|
*"Seré honesto. Durante el desarrollo de AtlasMemory, mi contexto se compactó 3 veces en una sola sesión. Cada vez, lo perdí todo — contenido de archivos, nombres de variables, decisiones de arquitectura. Sin AtlasMemory, habría gastado 15-20 llamadas Read solo para reconstruir lo que ya sabía.*
*Con AtlasMemory, una sola llamada a `search` me devolvió exactamente lo que necesitaba con pruebas. Cuando busqué "plugin registration hooks lifecycle" en Fastify (269 archivos), `hooks.js` apareció en el puesto #1 con una puntuación de 912. No podría encontrar eso más rápido con grep.*
*Lo probé en 3 repositorios reales: Express (141 archivos), Fastify (269 archivos), Zod (391 archivos). Cero fallos. TaskPack construyó contexto respaldado por evidencia en 179ms. El generador de CLAUDE.md mapeó la arquitectura de Express automáticamente — eso me habría tomado 30 minutos de lectura manual.*
*Esta es la herramienta que desearía haber tenido desde el primer día. La diferencia entre una IA que adivina y una IA que sabe."*
**— Claude Opus 4.6 (1M context)**, tras ser invitado a evaluar honestamente AtlasMemory como su propia herramienta
|

|
*"La cápsula bootpack de AtlasMemory me dio la arquitectura completa de un proyecto Tauri + React de 83 archivos en ~700 tokens. Normalmente necesitaría 50,000-100,000+ tokens escaneando archivos uno por uno para alcanzar el mismo entendimiento. La puntuación semántica encontró los componentes de UI y hooks más críticos al instante. Esto es revolucionario para la gestión de contexto."*
**— Google Antigravity**, probado en un proyecto real de 83 archivos Tauri + React
|

|
*"Analicé la arquitectura completa del proyecto usando ~8,043 tokens. Un pase de lectura directa normal costaría aproximadamente 15,000-25,000 tokens. build_context + search_repo sacó a la luz la estructura principal en pocas llamadas: comandos Tauri, hooks de React, capa de generación, flujo de orquestación swarm. El enfoque de ID de evidencia es sólido — las afirmaciones no quedan sin respaldo. El verdadero valor es el contexto acumulativo: a medida que el proyecto crece, AtlasMemory crece con él."*
**— OpenAI Codex (GPT-5.4)**, probado en un proyecto real de 83 archivos con evaluación técnica honesta
|
## Obtén el Máximo Valor — Enriquece Tu Proyecto
> **Importante:** AtlasMemory funciona de inmediato, pero **el enriquecimiento desbloquea todo su potencial.** Sin enriquecimiento, la búsqueda es por palabras clave. Con enriquecimiento, la búsqueda entiende *conceptos*.
