
Données pondérées
Ce chapitre est évoqué dans le webin-R #10 (Données pondérées, plan d’échantillonnage complexe & survey) sur YouTube.
S’il est tout à fait possible de travailler avec des données pondérées sous R, cette fonctionnalité n’est pas aussi bien intégrée que dans la plupart des autres logiciels de traitement statistique. En particulier, il y a plusieurs manières possibles de gérer la pondération. Cependant, lorsque l’on doit également prendre un compte un plan d’échantillonnage complexe (voir section dédiée ci-après), R fournit tous les outils nécessaires, alors que dans la plupart des logiciels propriétaires, il faut disposer d’une extension adéquate, pas toujours vendue de base avec le logiciel.
Dans ce qui suit, on utilisera le jeu de données tiré de l’enquête Histoire de vie et notamment sa variable de pondération poids1.
library(questionr)
data(hdv2003)
d <- hdv2003
range(d$poids)[1] 78.07834 31092.14132Options de certaines fonctions
Tout d’abord, certaines fonctions de R acceptent en argument un vecteur permettant de pondérer les observations (l’option est en général nommée weights ou row.w). C’est le cas par exemple des méthodes d’estimation de modèles linéaires2 (lm) ou de modèles linéaires généralisés 3 (glm) ou dans les analyses de correspondances4 des extensions ade4 ou FactoMineR.
Par contre cette option n’est pas présente dans les fonctions de base comme mean, var, table ou chisq.test.
Données pondérées avec l’extension survey
L’extension survey est spécialement dédiée au traitement d’enquêtes ayant des techniques d’échantillonnage et de pondération potentiellement très complexes.
L’extension s’installe comme la plupart des autres :
install.packages("survey")Le site officiel (en anglais) comporte beaucoup d’informations, mais pas forcément très accessibles :
http://r-survey.r-forge.r-project.org/.
Pour utiliser les fonctionnalités de l’extension, on doit d’abord définir le plan d’échantillonnage ou design de notre enquête, c’est-à-dire indiquer quel type de pondération nous souhaitons lui appliquer.
Dans un premier temps, nous utiliserons le plan d’échantillonnage le plus simple, avec une variable de pondération déjà calculée. Pour d’autres types de plan d’échantillonnage, voir la chapitre sur les plans d’échantillonnage complexes.
Ceci se fait à l’aide de la fonction svydesign :
library(survey)
dw <- svydesign(ids = ~1, data = d, weights = ~ d$poids)Cette fonction crée un nouvel objet, que nous avons nommé dw. Cet objet n’est pas à proprement parler un tableau de données, mais plutôt un tableau de données plus une méthode de pondération. dw et d sont des objets distincts, les opérations effectuées sur l’un n’ont pas d’influence sur l’autre. On peut cependant retrouver le contenu de d depuis dw en utilisant dw$variables :
str(d$age) int [1:2000] 28 23 59 34 71 35 60 47 20 28 ...str(dw$variables$age) int [1:2000] 28 23 59 34 71 35 60 47 20 28 ...Lorsque notre plan d’échantillonnage est déclaré, on peut lui appliquer une série de fonctions permettant d’effectuer diverses opérations statistiques en tenant compte de la pondération. On citera notamment :
svymean,svyvar,svytotal,svyquantile: statistiques univariées (moyenne, variance, total, quantiles)svytable: tri à plat et tableau croisésvychisq: test du χ²svyby: statistiques selon un facteursvyttest: test t de Student de comparaison de moyennessvyciprop: intervalle de confiance d’une proportionsvyglm: modèles linéaires généralisés (dont régression logistique)svyplot,svyhist,svyboxplot: fonctions graphiques
D’autres fonctions sont disponibles, comme svyratio, mais elles ne seront pas abordées ici.
Pour ne rien arranger, ces fonctions prennent leurs arguments sous forme de formules5, c’est-à-dire pas de la manière habituelle. En général l’appel de fonction se fait en spécifiant d’abord les variables d’intérêt sous forme de formule, puis l’objet survey.design.
