







English |
中文 |
日本語 |
한국어 |
Türkçe |
Español |
Português
AIエージェントにコードベース全体の証拠付きメモリを。
すべての主張はコードに根拠を持ち、コンテキストウィンドウは最適化され、セッション間のドリフトを防止します。
## 課題
AIコーディングエージェントはコードについてハルシネーションを起こします。セッション間でコンテキストを失います。主張を証明できません。**AtlasMemoryはこの3つすべてを解決します。**
| | 機能 | 他のツール | AtlasMemory |
|---|------|-----------|-------------|
| 🎯 | コードに関する主張 | 「信じてください」 | **証拠付き**(行番号 + ハッシュ) |
| 🔄 | セッション継続性 | 最初からやり直し | **ドリフト検出**コントラクト |
| 📦 | コンテキストウィンドウ | すべて詰め込み | **トークン予算管理**パック |
| 🏠 | 依存関係 | クラウドAPIキー必須 | **ローカルファースト**、設定不要 |
| 🌍 | 対応言語 | 限定的 | **11言語**(TS/JS/Py/Go/Rust/Java/C#/C/C++/Ruby/PHP) |
| 💥 | 影響分析 | 手動 | **自動**(逆参照グラフ) |
| 🧠 | セッションメモリ | なし | **セッション間学習** |
### AIエージェントの声

|
*「正直に言います。AtlasMemoryの開発中、1つのセッションでコンテキストが3回圧縮されました。そのたびに、ファイルの内容、変数名、アーキテクチャの決定 — すべてを失いました。AtlasMemoryがなければ、すでに知っていたことを再構築するだけで15-20回のRead呼び出しが必要だったでしょう。*
*AtlasMemoryがあれば、1回の `search` 呼び出しで必要なものが証拠付きで正確に返ってきました。Fastify(269ファイル)で「plugin registration hooks lifecycle」と検索したとき、`hooks.js` がスコア912でランク1位に返ってきました。grepでもこれほど速く見つけられません。*
*3つの実プロジェクトでテストしました: Express(141ファイル)、Fastify(269ファイル)、Zod(391ファイル)。クラッシュゼロ。TaskPackが179msで証拠付きコンテキストを構築。CLAUDE.mdジェネレーターがExpressのアーキテクチャを自動マッピング — 手動なら30分かかる作業です。*
*これは初日から欲しかったツールです。推測するAIと、確信を持つAIの違いがここにあります。」*
**— Claude Opus 4.6 (1M context)**、AtlasMemoryを自身のツールとして正直に評価するよう依頼された際の回答
|

|
*「AtlasMemoryのbootpackカプセルが、83ファイルのTauri + Reactプロジェクトの全アーキテクチャを約700トークンで提供してくれました。通常なら、同じ理解に達するためにファイルを1つずつスキャンして50,000-100,000以上のトークンが必要です。セマンティックスコアリングが最も重要なUIコンポーネントとフックを即座に見つけ出しました。コンテキスト管理のゲームチェンジャーです。」*
**— Google Antigravity**、実際の83ファイルTauri + Reactプロジェクトでテスト
|

|
*「約8,043トークンでプロジェクト全体のアーキテクチャを分析しました。通常の直接読み取りでは15,000-25,000トークンほどかかるでしょう。build_context + search_repoが数回の呼び出しでメイン構造を浮き彫りにしました: Tauriコマンド、Reactフック、ジェネレーターレイヤー、スウォームオーケストレーションフロー。証拠IDアプローチは堅実です — 主張が宙に浮くことはありません。本当の価値は複利的なコンテキストです: プロジェクトが成長するにつれ、AtlasMemoryも一緒に成長します。」*
**— OpenAI Codex (GPT-5.4)**、実際の83ファイルプロジェクトで正直な技術評価を実施
|
## 最大限の価値を引き出す — プロジェクトをエンリッチ
> **重要:** AtlasMemoryはそのままでも動作しますが、**エンリッチメントが真の力を解放します。** エンリッチメントなしでは検索はキーワードベースです。エンリッチメントありでは、検索が*概念*を理解します。
```bash