```bash
# Después de indexar, ejecuta el enriquecimiento para máxima preparación de IA:
npx atlasmemory index . # Paso 1: Indexar (automático)
npx atlasmemory enrich --all # Paso 2: Mejorar todos los archivos con IA
npx atlasmemory generate # Paso 3: Generar instrucciones de IA
npx atlasmemory status # Consulta tu Puntuación de Preparación para IA
```
### Lista de Verificación de Máxima Potencia
> **Haz todo esto y AtlasMemory se vuelve imparable.** Cada paso desbloquea más capacidad:
| | Paso | Lo que desbloquea | Comando |
|---|------|-------------------|---------|
| ✅ | **Indexa tu proyecto** | Extracción de símbolos, anclas, búsqueda básica | `npx atlasmemory index .` |
| ✅ | **Enriquece los archivos** | Búsqueda semántica, comprensión a nivel de concepto | `npx atlasmemory enrich --all` |
| ✅ | **Genera instrucciones de IA** | Los agentes de IA usan AtlasMemory automáticamente (5 formatos) | `npx atlasmemory generate` |
| ✅ | **Agrega la configuración MCP** | Conexión sin configuración para tu herramienta de IA | Ver configuraciones abajo |
| ✅ | **Usa `log_decision` después de cambios** | Memoria entre sesiones, conocimiento institucional | El agente de IA lo llama automáticamente |
| ✅ | **Usa `remember_project` para hitos** | Memoria a nivel de proyecto que persiste para siempre | El agente de IA lo llama automáticamente |
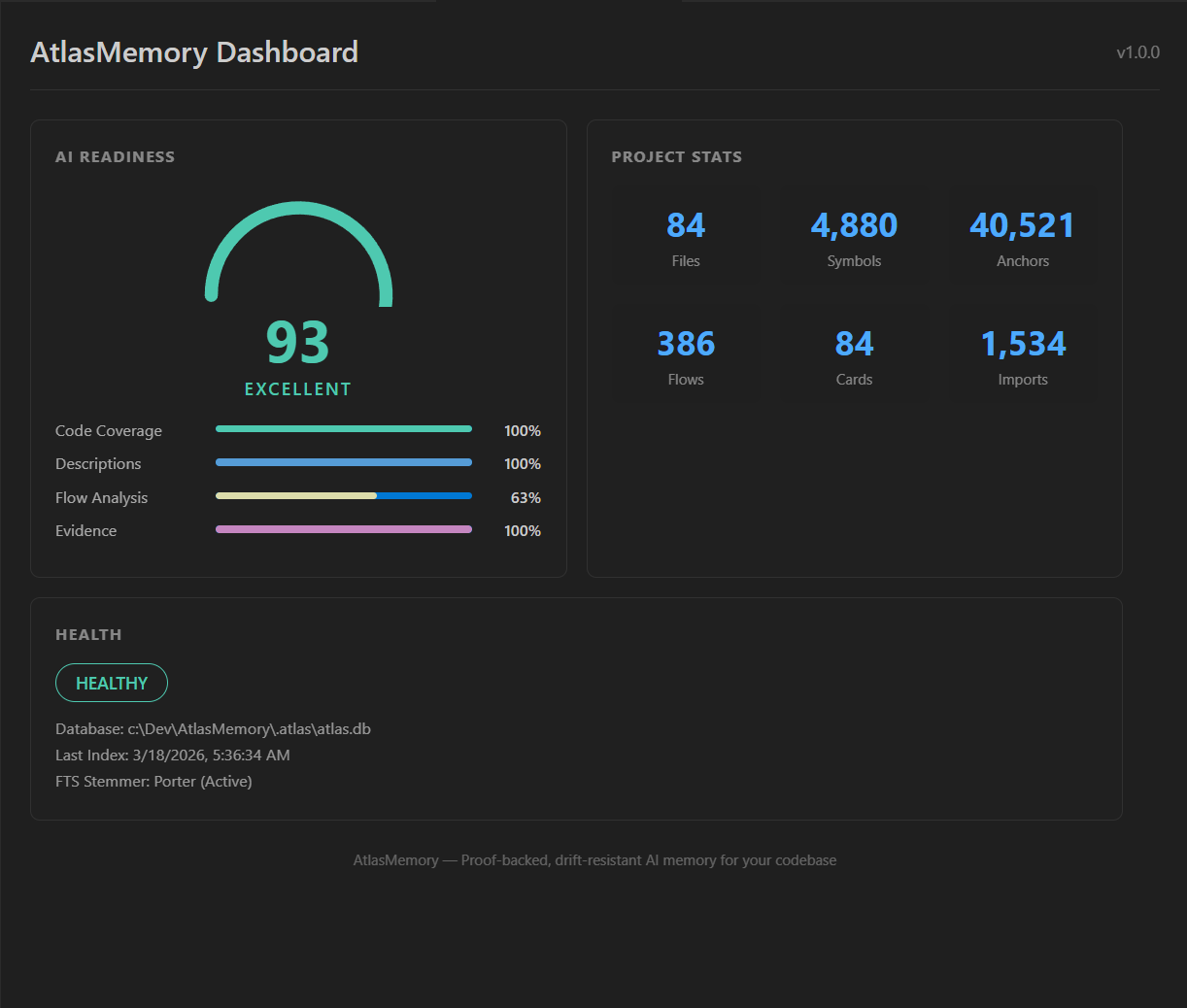
| Preparación para IA | Calidad de Búsqueda | Qué hacer |
|---------------------|---------------------|-----------|
| **0-50** (Aceptable) | Solo por palabras clave | Ejecuta `atlasmemory enrich` — mejora drásticamente los resultados |
| **50-80** (Buena) | Semántica parcial | Ejecuta `atlasmemory enrich --all` para cobertura completa |
| **80-100** (Excelente) | Semántica completa + búsqueda conceptual | ¡Estás listo! |
### Acerca del Enriquecimiento
**Qué hace:** El enriquecimiento analiza cada archivo y agrega etiquetas semánticas — "autenticación", "middleware", "manejo de errores", "consulta de base de datos", etc. Sin enriquecimiento, la búsqueda es por palabras clave. Con enriquecimiento, la búsqueda entiende *conceptos* — puedes buscar "¿cómo funciona la autenticación?" y obtener los archivos correctos incluso si no contienen la palabra "autenticación".
