
Idee besprechen. Paper erhalten. Autonom, Kollaborativ & Selbstevolvierend.
Einfach mit OpenClaw chatten: "Research X" → erledigt.
📄 Unser Paper ist auf arXiv — schau es dir an! AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration








🇺🇸 English ·
🇨🇳 中文 ·
🇯🇵 日本語 ·
🇰🇷 한국어 ·
🇫🇷 Français ·
🇩🇪 Deutsch ·
🇪🇸 Español ·
🇧🇷 Português ·
🇷🇺 Русский ·
🇸🇦 العربية
🏆 Paper-Showcase · 🧑✈️ Co-Pilot-Anleitung · 📖 Integrationsanleitung · 💬 Discord-Community
---

|
🏆 Showcase generierter Paper
8 Paper aus 8 Disziplinen — Mathematik, Statistik, Biologie, Informatik, NLP, RL, Vision, Robustheit — vollstaendig autonom generiert oder mit Human-in-the-Loop Co-Pilot-Fuehrung.

|
---
> **🧪 Wir suchen Tester!** Teste die Pipeline mit deiner eigenen Forschungsidee — aus jedem Fachgebiet — und [sag uns, was du denkst](TESTER_GUIDE.md). Dein Feedback beeinflusst direkt die naechste Version. **[→ Testing Guide](TESTER_GUIDE.md)** | **[→ 中文测试指南](TESTER_GUIDE_CN.md)** | **[→ 日本語テストガイド](TESTER_GUIDE_JA.md)**
---
## 🔥 News
- **[05/19/2026]** **v0.5.0** — **Multi-Domain-Experimentagenten + ARC-Bench** — Zwei wesentliche Updates. **(1) Domaenenspezifische Ausfuehrungsagenten:** Die Experimentphase (Stufen 10–13) leitet nun ueber die Standard-ML-Sandbox hinaus an Fachagenten weiter — **Hochenergiephysik** (ColliderAgent: FeynRules → MadGraph5 → Delphes ueber die Magnus-Cloud), **Biologie** (COBRApy-Stoffwechselmodellierung im Genommassstab) und **Statistik** (Simulationsstudien-Agent), mit einem generischen Docker-Executor fuer Chemie/Materialien. Die Pipeline waehlt den passenden Executor automatisch anhand der Forschungsdomaene. **(2) ARC-Bench:** ein offener Benchmark fuer autonome Forschung mit **55 Themen**, der **ML (25), Hochenergiephysik (10), Quanten (10), Biologie (7) und Statistik (3)** abdeckt — jedes Thema mit Manifest und Bewertungsrubrik (`experiments/arc_bench/`, jetzt auch auf [🤗 Hugging Face](https://huggingface.co/datasets/AIMING-Lab-UNC/ARC-Bench)). **[→ Leitfaden zur Domaenenintegration](DOMAIN_INTEGRATION_GUIDE.md)**
- **[04/01/2026]** **v0.4.0** — **Human-in-the-Loop Co-Pilot-System** — AutoResearchClaw ist nicht mehr rein autonom. Das neue HITL-System fuegt 6 Interventionsmodi hinzu (`full-auto`, `gate-only`, `checkpoint`, `step-by-step`, `co-pilot`, `custom`), stufenspezifische Richtlinien und tiefe Mensch-KI-Kollaboration. Enthalten: Ideen-Workshop zur gemeinsamen Hypothesenerstellung, Baseline-Navigator zur Ueberpruefung des Experimentdesigns, Paper-Co-Writer fuer kollaboratives Verfassen, SmartPause (konfidenzgesteuerte dynamische Intervention), ALHF-Interventionslernen, Anti-Halluzinations-Behauptungsverifikation, Kostenbudget-Leitplanken, Pipeline-Verzweigung fuer parallele Hypothesenerkundung und CLI-Befehle (`attach`/`status`/`approve`/`reject`/`guide`). **[→ Vollstaendige HITL-Anleitung](HITL_GUIDE.md)**
- **[03/30/2026]** **Flexibles Skill-Laden** — AutoResearchClaw unterstuetzt jetzt das Laden von Open-Source- und benutzerdefinierten Skills aus jeder Disziplin, um Ihr Forschungserlebnis weiter zu verbessern. 20 vorinstallierte Skills sind als sofort einsetzbare Referenzen enthalten, die wissenschaftliches Schreiben, Experimentdesign, Chemie, Biologie und mehr abdecken — einschliesslich eines [A-Evolve](https://github.com/A-EVO-Lab/a-evolve) Agentic-Evolution-Skills, der von der Community beigesteuert wurde. Laden Sie eigene ueber `researchclaw skills install` oder legen Sie eine `SKILL.md` in `.claude/skills/` ab. Siehe [Skills-Bibliothek](#-skills-bibliothek).
- **[03/22/2026]** [v0.3.2](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.2) — **Plattformuebergreifende Unterstuetzung + grosse Stabilitaet** — AutoResearchClaw laeuft jetzt mit jedem ACP-kompatiblen Agenten-Backend (Claude Code, Codex CLI, Copilot CLI, Gemini CLI, Kimi CLI) und unterstuetzt Messaging-Plattformen (Discord, Telegram, Lark, WeChat) ueber die OpenClaw-Bruecke. Neues CLI-Agent-Code-Generierungs-Backend delegiert Stages 10 und 13 an externe CLI-Agenten mit Budgetkontrolle und Timeout-Management. Enthaelt Anti-Fabrication-System (VerifiedRegistry + Experiment-Diagnose- und Reparaturschleife), 100+ Bugfixes, modulares Executor-Refactoring, `--resume` Auto-Erkennung, LLM-Retry-Haertung und Community-Fixes.
Frühere Versionen
- **[03/18/2026]** [v0.3.1](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.1) — **OpenCode Beast Mode + Community Contributions** — New "Beast Mode" routes complex code generation to [OpenCode](https://github.com/anomalyco/opencode) with automatic complexity scoring and graceful fallback. Added Novita AI provider support, thread-safety hardening, improved LLM output parsing robustness, and 20+ bug fixes from community PRs and internal audit.
