Guide to the Functional API
functional_api.RmdThe Keras functional API is the way to go for defining complex models, such as multi-output models, directed acyclic graphs, or models with shared layers.
This guide assumes that you are already familiar with the Sequential model.
Let’s start with something simple.
First example: a densely-connected network
The Sequential model is probably a better choice to implement such a network, but it helps to start with something really simple.
To use the functional API, build your input and output layers and then pass them to the model() function. This model can be trained just like Keras sequential models.
library(keras)
# input layer
inputs <- layer_input(shape = c(784))
# outputs compose input + dense layers
predictions <- inputs %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dense(units = 10, activation = 'softmax')
# create and compile model
model <- keras_model(inputs = inputs, outputs = predictions)
model %>% compile(
optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = c('accuracy')
)Note that Keras objects are modified in place which is why it’s not necessary for model to be assigned back to after it is compiled.
All models are callable, just like layers
With the functional API, it is easy to reuse trained models: you can treat any model as if it were a layer. Note that you aren’t just reusing the architecture of the model, you are also reusing its weights.
x <- layer_input(shape = c(784))
# This works, and returns the 10-way softmax we defined above.
y <- x %>% modelThis can allow, for instance, to quickly create models that can process sequences of inputs. You could turn an image classification model into a video classification model, in just one line:
Multi-input and multi-output models
Here’s a good use case for the functional API: models with multiple inputs and outputs. The functional API makes it easy to manipulate a large number of intertwined datastreams.
Let’s consider the following model. We seek to predict how many retweets and likes a news headline will receive on Twitter. The main input to the model will be the headline itself, as a sequence of words, but to spice things up, our model will also have an auxiliary input, receiving extra data such as the time of day when the headline was posted, etc.
The model will also be supervised via two loss functions. Using the main loss function earlier in a model is a good regularization mechanism for deep models.
Here’s what our model looks like:
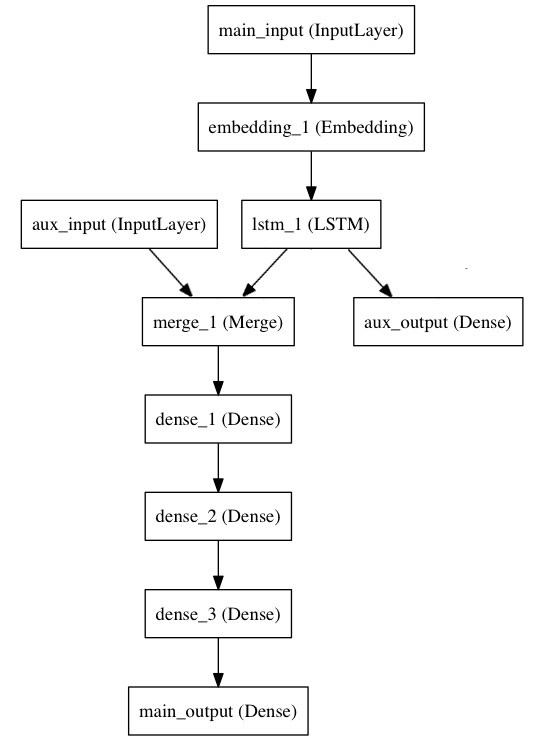
Let’s implement it with the functional API.
The main input will receive the headline, as a sequence of integers (each integer encodes a word). The integers will be between 1 and 10,000 (a vocabulary of 10,000 words) and the sequences will be 100 words long.
We’ll include an
library(keras)
main_input <- layer_input(shape = c(100), dtype = 'int32', name = 'main_input')
lstm_out <- main_input %>%
layer_embedding(input_dim = 10000, output_dim = 512, input_length = 100) %>%
layer_lstm(units = 32)Here we insert the auxiliary loss, allowing the LSTM and Embedding layer to be trained smoothly even though the main loss will be much higher in the model:
auxiliary_output <- lstm_out %>%
layer_dense(units = 1, activation = 'sigmoid', name = 'aux_output')At this point, we feed into the model our auxiliary input data by concatenating it with the LSTM output, stacking a deep densely-connected network on top and adding the main logistic regression layer
auxiliary_input <- layer_input(shape = c(5), name = 'aux_input')
main_output <- layer_concatenate(c(lstm_out, auxiliary_input)) %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dense(units = 1, activation = 'sigmoid', name = 'main_output')This defines a model with two inputs and two outputs:
model <- keras_model(
inputs = c(main_input, auxiliary_input),
outputs = c(main_output, auxiliary_output)
)Model
__________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==========================================================================================
main_input (InputLayer) (None, 100) 0
__________________________________________________________________________________________
embedding_1 (Embedding) (None, 100, 512) 5120000
__________________________________________________________________________________________
lstm_1 (LSTM) (None, 32) 69760
__________________________________________________________________________________________
aux_input (InputLayer) (None, 5) 0
__________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 37) 0
__________________________________________________________________________________________
dense_1 (Dense) (None, 64) 2432
__________________________________________________________________________________________
dense_2 (Dense) (None, 64) 4160
__________________________________________________________________________________________
dense_3 (Dense) (None, 64) 4160
__________________________________________________________________________________________
main_output (Dense) (None, 1) 65
__________________________________________________________________________________________
aux_output (Dense) (None, 1) 33
==========================================================================================
Total params: 5,200,610
Trainable params: 5,200,610
Non-trainable params: 0
__________________________________________________________________________________________We compile the model and assign a weight of 0.2 to the auxiliary loss. To specify different loss_weights or loss for each different output, you can use a list or a dictionary. Here we pass a single loss as the loss argument, so the same loss will be used on all outputs.
model %>% compile(
optimizer = 'rmsprop',
loss = 'binary_crossentropy',
loss_weights = c(1.0, 0.2)
)We can train the model by passing it lists of input arrays and target arrays:
model %>% fit(
x = list(headline_data, additional_data),
y = list(labels, labels),
epochs = 50,
batch_size = 32
)Since our inputs and outputs are named (we passed them a “name” argument), We could also have compiled the model via:
model %>% compile(
optimizer = 'rmsprop',
loss = list(main_output = 'binary_crossentropy', aux_output = 'binary_crossentropy'),
loss_weights = list(main_output = 1.0, aux_output = 0.2)
)
# And trained it via:
model %>% fit(
x = list(main_input = headline_data, aux_input = additional_data),
y = list(main_output = labels, aux_output = labels),
epochs = 50,
batch_size = 32
)The concept of layer “node”
Whenever you are calling a layer on some input, you are creating a new tensor (the output of the layer), and you are adding a “node” to the layer, linking the input tensor to the output tensor. When you are calling the same layer multiple times, that layer owns multiple nodes indexed as 1, 2, 2…
You can obtain the output tensor of a layer via layer$output, or its output shape via layer$output_shape. But what if a layer is connected to multiple inputs?
As long as a layer is only connected to one input, there is no confusion, and $output will return the one output of the layer:
a <- layer_input(shape = c(280, 256))
lstm <- layer_lstm(units = 32)
encoded_a <- a %>% lstm
lstm$outputNot so if the layer has multiple inputs:
a <- layer_input(shape = c(280, 256))
b <- layer_input(shape = c(280, 256))
lstm <- layer_lstm(units = 32)
encoded_a <- a %>% lstm
encoded_b <- b %>% lstm
lstm$outputAttributeError: Layer lstm_4 has multiple inbound nodes, hence the notion of "layer output" is ill-defined. Use `get_output_at(node_index)` instead.Okay then. The following works:
Simple enough, right?
The same is true for the properties input_shape and output_shape: as long as the layer has only one node, or as long as all nodes have the same input/output shape, then the notion of “layer output/input shape” is well defined, and that one shape will be returned by layer$output_shape/layer$input_shape. But if, for instance, you apply the same layer_conv_2d() layer to an input of shape (32, 32, 3), and then to an input of shape (64, 64, 3), the layer will have multiple input/output shapes, and you will have to fetch them by specifying the index of the node they belong to:
a <- layer_input(shape = c(32, 32, 3))
b <- layer_input(shape = c(64, 64, 3))
conv <- layer_conv_2d(filters = 16, kernel_size = c(3,3), padding = 'same')
conved_a <- a %>% conv
# only one input so far, the following will work
conv$input_shape
conved_b <- b %>% conv
# now the `$input_shape` property wouldn't work, but this does:
get_input_shape_at(conv, 1)
get_input_shape_at(conv, 2) More examples
Code examples are still the best way to get started, so here are a few more.
Inception module
For more information about the Inception architecture, see Going Deeper with Convolutions.
library(keras)
input_img <- layer_input(shape = c(256, 256, 3))
tower_1 <- input_img %>%
layer_conv_2d(filters = 64, kernel_size = c(1, 1), padding='same', activation='relu') %>%
layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding='same', activation='relu')
tower_2 <- input_img %>%
layer_conv_2d(filters = 64, kernel_size = c(1, 1), padding='same', activation='relu') %>%
layer_conv_2d(filters = 64, kernel_size = c(5, 5), padding='same', activation='relu')
tower_3 <- input_img %>%
layer_max_pooling_2d(pool_size = c(3, 3), strides = c(1, 1), padding = 'same') %>%
layer_conv_2d(filters = 64, kernel_size = c(1, 1), padding='same', activation='relu')
output <- layer_concatenate(c(tower_1, tower_2, tower_3), axis = 1)Residual connection on a convolution layer
For more information about residual networks, see Deep Residual Learning for Image Recognition.
Visual question answering model
This model can select the correct one-word answer when asked a natural-language question about a picture.
It works by encoding the question into a vector, encoding the image into a vector, concatenating the two, and training on top a logistic regression over some vocabulary of potential answers.
# First, let's define a vision model using a Sequential model.
# This model will encode an image into a vector.
vision_model <- keras_model_sequential()
vision_model %>%
layer_conv_2d(filters = 64, kernel_size = c(3, 3), activation = 'relu', padding = 'same',
input_shape = c(224, 224, 3)) %>%
layer_conv_2d(filters = 64, kernel_size = c(3, 3), activation = 'relu') %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_conv_2d(filters = 128, kernel_size = c(3, 3), activation = 'relu', padding = 'same') %>%
layer_conv_2d(filters = 128, kernel_size = c(3, 3), activation = 'relu') %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_conv_2d(filters = 256, kernel_size = c(3, 3), activation = 'relu', padding = 'same') %>%
layer_conv_2d(filters = 256, kernel_size = c(3, 3), activation = 'relu') %>%
layer_conv_2d(filters = 256, kernel_size = c(3, 3), activation = 'relu') %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_flatten()
# Now let's get a tensor with the output of our vision model:
image_input <- layer_input(shape = c(224, 224, 3))
encoded_image <- image_input %>% vision_model
# Next, let's define a language model to encode the question into a vector.
# Each question will be at most 100 word long,
# and we will index words as integers from 1 to 9999.
question_input <- layer_input(shape = c(100), dtype = 'int32')
encoded_question <- question_input %>%
layer_embedding(input_dim = 10000, output_dim = 256, input_length = 100) %>%
layer_lstm(units = 256)
# Let's concatenate the question vector and the image vector then
# train a logistic regression over 1000 words on top
output <- layer_concatenate(c(encoded_question, encoded_image)) %>%
layer_dense(units = 1000, activation='softmax')
# This is our final model:
vqa_model <- keras_model(inputs = c(image_input, question_input), outputs = output)Video question answering model
Now that we have trained our image QA model, we can quickly turn it into a video QA model. With appropriate training, you will be able to show it a short video (e.g. 100-frame human action) and ask a natural language question about the video (e.g. “what sport is the boy playing?” -> “football”).
video_input <- layer_input(shape = c(100, 224, 224, 3))
# This is our video encoded via the previously trained vision_model (weights are reused)
encoded_video <- video_input %>%
time_distributed(vision_model) %>%
layer_lstm(units = 256)
# This is a model-level representation of the question encoder, reusing the same weights as before:
question_encoder <- keras_model(inputs = question_input, outputs = encoded_question)
# Let's use it to encode the question:
video_question_input <- layer_input(shape = c(100), dtype = 'int32')
encoded_video_question <- video_question_input %>% question_encoder
# And this is our video question answering model:
output <- layer_concatenate(c(encoded_video, encoded_video_question)) %>%
layer_dense(units = 1000, activation = 'softmax')
video_qa_model <- keras_model(inputs= c(video_input, video_question_input), outputs = output)