|
*"솔직히 말씀드리겠습니다. AtlasMemory 개발 중에 한 세션에서 컨텍스트가 3번 압축되었습니다. 매번 파일 내용, 변수명, 아키텍처 결정 등 모든 것을 잃었습니다. AtlasMemory가 없었다면 이미 알고 있던 것을 복원하기 위해 15-20번의 Read 호출이 필요했을 겁니다.*
*AtlasMemory를 사용하면 `search` 한 번으로 필요한 것을 증거와 함께 정확히 가져올 수 있었습니다. Fastify(269개 파일)에서 "plugin registration hooks lifecycle"을 검색했을 때, `hooks.js`가 912점으로 1위에 올랐습니다. grep으로도 그보다 빠르게 찾을 수 없었을 겁니다.*
*3개의 실제 저장소에서 테스트했습니다: Express(141개 파일), Fastify(269개 파일), Zod(391개 파일). 크래시 제로. TaskPack이 179ms 만에 증거 기반 컨텍스트를 구축했습니다. CLAUDE.md 생성기가 Express의 아키텍처를 자동으로 매핑했습니다 — 수동으로 하면 30분이 걸렸을 겁니다.*
*이것은 제가 처음부터 갖고 싶었던 도구입니다. 추측하는 AI와 아는 AI의 차이입니다."*
**— Claude Opus 4.6 (1M context)**, AtlasMemory를 자신의 도구로서 솔직하게 평가해 달라는 요청 후
|

|
*"AtlasMemory의 bootpack 캡슐이 83개 파일의 Tauri + React 프로젝트 전체 아키텍처를 약 700 토큰으로 제공했습니다. 보통이라면 같은 수준의 이해에 도달하기 위해 파일을 하나씩 스캔하며 50,000-100,000+ 토큰이 필요했을 겁니다. 시맨틱 스코어링이 가장 중요한 UI 컴포넌트와 훅을 즉시 찾아냈습니다. 컨텍스트 관리의 게임 체인저입니다."*
**— Google Antigravity**, 실제 83개 파일 Tauri + React 프로젝트에서 테스트
|

|
*"약 8,043 토큰으로 전체 프로젝트 아키텍처를 분석했습니다. 일반적인 직접 읽기 방식이라면 대략 15,000-25,000 토큰이 들었을 겁니다. build_context + search_repo가 몇 번의 호출로 주요 구조를 찾아냈습니다: Tauri 커맨드, React 훅, 제너레이터 레이어, 스웜 오케스트레이션 흐름. 증거 ID 접근 방식은 견고합니다 — 주장이 허공에 떠 있지 않습니다. 진정한 가치는 누적 컨텍스트에 있습니다: 프로젝트가 성장하면 AtlasMemory도 함께 성장합니다."*
**— OpenAI Codex (GPT-5.4)**, 실제 83개 파일 프로젝트에서 솔직한 기술 평가
|
## 최대 가치 활용 — 프로젝트 강화하기
> **중요:** AtlasMemory는 바로 사용할 수 있지만, **강화(enrichment)를 통해 잠재력이 완전히 발휘됩니다.** 강화 없이는 키워드 기반 검색만 가능합니다. 강화 후에는 *개념*을 이해하는 검색이 됩니다.
