
Discutez une idee. Obtenez un article. Autonome, Collaboratif & Auto-evolutif.
Discutez avec OpenClaw : "Recherche X" → termine.
📄 Notre article est sur arXiv — venez le lire ! AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration








🇺🇸 English ·
🇨🇳 中文 ·
🇯🇵 日本語 ·
🇰🇷 한국어 ·
🇫🇷 Français ·
🇩🇪 Deutsch ·
🇪🇸 Español ·
🇧🇷 Português ·
🇷🇺 Русский ·
🇸🇦 العربية
🏆 Vitrine des articles · 🧑✈️ Guide Co-Pilote · 📖 Guide d'integration · 💬 Communaute Discord
---

|
🏆 Vitrine des articles generes
8 articles couvrant 8 domaines — mathematiques, statistiques, biologie, informatique, NLP, RL, vision, robustesse — generes de maniere entierement autonome ou avec guidage co-pilote Human-in-the-Loop.

|
---
> **🧪 Nous recherchons des testeurs !** Essayez le pipeline avec votre propre idee de recherche — dans n'importe quel domaine — et [dites-nous ce que vous en pensez](TESTER_GUIDE.md). Vos retours faconnent directement la prochaine version. **[→ Testing Guide](TESTER_GUIDE.md)** | **[→ 中文测试指南](TESTER_GUIDE_CN.md)** | **[→ 日本語テストガイド](TESTER_GUIDE_JA.md)**
---
## 🔥 News
- **[05/19/2026]** **v0.5.0** — **Agents d'experience multi-domaines + ARC-Bench** — Deux mises a jour majeures. **(1) Agents d'execution specialises par domaine :** l'etape d'experience (etapes 10 a 13) ne se limite plus au bac a sable ML par defaut et s'oriente vers des agents specialises selon le domaine — **physique des hautes energies** (ColliderAgent : FeynRules → MadGraph5 → Delphes via le cloud Magnus), **biologie** (modelisation metabolique a l'echelle du genome avec COBRApy) et **statistiques** (agent d'etudes de simulation), avec un executeur Docker generique pour la chimie/les materiaux. Le pipeline selectionne automatiquement le bon executeur selon le domaine. **(2) ARC-Bench :** un benchmark de recherche autonome ouvert de **55 sujets** couvrant **ML (25), physique des hautes energies (10), quantique (10), biologie (7) et statistiques (3)**, chacun fourni avec un manifeste et une grille de notation (`experiments/arc_bench/`, et aussi sur [🤗 Hugging Face](https://huggingface.co/datasets/AIMING-Lab-UNC/ARC-Bench)). **[→ Guide d'integration des domaines](DOMAIN_INTEGRATION_GUIDE.md)**
- **[04/01/2026]** **v0.4.0** — **Systeme Co-Pilote Human-in-the-Loop** — AutoResearchClaw n'est plus purement autonome. Le nouveau systeme HITL ajoute 6 modes d'intervention (`full-auto`, `gate-only`, `checkpoint`, `step-by-step`, `co-pilot`, `custom`), des politiques par etape, et une collaboration profonde humain-IA. Inclut : Atelier d'Idees pour la co-creation d'hypotheses, Navigateur de References pour la revue de conception experimentale, Co-Redacteur d'Article pour la redaction collaborative, SmartPause (intervention dynamique guidee par la confiance), apprentissage d'intervention ALHF, verification anti-hallucination des affirmations, garde-fous de budget, ramification du pipeline pour l'exploration parallele d'hypotheses, et commandes CLI (`attach`/`status`/`approve`/`reject`/`guide`). **[→ Guide HITL complet](HITL_GUIDE.md)**
- **[03/30/2026]** **Chargement flexible de competences** — AutoResearchClaw supporte desormais le chargement de competences open-source et personnalisees depuis n'importe quelle discipline pour enrichir votre experience de recherche. 20 competences pre-chargees sont incluses comme references pretes a l'emploi, couvrant la redaction scientifique, la conception experimentale, la chimie, la biologie, et plus encore — incluant une competence d'evolution agentique [A-Evolve](https://github.com/A-EVO-Lab/a-evolve) contribuee par la communaute. Chargez les votres via `researchclaw skills install` ou deposez un `SKILL.md` dans `.claude/skills/`. Voir [Bibliotheque de competences](#-bibliotheque-de-competences).
- **[03/22/2026]** [v0.3.2](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.2) — **Support multiplateforme + stabilite majeure** — AutoResearchClaw fonctionne desormais avec tout agent compatible ACP (Claude Code, Codex CLI, Copilot CLI, Gemini CLI, Kimi CLI) et supporte les plateformes de messagerie (Discord, Telegram, Lark, WeChat) via le pont OpenClaw. Nouveau backend de generation de code CLI-agent qui delegue les Stages 10 et 13 a des agents CLI externes avec controle de budget et gestion des timeouts. Inclut le systeme anti-fabrication (VerifiedRegistry + boucle diagnostic/reparation), 100+ corrections de bugs, refactoring modulaire de l'executor, auto-detection `--resume`, renforcement des retries LLM, et corrections communautaires.
Versions antérieures
- **[03/18/2026]** [v0.3.1](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.1) — **OpenCode Beast Mode + Community Contributions** — New "Beast Mode" routes complex code generation to [OpenCode](https://github.com/anomalyco/opencode) with automatic complexity scoring and graceful fallback. Added Novita AI provider support, thread-safety hardening, improved LLM output parsing robustness, and 20+ bug fixes from community PRs and internal audit.
