Configuration best practices entail route design considerations. Some important route design considerations are as follows:
- Every filter that modifies the message body results in a write to the disk. The new message body which is the output of the filter is written to disk.
- Every filter that modifies the properties of a message (adds, deletes, or modifies the existing value of a message property) results in a write to the disk. All of the message properties of the message are written to the disk with their current value even when only some of them are modified.
- When the message body is modified, the amount of data written to disk is proportional to the size of the message body.
- The amount of data written to disk is proportional to the total size of the message property values. If more data is stored in message properties, then more data will be written to disk every time the message is modified.
- Every additional filter the message has to pass through adds a performance cost, even if the filter does not modify the message or properties. This includes No-operation filters.
- The size of the configuration increases with additional routes, filters, communication points, and message definitions. The total size of the configuration impacts the performance of Rhapsody IDE, the engine, and the Management Console.
There is typically a trade-off between the performance of a configuration and its readability or modularity. The following recommendations attempt to strike a balance between the two:
- Naming Components in Routes
- Organizing Folders
- Organizing Lockers
- In-Route Documentation
- Route Design
- Queue Depth
- Communication Point Considerations
- Filter Considerations
- Conditional Connector Considerations
- Database Considerations
- JavaScript Use and Features
- Message Mapping Options and Considerations
- Lookup Tables
- Custom Components
- Message Properties
- Rhapsody Variables
- Testing and Peer Review
- Security and Access Controls
- Other General Considerations
Naming Components in Routes
Components should be named per function and purpose. Activities which would benefit from a sound naming convention include:
- Searching for a component in the Management Console.
- Applying a hierarchy to components displayed within Rhapsody IDE.
- Analyzing and understanding the processing logic.
- Streamlining onboarding and knowledge transfer to new team members assigned to a given project and for ongoing support activities.
Refer to Naming Conventions for details.
Organizing Folders
Folders group a set of related components. They are utilized in Rhapsody IDE (and Management Console) to provide structure and organization to the configuration. Use of a structure and meaningful names is important for the following reasons:
- To mitigate long route and communication point names and provide an easily searchable structure.
- As a high-level indication of function/purpose of routes held under the folder (for example, a folder might be used to group processing logic for input from a specific host; the host system type might be included in the folder name).
- As an indicator of a source and/or target system for messaging for the child routes (for example
PAS_ADTorPAS_to_RIS).
The folder structure will be aligned with the requirements of a solution. There are two folder structure paradigms that are most commonly used: SOA/Decoupled Paradigm and Interface/Solution Paradigm. However, a degree of flexibility in the folder structure may be required in order to ensure alignment with customer solution requirements.
SOA/Decoupled Paradigm
Under the SOA/Decoupled Paradigm, folders are organized under the respective locker by system name (for example, PAS, LIS). Each folder typically has subfolders that allow grouping of routes and related configurable components such as:
- Input.
- Processing (such as Normalisation, EMPI enrichment, identifier resolution, common code translation).
- Output.
- Common (for components that are shared for some or all of the above such as the Dynamic Router or Web Service Client communication points).
Folders which are not required can be omitted.
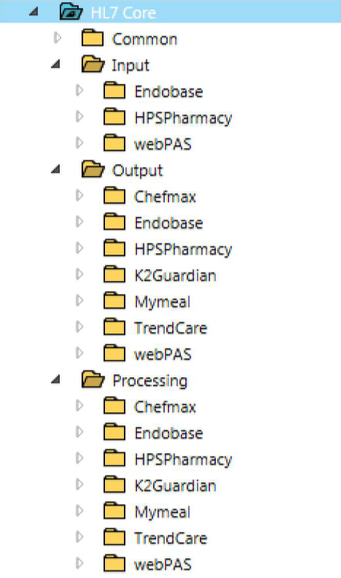
Advantages:
- Already developed components are easily identifiable based on the source, destination or any processing requirements. This makes it easy to identify common components (such as the input part of an interface) that can be reused to meet the requirements of a new interface requiring the same data and/or processing to be output to a new system via a new interface.
- This supports decoupling of systems participating in an end-to-end interface as Rhapsody is the mediator and source or destination may be replaced with change being restricted to the set of components targeted for the new system.
Disadvantages:
- It would not be clear to developers using Rhapsody IDE or administrators performing support actions what components are contributing to an end-to-end interface.
- Management Console users would typically have to start from the input to be able to identify other components that may be related to the interface or problem at hand.
- Additional auxiliary documentation is required over and above what is available within in-route and support note documentation to capture the relationship of the components which together are required for an end-to-end interface – this documentation may not be available within the inbuilt route notes and support notes features.
Interface/Solution Paradigm
Under the Interface/Solution Paradigm, folders are organized based on the interface or solution information (for example OrionReferralNotificationsToGP, PasADTToLab, PasToEMPI, AllDataToCDR, EMPIToSystems, ToMyHR). Within the parent folder, the following subfolders are typically used:
- Input.
- Processing (such as Normalisation, EMPI enrichment, identifier resolution, common code translation).
- Output.
- Common (for components that are shared for some or all of the above such as the Dynamic Router or Web Service Client communication points).
The folders are always present. If they are not required or, more commonly, reused from other interfaces, they can be left empty.
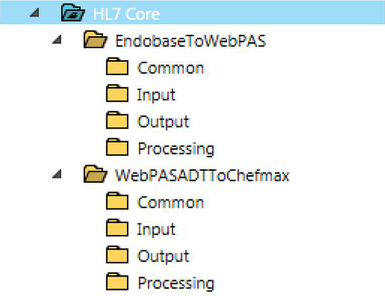
Advantages:
- The interface/solution purpose of the components is grouped by the parent folder name. This relationship is obvious to users of both the IDE and the management console and streamlines the process of searching for related components within the management console for support purposes. Generally, the link to the reusable components (which folder path they are in) can be captured in the newly deployed components and this combined with sensible parent folder names reduces overhead in day-to-day maintenance and management.
Disadvantages:
- Reusable components are not as readily identified as the SOA/Decoupled Paradigm – even though they may still be loosely coupled, they are deployed within the first interface that required them; future interfaces will need to rely on sensible naming of parent folders and auxiliary documentation to be able to identify if there are one or more components available for reuse in a new interface (this is generally not a major issue).
Organizing Lockers
Lockers are used for compartmentalizing the configuration in a way that allows access to that configuration to be controlled. Like a folder, a locker can be used to organize and group components, but a locker also has tools to restrict access (through the Managing Users component) so that only certain users can see and edit the configuration of a given locker, and so that only certain users can view the messages that are processed by the components in the locker.
Best practice guidance with respect to this is to determine the locker requirement on a project-by-project basis – lockers can be added as required to:
- Segregate components to ensure team members are not able to modify components that are not related to their solution or tenancy.
- Ensure that administrative users are only able to access a subset of message data and components within the Management Console (for example, to restrict access to patient data only from their site, or to ensure they are only able to start/stop components under their jurisdiction).
Messages may be directed from one Locker to another however they are only able to be distributed between lockers via the use of Dynamic Router communication points.
Segregating your configuration into lockers is not recommended unless there is a driving requirement to do so, as it increases the maintenance effort. Usage of multiple lockers requires the following Rhapsody objects and related configuration to be within the same locker for messages to flow correctly:
- Communication points.
- Message definition.
- Message tracking scheme.
- Chained/linked route.
Accordingly, they would need to be duplicated into different lockers for message flows across lockers. This results in additional efforts to maintain the components in multiple locations (for example, to add or change a message type in a definition).