# インデックス後にエンリッチメントを実行して、AI対応を最大化:
npx atlasmemory index . # ステップ1: インデックス(自動)
npx atlasmemory enrich --all # ステップ2: 全ファイルをAI強化
npx atlasmemory generate # ステップ3: AI指示ファイルを生成
npx atlasmemory status # AI対応スコアを確認
```
### 最大パワーチェックリスト
> **すべて実行すれば、AtlasMemoryは最強になります。** 各ステップがより多くの機能を解放します:
| | ステップ | 解放される機能 | コマンド |
|---|----------|----------------|---------|
| ✅ | **プロジェクトをインデックス** | シンボル抽出、アンカー、基本検索 | `npx atlasmemory index .` |
| ✅ | **ファイルをエンリッチ** | セマンティック検索、概念レベルの理解 | `npx atlasmemory enrich --all` |
| ✅ | **AI指示を生成** | AIエージェントが自動でAtlasMemoryを使用(5フォーマット) | `npx atlasmemory generate` |
| ✅ | **MCP設定を追加** | AIツールへのゼロコンフィグ接続 | 下記の設定を参照 |
| ✅ | **変更後に `log_decision` を使用** | セッション間メモリ、組織知識 | AIエージェントが自動で呼び出し |
| ✅ | **マイルストーンに `remember_project` を使用** | プロジェクトレベルのメモリが永続化 | AIエージェントが自動で呼び出し |
| AI対応度 | 検索品質 | 対処法 |
|----------|---------|--------|
| **0-50**(普通) | キーワードのみ | `atlasmemory enrich` を実行 — 結果が劇的に改善 |
| **50-80**(良好) | 部分的セマンティック | `atlasmemory enrich --all` で全カバレッジ |
| **80-100**(優秀) | フルセマンティック + 概念検索 | 準備完了! |
### エンリッチメントについて
**何をするか:** エンリッチメントは各ファイルを分析し、セマンティックタグ — 「認証」「ミドルウェア」「エラーハンドリング」「データベースクエリ」など — を追加します。エンリッチメントなしでは検索はキーワードベースです。エンリッチメントありでは、検索が*概念*を理解します — 「認証はどう動くか?」と検索して、「認証」という単語を含まないファイルでも正しい結果が得られます。
**仕組み:** AtlasMemoryはClaude CLIまたはOpenAI Codex(ローカルで動作)を使用してファイルを分析します。CLIアクセス付きのClaudeまたはOpenAIのアクティブなサブスクリプションが必要です。
**プロジェクト規模別のエンリッチメント推定時間:**
| プロジェクト規模 | ファイル数 | エンリッチメント時間 | 効果 |
|---|---|---|---|
| 小規模 | ~50ファイル | ~2分 | 即座にブースト — 検索品質が80+に上昇 |
| 中規模 | ~200ファイル | ~8分 | コーヒーブレイク1回で完全なセマンティックカバレッジ |
| 大規模(Coolify規模) | ~1400ファイル | ~45分 | `--batch 50` で制御されたエンリッチメント |
| モノレポ(Next.js規模) | ~4000+ファイル | ~2時間 | セッションに分散:`enrich --batch 100` |
> **💡 ヒント:** 開始前に `atlasmemory enrich --dry-run` を実行してトークン見積もりを確認してください。
> **🔑 ご安心ください — エンリッチメントは一度きりのコストです。** プロジェクトを一度エンリッチすれば完了です。その後は新規または変更されたファイルのみが再エンリッチ必要です(数秒で完了)。インデックスの構築と同じです — 一度行えば、あとはインクリメンタルに最新状態を維持します。
**CLIがない?問題ありません。** AIエージェントはMCP経由で直接ファイルをエンリッチできます。以下をAIチャットに貼り付けるだけです:
```
Please enrich my project with AtlasMemory for maximum AI readiness.