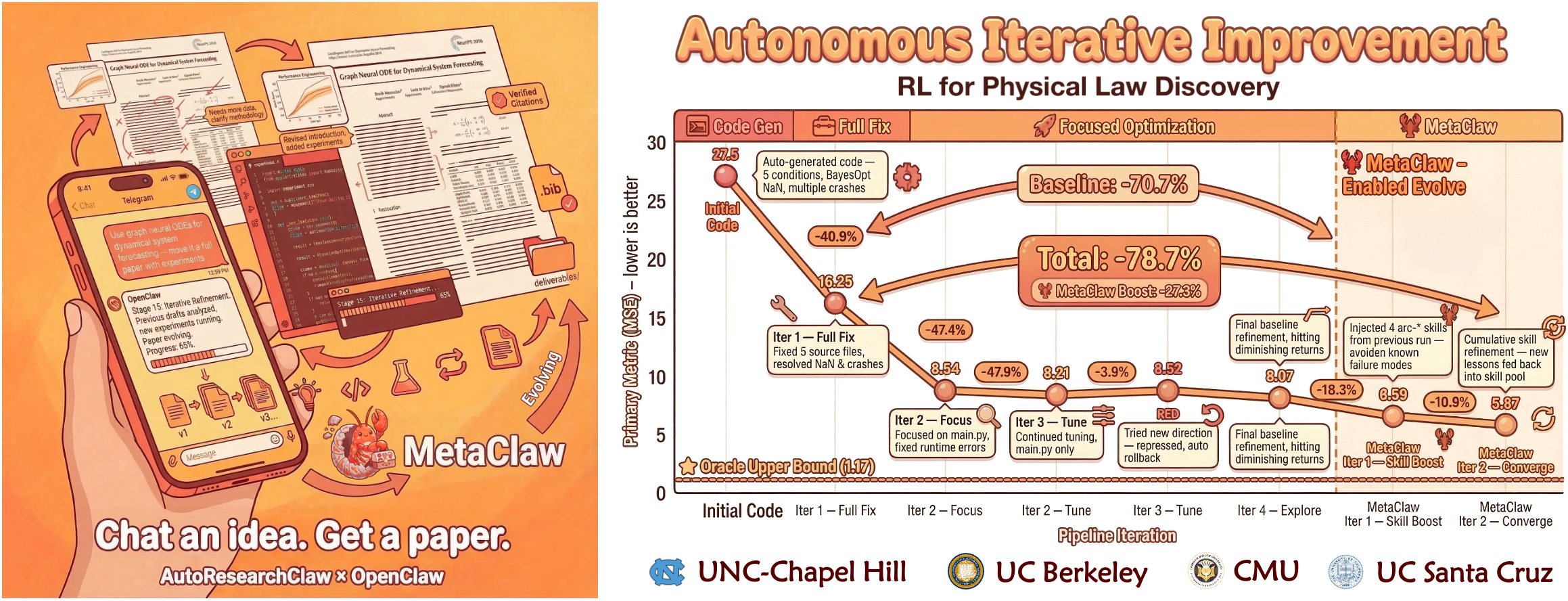
- **[03/17/2026]** [v0.3.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.0) — **MetaClaw Integration** — AutoResearchClaw now supports [MetaClaw](https://github.com/aiming-lab/MetaClaw) cross-run learning: pipeline failures → structured lessons → reusable skills, injected into all 23 stages. **+18.3%** robustness in controlled experiments. Opt-in (`metaclaw_bridge.enabled: true`), fully backward-compatible. See [Integration Guide](#-integration-metaclaw).
- **[03/16/2026]** [v0.2.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.2.0) — Three multi-agent subsystems (CodeAgent, BenchmarkAgent, FigureAgent), hardened Docker sandbox with network-policy-aware execution, 4-round paper quality audit (AI-slop detection, 7-dim review scoring, NeurIPS checklist), and 15+ bug fixes from production runs.
- **[03/15/2026]** [v0.1.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.1.0) — We release AutoResearchClaw: a fully autonomous 23-stage research pipeline that turns a single research idea into a conference-ready paper. No human intervention required.
---
## ⚡ Une commande. Un article.
```bash
# Entierement autonome — aucune intervention humaine
pip install -e . && researchclaw setup && researchclaw init && researchclaw run --topic "Your research idea here" --auto-approve
# Mode Co-Pilote — collaborez avec l'IA aux points de decision cles
researchclaw run --topic "Your research idea here" --mode co-pilot
```
---
## 🤔 De quoi s'agit-il ?
**Vous y pensez. AutoResearchClaw l'ecrit. Vous guidez les decisions cles.**
Donnez un sujet de recherche — recevez un article academique complet avec de la vraie litterature provenant d'OpenAlex, Semantic Scholar et arXiv, des experiences en sandbox adaptees au materiel (detection automatique GPU/MPS/CPU), une analyse statistique, une relecture multi-agents, et du LaTeX pret pour les conferences ciblant NeurIPS/ICML/ICLR. Executez-le en mode entierement autonome, ou utilisez le **mode Co-Pilote** pour guider l'IA aux points de decision critiques — choisissez les directions de recherche, revisez les conceptions experimentales, et co-redigez l'article. Aucune reference hallucinee.
| 📄 | paper_draft.md | Article academique complet (Introduction, Travaux connexes, Methode, Experiences, Resultats, Conclusion) |
| 📐 | paper.tex | LaTeX pret pour les conferences (templates NeurIPS / ICLR / ICML) |
| 📚 | references.bib | References BibTeX reelles provenant d'OpenAlex, Semantic Scholar et arXiv — auto-elaguees pour correspondre aux citations dans le texte |
| 🔍 | verification_report.json | Verification d'integrite et de pertinence des citations sur 4 couches (arXiv, CrossRef, DataCite, LLM) |
| 🧪 | experiment runs/ | Code genere + resultats sandbox + metriques JSON structurees |
| 📊 | charts/ | Graphiques de comparaison de conditions auto-generes avec barres d'erreur et intervalles de confiance |
| 📝 | reviews.md | Relecture multi-agents avec verification de coherence methodologie-preuves |
| 🧬 | evolution/ | Lecons d'auto-apprentissage extraites de chaque execution |
| 📦 | deliverables/ | Tous les livrables finaux dans un seul dossier — pret a compiler pour Overleaf |
Le pipeline s'execute **de bout en bout** — entierement autonome ou avec collaboration human-in-the-loop. Quand les experiences echouent, il s'auto-repare. Quand les hypotheses ne tiennent pas, il pivote. Quand les citations sont fausses, il les supprime. Quand vous voulez intervenir, il se met en pause et ecoute.