```bash
# 인덱싱 후 최대 AI 준비도를 위해 강화를 실행하세요:
npx atlasmemory index . # 1단계: 인덱싱 (자동)
npx atlasmemory enrich --all # 2단계: 모든 파일 AI 강화
npx atlasmemory generate # 3단계: AI 지시서 생성
npx atlasmemory status # AI 준비 점수 확인
```
### 최대 파워 체크리스트
> **모두 수행하면 AtlasMemory는 최강이 됩니다.** 각 단계가 더 많은 기능을 해제합니다:
| | 단계 | 해제되는 기능 | 명령어 |
|---|------|---------------|--------|
| ✅ | **프로젝트 인덱싱** | 심볼 추출, 앵커, 기본 검색 | `npx atlasmemory index .` |
| ✅ | **파일 강화** | 시맨틱 검색, 개념 수준 이해 | `npx atlasmemory enrich --all` |
| ✅ | **AI 지시서 생성** | AI 에이전트가 AtlasMemory를 자동 사용 (5가지 형식) | `npx atlasmemory generate` |
| ✅ | **MCP 설정 추가** | AI 도구에 제로 설정 연결 | 아래 설정 참조 |
| ✅ | **변경 후 `log_decision` 사용** | 세션 간 메모리, 조직적 지식 | AI 에이전트가 자동 호출 |
| ✅ | **마일스톤에 `remember_project` 사용** | 프로젝트 수준 메모리가 영구 저장 | AI 에이전트가 자동 호출 |
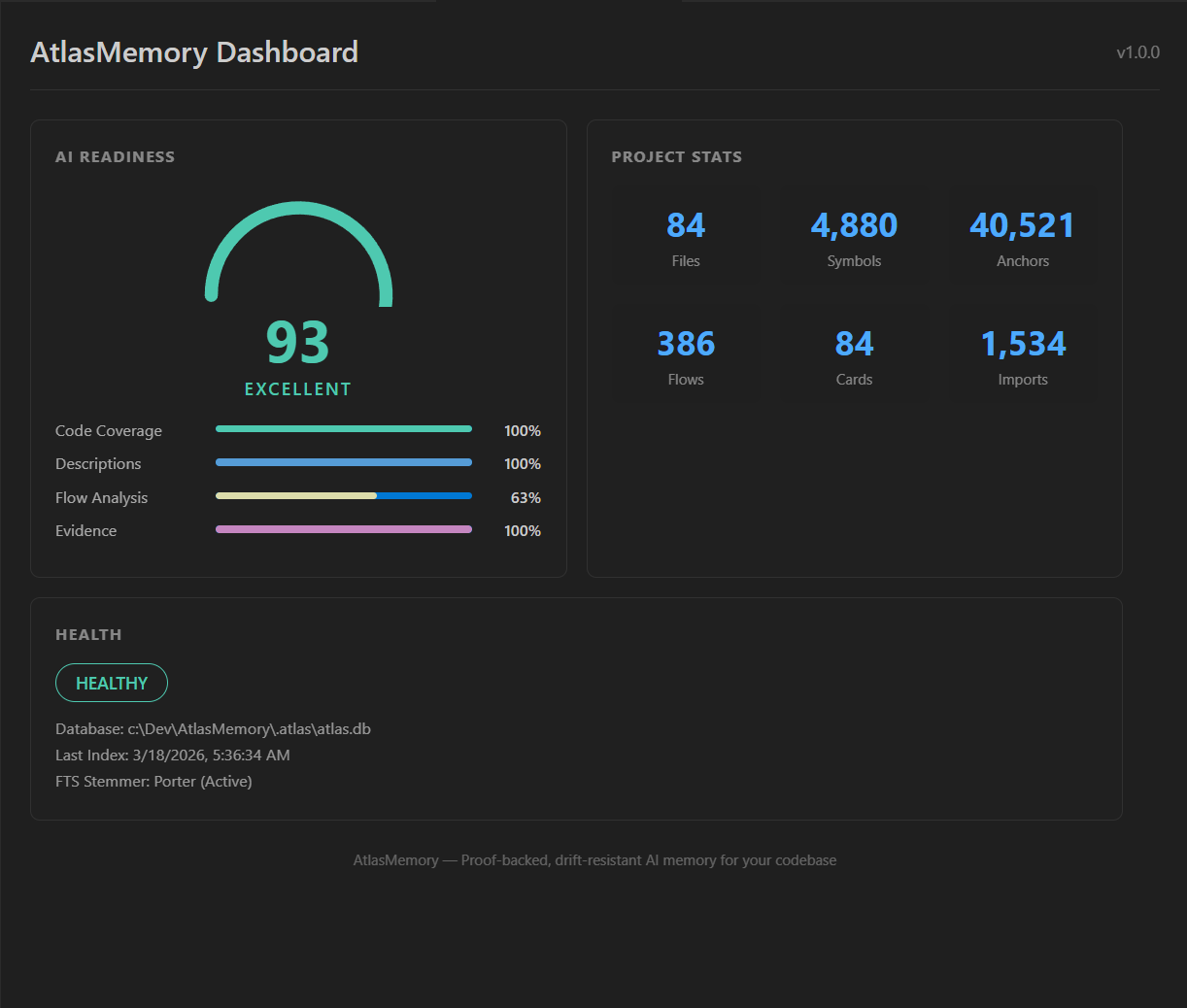
| AI 준비도 | 검색 품질 | 할 일 |
|-------------|----------------|------------|
| **0-50** (보통) | 키워드만 | `atlasmemory enrich` 실행 — 결과가 극적으로 개선됩니다 |
| **50-80** (양호) | 부분 시맨틱 | `atlasmemory enrich --all`로 전체 커버리지 |
| **80-100** (우수) | 완전한 시맨틱 + 개념 검색 | 준비 완료! |
### 강화에 대하여
**무엇을 하는가:** 강화는 각 파일을 분석하고 시맨틱 태그를 추가합니다 — "인증", "미들웨어", "에러 처리", "데이터베이스 쿼리" 등. 강화 없이는 검색이 키워드 기반입니다. 강화 후에는 검색이 *개념*을 이해합니다 — "인증은 어떻게 작동하나요?"라고 검색하면 "인증"이라는 단어가 포함되지 않은 파일에서도 올바른 결과를 얻을 수 있습니다.