Voyons tout de suite quelques exemples6 :
svymean(~age, dw) mean SE
age 46.347 0.5284svyquantile(~age, dw, quantile = c(0.25, 0.5, 0.75), ci = TRUE)$age
quantile ci.2.5 ci.97.5 se
0.25 31 31 33 0.5099045
0.5 45 44 47 0.7648568
0.75 60 59 63 1.0198091
attr(,"hasci")
[1] TRUE
attr(,"class")
[1] "newsvyquantile"svyvar(~heures.tv, dw, na.rm = TRUE) variance SE
heures.tv 2.9886 0.1836Les tris à plat se déclarent en passant comme argument le nom de la variable précédé d’un tilde (~), tandis que les tableaux croisés utilisent les noms des deux variables séparés par un signe plus (+) et précédés par un tilde (~).
svytable(~sexe, dw)sexe
Homme Femme
5149382 5921844 svytable(~ sexe + clso, dw) clso
sexe Oui Non Ne sait pas
Homme 2658744.04 2418187.64 72450.75
Femme 2602031.76 3242389.36 77422.79La fonction freq peut être utilisée si on lui passe en argument non pas la variable elle-même, mais son tri à plat obtenu avec svytable :
tab <- svytable(~peche.chasse, dw)
freq(tab, total = TRUE)On peut également récupérer le tableau issu de svytable dans un objet et le réutiliser ensuite comme n’importe quel tableau croisé :
tab <- svytable(~ sexe + clso, dw)
tab clso
sexe Oui Non Ne sait pas
Homme 2658744.04 2418187.64 72450.75
Femme 2602031.76 3242389.36 77422.79Les fonctions lprop et cprop de questionr sont donc tout à fait compatibles avec l’utilisation de survey.
lprop(tab) clso
sexe Oui Non Ne sait pas Total
Homme 51.6 47.0 1.4 100.0
Femme 43.9 54.8 1.3 100.0
Ensemble 47.5 51.1 1.4 100.0Le principe de la fonction svyby est similaire à celui de tapply7. Elle permet de calculer des statistiques selon plusieurs sous-groupes définis par un facteur. Par exemple :
svyby(~age, ~sexe, dw, svymean)gtsummary et survey
L’extension gtsummary fournit une fonction tbl_svysummary, similaire à tbl_summary, mais adaptée aux objets survey.
library(gtsummary)
theme_gtsummary_language("fr", decimal.mark = ",", big.mark = " ")Setting theme `language: fr`dw %>% tbl_svysummary(include = c("age", "sexe", "clso", "peche.chasse"))| Caractéristique | N = 11 071 2261 |
|---|---|
| age | 45 (31 – 60) |
| sexe | |
| Homme | 5 149 382 (47%) |
| Femme | 5 921 844 (53%) |
| clso | |
| Oui | 5 260 776 (48%) |
| Non | 5 660 577 (51%) |
| Ne sait pas | 149 874 (1,4%) |
| peche.chasse | |
| Non | 9 716 683 (88%) |
| Oui | 1 354 544 (12%) |
|
1
Médiane (EI); n (%)
|
|
dw %>%
tbl_svysummary(
include = c("age", "sexe", "clso", "peche.chasse"),
by = "sexe"
) %>%
add_overall(last = TRUE) %>%
add_p()| Caractéristique | Homme, N = 5 149 3821 | Femme, N = 5 921 8441 | Total, N = 11 071 2261 | p-valeur2 |
|---|---|---|---|---|
| age | 44 (30 – 59) | 45 (32 – 61) | 45 (31 – 60) | 0,067 |
| clso | 0,036 | |||
| Oui | 2 658 744 (52%) | 2 602 032 (44%) | 5 260 776 (48%) | |
| Non | 2 418 188 (47%) | 3 242 389 (55%) | 5 660 577 (51%) | |
| Ne sait pas | 72 451 (1,4%) | 77 423 (1,3%) | 149 874 (1,4%) | |
| peche.chasse | <0,001 | |||
| Non | 4 101 242 (80%) | 5 615 441 (95%) | 9 716 683 (88%) | |
| Oui | 1 048 141 (20%) | 306 403 (5,2%) | 1 354 544 (12%) | |
|
1
Médiane (EI); n (%)
2
test de Wilcoxon sur la somme des rangs adapté aux plans d'échantillonnage complexes; test du Chi² avec la correction du second ordre de Rao & Scott
|
||||
Graphiques natifs avec survey
survey est également capable de produire des graphiques à partir des données pondérées. Quelques exemples :
par(mfrow = c(2, 2))
svyplot(~ age + heures.tv, dw, col = "red", main = "Bubble plot")
svyhist(~heures.tv, dw, col = "peachpuff", main = "Histogramme")
svyboxplot(age ~ 1, dw, main = "Boxplot simple", ylab = "Âge")
svyboxplot(age ~ sexe, dw, main = "Boxplot double", ylab = "Âge", xlab = "Sexe")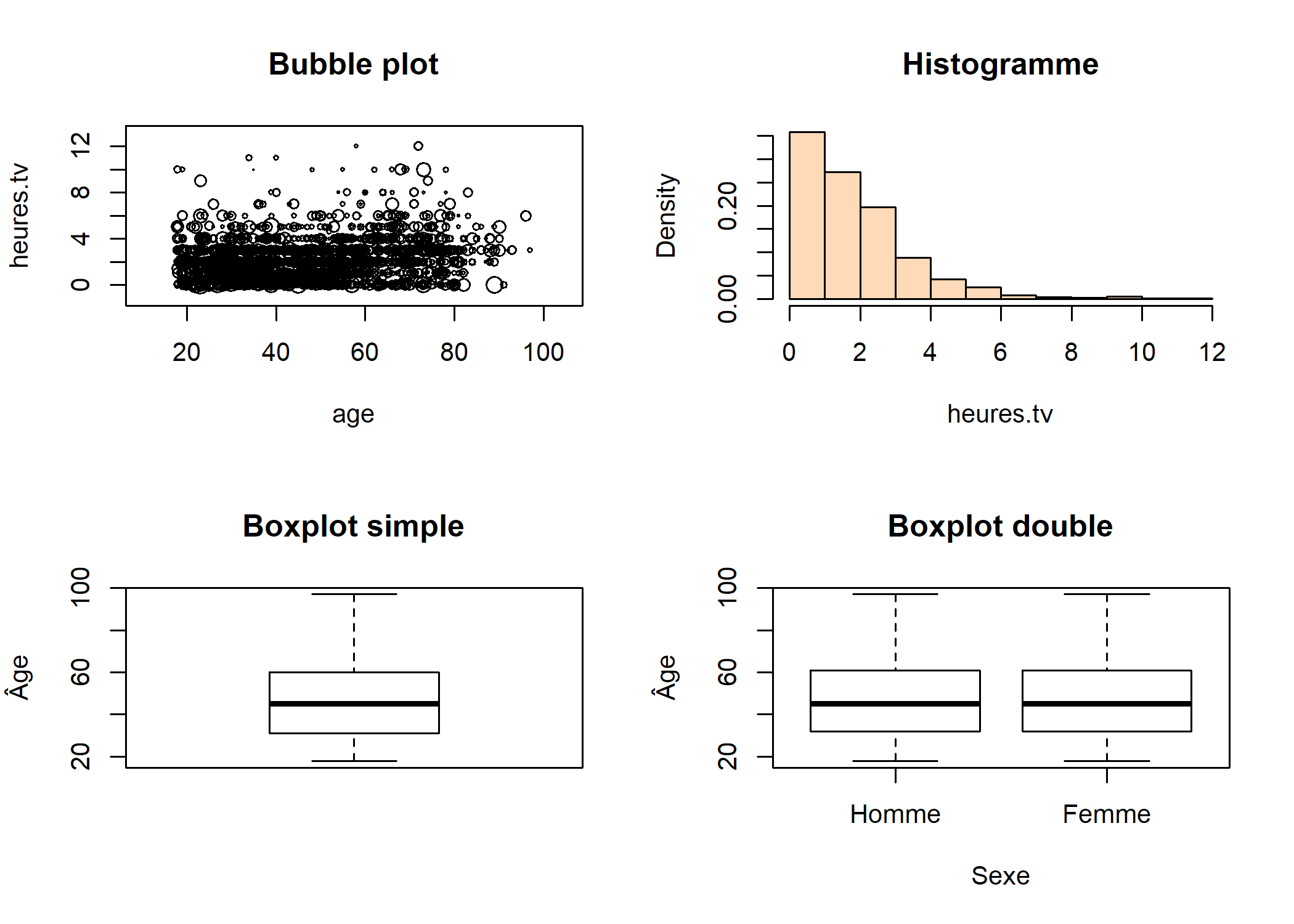
Graphiques ggplot2
ggplot2 accepte une esthétique weight pour indiquer des poids à prendre en compte dans les différents graphiques. La fonction weights permets justement de récupérer les poids d’un objet survey. La fonction ggplot n’accepte pas d’objet survey mais a besoin d’un tableau de données. Ce dernier peut être récupéré avec $variables.
library(ggplot2)
ggplot(dw$variables) +
aes(weight = weights(dw), x = sexe, fill = clso) +
geom_bar(position = "fill")
ATTENTION : les graphiques obtenus ne sont corrects qu’à la condition que seuls les poids soient nécessaires pour les construire, ce qui est le cas d’un nuage de points ou d’un diagramme en barres. Par contre, si le calcul du graphique implique le calcul de variance, la représentation sera incorrecte. Par exemple, avec geom_smooth, les aires de confiance affichées ne prendront pas correctement en compte le plan d’échantillonnage.
L’extenstion questionr propose, dans sa version de développement, une fonction ggsurvey pour faciliter les choses. Elle prend un objet survey, extrait le tableau de données et les poids, associe les poids à l’esthétique correspondante et appelle ggplot.
library(questionr)
ggsurvey(dw) +
aes(x = sexe, fill = clso) +
geom_bar(position = "fill")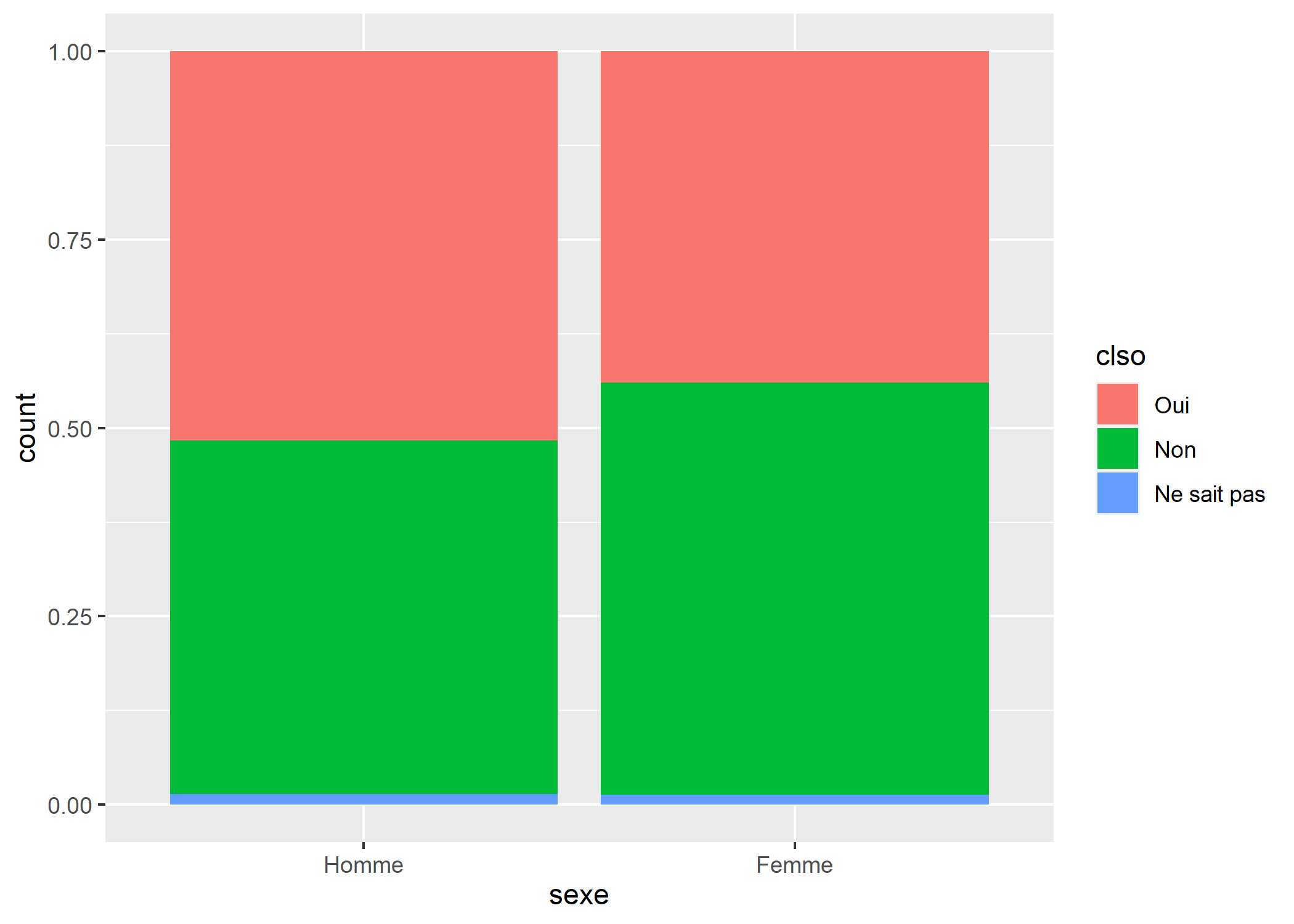
Pour installer la version de développement de questionr, on pourra utiliser la commande suivante :
if (!require(devtools)) {
install.packages("devtools")
library(devtools)
}
install_github("juba/questionr")Extraire un sous-échantillon
Si l’on souhaite travailler sur un sous-échantillon tout en gardant les informations d’échantillonnage, on utilisera la fonction subset présentée en détail dans le chapitre Sous-ensembles.
sous <- subset(dw, sexe == "Femme" & age >= 40)Modèles logistiques
Pour réaliser des modèles logistiques (binaires, multinomiaux ou ordinaux) avec prise en compte d’un plan d’échantillonnage, on pourra se référer à la sous-section dédiée du chapitre Régression logistique.
dplyr et survey
L’extension srvyr vise à permettre d’utiliser les verbes de dplyr avec survey. Le fonctionnement de cette extension est expliqué dans une vignette dédiée : https://cran.r-project.org/web/packages/srvyr/vignettes/srvyr-vs-survey.html.
Conclusion
Si, la gestion de la pondération sous R n’est sans doute pas ce qui se fait de plus pratique et de plus simple, on pourra quand même donner les conseils suivants :
- utiliser les options de pondération des fonctions usuelles ou les fonctions d’extensions comme
questionrpour les cas les plus simples ; - si on utilise
survey, effectuer autant que possible tous les recodages et manipulations sur les données non pondérées ; - une fois les recodages effectués, on déclare le design et on fait les analyses en tenant compte de la pondération ;
- surtout ne jamais modifier les variables du design. Toujours effectuer recodages et manipulations sur les données non pondérées, puis redéclarer le design pour que les mises à jour effectuées soient disponibles pour l’analyse.
On notera que cette variable est utilisée à titre purement illustratif. Le jeu de données étant un extrait d’enquête et la variable de pondération n’ayant pas été recalculée, elle n’a ici à proprement parler aucun sens.↩︎
Voir le chapitre régression linéaire.↩︎
Voir le chapitre sur la régression logistique.↩︎
Voir le chapitre dédié à l’analyse des correspondances.↩︎
Pour plus de détails sur les formules, voir le chapitre dédié.↩︎
Pour d’autres exemples, voir http://www.ats.ucla.edu/stat/r/faq/svy_r_oscluster.htm (en anglais).↩︎
La fonction
tapplyest présentée plus en détails dans le chapitre Manipulation de données.↩︎