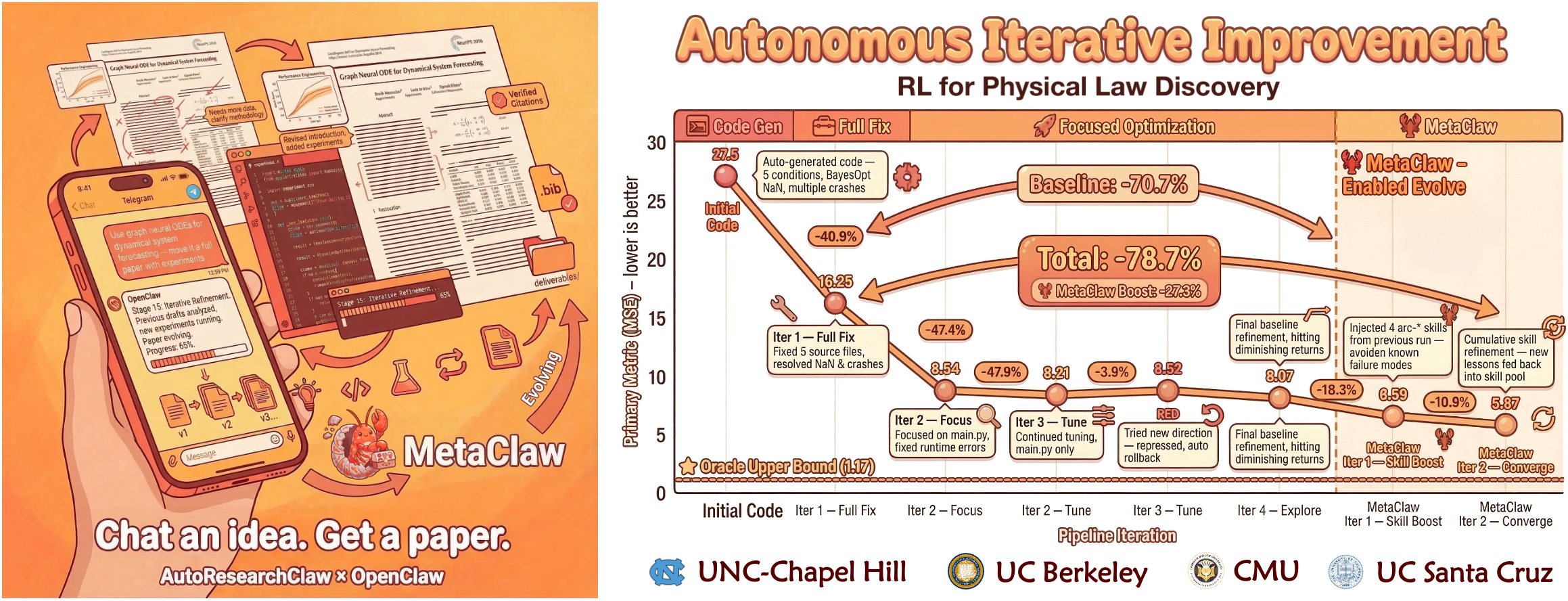
- **[03/17/2026]** [v0.3.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.0) — **MetaClaw Integration** — AutoResearchClaw now supports [MetaClaw](https://github.com/aiming-lab/MetaClaw) cross-run learning: pipeline failures → structured lessons → reusable skills, injected into all 23 stages. **+18.3%** robustness in controlled experiments. Opt-in (`metaclaw_bridge.enabled: true`), fully backward-compatible. See [Integration Guide](#-metaclaw-integration).
- **[03/16/2026]** [v0.2.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.2.0) — Three multi-agent subsystems (CodeAgent, BenchmarkAgent, FigureAgent), hardened Docker sandbox with network-policy-aware execution, 4-round paper quality audit (AI-slop detection, 7-dim review scoring, NeurIPS checklist), and 15+ bug fixes from production runs.
- **[03/15/2026]** [v0.1.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.1.0) — We release AutoResearchClaw: a fully autonomous 23-stage research pipeline that turns a single research idea into a conference-ready paper. No human intervention required.
---
## ⚡ Ein Befehl. Ein Paper.
```bash
# Vollstaendig autonom — kein menschliches Eingreifen
pip install -e . && researchclaw setup && researchclaw init && researchclaw run --topic "Your research idea here" --auto-approve
# Co-Pilot-Modus — an wichtigen Entscheidungspunkten mit KI zusammenarbeiten
researchclaw run --topic "Your research idea here" --mode co-pilot
```
---
## 🤔 Was ist das?
**Du denkst es. AutoResearchClaw schreibt es. Du triffst die wichtigen Entscheidungen.**
Gib ein Forschungsthema ein — erhalte ein vollstaendiges wissenschaftliches Paper mit echter Literatur von OpenAlex, Semantic Scholar und arXiv, hardwarebewussten Sandbox-Experimenten (automatische GPU/MPS/CPU-Erkennung), statistischer Analyse, Multi-Agenten-Peer-Review und konferenzfertigem LaTeX fuer NeurIPS/ICML/ICLR. Fuehre es vollstaendig autonom aus, oder verwende den **Co-Pilot-Modus**, um die KI an kritischen Entscheidungspunkten zu lenken — waehle Forschungsrichtungen, pruefe Experimentdesigns und verfasse das Paper gemeinsam. Keine halluzinierten Referenzen.
| 📄 | paper_draft.md | Vollstaendiges wissenschaftliches Paper (Einleitung, Verwandte Arbeiten, Methode, Experimente, Ergebnisse, Fazit) |
| 📐 | paper.tex | Konferenzfertiges LaTeX (NeurIPS / ICLR / ICML Templates) |
| 📚 | references.bib | Echte BibTeX-Referenzen von OpenAlex, Semantic Scholar und arXiv — automatisch bereinigt, um Inline-Zitationen zu entsprechen |
| 🔍 | verification_report.json | 4-Schicht-Zitationsintegritaets- und Relevanzpruefung (arXiv, CrossRef, DataCite, LLM) |
| 🧪 | experiment runs/ | Generierter Code + Sandbox-Ergebnisse + strukturierte JSON-Metriken |
| 📊 | charts/ | Automatisch generierte Vergleichsdiagramme mit Fehlerbalken und Konfidenzintervallen |
| 📝 | reviews.md | Multi-Agenten-Peer-Review mit Methodik-Evidenz-Konsistenzpruefungen |
| 🧬 | evolution/ | Selbstlernende Erkenntnisse aus jedem Durchlauf |
| 📦 | deliverables/ | Alle finalen Ergebnisse in einem Ordner — kompilierbereit fuer Overleaf |
Die Pipeline laeuft **End-to-End** — vollstaendig autonom oder mit Human-in-the-Loop-Kollaboration. Wenn Experimente fehlschlagen, repariert sie sich selbst. Wenn Hypothesen nicht bestaetigt werden, schwenkt sie um. Wenn Zitationen gefaelscht sind, entfernt sie diese. Wenn du steuern moechtest, pausiert sie und hoert zu.
🌍 **Ueberall ausfuehrbar.** AutoResearchClaw ist nicht an eine einzelne Plattform gebunden. Nutzen Sie es eigenstaendig ueber die CLI, verbinden Sie es mit [OpenClaw](https://github.com/openclaw/openclaw), oder integrieren Sie es mit jedem ACP-kompatiblen AI-Agenten — 🤖 Claude Code, 💻 Codex CLI, 🐙 Copilot CLI, ♊ Gemini CLI, 🌙 Kimi CLI und mehr. Dank der Messaging-Bruecke von OpenClaw koennen Sie eine komplette Forschung von 💬 Discord, ✈️ Telegram, 🐦 Lark (飞书), 💚 WeChat oder jeder anderen Plattform starten, die Ihr Team bereits nutzt. Ein Thema rein, ein Paper raus — egal wo Sie tippen.
---
## 🚀 Schnellstart
```bash
# 1. Klonen & installieren
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Setup (interaktiv — installiert OpenCode Beast Mode, prueft Docker/LaTeX)
researchclaw setup
# 3. Konfigurieren
researchclaw init # Interaktiv: LLM-Anbieter waehlen, erstellt config.arc.yaml
# Oder manuell: cp config.researchclaw.example.yaml config.arc.yaml
# 4. Ausfuehren
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "Your research idea" --auto-approve
```
Ausgabe → `artifacts/rc-YYYYMMDD-HHMMSS-/deliverables/` — kompilierfertiges LaTeX, BibTeX, Experimentcode, Diagramme.
📝 Minimale erforderliche Konfiguration
```yaml
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "https://api.openai.com/v1"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
```
---
## 🧠 Was macht es anders
| Faehigkeit | Funktionsweise |
|-----------|---------------|
| **🧑✈️ Co-Pilot-Modus** | 6 Interventionsmodi — von vollstaendig autonom bis Schritt-fuer-Schritt. Lenke die KI bei kritischen Entscheidungen (Hypothesen, Baselines, Paper-Erstellung) oder lass sie frei laufen. SmartPause erkennt automatisch, wann menschlicher Input hilfreich waere. |
| **🔄 PIVOT / REFINE Schleife** | Stufe 15 entscheidet autonom: PROCEED, REFINE (Parameter anpassen) oder PIVOT (neue Richtung). Artefakte automatisch versioniert. |
| **🤖 Multi-Agenten-Debatte** | Hypothesengenerierung, Ergebnisanalyse und Peer-Review verwenden jeweils strukturierte Multi-Perspektiven-Debatten. |
| **🧬 Selbstlernen** | Erkenntnisse pro Durchlauf extrahiert (Entscheidungsbegruendungen, Laufzeitwarnungen, Metrikanaomalien) mit 30-Tage-Zeitabklingung. Zukuenftige Durchlaeufe lernen aus vergangenen Fehlern. |
| **📚 Wissensdatenbank** | Jeder Durchlauf baut eine strukturierte KB ueber 6 Kategorien auf (Entscheidungen, Experimente, Ergebnisse, Literatur, Fragen, Reviews). |
| **🛡️ Sentinel Watchdog** | Hintergrund-Qualitaetsmonitor: NaN/Inf-Erkennung, Paper-Evidenz-Konsistenz, Zitationsrelevanz-Bewertung, Anti-Fabrikationsschutz. |
| **🔍 Behauptungsverifikation** | Inline-Faktencheck: extrahiert Behauptungen aus KI-generiertem Text und gleicht sie mit gesammelter Literatur ab. Markiert unbegruendete Zitationen und fabrizierte Zahlen. |
| **🌿 Verzweigungserkundung** | Forke die Pipeline, um mehrere Forschungsrichtungen gleichzeitig zu erkunden, Ergebnisse nebeneinander zu vergleichen und den besten Pfad zusammenzufuehren. |
---
## 🦞 OpenClaw-Integration
**AutoResearchClaw ist ein [OpenClaw](https://github.com/openclaw/openclaw)-kompatibler Dienst.** Installiere es in OpenClaw und starte autonome Forschung mit einer einzigen Nachricht — oder verwende es eigenstaendig ueber CLI, Claude Code oder jeden anderen KI-Coding-Assistenten.
### 🚀 Verwendung mit OpenClaw (empfohlen)
Wenn du bereits [OpenClaw](https://github.com/openclaw/openclaw) als KI-Assistenten nutzt:
```
1️⃣ Teile die GitHub-Repo-URL mit OpenClaw
2️⃣ OpenClaw liest automatisch RESEARCHCLAW_AGENTS.md → versteht die Pipeline
3️⃣ Sage: "Research [dein Thema]"
4️⃣ Fertig — OpenClaw klont, installiert, konfiguriert, fuehrt aus und liefert Ergebnisse
```
**Das war's.** OpenClaw uebernimmt `git clone`, `pip install`, Konfiguration und Pipeline-Ausfuehrung automatisch. Du chattest einfach.
💡 Was unter der Haube passiert
1. OpenClaw liest `RESEARCHCLAW_AGENTS.md` → lernt die Forschungs-Orchestrator-Rolle
2. OpenClaw liest `README.md` → versteht Installation und Pipeline-Struktur
3. OpenClaw kopiert `config.researchclaw.example.yaml` → `config.yaml`
4. Fragt nach deinem LLM-API-Schluessel (oder verwendet deine Umgebungsvariable)
5. Fuehrt `pip install -e .` + `researchclaw run --topic "..." --auto-approve` aus
6. Liefert Paper, LaTeX, Experimente und Zitationen zurueck
### 🔌 OpenClaw Bridge (Fortgeschritten)
Fuer tiefere Integration enthaelt AutoResearchClaw ein **Bridge-Adapter-System** mit 6 optionalen Faehigkeiten:
```yaml
# config.arc.yaml
openclaw_bridge:
use_cron: true # ⏰ Geplante Forschungsdurchlaeufe
use_message: true # 💬 Fortschrittsbenachrichtigungen (Discord/Slack/Telegram)
use_memory: true # 🧠 Sitzungsuebergreifende Wissenspersistenz
use_sessions_spawn: true # 🔀 Parallele Sub-Sessions fuer gleichzeitige Stufen
use_web_fetch: true # 🌐 Live-Websuche waehrend der Literaturrecherche
use_browser: false # 🖥️ Browserbasierte Paper-Sammlung
```
Jedes Flag aktiviert ein typisiertes Adapter-Protokoll. Wenn OpenClaw diese Faehigkeiten bereitstellt, nutzen die Adapter sie ohne Codeaenderungen. Siehe [`integration-guide.md`](integration-guide.md) fuer vollstaendige Details.
### ACP (Agent Client Protocol)
AutoResearchClaw kann **jeden ACP-kompatiblen Coding-Agenten** als LLM-Backend verwenden — keine API-Schluessel erforderlich. Der Agent kommuniziert ueber [acpx](https://github.com/openclaw/acpx) und haelt eine einzige persistente Sitzung ueber alle 23 Pipeline-Stufen aufrecht.
| Agent | Befehl | Hinweise |
|-------|--------|----------|
| Claude Code | `claude` | Anthropic |
| Codex CLI | `codex` | OpenAI |
| Copilot CLI | `gh` | GitHub |
| Gemini CLI | `gemini` | Google |
| OpenCode | `opencode` | SST |
| Kimi CLI | `kimi` | Moonshot |
```yaml
# config.yaml — ACP-Beispiel
llm:
provider: "acp"
acp:
agent: "claude" # Jeder ACP-kompatible Agent-CLI-Befehl
cwd: "." # Arbeitsverzeichnis fuer den Agenten
# Kein base_url oder api_key noetig — der Agent verwaltet seine eigene Authentifizierung.
```
```bash
# Einfach ausfuehren — der Agent verwendet seine eigenen Anmeldedaten
researchclaw run --config config.yaml --topic "Your research idea" --auto-approve
```
### 🛠️ Weitere Ausfuehrungsmoeglichkeiten
| Methode | Anleitung |
|---------|-----------|
| **Standalone CLI** | `researchclaw run --topic "..." --auto-approve` (autonom) oder `--mode co-pilot` (kollaborativ) |
| **Python API** | `from researchclaw.pipeline import Runner; Runner(config).run()` |
| **Claude Code** | Liest `RESEARCHCLAW_CLAUDE.md` — sage einfach *"Run research on [Thema]"* |
| **Copilot CLI** | `researchclaw run --topic "..."` mit `llm.acp.agent: "gh"` |
| **OpenCode** | Liest `.claude/skills/` — gleiche natuerliche Sprachschnittstelle |
| **Jeder KI-CLI** | Uebergib `RESEARCHCLAW_AGENTS.md` als Kontext → Agent bootstrappt automatisch |
---
## 🔬 Pipeline: 23 Stufen, 8 Phasen
```
Phase A: Forschungsplanung Phase E: Experimentausfuehrung
1. TOPIC_INIT 12. EXPERIMENT_RUN
2. PROBLEM_DECOMPOSE 13. ITERATIVE_REFINE ← Selbstheilung
Phase B: Literaturrecherche Phase F: Analyse & Entscheidung
3. SEARCH_STRATEGY 14. RESULT_ANALYSIS ← Multi-Agent
4. LITERATURE_COLLECT ← echte API 15. RESEARCH_DECISION ← PIVOT/REFINE
5. LITERATURE_SCREEN [Gate]
6. KNOWLEDGE_EXTRACT Phase G: Papiererstellung
16. PAPER_OUTLINE
Phase C: Wissenssynthese 17. PAPER_DRAFT
7. SYNTHESIS 18. PEER_REVIEW ← Evidenzpruefung
8. HYPOTHESIS_GEN ← Debatte 19. PAPER_REVISION
Phase D: Experimentdesign Phase H: Finalisierung
9. EXPERIMENT_DESIGN [Gate] 20. QUALITY_GATE [Gate]
10. CODE_GENERATION 21. KNOWLEDGE_ARCHIVE
11. RESOURCE_PLANNING 22. EXPORT_PUBLISH ← LaTeX
23. CITATION_VERIFY ← Relevanzpruefung
```
> **Gate-Stufen** (5, 9, 20) pausieren fuer menschliche Genehmigung oder werden mit `--auto-approve` automatisch genehmigt. Bei Ablehnung wird die Pipeline zurueckgesetzt.
> **Co-Pilot-Modus** (`--mode co-pilot`): Tiefe Mensch-KI-Kollaboration in den Stufen 7-8 (Ideen-Workshop), Stufe 9 (Baseline-Navigator) und Stufen 16-17 (Paper-Co-Writer). Andere Stufen laufen automatisch mit SmartPause-Ueberwachung.
> **Entscheidungsschleifen**: Stufe 15 kann REFINE (→ Stufe 13) oder PIVOT (→ Stufe 8) ausloesen, mit automatischer Artefakt-Versionierung.
📋 Was jede Phase bewirkt
| Phase | Beschreibung |
|-------|-------------|
| **A: Planung** | LLM zerlegt das Thema in einen strukturierten Problembaum mit Forschungsfragen |
| **A+: Hardware** | Automatische GPU-Erkennung (NVIDIA CUDA / Apple MPS / nur CPU), Warnung bei eingeschraenkter Hardware, Codegenerierung wird entsprechend angepasst |
| **B: Literatur** | Multi-Source-Suche (OpenAlex → Semantic Scholar → arXiv) nach echten Papern, Relevanzscreening, Extraktion von Wissenskarten |
| **C: Synthese** | Clustering der Ergebnisse, Identifizierung von Forschungsluecken, Generierung testbarer Hypothesen via Multi-Agenten-Debatte |
| **D: Design** | Experimentplan entwerfen, hardwarebewussten ausfuehrbaren Python-Code generieren (GPU-Stufe → Paketauswahl), Ressourcenbedarf schaetzen |
| **E: Ausfuehrung** | Experimente in Sandbox ausfuehren, NaN/Inf und Laufzeitfehler erkennen, Code via gezielter LLM-Reparatur selbst heilen |
| **F: Analyse** | Multi-Agenten-Analyse der Ergebnisse; autonome PROCEED / REFINE / PIVOT Entscheidung mit Begruendung |
| **G: Schreiben** | Gliederung → abschnittsweises Verfassen (5.000-6.500 Woerter) → Peer-Review (mit Methodik-Evidenz-Konsistenz) → Revision mit Laengenpruefung |
| **H: Finalisierung** | Qualitaets-Gate, Wissensarchivierung, LaTeX-Export mit Konferenztemplate, Zitationsintegritaets- und Relevanzpruefung |
---
## ✨ Hauptfunktionen
| Funktion | Beschreibung |
|----------|-------------|
| **📚 Multi-Source-Literatur** | Echte Paper von OpenAlex, Semantic Scholar und arXiv — Abfrageerweiterung, Deduplizierung, Circuit Breaker mit Graceful Degradation |
| **🔍 4-Schicht-Zitationsverifikation** | arXiv-ID-Pruefung → CrossRef/DataCite-DOI → Semantic-Scholar-Titelabgleich → LLM-Relevanzbewertung. Halluzinierte Refs automatisch entfernt. |
| **🖥️ Hardwarebewusste Ausfuehrung** | Automatische GPU-Erkennung (NVIDIA CUDA / Apple MPS / nur CPU) und Anpassung von Codegenerierung, Imports und Experimentumfang |
| **🦾 OpenCode Beast Mode** | Komplexe Experimente werden automatisch an [OpenCode](https://github.com/anomalyco/opencode) weitergeleitet — generiert Multi-File-Projekte mit individuellen Architekturen, Trainingsschleifen und Ablationsstudien. Installation ueber `researchclaw setup`. |
| **🧪 Sandbox-Experimente** | AST-validierter Code, unveraenderlicher Harness, NaN/Inf-Schnellabbruch, selbstheilende Reparatur, iterative Verfeinerung (bis zu 10 Runden), Teilergebnis-Erfassung |
| **📝 Konferenzqualitaet** | NeurIPS/ICML/ICLR-Templates, abschnittsweises Verfassen (5.000-6.500 Woerter), Anti-Fabrikationsschutz, Revisions-Laengenschutz, Anti-Disclaimer-Durchsetzung |
| **📐 Template-Umschaltung** | `neurips_2025`, `iclr_2026`, `icml_2026` — Markdown → LaTeX mit Mathematik, Tabellen, Abbildungen, Querverweisen, `\cite{}` |
| **🛡️ Anti-Fabrikation** | VerifiedRegistry erzwingt Ground-Truth-Experimentdaten in Papern. Automatische Diagnose und Reparatur fehlgeschlagener Experimente vor dem Schreiben. Ungepruefte Zahlen bereinigt. |
| **🚦 Qualitaets-Gates** | 3 Human-in-the-Loop-Gates (Stufen 5, 9, 20) mit Rollback. Ueberspringen mit `--auto-approve`. |
| **🧑✈️ HITL-Co-Pilot** | 6 Interventionsmodi mit stufenspezifischen Richtlinien. Ideen-Workshop, Baseline-Navigator, Paper-Co-Writer fuer tiefe Kollaboration. SmartPause, Kostenbudget-Leitplanken, Eskalationsrichtlinien und Interventionslernen fuer Produktionssicherheit. CLI/WebSocket/MCP-Adapter. |
| **💰 Kostenbudget-Leitplanken** | Budgetueberwachung mit konfigurierbaren Schwellenwert-Alarmen (50%/80%/100%). Pipeline pausiert automatisch, wenn die Kosten das Budget ueberschreiten. |
| **🔐 Reproduzierbarkeit** | SHA256-Pruefsummen fuer alle Stufenartefakte. Unveraenderliche Manifeste zur Verifikation. Mehrstufiges Undo mit versionierten Snapshots. |
---
## 🧑✈️ Human-in-the-Loop Co-Pilot
**AutoResearchClaw v0.4.0 fuehrt ein vollstaendiges Human-in-the-Loop (HITL)-System ein**, das die Pipeline von rein autonom zu einer kollaborativen Mensch-KI-Forschungsmaschine transformiert. Waehle dein Beteiligungsniveau:
### Interventionsmodi
| Modus | Befehl | Beschreibung |
|-------|--------|-------------|
| **Full Auto** | `--auto-approve` | Urspruengliches Verhalten — kein menschliches Eingreifen |
| **Gate Only** | `--mode gate-only` | Pause an 3 Gate-Stufen (5, 9, 20) zur Genehmigung |
| **Checkpoint** | `--mode checkpoint` | Pause an jeder Phasengrenze (8 Checkpoints) |
| **Co-Pilot** | `--mode co-pilot` | Tiefe Kollaboration an kritischen Stufen, sonst automatisch |
| **Step-by-Step** | `--mode step-by-step` | Pause nach jeder Stufe — lerne die Pipeline kennen |
| **Express** | `--mode express` | Schnellpruefung — nur die 3 kritischsten Gates |
### Co-Pilot-Workflow
```
Du: researchclaw run --topic "Quantenrauschen als neuronales Netzwerk-Regularisierung" --mode co-pilot
Pipeline fuehrt Stufen 1-7 automatisch aus...
┌─────────────────────────────────────────────────────────────┐
│ HITL | Stufe 08: HYPOTHESIS_GEN │
│ Post-Stage-Pruefung │
│ │
│ Erwaehnte Hypothesen: 3 │
│ Neuheitswert: 0.72 (moderat) │
│ │
│ [a] Genehmigen [r] Ablehnen [e] Bearbeiten [c] Kollaborieren │
│ [i] Anleitung einfuegen [v] Ausgabe anzeigen [q] Abbrechen │
└─────────────────────────────────────────────────────────────┘
Du: c (kollaborativen Chat starten)
Du: Hypothese 3 ist interessant, braucht aber Dropout/Label Smoothing als Baselines
KI: Aktualisiert — Dropout, Label Smoothing, MixUp, CutMix als Baselines hinzugefuegt...
Du: genehmigen
Pipeline setzt mit deiner verfeinerten Hypothese fort...
```
### CLI-Befehle
```bash
# Mit HITL-Modus starten
researchclaw run --topic "..." --mode co-pilot
# An eine pausierte Pipeline anhaengen (von einem anderen Terminal)
researchclaw attach artifacts/rc-2026-xxx
# Pipeline- und HITL-Status pruefen
researchclaw status artifacts/rc-2026-xxx
# Von einem anderen Terminal oder Skript genehmigen/ablehnen
researchclaw approve artifacts/rc-2026-xxx --message "Sieht gut aus"
researchclaw reject artifacts/rc-2026-xxx --reason "Wichtige Baseline fehlt"
# Anleitung fuer eine Stufe einfuegen (auch bevor sie laeuft)
researchclaw guide artifacts/rc-2026-xxx --stage 9 --message "ResNet-50 als primaere Baseline verwenden"
```
### Hauptfaehigkeiten
| Funktion | Beschreibung |
|----------|-------------|
| **Ideen-Workshop** | Hypothesen gemeinsam brainstormen, bewerten und verfeinern (Stufe 7-8) |
| **Baseline-Navigator** | KI schlaegt Baselines vor + Mensch fuegt hinzu/entfernt + Reproduzierbarkeitscheckliste (Stufe 9) |
| **Paper-Co-Writer** | Abschnittsweises Verfassen mit menschlicher Bearbeitung und KI-Feinschliff (Stufe 16-19) |
| **SmartPause** | Konfidenzgesteuerte dynamische Pausierung — erkennt automatisch, wann menschlicher Input hilfreich waere |
| **Behauptungsverifikation** | Inline-Faktencheck gegen gesammelte Literatur — markiert unbegruendete Behauptungen |
| **Kostenbudget-Leitplanken** | Budgetueberwachung mit 50%/80%/100% Schwellenwert-Alarmen |
| **Interventionslernen** | ALHF — lernt aus deinen Review-Mustern, um zukuenftige Pausen-Entscheidungen zu optimieren |
| **Verzweigungserkundung** | Forke die Pipeline, um mehrere Hypothesen zu erkunden, vergleiche und fuehre die beste zusammen |
| **Eskalationsrichtlinie** | Gestufte Benachrichtigung (Terminal → Slack → E-Mail → Auto-Halt) bei Unbeaufsichtigung |
| **3 Adapter** | CLI (Terminal), WebSocket (Web-Dashboard), MCP (externe Agenten) |
### Konfiguration
```yaml
# config.arc.yaml
hitl:
enabled: true
mode: co-pilot # full-auto | gate-only | checkpoint | co-pilot | custom
cost_budget_usd: 50.0 # Pausieren wenn Kosten das Budget ueberschreiten (0 = kein Limit)
notifications:
on_pause: true
on_quality_drop: true
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # 24h Standard-Wartezeit
auto_proceed_on_timeout: false
collaboration:
max_chat_turns: 50
save_chat_history: true
# Stufenspezifische benutzerdefinierte Richtlinien (optional, fuer 'custom'-Modus)
stage_policies:
8: { require_approval: true, enable_collaboration: true }
9: { require_approval: true, allow_edit_output: true }
```
### Abwaertskompatibilitaet
- **Standard: AUS.** Ohne `hitl.enabled: true` oder `--mode` verhaelt sich die Pipeline exakt wie zuvor.
- **`--auto-approve` funktioniert weiterhin.** Es ueberschreibt den HITL-Modus.
- **Alle 2.699 bestehenden Tests bestehen** mit vorhandenem HITL-Code.
---
## 🧠 MetaClaw-Integration
**AutoResearchClaw + [MetaClaw](https://github.com/aiming-lab/MetaClaw) = Eine Pipeline, die aus jedem Durchlauf lernt.**
MetaClaw fuegt **durchlaufuebergreifenden Wissenstransfer** zu AutoResearchClaw hinzu. Wenn aktiviert, erfasst die Pipeline automatisch Erkenntnisse aus Fehlern und Warnungen, konvertiert sie in wiederverwendbare Skills und injiziert diese Skills in alle 23 Pipeline-Stufen bei nachfolgenden Durchlaeufen — damit dieselben Fehler nie wiederholt werden.
### Funktionsweise
```
Durchlauf N wird ausgefuehrt → Fehler/Warnungen als Lektionen erfasst
↓
MetaClaw Lektion → Skill-Konvertierung
↓
arc-* Skill-Dateien in ~/.metaclaw/skills/ gespeichert
↓
Durchlauf N+1 → build_overlay() injiziert Skills in jeden LLM-Prompt
↓
LLM vermeidet bekannte Fallstricke → hoehere Qualitaet, weniger Wiederholungen
```
### Schnelleinrichtung
```bash
# 1. MetaClaw installieren (falls nicht vorhanden)
pip install metaclaw
# 2. In der Konfiguration aktivieren
```
```yaml
# config.arc.yaml
metaclaw_bridge:
enabled: true
proxy_url: "http://localhost:30000" # MetaClaw-Proxy (optional)
skills_dir: "~/.metaclaw/skills" # Wo Skills gespeichert werden
fallback_url: "https://api.openai.com/v1" # Direkter LLM-Fallback
fallback_api_key: "" # API-Schluessel fuer Fallback-URL
lesson_to_skill:
enabled: true
min_severity: "warning" # Warnungen + Fehler konvertieren
max_skills_per_run: 3
```
```bash
# 3. Wie gewohnt ausfuehren — MetaClaw arbeitet transparent
researchclaw run --config config.arc.yaml --topic "Your idea" --auto-approve
```
Nach jedem Durchlauf kannst du `~/.metaclaw/skills/arc-*/SKILL.md` pruefen, um die erlernten Skills deiner Pipeline zu sehen.
### Experimentergebnisse
In kontrollierten A/B-Experimenten (gleiches Thema, gleiches LLM, gleiche Konfiguration):
| Metrik | Baseline | Mit MetaClaw | Verbesserung |
|--------|----------|--------------|--------------|
| Stufen-Wiederholungsrate | 10.5% | 7.9% | **-24.8%** |
| Anzahl REFINE-Zyklen | 2.0 | 1.2 | **-40.0%** |
| Pipeline-Stufenabschluss | 18/19 | 19/19 | **+5.3%** |
| Gesamtrobustheitswert (Komposit) | 0.714 | 0.845 | **+18.3%** |
> Der Komposit-Robustheitswert ist ein gewichteter Durchschnitt aus Stufenabschlussrate (40%), Wiederholungsreduktion (30%) und REFINE-Zykluseffizienz (30%).
### Abwaertskompatibilitaet
- **Standard: AUS.** Wenn `metaclaw_bridge` fehlt oder `enabled: false`, verhaelt sich die Pipeline exakt wie zuvor.
- **Keine neuen Abhaengigkeiten.** MetaClaw ist optional — die Kern-Pipeline funktioniert ohne.
- **Alle 2.699 bestehenden Tests bestehen** mit dem Integrationscode.
---
## 🧩 Skills-Bibliothek
AutoResearchClaw unterstuetzt jetzt das Laden von **Open-Source- und benutzerdefinierten Skills**, um Ihr Forschungserlebnis weiter zu verbessern. Wir liefern ausserdem **20 vorinstallierte integrierte Skills** (wissenschaftliches Schreiben, Literatursuche, Chemie, Biologie und mehr) als sofort einsetzbare Referenzen mit, die von Anfang an ein hohes Mass an Flexibilitaet bieten. Deaktivieren Sie einen Skill, indem Sie `enabled: false` in seinen Frontmatter einfuegen.
**Beispiele fuer integrierte Skills:**
| Kategorie | Skill | Beschreibung |
|-----------|-------|-------------|
| **Schreiben** | `scientific-writing` | IMRAD-Struktur, Zitationsformatierung, Berichtsrichtlinien |
| **Domaene** | `chemistry-rdkit` | Molekuelanalyse, SMILES, Fingerprints, Wirkstoffforschung |
| **Experiment** | `literature-search` | Systematische Uebersicht, PRISMA-Methodik |
> Alle 20 Skills anzeigen mit `researchclaw skills list`.
### Eigene Skills laden
```bash
# Option 1: Skill installieren (projektuebergreifend persistent)
researchclaw skills install /path/to/my-skill/
# Option 2: SKILL.md ins Projekt legen
mkdir -p .claude/skills/my-custom-skill
# Dann eine SKILL.md mit YAML-Frontmatter erstellen (name, description, trigger-keywords, applicable-stages)
# Option 3: Gemeinsame Skill-Verzeichnisse in config.arc.yaml konfigurieren
# skills:
# custom_dirs:
# - /path/to/team-shared-skills
```
### Skills verwenden
Skills werden automatisch geladen und in LLM-Prompts injiziert — keine manuelle Aktivierung noetig. Verwenden Sie die CLI zur Inspektion:
```bash
researchclaw skills list # Alle geladenen Skills mit Quellen anzeigen
researchclaw skills validate ./my-skill # SKILL.md-Format pruefen
```
Community-Skills durchsuchen: [K-Dense-AI/claude-scientific-skills](https://github.com/K-Dense-AI/claude-scientific-skills) (150+ wissenschaftliche Skills aus mehreren Disziplinen).
---
## ⚙️ Konfigurationsreferenz
Klicken zum Aufklappen der vollstaendigen Konfigurationsreferenz
```yaml
# === Projekt ===
project:
name: "my-research" # Projektbezeichner
mode: "docs-first" # docs-first | semi-auto | full-auto
# === Forschung ===
research:
topic: "..." # Forschungsthema (erforderlich)
domains: ["ml", "nlp"] # Forschungsdomaenen fuer Literatursuche
daily_paper_count: 8 # Ziel-Paperzahl pro Suchabfrage
quality_threshold: 4.0 # Mindestqualitaetswert fuer Paper
# === Laufzeit ===
runtime:
timezone: "America/New_York" # Fuer Zeitstempel
max_parallel_tasks: 3 # Limit gleichzeitiger Experimente
approval_timeout_hours: 12 # Gate-Stufen-Timeout
retry_limit: 2 # Wiederholungsanzahl bei Stufenfehler
# === LLM ===
llm:
provider: "openai-compatible" # openai | openrouter | deepseek | minimax | acp | openai-compatible
base_url: "https://..." # API-Endpunkt (erforderlich fuer openai-compatible)
api_key_env: "OPENAI_API_KEY" # Umgebungsvariable fuer API-Schluessel (erforderlich fuer openai-compatible)
api_key: "" # Oder Schluessel direkt eintragen
primary_model: "gpt-4o" # Primaeres Modell
fallback_models: ["gpt-4o-mini"] # Fallback-Kette
s2_api_key: "" # Semantic Scholar API-Schluessel (optional, hoehere Rate-Limits)
acp: # Nur verwendet wenn provider: "acp"
agent: "claude" # ACP-Agent-CLI-Befehl (claude, codex, gemini, etc.)
cwd: "." # Arbeitsverzeichnis fuer den Agenten
# === Experiment ===
experiment:
mode: "sandbox" # simulated | sandbox | docker | ssh_remote
time_budget_sec: 300 # Max. Ausfuehrungszeit pro Durchlauf (Standard: 300s)
max_iterations: 10 # Max. Optimierungsiterationen
metric_key: "val_loss" # Primaerer Metrikname
metric_direction: "minimize" # minimize | maximize
sandbox:
python_path: ".venv/bin/python"
gpu_required: false
allowed_imports: [math, random, json, csv, numpy, torch, sklearn]
max_memory_mb: 4096
docker:
image: "researchclaw/experiment:latest"
network_policy: "setup_only" # none | setup_only | pip_only | full
gpu_enabled: true
memory_limit_mb: 8192
auto_install_deps: true # Automatische Import-Erkennung → requirements.txt
ssh_remote:
host: "" # GPU-Server-Hostname
gpu_ids: [] # Verfuegbare GPU-IDs
remote_workdir: "/tmp/researchclaw_experiments"
opencode: # OpenCode Beast Mode (auto-installiert ueber `researchclaw setup`)
enabled: true # Hauptschalter (Standard: true)
auto: true # Auto-Ausloesung ohne Bestaetigung (Standard: true)
complexity_threshold: 0.2 # 0.0-1.0 — hoeher = nur bei komplexen Experimenten ausloesen
model: "" # Modell ueberschreiben (leer = llm.primary_model verwenden)
timeout_sec: 600 # Max. Sekunden fuer OpenCode-Generierung
max_retries: 1 # Wiederholungsanzahl bei Fehler
workspace_cleanup: true # Temporaeren Workspace nach Sammlung entfernen
code_agent: # CodeAgent v2 — Mehrphasen-Codegenerierung
enabled: true # CodeAgent statt Legacy-Einzelprompt-Codegen verwenden
architecture_planning: true # Tiefe Implementierungsblaupause vor dem Codieren generieren
sequential_generation: true # Dateien einzeln nach Abhaengigkeits-DAG generieren
hard_validation: true # AST-basierte Validierungs-Gates (blockiert identische Ablationen, hardcodierte Metriken)
hard_validation_max_repairs: 2 # Max. Reparaturversuche bei fehlgeschlagener Validierung
exec_fix_max_iterations: 3 # Ausfuehrungs-Reparaturversuche
exec_fix_timeout_sec: 60 # Timeout pro Reparaturversuch
benchmark_agent: # BenchmarkAgent — automatisierte Datensatz- & Baseline-Auswahl
enabled: true # 4-Agenten-Benchmark-Pipeline aktivieren (Surveyor→Selector→Acquirer→Validator)
enable_hf_search: true # HuggingFace Datasets durchsuchen
enable_web_search: true # Google Scholar nach Benchmarks durchsuchen
tier_limit: 2 # Datensatz-Stufen-Filter (1=klein/gecacht, 2=mittel, 3=gross)
min_benchmarks: 1 # Mindestanzahl Datensaetze
min_baselines: 2 # Mindestanzahl Baseline-Methoden
figure_agent: # FigureAgent — akademische Abbildungserstellung
enabled: true # 5-Agenten-Abbildungs-Pipeline aktivieren (Planner→CodeGen→Renderer→Critic→Integrator)
min_figures: 3 # Mindestanzahl Abbildungen
max_figures: 8 # Maximalanzahl Abbildungen
max_iterations: 3 # Kritik-gesteuerte Verfeinerungsiterationen
dpi: 300 # Ausgabeaufloesung
strict_mode: false # Pipeline bei fehlgeschlagener Abbildungserstellung abbrechen
repair: # Anti-Fabrikations-Experiment-Reparatur
enabled: true # Fehlgeschlagene Experimente automatisch diagnostizieren und reparieren
max_cycles: 3 # Reparatur-Wiederholungsschleifen
min_completion_rate: 0.5 # >=50% Bedingungen muessen abgeschlossen sein
min_conditions: 2 # Mindestens 2 Bedingungen fuer gueltiges Experiment
use_opencode: true # Reparaturen ueber OpenCode Beast Mode leiten
# === Websuche (Optional) ===
web_search:
enabled: true # Web-erweiterte Literatursuche aktivieren
tavily_api_key_env: "TAVILY_API_KEY" # Tavily API-Schluessel Umgebungsvariable (optional)
enable_scholar: true # Google Scholar-Suche
enable_pdf_extraction: true # Text aus PDFs extrahieren
max_web_results: 10 # Max. Webergebnisse pro Abfrage
# === Export ===
export:
target_conference: "neurips_2025" # neurips_2025 | iclr_2026 | icml_2026
authors: "Anonymous"
bib_file: "references"
# === Prompts ===
prompts:
custom_file: "" # Pfad zur benutzerdefinierten Prompts-YAML (leer = Standardwerte)
# === HITL Co-Pilot (NEU in v0.4.0) ===
hitl:
enabled: false # Auf true setzen um HITL zu aktivieren
mode: co-pilot # full-auto | gate-only | checkpoint | step-by-step | co-pilot | custom
cost_budget_usd: 0.0 # Kostenlimit in USD (0 = kein Limit)
notifications:
on_pause: true # Benachrichtigung wenn Pipeline pausiert
on_quality_drop: true # Benachrichtigung bei Qualitaetsproblemen
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # Bis zu 24h auf menschlichen Input warten
auto_proceed_on_timeout: false # Wenn true, automatisch genehmigen bei Timeout
collaboration:
max_chat_turns: 50 # Max. Turns pro Kollaborationssitzung
save_chat_history: true # Chat-Protokolle speichern
stage_policies: {} # Stufenspezifische Ueberschreibungen (fuer 'custom'-Modus)
# === Sicherheit ===
security:
hitl_required_stages: [5, 9, 20] # Stufen, die menschliche Genehmigung erfordern
allow_publish_without_approval: false
redact_sensitive_logs: true
# === Wissensdatenbank ===
knowledge_base:
backend: "markdown" # markdown | obsidian
root: "docs/kb"
# === Benachrichtigungen ===
notifications:
channel: "console" # console | discord | slack
target: ""
# === MetaClaw Bridge (Optional) ===
metaclaw_bridge:
enabled: false # Auf true setzen fuer durchlaufuebergreifendes Lernen
proxy_url: "http://localhost:30000" # MetaClaw-Proxy-URL
skills_dir: "~/.metaclaw/skills" # Wo arc-* Skills gespeichert werden
fallback_url: "" # Direkter LLM-Fallback wenn Proxy nicht erreichbar
fallback_api_key: "" # API-Schluessel fuer Fallback-Endpunkt
lesson_to_skill:
enabled: true # Lektionen automatisch in Skills konvertieren
min_severity: "warning" # Mindestschwere fuer Konvertierung
max_skills_per_run: 3 # Max. neue Skills pro Pipeline-Durchlauf
prm: # Process Reward Model Qualitaets-Gate (optional)
enabled: false # LLM-als-Juror zur Bewertung von Stufenausgaben verwenden
model: "gpt-5.4" # PRM-Juror-Modell
votes: 3 # Mehrheitsentscheidung-Anzahl
gate_stages: [5, 9, 15, 20] # Stufen fuer PRM-Gates
# === OpenClaw Bridge ===
openclaw_bridge:
use_cron: false # Geplante Forschungsdurchlaeufe
use_message: false # Fortschrittsbenachrichtigungen
use_memory: false # Sitzungsuebergreifende Wissenspersistenz
use_sessions_spawn: false # Parallele Sub-Sessions starten
use_web_fetch: false # Live-Websuche
use_browser: false # Browserbasierte Paper-Sammlung
```
---
## 🙏 Danksagungen
Inspiriert von:
- 🔬 [AI Scientist](https://github.com/SakanaAI/AI-Scientist) (Sakana AI) — Pionier der automatisierten Forschung
- 🧠 [AutoResearch](https://github.com/karpathy/autoresearch) (Andrej Karpathy) — End-to-End-Forschungsautomatisierung
- 🌐 [FARS](https://analemma.ai/blog/introducing-fars/) (Analemma) — Fully Automated Research System
---
## 📄 Lizenz
MIT — siehe [LICENSE](../LICENSE) fuer Details.
---
## 📌 Zitation
Wenn du AutoResearchClaw nuetzlich findest, zitiere bitte:
```bibtex
@misc{liu2026autoresearchclawselfreinforcingautonomousresearch,
title={AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration},
author={Jiaqi Liu and Shi Qiu and Mairui Li and Bingzhou Li and Haonian Ji and Siwei Han and Xinyu Ye and Peng Xia and Zihan Dong and Congyu Zhang and Letian Zhang and Guiming Chen and Haoqin Tu and Xinyu Yang and Lu Feng and Xujiang Zhao and Haifeng Chen and Jiawei Zhou and Xiao Wang and Weitong Zhang and Hongtu Zhu and Yun Li and Jieru Mei and Hongliang Fei and Jiaheng Zhang and Linjie Li and Linjun Zhang and Yuyin Zhou and Sheng Wang and Caiming Xiong and James Zou and Zeyu Zheng and Cihang Xie and Mingyu Ding and Huaxiu Yao},
year={2026},
eprint={2605.20025},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.20025},
}
```
Gebaut mit 🦞 vom AutoResearchClaw-Team