
Converse uma ideia. Receba um artigo. Autônomo, Colaborativo & Auto-evolutivo.
Converse com o OpenClaw: "Pesquise X" → pronto.
📄 Nosso artigo está no arXiv — venha ler! AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration








🇺🇸 English ·
🇨🇳 中文 ·
🇯🇵 日本語 ·
🇰🇷 한국어 ·
🇫🇷 Français ·
🇩🇪 Deutsch ·
🇪🇸 Español ·
🇧🇷 Português ·
🇷🇺 Русский ·
🇸🇦 العربية
🏆 Galeria de Artigos · 🧑✈️ Guia do Co-Piloto · 📖 Guia de Integração · 💬 Comunidade Discord
---

|
🏆 Galeria de Artigos Gerados
8 artigos em 8 domínios — matemática, estatística, biologia, computação, NLP, RL, visão, robustez — gerados de forma totalmente autônoma ou com orientação de co-piloto Human-in-the-Loop.

|
---
> **🧪 Estamos procurando testadores!** Experimente o pipeline com sua própria ideia de pesquisa — de qualquer área — e [diga-nos o que achou](TESTER_GUIDE.md). Seu feedback molda diretamente a próxima versão. **[→ Testing Guide](TESTER_GUIDE.md)** | **[→ 中文测试指南](TESTER_GUIDE_CN.md)** | **[→ 日本語テストガイド](TESTER_GUIDE_JA.md)**
---
## 🔥 News
- **[05/19/2026]** **v0.5.0** — **Agentes de Experimento Multidomínio + ARC-Bench** — Duas atualizações principais. **(1) Agentes de execução especializados por domínio:** o estágio de experimentos (estágios 10–13) agora vai além do sandbox de ML padrão e roteia para agentes especializados por área — **física de altas energias** (ColliderAgent: FeynRules → MadGraph5 → Delphes via nuvem Magnus), **biologia** (modelagem metabólica em escala genômica com COBRApy) e **estatística** (agente de estudos de simulação), com um executor Docker genérico para química/materiais. O pipeline seleciona automaticamente o executor certo conforme o domínio. **(2) ARC-Bench:** um benchmark de pesquisa autônoma aberta com **55 tópicos** cobrindo **ML (25), física de altas energias (10), quântica (10), biologia (7) e estatística (3)**, cada um com um manifesto e uma rubrica de avaliação (`experiments/arc_bench/`, e também no [🤗 Hugging Face](https://huggingface.co/datasets/AIMING-Lab-UNC/ARC-Bench)). **[→ Guia de Integração de Domínios](DOMAIN_INTEGRATION_GUIDE.md)**
- **[04/01/2026]** **v0.4.0** — **Sistema Co-Piloto Human-in-the-Loop** — O AutoResearchClaw não é mais puramente autônomo. O novo sistema HITL adiciona 6 modos de intervenção (`full-auto`, `gate-only`, `checkpoint`, `step-by-step`, `co-pilot`, `custom`), políticas por estágio e colaboração profunda humano-IA. Inclui: Idea Workshop para co-criação de hipóteses, Baseline Navigator para revisão de design experimental, Paper Co-Writer para redação colaborativa, SmartPause (intervenção dinâmica baseada em confiança), aprendizado de intervenção ALHF, verificação de afirmações anti-alucinação, guardrails de orçamento de custo, ramificação de pipeline para exploração paralela de hipóteses e comandos CLI (`attach`/`status`/`approve`/`reject`/`guide`). **[→ Guia Completo HITL](HITL_GUIDE.md)**
- **[03/30/2026]** **Carregamento Flexível de Skills** — O AutoResearchClaw agora suporta o carregamento de skills open-source e customizadas de qualquer disciplina para aprimorar ainda mais sua experiência de pesquisa. 20 skills pré-carregadas estão incluídas como referências prontas para uso, cobrindo escrita científica, design experimental, química, biologia e mais — incluindo uma skill de evolução agêntica [A-Evolve](https://github.com/A-EVO-Lab/a-evolve) contribuída pela comunidade. Carregue as suas via `researchclaw skills install` ou coloque um `SKILL.md` em `.claude/skills/`. Veja [Biblioteca de Skills](#-biblioteca-de-skills).
- **[03/22/2026]** [v0.3.2](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.2) — **Suporte multiplataforma + grande estabilidade** — O AutoResearchClaw agora funciona com qualquer agente compativel com ACP (Claude Code, Codex CLI, Copilot CLI, Gemini CLI, Kimi CLI) e suporta plataformas de mensagens (Discord, Telegram, Lark, WeChat) via ponte OpenClaw. Novo backend de geracao de codigo CLI-agent que delega os Stages 10 e 13 a agentes CLI externos com controle de orcamento e gerenciamento de timeout. Inclui sistema anti-fabricacao (VerifiedRegistry + loop de diagnostico e reparo), 100+ correcoes de bugs, refatoracao modular do executor, auto-deteccao de `--resume`, endurecimento de retries LLM e correcoes da comunidade.
Versões anteriores
- **[03/18/2026]** [v0.3.1](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.1) — **OpenCode Beast Mode + Community Contributions** — New "Beast Mode" routes complex code generation to [OpenCode](https://github.com/anomalyco/opencode) with automatic complexity scoring and graceful fallback. Added Novita AI provider support, thread-safety hardening, improved LLM output parsing robustness, and 20+ bug fixes from community PRs and internal audit.
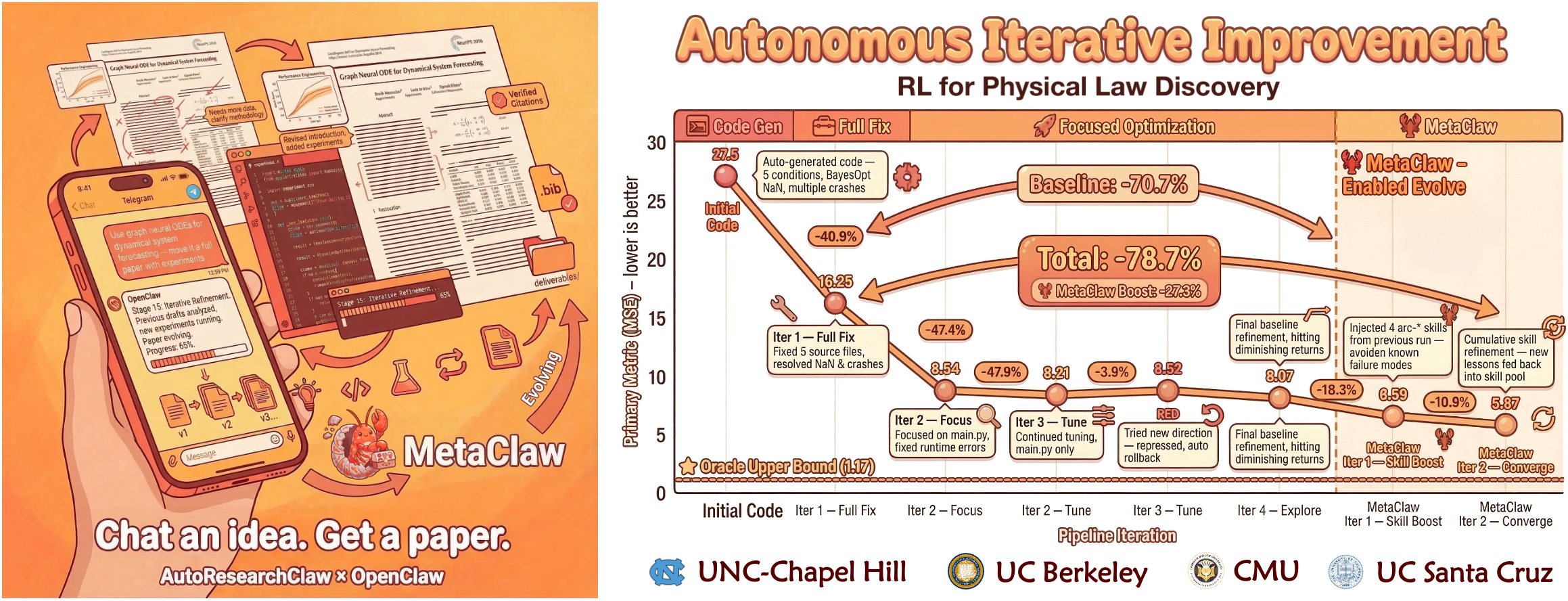
- **[03/17/2026]** [v0.3.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.3.0) — **MetaClaw Integration** — AutoResearchClaw now supports [MetaClaw](https://github.com/aiming-lab/MetaClaw) cross-run learning: pipeline failures → structured lessons → reusable skills, injected into all 23 stages. **+18.3%** robustness in controlled experiments. Opt-in (`metaclaw_bridge.enabled: true`), fully backward-compatible. See [Integration Guide](#-metaclaw-integration).
- **[03/16/2026]** [v0.2.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.2.0) — Three multi-agent subsystems (CodeAgent, BenchmarkAgent, FigureAgent), hardened Docker sandbox with network-policy-aware execution, 4-round paper quality audit (AI-slop detection, 7-dim review scoring, NeurIPS checklist), and 15+ bug fixes from production runs.
- **[03/15/2026]** [v0.1.0](https://github.com/aiming-lab/AutoResearchClaw/releases/tag/v0.1.0) — We release AutoResearchClaw: a fully autonomous 23-stage research pipeline that turns a single research idea into a conference-ready paper. No human intervention required.
---
## ⚡ Um Comando. Um Artigo.
```bash
# Totalmente autônomo — sem intervenção humana
pip install -e . && researchclaw setup && researchclaw init && researchclaw run --topic "Your research idea here" --auto-approve
# Modo Co-Piloto — colabore com a IA em pontos de decisão chave
researchclaw run --topic "Your research idea here" --mode co-pilot
```
---
## 🤔 O Que É Isto?
**Você pensa. AutoResearchClaw escreve. Você guia as decisões-chave.**
Forneça um tópico de pesquisa — receba de volta um artigo acadêmico completo com literatura real do OpenAlex, Semantic Scholar & arXiv, experimentos em sandbox com detecção automática de hardware (GPU/MPS/CPU), análise estatística, revisão por pares multi-agente, e LaTeX pronto para conferência mirando NeurIPS/ICML/ICLR. Execute de forma totalmente autônoma, ou use o **modo Co-Piloto** para guiar a IA em pontos de decisão críticos — escolha direções de pesquisa, revise designs experimentais e co-escreva o artigo. Sem referências alucinadas.
| 📄 | paper_draft.md | Artigo acadêmico completo (Introdução, Trabalhos Relacionados, Método, Experimentos, Resultados, Conclusão) |
| 📐 | paper.tex | LaTeX pronto para conferência (templates NeurIPS / ICLR / ICML) |
| 📚 | references.bib | Referências BibTeX reais do OpenAlex, Semantic Scholar e arXiv — auto-podadas para corresponder às citações inline |
| 🔍 | verification_report.json | Verificação de integridade + relevância de citações em 4 camadas (arXiv, CrossRef, DataCite, LLM) |
| 🧪 | experiment runs/ | Código gerado + resultados do sandbox + métricas JSON estruturadas |
| 📊 | charts/ | Gráficos de comparação de condições gerados automaticamente com barras de erro e intervalos de confiança |
| 📝 | reviews.md | Revisão por pares multi-agente com verificações de consistência metodologia-evidência |
| 🧬 | evolution/ | Lições de autoaprendizagem extraídas de cada execução |
| 📦 | deliverables/ | Todas as saídas finais em uma pasta — pronto para compilar no Overleaf |
O pipeline roda **de ponta a ponta** — totalmente autônomo ou com colaboração human-in-the-loop. Quando experimentos falham, ele se auto-repara. Quando hipóteses não se sustentam, ele pivota. Quando citações são falsas, ele as elimina. Quando você quer direcionar, ele pausa e escuta.
🌍 **Execute em qualquer lugar.** O AutoResearchClaw não está preso a uma única plataforma. Use-o de forma independente via CLI, conecte-o ao [OpenClaw](https://github.com/openclaw/openclaw), ou integre-o com qualquer agente compatível com ACP — 🤖 Claude Code, 💻 Codex CLI, 🐙 Copilot CLI, ♊ Gemini CLI, 🌙 Kimi CLI, e muito mais. Graças à ponte de mensagens do OpenClaw, você pode iniciar uma pesquisa completa pelo 💬 Discord, ✈️ Telegram, 🐦 Lark (飞书), 💚 WeChat, ou qualquer plataforma que sua equipe já utiliza. Um tópico na entrada, um artigo na saída — não importa de onde você digita.
---
## 🚀 Início Rápido
```bash
# 1. Clone & instale
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Setup (interativo — instala OpenCode beast mode, verifica Docker/LaTeX)
researchclaw setup
# 3. Configure
researchclaw init # Interativo: escolha provedor LLM, cria config.arc.yaml
# Ou manualmente: cp config.researchclaw.example.yaml config.arc.yaml
# 4. Execute
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "Your research idea" --auto-approve
```
Saída → `artifacts/rc-YYYYMMDD-HHMMSS-/deliverables/` — LaTeX, BibTeX, código de experimentos, gráficos prontos para compilação.
📝 Configuração mínima necessária
```yaml
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "https://api.openai.com/v1"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
```
---
## 🧠 O Que o Torna Diferente
| Capacidade | Como Funciona |
|-----------|-------------|
| **🧑✈️ Modo Co-Piloto** | 6 modos de intervenção — de totalmente autônomo a passo a passo. Guie a IA em decisões críticas (hipóteses, baselines, escrita do artigo) ou deixe-a executar livremente. SmartPause detecta automaticamente quando a contribuição humana ajudaria. |
| **🔄 Loop PIVOT / REFINE** | O Estágio 15 decide autonomamente: PROCEED, REFINE (ajustar parâmetros) ou PIVOT (nova direção). Artefatos versionados automaticamente. |
| **🤖 Debate Multi-Agente** | Geração de hipóteses, análise de resultados e revisão por pares usam debate estruturado com múltiplas perspectivas. |
| **🧬 Autoaprendizagem** | Lições extraídas por execução (justificativa de decisões, avisos de runtime, anomalias em métricas) com decaimento temporal de 30 dias. Execuções futuras aprendem com erros passados. |
| **📚 Base de Conhecimento** | Cada execução constrói uma KB estruturada com 6 categorias (decisões, experimentos, descobertas, literatura, questões, revisões). |
| **🛡️ Sentinel Watchdog** | Monitor de qualidade em segundo plano: detecção de NaN/Inf, consistência artigo-evidência, pontuação de relevância de citações, guarda anti-fabricação. |
| **🔍 Verificação de Afirmações** | Verificação de fatos inline: extrai afirmações do texto gerado por IA e cruza referências com a literatura coletada. Sinaliza citações infundadas e números fabricados. |
| **🌿 Exploração de Ramificações** | Bifurque o pipeline para explorar múltiplas direções de pesquisa simultaneamente, compare resultados lado a lado e mescle o melhor caminho. |
---
## 🦞 Integração OpenClaw
**AutoResearchClaw é um serviço compatível com [OpenClaw](https://github.com/openclaw/openclaw).** Instale-o no OpenClaw e inicie pesquisa autônoma com uma única mensagem — ou use-o de forma independente via CLI, Claude Code ou qualquer assistente de codificação IA.
### 🚀 Usar com OpenClaw (Recomendado)
Se você já usa o [OpenClaw](https://github.com/openclaw/openclaw) como seu assistente de IA:
```
1️⃣ Compartilhe a URL do repositório GitHub com o OpenClaw
2️⃣ O OpenClaw lê automaticamente RESEARCHCLAW_AGENTS.MD → entende o pipeline
3️⃣ Diga: "Pesquise [seu tópico]"
4️⃣ Pronto — o OpenClaw clona, instala, configura, executa e retorna os resultados
```
**É isso.** O OpenClaw gerencia `git clone`, `pip install`, configuração e execução do pipeline automaticamente. Você apenas conversa.
💡 O que acontece por baixo dos panos
1. O OpenClaw lê `RESEARCHCLAW_AGENTS.md` → aprende o papel de orquestrador de pesquisa
2. O OpenClaw lê `README.md` → entende a instalação e estrutura do pipeline
3. O OpenClaw copia `config.researchclaw.example.yaml` → `config.yaml`
4. Solicita sua chave de API do LLM (ou usa sua variável de ambiente)
5. Executa `pip install -e .` + `researchclaw run --topic "..." --auto-approve`
6. Retorna o artigo, LaTeX, experimentos e citações
### 🔌 Bridge OpenClaw (Avançado)
Para integração mais profunda, o AutoResearchClaw inclui um **sistema de adaptadores bridge** com 6 capacidades opcionais:
```yaml
# config.arc.yaml
openclaw_bridge:
use_cron: true # ⏰ Execuções de pesquisa agendadas
use_message: true # 💬 Notificações de progresso (Discord/Slack/Telegram)
use_memory: true # 🧠 Persistência de conhecimento entre sessões
use_sessions_spawn: true # 🔀 Criar sub-sessões paralelas para estágios concorrentes
use_web_fetch: true # 🌐 Busca web ao vivo durante revisão de literatura
use_browser: false # 🖥️ Coleta de artigos baseada em navegador
```
Cada flag ativa um protocolo de adaptador tipado. Quando o OpenClaw fornece essas capacidades, os adaptadores as consomem sem alterações no código. Consulte [`integration-guide.md`](integration-guide.md) para detalhes completos.
### ACP (Agent Client Protocol)
O AutoResearchClaw pode usar **qualquer agente de codificação compatível com ACP** como seu backend LLM — sem necessidade de chaves de API. O agente se comunica via [acpx](https://github.com/openclaw/acpx), mantendo uma única sessão persistente ao longo de todos os 23 estágios do pipeline.
| Agente | Comando | Notas |
|-------|---------|-------|
| Claude Code | `claude` | Anthropic |
| Codex CLI | `codex` | OpenAI |
| Copilot CLI | `gh` | GitHub |
| Gemini CLI | `gemini` | Google |
| OpenCode | `opencode` | SST |
| Kimi CLI | `kimi` | Moonshot |
```yaml
# config.yaml — exemplo ACP
llm:
provider: "acp"
acp:
agent: "claude" # Qualquer comando CLI de agente compatível com ACP
cwd: "." # Diretório de trabalho para o agente
# Sem base_url ou api_key necessários — o agente gerencia sua própria autenticação.
```
```bash
# Basta executar — o agente usa suas próprias credenciais
researchclaw run --config config.yaml --topic "Your research idea" --auto-approve
```
### 🛠️ Outras Formas de Executar
| Método | Como |
|--------|------|
| **CLI Independente** | `researchclaw run --topic "..." --auto-approve` (autônomo) ou `--mode co-pilot` (colaborativo) |
| **API Python** | `from researchclaw.pipeline import Runner; Runner(config).run()` |
| **Claude Code** | Lê `RESEARCHCLAW_CLAUDE.md` — basta dizer *"Execute pesquisa sobre [tópico]"* |
| **Copilot CLI** | `researchclaw run --topic "..."` com `llm.acp.agent: "gh"` |
| **OpenCode** | Lê `.claude/skills/` — mesma interface em linguagem natural |
| **Qualquer CLI de IA** | Forneça `RESEARCHCLAW_AGENTS.md` como contexto → o agente faz bootstrap automaticamente |
---
## 🔬 Pipeline: 23 Estágios, 8 Fases
```
Fase A: Escopo da Pesquisa Fase E: Execução de Experimentos
1. TOPIC_INIT 12. EXPERIMENT_RUN
2. PROBLEM_DECOMPOSE 13. ITERATIVE_REFINE ← auto-reparo
Fase B: Descoberta de Literatura Fase F: Análise & Decisão
3. SEARCH_STRATEGY 14. RESULT_ANALYSIS ← multi-agente
4. LITERATURE_COLLECT ← API real 15. RESEARCH_DECISION ← PIVOT/REFINE
5. LITERATURE_SCREEN [gate]
6. KNOWLEDGE_EXTRACT Fase G: Escrita do Artigo
16. PAPER_OUTLINE
Fase C: Síntese de Conhecimento 17. PAPER_DRAFT
7. SYNTHESIS 18. PEER_REVIEW ← verif. evidência
8. HYPOTHESIS_GEN ← debate 19. PAPER_REVISION
Fase D: Design de Experimentos Fase H: Finalização
9. EXPERIMENT_DESIGN [gate] 20. QUALITY_GATE [gate]
10. CODE_GENERATION 21. KNOWLEDGE_ARCHIVE
11. RESOURCE_PLANNING 22. EXPORT_PUBLISH ← LaTeX
23. CITATION_VERIFY ← verif. relevância
```
> **Estágios gate** (5, 9, 20) pausam para aprovação humana ou aprovam automaticamente com `--auto-approve`. Em caso de rejeição, o pipeline faz rollback.
> **Modo Co-Piloto** (`--mode co-pilot`): Colaboração profunda humano-IA nos Estágios 7-8 (Idea Workshop), Estágio 9 (Baseline Navigator) e Estágios 16-17 (Paper Co-Writer). Os outros estágios executam automaticamente com monitoramento SmartPause.
> **Loops de decisão**: O Estágio 15 pode acionar REFINE (→ Estágio 13) ou PIVOT (→ Estágio 8), com versionamento automático de artefatos.
📋 O Que Cada Fase Faz
| Fase | O Que Acontece |
|------|----------------|
| **A: Escopo** | O LLM decompõe o tópico em uma árvore de problemas estruturada com questões de pesquisa |
| **A+: Hardware** | Detecta automaticamente GPU (NVIDIA CUDA / Apple MPS / apenas CPU), avisa se o hardware local é limitado, adapta a geração de código adequadamente |
| **B: Literatura** | Busca multi-fonte (OpenAlex → Semantic Scholar → arXiv) por artigos reais, triagem por relevância, extração de fichas de conhecimento |
| **C: Síntese** | Agrupa descobertas, identifica lacunas de pesquisa, gera hipóteses testáveis via debate multi-agente |
| **D: Design** | Projeta plano de experimento, gera Python executável com consciência de hardware (tier de GPU → seleção de pacotes), estima necessidades de recursos |
| **E: Execução** | Executa experimentos em sandbox, detecta NaN/Inf e bugs de runtime, auto-repara código via reparo direcionado por LLM |
| **F: Análise** | Análise multi-agente dos resultados; decisão autônoma PROCEED / REFINE / PIVOT com justificativa |
| **G: Escrita** | Outline → redação seção por seção (5.000-6.500 palavras) → revisão por pares (com consistência metodologia-evidência) → revisão com guarda de tamanho |
| **H: Finalização** | Quality gate, arquivamento de conhecimento, exportação LaTeX com template de conferência, verificação de integridade + relevância de citações |
---
## ✨ Funcionalidades Principais
| Funcionalidade | Descrição |
|---------|------------|
| **📚 Literatura Multi-Fonte** | Artigos reais do OpenAlex, Semantic Scholar & arXiv — expansão de consultas, deduplicação, circuit breaker com degradação graciosa |
| **🔍 Verificação de Citações em 4 Camadas** | Verificação de arXiv ID → CrossRef/DataCite DOI → correspondência de título no Semantic Scholar → pontuação de relevância por LLM. Referências alucinadas removidas automaticamente. |
| **🖥️ Execução com Consciência de Hardware** | Detecta automaticamente GPU (NVIDIA CUDA / Apple MPS / apenas CPU) e adapta geração de código, imports e escala de experimentos |
| **🦾 OpenCode Beast Mode** | Experimentos complexos roteados automaticamente para o [OpenCode](https://github.com/anomalyco/opencode) — gera projetos multi-arquivo com arquiteturas customizadas, loops de treinamento e estudos de ablação. Instale via `researchclaw setup`. |
| **🧪 Experimentos em Sandbox** | Código validado por AST, harness imutável, fast-fail para NaN/Inf, reparo auto-reparável, refinamento iterativo (até 10 rodadas), captura de resultados parciais |
| **📝 Escrita com Qualidade de Conferência** | Templates NeurIPS/ICML/ICLR, redação seção por seção (5.000-6.500 palavras), guarda anti-fabricação, guarda de tamanho na revisão, imposição anti-disclaimer |
| **📐 Troca de Template** | `neurips_2025`, `iclr_2026`, `icml_2026` — Markdown → LaTeX com matemática, tabelas, figuras, referências cruzadas, `\cite{}` |
| **🛡️ Anti-Fabricação** | VerifiedRegistry impõe dados experimentais reais nos artigos. Diagnostica automaticamente experimentos falhados e os repara antes da escrita. Números não verificados são sanitizados. |
| **🚦 Quality Gates** | 3 gates com human-in-the-loop (Estágios 5, 9, 20) com rollback. Pule com `--auto-approve`. |
| **🧑✈️ Co-Piloto HITL** | 6 modos de intervenção com políticas por estágio. Idea Workshop, Baseline Navigator, Paper Co-Writer para colaboração profunda. SmartPause, guardrails de custo, políticas de escalação e aprendizado de intervenção para segurança em produção. Adaptadores CLI/WebSocket/MCP. |
| **💰 Guardrails de Custo** | Monitoramento de orçamento com alertas de limite configuráveis (50%/80%/100%). O pipeline pausa automaticamente quando o custo excede o orçamento. |
| **🔐 Reprodutibilidade** | Checksums SHA256 para todos os artefatos de estágio. Manifestos imutáveis para verificação. Undo multi-nível com snapshots versionados. |
---
## 🧑✈️ Co-Piloto Human-in-the-Loop
**O AutoResearchClaw v0.4.0 introduz um sistema Human-in-the-Loop (HITL) completo** que transforma o pipeline de puramente autônomo para um motor de pesquisa colaborativa humano-IA. Escolha seu nível de envolvimento:
### Modos de Intervenção
| Modo | Comando | O Que Faz |
|------|---------|-----------|
| **Full Auto** | `--auto-approve` | Comportamento original — sem intervenção humana |
| **Gate Only** | `--mode gate-only` | Pausa nos 3 estágios gate (5, 9, 20) para aprovação |
| **Checkpoint** | `--mode checkpoint` | Pausa em cada fronteira de fase (8 checkpoints) |
| **Co-Pilot** | `--mode co-pilot` | Colaboração profunda em estágios críticos, automático nos demais |
| **Step-by-Step** | `--mode step-by-step` | Pausa após cada estágio — aprenda o pipeline |
| **Express** | `--mode express` | Revisão rápida — apenas os 3 gates mais críticos |
### Fluxo de Trabalho do Co-Piloto
```
Você: researchclaw run --topic "Ruído quântico como regularização de redes neurais" --mode co-pilot
Pipeline executa Estágios 1-7 automaticamente...
┌─────────────────────────────────────────────────────────────┐
│ HITL | Estágio 08: HYPOTHESIS_GEN │
│ Revisão pós-estágio │
│ │
│ Hipóteses mencionadas: 3 │
│ Pontuação de novidade: 0.72 (moderada) │
│ │
│ [a] Aprovar [r] Rejeitar [e] Editar [c] Colaborar │
│ [i] Injetar orientação [v] Ver saída [q] Abortar │
└─────────────────────────────────────────────────────────────┘
Você: c (iniciar chat colaborativo)
Você: Hipótese 3 é interessante mas precisa de Dropout/Label Smoothing como baselines
IA: Atualizado — adicionei Dropout, Label Smoothing, MixUp, CutMix como baselines...
Você: approve
Pipeline continua com sua hipótese refinada...
```
### Comandos CLI
```bash
# Iniciar com modo HITL
researchclaw run --topic "..." --mode co-pilot
# Anexar a um pipeline pausado (de outro terminal)
researchclaw attach artifacts/rc-2026-xxx
# Verificar status do pipeline e HITL
researchclaw status artifacts/rc-2026-xxx
# Aprovar/rejeitar de outro terminal ou script
researchclaw approve artifacts/rc-2026-xxx --message "LGTM"
researchclaw reject artifacts/rc-2026-xxx --reason "Baseline chave faltando"
# Injetar orientação para um estágio (mesmo antes de ele executar)
researchclaw guide artifacts/rc-2026-xxx --stage 9 --message "Usar ResNet-50 como baseline principal"
```
### Capacidades Principais
| Funcionalidade | Descrição |
|---------|------------|
| **Idea Workshop** | Brainstorm, avalie e refine hipóteses de forma colaborativa (Estágio 7-8) |
| **Baseline Navigator** | IA sugere baselines + humano adiciona/remove + checklist de reprodutibilidade (Estágio 9) |
| **Paper Co-Writer** | Redação seção por seção com edição humana e polimento por IA (Estágio 16-19) |
| **SmartPause** | Pausa dinâmica baseada em confiança — detecta automaticamente quando a contribuição humana ajudaria |
| **Verificação de Afirmações** | Verificação de fatos inline contra a literatura coletada — sinaliza afirmações infundadas |
| **Guardrails de Custo** | Monitoramento de orçamento com alertas de limite 50%/80%/100% |
| **Aprendizado de Intervenção** | ALHF — aprende com seus padrões de revisão para otimizar futuras decisões de pausa |
| **Exploração de Ramificações** | Bifurque o pipeline para explorar múltiplas hipóteses, compare e mescle a melhor |
| **Política de Escalação** | Notificação em camadas (terminal → Slack → email → auto-halt) quando desacompanhado |
| **3 Adaptadores** | CLI (terminal), WebSocket (dashboard web), MCP (agentes externos) |
### Configuração
```yaml
# config.arc.yaml
hitl:
enabled: true
mode: co-pilot # full-auto | gate-only | checkpoint | co-pilot | custom
cost_budget_usd: 50.0 # Pausar quando custo exceder orçamento (0 = sem limite)
notifications:
on_pause: true
on_quality_drop: true
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # Espera padrão de 24h
auto_proceed_on_timeout: false
collaboration:
max_chat_turns: 50
save_chat_history: true
# Políticas customizadas por estágio (opcional, para modo 'custom')
stage_policies:
8: { require_approval: true, enable_collaboration: true }
9: { require_approval: true, allow_edit_output: true }
```
### Compatibilidade Retroativa
- **Padrão: DESATIVADO.** Sem `hitl.enabled: true` ou `--mode`, o pipeline funciona exatamente como antes.
- **`--auto-approve` ainda funciona.** Ele sobrescreve o modo HITL.
- **Todos os 2.699 testes existentes passam** com o código HITL presente.
---
## 🧠 Integração MetaClaw
**AutoResearchClaw + [MetaClaw](https://github.com/aiming-lab/MetaClaw) = Um pipeline que aprende com cada execução.**
MetaClaw adiciona **transferência de conhecimento entre execuções** ao AutoResearchClaw. Quando ativado, o pipeline captura automaticamente lições de falhas e avisos, converte-as em habilidades reutilizáveis e injeta essas habilidades em todos os 23 estágios do pipeline em execuções subsequentes — para que os mesmos erros nunca se repitam.
### Como Funciona
```
Run N executa → falhas/avisos capturados como Lessons
↓
MetaClaw Lesson → conversão em Skill
↓
Arquivos arc-* Skill armazenados em ~/.metaclaw/skills/
↓
Run N+1 → build_overlay() injeta skills em cada prompt LLM
↓
LLM evita armadilhas conhecidas → maior qualidade, menos retentativas
```
### Configuração Rápida
```bash
# 1. Instale o MetaClaw (se ainda não tiver)
pip install metaclaw
# 2. Ative na sua configuração
```
```yaml
# config.arc.yaml
metaclaw_bridge:
enabled: true
proxy_url: "http://localhost:30000" # Proxy MetaClaw (opcional)
skills_dir: "~/.metaclaw/skills" # Onde as skills são armazenadas
fallback_url: "https://api.openai.com/v1" # Fallback direto para LLM
fallback_api_key: "" # Chave de API para URL de fallback
lesson_to_skill:
enabled: true
min_severity: "warning" # Converte warnings + errors
max_skills_per_run: 3
```
```bash
# 3. Execute normalmente — MetaClaw funciona de forma transparente
researchclaw run --config config.arc.yaml --topic "Your idea" --auto-approve
```
Após cada execução, verifique `~/.metaclaw/skills/arc-*/SKILL.md` para ver as skills que seu pipeline aprendeu.
### Resultados dos Experimentos
Em experimentos A/B controlados (mesmo tópico, mesmo LLM, mesma configuração):
| Métrica | Baseline | Com MetaClaw | Melhoria |
|---------|----------|---------------|----------|
| Taxa de retentativa por estágio | 10.5% | 7.9% | **-24.8%** |
| Contagem de ciclos REFINE | 2.0 | 1.2 | **-40.0%** |
| Conclusão de estágios do pipeline | 18/19 | 19/19 | **+5.3%** |
| Pontuação de robustez geral (composta) | 0.714 | 0.845 | **+18.3%** |
> A pontuação composta de robustez é uma média ponderada da taxa de conclusão de estágios (40%), redução de retentativas (30%) e eficiência de ciclos REFINE (30%).
### Compatibilidade Retroativa
- **Padrão: DESATIVADO.** Se `metaclaw_bridge` estiver ausente ou `enabled: false`, o pipeline funciona exatamente como antes.
- **Sem novas dependências.** MetaClaw é opcional — o pipeline principal funciona sem ele.
- **Todos os 2.699 testes existentes passam** com o código de integração presente.
---
## 🧩 Biblioteca de Skills
O AutoResearchClaw agora suporta o carregamento de **skills open-source e customizadas** para aprimorar ainda mais sua experiência de pesquisa. Também incluímos **20 skills integradas pré-carregadas** (escrita científica, busca de literatura, química, biologia e mais) como referências prontas para uso, oferecendo um alto grau de flexibilidade desde o início. Desabilite qualquer skill adicionando `enabled: false` ao seu frontmatter.
**Exemplos de skills integradas:**
| Categoria | Skill | Descrição |
|-----------|-------|-----------|
| **Escrita** | `scientific-writing` | Estrutura IMRAD, formatação de citações, diretrizes de relatórios |
| **Domínio** | `chemistry-rdkit` | Análise molecular, SMILES, fingerprints, descoberta de fármacos |
| **Experimento** | `literature-search` | Revisão sistemática, metodologia PRISMA |
> Veja todas as 20 skills com `researchclaw skills list`.
### Carregue Suas Próprias Skills
```bash
# Opção 1: Instalar uma skill (persiste entre projetos)
researchclaw skills install /path/to/my-skill/
# Opção 2: Coloque um SKILL.md no projeto
mkdir -p .claude/skills/my-custom-skill
# Depois crie um SKILL.md com frontmatter YAML (name, description, trigger-keywords, applicable-stages)
# Opção 3: Configure diretórios compartilhados de skills no config.arc.yaml
# skills:
# custom_dirs:
# - /path/to/team-shared-skills
```
### Usando Skills
Skills são carregadas e injetadas nos prompts LLM automaticamente — sem ativação manual necessária. Use o CLI para inspecionar:
```bash
researchclaw skills list # Mostra todas as skills carregadas com fontes
researchclaw skills validate ./my-skill # Verifica formato do SKILL.md
```
Explore skills da comunidade: [K-Dense-AI/claude-scientific-skills](https://github.com/K-Dense-AI/claude-scientific-skills) (150+ skills científicas em múltiplas disciplinas).
---
## ⚙️ Referência de Configuração
Clique para expandir a referência completa de configuração
```yaml
# === Projeto ===
project:
name: "my-research" # Identificador do projeto
mode: "docs-first" # docs-first | semi-auto | full-auto
# === Pesquisa ===
research:
topic: "..." # Tópico de pesquisa (obrigatório)
domains: ["ml", "nlp"] # Domínios de pesquisa para busca de literatura
daily_paper_count: 8 # Artigos alvo por consulta de busca
quality_threshold: 4.0 # Pontuação mínima de qualidade para artigos
# === Runtime ===
runtime:
timezone: "America/New_York" # Para timestamps
max_parallel_tasks: 3 # Limite de experimentos concorrentes
approval_timeout_hours: 12 # Timeout de estágios gate
retry_limit: 2 # Contagem de retentativas em falha de estágio
# === LLM ===
llm:
provider: "openai-compatible" # openai | openrouter | deepseek | minimax | acp | openai-compatible
base_url: "https://..." # Endpoint da API (obrigatório para openai-compatible)
api_key_env: "OPENAI_API_KEY" # Variável de ambiente para chave da API (obrigatório para openai-compatible)
api_key: "" # Ou insira a chave diretamente aqui
primary_model: "gpt-4o" # Modelo primário
fallback_models: ["gpt-4o-mini"] # Cadeia de fallback
s2_api_key: "" # Chave API do Semantic Scholar (opcional, limites de taxa maiores)
acp: # Usado apenas quando provider: "acp"
agent: "claude" # Comando CLI do agente ACP (claude, codex, gemini, etc.)
cwd: "." # Diretório de trabalho para o agente
# === Experimento ===
experiment:
mode: "sandbox" # simulated | sandbox | docker | ssh_remote
time_budget_sec: 300 # Tempo máximo de execução por run (padrão: 300s)
max_iterations: 10 # Máximo de iterações de otimização
metric_key: "val_loss" # Nome da métrica primária
metric_direction: "minimize" # minimize | maximize
sandbox:
python_path: ".venv/bin/python"
gpu_required: false
allowed_imports: [math, random, json, csv, numpy, torch, sklearn]
max_memory_mb: 4096
docker:
image: "researchclaw/experiment:latest"
network_policy: "setup_only" # none | setup_only | pip_only | full
gpu_enabled: true
memory_limit_mb: 8192
auto_install_deps: true # Detecção automática de imports → requirements.txt
ssh_remote:
host: "" # Hostname do servidor GPU
gpu_ids: [] # IDs de GPU disponíveis
remote_workdir: "/tmp/researchclaw_experiments"
opencode: # OpenCode Beast Mode (auto-instalado via `researchclaw setup`)
enabled: true # Interruptor principal (padrão: true)
auto: true # Acionamento automático sem confirmação (padrão: true)
complexity_threshold: 0.2 # 0.0-1.0 — maior = só aciona em experimentos complexos
model: "" # Modelo override (vazio = usa llm.primary_model)
timeout_sec: 600 # Máximo de segundos para geração OpenCode
max_retries: 1 # Contagem de retentativas em falha
workspace_cleanup: true # Remove workspace temporário após coleta
code_agent: # CodeAgent v2 — geração de código multi-fase
enabled: true # Usar CodeAgent em vez da geração legada de prompt único
architecture_planning: true # Gerar blueprint detalhado de implementação antes de codificar
sequential_generation: true # Gerar arquivos um a um seguindo o DAG de dependências
hard_validation: true # Validação baseada em AST (bloqueia ablações idênticas, métricas hardcoded)
hard_validation_max_repairs: 2 # Máximo de tentativas de reparo quando validação falha
exec_fix_max_iterations: 3 # Tentativas de correção na execução
exec_fix_timeout_sec: 60 # Timeout por tentativa de correção
benchmark_agent: # BenchmarkAgent — seleção automatizada de datasets e baselines
enabled: true # Ativar pipeline de 4 agentes (Surveyor→Selector→Acquirer→Validator)
enable_hf_search: true # Buscar em HuggingFace Datasets
enable_web_search: true # Buscar benchmarks no Google Scholar
tier_limit: 2 # Filtragem de tier de datasets (1=pequeno/cache, 2=médio, 3=grande)
min_benchmarks: 1 # Mínimo de datasets necessários
min_baselines: 2 # Mínimo de métodos baseline necessários
figure_agent: # FigureAgent — geração de figuras acadêmicas
enabled: true # Ativar pipeline de 5 agentes (Planner→CodeGen→Renderer→Critic→Integrator)
min_figures: 3 # Mínimo de figuras a gerar
max_figures: 8 # Máximo de figuras
max_iterations: 3 # Iterações de refinamento via Critic
dpi: 300 # Resolução de saída
strict_mode: false # Falhar pipeline se geração de figuras falhar
repair: # Anti-fabricação — reparo de experimentos
enabled: true # Auto-diagnosticar e reparar experimentos falhados
max_cycles: 3 # Ciclos de reparo
min_completion_rate: 0.5 # >=50% das condições devem completar para prosseguir
min_conditions: 2 # Mínimo de 2 condições para experimento válido
use_opencode: true # Rotear reparos pelo OpenCode Beast Mode
# === Busca Web (Opcional) ===
web_search:
enabled: true # Ativar busca de literatura com web
tavily_api_key_env: "TAVILY_API_KEY" # Variável de ambiente para chave Tavily API (opcional)
enable_scholar: true # Busca no Google Scholar
enable_pdf_extraction: true # Extrair texto de PDFs
max_web_results: 10 # Máximo de resultados web por consulta
# === Exportação ===
export:
target_conference: "neurips_2025" # neurips_2025 | iclr_2026 | icml_2026
authors: "Anonymous"
bib_file: "references"
# === Prompts ===
prompts:
custom_file: "" # Caminho para YAML de prompts customizados (vazio = padrões)
# === Co-Piloto HITL (NOVO no v0.4.0) ===
hitl:
enabled: false # Defina como true para ativar HITL
mode: co-pilot # full-auto | gate-only | checkpoint | step-by-step | co-pilot | custom
cost_budget_usd: 0.0 # Limite de custo em USD (0 = sem limite)
notifications:
on_pause: true # Notificar quando o pipeline pausar
on_quality_drop: true # Notificar em problemas de qualidade
channels: ["terminal"] # terminal | slack | webhook
timeouts:
default_human_timeout_sec: 86400 # Esperar até 24h por entrada humana
auto_proceed_on_timeout: false # Se true, auto-aprovar no timeout
collaboration:
max_chat_turns: 50 # Máximo de turnos por sessão de colaboração
save_chat_history: true # Persistir logs de chat
stage_policies: {} # Overrides por estágio (para modo 'custom')
# === Segurança ===
security:
hitl_required_stages: [5, 9, 20] # Estágios que requerem aprovação humana
allow_publish_without_approval: false
redact_sensitive_logs: true
# === Base de Conhecimento ===
knowledge_base:
backend: "markdown" # markdown | obsidian
root: "docs/kb"
# === Notificações ===
notifications:
channel: "console" # console | discord | slack
target: ""
# === MetaClaw Bridge (Opcional) ===
metaclaw_bridge:
enabled: false # Defina como true para ativar aprendizado entre execuções
proxy_url: "http://localhost:30000" # URL do proxy MetaClaw
skills_dir: "~/.metaclaw/skills" # Onde as skills arc-* são armazenadas
fallback_url: "" # Fallback direto para LLM quando o proxy está fora
fallback_api_key: "" # Chave de API para endpoint de fallback
lesson_to_skill:
enabled: true # Auto-converter lições em skills
min_severity: "warning" # Severidade mínima para converter
max_skills_per_run: 3 # Máximo de novas skills por execução do pipeline
prm: # Process Reward Model quality gate (opcional)
enabled: false # Usar LLM-as-judge para pontuar saídas de estágio
model: "gpt-5.4" # Modelo juiz PRM
votes: 3 # Contagem de votos por maioria
gate_stages: [5, 9, 15, 20] # Estágios onde aplicar gates PRM
# === Bridge OpenClaw ===
openclaw_bridge:
use_cron: false # Execuções de pesquisa agendadas
use_message: false # Notificações de progresso
use_memory: false # Persistência de conhecimento entre sessões
use_sessions_spawn: false # Criar sub-sessões paralelas
use_web_fetch: false # Busca web ao vivo
use_browser: false # Coleta de artigos baseada em navegador
```
---
## 🙏 Agradecimentos
Inspirado por:
- 🔬 [AI Scientist](https://github.com/SakanaAI/AI-Scientist) (Sakana AI) — Pioneiro em pesquisa automatizada
- 🧠 [AutoResearch](https://github.com/karpathy/autoresearch) (Andrej Karpathy) — Automação de pesquisa de ponta a ponta
- 🌐 [FARS](https://analemma.ai/blog/introducing-fars/) (Analemma) — Fully Automated Research System
---
## 📄 Licença
MIT — veja [LICENSE](../LICENSE) para detalhes.
---
## 📌 Citação
Se você achar o AutoResearchClaw útil, por favor cite:
```bibtex
@misc{liu2026autoresearchclawselfreinforcingautonomousresearch,
title={AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration},
author={Jiaqi Liu and Shi Qiu and Mairui Li and Bingzhou Li and Haonian Ji and Siwei Han and Xinyu Ye and Peng Xia and Zihan Dong and Congyu Zhang and Letian Zhang and Guiming Chen and Haoqin Tu and Xinyu Yang and Lu Feng and Xujiang Zhao and Haifeng Chen and Jiawei Zhou and Xiao Wang and Weitong Zhang and Hongtu Zhu and Yun Li and Jieru Mei and Hongliang Fei and Jiaheng Zhang and Linjie Li and Linjun Zhang and Yuyin Zhou and Sheng Wang and Caiming Xiong and James Zou and Zeyu Zheng and Cihang Xie and Mingyu Ding and Huaxiu Yao},
year={2026},
eprint={2605.20025},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.20025},
}
```
Construído com 🦞 pela equipe AutoResearchClaw