
Comparte una idea. Obten un articulo. Autonomo, Colaborativo & Auto-evolutivo.
Chatea con OpenClaw: "Investiga X" → hecho.
📄 Nuestro articulo esta en arXiv — ¡ven a leerlo! AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration








🇺🇸 English ·
🇨🇳 中文 ·
🇯🇵 日本語 ·
🇰🇷 한국어 ·
🇫🇷 Français ·
🇩🇪 Deutsch ·
🇪🇸 Español ·
🇧🇷 Português ·
🇷🇺 Русский ·
🇸🇦 العربية
🏆 Galeria de articulos · 🧑✈️ Guia de Co-Piloto · 📖 Guia de integracion · 💬 Comunidad Discord
---

|
🏆 Galeria de articulos generados
8 articulos en 8 dominios — matematicas, estadistica, biologia, computacion, NLP, RL, vision, robustez — generados de forma completamente autonoma o con guia de co-piloto Human-in-the-Loop.

|
---
> **🧪 Buscamos testers!** Prueba el pipeline con tu propia idea de investigacion — de cualquier campo — y [cuentanos que piensas](TESTER_GUIDE.md). Tu feedback da forma directamente a la proxima version. **[→ Testing Guide](TESTER_GUIDE.md)** | **[→ 中文测试指南](TESTER_GUIDE_CN.md)** | **[→ 日本語テストガイド](TESTER_GUIDE_JA.md)**
---
## 🔥 News
- **[05/19/2026]** **v0.5.0** — **Agentes de experimentacion multidominio + ARC-Bench** — Dos actualizaciones principales. **(1) Agentes de ejecucion especializados por dominio:** la etapa de experimentos (etapas 10–13) ahora va mas alla del sandbox de ML por defecto y enruta a agentes especializados por campo — **fisica de altas energias** (ColliderAgent: FeynRules → MadGraph5 → Delphes via la nube Magnus), **biologia** (modelado metabolico a escala genomica con COBRApy) y **estadistica** (agente de estudios de simulacion), con un ejecutor Docker generico para quimica/materiales. El pipeline selecciona automaticamente el ejecutor adecuado segun el dominio. **(2) ARC-Bench:** un benchmark de investigacion autonoma abierta de **55 temas** que cubre **ML (25), fisica de altas energias (10), cuantica (10), biologia (7) y estadistica (3)**, cada uno con un manifiesto y una rubrica de evaluacion (`experiments/arc_bench/`, y también en [🤗 Hugging Face](https://huggingface.co/datasets/AIMING-Lab-UNC/ARC-Bench)). **[→ Guia de integracion de dominios](DOMAIN_INTEGRATION_GUIDE.md)**
- **[04/01/2026]** **v0.4.0** — **Sistema Co-Piloto Human-in-the-Loop** — AutoResearchClaw ya no es puramente autonomo. El nuevo sistema HITL agrega 6 modos de intervencion (`full-auto`, `gate-only`, `checkpoint`, `step-by-step`, `co-pilot`, `custom`), politicas por etapa y colaboracion profunda humano-IA. Incluye: Taller de Ideas para co-creacion de hipotesis, Navegador de Baselines para revision del diseno experimental, Co-Escritor de Articulos para redaccion colaborativa, SmartPause (intervencion dinamica basada en confianza), aprendizaje de intervencion ALHF, verificacion de afirmaciones anti-alucinacion, guardias de presupuesto, ramificacion del pipeline para exploracion paralela de hipotesis, y comandos CLI (`attach`/`status`/`approve`/`reject`/`guide`). **[→ Guia HITL completa](HITL_GUIDE.md)**
- **[03/30/2026]** **Carga Flexible de Habilidades** — AutoResearchClaw ahora soporta la carga de habilidades de codigo abierto y personalizadas de cualquier disciplina para mejorar aun mas tu experiencia de investigacion. Se incluyen 20 habilidades precargadas como referencias listas para usar, cubriendo redaccion cientifica, diseno experimental, quimica, biologia y mas — incluyendo una habilidad de evolucion agente [A-Evolve](https://github.com/A-EVO-Lab/a-evolve) contribuida por la comunidad. Carga las tuyas via `researchclaw skills install` o coloca un `SKILL.md` en `.claude/skills/`. Ver [Biblioteca de Habilidades](#-biblioteca-de-habilidades).
- **[03/22/2026]** [v0.3.2](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.2) — **Soporte multiplataforma + estabilidad mayor** — AutoResearchClaw ahora funciona con cualquier agente compatible con ACP (Claude Code, Codex CLI, Copilot CLI, Gemini CLI, Kimi CLI) y soporta plataformas de mensajeria (Discord, Telegram, Lark, WeChat) via el puente OpenClaw. Nuevo backend de generacion de codigo CLI-agent que delega las Stages 10 y 13 a agentes CLI externos con control de presupuesto y gestion de timeouts. Incluye sistema anti-fabricacion (VerifiedRegistry + bucle de diagnostico y reparacion), 100+ correcciones de bugs, refactorizacion modular del executor, auto-deteccion de `--resume`, endurecimiento de reintentos LLM y correcciones de la comunidad.
Versiones anteriores
- **[03/18/2026]** [v0.3.1](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.1) — **OpenCode Beast Mode + Community Contributions** — New "Beast Mode" routes complex code generation to [OpenCode](https://github.com/anomalyco/opencode) with automatic complexity scoring and graceful fallback. Added Novita AI provider support, thread-safety hardening, improved LLM output parsing robustness, and 20+ bug fixes from community PRs and internal audit.