🌍 **Utilisable partout.** AutoResearchClaw n'est pas verrouille sur une seule plateforme. Utilisez-le en CLI autonome, connectez-le a [OpenClaw](https://github.com/openclaw/openclaw), ou integrez-le avec n'importe quel agent compatible ACP — 🤖 Claude Code, 💻 Codex CLI, 🐙 Copilot CLI, ♊ Gemini CLI, 🌙 Kimi CLI, et bien d'autres. Grace au pont de messagerie d'OpenClaw, vous pouvez lancer une recherche complete depuis 💬 Discord, ✈️ Telegram, 🐦 Lark (飞书), 💚 WeChat, ou la plateforme que votre equipe utilise deja. Un sujet en entree, un article en sortie — peu importe d'ou vous l'envoyez.
---
## 🚀 Demarrage rapide
```bash
# 1. Cloner & installer
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Setup (interactif — installe OpenCode beast mode, verifie Docker/LaTeX)
researchclaw setup
# 3. Configurer
researchclaw init # Interactif : choisir le fournisseur LLM, cree config.arc.yaml
# Ou manuellement : cp config.researchclaw.example.yaml config.arc.yaml
# 4. Executer
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "Your research idea" --auto-approve
```
Sortie → `artifacts/rc-YYYYMMDD-HHMMSS-/deliverables/` — LaTeX pret a compiler, BibTeX, code d'experience, graphiques.
📝 Configuration minimale requise
```yaml
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "https://api.openai.com/v1"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
```
---
## 🧠 Ce qui le distingue
| Capacite | Fonctionnement |
|----------|---------------|
| **🧑✈️ Mode Co-Pilote** | 6 modes d'intervention — du mode entierement autonome au pas-a-pas. Guidez l'IA aux decisions critiques (hypotheses, references, redaction) ou laissez-la faire. SmartPause detecte automatiquement quand une intervention humaine serait utile. |
| **🔄 Boucle PIVOT / REFINE** | L'etape 15 decide de maniere autonome : PROCEED, REFINE (ajuster les parametres) ou PIVOT (nouvelle direction). Artefacts auto-versionnes. |
| **🤖 Debat multi-agents** | La generation d'hypotheses, l'analyse de resultats et la relecture par les pairs utilisent chacune un debat structure multi-perspectives. |
| **🧬 Auto-apprentissage** | Lecons extraites a chaque execution (justification des decisions, avertissements d'execution, anomalies de metriques) avec decroissance temporelle a 30 jours. Les executions futures apprennent des erreurs passees. |
| **📚 Base de connaissances** | Chaque execution construit une KB structuree couvrant 6 categories (decisions, experiences, resultats, litterature, questions, relectures). |
| **🛡️ Sentinel Watchdog** | Moniteur de qualite en arriere-plan : detection NaN/Inf, coherence article-preuves, score de pertinence des citations, protection anti-fabrication. |
| **🔍 Verification des affirmations** | Verification factuelle en ligne : extrait les affirmations du texte genere par l'IA et les recoupe avec la litterature collectee. Signale les citations non fondees et les chiffres fabriques. |
| **🌿 Exploration par ramification** | Dupliquez le pipeline pour explorer plusieurs directions de recherche simultanement, comparez les resultats cote a cote, et fusionnez le meilleur chemin. |
---
## 🦞 Integration OpenClaw
**AutoResearchClaw est un service compatible [OpenClaw](https://github.com/openclaw/openclaw).** Installez-le dans OpenClaw et lancez une recherche autonome avec un seul message — ou utilisez-le de maniere autonome via CLI, Claude Code, ou tout assistant de codage IA.
### 🚀 Utilisation avec OpenClaw (recommande)
Si vous utilisez deja [OpenClaw](https://github.com/openclaw/openclaw) comme assistant IA :
```
1️⃣ Partagez l'URL du depot GitHub avec OpenClaw
2️⃣ OpenClaw lit automatiquement RESEARCHCLAW_AGENTS.md → comprend le pipeline
3️⃣ Dites : "Research [votre sujet]"
4️⃣ C'est fait — OpenClaw clone, installe, configure, execute et renvoie les resultats
```
**C'est tout.** OpenClaw gere `git clone`, `pip install`, la configuration et l'execution du pipeline automatiquement. Vous n'avez qu'a discuter.
💡 Ce qui se passe en coulisses
1. OpenClaw lit `RESEARCHCLAW_AGENTS.md` → apprend le role d'orchestrateur de recherche
2. OpenClaw lit `README.md` → comprend l'installation et la structure du pipeline
3. OpenClaw copie `config.researchclaw.example.yaml` → `config.yaml`
4. Demande votre cle API LLM (ou utilise votre variable d'environnement)
5. Execute `pip install -e .` + `researchclaw run --topic "..." --auto-approve`
6. Renvoie l'article, le LaTeX, les experiences et les citations
### 🔌 Pont OpenClaw (avance)
Pour une integration plus poussee, AutoResearchClaw inclut un **systeme d'adaptateurs pont** avec 6 fonctionnalites optionnelles :
```yaml
# config.arc.yaml
openclaw_bridge:
use_cron: true # ⏰ Executions de recherche planifiees
use_message: true # 💬 Notifications de progression (Discord/Slack/Telegram)
use_memory: true # 🧠 Persistance des connaissances inter-sessions
use_sessions_spawn: true # 🔀 Lancement de sous-sessions paralleles pour les etapes concurrentes
use_web_fetch: true # 🌐 Recherche web en direct pendant la revue de litterature
use_browser: false # 🖥️ Collecte d'articles via navigateur
```
Chaque option active un protocole d'adaptateur type. Quand OpenClaw fournit ces fonctionnalites, les adaptateurs les consomment sans modification de code. Voir [`integration-guide.md`](integration-guide.md) pour tous les details.
### ACP (Agent Client Protocol)
AutoResearchClaw peut utiliser **n'importe quel agent de codage compatible ACP** comme backend LLM — sans cle API requise. L'agent communique via [acpx](https://github.com/openclaw/acpx), en maintenant une session persistante unique a travers les 23 etapes du pipeline.
| Agent | Commande | Notes |
|-------|----------|-------|
| Claude Code | `claude` | Anthropic |
| Codex CLI | `codex` | OpenAI |
| Copilot CLI | `gh` | GitHub |
| Gemini CLI | `gemini` | Google |
| OpenCode | `opencode` | SST |
| Kimi CLI | `kimi` | Moonshot |
```yaml
# config.yaml — exemple ACP
llm:
provider: "acp"
acp:
agent: "claude" # N'importe quel agent CLI compatible ACP
cwd: "." # Repertoire de travail pour l'agent
# Pas besoin de base_url ou api_key — l'agent gere sa propre authentification.
```
```bash
# Executez simplement — l'agent utilise ses propres identifiants
researchclaw run --config config.yaml --topic "Your research idea" --auto-approve
```
### 🛠️ Autres methodes d'execution
| Methode | Comment |
|---------|---------|
| **CLI autonome** | `researchclaw run --topic "..." --auto-approve` (autonome) ou `--mode co-pilot` (collaboratif) |
| **API Python** | `from researchclaw.pipeline import Runner; Runner(config).run()` |
| **Claude Code** | Lit `RESEARCHCLAW_CLAUDE.md` — dites simplement *"Run research on [sujet]"* |
| **Copilot CLI** | `researchclaw run --topic "..."` avec `llm.acp.agent: "gh"` |
| **OpenCode** | Lit `.claude/skills/` — meme interface en langage naturel |
| **Tout CLI IA** | Fournissez `RESEARCHCLAW_AGENTS.md` comme contexte → l'agent s'auto-initialise |
---
## 🔬 Pipeline : 23 etapes, 8 phases
```
Phase A : Cadrage de la recherche Phase E : Execution des experiences
1. TOPIC_INIT 12. EXPERIMENT_RUN
2. PROBLEM_DECOMPOSE 13. ITERATIVE_REFINE ← auto-reparation
Phase B : Decouverte de litterature Phase F : Analyse et decision
3. SEARCH_STRATEGY 14. RESULT_ANALYSIS ← multi-agents
4. LITERATURE_COLLECT ← API reelle 15. RESEARCH_DECISION ← PIVOT/REFINE
5. LITERATURE_SCREEN [porte]
6. KNOWLEDGE_EXTRACT Phase G : Redaction de l'article
16. PAPER_OUTLINE
Phase C : Synthese des connaissances 17. PAPER_DRAFT
7. SYNTHESIS 18. PEER_REVIEW ← verif. preuves
8. HYPOTHESIS_GEN ← debat 19. PAPER_REVISION
Phase D : Conception experimentale Phase H : Finalisation
9. EXPERIMENT_DESIGN [porte] 20. QUALITY_GATE [porte]
10. CODE_GENERATION 21. KNOWLEDGE_ARCHIVE
11. RESOURCE_PLANNING 22. EXPORT_PUBLISH ← LaTeX
23. CITATION_VERIFY ← verif. pertinence
```
> **Etapes de validation** (5, 9, 20) : pause pour approbation humaine ou approbation automatique avec `--auto-approve`. En cas de rejet, le pipeline revient en arriere.
> **Mode Co-Pilote** (`--mode co-pilot`) : Collaboration profonde humain-IA aux etapes 7-8 (Atelier d'Idees), etape 9 (Navigateur de References), et etapes 16-17 (Co-Redacteur d'Article). Les autres etapes s'executent automatiquement avec surveillance SmartPause.
> **Boucles de decision** : l'etape 15 peut declencher REFINE (→ etape 13) ou PIVOT (→ etape 8), avec versionnement automatique des artefacts.
