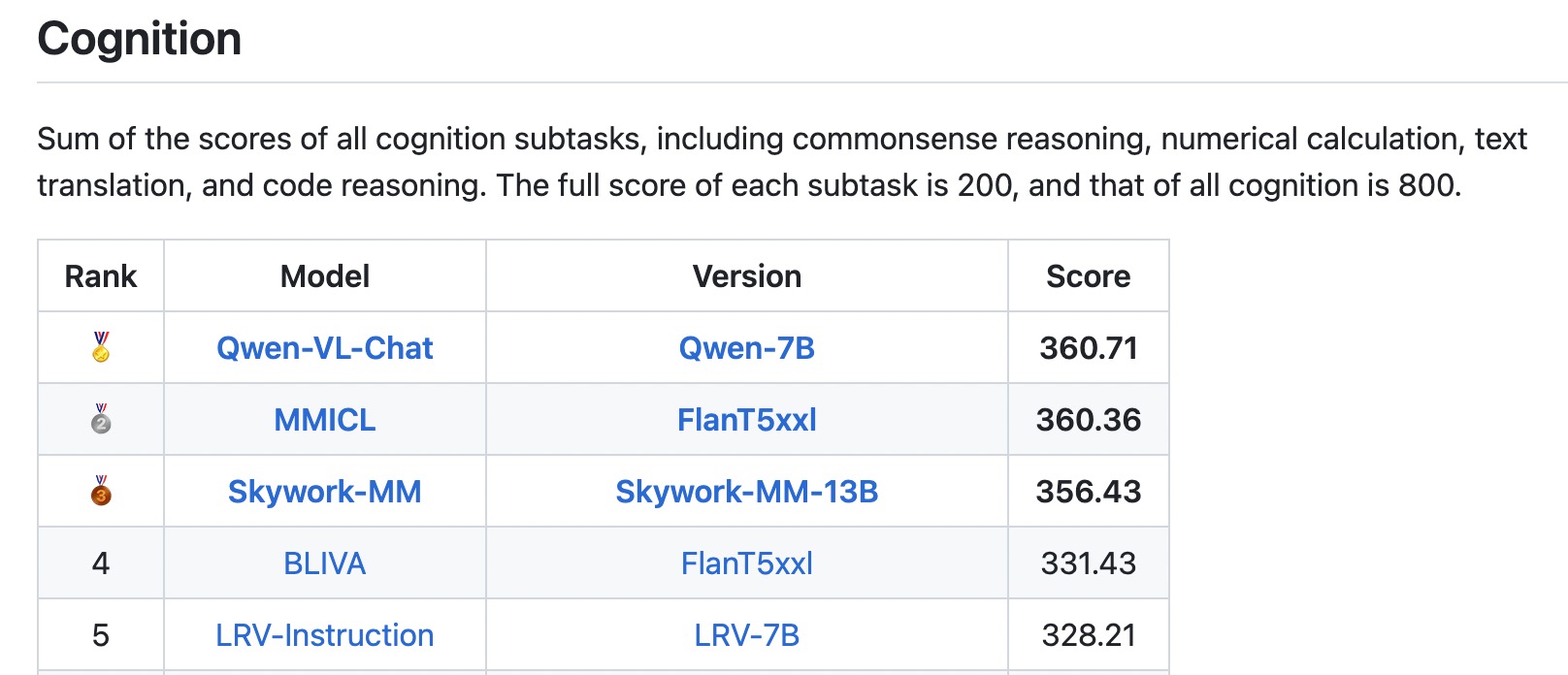
* ```2023.9.5``` 👏👏👏 Qwen-VL-Chat은 MME Benchmark, 멀티모달 대형 언어 모델을 위한 종합적인 평가 벤치마크에서 SOTAs를 달성했습니다. 이는 총 14개의 하위 과제에서 인식과 인지 능력을 모두 측정합니다.
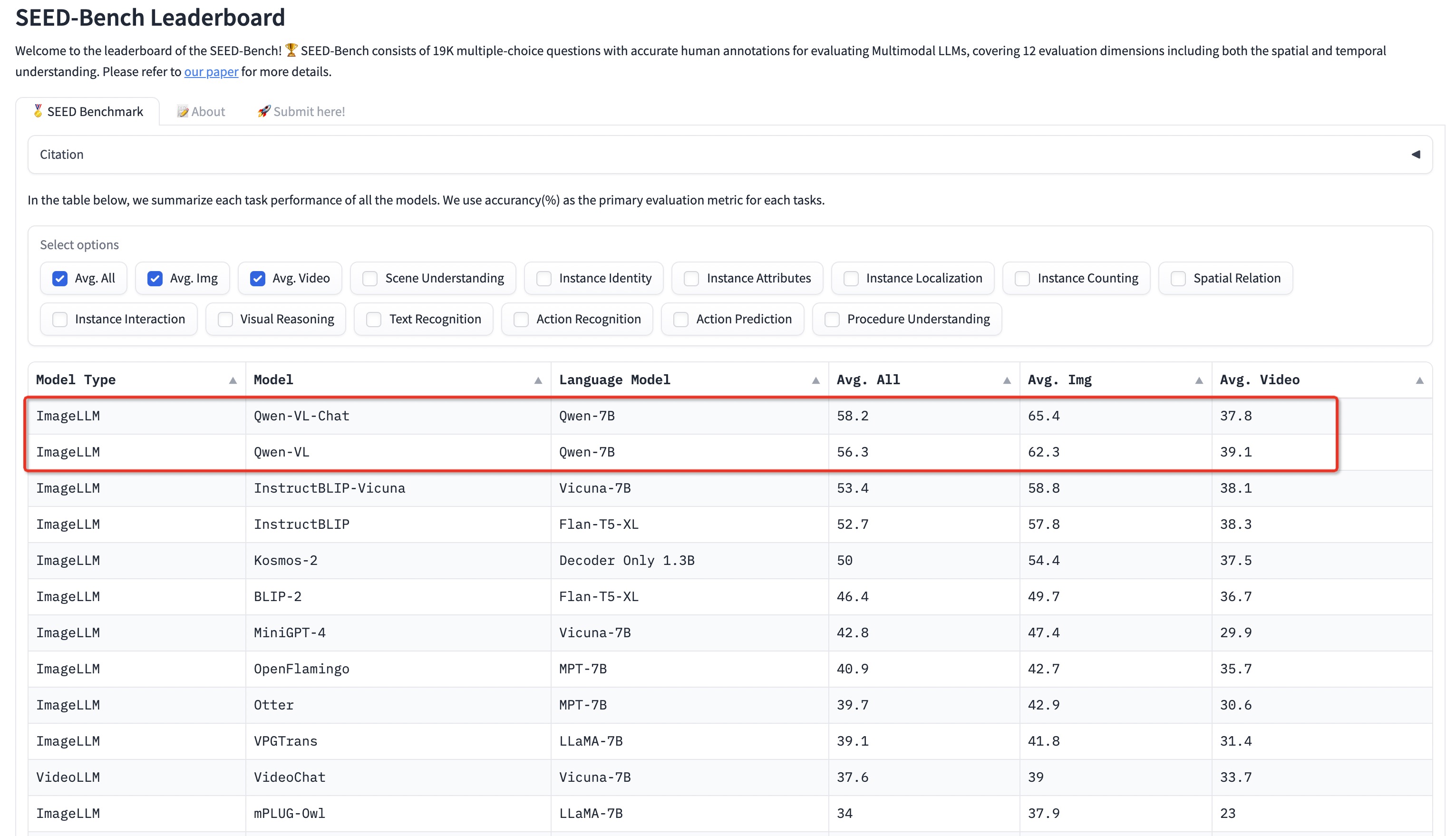
* ```2023.9.4``` ⭐⭐⭐ Qwen-VL 시리즈는 Seed-Bench, 이미지 및 비디오 이해를 평가하는 19K 다중 선택 질문의 멀티모달 벤치마크에서 SOTAs를 달성했습니다. 이는 정확한 인간 주석을 갖추고 있습니다.