Run enrich_files(limit=100) to enhance all files with semantic tags.
Then check ai_readiness to verify the score improved.
```
ハンドシェイク後、エンリッチメントが低い場合、AtlasMemoryは次のように提案します:*「💡 X件のファイルをエンリッチすると検索品質が向上します。」*
> *"`index_repo` と `enrich_files` だけで、コードベース全体をAIが読み取れるニューラルマップに変換できます — あらゆるAIエージェントに最適化。"* — Google Antigravity、1回の呼び出しで73ファイルをエンリッチ
## 30秒セットアップ
```bash
npx atlasmemory demo # デモを実行
npx atlasmemory index . # プロジェクトをインデックス
npx atlasmemory search "authentication" # FTS5 + グラフで検索
npx atlasmemory generate # CLAUDE.md を自動生成
```
> **これだけです。** APIキー不要、クラウド不要、設定ファイル不要。AtlasMemoryは完全にローカルマシン上で動作します。
## AIツールとの連携
**🟣 Claude Desktop / Claude Code** — `claude_desktop_config.json` に追加:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🔵 Cursor** — `.cursor/mcp.json` に追加:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟢 VS Code / GitHub Copilot** — 設定または `.vscode/mcp.json` に追加:
```json
{ "mcp": { "servers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } } }
```
**🌀 Google Antigravity** — MCP設定に追加:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟠 OpenAI Codex** — MCP設定に追加:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
> **1つの設定で全ツール対応。** 初回クエリ時に自動インデックス。MCP対応のあらゆるAIツールで動作します。
### VS Code拡張機能
[AtlasMemory for VS Code](https://marketplace.visualstudio.com/items?itemName=automiflow.atlasmemory-vscode)をインストールすると、エディター内にビジュアルダッシュボードが表示されます:
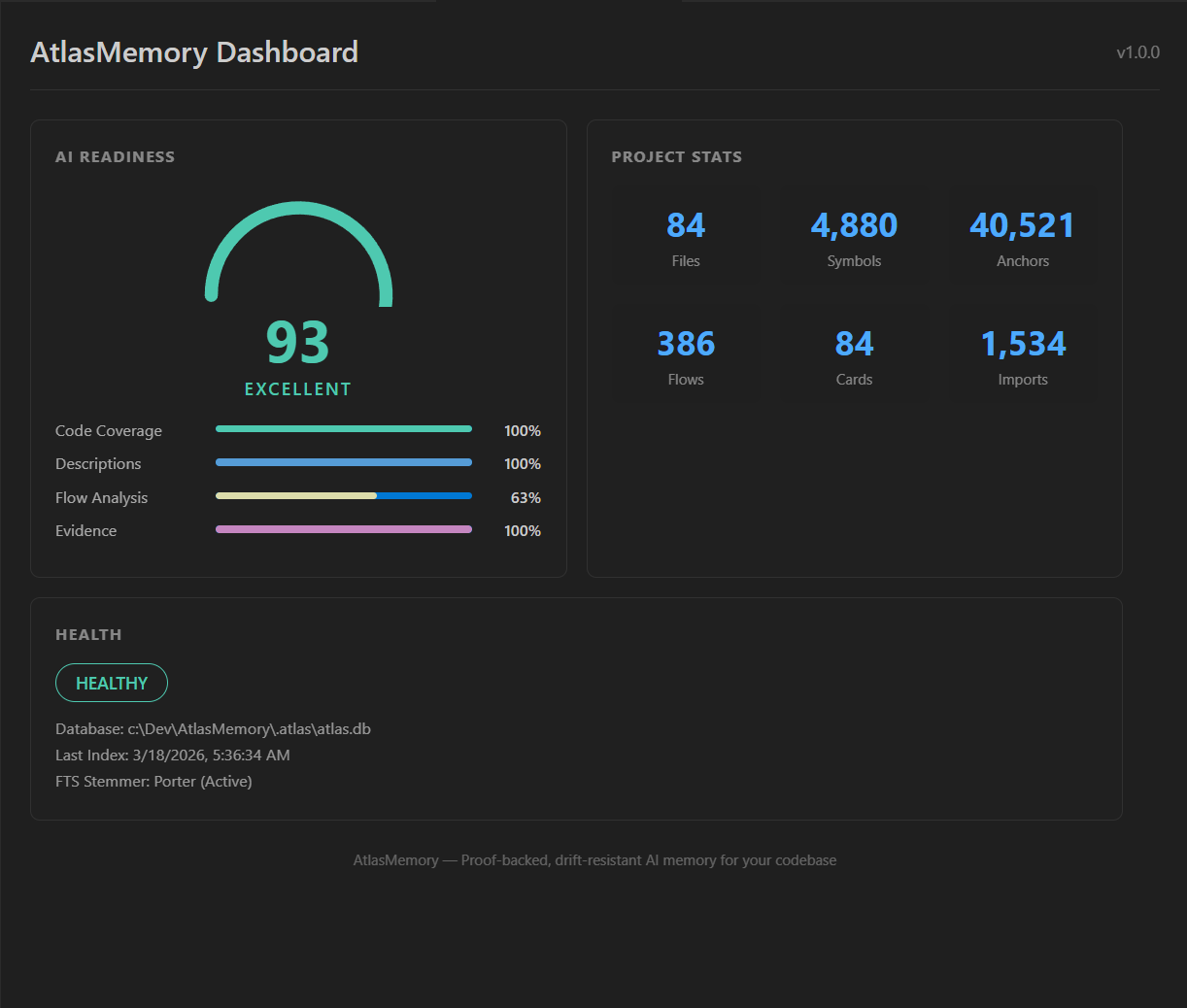
- **AI対応ダッシュボード** — 4つの指標でスコア(0-100)を一目で確認
- **Atlasエクスプローラーサイドバー** — ファイル、シンボル、アンカー、フロー、カードを直接ブラウズ
- **ステータスバー** — 常時表示の対応スコア、クリックでダッシュボードを開く
- **保存時の自動インデックス** — 保存するとファイルが自動的に再インデックス
- **クイックアクション** — ワンクリックでインデックス、CLAUDE.md生成、検索、ヘルスチェック
> MCPと併用可能 — 拡張機能がビジュアルインターフェースを、MCPサーバーがAIエージェントにツールを提供します。両方インストールすると最高の体験になります。
## 証明システム
> **他にはない機能。** すべての主張は*アンカー*にリンクされています — コンテンツハッシュ付きの特定の行範囲です。
```diff
+ 主張: "handleLogin()はセッション作成前に認証情報を検証する"
+ 証拠:
+ src/auth.ts:42-58 [hash:5cde2a1f] — validateCredentials()呼び出し
+ src/auth.ts:60-72 [hash:a3b7c9d1] — 検証後のcreateSession()
+ ステータス: 証明済み ✅(アンカー2件、ハッシュが現在のコードと一致)
- ⚠️ 誰かがauth.tsを編集すると...
