Section 2 Cleaning and Tokenization
knitr::opts_chunk$set(message = FALSE, warning = FALSE, echo = TRUE)
# set to TRUE to run this on only one reference file
debugging <- FALSE
# this will expect the file or files to be in a subdirectory with the following name
refsource <- "MungingProj2"
dataDir <- "Proj2Data"
workingDir <- refsource
# prefixes for all File reads and writes
# titles for tables
titletext <- "RedditCrypto"
srs = c("CryptoCurrency","CryptoMarkets")
`%notin%` <- Negate(`%in%`)2.1 Import Clean
The data imported in the following code chunk was collected using the Python Reddit API Wrapper to extract data from the subreddits in this study
subm_fnames <- list.files(dataDir, pattern = "*_submissions.csv", full.names = TRUE)
comm_fnames <- list.files(dataDir, pattern = "*_comments.csv", full.names = TRUE)
subr_fnames <- list.files(dataDir, pattern = "*_subreddit.csv", full.names = TRUE)
for (i in 1:length(subm_fnames))
assign(srs[i], read.csv(subm_fnames[i]))
SubmData<- rbind(CryptoCurrency, CryptoMarkets)
for (i in 1:length(comm_fnames))
assign(srs[i], read.csv(comm_fnames[i]))
CommData<- rbind(CryptoCurrency, CryptoMarkets)
for (i in 1:length(subr_fnames))
assign(srs[i], read.csv(subr_fnames[i]))
SubrData<- rbind(CryptoCurrency, CryptoMarkets)2.1.1 Fix Names
Subreddits are identifiable among online communities in that they are often referenced according to the url suffix of the subreddit webpage (i.e. r/CryptoCurrency comes from reddit.com/r/CryptoCurrency). To retain this cultural identifier, we modify the names
srs <- unique(SubmData$subreddit)
SubmData <- SubmData %>%
mutate(
subreddit = case_when(
.$subreddit == srs[1] ~ "r/CryptoCurrency",
.$subreddit == srs[2] ~ "r/CryptoMarkets")
) %>%
ungroup()
srs <- unique(CommData$subreddit)
CommData <- CommData %>%
mutate(
subreddit = case_when(