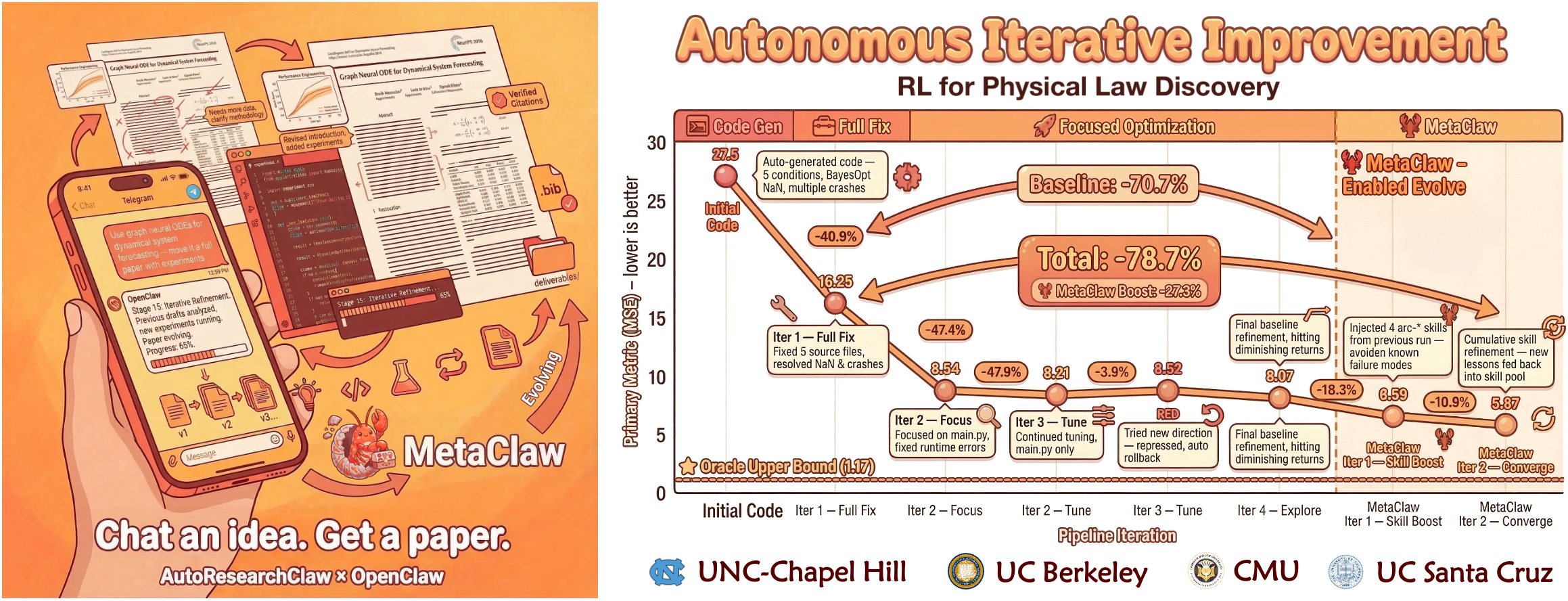
- **[03/17/2026]** [v0.3.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.0) — **MetaClaw Integration** — AutoResearchClaw now supports [MetaClaw](https://github.com/aiming-lab/MetaClaw) cross-run learning: pipeline failures → structured lessons → reusable skills, injected into all 23 stages. **+18.3%** robustness in controlled experiments. Opt-in (`metaclaw_bridge.enabled: true`), fully backward-compatible. See [Integration Guide](#-integracion-metaclaw).
- **[03/16/2026]** [v0.2.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.2.0) — Three multi-agent subsystems (CodeAgent, BenchmarkAgent, FigureAgent), hardened Docker sandbox with network-policy-aware execution, 4-round paper quality audit (AI-slop detection, 7-dim review scoring, NeurIPS checklist), and 15+ bug fixes from production runs.
- **[03/15/2026]** [v0.1.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.1.0) — We release AutoResearchClaw: a fully autonomous 23-stage research pipeline that turns a single research idea into a conference-ready paper. No human intervention required.
---
## ⚡ Un comando. Un articulo.
```bash
# Totalmente autonomo — sin intervencion humana
pip install -e . && researchclaw setup && researchclaw init && researchclaw run --topic "Your research idea here" --auto-approve
# Modo Co-Piloto — colabora con la IA en puntos de decision clave
researchclaw run --topic "Your research idea here" --mode co-pilot
```
---
## 🤔 Que es esto?
**Tu lo piensas. AutoResearchClaw lo escribe. Tu guias las decisiones clave.**
Proporciona un tema de investigacion — recibe un articulo academico completo con literatura real de OpenAlex, Semantic Scholar y arXiv, experimentos en sandbox adaptados al hardware (deteccion automatica GPU/MPS/CPU), analisis estadistico, revision multi-agentes, y LaTeX listo para conferencia orientado a NeurIPS/ICML/ICLR. Ejecutalo completamente autonomo, o usa el **modo Co-Piloto** para guiar a la IA en puntos de decision criticos — elige direcciones de investigacion, revisa disenos experimentales y co-escribe el articulo. Sin referencias alucinadas.
| 📄 | paper_draft.md | Articulo academico completo (Introduccion, Trabajo relacionado, Metodo, Experimentos, Resultados, Conclusion) |
| 📐 | paper.tex | LaTeX listo para conferencia (plantillas NeurIPS / ICLR / ICML) |
| 📚 | references.bib | Referencias BibTeX reales de OpenAlex, Semantic Scholar y arXiv — auto-depuradas para coincidir con las citas en linea |
| 🔍 | verification_report.json | Verificacion de integridad + relevancia de citas en 4 capas (arXiv, CrossRef, DataCite, LLM) |
| 🧪 | experiment runs/ | Codigo generado + resultados en sandbox + metricas JSON estructuradas |
| 📊 | charts/ | Graficos de comparacion de condiciones auto-generados con barras de error e intervalos de confianza |
| 📝 | reviews.md | Revision por pares multi-agente con verificacion de consistencia metodologia-evidencia |
| 🧬 | evolution/ | Lecciones de auto-aprendizaje extraidas de cada ejecucion |
| 📦 | deliverables/ | Todos los entregables finales en una sola carpeta — listos para compilar en Overleaf |
El pipeline se ejecuta **de principio a fin** — completamente autonomo o con colaboracion human-in-the-loop. Cuando los experimentos fallan, se auto-repara. Cuando las hipotesis no se sostienen, pivotea. Cuando las citas son falsas, las elimina. Cuando quieres dirigir, se pausa y escucha.