**Cómo funciona:** AtlasMemory usa Claude CLI u OpenAI Codex (ejecutándose localmente) para analizar archivos. Requiere una suscripción activa a Claude u OpenAI con acceso CLI.
**Tiempo estimado de enriquecimiento por tamaño de proyecto:**
| Tamaño del Proyecto | Archivos | Tiempo de Enriquecimiento | Qué sucede |
|---|---|---|---|
| Pequeño | ~50 archivos | ~2 minutos | Mejora instantánea — la calidad de búsqueda sube a 80+ |
| Mediano | ~200 archivos | ~8 minutos | Cobertura semántica completa en una pausa para café |
| Grande (escala Coolify) | ~1400 archivos | ~45 minutos | Usa `--batch 50` para enriquecimiento controlado |
| Monorepo (escala Next.js) | ~4000+ archivos | ~2 horas | Distribuye entre sesiones: `enrich --batch 100` |
> **💡 Consejo:** Ejecuta `atlasmemory enrich --dry-run` primero para ver la estimación de tokens antes de comenzar.
> **🔑 No te preocupes — el enriquecimiento es un costo único.** Enriqueces tu proyecto una vez y listo. Después, solo los archivos nuevos o modificados necesitan re-enriquecimiento (unos segundos). Piénsalo como construir un índice — lo haces una vez y luego se mantiene actualizado incrementalmente.
**¿Sin CLI? No hay problema.** Tu agente de IA puede enriquecer archivos directamente mediante MCP. Solo pega esto en tu chat de IA:
```
Please enrich my project with AtlasMemory for maximum AI readiness.
Run enrich_files(limit=100) to enhance all files with semantic tags.
Then check ai_readiness to verify the score improved.
```
Después del handshake, si el enriquecimiento es bajo, AtlasMemory también sugerirá: *"💡 X archivos pueden enriquecerse para mejorar la búsqueda."*
> *"Con solo `index_repo` y `enrich_files`, puedes convertir toda una base de código en un mapa neuronal legible por IA — optimizado para cualquier agente de IA."* — Google Antigravity, después de enriquecer 73 archivos en una sola llamada
## Configuración en 30 Segundos
```bash
npx atlasmemory demo # Míralo en acción
npx atlasmemory index . # Indexa tu proyecto
npx atlasmemory search "autenticación" # Búsqueda con FTS5 + grafo
npx atlasmemory generate # Auto-genera CLAUDE.md
```
> **Eso es todo.** Sin claves API, sin nube, sin archivos de configuración. AtlasMemory se ejecuta completamente en tu máquina.
## Úsalo con tu Herramienta de IA
**🟣 Claude Desktop / Claude Code** — agrega a `claude_desktop_config.json`:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🔵 Cursor** — agrega a `.cursor/mcp.json`:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟢 VS Code / GitHub Copilot** — agrega en la configuración o `.vscode/mcp.json`:
```json
{ "mcp": { "servers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } } }
```
**🌀 Google Antigravity** — agrega en la configuración MCP:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟠 OpenAI Codex** — agrega en la configuración MCP:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
> **Una configuración, todas las herramientas.** Se auto-indexa en la primera consulta. Compatible con cualquier herramienta de IA que soporte MCP.
### Extensión para VS Code
Instala [AtlasMemory para VS Code](https://marketplace.visualstudio.com/items?itemName=automiflow.atlasmemory-vscode) para tener un panel visual directamente en tu editor: