<< , <<<
<< ( here document ), <<< ( here string ) 은 실행 중에 임시 파일을 만들어서 stdin 에 연결합니다. 그러므로 echo 명령 대신에 cat 명령을 사용합니다. 아래는 ls -l 명령의 인수로 here docuemnt 를 사용하였는데 stdin 입력으로 sh-thd.Th1cFU 임시 파일이 사용된 후 삭제된 것을 볼수가 있습니다.
sh에서는<<만 사용할 수 있습니다.
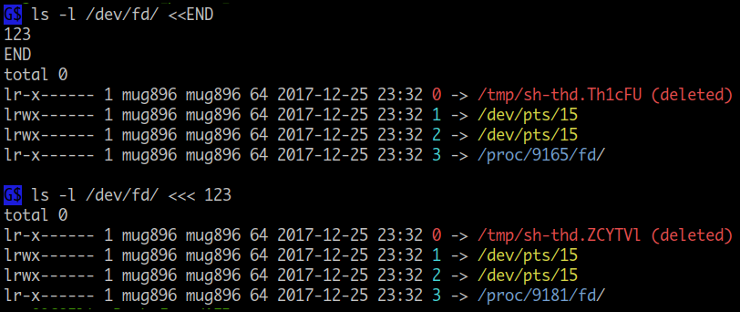
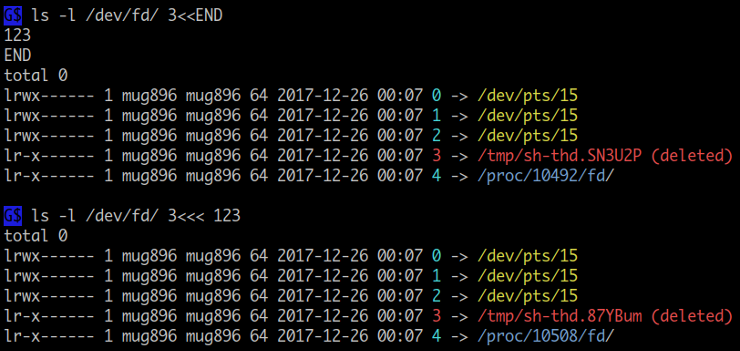
<<, <<< 왼쪽에 공백없이 붙여서 file descriptor 를 사용할 수 있습니다.
$ 3<<< hello <&3 cat # <&3 는 0<&3 와 같은 것임
hello
$ 3<<END cat /dev/fd/3
> hello
> END
hello
---------------------------------------------------
$ exec 3<<END
> 111
> 222
> END
$ ls -l /proc/$$/fd/
total 0
lrwx------ 1 mug896 mug896 64 2018-01-05 18:51 0 -> /dev/pts/15
lrwx------ 1 mug896 mug896 64 2018-01-05 18:51 1 -> /dev/pts/15
lrwx------ 1 mug896 mug896 64 2018-01-05 18:51 2 -> /dev/pts/15
lrwx------ 1 mug896 mug896 64 2018-01-05 18:51 255 -> /dev/pts/15
lr-x------ 1 mug896 mug896 64 2018-01-05 18:51 3 -> /tmp/sh-thd.0bYLMF (deleted)
$ cat /dev/fd/3
111
222
$ cat /dev/fd/3
111
222
$ cat <&3
111
222
$ cat <&3
$ # <&3 는 파일 포지션이 이동하므로
$ exec 3>&-
-----------------------------------------
# 파이프로 인해 stdin 이 사용 중 일 경우
$ command ... | sed -f /dev/fd/3 3<<EOF
...
EOF
$ command ... | awk -f /dev/fd/3 3<<\EOF
...
EOF
<< (here document)
awk, sed 같은 명령을 작성할 때는 quotes 을 사용하므로 동일한 quotes 을 출력에 사용하려면 escape 과정을 거쳐야 하는데요. heredoc 을 이용하면 파일에서 작성하는 것과 같이 quotes 을 escape 할 필요가 없습니다. 또한 본문 내용 중에 변수를 사용할 수도 있어서 여러모로 편리한 기능입니다.
heredoc 은 본문의 처음과 끝을 별도의 레이블로 구분하는데 이때 사용되는 구분자 명은 임의로 만들어 사용할 수 있습니다. 한가지 주의할 점은 마지막 줄은 구분자 외에 다른 문자가 와서는 안됩니다. 구분자를 quote 하거나 escape 하면 변수확장, 명령치환이 일어나지 않습니다.
# quotes 을 escape 하지 않고 사용할 수 있어서 echo 명령 대신에 출력에 사용하기 좋습니다.
# 예) 명령의 help 메시지 작성
$ cat <<EOF
> this is "double quotes"
> this is 'single quotes'
> EOF
this is "double quotes"
this is 'single quotes'
# 기본적으로 본문에서 변수확장, 명령치환이 일어난다.
$ AA=100
$ cat <<ABC # 구분자 ABC
> here $AA
> document $(date +%D)
> ABC
here 100
document 07/23/15
# 구분자를 quote 하거나 escape 하면 변수확장, 명령치환이 안된다.
$ AA=100
$ cat <<'END' # 또는 <<\END
> here $AA
> document $(date +%D)
> END
here $AA
document $(date +%D)
awk, sed 명령 사용예
# heredoc 은 stdin 에 연결되므로 '-f -' 옵션을 사용 ('-' 는 stdin 을 나타냄)
$ awk -f - <<\EOF
> BEGIN { print "''print single quotes easily''" }
> EOF
''print single quotes easily''
# single, double quotes 을 쉽게 출력할 수 있다.
# ( 파이프 로인해 stdin 이 사용 중이므로 -f /dev/fd/3 를 사용 )
$ echo "print quotes easily" | sed -f /dev/fd/3 3<<EOF
> s/.*/''&""/
> EOF
''print quotes easily""
$ echo "print quotes easily" | sed "$( cat <<EOF
> s/.*/''&""/
> EOF
> )"
''print quotes easily""
현재 각 cpu core 에 바운드된 스레드 개수를 실시간으로 보기
# ps 명령에서 psr 은 현재 스레드가 바운드된 cpu core 를 말하고
# 뒤에 '=' 는 ps 명령이 타이틀을 표시하지 않게 합니다.
# 출력 결과가 실제 코어 수 보다 많게 나오는 이유는 Hyper-Threading 때문입니다.
$ watch -td -n1 "$( cat <<\EOF
ps axH -o psr= |
awk '{a[$1]++} END {
for (i in a) { printf "c%-6d",i }; print "";
for (i in a) { printf "%-7d", a[i] }; print "" }'
EOF
)"
Here document 를 파일로 쓰기
$ cat > tmp/outfile <<\END
> here
> document
> END
$ cat <<\END > tmp/outfile
> here
> document
> END
$ <<\END cat > tmp/outfile
> here
> document
> END
Here document 를 파이프로 전달하기
$ sqlite3 mydatabase <<\@ | awk -F '\t' \
'
BEGIN { print "<table>" }
{ printf "<tr><td>%s</td><td>%s</td></tr>\n", $1, $2 }
END { print "</table>" }
'
.mode list
.separator \t
.header off
SELECT name,phone FROM person;
@
# 또는
$ sqlite3 mydatabase <<\@ | awk -f /dev/fd/3 3<<\@@ -F '\t'
.mode list
.separator \t
.header off
SELECT name,phone FROM person;
@
BEGIN { print "<table>" }
{ printf "<tr><td>%s</td><td>%s</td></tr>\n", $1, $2 }
END { print "</table>" }
@@
<table>
<tr><td>Jennifer Whalen</td><td>010-8129-4728</td></tr>
<tr><td>Donald OConnell</td><td>010-3512-4623</td></tr>
. . .
. . .
-------------------------------------------------------
$ cat <<\END | m4
define( `hello', `Hello world')
hello, welcome to m4!
END
Hello world, welcome to m4!
# 또는 다음과 같이 해도 됩니다.
# <<END 는 0<<END 와 같은 것임
$ <<\END m4
define( `hello', `Hello world')
hello, welcome to m4!
END
Hello world, welcome to m4!
-------------------------------
# 명령행 상에서 첫번째 '-' 는 stdout 을( -o 옵션과 ), 두번째 '-' 는 stdin 을 나타냄
# gcc 는 파일 확장자를 통해 c, c++ 파일을 구분하는데 지금은 stdin 으로부터
# 입력을 받으므로 -x 옵션을 이용해 c 파일임을 명시해야 합니다. ( c++ 의 경우는 -xc++ )
$ gcc -S -masm=intel -xc -fno-asynchronous-unwind-tables -o - - <<\@
int a = 1;
int foo() {
int b = 2;
int c = a + b;
return c;
}
@
.file ""
.intel_syntax noprefix
.text
.globl a
. . . .
. . . .
Here document 를 이용한 변수값 설정
$ AA=$(cat <<@ # 구분자 '@'
> 'here'
> "document"
> @ # 마지막 줄은 구분자 외에 다른 문자가 오면 안된다.
> )
$ echo "$AA"
'here'
"document"
............................................................
# 명령치환이 일어나야 하므로 END 구분자를 escape 하면 안됩니다.
$ IFS=, read AA BB CC <<END
$( awk 'BEGIN{ print "100,,*" }' ) # 두 번째 값은 empty
END
$ echo "$AA : $BB : $CC"
100 : : *
while 문의 입력으로 사용하기
$ while read -r line; do
> echo "$line"
> done <<END
> here
> document
> END
here
document
Leading tab 을 이용한 들여쓰기
here document 기호로 <<- 를 이용하면 내용을 작성할 때 leading tab 을 사용하여
들여 쓰기를 할 수 있습니다. 출력시에는 leading tab 이 제거되어 출력됩니다.
명령문 작성시 tab 문자 입력은
Ctrl-v+tab으로 할 수 있습니다.
$ if true; then
> cat <<END
> here
> document
> with tab
> END
> fi
here # 출력에 leading tab 이 포함됨
document
with tab
# '<<' 기호 대신에 '<<-' 를 사용
$ if true; then
> cat <<-END
> here
> document
> with tab
> END # 종료 구분자도 들여쓰기 가능
> fi
here # 출력은 leading tab 이 제거되어 출력됩니다.
document
with tab
중첩사용
$ cat <<-\END1 <<END2
'hello'
"world"
END1
message start
$( cat /dev/stdin )
message end
END2
################# output ##############
message start
'hello'
"world"
message end
<<< (here string)
here string 은 <<< 우측에 하나의 인수만을 갖습니다.
인수에 변수나 명령치환이 사용될 경우 대입연산 에서와 같이 quote 하지 않아도 포멧이 유지되며
globbing 이 발생하지 않습니다.
# quote 하지 않아도 포멧이 유지된다.
$ cat <<< $( echo -e "hello\nhere string" )
hello
here string
# globbing 이 발생하지 않는다.
$ cat <<< *
*
명령의 출력을 read 명령을 이용해 변수값에 설정하려고 할 때 파이프를 사용하면 subshell 로 인해 설정된 변수의 값을 유지할 수가 없습니다. 이때 here string 을 이용하면 현재 shell 에서 실행되어 문제를 해결할 수 있습니다.
# read 명령이 '|' 로인해 subshell 에서 실행되어 값이 표시되지 않는다
$ awk 'BEGIN { print "here string test" }' | read v1 v2 v3
$ echo "$v1 : $v2 : $v3"
: :
# '<<<' 는 현재 shell 에서 실행되어 정상적으로 값을출력.
$ read v1 v2 v3 <<< $( awk 'BEGIN{ print "here string test" }' )
$ echo "$v1 : $v2 : $v3"
here : string : test
# 변수값 중에 empty 값이 있을 경우
$ IFS=, read AA BB CC <<< $( awk 'BEGIN{ print "100,,*" }' )
$ echo "$AA : $BB : $CC"
100 : : *
here string 은 마지막에 자동으로 newline 을 붙입니다.