🌍 **Ejecutalo en cualquier lugar.** AutoResearchClaw no esta atado a una sola plataforma. Usalo de forma independiente por CLI, conectalo a [OpenClaw](https://github.com/openclaw/openclaw), o integralo con cualquier agente compatible con ACP — 🤖 Claude Code, 💻 Codex CLI, 🐙 Copilot CLI, ♊ Gemini CLI, 🌙 Kimi CLI, y mas. Gracias al puente de mensajeria de OpenClaw, puedes iniciar una investigacion completa desde 💬 Discord, ✈️ Telegram, 🐦 Lark (飞书), 💚 WeChat, o cualquier plataforma que tu equipo ya utilice. Un tema de entrada, un paper de salida — sin importar donde lo escribas.
---
## 🚀 Inicio rapido
```bash
# 1. Clonar e instalar
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Setup (interactivo — instala OpenCode beast mode, verifica Docker/LaTeX)
researchclaw setup
# 3. Configurar
researchclaw init # Interactivo: elegir proveedor LLM, crea config.arc.yaml
# O manualmente: cp config.researchclaw.example.yaml config.arc.yaml
# 4. Ejecutar
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "Your research idea" --auto-approve
```
Salida → `artifacts/rc-YYYYMMDD-HHMMSS-/deliverables/` — LaTeX listo para compilar, BibTeX, codigo experimental, graficos.
📝 Configuracion minima requerida
```yaml
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "https://api.openai.com/v1"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
```
---
## 🧠 Que lo hace diferente
| Capacidad | Como funciona |
|-----------|--------------|
| **🧑✈️ Modo Co-Piloto** | 6 modos de intervencion — desde completamente autonomo hasta paso a paso. Guia a la IA en decisiones criticas (hipotesis, baselines, redaccion del articulo) o dejala correr libre. SmartPause auto-detecta cuando la entrada humana ayudaria. |
| **🔄 Bucle PIVOT / REFINE** | La etapa 15 decide de forma autonoma: PROCEED, REFINE (ajustar parametros) o PIVOT (nueva direccion). Artefactos auto-versionados. |
| **🤖 Debate multi-agente** | La generacion de hipotesis, el analisis de resultados y la revision por pares utilizan cada uno debate estructurado multi-perspectiva. |
| **🧬 Auto-aprendizaje** | Lecciones extraidas por ejecucion (justificacion de decisiones, advertencias de ejecucion, anomalias de metricas) con decaimiento temporal de 30 dias. Las ejecuciones futuras aprenden de errores pasados. |
| **📚 Base de conocimiento** | Cada ejecucion construye una KB estructurada en 6 categorias (decisiones, experimentos, hallazgos, literatura, preguntas, revisiones). |
| **🛡️ Vigilante Sentinel** | Monitor de calidad en segundo plano: deteccion NaN/Inf, consistencia articulo-evidencia, puntuacion de relevancia de citas, guardia anti-fabricacion. |
| **🔍 Verificacion de afirmaciones** | Verificacion de hechos en linea: extrae afirmaciones del texto generado por IA y las cruza con la literatura recopilada. Marca citas infundadas y numeros fabricados. |
| **🌿 Exploracion de ramas** | Bifurca el pipeline para explorar multiples direcciones de investigacion simultaneamente, compara resultados lado a lado y fusiona el mejor camino. |
---
## 🦞 Integracion con OpenClaw
**AutoResearchClaw es un servicio compatible con [OpenClaw](https://github.com/openclaw/openclaw).** Instalalo en OpenClaw y lanza investigacion autonoma con un solo mensaje — o usalo de forma independiente via CLI, Claude Code o cualquier asistente de programacion con IA.
### 🚀 Uso con OpenClaw (Recomendado)
Si ya usas [OpenClaw](https://github.com/openclaw/openclaw) como tu asistente de IA:
```
1️⃣ Comparte la URL del repositorio de GitHub con OpenClaw
2️⃣ OpenClaw lee automaticamente RESEARCHCLAW_AGENTS.md → comprende el pipeline
3️⃣ Di: "Research [tu tema]"
4️⃣ Listo — OpenClaw clona, instala, configura, ejecuta y devuelve los resultados
```
**Eso es todo.** OpenClaw se encarga de `git clone`, `pip install`, configuracion y ejecucion del pipeline automaticamente. Tu solo chateas.
💡 Que sucede internamente
1. OpenClaw lee `RESEARCHCLAW_AGENTS.md` → aprende el rol de orquestador de investigacion
2. OpenClaw lee `README.md` → comprende la instalacion y la estructura del pipeline
3. OpenClaw copia `config.researchclaw.example.yaml` → `config.yaml`
4. Solicita tu clave API del LLM (o usa tu variable de entorno)
5. Ejecuta `pip install -e .` + `researchclaw run --topic "..." --auto-approve`
6. Devuelve el articulo, LaTeX, experimentos y citas
### 🔌 Bridge de OpenClaw (Avanzado)
Para una integracion mas profunda, AutoResearchClaw incluye un **sistema de adaptadores bridge** con 6 capacidades opcionales:
```yaml
# config.arc.yaml
openclaw_bridge:
use_cron: true # ⏰ Ejecuciones de investigacion programadas
use_message: true # 💬 Notificaciones de progreso (Discord/Slack/Telegram)
use_memory: true # 🧠 Persistencia de conocimiento entre sesiones
use_sessions_spawn: true # 🔀 Generar sub-sesiones paralelas para etapas concurrentes
use_web_fetch: true # 🌐 Busqueda web en vivo durante la revision de literatura
use_browser: false # 🖥️ Recopilacion de articulos basada en navegador
```
Cada flag activa un protocolo de adaptador tipado. Cuando OpenClaw proporciona estas capacidades, los adaptadores las consumen sin cambios en el codigo. Consulta [`integration-guide.md`](integration-guide.md) para mas detalles.