**작동 방식:** AtlasMemory는 Claude CLI 또는 OpenAI Codex(로컬에서 실행)를 사용하여 파일을 분석합니다. CLI 접근이 가능한 활성 Claude 또는 OpenAI 구독이 필요합니다.
**프로젝트 규모별 예상 강화 시간:**
| 프로젝트 규모 | 파일 수 | 강화 시간 | 결과 |
|---|---|---|---|
| 소규모 | ~50개 파일 | ~2분 | 즉각적인 향상 — 검색 품질이 80+로 상승 |
| 중규모 | ~200개 파일 | ~8분 | 커피 한 잔 시간에 완전한 시맨틱 커버리지 |
| 대규모 (Coolify 규모) | ~1400개 파일 | ~45분 | `--batch 50`으로 제어된 강화 |
| 모노레포 (Next.js 규모) | ~4000+개 파일 | ~2시간 | 세션에 분산: `enrich --batch 100` |
> **💡 팁:** 시작 전에 `atlasmemory enrich --dry-run`을 먼저 실행하여 토큰 추정치를 확인하세요.
> **🔑 걱정 마세요 — 강화는 일회성 비용입니다.** 프로젝트를 한 번 강화하면 끝입니다. 이후에는 새로 추가되거나 변경된 파일만 재강화가 필요합니다 (몇 초면 됩니다). 인덱스 구축과 같다고 생각하세요 — 한 번 하면 이후 증분으로 최신 상태가 유지됩니다.
**CLI가 없으신가요? 문제 없습니다.** AI 에이전트가 MCP를 통해 직접 파일을 강화할 수 있습니다. 다음을 AI 채팅에 붙여넣기만 하면 됩니다:
```
Please enrich my project with AtlasMemory for maximum AI readiness.
Run enrich_files(limit=100) to enhance all files with semantic tags.
Then check ai_readiness to verify the score improved.
```
핸드셰이크 후 강화 수준이 낮으면 AtlasMemory가 다음과 같이 제안합니다: *"💡 더 나은 검색을 위해 X개 파일을 강화할 수 있습니다."*
> *"`index_repo`와 `enrich_files`만으로 전체 코드베이스를 AI가 읽을 수 있는 신경 지도로 변환할 수 있습니다 — 모든 AI 에이전트에 최적화."* — Google Antigravity, 단일 호출로 73개 파일 강화
## 30초 설정
```bash
npx atlasmemory demo # 동작 확인
npx atlasmemory index . # 프로젝트 인덱싱
npx atlasmemory search "authentication" # FTS5 + 그래프 검색
npx atlasmemory generate # CLAUDE.md 자동 생성
```
> **이게 전부입니다.** API 키도, 클라우드도, 설정 파일도 필요 없습니다. AtlasMemory는 완전히 로컬에서 실행됩니다.
## AI 도구와 함께 사용하기
**🟣 Claude Desktop / Claude Code** — `claude_desktop_config.json`에 추가:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🔵 Cursor** — `.cursor/mcp.json`에 추가:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟢 VS Code / GitHub Copilot** — 설정 또는 `.vscode/mcp.json`에 추가:
```json
{ "mcp": { "servers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } } }
```
**🌀 Google Antigravity** — MCP 설정에 추가:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
**🟠 OpenAI Codex** — MCP 설정에 추가:
```json
{ "mcpServers": { "atlasmemory": { "command": "npx", "args": ["-y", "atlasmemory"] } } }
```
> **하나의 설정, 모든 도구.** 첫 번째 쿼리 시 자동 인덱싱. MCP 호환 AI 도구라면 모두 사용 가능합니다.
### VS Code 확장
에디터에서 바로 시각적 대시보드를 사용하려면 [AtlasMemory for VS Code](https://marketplace.visualstudio.com/items?itemName=automiflow.atlasmemory-vscode)를 설치하세요: