![]()
Einfach mit OpenClaw chatten: "Research X" → erledigt.
![]()
🇺🇸 English · 🇨🇳 中文 · 🇯🇵 日本語 · 🇰🇷 한국어 · 🇫🇷 Français · 🇩🇪 Deutsch · 🇪🇸 Español · 🇧🇷 Português · 🇷🇺 Русский · 🇸🇦 العربية
🏆 Paper-Showcase · 📖 Integrationsanleitung · 💬 Discord-Community
---

|
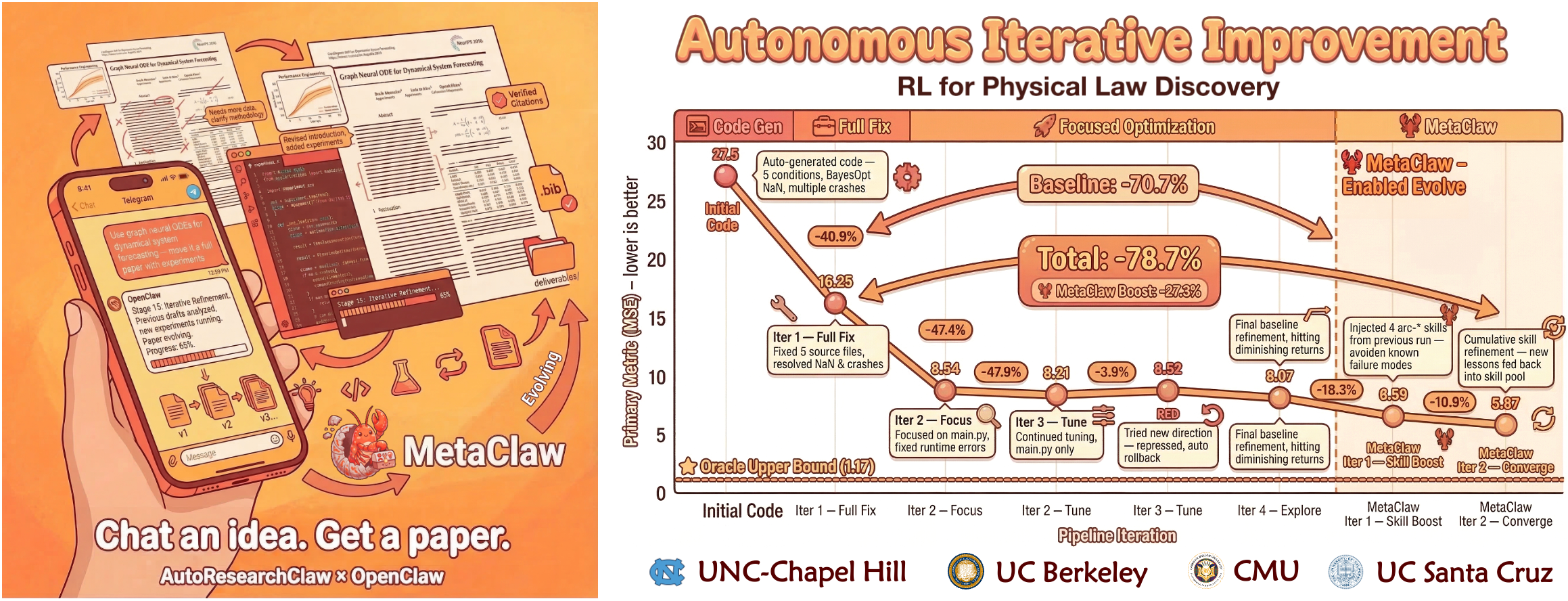
🏆 Showcase generierter Paper 8 Paper aus 8 Disziplinen — Mathematik, Statistik, Biologie, Informatik, NLP, RL, Vision, Robustheit — vollstaendig autonom generiert ohne menschliches Eingreifen. |
| 📄 | paper_draft.md | Vollstaendiges wissenschaftliches Paper (Einleitung, Verwandte Arbeiten, Methode, Experimente, Ergebnisse, Fazit) |
| 📐 | paper.tex | Konferenzfertiges LaTeX (NeurIPS / ICLR / ICML Templates) |
| 📚 | references.bib | Echte BibTeX-Referenzen von OpenAlex, Semantic Scholar und arXiv — automatisch bereinigt, um Inline-Zitationen zu entsprechen |
| 🔍 | verification_report.json | 4-Schicht-Zitationsintegritaets- und Relevanzpruefung (arXiv, CrossRef, DataCite, LLM) |
| 🧪 | experiment runs/ | Generierter Code + Sandbox-Ergebnisse + strukturierte JSON-Metriken |
| 📊 | charts/ | Automatisch generierte Vergleichsdiagramme mit Fehlerbalken und Konfidenzintervallen |
| 📝 | reviews.md | Multi-Agenten-Peer-Review mit Methodik-Evidenz-Konsistenzpruefungen |
| 🧬 | evolution/ | Selbstlernende Erkenntnisse aus jedem Durchlauf |
| 📦 | deliverables/ | Alle finalen Ergebnisse in einem Ordner — kompilierbereit fuer Overleaf |
Gebaut mit 🦞 vom AutoResearchClaw-Team