.$subreddit == srs[1] ~ "r/CryptoCurrency",
.$subreddit == srs[2] ~ "r/CryptoMarkets")
) %>%
ungroup()2.1.2 Subreddit information
submnums <- table(SubmData$subreddit)
SubmNums <- as.data.frame(submnums, .name_repair = "minimal")
colnames(SubmNums)[1] <- "Subreddit"
ggplot(SubmNums, aes(x = Subreddit, y = Freq, fill = Subreddit)) + geom_bar(stat = "identity") + scale_y_continuous(name="# of Submissions by Subreddit", labels = scales::comma)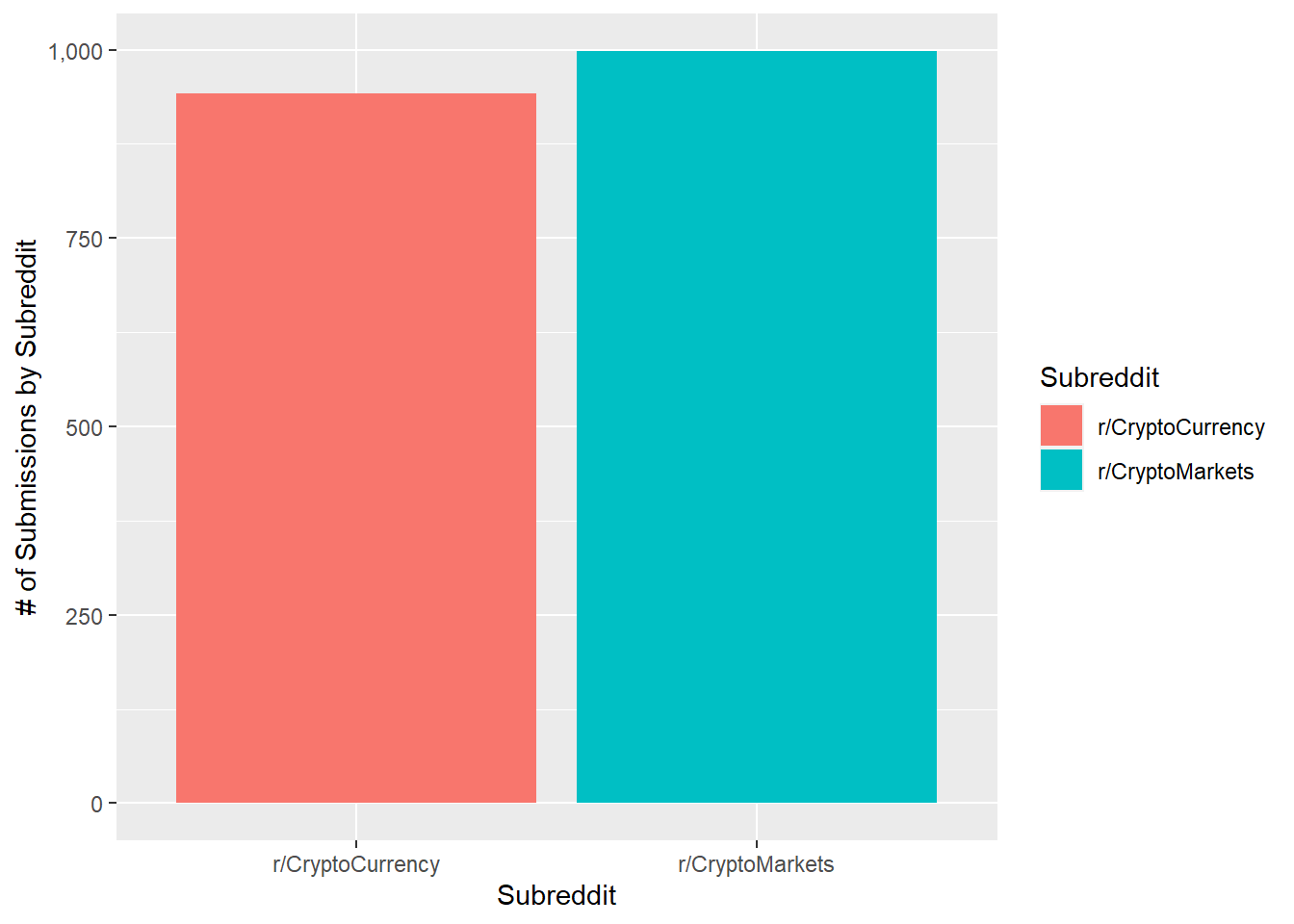
c <- CommData
commnums <- table(c$subreddit)
CommNums <- as.data.frame(commnums, .name_repair = "minimal")
colnames(CommNums)[1] <- "Subreddit"
ggplot(CommNums, aes(x = Subreddit, y = Freq, fill = Subreddit)) + geom_bar(stat = "identity") + scale_y_continuous(name="# of Comments by Subreddit (from 300 posts each)", labels = scales::comma)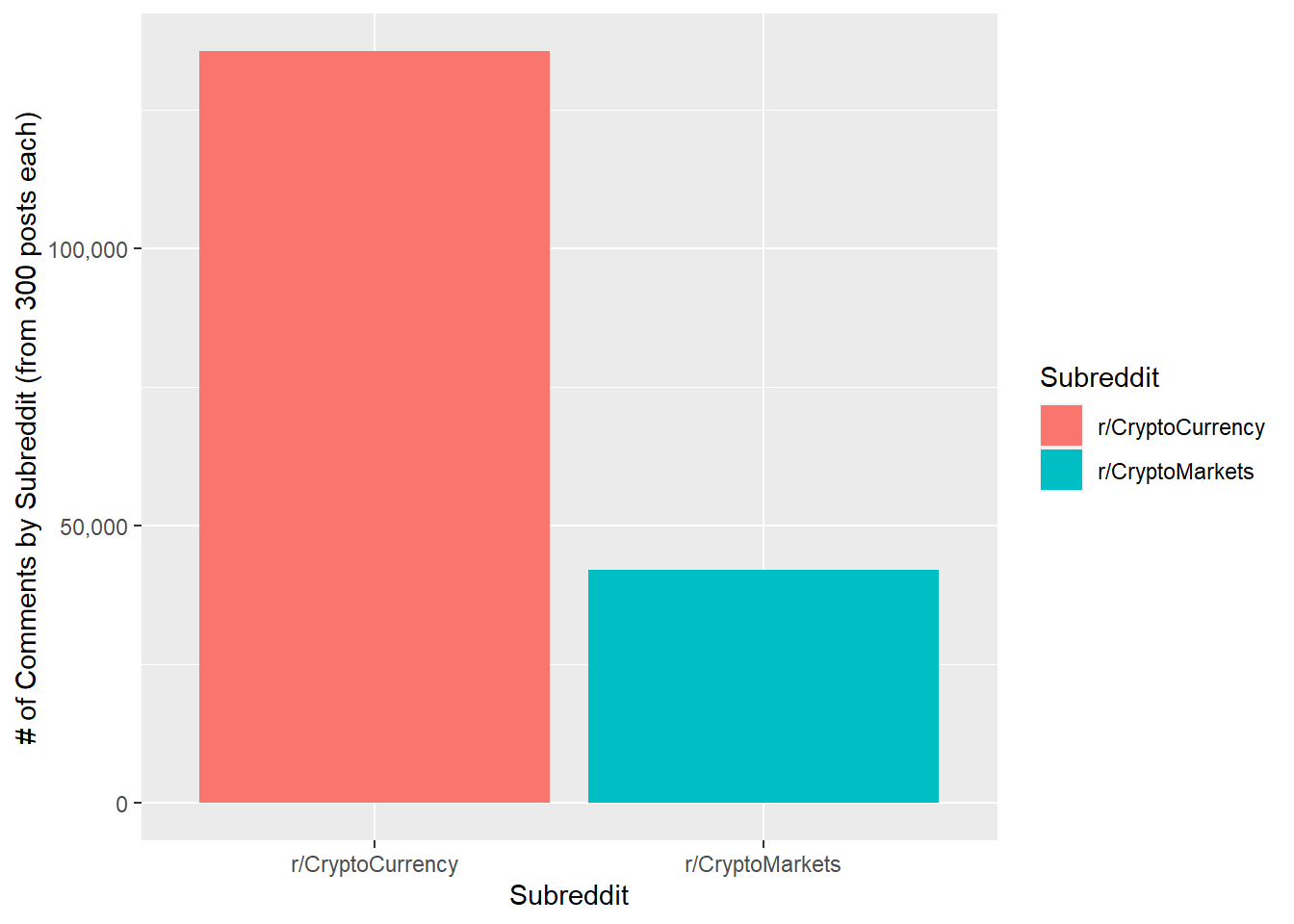
| X | title | subscribers | created | public_description |
|---|---|---|---|---|
| 0 | Cryptocurrency News & Discussion | 1117855 | 2013-03-11 17:51:50 | The official source for CryptoCurrency News, Discussion & Analysis. |
| 0 | r/CryptoMarkets | 236835 | 2013-11-12 18:50:17 |
FOREX community for cryptocurrencies. Tags: mt gox bitcoin, long term potential, open source exchange, low inflation rate, demand and price, technical analysis, fundamentals, Bitcoin, Ethereum, Litecoin, Monero, Dash, Augur, token, volume, oscillator, RSI, stochastic, trend, sentiment, strategy, scam, coin, coinmarketcap, altcoin, Peercoin, script, blockchain, PoW, PoS, Proof of Work, |
Submissions from each subreddit:
Comments in each subreddit:
2.2 Submissions
The analysis of langauge begins by quantifying the presence of words in each Subm, through the process of tokenization. Tokens are discrete strings of words or characters that can be isolated as n-grams; with n pertaining to the number of words in each token. Tokens are pulled from the body of text that is most informative for the purposes of analysis. For submissions, the informative text is the title of the submission, which contains information on topics; whereas, for comments, the informative text is the comment itself.
2.2.1 Clean
To ensure that our data accurately represent activity within the communitas, we want to ensure that each observation is a unique instance of engagement. Reposts tend to be common on reddit, so using a distinct() function on the text column will remove any duplicate posts. Additionally, any posts that are removed from the subreddits return an NA value in user column, thus we can remove deleted comments by filtering out all non user == NA.
#Clean
Encoding(SubmData$text) <- "UTF-8"
Submissions <- SubmData %>%
group_by(user) %>%
filter(!is.na(user)) %>% # Take out deleted comments
ungroup() %>%
distinct(text, .keep_all = TRUE) #remove duplicate submissions
paste("Removed", nrow(SubmData) - nrow(Submissions),"submissions.")## [1] "Removed 14 submissions."data(stop_words)
SubmissionTkns <- Submissions %>%
group_by(subreddit) %>%
unnest_tokens(word, text) %>%
ungroup()As part of the tokenization process for submissions, we remove stop words (e.g. “and”, “a”, “the”) because we are interested in using our tokens to identify prevalent topics of discussion and attitudes in the subreddits.
2.2.1.1 Tokens
#Create object for numbers, so that we can remove them from the data
nums <- SubmissionTkns %>% filter(str_detect(word, "^[0-9]")) %>% select(word) %>% unique() #Source: https://richpauloo.github.io/2017-12-29-Using-tidytext-to-make-word-clouds/
SubmissionTkns <- SubmissionTkns %>%
anti_join(stop_words, by = "word") %>%
anti_join(nums, by = "word") %>%
filter(!grepl("_", .$word))
G1Subm <- SubmissionTkns
2.3 Comments
2.3.1 Clean
2.3.1.1 Tokenize