In-Route Documentation
Notes
All routes, filters and communication points, where appropriate, should contain the following minimum documentation within their Notes.
| Item | Purpose |
|---|---|
| Author | The user who initially configured the component. |
| Creation | The date the component was created or copied. |
| Purpose | The description of the purpose of the component that explains what the component's intended use is and a summary of how that is achieved. |
| History | Modification history of the component after development (for example, BAU, fixed issue found in UAT). One line per change, each line contains the initials or name of the person making the change, the date, and the change description (include feature/bug ticket reference if available). |
For example:
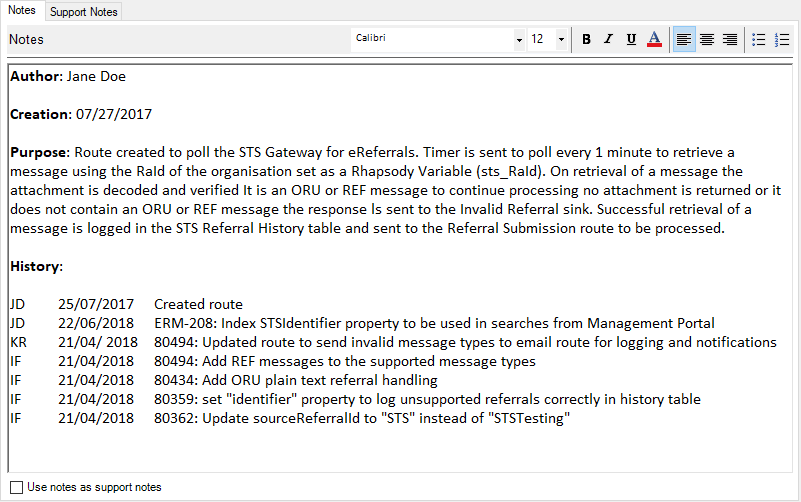
Comprehensive documentation of your configuration aids ongoing maintenance and is also provided in the Rhapsody self-generated documentation. For shared JavaScript library functions, JavaScript filters and Mapper filters this will be included at the start of the code and a summary will be included within the Notes section.
Check-in Comments
For environments that are shared across multiple team members, ensure suitable comments are entered when checking in changes. It can be beneficial to follow a standard format agreed for the project. For example:
Description of your changes Issue: CPO-123456 Reviewer: Jane Doe
Route Design
Discard Before Processing
In general, conditional filtering of messages should occur as early as possible in the processing pipeline to ensure that additional processing of the message is not incurred (particularly expensive operations such as transformation, output mapping, JavaScript filter operations). There are various methods to do so, for example:
- Conditional connector.
- Conditional logic within the filters that support it (for example, the JavaScript filter).
Fail-safe, Fail-early
Do not assume that data sent to a route will always match the specified format. Always ensure that if a given route requires data in a certain format, it is verified within that route before further processing and invalid data is handled specifically (for example, discarded via the No Match connector or passed to an error handling process as may be required depending on the route function).
Error detection should occur as early as practical so that messages are trapped or discarded before additional processing steps are incurred. For example, if a given type of message will always be discarded for a given output ensure that this is detected in the early stages of the output sequence rather than in the later stages.
Intra-Route Error Handling and Exception Processing
Error handling covers a wide range of topics, but the goal is to create a configuration where errors are the exception. Error handling should be actively planned and included as a part of the interface design. Route Error Handlers should be added to each route to handle edge cases/exceptions but it can also be used to direct known errors to appropriate destinations such as email notifications or a sink. The goal should be minimizing the number of errors that go to the Error Queue.
If the Error Queue is left to grow over time without careful management, then it will reduce the data volume available for the live message store. In severe cases, this can lead to disk space for available data running out earlier than calculated or expected.
In-filter processing can also be used to detect certain error conditions (missing information, logical error in a combination of fields, change of the input message type compared to a known structure, a message that is not valid based on business rules rather than format/definition). The JavaScript filter can be used to call the addErrors() method in these types of scenarios to add specific information about the error and then cause the message to be output to the error connector/path of the route
The method for handling the errors will be determined based on the interface pattern and requirements. However, in all cases, Error Handling should be designed and implemented (as per pattern and customer requirements) so that it is adopted from initial configuration forwards rather than added on at the end.
Options for handling errors include:
- Unhandled - the message is sent to the Error Queue (this should be the last resort, not the norm).
- Direct handling - logic is implemented to manage messages with known errors; the error detail is available from the message object by calling the getErrors() method in a JavaScript filter. Once processing is complete, the message may then be:
- Ignored, as this is a known error which does not require further processing, and output to a Sink.
- Handled explicitly by output to a Communication Point/Route for this purpose (for example, to automate raising a helpdesk ticket or to email specific people with the event details).
- Re-routed to the Error Queue.
Errors relating to filter failure (rather than processing of the message content) bypass the Error Output connection and are placed directly into the Error Queue. For example, system level errors will result in this behavior.
Route Layout and Processing Complexity
In essence, the route design canvas of the IDE presents a map or a flowchart of the high-level logic required to process messages. The following guidelines are recommended to ensure that the flow of data through a route can be easily interpreted and checked to ensure that the route logic is consistent with the requirements as well as for streamlining support and maintenance:
- Message path flows generally from left to right (input to output).
- For some scenarios, the route may output then return to an input path such as when processing a message and then the Acknowledgement via an Out->In communication point. This is a normal scenario and the flow is still generalized as left to right, similar to the operation of a cursor on a page of typing.
- Input connections should be made from a component to the left of the filter.
- Output connections should be made to components to the right of the filter (this also includes No-match and Error connection points).
- No-match connections should generally be made above and to the right of the filter.
- Error connections should generally be made below and to the right of the filter.
- Note that the use of the Route Error Handler may streamline error processing and avoid requiring individual paths from Error Connectors, as well as No-Match Connectors in some scenarios (if a condition is not met and there is no path from the No-Match the message will route to the error path).
- Connector paths do not cross each other (this can often be achieved through the use of additional No Operation Filters).
- Avoid loops in the configuration that bring the message back to an earlier point in the same route.
Overly complex routes with multiple significant branching and/or return to filter components generally indicate that the configuration is attempting to achieve too much in a single route. In this case, consider splitting the single route into several route stages, each of which performs a specific function before passing the message to the next stage for processing. This can be achieved either using Dynamic Routers or through Linking/Chaining Routes.