### ACP (Agent Client Protocol)
AutoResearchClaw puede usar **cualquier agente de programacion compatible con ACP** como backend LLM — sin necesidad de claves API. El agente se comunica via [acpx](https://github.com/openclaw/acpx), manteniendo una sola sesion persistente a traves de las 23 etapas del pipeline.
| Agente | Comando | Notas |
|--------|---------|-------|
| Claude Code | `claude` | Anthropic |
| Codex CLI | `codex` | OpenAI |
| Copilot CLI | `gh` | GitHub |
| Gemini CLI | `gemini` | Google |
| OpenCode | `opencode` | SST |
| Kimi CLI | `kimi` | Moonshot |
```yaml
# config.yaml — ejemplo ACP
llm:
provider: "acp"
acp:
agent: "claude" # Cualquier comando CLI de agente compatible con ACP
cwd: "." # Directorio de trabajo para el agente
# No se necesita base_url ni api_key — el agente gestiona su propia autenticacion.
```
```bash
# Solo ejecuta — el agente usa sus propias credenciales
researchclaw run --config config.yaml --topic "Your research idea" --auto-approve
```
### 🛠️ Otras formas de ejecucion
| Metodo | Como |
|--------|------|
| **CLI independiente** | `researchclaw run --topic "..." --auto-approve` (autonomo) o `--mode co-pilot` (colaborativo) |
| **API de Python** | `from researchclaw.pipeline import Runner; Runner(config).run()` |
| **Claude Code** | Lee `RESEARCHCLAW_CLAUDE.md` — solo di *"Run research on [tema]"* |
| **Copilot CLI** | `researchclaw run --topic "..."` con `llm.acp.agent: "gh"` |
| **OpenCode** | Lee `.claude/skills/` — la misma interfaz en lenguaje natural |
| **Cualquier CLI de IA** | Proporciona `RESEARCHCLAW_AGENTS.md` como contexto → el agente se auto-configura |
---
## 🔬 Pipeline: 23 etapas, 8 fases
```
Fase A: Alcance de investigacion Fase E: Ejecucion de experimentos
1. TOPIC_INIT 12. EXPERIMENT_RUN
2. PROBLEM_DECOMPOSE 13. ITERATIVE_REFINE ← auto-reparacion
Fase B: Descubrimiento de literatura Fase F: Analisis y decision
3. SEARCH_STRATEGY 14. RESULT_ANALYSIS ← multi-agente
4. LITERATURE_COLLECT ← API real 15. RESEARCH_DECISION ← PIVOT/REFINE
5. LITERATURE_SCREEN [compuerta]
6. KNOWLEDGE_EXTRACT Fase G: Redaccion del articulo
16. PAPER_OUTLINE
Fase C: Sintesis de conocimiento 17. PAPER_DRAFT
7. SYNTHESIS 18. PEER_REVIEW ← verif. evidencia
8. HYPOTHESIS_GEN ← debate 19. PAPER_REVISION
Fase D: Diseno experimental Fase H: Finalizacion
9. EXPERIMENT_DESIGN [compuerta] 20. QUALITY_GATE [compuerta]
10. CODE_GENERATION 21. KNOWLEDGE_ARCHIVE
11. RESOURCE_PLANNING 22. EXPORT_PUBLISH ← LaTeX
23. CITATION_VERIFY ← verif. relevancia
```
> Las **etapas con compuerta** (5, 9, 20) se pausan para aprobacion humana o se auto-aprueban con `--auto-approve`. Al rechazar, el pipeline retrocede.
> **Modo Co-Piloto** (`--mode co-pilot`): Colaboracion profunda humano-IA en las Etapas 7-8 (Taller de Ideas), Etapa 9 (Navegador de Baselines) y Etapas 16-17 (Co-Escritor de Articulos). Las demas etapas se auto-ejecutan con monitoreo SmartPause.
> **Bucles de decision**: La etapa 15 puede activar REFINE (→ Etapa 13) o PIVOT (→ Etapa 8), con versionado automatico de artefactos.
📋 Que hace cada fase
| Fase | Que sucede |
|------|-----------|
| **A: Alcance** | El LLM descompone el tema en un arbol de problemas estructurado con preguntas de investigacion |
| **A+: Hardware** | Deteccion automatica de GPU (NVIDIA CUDA / Apple MPS / solo CPU), advierte si el hardware local es limitado, adapta la generacion de codigo en consecuencia |
| **B: Literatura** | Busqueda multi-fuente (OpenAlex → Semantic Scholar → arXiv) de articulos reales, filtrado por relevancia, extraccion de fichas de conocimiento |
| **C: Sintesis** | Agrupa hallazgos, identifica brechas de investigacion, genera hipotesis comprobables mediante debate multi-agente |
| **D: Diseno** | Disena plan experimental, genera Python ejecutable adaptado al hardware (nivel de GPU → seleccion de paquetes), estima necesidades de recursos |
| **E: Ejecucion** | Ejecuta experimentos en sandbox, detecta NaN/Inf y errores en tiempo de ejecucion, auto-repara codigo mediante reparacion LLM dirigida |
| **F: Analisis** | Analisis multi-agente de resultados; decision autonoma PROCEED / REFINE / PIVOT con justificacion |
| **G: Redaccion** | Esquema → redaccion seccion por seccion (5,000-6,500 palabras) → revision por pares (con consistencia metodologia-evidencia) → revision con guardia de longitud |
| **H: Finalizacion** | Compuerta de calidad, archivado de conocimiento, exportacion LaTeX con plantilla de conferencia, verificacion de integridad + relevancia de citas |
---
## ✨ Caracteristicas principales
| Caracteristica | Descripcion |
|----------------|------------|
| **📚 Literatura multi-fuente** | Articulos reales de OpenAlex, Semantic Scholar y arXiv — expansion de consultas, deduplicacion, circuit breaker con degradacion gradual |
| **🔍 Verificacion de citas en 4 capas** | Verificacion de arXiv ID → DOI CrossRef/DataCite → coincidencia de titulo Semantic Scholar → puntuacion de relevancia LLM. Referencias alucinadas auto-eliminadas. |
| **🖥️ Ejecucion adaptada al hardware** | Deteccion automatica de GPU (NVIDIA CUDA / Apple MPS / solo CPU) y adaptacion de la generacion de codigo, imports y escala experimental |
| **🦾 OpenCode Beast Mode** | Los experimentos complejos se enrutan automaticamente a [OpenCode](https://github.com/anomalyco/opencode) — genera proyectos multi-archivo con arquitecturas personalizadas, bucles de entrenamiento y estudios de ablacion. Instalacion via `researchclaw setup`. |
| **🧪 Experimentos en sandbox** | Codigo validado por AST, harness inmutable, fallo rapido NaN/Inf, reparacion auto-curativa, refinamiento iterativo (hasta 10 rondas), captura de resultados parciales |
| **📝 Redaccion de calidad conferencia** | Plantillas NeurIPS/ICML/ICLR, redaccion seccion por seccion (5,000-6,500 palabras), guardia anti-fabricacion, guardia de longitud en revision, enforcement anti-disclaimer |
| **📐 Cambio de plantilla** | `neurips_2025`, `iclr_2026`, `icml_2026` — Markdown → LaTeX con formulas, tablas, figuras, referencias cruzadas, `\cite{}` |
| **🛡️ Anti-fabricacion** | VerifiedRegistry impone datos experimentales de verdad fundamental en los articulos. Auto-diagnostica experimentos fallidos y los repara antes de escribir. Numeros no verificados sanitizados. |
| **🚦 Compuertas de calidad** | 3 compuertas con intervencion humana posible (etapas 5, 9, 20) con retroceso. Omitir con `--auto-approve`. |
| **🧑✈️ Co-Piloto HITL** | 6 modos de intervencion con politicas por etapa. Taller de Ideas, Navegador de Baselines, Co-Escritor de Articulos para colaboracion profunda. SmartPause, guardias de presupuesto, politicas de escalacion y aprendizaje de intervencion para seguridad en produccion. Adaptadores CLI/WebSocket/MCP. |
| **💰 Guardias de presupuesto** | Monitoreo de costos con alertas de umbral configurables (50%/80%/100%). El pipeline se auto-pausa cuando el costo excede el presupuesto. |
| **🔐 Reproducibilidad** | Checksums SHA256 para todos los artefactos de etapa. Manifiestos inmutables para verificacion. Deshacer multi-nivel con snapshots versionados. |
---
## 🧑✈️ Co-Piloto Human-in-the-Loop
**AutoResearchClaw v0.4.0 introduce un sistema completo Human-in-the-Loop (HITL)** que transforma el pipeline de puramente autonomo a un motor de investigacion colaborativo humano-IA. Elige tu nivel de participacion:
### Modos de intervencion
| Modo | Comando | Que hace |
|------|---------|----------|
| **Full Auto** | `--auto-approve` | Comportamiento original — sin intervencion humana |
| **Gate Only** | `--mode gate-only` | Pausa en las 3 etapas con compuerta (5, 9, 20) para aprobacion |
| **Checkpoint** | `--mode checkpoint` | Pausa en cada limite de fase (8 checkpoints) |
| **Co-Pilot** | `--mode co-pilot` | Colaboracion profunda en etapas criticas, auto en el resto |
| **Step-by-Step** | `--mode step-by-step` | Pausa despues de cada etapa — aprende el pipeline |
| **Express** | `--mode express` | Revision rapida — solo las 3 compuertas mas criticas |
### Flujo de trabajo Co-Piloto
```
Tu: researchclaw run --topic "Ruido cuantico como regularizacion de redes neuronales" --mode co-pilot
El pipeline ejecuta las Etapas 1-7 automaticamente...
┌─────────────────────────────────────────────────────────────┐
│ HITL | Etapa 08: HYPOTHESIS_GEN │
│ Revision post-etapa │
│ │
│ Hipotesis mencionadas: 3 │
│ Puntuacion de novedad: 0.72 (moderada) │
│ │
│ [a] Aprobar [r] Rechazar [e] Editar [c] Colaborar │
│ [i] Inyectar guia [v] Ver salida [q] Abortar │
└─────────────────────────────────────────────────────────────┘
Tu: c (iniciar chat colaborativo)
Tu: La Hipotesis 3 es interesante pero necesita Dropout/Label Smoothing como baselines
IA: Actualizado — se agregaron Dropout, Label Smoothing, MixUp, CutMix como baselines...
Tu: aprobar
El pipeline continua con tu hipotesis refinada...
```
### Comandos CLI
```bash
# Iniciar con modo HITL
researchclaw run --topic "..." --mode co-pilot
# Conectarse a un pipeline pausado (desde otra terminal)
researchclaw attach artifacts/rc-2026-xxx
# Verificar el estado del pipeline y HITL
researchclaw status artifacts/rc-2026-xxx
# Aprobar/rechazar desde otra terminal o script
researchclaw approve artifacts/rc-2026-xxx --message "LGTM"
researchclaw reject artifacts/rc-2026-xxx --reason "Falta baseline clave"
# Inyectar guia para una etapa (incluso antes de que se ejecute)
researchclaw guide artifacts/rc-2026-xxx --stage 9 --message "Usar ResNet-50 como baseline principal"
```
### Capacidades clave
| Caracteristica | Descripcion |
|----------------|------------|
| **Taller de Ideas** | Lluvia de ideas, evaluacion y refinamiento de hipotesis de forma colaborativa (Etapa 7-8) |
| **Navegador de Baselines** | La IA sugiere baselines + el humano agrega/elimina + checklist de reproducibilidad (Etapa 9) |
| **Co-Escritor de Articulos** | Redaccion seccion por seccion con edicion humana y pulido por IA (Etapa 16-19) |
| **SmartPause** | Pausa dinamica basada en confianza — auto-detecta cuando la entrada humana ayudaria |
| **Verificacion de afirmaciones** | Verificacion de hechos en linea contra la literatura recopilada — marca afirmaciones infundadas |
| **Guardias de presupuesto** | Monitoreo de costos con alertas de umbral al 50%/80%/100% |
| **Aprendizaje de intervencion** | ALHF — aprende de tus patrones de revision para optimizar futuras decisiones de pausa |
| **Exploracion de ramas** | Bifurca el pipeline para explorar multiples hipotesis, compara y fusiona la mejor |
| **Politica de escalacion** | Notificacion escalonada (terminal → Slack → email → auto-parada) cuando esta desatendido |
| **3 Adaptadores** | CLI (terminal), WebSocket (panel web), MCP (agentes externos) |
### Configuracion
```yaml
# config.arc.yaml
hitl:
enabled: true
mode: co-pilot # full-auto | gate-only | checkpoint | co-pilot | custom
cost_budget_usd: 50.0 # Pausar cuando el costo exceda el presupuesto (0 = sin limite)
notifications:
on_pause: true
on_quality_drop: true
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # 24h de espera por defecto
auto_proceed_on_timeout: false
collaboration:
max_chat_turns: 50
save_chat_history: true
# Politicas personalizadas por etapa (opcional, para modo 'custom')
stage_policies:
8: { require_approval: true, enable_collaboration: true }
9: { require_approval: true, allow_edit_output: true }
```
### Retrocompatibilidad
- **Por defecto: DESACTIVADO.** Sin `hitl.enabled: true` o `--mode`, el pipeline se comporta exactamente como antes.
- **`--auto-approve` sigue funcionando.** Anula el modo HITL.
- **Los 2,699 tests existentes pasan** con el codigo HITL presente.
---
## 🧠 Integracion MetaClaw
**AutoResearchClaw + [MetaClaw](https://github.com/aiming-lab/MetaClaw) = Un pipeline que aprende de cada ejecucion.**
MetaClaw agrega **transferencia de conocimiento entre ejecuciones** a AutoResearchClaw. Cuando esta habilitado, el pipeline captura automaticamente lecciones de fallos y advertencias, las convierte en habilidades reutilizables, e inyecta esas habilidades en las 23 etapas del pipeline en ejecuciones posteriores — para que los mismos errores nunca se repitan.
### Como funciona
```
Ejecucion N se ejecuta → fallos/advertencias capturados como Lecciones
↓
MetaClaw Leccion → conversion a Habilidad
↓
Archivos de habilidades arc-* almacenados en ~/.metaclaw/skills/
↓
Ejecucion N+1 → build_overlay() inyecta habilidades en cada prompt LLM
↓
El LLM evita trampas conocidas → mayor calidad, menos reintentos
```
### Configuracion rapida
```bash
# 1. Instalar MetaClaw (si no esta instalado)
pip install metaclaw
# 2. Habilitar en tu configuracion
```
```yaml
# config.arc.yaml
metaclaw_bridge:
enabled: true
proxy_url: "http://localhost:30000" # Proxy MetaClaw (opcional)
skills_dir: "~/.metaclaw/skills" # Donde se almacenan las habilidades
fallback_url: "https://api.openai.com/v1" # Fallback directo al LLM
fallback_api_key: "" # Clave API para la URL de fallback
lesson_to_skill:
enabled: true
min_severity: "warning" # Convertir advertencias + errores
max_skills_per_run: 3
```
```bash
# 3. Ejecuta como siempre — MetaClaw funciona de forma transparente
researchclaw run --config config.arc.yaml --topic "Your idea" --auto-approve
```
Despues de cada ejecucion, revisa `~/.metaclaw/skills/arc-*/SKILL.md` para ver las habilidades que tu pipeline ha aprendido.
### Resultados experimentales
En experimentos controlados A/B (mismo tema, mismo LLM, misma configuracion):
| Metrica | Linea base | Con MetaClaw | Mejora |
|---------|------------|--------------|--------|
| Tasa de reintento de etapas | 10.5% | 7.9% | **-24.8%** |
| Conteo de ciclos REFINE | 2.0 | 1.2 | **-40.0%** |
| Completacion de etapas del pipeline | 18/19 | 19/19 | **+5.3%** |
| Puntuacion de robustez global (compuesta) | 0.714 | 0.845 | **+18.3%** |
> La puntuacion de robustez compuesta es un promedio ponderado de la tasa de completacion de etapas (40%), reduccion de reintentos (30%) y eficiencia de ciclos REFINE (30%).
### Retrocompatibilidad
- **Por defecto: DESACTIVADO.** Si `metaclaw_bridge` esta ausente o `enabled: false`, el pipeline se comporta exactamente como antes.
- **Sin nuevas dependencias.** MetaClaw es opcional — el pipeline base funciona sin el.
- **Los 2,699 tests existentes pasan** con el codigo de integracion presente.
---
## 🧩 Biblioteca de Habilidades
AutoResearchClaw ahora soporta la carga de **habilidades de codigo abierto y personalizadas** para mejorar aun mas tu experiencia de investigacion. Tambien incluimos **20 habilidades integradas precargadas** (redaccion cientifica, busqueda de literatura, quimica, biologia y mas) como referencias listas para usar, ofreciendo un alto grado de flexibilidad desde el primer momento. Desactiva cualquier habilidad agregando `enabled: false` a su frontmatter.
**Habilidades integradas de ejemplo:**
| Categoria | Habilidad | Descripcion |
|-----------|-----------|-------------|
| **Redaccion** | `scientific-writing` | Estructura IMRAD, formato de citas, guias de reporte |
| **Dominio** | `chemistry-rdkit` | Analisis molecular, SMILES, fingerprints, descubrimiento de farmacos |
| **Experimento** | `literature-search` | Revision sistematica, metodologia PRISMA |
> Ver las 20 habilidades con `researchclaw skills list`.
### Carga tus propias habilidades
```bash
# Opcion 1: Instalar una habilidad (persiste entre proyectos)
researchclaw skills install /path/to/my-skill/
# Opcion 2: Coloca un SKILL.md en el proyecto
mkdir -p .claude/skills/my-custom-skill
# Luego crea un SKILL.md con frontmatter YAML (name, description, trigger-keywords, applicable-stages)
# Opcion 3: Configura directorios de habilidades compartidos en config.arc.yaml
# skills:
# custom_dirs:
# - /path/to/team-shared-skills
```
### Uso de habilidades
Las habilidades se cargan e inyectan en los prompts del LLM automaticamente — no se necesita activacion manual. Usa el CLI para inspeccionar:
```bash
researchclaw skills list # Muestra todas las habilidades cargadas con sus fuentes
researchclaw skills validate ./my-skill # Verifica el formato de SKILL.md
```
Explora habilidades de la comunidad: [K-Dense-AI/claude-scientific-skills](https://github.com/K-Dense-AI/claude-scientific-skills) (150+ habilidades cientificas en multiples disciplinas).
---
## ⚙️ Referencia de configuracion
Haz clic para expandir la referencia completa de configuracion
```yaml
# === Proyecto ===
project:
name: "my-research" # Identificador del proyecto
mode: "docs-first" # docs-first | semi-auto | full-auto
# === Investigacion ===
research:
topic: "..." # Tema de investigacion (requerido)
domains: ["ml", "nlp"] # Dominios de investigacion para busqueda de literatura
daily_paper_count: 8 # Articulos objetivo por consulta de busqueda
quality_threshold: 4.0 # Puntuacion minima de calidad para articulos
# === Tiempo de ejecucion ===
runtime:
timezone: "America/New_York" # Para marcas de tiempo
max_parallel_tasks: 3 # Limite de experimentos concurrentes
approval_timeout_hours: 12 # Timeout de etapas con compuerta
retry_limit: 2 # Numero de reintentos por fallo de etapa
# === LLM ===
llm:
provider: "openai-compatible" # openai | openrouter | deepseek | minimax | acp | openai-compatible
base_url: "https://..." # Endpoint de API (requerido para openai-compatible)
api_key_env: "OPENAI_API_KEY" # Variable de entorno para la clave API (requerido para openai-compatible)
api_key: "" # O codifica la clave aqui directamente
primary_model: "gpt-4o" # Modelo principal
fallback_models: ["gpt-4o-mini"] # Cadena de fallback
s2_api_key: "" # Clave API de Semantic Scholar (opcional, mayores limites de tasa)
acp: # Solo se usa cuando provider: "acp"
agent: "claude" # Comando CLI del agente ACP (claude, codex, gemini, etc.)
cwd: "." # Directorio de trabajo para el agente
# === Experimento ===
experiment:
mode: "sandbox" # simulated | sandbox | docker | ssh_remote
time_budget_sec: 300 # Tiempo maximo de ejecucion por corrida (por defecto: 300s)
max_iterations: 10 # Maximo de iteraciones de optimizacion
metric_key: "val_loss" # Nombre de la metrica principal
metric_direction: "minimize" # minimize | maximize
sandbox:
python_path: ".venv/bin/python"
gpu_required: false
allowed_imports: [math, random, json, csv, numpy, torch, sklearn]
max_memory_mb: 4096
docker:
image: "researchclaw/experiment:latest"
network_policy: "setup_only" # none | setup_only | pip_only | full
gpu_enabled: true
memory_limit_mb: 8192
auto_install_deps: true # Deteccion automatica de imports → requirements.txt
ssh_remote:
host: "" # Nombre de host del servidor GPU
gpu_ids: [] # IDs de GPU disponibles
remote_workdir: "/tmp/researchclaw_experiments"
opencode: # OpenCode Beast Mode (auto-instalado via `researchclaw setup`)
enabled: true # Interruptor principal (por defecto: true)
auto: true # Auto-activacion sin confirmacion (por defecto: true)
complexity_threshold: 0.2 # 0.0-1.0 — mas alto = solo se activa para experimentos complejos
model: "" # Modelo a forzar (vacio = usa llm.primary_model)
timeout_sec: 600 # Segundos maximos para generacion OpenCode
max_retries: 1 # Numero de reintentos por fallo
workspace_cleanup: true # Eliminar workspace temporal despues de recoleccion
code_agent: # CodeAgent v2 — generacion de codigo multi-fase
enabled: true # Usar CodeAgent en vez del codegen legacy de un solo prompt
architecture_planning: true # Generar blueprint de implementacion profunda antes de codificar
sequential_generation: true # Generar archivos uno a uno siguiendo el DAG de dependencias
hard_validation: true # Validacion AST (bloquea ablaciones identicas, metricas hardcodeadas)
hard_validation_max_repairs: 2 # Max intentos de reparacion cuando la validacion falla
exec_fix_max_iterations: 3 # Intentos de correccion de ejecucion en bucle
exec_fix_timeout_sec: 60 # Timeout por intento de exec-fix
benchmark_agent: # BenchmarkAgent — seleccion automatizada de datasets y baselines
enabled: true # Habilitar pipeline de 4 agentes (Surveyor→Selector→Acquirer→Validator)
enable_hf_search: true # Buscar en HuggingFace Datasets
enable_web_search: true # Buscar en Google Scholar para benchmarks
tier_limit: 2 # Filtrado de nivel de dataset (1=pequeno/cache, 2=medio, 3=grande)
min_benchmarks: 1 # Minimo de datasets requeridos
min_baselines: 2 # Minimo de metodos baseline requeridos
figure_agent: # FigureAgent — generacion de figuras academicas
enabled: true # Habilitar pipeline de 5 agentes (Planner→CodeGen→Renderer→Critic→Integrator)
min_figures: 3 # Minimo de figuras a generar
max_figures: 8 # Maximo de figuras
max_iterations: 3 # Iteraciones de refinamiento dirigidas por el Critic
dpi: 300 # Resolucion de salida
strict_mode: false # Fallar pipeline si la generacion de figuras falla
repair: # Reparacion de experimentos anti-fabricacion
enabled: true # Auto-diagnosticar y reparar experimentos fallidos
max_cycles: 3 # Bucles de reintento de reparacion
min_completion_rate: 0.5 # >=50% de condiciones deben completarse para continuar
min_conditions: 2 # Al menos 2 condiciones para un experimento valido
use_opencode: true # Enrutar reparaciones a traves de OpenCode Beast Mode
# === Busqueda web (Opcional) ===
web_search:
enabled: true # Habilitar busqueda de literatura aumentada por web
tavily_api_key_env: "TAVILY_API_KEY" # Variable de entorno para clave API de Tavily (opcional)
enable_scholar: true # Busqueda en Google Scholar
enable_pdf_extraction: true # Extraer texto de PDFs
max_web_results: 10 # Maximo de resultados web por consulta
# === Exportacion ===
export:
target_conference: "neurips_2025" # neurips_2025 | iclr_2026 | icml_2026
authors: "Anonymous"
bib_file: "references"
# === Prompts ===
prompts:
custom_file: "" # Ruta a YAML de prompts personalizados (vacio = valores por defecto)
# === Co-Piloto HITL (NUEVO en v0.4.0) ===
hitl:
enabled: false # Establecer en true para habilitar HITL
mode: co-pilot # full-auto | gate-only | checkpoint | step-by-step | co-pilot | custom
cost_budget_usd: 0.0 # Limite de costo en USD (0 = sin limite)
notifications:
on_pause: true # Notificar cuando el pipeline se pausa
on_quality_drop: true # Notificar por problemas de calidad
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # Esperar hasta 24h por entrada humana
auto_proceed_on_timeout: false # Si es true, auto-aprobar al expirar timeout
collaboration:
max_chat_turns: 50 # Max turnos por sesion de colaboracion
save_chat_history: true # Persistir registros de chat
stage_policies: {} # Overrides por etapa (para modo 'custom')
# === Seguridad ===
security:
hitl_required_stages: [5, 9, 20] # Etapas que requieren aprobacion humana
allow_publish_without_approval: false
redact_sensitive_logs: true
# === Base de conocimiento ===
knowledge_base:
backend: "markdown" # markdown | obsidian
root: "docs/kb"
# === Notificaciones ===
notifications:
channel: "console" # console | discord | slack
target: ""
# === Puente MetaClaw (Opcional) ===
metaclaw_bridge:
enabled: false # Establecer en true para habilitar aprendizaje entre ejecuciones
proxy_url: "http://localhost:30000" # URL del proxy MetaClaw
skills_dir: "~/.metaclaw/skills" # Donde se almacenan las habilidades arc-*
fallback_url: "" # Fallback directo al LLM cuando el proxy esta caido
fallback_api_key: "" # Clave API para el endpoint de fallback
lesson_to_skill:
enabled: true # Convertir lecciones en habilidades automaticamente
min_severity: "warning" # Severidad minima para conversion
max_skills_per_run: 3 # Max de nuevas habilidades por ejecucion del pipeline
prm: # Process Reward Model compuerta de calidad (opcional)
enabled: false # Usar LLM-como-juez para puntuar salidas de etapas
model: "gpt-5.4" # Modelo juez PRM
votes: 3 # Conteo de voto mayoritario
gate_stages: [5, 9, 15, 20] # Etapas donde aplicar compuertas PRM
# === Bridge de OpenClaw ===
openclaw_bridge:
use_cron: false # Ejecuciones de investigacion programadas
use_message: false # Notificaciones de progreso
use_memory: false # Persistencia de conocimiento entre sesiones
use_sessions_spawn: false # Generar sub-sesiones paralelas
use_web_fetch: false # Busqueda web en vivo
use_browser: false # Recopilacion de articulos basada en navegador
```
---
## 🙏 Agradecimientos
Inspirado por:
- 🔬 [AI Scientist](https://github.com/SakanaAI/AI-Scientist) (Sakana AI) — Pionero en investigacion automatizada
- 🧠 [AutoResearch](https://github.com/karpathy/autoresearch) (Andrej Karpathy) — Automatizacion de investigacion de principio a fin
- 🌐 [FARS](https://analemma.ai/blog/introducing-fars/) (Analemma) — Sistema de investigacion completamente automatizado
---
## 📄 Licencia
MIT — consulta [LICENSE](../LICENSE) para mas detalles.
---
## 📌 Citacion
Si encuentras AutoResearchClaw util, por favor cita:
```bibtex
@misc{liu2026autoresearchclawselfreinforcingautonomousresearch,
title={AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration},
author={Jiaqi Liu and Shi Qiu and Mairui Li and Bingzhou Li and Haonian Ji and Siwei Han and Xinyu Ye and Peng Xia and Zihan Dong and Congyu Zhang and Letian Zhang and Guiming Chen and Haoqin Tu and Xinyu Yang and Lu Feng and Xujiang Zhao and Haifeng Chen and Jiawei Zhou and Xiao Wang and Weitong Zhang and Hongtu Zhu and Yun Li and Jieru Mei and Hongliang Fei and Jiaheng Zhang and Linjie Li and Linjun Zhang and Yuyin Zhou and Sheng Wang and Caiming Xiong and James Zou and Zeyu Zheng and Cihang Xie and Mingyu Ding and Huaxiu Yao},
year={2026},
eprint={2605.20025},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.20025},
}
```
Construido con 🦞 por el equipo de AutoResearchClaw