* ```2023.9.1``` 🔥🔥🔥 기본적인 인식과 이해력뿐만 아니라 문학 창작까지 아우르는 복합 언어 모델에 대한 종합적인 평가인 [TouchStone](https://github.com/OFA-Sys/TouchStone) 평가를 출시합니다. 강력한 LLM을 심사위원으로 활용하고, 멀티모달 정보를 텍스트로 변환하여 평가합니다.
* ```2023.8.31``` 🌟🌟🌟 Qwen-VL-Chat용 Int4 양자화 모델인 **Qwen-VL-Chat-Int4**를 출시하여 메모리 비용은 낮추고 추론 속도는 향상시켰습니다. 또한 벤치마크 평가에서도 성능 저하가 크지 않습니다.
* ```2023.8.22``` 🎉🎉🎉 모델스코프와 허깅페이스에 **Qwen-VL**과 **Qwen-VL-Chat**을 모두 출시합니다. 학습 내용 및 모델 성능 등 모델에 대한 자세한 내용은 [논문](https://arxiv.org/abs/2308.12966)을 통해 확인할 수 있습니다.
## Evaluation
세 가지 관점에서 모델의 기능을 평가했습니다:
1. **표준 벤치마크**: 멀티모달 작업의 네 가지 주요 범주에 대한 모델의 기본 작업 기능을 평가합니다:
- 제로 샷 캡션: 보이지 않는 데이터 세트에 대한 모델의 제로샷 이미지 캡션 능력을 평가합니다.
- 일반 VQA: 판단, 색상, 숫자, 카테고리 등과 같은 사진의 일반적인 질문에 대한 답변 능력을 평가합니다.
- 텍스트 기반 VQA: 문서 QA, 차트 QA 등과 같이 사진 속 텍스트를 인식하는 모델의 능력을 평가합니다.
- 참조 표현 이해: 참조 표현식으로 설명된 이미지에서 대상 객체를 찾아내는 능력을 평가합니다.
2. **터치스톤**: 전반적인 텍스트-이미지 대화 능력과 사람과의 일치도를 평가하기 위해 [TouchStone](https://github.com/OFA-Sys/TouchStone)이라는 벤치마크를 구축했으며, 이 벤치마크는 GPT4로 채점하여 LVLM 모델을 평가합니다.
- 터치스톤 벤치마크는 총 300개 이상의 이미지, 800개 이상의 질문, 27개 카테고리를 다룹니다. 속성 기반 Q&A, 유명인 인식, 시 쓰기, 여러 이미지 요약, 제품 비교, 수학 문제 풀이 등이 포함됩니다.
- 직접 이미지 입력이라는 현재 GPT4의 한계를 극복하기 위해 TouchStone은 사람이 직접 라벨을 지정하여 세분화된 이미지 주석을 제공합니다. 이러한 세부 주석은 문제 및 모델의 출력과 함께 채점을 위해 GPT4에 제공됩니다.
- 벤치마크에는 영어와 중국어 버전이 모두 포함되어 있습니다.
3. **기타 멀티모달 벤치마크**: 다른 멀티모달 벤치마크에서도 모델의 성능을 평가했습니다:
- 멀티모달 대규모 언어 모델에 대한 종합적인 평가 벤치마크인 [MME 벤치마크](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation). Qwen-VL-Chat은 지각과 인지 트랙 모두에서 SOTA를 달성했습니다.
- [Seed-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard)는 멀티모달 LLM을 평가하기 위한 정확한 인간 주석이 포함된 19K 객관식 질문으로 구성된 멀티모달 벤치마크입니다. 큐원 시리즈는 이 벤치마크에서 SOTA를 달성했습니다.
평가 결과는 다음과 같습니다.
Qwen-VL은 여러 VL 작업에서 현재 SOTA 제너럴리스트 모델보다 성능이 뛰어나며, 기능 범위 측면에서 더 포괄적인 기능을 지원합니다.

### Zero-shot Captioning & General VQA
| Model type | Model | Zero-shot Captioning | General VQA | |||||
|---|---|---|---|---|---|---|---|---|
| NoCaps | Flickr30K | VQAv2dev | OK-VQA | GQA | SciQA-Img (0-shot) |
VizWiz (0-shot) |
||
| Generalist Models |
Flamingo-9B | - | 61.5 | 51.8 | 44.7 | - | - | 28.8 |
| Flamingo-80B | - | 67.2 | 56.3 | 50.6 | - | - | 31.6 | |
| Unified-IO-XL | 100.0 | - | 77.9 | 54.0 | - | - | - | |
| Kosmos-1 | - | 67.1 | 51.0 | - | - | - | 29.2 | |
| Kosmos-2 | - | 80.5 | 51.1 | - | - | - | - | |
| BLIP-2 (Vicuna-13B) | 103.9 | 71.6 | 65.0 | 45.9 | 32.3 | 61.0 | 19.6 | |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | - | - | 49.5 | 63.1 | 33.4 | |
| Shikra (Vicuna-13B) | - | 73.9 | 77.36 | 47.16 | - | - | - | |
| Qwen-VL (Qwen-7B) | 121.4 | 85.8 | 78.8 | 58.6 | 59.3 | 67.1 | 35.2 | |
| Qwen-VL-Chat | 120.2 | 81.0 | 78.2 | 56.6 | 57.5 | 68.2 | 38.9 | |
| Previous SOTA (Per Task Fine-tuning) |
- | 127.0 (PALI-17B) |
84.5 (InstructBLIP -FlanT5-XL) |
86.1 (PALI-X -55B) |
66.1 (PALI-X -55B) |
72.1 (CFR) |
92.53 (LLaVa+ GPT-4) |
70.9 (PALI-X -55B) |
| Model type | Model | TextVQA | DocVQA | ChartQA | AI2D | OCR-VQA |
|---|---|---|---|---|---|---|
| Generalist Models | BLIP-2 (Vicuna-13B) | 42.4 | - | - | - | - |
| InstructBLIP (Vicuna-13B) | 50.7 | - | - | - | - | |
| mPLUG-DocOwl (LLaMA-7B) | 52.6 | 62.2 | 57.4 | - | - | |
| Pix2Struct-Large (1.3B) | - | 76.6 | 58.6 | 42.1 | 71.3 | |
| Qwen-VL (Qwen-7B) | 63.8 | 65.1 | 65.7 | 62.3 | 75.7 | |
| Specialist SOTAs (Specialist/Finetuned) |
PALI-X-55B (Single-task FT) (Without OCR Pipeline) |
71.44 | 80.0 | 70.0 | 81.2 | 75.0 |
| Model type | Model | RefCOCO | RefCOCO+ | RefCOCOg | GRIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | test-A | test-B | val | test-A | test-B | val-u | test-u | refexp | ||
| Generalist Models | GPV-2 | - | - | - | - | - | - | - | - | 51.50 |
| OFA-L* | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | 61.70 | |
| Unified-IO | - | - | - | - | - | - | - | - | 78.61 | |
| VisionLLM-H | 86.70 | - | - | - | - | - | - | - | ||
| Shikra-7B | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 69.34 | |
| Shikra-13B | 87.83 | 91.11 | 81.81 | 82.89 | 87.79 | 74.41 | 82.64 | 83.16 | 69.03 | |
| Qwen-VL-7B | 89.36 | 92.26 | 85.34 | 83.12 | 88.25 | 77.21 | 85.58 | 85.48 | 78.22 | |
| Qwen-VL-7B-Chat | 88.55 | 92.27 | 84.51 | 82.82 | 88.59 | 76.79 | 85.96 | 86.32 | - | |
| Specialist SOTAs (Specialist/Finetuned) |
G-DINO-L | 90.56 | 93.19 | 88.24 | 82.75 | 88.95 | 75.92 | 86.13 | 87.02 | - |
| UNINEXT-H | 92.64 | 94.33 | 91.46 | 85.24 | 89.63 | 79.79 | 88.73 | 89.37 | - | |
| ONE-PEACE | 92.58 | 94.18 | 89.26 | 88.77 | 92.21 | 83.23 | 89.22 | 89.27 | - | |
#### SEED-Bench [SEED-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard)는 **이미지** 및 **동영상** 이해도를 포함한 12가지 평가 차원을 포괄하는 멀티모달 LLM을 평가하기 위한 정확한 사람의 주석이 포함된 19K 개의 객관식 문항으로 구성된 멀티모달 벤치마크입니다. 자세한 내용은 [여기](eval_mm/seed_bench/EVAL_SEED.md)에서 확인할 수 있습니다. 이 벤치마크에서 Qwen-VL과 Qwen-VL-Chat은 SOTA를 달성했습니다.
## Requirements
* python 3.8 and above
* pytorch 1.12 and above, 2.0 and above are recommended
* CUDA 11.4 and above are recommended (this is for GPU users)
## Quickstart
아래에서는 🤖 모델스코프 및 🤗 트랜스포머와 함께 Qwen-VL 및 Qwen-VL-Chat을 사용하는 방법을 보여주는 간단한 예제를 제공합니다.
코드를 실행하기 전에 환경을 설정하고 필요한 패키지를 설치했는지 확인하세요. 위의 요구 사항을 충족하는지 확인한 다음 종속 라이브러리를 설치하세요.
```bash
pip install -r requirements.txt
```
이제 모델스코프 또는 트랜스포머로 시작할 수 있습니다. 비전 인코더에 대한 자세한 사용법은 [튜토리얼](TUTORIAL.md)을 참조하세요.
#### 🤗 Transformers
추론에 Qwen-VL-Chat을 사용하려면 아래에 설명된 대로 몇 줄의 코드를 입력하기만 하면 됩니다. 단, **최신 코드를 사용하고 있는지 확인하세요**.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# 击掌

HuggingFace에서 모델 체크포인트와 코드를 다운로드하는 동안 네트워크 문제가 발생하는 경우, 아래에 설명된 대로 모델스코프에서 체크포인트를 먼저 가져온 다음 로컬 디렉터리에서 로드하는 방법을 사용할 수 있습니다.
```python
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-VL')
model_dir = snapshot_download('qwen/Qwen-VL-Chat')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="cuda",
trust_remote_code=True
).eval()
```
#### 🤖 ModelScope
ModelScope는 서비스형 모델(MaaS)을 위한 오픈소스 플랫폼으로, AI 개발자에게 유연하고 비용 효율적인 모델 서비스를 제공합니다. 마찬가지로 아래와 같이 ModelScope로 모델을 실행할 수 있습니다.
```python
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# use bf16
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# use auto
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation (No need to do this if you are using transformers>=4.32.0)
# model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 1st dialogue turn
# Either a local path or an url between Running Qwen-VL
Qwen-VL pretrained base model을 실행하는 것도 매우 간단합니다.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation (No need to do this if you are using transformers>4.32.0)
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': 'Generate the caption in English with grounding:'},
])
inputs = tokenizer(query, return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
print(response)
# https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpegGenerate the caption in English with grounding: Woman

tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# "击掌"
## Quantization
### Usage
[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ)를 기반으로 하는 새로운 솔루션을 제공하고, 거의 무손실 모델 효과를 달성하면서도 메모리 비용과 추론 속도 모두에서 성능이 향상된 Qwen-VL-Chat용 Int4 양자화 모델인 [Qwen-VL-Chat-Int4](https://huggingface.co/Qwen/Qwen-VL-Chat-Int4)를 출시했습니다.
여기에서는 제공된 양자화된 모델을 추론에 사용하는 방법을 보여줍니다. 시작하기 전에 요구 사항(예: torch 2.0 이상, transformers 4.32.0 이상 등) 및 필요한 패키지를 제대로 설치했는지 확인하세요.
```bash
pip install optimum
git clone https://github.com/JustinLin610/AutoGPTQ.git & cd AutoGPTQ
pip install -v .
```
만약 'auto-gptq' 설치에 문제가 있다면, 공식 [repo](https://github.com/PanQiWei/AutoGPTQ)에서 휠을 찾아보시길 권장합니다.