The following screenshot shows an example of a monolithic route that would be better deployed as a series of route stages to simplify the overall layout and avoid potential logic issues:
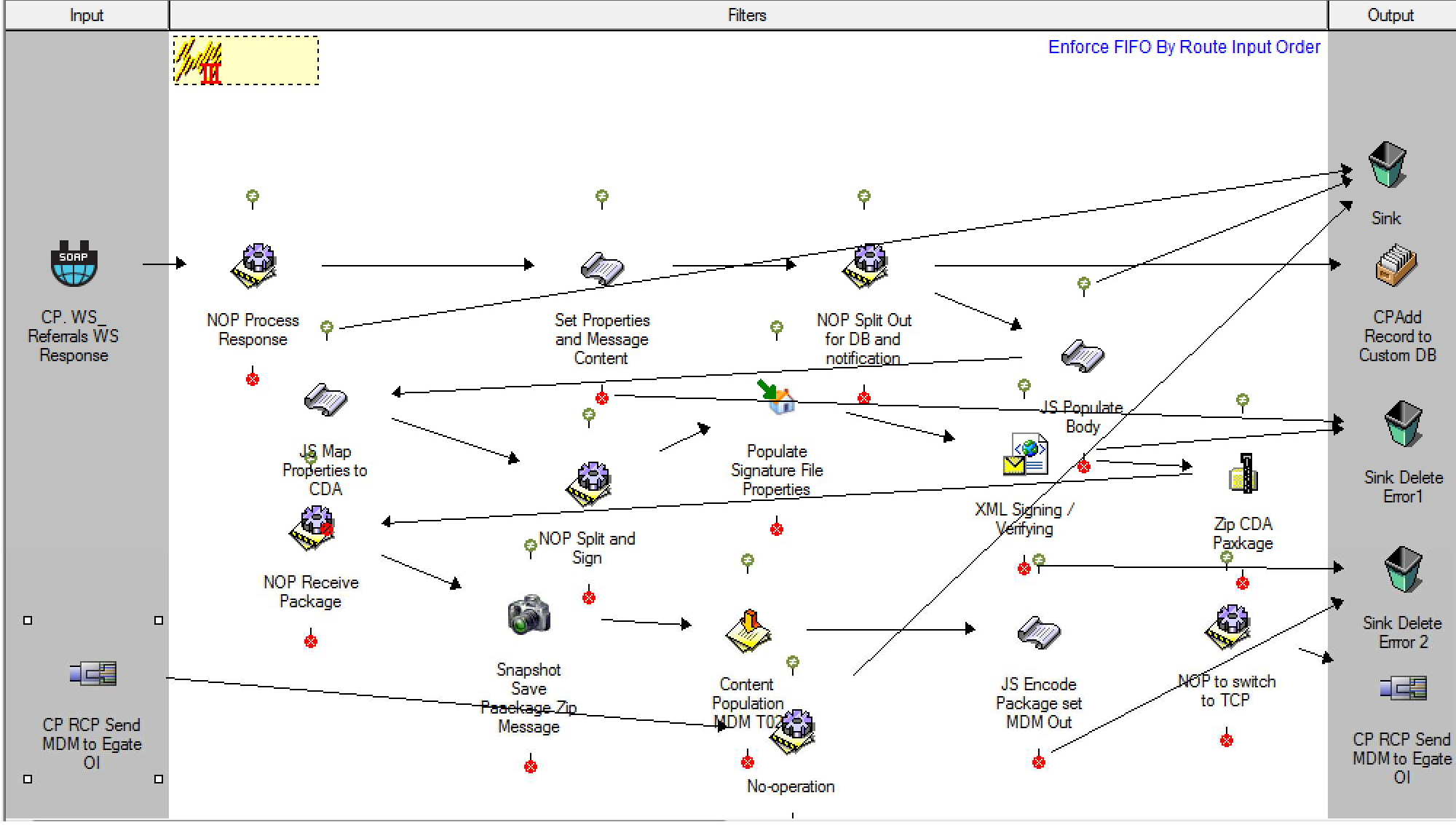
The following screenshots show an example of simplifying layout and targeting smaller, more specific, areas of functionality using several route stages.
A Simplified Route Layout - Stage 1:

A Simplified Route Layout - Stage 2:
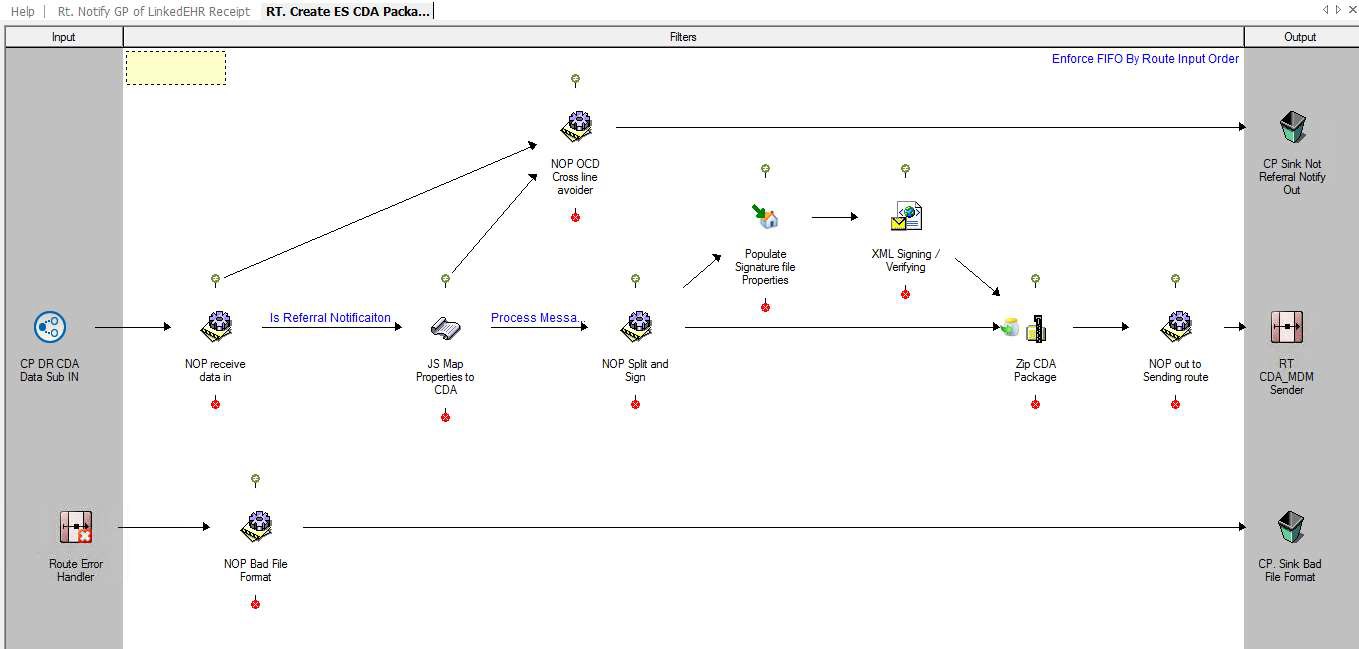
A Simplified Route Layout - Stage 3:
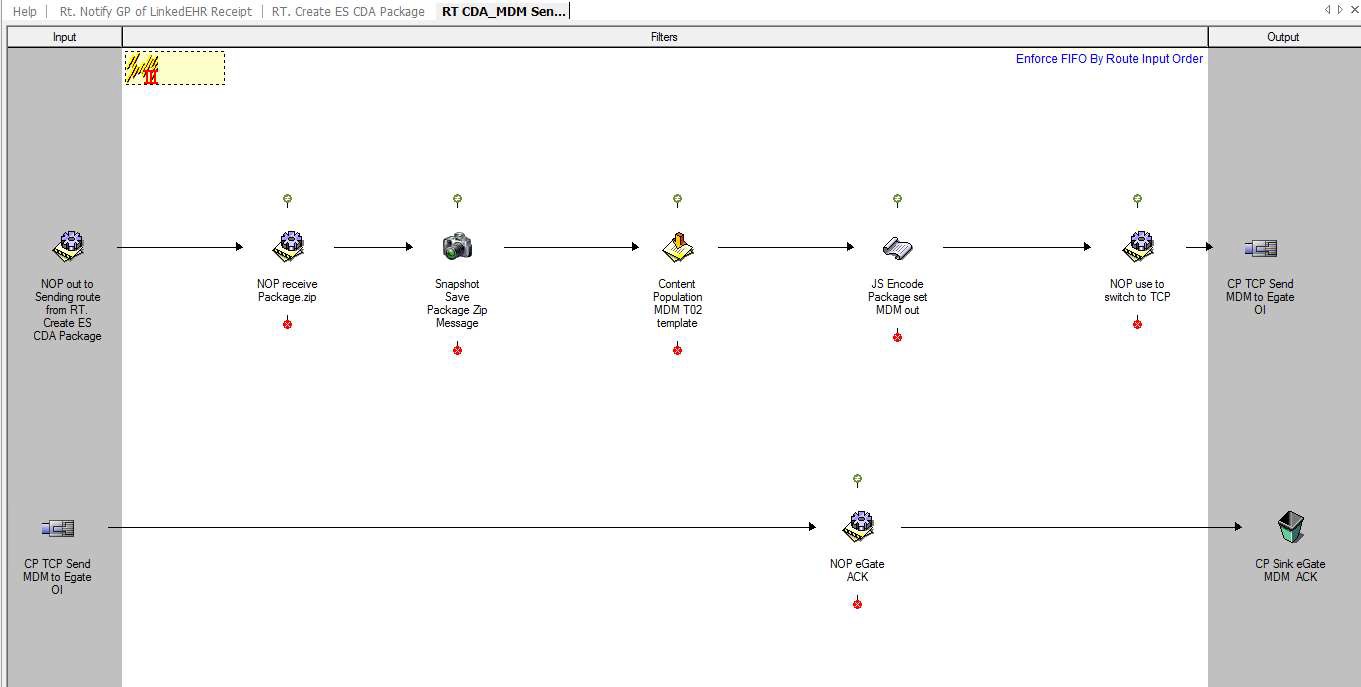
Linking/Chaining Routes
In a complex configuration, it is often useful to distribute the processing logic across multiple routes, limiting each route to one high-level function and ensuring that the clarity and purpose of each route are maintained.
In some scenarios, it may be beneficial to directly link the routes in a chain (this is generally the case where the overall requirement cannot be achieved unless all the links in the chain execute in sequence). For other cases, the use of dynamic routers would be recommended to separate the stages of the route processing.
When routes are chained there is a risk that re-arrangement of filters or changes to message paths may lead to disconnection of the link. For this reason, when chaining routes together follow the following process to ensure the connections are managed properly and can easily be identified:
- Place a No-operation filter as the last processing element in the up-stream route.
- Place a No-operation filter as the first processing element in the downstream route.
- Drag the downstream route (selected from the configuration workspace) onto the output side of the up-stream route.
- Connect the No-operation filter on the upstream route to the route icon in the output frame. This will place the connection into the correct location on the paired route.
- Connect the No-operation filter on the downstream route to the connection icon in the Input frame.
- Check in both routes to save the configuration.
This model is often described as providing bookends to the routes, and generally protects the connections between the routes. It is, however, prudent to confirm the connectivity between the routes if changes are made to either route.
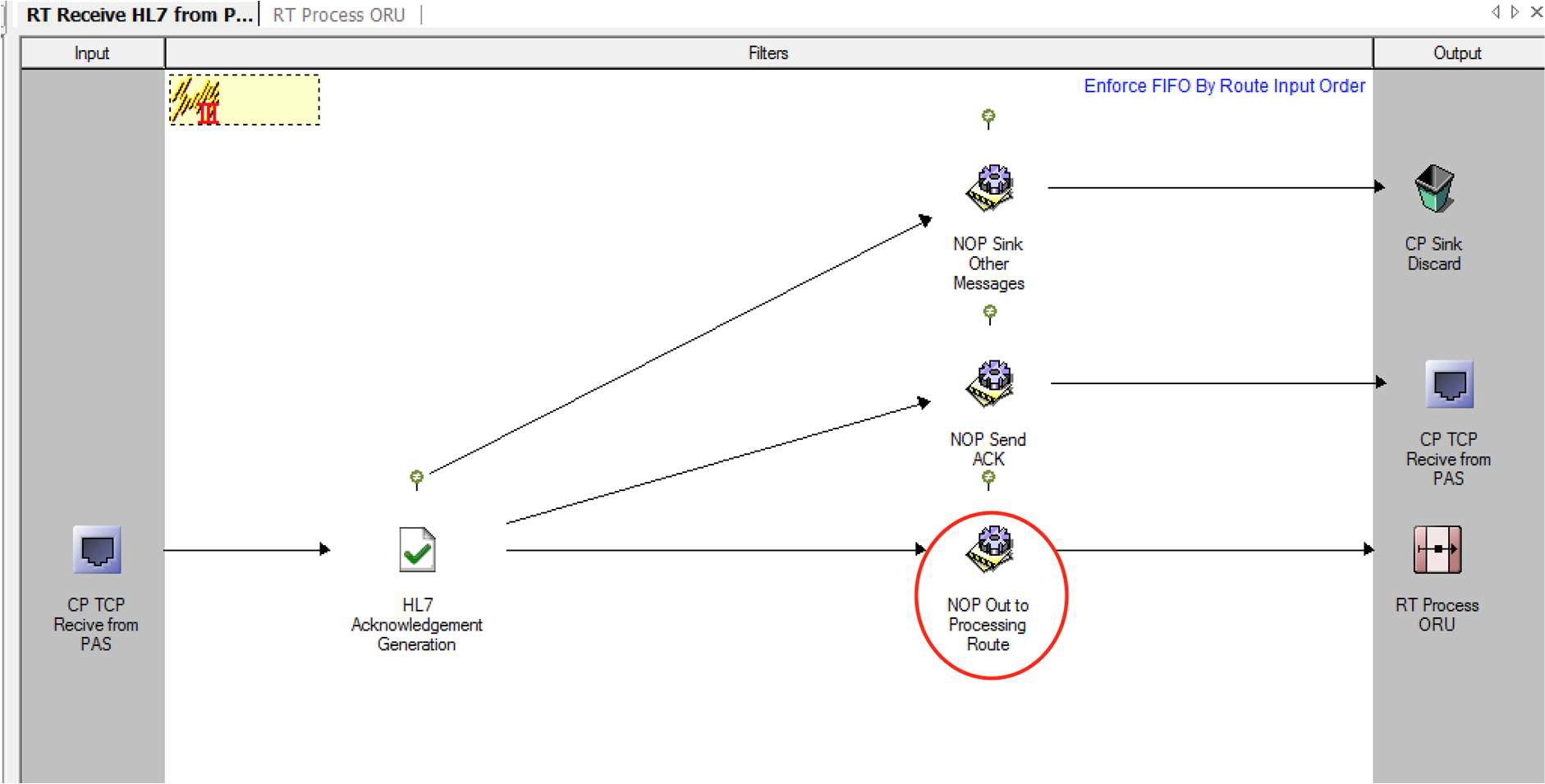
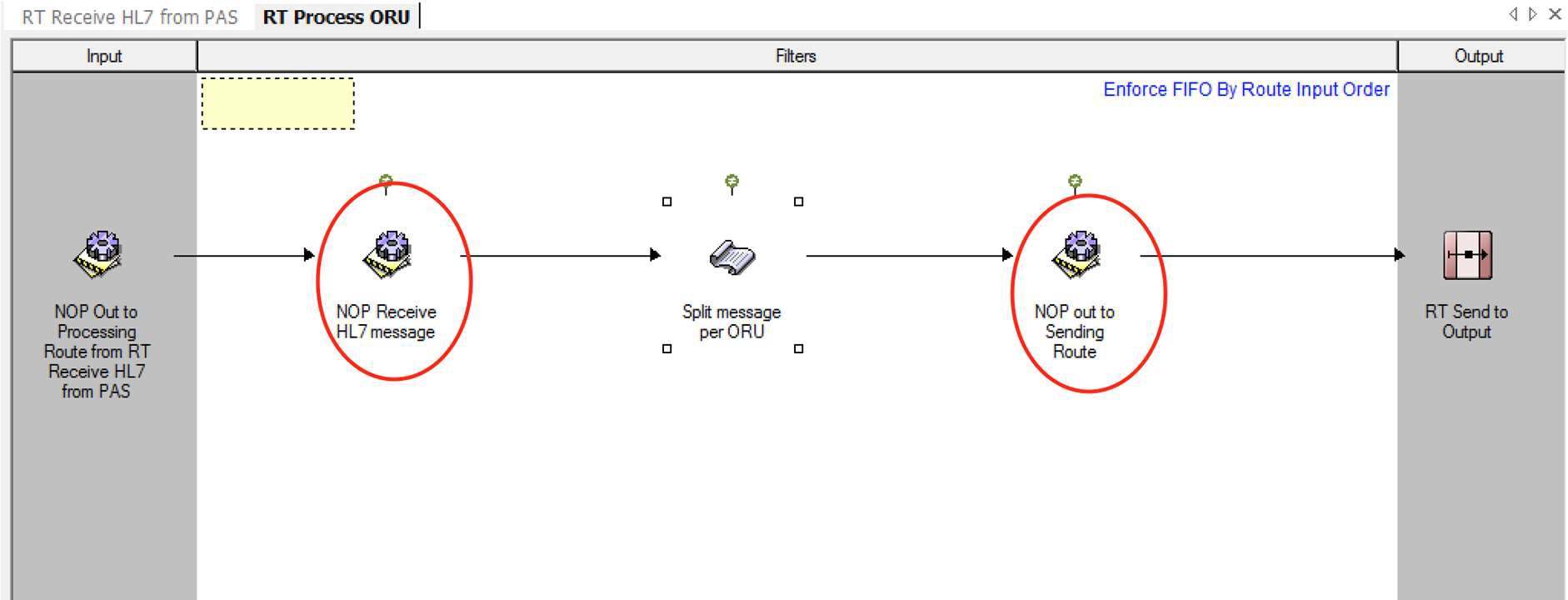
Multiple input connections may be made to the output route icon in the up-stream route. Each will result in a separate input connection to the downstream route, thereby allowing separation of processing for each path.
Message Definitions and Parsing
If a message definition is placed on the route, message parsing will occur prior to processing by the first filter on the route. This ensures that properties defined at route level are available to condition connectors and certain filters.
Message parsing is required by the following communication points and filters:
- HL7 Acknowledgement Generation filter.
- EDI Message Validation filter.
- Content Population filter.
- Code Validation filter.
- Date Validation filter.
- Mapper filter.
- Code Translation filter.
- JavaScript filter (if the message has not previously been parsed)
- XSD Validator filter.
- HIPAA filters.
- Database filters and communication points that use message fields in the query.
As message parsing incurs a processing cost, it should only be undertaken when necessary. Use the following guidelines to avoid unnecessary re-parsing of messages:
- Place only one message definition on a route if parsing is required for the route to operate.
- A message definition is not required for the following routes:
- Pass-through routes.
- Routes with messages that are processed purely using the following methods:
- String-based processing.
- XML processing via E4X.
- XPath processing of well-formed XML.
- HAPI message processing (as HAPI does not require a message definition).
- Using only the HL7 Message Modifier filter.
- JSON processing.
- Certain scenarios using Web Services or Database Orchestration
- Avoid using multiple filters which require message parsing when possible:
- JavaScript filters cause a message parse operation for each filter – where possible combine multiple JavaScript filters into a single filter (the use of shared JavaScript libraries can be used to offset the overall complexity and maintenance effort for single JavaScript filters. Refer to JavaScript Use and Features).
- Message Validation filters on a route with JavaScript or Mapper filters – often the validation component can be achieved within the other filter, allowing removal of a parse operation.
- Property Population filters which map message fields to properties on a route with JavaScript or Mapper filters – again, these filters can typically achieve all the required functionality
- Avoid adding multiple message definitions to a single route. Rhapsody does not guarantee which message definition will be used in this scenario. The first definition which allows a successful parse may not necessarily be the expected one, which can lead to inconsistent results. Typically, if a pattern looks like more than one definition is required on a route to achieve the outcome then it is probable that:
- The solution is performing a mapping operation that is better suited to the Mapper.
- The route should be split into multiple stage routes each targeting a specific area of functionality and only requiring at most a single definition per stage.
Multi-threading versus Single-threading
Rhapsody is a multi-threaded Java application and uses 10 worker threads (by default) to manage all the route processing. In general, the processing cycle typically has the following states:
- Route worker thread becomes available.
- Next route operation selected from the queue (each operation equates to processing one message through a single filter).
- Processing transaction starts.
- Message processed by the filter logic.
- Processing transaction completes.
- Route worker thread becomes available.
This design enables multiple messages on a route to complete processing by a filter at more or less the same time, unless either filter concurrency restricts processing or the route is constrained to processing in strict message order by FIFO constraints.
The filter concurrency is normally set to zero which allows the multiple and potentially out of order processing (note however when FIFO is set on a route even though the messages may be processed out of order due to different paths or complexity of messages in a given route, the messages will always leave the route in the FIFO order received). It may be necessary to limit concurrency in one of the following cases:
- Message processing order is significant - messages must process in the order of receipt (particularly if there is an in-route orchestration and the processing result of a later message would be different if the earlier message has not processed).
- Slow filter processing - in these cases, under moderate to high loads, it may be possible for all of the worker threads to be processing messages through an instance of the same filter at the same time which will effectively block other processing.
Filter Concurrency is available as a filter property for filter types likely to experience this issue. Setting the concurrency to a non-zero value limits the number of messages able to be processed through the filter instance to that value. The Database and Execute Process filters are particularly prone to needing attention to concurrency.
Dynamic Routers
Use of the Dynamic Router communication point (dynamic router) is recommended for decoupling routes which publish and distribute data, process data or subscribe to, or receive and send data to downstream systems. Earlier versions of Rhapsody were constrained to the use of chained routes to achieve the same outcome. Use of dynamic routers at the boundaries of internal routes are advantageous because new consumers of existing data can be added in the future without needing to modify existing, validated, in-production configuration, thus mitigating the risk of introducing issues or regressions to the current function.
However, because data is Published/Subscribed to in a dynamic fashion there is potential to introduce issues within configuration if the following guidance is not followed:
Subscribers (routes which use a dynamic router configured for input mode):
- A route which contains that input dynamic router should verify the data is of the required type before performing any operations. This prevents errors or exceptions as data sent to the input dynamic router could change after deployment. For example, a source system could start sending new data types via an existing input interface or a newly deployed configuration could match an existing target name of an input dynamic router.
- If present, the
router:Destinationproperty should have the current value removed (set the property value to null if it is not required, or to a specific value as required) to ensure that processing through any down-stream output dynamic routers does not result in route loops.
Publishing routes (routes which use a dynamic router configured for output mode and may use dynamic destination lists set via in route JavaScript processing):
- Use Target Name (for example,
@theTarget) if possible, multiple receivers can be configured with the same target name to receive the set of data from the output dynamic router. This method is simpler to manage and less prone to error than the path method. It supports delivery to multiple components with the same target name. In addition, the path value would have to be updated if the component is moved within the IDE to a different path. - While a single instance of a dynamic router, using dynamic destinations, can be used in multiple routes to reduce communication point clutter, there are disadvantages to this approach which need to be balanced for a given solution’s requirements:
- The Archive queue will contain data sets from the multiple routes – this may obfuscate the cause of issues or increase overhead for some Management Console administrative tasks.
- If the communication point must be shut down for any reason it will block the output (and result in queuing) for all routes that this output component is contained in.
- Where destinations are set dynamically, care must be taken if the list of destinations being set within the JavaScript filter is populated from a source which can change (for example, a lookup table). If a target name does not exist, the message will be routed as per the configuration setting for On Missing Dynamic Destination.
- We recommend immediately adding an input dynamic router with a matching Target Name and checking in the component whenever making changes to dynamically generated destination lists.
- Where retiring a component, remove the destination from the generated property list first then retire the matching input dynamic router component/route
Identifying Bottlenecks in the Route
When you create a route, it is recommended you identify the bottlenecks in order to optimize performance. In the Management Console, there are a number of reporting options available that can help with this. The performance statistics report can be used to identify which filters in the route take the most time to process the message. However, as there is a processing overhead when running a performance statistics report, it is recommended running it in a non-production environment.
Queue Depth
Communication points (depending on type) have an input and/or an output queue (depending on their directionality) while routes have a processing queue. In general, messages flow through the Rhapsody engine more or less unhindered. Messages may queue on some components at some stages because of load, slow processing or some external factors, but queuing is generally transient.
Factors which can impact the size of queues include:
- A requirement to throttle messages or only send messages to downstream systems during certain hours
- An issue at the receiving system end that will result in a backlog within Rhapsody until the issue is resolved
- A system which sends messages in large batches or bursts (either due to the nature of the information exchange or because it has been offline and needs to send a large amount of data that would normally flow over a longer period at a lower rate of messages per minute)
- A system is decommissioned while messages are still being processed within Rhapsody
- Resource intensive message processing and/or very large message processing within a route
- Single threaded/Strict FIFO requirements
Attention should be paid during route development to the potential for messages to queue (particularly with respect to the last two list items above which are controlled by Rhapsody). To reduce the potential for queueing:
- Develop a solution using standard product-supplied Rhapsody communication points and filters in preference to developing custom components. This reuses code libraries as typically the product-supplied components align with, and are tested with respect to, Rhapsody performance and multi-threading capabilities (which in turn generally avoid large processing queues in most scenarios).
- Constrain the use of Strict FIFO or interfaces with filter processing that requires no concurrency to only those use cases which absolutely require it to ensure minimal impact to engine performance and queue depth.
- Ensure components are correctly configured with Auto Start parameters to ensure queues do not form because one of the components has not started.
There are several significant impacts of queuing on the engine:
- Queues are managed as memory objects; consequently, large queues will lock memory for the queue and make it unavailable for normal processing.
- When an engine restarts, the active objects are validated before processing can resume; consequently, large queues will take a finite time to validate and delay the resumption of normal processing by the engine.
- Messages on queues are not eligible for removal from the data store by the Rhapsody Archive Cleanup process (for the scenario of a decommissioned system the messages may need to be manually deleted from the queue so they are eligible for clean-up).
Communication Point Considerations
- Wherever possible use an instance of a communication point on a single route only. This provides advantages in terms of storage, queue management, and message tracking.
- There may be limitations and considerations for a specific solution (such as the licensed number of communication points) that need to be considered.
- In some cases, it is advantageous to reuse a communication point on multiple routes to reduce maintenance overhead and effort for those communication points with significant configuration components – web service clients connecting to the same service with a number of different methods are an example of this. Database communication points used to log/store all received messages may be another.
- Use multiple sinks rather than a single, general purpose sink. This allows you to see how many messages are being discarded for a particular system.
- Communication points such as sinks and dynamic routers where messages do not enter or leave the engine instance do not count towards the licensed number of communication points.
- De-batch large messages in a Directory communication point instead of a de-batching filter (either the Batch/De-batch or Zip/Unzip filter). This is more efficient as the communication point can read each message out of the batch from disk without loading the complete batch into memory.
- Ensure the Connection Retries property for a communication point is set appropriately for the system that it is connecting to, and has been tested to ensure it is tuned appropriately.
- Where multiple actions need to be performed on a message when it is received on a given route, it should be received on the route then split via the use of a No-operation filter for each action. Do not directly split the input from the input communication point as this results in duplicate parsing of the message and duplicate storage of the input message and properties within the Rhapsody datastore.
- Where connections between two Rhapsody instances is required, the Rhapsody Connector communication point should be used instead of the TCP communication points.
Filter Considerations
- Pay attention to earlier recommendations for combining filter functions where possible to avoid multiple message parses and increased data store volume use.
- Only set filter concurrency to a non-zero number if performance analysis indicates the filter is consuming large amounts of resources and is negatively impacting overall system performance. Setting filter concurrency to 1 will greatly reduce the throughput (as the route will become single-threaded) and is only required in a small number of use cases (such as where absolute FIFO is required within the route, rather than simply for end-to-end message delivery).
- The use of database filters is only suited to certain scenarios, as outlined in the Database Considerations.
- Avoid using excessive No-Operation filters for route commenting – this practice introduces excessive growth of the events within the Message Store and has been demonstrated to negatively impact large-scale deployments. No-operation filters should only be used to:
- Split message processing paths.
- Improve route layout by avoiding crossed connectors.
- Support Message Collection (if this feature is used, ensure that the name of the filter reflects this).
Conditional Connector Considerations
Override the Condition Description
Always override the default condition description for the connector and replace it with the shortest text that makes sense to describe the condition (for example, is Required Message Type, eReferral Only).
Rhapsody Variables in Conditional Connectors
Though Rhapsody variables can be used for any value that may require an update in future, it is not recommended they be used in Conditional Connectors for the following reasons:
- The condition they are matching is not immediately obvious when viewing the component or troubleshooting condition test results – the user must access the Variables Manager which cannot be opened at the same time as the UI component of the Conditional Connector.
- In the current Rhapsody version (and all previous versions) they are not exported between environments unless you select the Export Unused Rhapsody Variables option – this can result in a lot of unnecessary clutter in the downstream environments which will have to be manually mediated.
Database Considerations
Refer to Database Components Best Practice Guide for details.
JavaScript Use and Features
Coding Guidelines
The following general guidelines are the general guidelines for writing JavaScript code within Rhapsody.
Dos:
- Use shared JavaScript libraries to add functions that can be re-used across JavaScript filters.
- Improve code readability and self-documentation through the longhand versions of constructs such as the ternary operator.
- Code within the JavaScript filter or the function within the JavaScript Library should follow the same documentation convention as the route notes for capturing the date, author, purpose and modification history.
Don'ts:
- Avoid using multiple JavaScript filters in the same route. Instead try to combine into a single JavaScript filter where possible, and utilize the shared JavaScript feature to reduce filter code complexity.
- Do not use system commands, for example
System.getProperty(). These calls are generally synchronized so that two calls cannot be made at one time. - Do not use
System.exit()in any JavaScript filter as this will cause processing to halt. - Do not create delays in the code of a JavaScript filter. If a delay is needed, If a delay is needed, use Message Collection functionality in the route.
- Avoid intermingling
setFieldandGetTextcalls in your code. This switches the editing models (from parsed message to message text). - Avoid excessive commenting – code developed following the above guidelines should be readable and self-documenting, comments should be used to identify major features, executions or considerations of the code.
Using Shared JavaScript Library Functions
We recommend using shared JavaScript library functions wherever possible as this ensures a central location for management, testing, and updates (rather than requiring each JavaScript filter that may contain a copy of the code to be updated). This, in turn, streamlines the code within shared JavaScript filters and supports scenarios where multiple JavaScript filters can be combined into a single filter without combining large amounts of JavaScript code in the single filter.
When creating shared JavaScript library functions take the following into consideration:
- The shared JavaScript library function does not have scope visibility of the standard JavaScript objects available to the JavaScript filter (such as the Input and Output message or the log). Ensure you pass these as parameters where required.
- Shared JavaScript library functions can only access other shared functions that are contained in the same library in the current version.
- For debugging during initial development, it is often better to build and test the function within a JavaScript filter and then promote it to the shared JavaScript library (taking into consideration any scope dependencies as previously noted).
Considerations for Multiple JavaScript Filters and Parsing/Route Performance
The use of multiple JavaScript filters can have an impact on the performance as each filter requires a parse of the message, thereby resulting in multiple parses (note this is not the case if there is no message definition on the route in question). In some cases, multiple JavaScript filters may be required due to reasons such as:
- Processing logic – for example after a message has been processed by a JavaScript filter, it needs to be split because one path requires the message/properties at that state while the other path requires additional processing by a separate JavaScript filter before being output from the route.
- Separating complex JavaScript operations into discrete units of function to simplify testing and maintenance. There are two strategies for solving this issue:
- Move the unit into multiple shared JavaScript Library functions (which are tested and validated separately, and may be maintained separately) and then call the functions from within a single JavaScript filter. This is the preferred method – particularly where the presence of a message definition on a route would otherwise cause multiple parses of the message.
- If there is a compelling reason to use multiple JavaScript filters for a given solution’s requirement to separate the processing into functional units, ensure that this method is only used on routes that do not have a message definition associated with them. This can be mitigated for routes that do have a message definition associated with them if the performance testing demonstrates no significant difference in route transit time for the use of multiple JavaScript filters compared to a single filter.
Message Mapping Options and Considerations
General Considerations
Message mapping and transformation is supported through a number of Rhapsody features and components. Previously, the general rule was to use the Mapper filter as the compiled code was more efficient than the other available options. However, improvements in engine efficiency mean that while this is still generally true, the difference in execution time is often insignificant and several other factors and constraints must now be considered when deciding how to manage message mapping:
- The Mapper filter requires a Mapper Definition File, which in turn requires an input definition and output definition file for the message formats. The usage of the Mapper filter is generally better suited to scenarios where there is a significant difference between the input and output format and where significant effort is required in mapping between them.
- Mapping or transformation that involves a small number of fields is better suited to the JavaScript filter (which may include the use of the shared JavaScript libraries) since the transformations can be grouped as execution lines and readily identified when maintaining the solution. This is often the case when the input and output formats share a format definition. Even for cases where the definitions are different, the same requirement can be achieved for smaller transformations by either using the HAPI libraries or splitting the transformation into an input and output stage each with a separate message definition (providing that while different, the definitions are still compatible).
- Mapping HL7 to XML or vice versa can be achieved through either the use of E4X template processing within the JavaScript filter or by using the Mapper filter. Please consider the following exception scenarios:
- When dealing with scenarios that require insertion of XML snippets into an existing XML document, these are currently best suited to delivery via mapping in JavaScript filter using E4X processing.
- When parsing large XML files while performing mapping to and from XML, these are currently best suited to delivery via mapping in Mapper filter.
- Mapping where features required are only exposed through JavaScript Objects will require the use of the JavaScript filter, for example:
- HAPIMessage Object.
- JSON object.
- Snapshot loading and processing (especially where multiple snapshots are used).
- Mapping and transformation of messages that are known to not always conform to a strict message format are generally best handled within the JavaScript filter (this is often true for like-for-like migrations of legacy interfaces where input messages may need to be processed without definitions to correct or retain format/value issues within the message) as there may be the potential to correct or ignore the error and continue processing. Use of the Mapper in this scenario will either fail or ignore depending on the Fail on Errors property configuration of the Mapper filter.
- Mapping via the use of the Intelligent Mapper will require the development of the mapping within an Intelligent Mapper mapping project along with the use of the Intelligent Mapper filter (this is effectively a specialized version of a JavaScript filter that only supports the use of the read-only JavaScript Mapping developed within the project).
Specific Considerations for the Mapper Filter
- Use submaps for code reuse and easy maintenance.
- Structure your maps based on the output message structure.
- When using the Automap feature of the Map Designer care must be taken. This feature is best suited to message types where the input is very similar to the output; where this is not the case some components may not be auto mapped and “To Do” sections will exist which require manual coding for the mapping. Therefore, always ensure that if the Automap is used the code is searched globally for “To Do” sections and these are completed prior to use in the engine.
Lookup Tables
Lookup tables within Rhapsody provide more flexible options and better performance than database filters such as the Generic Code Translation filter. They are typically suited to situations where less than 600,000 rows are expected. Moreover, they may be accessed directly from within JavaScript and Mapper filters as part of message manipulation operations rather than requiring a separate component execution (communication point or filter).
Care must still be taken to ensure code which uses these features is safe. However, as they are part of engine runtime processes, they are less prone to errors as may be encountered with database filters (such as connectivity failures).
Custom Components
Custom components, which are developed using Rhapsody RDK, should only be used when the required functionality cannot be achieved using standard Rhapsody communication points and filters. The default position should be to use the Rhapsody standard components if they can achieve the outcome because:
- Custom components may not provide the same level of detail for logging and Management Console.
- Custom components typically require a different skill set to produce and maintain when compared to standard Rhapsody components.
- They are not supported by Rhapsody – any issues with custom components are the responsibility of the client to maintain and resolve.
- Reuse of existing customer libraries via the RDK can lead to issues due to:
- Java version issues.
- Execution of multiple functions which negates the message inspection, logging, and management aspects of Rhapsody.
Custom components may be required or considered where:
- Connectivity to a system or function is provided by a third-party software component (API, EJB, etc.) that is not directly supported by current Rhapsody components, for example calling Oracle HMPI EJB functions to retrieve a patient Single Best Record.
- The functional requirement is of significant benefit to the solution or is a key requirement for the solution but cannot be achieved by the current out-of-box components (for example development of signing and encryption filters using ADHA libraries to upload documents to My Health Record).
When developing a custom component follow these processes:
- Raise a Jira ticket for development review of the proposed component development to ensure that:
- Similar functionality is not on the roadmap.
- The proposal is sanity checked.
- If the feature is beneficial to multiple customers or the product, there is an opportunity to uplift the component to become a standard feature of the product
- Ensure the target functionality of the component is specific - the component should not generally encapsulate multiple unrelated functions (unless this is the requirement for the component such as may be required to manage a distributed transaction with orchestration). This is to streamline troubleshooting and maintenance efforts.
- Ensure the logging events are in line with standard Rhapsody components so that the information presented to the user within the Management Console is consistent with other standard components.
Refer to Rhapsody Development Kit for details on how to build custom components.
Message Properties
Avoid Assigning the Message Body to a Property
Some implementation scenarios require capturing a snapshot of a message body as a property so that it can later be retrieved. In versions of Rhapsody before Rhapsody 6.2.1, message properties were used for this purpose. However, message properties are not designed to convey large amounts of data. Doing so has a negative impact on performance as well as increasing the amount of data store used for each message operation. This can be avoided as of Rhapsody 6.2.1 by one of the following methods:
- Using the Snapshot Save filter to save the current message and its properties. This can then be used to achieve the desired outcome by:
- Using the Snapshot Load filter for simple scenarios where you want to replace the message on the path with the previously saved snapshot.