$ od -a <<< '123'
0000000 1 2 3 nl
0000004
Quiz
쉘 스크립트에 바이너리 파일을 저장하여 실행하려면?
base64 를 이용하는 방법
base64 명령을 이용하면 binary 파일이 텍스트로 변환되므로 이 방법은 binary 파일을 전송할 수 없는 환경에서 이용할 수 있습니다.
1 . 먼저 base64 명령을 이용하여 binary 파일을 텍스트로 변환합니다.
$ base64 binaryCommand > test.sh
2 . test.sh 파일을 텍스트 에디터로 열어 보면 base64 로 인코딩된 데이터가 저장되어있습니다. 다음과 같이 수정하여 사용하면 됩니다.
#!/bin/bash
# 먼저 시스템이 바이너리 명령을 실행할 수 있는지 체크합니다.
[ "$(uname -mo)" = "x86_64 GNU/Linux" ] || { echo "binary can't execute"; exit 1 ;}
trap 'rm -f "$tmpFile"' EXIT
echo start...
tmpFile=`mktemp -p .`
base64 -d > "$tmpFile" <<\END
f0VMRgIBAQAAAAAAAAAAAAIAPgABAAAAsABAAAAAAABAAAAAAAAAAAABAAAAAAAAAAAAAEAAOAAC
AEAABAADAAEAAAAFAAAAAAAAAAAAAAAAAEAAAAAAAAAAQAAAAAAA2gAAAAAAAADaAAAAAAAAAAAA
IAAAAAAAAQAAAAYAAADaAAAAAAAAANoAYAAAAAAA2gBgAAAAAAAOAAAAAAAAAA4AAAAAAAAAAAAg
AAAAAABIx8ABAAAASMfHAQAAAEjHxtoAYABIx8IOAAAADwVIx8A8AAAASDH/DwVIZWxsbywgd29y
bGQhCgAuc2hzdHJ0YWIALnRleHQALmRhdGEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALAAAAAQAAAAYAAAAAAAAAsABAAAAA
AACwAAAAAAAAACoAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAEQAAAAEAAAADAAAAAAAA
ANoAYAAAAAAA2gAAAAAAAAAOAAAAAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAEAAAADAAAA
AAAAAAAAAAAAAAAAAAAAAOgAAAAAAAAAFwAAAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAA=
END
( chmod +x "$tmpFile"; exec "$tmpFile" )
echo end...
base64 명령은 바이너리 파일을 텍스트 파일로 변환해 주는 유틸입니다.
변환할때 6 bits 를 1 문자로 바꾸는데 이때 사용하는 문자셋은A-Z,a-z,0-9,+,/총 64 문자 (2^6 = 64) 입니다. ( 이것이 명령 이름에 붙은 64 의미입니다 ) 예를 들어 3 bytes ( 3 * 8 = 24 bits ) 를 변환할 경우 결과적으로 4 개의 문자가 ( 24 / 6 = 4 ) 생겨서 4 bytes 가 되므로 실제 파일 보다 약 33% 정도 크기가 커집니다. base64 를 사용하지 않고 hex 로 바꾼다면 1 byte 당 2 문자가 필요하므로 파일 사이즈가 2 배가 됩니다.
binary 파일을 직접 append 하는 방법
이 방법은 base64 인코딩을 거치지 않고 binary 파일을 직접 스크립트 파일에 append 합니다. binary 파일은 압축파일, 실행파일, 이미지, 동영상 어떤 종류던 상관없습니다. 인코딩에 의해 파일 사이즈가 커지지 않으므로 프로그램을 쉘 스크립트를 이용해 배포할때 주로 이 방법을 사용합니다.
1 . 먼저 append 할 binary 파일의 사이즈를 구합니다.
$ stat -c %s binaryFile
512
2 . 그다음 아래와 같은 내용의 스크립트 파일을 먼저 작성합니다.
이번에는 sh 로 작성하였습니다.
base64 를 이용하는 방법에서는 없었던 tail 명령이 사용된 걸 볼 수 있습니다.
이 부분이 스크립트 파일에 append 된 binary 파일을 추출하는 과정입니다.
그리고 마지막에는 반드시 exit 명령을 사용해서 종료해야 합니다.
그렇지 않으면 실행이 append 된 파일까지 넘어갑니다.
#!/bin/sh
[ "$(uname -mo)" = "x86_64 GNU/Linux" ] || { echo "binary can't execute"; exit 1 ;}
trap 'exit' HUP INT QUIT TERM
trap 'rm -f "$tmpFile"' EXIT
scriptFile=$0
tmpFile=`mktemp -p .`
# tail 명령으로 append 된 binary file 을 추출
tail -c 512 "$scriptFile" > "$tmpFile"
( chmod +x "$tmpFile"; exec "$tmpFile" )
# 마지막은 반드시 exit 명령으로 종료
exit
3 . 스크립트 파일 작성을 완료하였으면 저장하고 나와서 마지막으로 binary 파일을 append 합니다.
$ cat binaryFile >> test.sh
한가지 참고 해야될 사항은 파일을 append 하고 나서 스크립트 파일을 다시 수정해야될 경우가 생길수 있는데 이때 vi 에디터로 수정하여 저장하면 파일의 마지막 부분에 자동으로 newline 이 붙어서 문제가 됩니다. 그러므로 파일을 다시 수정할 때나 아니면 이미 파일의 마지막에 newline 이 포함되었다면 다음과 같은 방법으로 종료하여 newline 을 제거할수 있습니다.
# vi 로 스크립트 수정이 완료되었으면 다음과 같이 종료해야 합니다.
: set binary noeol
: wq
2.
binary 파일을 hex 로 변경하여 저장하고 다시 hex 파일을 binary 파일로 만들려면 어떻게 할까요?
/bin/date 를 대상으로 hex 변환에 od 명령을, 복구에 xxd 명령을 사용하겠습니다.
# binary 를 hex 로 변환
# od 명령의 -v 옵션은 같은 내용의 라인이 연이어 출력될 경우 '*' 로 표시되는 것을 방지합니다.
$ od -v -An -tx1 /bin/date > date.hex
# 또는
$ xxd -p /bin/date > date.hex
$ head -2 date.hex
7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
03 00 3e 00 01 00 00 00 a0 37 00 00 00 00 00 00
# hex 파일을 다시 binary 로 변환
$ xxd -r -p date.hex > date2
# 원본 binary 와 비교
$ cmp /bin/date date2
$ echo $?
0
.....................................................
$ cmp /bin/date <(od -v -An -tx1 /bin/date | xxd -r -p)
$ echo $?
0
파일의 특정 offset 에서부터 N 바이트 hex 추출
# offset 2 에서부터 4 바이트 hex 추출
$ echo 1234567890 | od -j2 -N4 -tx1z
0000002 33 34 35 36 >3456<
0000010
$ echo 1234567890 | hd -s2 -n4
00000002 33 34 35 36 |3456|
00000008
hex 값이 아닌 정수나 float 값으로 추출하고 싶으면

# 8 바이트 건너뛰고(-j8), 8 바이트를 읽음(-N8), 각각 4 바이트씩을 signed decimal 로 처리(-td4)
# x86 cpu 는 little endian 이므로 03 00 00 00 값이 정수값으로 처리될 때는
# 작은쪽(little) 주소의 바이트 값이 숫자 끝으로(endian) 오게 돼서 0x00000003 이 됩니다.
$ od -j8 -N8 -td4 binary
0000010 3 4
0000020
# 16 바이트를 읽어들이고(-N16) 각각 8 바이트를 unsinged deciaml 로 처리(-tu8)
$ od -j16 -N16 -tu8 binary
0000020 5 6
0000040
# 4 바이트를 읽어들이고(-N4) 각각 2 바이트를 unsinged deciaml 로 처리(-tu2)
$ od -j32 -N4 -tu2 binary
0000040 7 8
0000044