그러면 정량화된 모델을 쉽게 로드하고 평소와 동일하게 추론을 실행할 수 있습니다.
```python
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-VL-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
# Either a local path or an url between tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
```
### Performance
[TouchStone](https://github.com/OFA-Sys/TouchStone)벤치마크에서 BF16 및 Int4 모델의 모델 성능을 살펴본 결과, 양자화된 모델에서 성능 저하가 크지 않은 것으로 나타났습니다. 결과는 아래와 같습니다.
| Quantization | ZH | EN |
| ------------ | :--------: | :-----------: |
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
### Inference Speed
이미지의 컨텍스트(258개의 토큰이 필요한)를 가지고 각각 1792개(2048-258개), 7934개(8192-258개)의 토큰을 생성하는 평균 추론 속도(토큰/초)를 BF16 정밀도와 Int4 양자화 하에서 측정했습니다.
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
| ------------ | :-----------------: | :-----------------: |
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
프로파일링은 PyTorch 2.0.1 및 CUDA 11.4가 탑재된 단일 A100-SXM4-80G GPU에서 실행됩니다.
### GPU Memory Usage
또한 1792개(2048-258개)의 토큰(이미지 포함)을 컨텍스트로 인코딩하고 단일 토큰을 생성할 때와 7934개(8192-258개)의 토큰(이미지가 컨텍스트로 포함)을 생성할 때 각각 BF16 또는 Int4 양자화 수준에서 최대 GPU 메모리 사용량을 프로파일링했습니다. 결과는 아래와 같습니다.
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
| ------------ | :---------------------------------: | :-----------------------------------: |
| BF16 | 22.60GB | 28.01GB |
| Int4 | 11.82GB | 17.23GB |
위의 속도 및 메모리 프로파일링은 [이 스크립트](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py)를 사용하여 수행되었습니다.
## Finetuning
이제 사용자가 다운스트림 애플리케이션을 위해 사전 학습된 모델을 간단한 방식으로 미세 조정할 수 있도록 공식 학습 스크립트인 `finetune.py`를 제공합니다. 또한, 걱정 없이 미세 조정을 시작할 수 있는 셸 스크립트도 제공합니다. 이 스크립트는 딥스피드와 FSDP를 통한 학습을 지원합니다. 제공되는 셸 스크립트는 DeepSpeed를 사용하므로 시작하기 전에 DeepSpeed를 설치하는 것이 좋습니다.
```bash
pip install deepspeed
```
### Data preparation
학습 데이터를 준비하려면 모든 샘플을 목록에 넣고 json 파일에 저장해야 합니다. 각 샘플은 ID와 대화 목록으로 구성된 사전입니다. 아래는 샘플 1개가 포함된 간단한 예제 목록입니다.
```json
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是Qwen-VL,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg\n图中的狗是什么品种?"
},
{
"from": "assistant",
"value": "图中是一只拉布拉多犬。"
},
{
"from": "user",
"value": "框出图中的格子衬衫"
},
{
"from": "assistant",
"value": "格子衬衫
assets/mm_tutorial/Chongqing.jpeg\nPicture 2:
assets/mm_tutorial/Beijing.jpeg\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
```
VL 작업에서는 `
img_path\n{your prompt}`로 표시되며, 여기서 `id`는 대화에서 이미지의 위치(1부터 시작)를 나타냅니다. `img_path`는 로컬 파일 경로 또는 웹 링크일 수 있습니다.
박스의 좌표는 `
| Method | Sequence Length | |||
|---|---|---|---|---|
| 384 | 512 | 1024 | 2048 | |
| LoRA (Base) | 37.1G / 2.3s/it | 37.3G / 2.4s/it | 38.7G / 3.6s/it | 38.7G / 6.1s/it |
| LoRA (Chat) | 23.3G / 2.2s/it | 23.6G / 2.3s/it | 25.1G / 3.5s/it | 27.3G / 5.9s/it |
| Q-LoRA | 17.0G / 4.2s/it | 17.2G / 4.5s/it | 18.2G / 5.5s/it | 19.3G / 7.9s/it |
{kind=link}