- Using the JavaScript Object functions to load the snapshot or load a snapshot by ID. While the
rhapsody:SnapshotMessageIdproperty contains only the most recent saved snapshot, it is possible to save and retrieve multiple snapshots using custom properties and then load them through the JavaScriptloadMessageSnapshotForIdmethod
- Saving a temporary message into a database using a Database communication point (via a stored procedure) and store the return value (a unique link to the stored message) as a message property. This can then be used by a downstream process to retrieve the saved message from the database and process it (refer to Database Considerations). This is crucial because message snapshots can only be loaded while they are present within the Rhapsody Data Store (within a single cluster only), in other words, while they have yet to be removed by the Archive Cleanup process, or processed to a different cluster. In most scenarios, this is not an issue as a snapshot is not eligible for removal in the time frame where a typical sequence of route processes is executing in a single cluster. However, there can be a significant delay (from days to weeks) between the process that stores a temporary message and the process that completes the output, or where the message is sent to another functional cluster via a Rhapsody Connector.
Managing Message Properties
As they flow through the engine, messages can accumulate message properties. This can result in 'message property spam' in later routes where large numbers of message properties have to be managed and understood in downstream use. This can impact the effort required to analyze message property changes on a message path in the Management Console. Large numbers of properties also impact the size of data store use and overall engine performance.
The following strategies are recommended for managing properties:
- Custom properties which are important for use in downstream routes deployed by a solution should be documented in a property register for easy reference by future teams maintaining or extending the solution (for example, the set of properties set by the publisher of data which can be used by subscribers to determine if the data should be processed or filtered out).
- Custom properties received by a downstream route that are no longer required should be removed after use when possible (by setting the property value to null).
As this typically requires a filter, this should be done when a given route stage would already be utilizing a filter such as the JavaScript filter which can update the properties rather than adding a filter solely for this purpose, unless the downstream properties are unmanageable in number.
If a large number of properties are required for downstream processing consider creating a JSON object to contain all the property-value pairs, this could be set as the message text and saved as a snapshot for use in downstream routes and filters rather than polluting the message properties with large numbers of properties.
Indexing and Searching
By default, Rhapsody properties are not searchable within the Management Console. Message properties can be defined as indexed to be used for message searches in the Management Console based on the content of this property, obviating the need for a full meta-search across all messages.
In order to prevent unnecessary processing and disk utilization by the message property indexing logic, ensure indexing is restricted solely to fields that are required for fast lookups on message searches.
Rhapsody Variables
Avoid hardcoding values of ports, IP addresses, hostnames, and other configurable parameters into your routes or communication points. These parameters should be configured through Rhapsody variables so that they are easy to access and change. Using variables exposes configuration settings in one single location that would otherwise be embedded in routes and communication points.
Use Rhapsody Variables for environment-specific parameters such as:
- File paths/directories.
- Email addresses.
- Remote system host and port details.
- Local service host and port details.
- Connection details for external systems and databases such as username.
- Web service URLs.
- Access credentials.
Using Rhapsody variables in this way is also useful when migrating a configuration from a non-production environment to production. Rhapsody variables allow for differences in system configurations between environments and provide a smooth transition of configuration to the production environment as the variables are not overridden by default when Rhapsody configuration is imported from one environment to another. This allows different configuration settings to be used in production and non-production environments. The use of variables also helps expose configurations settings that would otherwise be embedded and hidden, making for quick access and change.
Testing and Peer Review
Peer review is recommended during development and is required before promotion of a solution between environments or merging into a master repository. Peer review should take into consideration the documentation (including route self-documentation, test results, and any documented deviations or design decisions which are not normally considered best practice). The reviewer is typically not the same person who develops the solution.
Development Testing
A solution will require testing and validation to demonstrate the soundness of the solution. Evidence of the completion and result of testing will typically be required by the peer review process and ultimately the customer. The level of testing and related documentation may differ by customer/contract however evidence of completion of the following is expected at minimum before promotion out of the development environment:
- Unit testing of filters and conditional connectors via the inbuilt test feature for:
- Invalid cases
- Valid cases
- Both of which may require permutations based on the number of conditions or branches executed in a given component
- Unit testing of message flow (input, output, property and message change throughout the route as per the message flow in the Management Console) for individual routes
- For both valid and invalid messages, messages which demonstrate conditions of the route end to end.
- End to end message testing for the sequence of routes related to a given interface or set of interfaces for the current solution under development.
Note the following:
- In some cases, it is not effective to test certain conditions at a unit level within the filter test function – particularly if the filter requires the result of processing from earlier route components; in these cases, the testing will revert to the route level unit testing.
- Where a filter test requires a message snapshot the configured property must contain the ID of a message still within the message store if tested within the filter. This may require the use of a hold queue to ensure the identified message is available.
Security and Access Controls
Most communication points support secure transport and/or authentication protocol. Therefore, Rhapsody's default best practice recommendation is to always enable the secure transport options. Refer to TLS/SSL Support in Rhapsody for details.
In addition, where authentication is required (for example, basic authentication, WSS for SOAP, etc.), it is recommended you always opt for encrypted/hashed passwords. This mitigates the risk of plain text credentials being captured in the message log as part of the transported message.
It is also the best practice to keep the security setting identity between the production environments and at least one non-production environment.
Other General Considerations
Assign a Specific User to Run the Rhapsody Process
On the server where Rhapsody is installed, instead of running the application services the default administrator user, set up a separate user to run the Rhapsody service. The two key benefits to this approach are:
- The ability to detect issues that relate to the operating system and Rhapsody interactions and for configuration of operating system and environment settings specific to Rhapsody. For example, setting the maximum number of file handles that can be assigned to the Rhapsody process.
- Ensure that resources assigned to the Rhapsody execution user are not shared with other processes that are not related to the Rhapsody Engine on the server system.
The service account should have access to the requisite network resources and the password policy for the account should be set to never expire.
Account Access to Rhapsody IDE and Management Console
Avoid re-using the default administrator account for multiple users as this makes auditing and tracking of user actions difficult. Ensure that a new account is created for access (either via LDAP or the inbuilt Rhapsody user management) with appropriate roles assigned for each new user. This will enable:
- Restriction of access to Rhapsody IDE features or Management Console functions by role.
- Ability to easily disable a user’s access when required.
- Ability to determine the user responsible for an action based on their user ID (for example, who checked in a given change to Rhapsody IDE).
Cleaning Up Archived Messages
- Schedule routine operations of the Archive Cleanup.
- Schedule the Error Queue Defragmentation process.
Backups
- Consider when to schedule backups – a message backup will pause routes for a short period of time to back up active files.
- Configure an infrequent full backup to the same directory as a frequent incremental; for example, a weekly full backup and a daily incremental backup.
- Each full backup provides a fresh starting point for further incremental backups, rather than having a never-ending chain.
Backups are not deleted by Rhapsody. Refer to Archive Cleanup for details.
Notification Schemes
How notification schemes in the Management Console are configured varies highly from customer to customer depending on their size, priorities of different interfaces and the number of resources in the team administering Rhapsody. At a minimum, the following notification functionality should be configured and tested for every environment:
- The configuration is set up to send notifications to a default administrative user email account or distribution list name.
- Thresholds for warnings and alerts (for example, large queues, communication point shut down, etc.) have been configured inline with the minimum solution/customer requirements.
- The notification event history is included in the scheduled Archive Cleanup configuration as this can build up over time and take up a considerable amount of disk space.