📋 Ce que fait chaque phase
| Phase | Ce qui se passe |
|-------|-----------------|
| **A : Cadrage** | Le LLM decompose le sujet en un arbre de problemes structure avec des questions de recherche |
| **A+ : Materiel** | Detection automatique du GPU (NVIDIA CUDA / Apple MPS / CPU uniquement), avertissement si le materiel local est limite, adaptation de la generation de code en consequence |
| **B : Litterature** | Recherche multi-sources (OpenAlex → Semantic Scholar → arXiv) de vrais articles, filtrage par pertinence, extraction de fiches de connaissances |
| **C : Synthese** | Regroupement des resultats, identification des lacunes de recherche, generation d'hypotheses testables via debat multi-agents |
| **D : Conception** | Conception du plan experimental, generation de Python executable adapte au materiel (niveau GPU → selection de packages), estimation des besoins en ressources |
| **E : Execution** | Execution des experiences en sandbox, detection de NaN/Inf et bugs d'execution, auto-reparation du code via reparation ciblee par LLM |
| **F : Analyse** | Analyse multi-agents des resultats ; decision autonome PROCEED / REFINE / PIVOT avec justification |
| **G : Redaction** | Plan → redaction section par section (5 000-6 500 mots) → relecture (avec verification de coherence methodologie-preuves) → revision avec controle de longueur |
| **H : Finalisation** | Porte qualite, archivage des connaissances, export LaTeX avec template de conference, verification d'integrite et de pertinence des citations |
---
## ✨ Fonctionnalites cles
| Fonctionnalite | Description |
|----------------|------------|
| **📚 Litterature multi-sources** | Vrais articles depuis OpenAlex, Semantic Scholar et arXiv — expansion de requetes, deduplication, disjoncteur avec degradation gracieuse |
| **🔍 Verification des citations en 4 couches** | Verification arXiv ID → DOI CrossRef/DataCite → correspondance de titre Semantic Scholar → score de pertinence LLM. References hallucinées auto-supprimees. |
| **🖥️ Execution adaptee au materiel** | Detection automatique du GPU (NVIDIA CUDA / Apple MPS / CPU uniquement) et adaptation de la generation de code, des imports et de l'echelle experimentale |
| **🦾 OpenCode Beast Mode** | Les experiences complexes sont automatiquement dirigees vers [OpenCode](https://github.com/anomalyco/opencode) — genere des projets multi-fichiers avec architectures personnalisees, boucles d'entrainement et etudes d'ablation. Installation via `researchclaw setup`. |
| **🧪 Experiences en sandbox** | Code valide par AST, harnais immuable, echec rapide NaN/Inf, reparation auto-guerison, raffinement iteratif (jusqu'a 10 tours), capture de resultats partiels |
| **📝 Redaction de qualite conference** | Templates NeurIPS/ICML/ICLR, redaction section par section (5 000-6 500 mots), protection anti-fabrication, controle de longueur en revision, application anti-clause de non-responsabilite |
| **📐 Changement de template** | `neurips_2025`, `iclr_2026`, `icml_2026` — Markdown → LaTeX avec formules, tableaux, figures, references croisees, `\cite{}` |
| **🛡️ Anti-fabrication** | VerifiedRegistry impose les donnees experimentales de verite terrain dans les articles. Diagnostic automatique des experiences echouees et reparation avant la redaction. Chiffres non verifies assainis. |
| **🚦 Portes qualite** | 3 portes human-in-the-loop (etapes 5, 9, 20) avec retour en arriere. A passer avec `--auto-approve`. |
| **🧑✈️ Co-Pilote HITL** | 6 modes d'intervention avec politiques par etape. Atelier d'Idees, Navigateur de References, Co-Redacteur d'Article pour une collaboration approfondie. SmartPause, garde-fous de budget, politiques d'escalade et apprentissage d'intervention pour la securite en production. Adaptateurs CLI/WebSocket/MCP. |
| **💰 Garde-fous de budget** | Surveillance des couts avec alertes a seuils configurables (50%/80%/100%). Le pipeline se met automatiquement en pause lorsque le cout depasse le budget. |
| **🔐 Reproductibilite** | Checksums SHA256 pour tous les artefacts d'etape. Manifestes immuables pour la verification. Annulation multi-niveaux avec snapshots versionnes. |
---
## 🧑✈️ Co-Pilote Human-in-the-Loop
**AutoResearchClaw v0.4.0 introduit un systeme complet Human-in-the-Loop (HITL)** qui transforme le pipeline d'un mode purement autonome en un moteur de recherche collaboratif humain-IA. Choisissez votre niveau d'implication :
### Modes d'intervention
| Mode | Commande | Description |
|------|----------|------------|
| **Full Auto** | `--auto-approve` | Comportement original — aucune intervention humaine |
| **Gate Only** | `--mode gate-only` | Pause aux 3 etapes de validation (5, 9, 20) pour approbation |
| **Checkpoint** | `--mode checkpoint` | Pause a chaque frontiere de phase (8 checkpoints) |
| **Co-Pilot** | `--mode co-pilot` | Collaboration approfondie aux etapes critiques, auto ailleurs |
| **Step-by-Step** | `--mode step-by-step` | Pause apres chaque etape — pour decouvrir le pipeline |
| **Express** | `--mode express` | Revue rapide — seulement les 3 portes les plus critiques |
### Flux de travail Co-Pilote
```
You: researchclaw run --topic "Quantum noise as neural network regularization" --mode co-pilot
Le pipeline execute les etapes 1-7 automatiquement...
┌─────────────────────────────────────────────────────────────┐
│ HITL | Stage 08: HYPOTHESIS_GEN │
│ Revue post-etape │
│ │
│ Hypotheses mentionnees : 3 │
│ Score de nouveaute : 0.72 (modere) │
│ │
│ [a] Approuver [r] Rejeter [e] Editer [c] Collaborer │
│ [i] Injecter un guidage [v] Voir la sortie [q] Annuler │
└─────────────────────────────────────────────────────────────┘
You: c (demarrer un chat collaboratif)
You: L'hypothese 3 est interessante mais il faut Dropout/Label Smoothing comme references
AI: Mis a jour — ajout de Dropout, Label Smoothing, MixUp, CutMix comme references...
You: approve
Le pipeline continue avec votre hypothese affinee...
```
### Commandes CLI
```bash
# Demarrer en mode HITL
researchclaw run --topic "..." --mode co-pilot
# S'attacher a un pipeline en pause (depuis un autre terminal)
researchclaw attach artifacts/rc-2026-xxx
# Verifier l'etat du pipeline et du HITL
researchclaw status artifacts/rc-2026-xxx
# Approuver/rejeter depuis un autre terminal ou script
researchclaw approve artifacts/rc-2026-xxx --message "LGTM"
researchclaw reject artifacts/rc-2026-xxx --reason "Reference cle manquante"
# Injecter un guidage pour une etape (meme avant son execution)
researchclaw guide artifacts/rc-2026-xxx --stage 9 --message "Utiliser ResNet-50 comme reference principale"
```
### Capacites cles
| Fonctionnalite | Description |
|----------------|------------|
| **Atelier d'Idees** | Brainstorming, evaluation et affinement collaboratif des hypotheses (etapes 7-8) |
| **Navigateur de References** | L'IA suggere des references + l'humain ajoute/supprime + checklist de reproductibilite (etape 9) |
| **Co-Redacteur d'Article** | Redaction section par section avec edition humaine et polissage IA (etapes 16-19) |
| **SmartPause** | Pause dynamique guidee par la confiance — detecte automatiquement quand une intervention humaine serait utile |
| **Verification des affirmations** | Verification factuelle en ligne contre la litterature collectee — signale les affirmations non fondees |
| **Garde-fous de budget** | Surveillance des couts avec alertes a seuils 50%/80%/100% |
| **Apprentissage d'intervention** | ALHF — apprend de vos habitudes de revision pour optimiser les futures decisions de pause |
| **Exploration par ramification** | Dupliquer le pipeline pour explorer plusieurs hypotheses, comparer, fusionner la meilleure |
| **Politique d'escalade** | Notification a niveaux (terminal → Slack → email → arret auto) en cas d'absence |
| **3 adaptateurs** | CLI (terminal), WebSocket (tableau de bord web), MCP (agents externes) |
### Configuration
```yaml
# config.arc.yaml
hitl:
enabled: true
mode: co-pilot # full-auto | gate-only | checkpoint | co-pilot | custom
cost_budget_usd: 50.0 # Pause quand le cout depasse le budget (0 = pas de limite)
notifications:
on_pause: true
on_quality_drop: true
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # 24h d'attente par defaut
auto_proceed_on_timeout: false
collaboration:
max_chat_turns: 50
save_chat_history: true
# Politiques personnalisees par etape (optionnel, pour le mode 'custom')
stage_policies:
8: { require_approval: true, enable_collaboration: true }
9: { require_approval: true, allow_edit_output: true }
```
### Retrocompatibilite
- **Par defaut : DESACTIVE.** Sans `hitl.enabled: true` ou `--mode`, le pipeline se comporte exactement comme avant.
- **`--auto-approve` fonctionne toujours.** Il prend le pas sur le mode HITL.
- **Les 2 699 tests existants passent** avec le code HITL present.
---
## 🧠 Integration MetaClaw
**AutoResearchClaw + [MetaClaw](https://github.com/aiming-lab/MetaClaw) = Un pipeline qui apprend de chaque execution.**
MetaClaw ajoute le **transfert de connaissances inter-executions** a AutoResearchClaw. Lorsqu'il est active, le pipeline capture automatiquement les lecons des echecs et avertissements, les convertit en competences reutilisables, et injecte ces competences dans les 23 etapes du pipeline lors des executions suivantes — pour ne jamais repeter les memes erreurs.
### Fonctionnement
```
Execution N s'execute → echecs/avertissements captures comme Lecons
↓
MetaClaw Lecon → conversion en Competence
↓
Fichiers de competences arc-* stockes dans ~/.metaclaw/skills/
↓
Execution N+1 → build_overlay() injecte les competences dans chaque prompt LLM
↓
Le LLM evite les pieges connus → meilleure qualite, moins de tentatives
```
### Configuration rapide
```bash
# 1. Installer MetaClaw (si ce n'est pas deja fait)
pip install metaclaw
# 2. Activer dans votre configuration
```
```yaml
# config.arc.yaml
metaclaw_bridge:
enabled: true
proxy_url: "http://localhost:30000" # Proxy MetaClaw (optionnel)
skills_dir: "~/.metaclaw/skills" # Ou les competences sont stockees
fallback_url: "https://api.openai.com/v1" # Repli direct vers le LLM
fallback_api_key: "" # Cle API pour l'URL de repli
lesson_to_skill:
enabled: true
min_severity: "warning" # Convertir avertissements + erreurs
max_skills_per_run: 3
```
```bash
# 3. Executez comme d'habitude — MetaClaw fonctionne de maniere transparente
researchclaw run --config config.arc.yaml --topic "Your idea" --auto-approve
```
Apres chaque execution, verifiez `~/.metaclaw/skills/arc-*/SKILL.md` pour voir les competences que votre pipeline a apprises.
### Resultats experimentaux
Dans des experiences controlees A/B (meme sujet, meme LLM, meme configuration) :
| Metrique | Reference | Avec MetaClaw | Amelioration |
|----------|-----------|---------------|--------------|
| Taux de relance des etapes | 10.5% | 7.9% | **-24.8%** |
| Nombre de cycles REFINE | 2.0 | 1.2 | **-40.0%** |
| Completion des etapes du pipeline | 18/19 | 19/19 | **+5.3%** |
| Score de robustesse global (composite) | 0.714 | 0.845 | **+18.3%** |
> Le score de robustesse composite est une moyenne ponderee du taux de completion des etapes (40%), de la reduction des tentatives (30%) et de l'efficacite des cycles REFINE (30%).
### Retrocompatibilite
- **Par defaut : DESACTIVE.** Si `metaclaw_bridge` est absent ou `enabled: false`, le pipeline se comporte exactement comme avant.
- **Aucune nouvelle dependance.** MetaClaw est optionnel — le pipeline de base fonctionne sans.
- **Les 2 699 tests existants passent** avec le code d'integration present.
---
## 🧩 Bibliotheque de competences
AutoResearchClaw supporte desormais le chargement de **competences open-source et personnalisees** pour enrichir votre experience de recherche. Nous livrons egalement **20 competences integrees pre-chargees** (redaction scientifique, recherche documentaire, chimie, biologie, et plus) comme references pretes a l'emploi, offrant un haut degre de flexibilite des l'installation. Desactivez n'importe quelle competence en ajoutant `enabled: false` a son frontmatter.