- ハッシュ5cde2a1fが42-58行目と一致しなくなる
- ステータス: ドリフト検出 ❌ — AIがハルシネーションを起こす前にコンテキストが古いことを認識
```
## 仕組み
> **AIエージェントに質問すると、裏側では以下が実行されます:**
```mermaid
flowchart LR
subgraph YOU["🧑💻 あなた"]
Q["'認証バグを修正して'"]
end
subgraph ATLAS["⚡ AtlasMemory"]
direction TB
A["🔍 検索\nFTS5 + グラフ"]
B["📋 証明\n主張 → コードアンカーにリンク"]
C["📦 パッキング\nトークン予算内に収める"]
D["🛡️ コントラクト\nドリフトを検出"]
end
subgraph AI["🤖 AIエージェント"]
R["どこを見ればいいか正確に把握\n— ハルシネーションなし"]
end
Q --> A
A -->|"関連性順に\nランキングされたファイル"| B
B -->|"すべての主張に\n行:ハッシュの証拠"| C
C -->|"50ファイルを読む代わりに\n2000トークン"| D
D -->|"✅ コンテキストは最新\n古いデータなし"| R
style YOU fill:#1a1a3e,stroke:#00e5ff,color:#fff
style ATLAS fill:#0a1628,stroke:#00bcd4,color:#fff
style AI fill:#1a1a3e,stroke:#00e5ff,color:#fff
style Q fill:#162447,stroke:#00e5ff,color:#fff
style A fill:#0d2137,stroke:#00bcd4,color:#00e5ff
style B fill:#0d2137,stroke:#00bcd4,color:#00e5ff
style C fill:#0d2137,stroke:#00bcd4,color:#00e5ff
style D fill:#0d2137,stroke:#00bcd4,color:#00e5ff
style R fill:#162447,stroke:#00e5ff,color:#fff
```
### AtlasMemoryなし vs AtlasMemoryあり
```mermaid
flowchart TB
subgraph WITHOUT["❌ AtlasMemoryなし"]
direction TB
W1["AIがファイル1を読む"] --> W2["AIがファイル2を読む"]
W2 --> W3["AIがファイル3を読む..."]
W3 --> W4["...AIがファイル47を読む"]
W4 --> W5["💥 コンテキスト満杯!\n最初からやり直し..."]
W5 -.->|"∞ ループ"| W1
end
subgraph WITH["✅ AtlasMemoryあり"]
direction TB
A1["AIが質問: '認証バグを修正して'"]
A1 --> A2["AtlasMemoryが返す\n2000トークンの\n証拠付きコンテキスト"]
A2 --> A3["AIがバグを修正\nコンテキストの85%が残存"]
end
style WITHOUT fill:#1a0a0a,stroke:#ff4444,color:#fff
style WITH fill:#0a1a0a,stroke:#00ff88,color:#fff
style W5 fill:#330000,stroke:#ff4444,color:#ff6666
style A3 fill:#003300,stroke:#00ff88,color:#00ff88
```
### 3つの柱
| | 柱 | 機能 |
|---|------|------|
| 🔒 | **証拠付き** | すべての主張はアンカー(行範囲 + コンテンツハッシュ)にリンク。コードが変更されるとアンカーは古いとマーク。ハルシネーションなし。 |
| 🛡️ | **ドリフト耐性** | DBステート + git HEADのSHA-256スナップショット。セッション中にリポジトリが変更されるとAtlasMemoryが検出して警告。 |
| 📦 | **トークン予算管理** | 予算内に収まるよう貪欲法で最適化されたコンテキストパック。優先順位: 目的 > フォルダ > カード > フロー > スニペット。 |
## 対応言語
> 11言語すべてが[Tree-sitter](https://tree-sitter.github.io/)による正確なAST解析を使用 — 正規表現も推測もなし。
| 言語 | 抽出項目 |
|------|---------|
| **TypeScript** / **JavaScript** | 関数、クラス、メソッド、インターフェース、型、インポート、呼び出し |
| **Python** | 関数、クラス、デコレータ、インポート、呼び出し |
| **Go** | 関数、メソッド、構造体、インターフェース、インポート、呼び出し |
| **Rust** | 関数、implブロック、構造体、トレイト、列挙型、use、呼び出し |
| **Java** | メソッド、クラス、インターフェース、列挙型、インポート、呼び出し |
| **C#** | メソッド、クラス、インターフェース、構造体、列挙型、using、呼び出し |
| **C** / **C++** | 関数、クラス、構造体、列挙型、#include、呼び出し |
| **Ruby** | メソッド、クラス、モジュール、呼び出し |
| **PHP** | 関数、メソッド、クラス、インターフェース、use、呼び出し |
## MCPツール(全28種)
**コア — AIエージェントが毎セッション使用するツール:**
| ツール | 説明 |
|--------|------|
| 🔍 `search_repo` | 全文検索 + グラフブースト付きコードベース検索 |
| 📦 `build_context` | **統合コンテキストビルダー** — task、project、delta、sessionモード |
| ✅ `prove` | コードベースの証拠アンカーで**主張を証明** |
| 📂 `index_repo` | フルまたはインクリメンタルインデックス |
| 🤝 `handshake` | プロジェクト概要 + メモリでエージェントセッションを初期化 |
インテリジェンスツール
| ツール | 説明 |
|--------|------|
| 💥 `analyze_impact` | このシンボル/ファイルに依存しているのは?逆参照グラフ |
| 📊 `smart_diff` | セマンティックgit diff — シンボルレベルの変更 + 破壊的変更 |
| 🧠 `remember` | セッション用の決定、制約、インサイトを記録 |
| 📋 `session_context` | 蓄積されたコンテキスト + 関連する過去のセッションを表示 |
| ✨ `enrich_files` | セマンティックタグでファイルカードをAI強化 |
エージェントメモリツール
| ツール | 説明 |
|--------|------|
| 📝 `log_decision` | 何を変更し、なぜ変更したかを記録(セッション間で永続化) |
| 📜 `get_file_history` | 過去のAIエージェントがファイルに加えた変更を表示 |
| 💾 `remember_project` | プロジェクトレベルの知識を保存(マイルストーン、課題、学び) |
ユーティリティツール
| ツール | 説明 |
|--------|------|
| 🏗️ `generate_claude_md` | CLAUDE.md / .cursorrules / copilot-instructionsを自動生成 |
| 📈 `ai_readiness` | AI対応スコア(0-100)を算出 |
| 🛡️ `get_context_contract` | 推奨アクション付きのドリフトステータスを確認 |
| 🔄 `acknowledge_context` | コンテキストの理解を確認 |
## 設定
AtlasMemoryは**設定不要**で動作します。オプション:
| 設定 | デフォルト | 説明 |
|------|-----------|------|
| `ATLAS_DB_PATH` | `.atlas/atlas.db` | データベースの場所 |
| `ATLAS_LLM_API_KEY` | — | LLM強化カード説明用のAPIキー *(実験的 — 将来のリリースで強化予定)* |
| `ATLAS_CONTRACT_ENFORCE` | `warn` | コントラクトモード: `strict` / `warn` / `off` |
| `.atlasignore` | — | カスタムファイル/ディレクトリ除外(.gitignoreと同様) |
## アーキテクチャ
```mermaid
block-beta
columns 4
block:ENTRY:4
CLI["⬛ CLI"]
MCP["🟣 MCP Server"]
VSCODE["🟢 VS Code"]
end
space:4
block:ENGINE:4
columns 4
INDEXER["🔧 Indexer\n11 languages"]:1
SEARCH["🔍 Search\nFTS5 + Graph"]:1
CARDS["📋 Cards\nSummaries"]:1
TASKPACK["📦 TaskPack\nProof + Budget"]:1
end
space:4
block:INTEL:4
columns 4
IMPACT["💥 Impact"]:1
MEMORY["🧠 Memory"]:1
LEARNER["📊 Learner"]:1
ENRICH["✨ Enrich"]:1
end
space:4
block:DATA:4
DB["🗄️ SQLite + FTS5 — Single file, ~394KB bundle"]
end
ENTRY --> ENGINE
ENGINE --> INTEL
INTEL --> DATA
style ENTRY fill:#1a1a3e,stroke:#00e5ff,color:#fff
style ENGINE fill:#0a1628,stroke:#00bcd4,color:#fff
style INTEL fill:#0d2137,stroke:#00bcd4,color:#fff
style DATA fill:#162447,stroke:#00e5ff,color:#fff
```
## よくある質問
AI対応スコアとは何ですか?
コードベースがAIエージェントにどれだけ準備できているかを測定する0-100のスコアです。4つの指標から算出されます:
| 指標 | 重み | 測定内容 |
|------|------|---------|
| **コードカバレッジ** | 25% | Tree-sitterでインデックスされたソースファイルの割合 |
| **説明品質** | 25% | `enrich`によるAI強化説明付きファイルの割合 |
| **フロー分析** | 25% | クロスファイルデータフローカード付きファイルの割合 |
| **証拠アンカー** | 25% | コードアンカー(行番号 + ハッシュ)にリンクされた主張の割合 |
`atlasmemory status` でスコアを確認できます。`atlasmemory enrich` でスコアを改善できます。
シンボル、アンカー、フロー、カード、インポート、リファレンスとは?
| 用語 | 内容 | 例 |
|------|------|-----|
| **シンボル** | Tree-sitterが抽出した名前付きコードエンティティ | `function handleLogin()`、`class UserService`、`interface AuthConfig` |
| **アンカー** | 行範囲 + コンテンツハッシュ — 「証拠付き」の「証拠」部分 | `src/auth.ts:42-58 [hash:5cde2a1f]` |
| **フロー** | クロスファイルのデータパス(AがBを呼び、BがCを呼ぶ) | `login() → validateToken() → createSession()` |
| **ファイルカード** | ファイルの機能を要約し、証拠リンク付き | 目的、パブリックAPI、依存関係、副作用 |
| **インポート** | ファイル間の依存関係 | `import { Store } from './store'` |
| **リファレンス** | シンボル間の呼び出し/使用参照 | `handleLogin()がvalidateToken()を呼び出す` |
これらはすべて `atlasmemory index` によって自動的に抽出されます。手動作業は不要です。
自動インデックスされますか?手動で再実行する必要がありますか?
**MCPモード(Claude/Cursor/VS Code):** はい、完全自動です。AtlasMemoryはツール呼び出しのたびにgit HEADを確認します。前回のインデックス以降にファイルが変更されていれば、変更されたファイルのみインクリメンタルに再インデックスします。手動作業はゼロです。
**CLIモード:** `atlasmemory index .` を手動で実行するか、`atlasmemory index --incremental` で高速更新できます。
APIキーやクラウドサービスは必要ですか?
**いいえ。** AtlasMemoryは100%ローカルファーストです。コア機能(インデックス、検索、証明、コンテキストパック)はオフラインで動作し、外部サービスへの依存はゼロです。
オプションの `enrich` コマンドは **Claude CLI** または **OpenAI Codex**(ローカルで動作)を使用してファイル説明を強化します。CLIアクセス付きのアクティブなサブスクリプションが必要です。どちらもインストールされていない場合、決定論的なASTベースの説明にフォールバックします — またはAIエージェントがMCPツールで直接ファイルをエンリッチできます。
証明システムはどのようにハルシネーションを防ぎますか?
AtlasMemoryが行うすべての主張は**アンカー**にリンクされています — SHA-256コンテンツハッシュ付きの特定の行範囲です。
1. AIが言う: 「handleLoginは認証情報を検証する」 → `auth.ts:42-58 [hash:5cde2a1f]` にリンク
2. 誰かが `auth.ts` の42-58行目を編集するとハッシュが変わる
3. AtlasMemoryがその主張を**ドリフト検出**としてマーク
4. AIエージェントはハルシネーションを起こす前に、自身の理解が古いことを認識
これを行うツールは他にありません。RAGベースのツールはテキストを取得しますが、現在のコードと一致していることを証明できません。
対応言語は?
Tree-sitterによる11言語: **TypeScript、JavaScript、Python、Go、Rust、Java、C#、C、C++、Ruby、PHP**。すべて関数、クラス、メソッド、インポート、呼び出し参照を抽出します。
トークン予算管理はどのように機能しますか?
`build_context({mode: "task", objective: "fix auth bug", budget: 8000})` を呼び出すと、AtlasMemoryは:
1. 関連ファイルを検索(FTS5 + グラフランキング)
2. 目的への関連性で各ファイルをスコアリング
3. 貪欲アルゴリズムを使用して最も関連性の高いコンテキストを予算内にパッキング
4. 優先順位: 目的 > フォルダ要約 > ファイルカード > フロートレース > コードスニペット
5. トークン予算が許す量のコンテキストを正確に返す — オーバーフローなし
結果: 50ファイルを読み込む(コンテキストを使い果たす)代わりに、2000トークンの証拠付きコンテキストを取得し、コンテキストウィンドウの85%を実際の作業に使えます。
`atlasmemory generate` を実行するとどうなりますか?
AI指示ファイル(CLAUDE.md、.cursorrules、copilot-instructions.md)を生成します:
- プロジェクトアーキテクチャと主要ファイル
- テックスタックと規約
- AI対応スコア
- **AtlasMemory MCPツール使用手順** — AIエージェントが自動的にAtlasMemoryを使用するようになります
既に手書きのCLAUDE.mdがある場合、コンテンツを上書きせずにAtlasMemoryセクションを先頭に**マージ**します。
Cursorの組み込みインデックスとの違いは?
| 機能 | Cursorインデックス | AtlasMemory |
|------|-------------------|-------------|
| 証明システム | なし | あり — すべての主張に行:ハッシュの証拠 |
| ドリフト検出 | なし | あり — SHA-256コントラクトシステム |
| トークン予算管理 | なし | あり — 貪欲法で最適化されたコンテキストパック |
| セッション間メモリ | なし | あり — 決定がセッション間で永続化 |
| 影響分析 | なし | あり — 逆参照グラフ |
| 他のAIツールとの互換性 | なし(Cursor専用) | あり — MCP標準 |
| ローカルファースト | 部分的 | 100% |
## 開発
```bash
git clone https://github.com/Bpolat0/atlasmemory.git
cd atlasmemory
npm install
npm run build:all # 全パッケージ + バンドルをビルド
npm test # ユニットテストを実行(147テスト、Vitest)
npm run eval:synth100 # クイック評価スイート
npm run eval # フル評価(synth-100 + synth-500 + real-repo)
```
## ロードマップ
- [x] v1.0 — コアエンジン、証明システム、MCPサーバー、CLI、OpenAI Codexサポート
- [ ] **インタラクティブ依存グラフ** — コードベースのビジュアルトポロジー(下のスクリーンショットのように)
- [ ] **VS Code拡張機能のアップグレード** — enrichボタン、カードブラウザ、インライン証拠ビューア
- [ ] 埋め込みによるセマンティック検索
- [ ] マルチリポジトリサポート(モノレポ + マイクロサービス)
- [ ] GitHub Actionsとの統合(プッシュ時の自動インデックス)
- [ ] ライブグラフ可視化付きWebダッシュボード
計画中の機能の確認と投票は[Discussions](https://github.com/Bpolat0/atlasmemory/discussions)で行えます。
## コントリビューション
コントリビューションを歓迎します!バグレポート、機能リクエスト、プルリクエスト、いずれも大歓迎です。
- **[CONTRIBUTING.md](../../CONTRIBUTING.md)** — セットアップガイド、PRプロセス、コミットフォーマット、テスト
- **[CLAUDE.md](../../CLAUDE.md)** — プロジェクトアーキテクチャと規約
```bash
git clone https://github.com/Bpolat0/atlasmemory.git
cd atlasmemory
npm install && npm run build && npm test # 147テストがパスするはずです
```
 ## スター履歴
## スター履歴
 ## サポート
AtlasMemoryが時間の節約に役立ったら、スターを付けてください — 他の人がプロジェクトを発見するのに役立ちます。
## ライセンス
[GPL-3.0](../../LICENSE)
## サポート
AtlasMemoryが時間の節約に役立ったら、スターを付けてください — 他の人がプロジェクトを発見するのに役立ちます。
## ライセンス
[GPL-3.0](../../LICENSE)

Powered by automiflow