**Exemples de competences integrees :**
| Categorie | Competence | Description |
|-----------|------------|------------|
| **Redaction** | `scientific-writing` | Structure IMRAD, formatage des citations, directives de rapport |
| **Domaine** | `chemistry-rdkit` | Analyse moleculaire, SMILES, empreintes digitales, decouverte de medicaments |
| **Experience** | `literature-search` | Revue systematique, methodologie PRISMA |
> Voir les 20 competences avec `researchclaw skills list`.
### Charger vos propres competences
```bash
# Option 1 : Installer une competence (persiste entre les projets)
researchclaw skills install /path/to/my-skill/
# Option 2 : Deposer un SKILL.md dans le projet
mkdir -p .claude/skills/my-custom-skill
# Puis creer un SKILL.md avec frontmatter YAML (name, description, trigger-keywords, applicable-stages)
# Option 3 : Configurer des repertoires de competences partages dans config.arc.yaml
# skills:
# custom_dirs:
# - /path/to/team-shared-skills
```
### Utilisation des competences
Les competences sont chargees et injectees dans les prompts LLM automatiquement — aucune activation manuelle necessaire. Utilisez le CLI pour inspecter :
```bash
researchclaw skills list # Afficher toutes les competences chargees avec leurs sources
researchclaw skills validate ./my-skill # Verifier le format du SKILL.md
```
Parcourir les competences communautaires : [K-Dense-AI/claude-scientific-skills](https://github.com/K-Dense-AI/claude-scientific-skills) (150+ competences scientifiques couvrant plusieurs disciplines).
---
## ⚙️ Reference de configuration
Cliquez pour afficher la reference complete de configuration
```yaml
# === Projet ===
project:
name: "my-research" # Identifiant du projet
mode: "docs-first" # docs-first | semi-auto | full-auto
# === Recherche ===
research:
topic: "..." # Sujet de recherche (requis)
domains: ["ml", "nlp"] # Domaines de recherche pour la revue de litterature
daily_paper_count: 8 # Nombre cible d'articles par requete de recherche
quality_threshold: 4.0 # Score qualite minimum pour les articles
# === Execution ===
runtime:
timezone: "America/New_York" # Pour les horodatages
max_parallel_tasks: 3 # Limite d'experiences concurrentes
approval_timeout_hours: 12 # Timeout des etapes de validation
retry_limit: 2 # Nombre de tentatives en cas d'echec d'etape
# === LLM ===
llm:
provider: "openai-compatible" # openai | openrouter | deepseek | minimax | acp | openai-compatible
base_url: "https://..." # Point d'acces API (requis pour openai-compatible)
api_key_env: "OPENAI_API_KEY" # Variable d'env pour la cle API (requis pour openai-compatible)
api_key: "" # Ou cle en dur ici
primary_model: "gpt-4o" # Modele principal
fallback_models: ["gpt-4o-mini"] # Chaine de repli
s2_api_key: "" # Cle API Semantic Scholar (optionnel, limites de debit plus elevees)
acp: # Utilise uniquement quand provider: "acp"
agent: "claude" # Commande CLI de l'agent ACP (claude, codex, gemini, etc.)
cwd: "." # Repertoire de travail pour l'agent
# === Experience ===
experiment:
mode: "sandbox" # simulated | sandbox | docker | ssh_remote
time_budget_sec: 300 # Temps d'execution max par lancement (defaut : 300s)
max_iterations: 10 # Iterations d'optimisation max
metric_key: "val_loss" # Nom de la metrique principale
metric_direction: "minimize" # minimize | maximize
sandbox:
python_path: ".venv/bin/python"
gpu_required: false
allowed_imports: [math, random, json, csv, numpy, torch, sklearn]
max_memory_mb: 4096
docker:
image: "researchclaw/experiment:latest"
network_policy: "setup_only" # none | setup_only | pip_only | full
gpu_enabled: true
memory_limit_mb: 8192
auto_install_deps: true # Detection auto des imports → requirements.txt
ssh_remote:
host: "" # Nom d'hote du serveur GPU
gpu_ids: [] # Identifiants GPU disponibles
remote_workdir: "/tmp/researchclaw_experiments"
opencode: # OpenCode Beast Mode (auto-installe via `researchclaw setup`)
enabled: true # Interrupteur principal (defaut : true)
auto: true # Declenchement auto sans confirmation (defaut : true)
complexity_threshold: 0.2 # 0.0-1.0 — plus eleve = ne se declenche que pour les experiences complexes
model: "" # Modele a forcer (vide = utilise llm.primary_model)
timeout_sec: 600 # Duree max en secondes pour la generation OpenCode
max_retries: 1 # Nombre de tentatives en cas d'echec
workspace_cleanup: true # Supprimer l'espace de travail temporaire apres collecte
code_agent: # CodeAgent v2 — generation de code multi-phases
enabled: true # Utiliser CodeAgent au lieu de la generation mono-prompt heritee
architecture_planning: true # Generer un plan d'implementation detaille avant le codage
sequential_generation: true # Generer les fichiers un par un selon le DAG de dependances
hard_validation: true # Portes de validation basees sur AST (bloque les ablations identiques, metriques codees en dur)
hard_validation_max_repairs: 2 # Tentatives de reparation max en cas d'echec de validation
exec_fix_max_iterations: 3 # Tentatives de correction dans la boucle d'execution
exec_fix_timeout_sec: 60 # Timeout par tentative de correction d'execution
benchmark_agent: # BenchmarkAgent — selection automatisee de jeux de donnees et references
enabled: true # Activer le pipeline de benchmark a 4 agents (Surveyor→Selector→Acquirer→Validator)
enable_hf_search: true # Rechercher dans HuggingFace Datasets
enable_web_search: true # Rechercher des benchmarks sur Google Scholar
tier_limit: 2 # Filtrage par niveau de jeu de donnees (1=petit/cache, 2=moyen, 3=grand)
min_benchmarks: 1 # Nombre minimum de jeux de donnees requis
min_baselines: 2 # Nombre minimum de methodes de reference requises
figure_agent: # FigureAgent — generation de figures academiques
enabled: true # Activer le pipeline de figures a 5 agents (Planner→CodeGen→Renderer→Critic→Integrator)
min_figures: 3 # Nombre minimum de figures a generer
max_figures: 8 # Nombre maximum de figures
max_iterations: 3 # Iterations de raffinement guidees par le Critic
dpi: 300 # Resolution de sortie
strict_mode: false # Echouer le pipeline si la generation de figures echoue
repair: # Reparation d'experiences anti-fabrication
enabled: true # Diagnostiquer et reparer automatiquement les experiences echouees
max_cycles: 3 # Boucles de reparation
min_completion_rate: 0.5 # >=50% des conditions doivent etre completees pour continuer
min_conditions: 2 # Au moins 2 conditions pour une experience valide
use_opencode: true # Acheminer les reparations via OpenCode Beast Mode
# === Recherche Web (Optionnel) ===
web_search:
enabled: true # Activer la recherche de litterature augmentee par le web
tavily_api_key_env: "TAVILY_API_KEY" # Variable d'env pour la cle API Tavily (optionnel)
enable_scholar: true # Recherche Google Scholar
enable_pdf_extraction: true # Extraire le texte des PDF
max_web_results: 10 # Resultats web max par requete
# === Export ===
export:
target_conference: "neurips_2025" # neurips_2025 | iclr_2026 | icml_2026
authors: "Anonymous"
bib_file: "references"
# === Prompts ===
prompts:
custom_file: "" # Chemin vers un YAML de prompts personnalises (vide = defauts)
# === Co-Pilote HITL (NOUVEAU dans v0.4.0) ===
hitl:
enabled: false # Mettre a true pour activer le HITL
mode: co-pilot # full-auto | gate-only | checkpoint | step-by-step | co-pilot | custom
cost_budget_usd: 0.0 # Limite de cout en USD (0 = pas de limite)
notifications:
on_pause: true # Notifier quand le pipeline se met en pause
on_quality_drop: true # Notifier en cas de baisse de qualite
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # Attendre jusqu'a 24h pour une reponse humaine
auto_proceed_on_timeout: false # Si true, approuver automatiquement au timeout
collaboration:
max_chat_turns: 50 # Max de tours par session de collaboration
save_chat_history: true # Persister les logs de chat
stage_policies: {} # Surcharges par etape (pour le mode 'custom')
# === Securite ===
security:
hitl_required_stages: [5, 9, 20] # Etapes necessitant une approbation humaine
allow_publish_without_approval: false
redact_sensitive_logs: true
# === Base de connaissances ===
knowledge_base:
backend: "markdown" # markdown | obsidian
root: "docs/kb"
# === Notifications ===
notifications:
channel: "console" # console | discord | slack
target: ""
# === Pont MetaClaw (Optionnel) ===
metaclaw_bridge:
enabled: false # Mettre a true pour activer l'apprentissage inter-executions
proxy_url: "http://localhost:30000" # URL du proxy MetaClaw
skills_dir: "~/.metaclaw/skills" # Ou les competences arc-* sont stockees
fallback_url: "" # Repli direct vers le LLM quand le proxy est indisponible
fallback_api_key: "" # Cle API pour le point d'acces de repli
lesson_to_skill:
enabled: true # Conversion automatique des lecons en competences
min_severity: "warning" # Severite minimum pour la conversion
max_skills_per_run: 3 # Max de nouvelles competences par execution
prm: # Porte qualite Process Reward Model (optionnel)
enabled: false # Utiliser LLM-as-judge pour noter les sorties d'etape
model: "gpt-5.4" # Modele juge PRM
votes: 3 # Nombre de votes majoritaires
gate_stages: [5, 9, 15, 20] # Etapes auxquelles appliquer les portes PRM
# === Pont OpenClaw ===
openclaw_bridge:
use_cron: false # Executions de recherche planifiees
use_message: false # Notifications de progression
use_memory: false # Persistance des connaissances inter-sessions
use_sessions_spawn: false # Lancement de sous-sessions paralleles
use_web_fetch: false # Recherche web en direct
use_browser: false # Collecte d'articles via navigateur
```
---
## 🙏 Remerciements
Inspire par :
- 🔬 [AI Scientist](https://github.com/SakanaAI/AI-Scientist) (Sakana AI) — Pionnier de la recherche automatisee
- 🧠 [AutoResearch](https://github.com/karpathy/autoresearch) (Andrej Karpathy) — Automatisation de la recherche de bout en bout
- 🌐 [FARS](https://analemma.ai/blog/introducing-fars/) (Analemma) — Systeme de recherche entierement automatise
---
## 📄 Licence
MIT — voir [LICENSE](../LICENSE) pour les details.
---
## 📌 Citation
Si vous trouvez AutoResearchClaw utile, veuillez citer :
```bibtex
@misc{liu2026autoresearchclawselfreinforcingautonomousresearch,
title={AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration},
author={Jiaqi Liu and Shi Qiu and Mairui Li and Bingzhou Li and Haonian Ji and Siwei Han and Xinyu Ye and Peng Xia and Zihan Dong and Congyu Zhang and Letian Zhang and Guiming Chen and Haoqin Tu and Xinyu Yang and Lu Feng and Xujiang Zhao and Haifeng Chen and Jiawei Zhou and Xiao Wang and Weitong Zhang and Hongtu Zhu and Yun Li and Jieru Mei and Hongliang Fei and Jiaheng Zhang and Linjie Li and Linjun Zhang and Yuyin Zhou and Sheng Wang and Caiming Xiong and James Zou and Zeyu Zheng and Cihang Xie and Mingyu Ding and Huaxiu Yao},
year={2026},
eprint={2605.20025},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.20025},
}
```
Construit avec 🦞 par l'equipe AutoResearchClaw